基于乏信息融合技術的機床加工誤差的調整方法
2016-07-26 01:49:29夏新濤朱文換陳士忠
中國機械工程 2016年13期
夏新濤 朱文換 陳士忠
河南科技大學,洛陽,471003
?
基于乏信息融合技術的機床加工誤差的調整方法
夏新濤朱文換陳士忠
河南科技大學,洛陽,471003
摘要:基于融合隸屬函數法、最大隸屬度法、滾動均值法、算術平均值法和自助法,提出一種乏信息融合技術,以實現機床加工誤差的調整。首先運用乏信息融合技術融合機床試加工時輸出的小樣本數據,獲取機床試加工時工件的估計真值,以調整機床的加工誤差,使工件滿足質量要求;然后獲取機床調整后輸出的小樣本可靠數據,運用模糊集合理論,在給定的置信水平下,預測可靠數據的估計區間。仿真和試驗結果表明:運用乏信息融合技術,可實現對機床加工誤差的調整。調整后的機床是可靠的,驗證了運用乏信息融合技術調整機床的可行性。
關鍵詞:乏信息融合;機床;誤差;調整;可靠性;模糊集合理論
0引言
一個復雜的機械加工過程是由若干工序組成的,在機械加工的每一道工序中總是需要對工藝系統進行調整,因而會產生調整誤差。機床調整的基本方法有試切法和調整法,通常采用試切法調整,即對工件進行試切-測量-調整-再試切,直到工件達到要求的精度為止[1-3]。
對于制造過程而言,在大批量生產條件下,對軸承套圈磨削尺寸控制時,要對磨削系統進行調整。短期的調整過程可以看成一個靜態過程,若短期內連續試磨少量工件(4~10個),那么得到的幾個數據就構成了小樣本數據序列,可以用靜態方法分析。
采用乏信息系統理論分析,可以不考慮隨機變量的概率分布問題,即使是小樣本數據[4],用一種方法就可以評估具有不同概率分布的隨機變量。在乏信息系統屬性真值估計中,由于缺乏信息,一般要用多種方法對計算結果進行校正、融合與綜合考慮,以從多個側面獲取系統的屬性信息。因不同方法有不同準則,故所獲取的屬性信息各異。這些屬性信息與系統的屬性真值有關,可以構成一個集合,即估計真值集合。顯然,該集合從不同側面描述了系統的屬性特征。利用真值融合技術[5-7]將這些信息進行融合,就可以更合理地估計出系統的屬性真值。
本文基于融合隸屬函數法、最大隸屬度法、滾動均值法、算術平均值法和自助法,提出采用一種乏信息融合技術來調整機床的加工誤差,并運用模糊集合理論[3,8],判斷調整后的機床的可靠性[9]。
1加工誤差的乏信息融合技術
乏信息融合技術的第一步是用5種方法從原始數據序列獲取5個初始估計真值;第二步是將這5個初始估計真值作為真值融合序列,再用這5種方法對真值融合序列進行多次融合,將獲得的滿足極差準則的最終融合值作為機床調整時有關工件的最終估計真值。
1.1獲取小樣本數據
假設在機床調整階段,機床試加工過程中輸出的小樣本數據,構成一個小樣本原始數據序列,用向量X表示為
X=(x(1),x(2),…,x(n),…,x(N))
(1)
n=1,2,…,N
式中,X為機床調整時輸出的小樣本原始數據序列;x(n)為X中的第n個數據;N為X的數據個數,一般取4~10。
1.2用乏信息融合技術預測估計真值
隸屬函數法在機床調整階段,將原始數據序列X從小到大排序并重新編號,可得到數據序列Γ:
Γ=(x1,x2,…xi,…,xN)
(2)
且有
xi≤xi+1i=1,2,…N-1
(3)
定義差值序列d為
d=(d1,d2,…di,…,dN-1)
(4)
其中
di=xi+1-xi
一般di越小,數據越密集,反之越疏松,即di和xi的分布密度有關。為此,假設線性隸屬函數mi(即概率密度因子)為
(5)
其中,最小差值和最大差值分別為
dmin=mindi
dmax=maxdi
設緊鄰均值序列Z為
Z=(z1,z2,…,zi,…,zN-1)
(6)
其中
機床加工系統的一個初始估計真值X01為
(7)
最大隸屬度法基于上述的隸屬函數法,設最大隸屬度mmax為
mmax=maxmi=1
(8)
取對應mmax的xv+1和xv的均值作為原始數據序列的初始估計真值X02,即
(9)
若有T個重復的mmax,則設第t個均值為解的進行時X0t:
(10)
機床加工系統的一個初始估計真值X02為
(11)
自助法在機床調整階段,從原始數據序列X中等概率可放回地抽樣,每次抽取1個數據共抽取N個數據,得到一個自助樣本Xb,連續重復抽取B次,得到B個自助再抽樣樣本:
Xb=(xb(1),xb(2),…,xb(n),…,xb(N))
(12)
b=1,2,…,B
式中,Xb為第b個自助樣本;xb(n)為Xb中的第n個數據;N為Xb的數據個數。
求自助樣本Xb的均值:
從而得到一個樣本含量為B的自助大樣本XG:
XG=(X1,X2,…,Xb,…,XB)
(13)
將XG從小到大排序,并分為Q組,得到各組的組中值XNq和離散頻率Fq,其中q=1,2,…,Q。以頻率Fq為權重,用加權均值表示機床加工系統的一個初始估計真值X03為
(14)
滾動均值法滾動均值法來源于自助再抽樣,但每次抽樣的數據個數是從1到N之間變化的,并且依次序從前向后滾動,而且滾動是可返回的,反復抽樣,抽樣數據個數逐步增加,直到一次全部抽完為止,最后融合使抽樣均值逐步逼近系統的真值。
基于原始數據序列X和式(2)、式(3)定義逐步均值累加項為
最后融合得到的機床加工系統的一個初始估計真值X04為
(15)
算術平均值法基于原始數據序列X,可得機床加工系統的一個初始估計真值X05為
(16)
將以上5種方法得到的5個初始估計真值構成一個真值融合序列XF,用向量表示為
XF=(X01,X02,X03,X04,X05)
(17)
再用這5種方法對真值融合序列XF進行多次融合,得到滿足極差準則的最終融合值,即機床加工系統的最終估計真值XFu。
1.3機床加工誤差的調整
在試切法調整機床的過程中,首先對試加工工件進行測量,獲取工件某性能參數的測量值,然后將測量值與工件要求的理想值作比較,來判斷機床是否調整到良好的運行狀態。但任何一種精確的測量方法和精密量具都不可能絕對準確,機床在加工過程中必定會存在誤差,即機床的調整誤差不可避免。因此,在機床調整過程中,根據工件的加工質量要求,在保證加工工件滿足質量要求的前提下,需合理規定機床的允許調整誤差。
由于調整是未知的,在實際調整操作過程中,每次調整都應盡量使實際加工工件的測量值接近工件要求的理想值,由于機床結構較復雜,且其影響因素較多、較難控制,每次調整后得到的測量值的估計真值與工件的理想值會有一定的偏差。應參照機床的允許調整誤差來決定調整機床的次數。
在調整機床的過程中,已知產品某性能參數要求加工的理想值XT和機床的允許調整誤差μ。按照試切法調整機床,即在較短時間內連續試加工很少的幾個工件,可依次獲取該工件性能參數的測量值,并構成小樣本原始數據序列X(即式(1))。
第一次試切時,給定工件的加工尺寸Xc1等于工件的理想值XT,運用乏信息融合技術得到該工件某性能參數的估計真值XFu1。
機床第一次調整產生的調整誤差為
(18)
若μ1≤μ,則表明機床的加工誤差能夠滿足產品某性能參數的允許調整誤差,可認為此時機床已調整良好,即機床調整完畢,可對工件進行正常加工生產。
若μ1>μ,則表明機床的加工誤差不能夠滿足產品某性能參數的允許調整誤差,可認為此時機床仍沒有調整好,須對機床的加工誤差繼續調整。
當XT>XFu1時,即工件的理想值大于測量值的估計真值XFu1,此時,應以給定工件的理想值XT為基礎,在第二次試切時給定工件的加工尺寸Xc2為
(19)
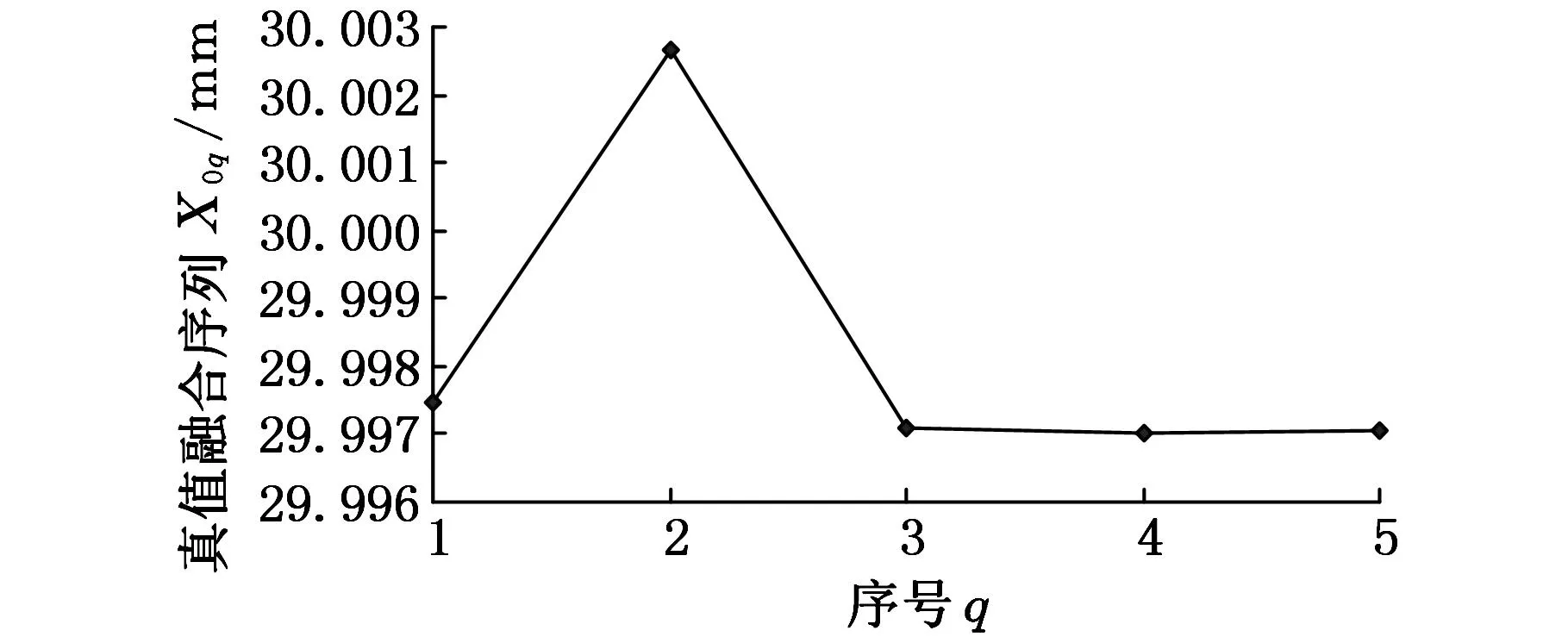
當XT (20) 比較估計真值與理想值的大小,由式(19)和式(20),來確定第二次試切時給定的工件加工尺寸Xc2,然后運用乏信息融合技術得到該工件某性能參數的估計真值XFu2。 此時,機床第二次調整產生的調整誤差為 (21) 若μ2≤μ,則表明機床的加工誤差能夠滿足產品某性能參數的允許調整誤差,可認為此時機床已調整良好,即機床調整完畢,可對工件進行正常加工生產。若第二次調整不滿足要求,則需繼續調整機床直到其加工誤差滿足規定的允許調整誤差為止。 由于機床結構較復雜,隨著加工時間的不斷累積,會出現各種擾動等不穩定現象,機床加工誤差的調整不可能一次完成,可能需要進行兩次或兩次以上更多的調整,因此,應根據調整過程中的實際情況,合理有序地完成機床加工誤差的調整工作,從而使機床加工出的產品滿足質量要求。 1.4預測機床調整后的估計區間 1.4.1確定小樣本可靠數據 假設機床調整后,滿足加工質量要求的小樣本可靠數據,構成一個小樣本可靠數據序列(表示系統本身的能力)Xr,即 Xr=(x1,x2,…,xj,…,xg)j=1,2,…,g (22) 式中,Xr為小樣本可靠數據序列;xj為Xr中的第j個數據;g為Xr的數據個數。 1.4.2預測機床調整后的估計區間 用模糊集合理論預測機床調整后的估計區間。首先,基于可靠數據序列Xr,借助于隸屬函數法中式(2)~式(5),建立有關可靠數據的隸屬函數。 設離散值h1s(xs)和h2s(xs)分別為 h1s(xs)=mss=1,2,…,τ (23) h2s(xs)=mss=τ,τ+1,…,g-1 (24) 式中,ms為概率密度因子,且τ的含義與式(9)中的v相同。 若離散值h1s(xs)和h2s(xs)已知,則可以用最大模范數最小法得到隸屬函數h1(x)和h2(x)。 在試驗分析中,機床加工過程中輸出的試驗數據可看作是一個已知的離散變量,因此,利用所研究的試驗數據得到的離散值h1s(xs)和h2s(xs)也是已知的。理論上講,某系統屬性的隸屬函數圖像是一條光滑的連續曲線,因此,隸屬函數不能直接通過試驗數據(離散變量)得到。為此,根據模糊集合理論,給出了求解隸屬函數的基本思路:首先,設定兩個分別含有待定系數al和bl的多項式f1和f2,且這兩個多項式可以構成一條曲線Q;然后,盡量使得曲線Q與離散值h1s(xs)和h2s(xs)擬合,在二者擬合效果最好時,確定待定系數al和bl;最后,將擬合效果最好時得到的系數al和bl分別代入多項式f1和f2中,確定多項式f1和f2,從而得到多項式f1和f2對應的逼近值f1(x)和f2(x),此時逼近值f1(x)和f2(x)也就是所求的隸屬函數h1s(xs)和h2s(xs)。 基于上述求解隸屬函數的基本思路,根據模糊集合理論,利用最大模范數最小法求解隸屬函數的具體步驟如下所示。 用兩個多項式 (25) (26) 分別逼近離散值h1s(xs)和h2s(xs)。即用式(25)和式(26)分別逼近式(23)和式(24),可得h1(x)=f1(x)和h2(x)=f2(x),從而得到隸屬函數h1(x)和h2(x)。式中,L是多項式f1和f2的階次,通常,L取3或4時可獲得較高的逼近精度;X0為用最大隸屬度法計算的有關機床加工系統的一個估計真值;al和bl分別為多項式f1和f2的待定系數。 設多項式f1和f2對應的逼近值f1(x)和f2(x)與離散值h1s(xs)和h2s(xs)的差值分別為 r1s=f1(xs)-h1s(xs);s=1,2,…,τ r2s=f2(xs)-h2s(xs);s=τ,τ+1,…,g-1 定義最大模范數 (27) 為了得到最精確的逼近值,應使得差值r1s和r2s的最大模范數最小化。為此,選擇待定系數al滿足 min‖r1‖∞ (28) 選擇待定系數bl滿足 min‖r2‖∞ (29) 則可以確定待定系數al和bl,進而得到隸屬函數h1(x)和h2(x)。式中,r1和r2分別對應逼近值f1(x)和f2(x)與離散值h1s(xs)和h2s(xs)的最大差值的絕對值取最小時的r1s和r2s。其中,式(28)和式(29)的約束條件分別為 df1/dx≥0 df2/dx≤0 根據模糊集合理論,可知某機床加工系統的屬性從真到假變化有一個過渡區間即 (30) 式中,G(x)為機床總體屬性變化的特征函數,G(x)=1為真,G(x)=0為假;λ為水平,λ[0,1];λ*為最優水平。 設機床總體屬性參數的變化區間為[XL,XU],XL表示估計區間的下界值,XU表示估計區間的上界值。根據式(30),在區間[XL,XU]內x是可用的,特征值為1;而在區間[XL,XU]外x是不可用的,特征值為0。根據水平λ,機床系統總體屬性參數的變化區間可以描述為 即在h(x)=λ條件下獲取x的估計區間[XL,XU]。 機床總體屬性變化的隸屬函數: (31) 選擇水平λ=λ*,且滿足 可以求出機床總體屬性參數的變化區間[XL,XU]。 機床總體屬性參數的置信水平P可以用隸屬函數表示為 (32) 0≤P≤1 由式(32)可知,P受λ和L的共同影響,若要求P值不變,則可調節λ和L來滿足要求。此外,因獲得的可靠數據較少(即g值較小),故L值很小,一般在1~4。在實際計算中,一般給定P,優選L,再調節λ以滿足P,就可以得到在置信水平P下的估計區間[XL,XU]。 根據模糊集合理論,在給定的置信水平P下,可預測出可靠數據序列的估計區間,即機床調整后的估計區間。 1.5預測調整后機床的可靠性 1.5.1采集實際輸出數據 假設機床在調整后,制造過程中實際輸出的數據信息構成一個數據序列XA,即 XA=(xA(1),xA(2),…,xA(i),…xA(K)) (33) i=1,2,…,K 式中,XA為實際輸出的數據序列;xA(i)為XA中的第i個數據;K為XA的數據個數。 若實際輸出的數據較少(即K值較小),預測的機床可靠性就會不準確。為準確預測調整后機床的可靠性,可以運用灰自助原理,利用實際輸出的少量數據生成大量數據,再來預測調整后機床的可靠性。 按照自助法中的等概率可放回抽樣方法,對式(33)進行抽樣,得到的第b個自助樣本XAb為 XAb=(xAb(1),xAb(2),…,xAb(i),…xAb(K)) (34) b=1,2,…,B 式中,xAb(i)為XAb中的第i個數據;K為XAb的數據個數。 由灰預測模型GM(1,1),設XAb的一次累加生成序列向量為 Yb=(yb(1),yb(2),…,yb(u),…,yb(K)) (35) 其中 一次累加生成序列向量Yb可用灰微分方程描述為 (36) 式中,u為一個連續變量;c1、c2為待定系數。 設均值生成序列向量為 Zb=(zb(2),zb(3),…,zb(u),…,zb(K)) (37) u=2,3,…,K 其中 zb(u)=(0.5yb(u)+0.5yb(u-1)) 在初始條件yb(1)=xAb(1)下,設灰微分方程的最小二乘解為 (38) 其中,系數c1和c2為 式中,I為K-1維的單位矢量。 由式(38),可以得到累減生成的第b個數據: αb=ηb(u+1)-ηb(u) (39) 根據灰自助原理,由式(39)可將實際輸出的少量數據生成大量數據,并構成一個大樣本數據序列β β=(α1,α2,…,αb,…,αB)b=1,2,…,B (40) 由統計學可得,實際輸出信息的取值區間為[IL,IU],其中IL表示實際輸出信息的下界值,IU表示實際輸出信息的上界值。 1.5.2建立機床可靠性函數 在置信水平P下,預測的估計區間與實際輸出信息的取值區間之間的關系為 (41) 機床調整后,加工過程中實際輸出的數據信息應滿足式(41);若不滿足則需對機床進行可靠性分析。 設XA中有w個元素在估計區間[XL,XU]之外,則機床的可靠性函數R為 (42) 若XA中的K值較小,應根據式(34)~式(40),令XA=XAb,K=B。 根據式(42),可預測調整后的機床可靠性。如果可靠性R越大,表示運用乏信息融合技術獲取的估計真值越準確,機床越可靠。若R≥P,則認為調整后的機床是可靠的;否則,認為調整后的機床是不可靠的。 2案例研究 2.1調整機床的仿真試驗 在仿真試驗中,已知待加工的30206圓錐滾子軸承內圈內徑的理想值XT=30 mm,規定的允許調整誤差μ=0.002 mm。 在第一次試切加工時,應按Xc1=XT=30 mm調整機床。由于30206圓錐滾子軸承內圈內徑的尺寸數據服從正態分布,用蒙特卡羅方法仿真出8個數學期望E=30 mm和標準差s=0.01的服從正態分布的試驗數據作為本次調整后獲得的8個軸承內徑測量值,并構成一個小樣本原始數據序列X(N=8),且有X=(30.005 38, 30.000 99, 29.989 85, 29.991 96, 30.004 32, 29.999 93, 29.995 79, 29.9879)mm,如圖1所示。 圖1 小樣本原始數據序列X(第一次調整) 在置信水平P=95%下,令B=20 000,運用乏信息融合技術的第一步內容,根據式(2)~式(17)處理小樣本原始數據序列X,可以得到5個初始估計真值,并將這5個初始估計真值構成本次調整機床后獲得的真值融合序列XF=(29.997 46,30.002 65,29.997 08,29.997 01,29.997 05)mm,如圖2所示。 圖2 真值融合序列XF(第一次調整) 然后運用乏信息融合技術的第二步內容,根據式(2)~式(17)對真值融合序列XF進行了5次融合,從而得到滿足極差準則的最終估計真值XFu1=29.997 59 mm。 根據式(18)可得,第一次調整誤差μ1=0.002 41 mm,且μ1>μ,則機床的加工誤差不能滿足軸承性能參數的允許調整誤差。因預測的估計真值XFu1=29.997 59 mm 根據式(19)可得,在第二次試切加工時,應按Xc2=XT+μ1=30.002 41 mm調整機床,用蒙特卡羅方法仿真出8個數學期望E=30.002 41和標準差s=0.01的服從正態分布的試驗數據作為本次調整后獲得的8個軸承內徑測量值,并構成一個小樣本原始數據序列X′(N=8),且有X′=(29.999 07, 30.004 68, 30.010 53, 30.012 65, 29.985, 29.990 61, 30.009 48, 29.998 58)mm,如圖3所示。 圖3 小樣本原始數據序列X′(第二次調整) 圖4 真值融合序列(第二次調整) 根據式(21)可得,第二次調整誤差μ2=0.001 62 mm,且μ2<μ,則此時機床的加工誤差能夠滿足軸承該性能參數的允許調整誤差。此時,可認為機床已調整良好,可對工件進行正常加工生產。 在本次試驗中,因第二次調整時機床已調整好,可根據模糊集合理論對第二次調整時獲得的小樣本原始數據序列X′(即此時可看作小樣本可靠數據)進行處理,在置信水平P=95%下,優選L=3,再調節λ以滿足P=95%,得到最優水平λ*=0.333 32,可預測出該機床調整后加工的軸承內圈內徑的估計區間[XL,XU]=[29.983 71, 30.0261]。以這樣的結果可以預測在后續的正常生產中加工的軸承內圈內徑的尺寸數據落在預測區間[29.983 71, 30.0261]內的概率至少為95%,此時調整完畢。 2.2機床調整后的仿真與試驗 2.2.1機床調整后的仿真分析 仿真一個服從正態分布的系統數據,模擬機床調整后的實際加工過程。用蒙特卡羅方法仿真出20 000個數學期望E=0和標準差s=0.01的服從正態分布的試驗數據,并構成一個仿真數據序列X20000,如圖5所示。 圖5 正態分布仿真數據序列X20000 選取仿真數據序列X20000中的前10個仿真數據作為小樣本數據序列X10(對應X20000中的序號為從1到10),如圖6所示。小樣本數據序列X10可認為是機床調整后獲取的滿足加工質量要求的小樣本可靠數據序列Xr(g=10)。選取仿真數據序列X20000中的后19 990個仿真數據作為機床實際加工中輸出的數據信息(對應X20000中的序號為從11到20 000),構成機床實際輸出的數據序列XA(K=19 990)。 圖6 小樣本可靠數據序列Xr 根據模糊集合理論,在置信水平P=95%下,優選L=3,調節λ以滿足P=95%,得到最優水平λ*=0.3702,能夠預測出小樣本可靠數據序列Xr的估計區間[XL,XU]=[-0.020 77, 0.0215]。 在本次仿真試驗中,模擬的機床實際輸出的數據序列XA的數據個數K=19 990,由統計學原理,計算出機床實際輸出的數據序列XA中不在估計區間[-0.020 77, 0.0215]內的數據個數w=637,根據式(41)~式(42),可得預測的可靠性R=96.81%>P=95%,則說明調整后的機床是可靠的。 2.2.2機床調整后的試驗研究 本試驗選定30204型圓錐滾子軸承的外滾道圓度數據。在某專用磨床調整之后系統正常運行的一個磨削周期中,隨機連續抽取30套軸承,按順序編號后測量其外滾道圓度數據,測得的圓度數據依次為(單位:μm):1.74, 1.76, 2.04, 0.80, 1.46, 1.62, 1.73, 1.76, 2.70, 1.19, 1.60, 1.47, 1.04, 1.56, 1.19, 1.32, 1.23, 2.23, 0.90, 1.24, 1.77, 1.21, 1.88, 1.34, 1.98, 1.30, 1.64, 2.03, 2.73, 0.95。所測的外滾道圓度數據構成一個數據序列X30。 選取外滾道圓度數據序列X30中前5個試驗數據作為小樣本數據序列X5(對應X30中的序號為從1到5),如圖7所示。小樣本數據序列X5可認為是機床調整后獲取的滿足加工質量要求的小樣本可靠數據序列Xr(g=5)。 圖7 軸承外滾道圓度的小樣本可靠數據序列Xr 選取外滾道圓度數據序列X30中的后25個試驗數據作為機床實際加工中輸出的數據信息(對應X30中的序號為從6到30),構成機床實際輸出的數據序列XA(K=25)。因K=25即實際輸出的數據個數較少,預測出的機床可靠性結果可能不準確。為能夠準確預測機床的可靠性,應運用灰自助原理,令B=20 000,將XA中的機床實際輸出的25個數據生成20 000個數據,構成一個大量生成數據序列β,并將大量生成數據序列β作為機床調整后機床加工過程中實際輸出的大量數據序列β,如圖8所示。 圖8 機床實際輸出的大量數據序列β 根據模糊集合理論,在置信水平P=95%下,優選L=3,調節λ以滿足P=95%,得到最優水平λ*=0.2399,能夠預測出小樣本可靠數據序列Xr的估計區間[XL,XU]=[0, 0.0215]。由統計學原理,計算出機床實際輸出的大量數據序列β中不在估計區間[0, 0.0215]內的數據有11個,根據式(33)~式(42),可得預測的可靠性R=99.45%>P=95%,則說明調整后的機床是可靠的。 3結束語 運用乏信息融合技術研究機床試加工時輸出的小樣本數據,獲取了機床調整過程中工件的估計真值,對機床的加工誤差進行了調整;運用模糊集合理論,在給定的置信水平下,借助于機床調整后輸出的小樣本可靠數據,預測了機床調整后的估計區間,并判斷了調整后機床的可靠程度。 調整機床的仿真試驗表明,運用乏信息融合技術,能夠實現對機床的加工誤差進行調整;機床調整后的試驗結果表明,在置信水平95%下,運用模糊集合理論預測的機床可靠性大于置信水平,說明調整后的機床是可靠的,驗證了運用乏信息融合技術調整機床的可行性。 參考文獻: [1]夏新濤, 秦園園, 邱明. 基于灰自助最大熵法的機床加工誤差的調整[J]. 中國機械工程, 2014, 25(17): 2273-2277. XiaXintao,QinYuanyuan,QiuMing.AdjustmentfortheMachiningErrorsofMachineToolBasedonGreyBootstrapMaximumEntropyMethod[J].ChinaMechanicalEngineering, 2014, 25(17): 2273-2277. [2]謝東, 丁杰雄, 霍彥波, 等. 數控機床轉動軸進給系統輪廓誤差分析[J]. 中國機械工程, 2012, 23(12): 1387-1392. XieDong,DingJiexiong,HuoYanbo,etal.ContourErrorAnalysisforRotationFeedAxisinCNCMachines[J].ChinaMechanicalEngineering, 2012, 23(12): 1387-1392. [3]夏新濤, 王中宇, 朱堅民, 等. 制造系統的非統計調整與誤差預測[J]. 機械工程學報, 2005, 41(1): 135-139, 171. XiaXintao,WangZhongyu,ZhuJianmin,etal.RegulationandErrorForecastofManufactureSystemUsingNon-statisticalTheory[J].ChineseJournalofMechanicalEngineering, 2005, 41(1): 135-139, 171. [4]GeLY,WangZY.NovelUncertainty-evaluationMethodofVirtualInstrumentSmallSampleSize[J].JournalofTestingandEvaluation, 2008, 36(3): 453-459. [5]王雅紅, 夏新濤, 王中宇. 基于乏信息系統的本征融合技術[J]. 航空動力學報,2008, 23(8): 1432-1437. WangYahong,XiaXintao,WangZhongyu.Eigen-fusionTechniqueBasedonInformationPoorSystem[J].JournalofAerospacePower, 2008, 23(8): 1432-1437. [6]ChenMY,LughoferE,SakamuraK.InformationFusioninSmartLivingTechnologyInnovations[J].InformationFusion, 2015(21):1-2. [7]LiWH,GaoK,WuJ,etal.SVM-basedInformationFusionforWeldDeviationExtractionandWeldGrooveStateIdentificationinRotatingArcNarrowGapMAGWelding[J].TheInternationalJournalofAdvancedManufacturingTechnology, 2014, 74(9/12): 1355-1364. [8]XuX,ZhouKK,ZouNN.HierarchicalControlofRideHeightSystemforElectronicallyControlledAirSuspensionBasedonVariableStructureandFuzzyControlTheory[J].ChineseJournalofMechanicalEngineering, 2015, 28(5): 945-953. [9]張根保, 康麗娜. 可靠性評估技術[J]. 制造技術與機床, 2015(8): 5-10. ZhangGenbao,KangLina.ReliabilityEvaluationTechnology[J].ManufacturingTechnology&MachineTool, 2015(8): 5-10. (編輯王旻玥) 收稿日期:2015-11-30 基金項目:國家自然科學基金資助項目(51475144,51075123) 中圖分類號:TH161.23 DOI:10.3969/j.issn.1004-132X.2016.13.019 作者簡介:夏新濤,男,1957年生。河南科技大學機電工程學院教授、博士研究生導師。主要研究方向為滾動軸承性能分析與乏信息融合。出版專著12部,發表論文200余篇。朱文換,女,1988年生。河南科技大學機電工程學院碩士研究生。陳士忠,男,1989年生。河南科技大學機電工程學院碩士研究生。 Adjustment Method for Machining Errors of Machine Tool Based on Poor Information Fusion Technology Xia XintaoZhu WenhuanChen Shizhong Henan University of Science and Technology, Luoyang, Henan, 471003 Abstract:Based on fusing membership function method, maximum membership degree method, rolling mean method, arithmetic mean value method and bootstrap method, a poor information fusion technology was proposed to realize adjustment for machining errors of machine tool. The output small sample data in machine tool trial processing were fused using the poor information fusion technology to obtain estimated true value of the parts, and the machining errors of machine tool could be adjusted to make the machined parts meet quality requirements. Then the output small sample reliable data was obtained in machine tool adjusted well processing, and the estimated interval of the reliable data could be predicted using the fuzzy set theory under the given confidence levels. The results of simulation and experiments show that the poor information fusion technology can realize the error adjustment of machine tool, and the adjusted machine tool is reliable, and the feasibility of utilizing the information fusion technology to adjust machine tool was verified. Key words:poor information fusion;machine tool;error;adjustment;reliability;fuzzy set theory