反蓄意模仿說話人識別系統中特征參數提取的研究*
2016-08-01 07:19:09唐宗渤王茂蓉劉繼錦
網絡安全與數據管理 2016年12期
唐宗渤, 周 萍,王茂蓉,劉繼錦
(1.桂林電子科技大學 信息科技學院,廣西 桂林 541004; 2.桂林電子科技大學 電子工程與自動化學院,廣西 桂林 541004)
?
反蓄意模仿說話人識別系統中特征參數提取的研究*
唐宗渤1, 周萍2,王茂蓉2,劉繼錦2
(1.桂林電子科技大學 信息科技學院,廣西 桂林 541004; 2.桂林電子科技大學 電子工程與自動化學院,廣西 桂林 541004)
摘要:當模仿者蓄意模仿說話人的語音且相似度極高時,說話人識別系統就有可能被欺騙。特征參數的提取是說話人識別的關鍵環節,直接影響了系統的識別性能。MFCC是語音識別中最熱門的特征參數之一,但由于其只反映了語音的靜態特性,為了提取更具個人語音特性的特征參數,引入加權MFCC,同時結合離散小波變換得到DWTWC,根據增減分量法,提出了DWI-MFCC。實驗表明,DWI-MFCC倒譜系數比MFCC能更有效地區分語音的相似度。
關鍵詞:特征參數; MFCC; 蓄意模仿; 增減分量法
引用格式:唐宗渤, 周萍,王茂蓉,等. 反蓄意模仿說話人識別系統中特征參數提取的研究[J].微型機與應用,2016,35(12):18-20.
0引言
生物認證技術[1]作為一種身份鑒別技術,它具有安全、方便等優點。但與其他生物特性相比,聲音更容易被模仿,特別在蓄意模仿與目標說話人的語音相似度極高時,就給識別系統的魯棒性帶來嚴峻考驗。有效的聲學特征,可大大提高識別性能。常用的特征參數有基因頻率、線性預測參數LPC、Mel頻率倒譜系數[2]MFCC等。其中MFCC能充分模擬人耳的聽覺感知特性,應用較多。但其只能體現語音的靜態特征,為了提取更具個人特性的參數,本文對MFCC作加權處理,結合離散小波變換引進DWTWC,根據增減分量法,提出DWI-MFCC。實驗表明,DWI-MFCC比傳統MFCC更能區分語音的相似度,提高識別系統的魯棒性。
1特征參數的提取
1.1Mel頻率倒譜系數
MFCC[2]作為模擬人耳特殊感知能力的參數得到研究者的推崇。其實際頻率f與Mel頻率fMel之間的轉換關系如式(1)所示,其中fMel的單位為Mel,f的單位為Hz。MFCC的提取過程如圖1所示,其參數分布示例圖如圖2所示。
(1)

圖1 MFCC參數提取流程圖
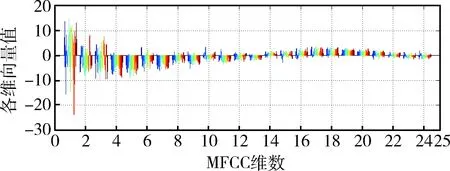
圖2 MFCC的參數分布示例圖
由圖2可知,隨著維數的升高,MFCC變化幅度變小,升高到一定程度后,系統識別性不僅沒有提高,反而增加了運算量。
1.2加權Mel頻率倒譜系數
為了得到更具區分性的加權特征參數,本文采用升半正弦函數[3]進行加權,如式(2)所示:
r=0.5+0.5*sin(π*(i-1)/n)
(2)
其中i=1,2,…,n為維數,本文n=24,0.5是靜態分量。為了更準確地體現不同說話人的個性特征差異[4],本文提出另一種加權函數如式(3)所示,得到改進的加權特征參數IWMFCC。
(3)
1.3DWTWC語音特征參數提取
在提取特征參數時,用離散小波變換代替傅里葉變換,用中頻區域分布密集的Mid-Mel濾波器組[5-6]代替原來的濾波器, DWTWC參數的提取步驟如下:首先對語音信號進行預加重、分幀加窗等;接著用離散小波變換[7]對預處理后的信號進行處理,選擇適當的小波基和分解層數對其分解,并計算小波系數;然后利用頻譜的拼接把系數組成一組參數,求其能量;最后取對數,再經過DCT可得到相應的DWTWC。其提取過程如圖3所示。

圖3 DWTWC的提取流程圖
與MFCC提取流程不同的是其前端處理采用離散小波變換[8],Mel濾波器換成了Mid-Mel濾波器組,有效補充了中頻區域的語音信息。
2DWI-MFCC混合特征參數
為了提高識別率,需對MFCC、WMFCC、IMFCC和DWTWC進行融合,用增減分量法[9]對維度進行篩選,將對識別率貢獻最大的n階分量進行組合,得到新的混合特征參數,如式(4)所示:
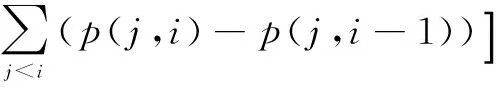
(4)
其中,n為階數,p(i,j)為從第i到第j階的識別率,R(i)為第i階分量平均貢獻值,若其大于0,則對識別有貢獻,反之則使識別率下降。文中僅順序摒棄或增添特征分量[10]。由式(4)計算出各參數中對識別率貢獻最大的特征分量,對其組合得到新的特征參數,即 DWI-MFCC。
3實驗結果與分析
3.1不同特征參數歐氏距離排名對比
本文從專業配音網站提取語音庫,采樣頻率為8 kHz,量化精度為16 bit。提取16階MFCC,計算被模仿者與模仿者語音的MFCC和DWI-MFCC的歐氏距離,然后對其從小到大排序得到表1。
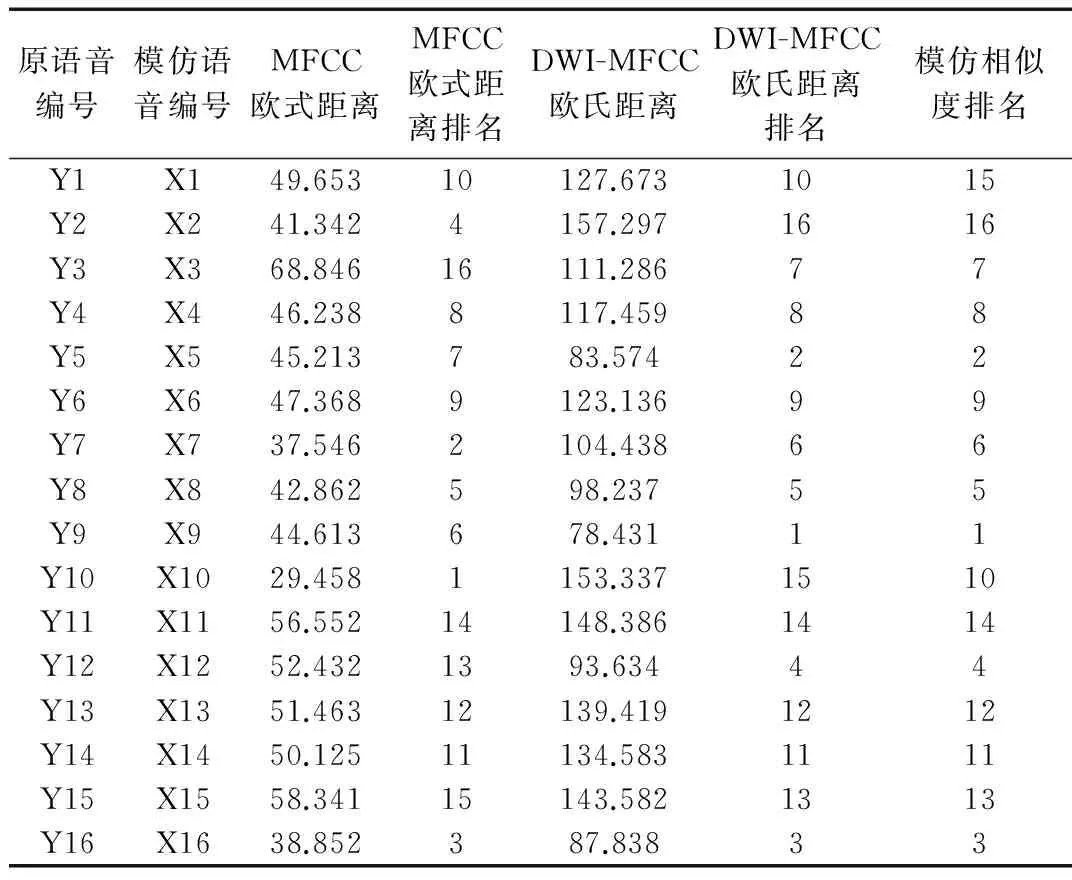
表1 MFCC和DWI-MFCC的歐氏距離排名
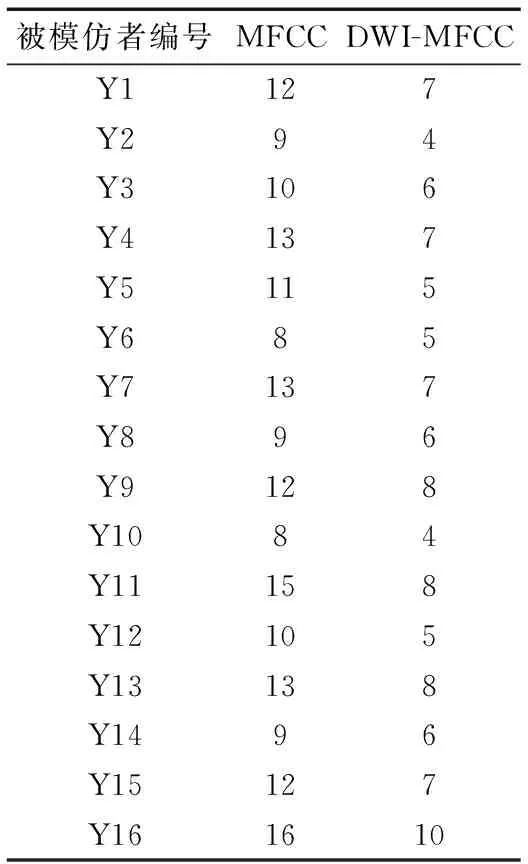
表2 不同的特征參數的錯誤
由表1可得,采用DWI-MFCC的原語音和模仿語音的排名一致性高達87.5%,證明 DWI-MFCC不但有效補充了MFCC在中頻區域的語音信息,而且很好地體現了語音個性特征;而采用MFCC時,排名一致性只有43.75%,這是因為MFCC中只包含了語音的靜態特性。綜上,本文提出的DWI-MFCC對語音模仿的區分能力更強,能更有效區分出原語音和被模仿語音。
3.2不同特征參數實驗結果的對比
為驗證特征參數的語音模仿區分性能,建立基于SVM的蓄意模仿識別系統,首先選取80人模仿語音庫中16位名人的聲音。訓練階段,先提取目標說話人與待測試說話人的特征參數,將其分別記為“+1”類和“-1”類并用以訓練出目標說話人的SVM模型。測試階段,將待測試語音與目標說話人的模型進行匹配,再和預先設定的閾值進行比較。本文選取徑向基函數作為SVM的核函數,懲罰系數為3,核函數參數為0.6。實驗采用16階的MFCC和DWI-MFCC分別作為樣本建立SVM模型,對數據進行[0,1]歸一化,計算出每個被模仿者使用不同特征參數時的錯誤接受率(FA),如表2所示,圖4給出了兩者的錯誤接受率的對比圖。
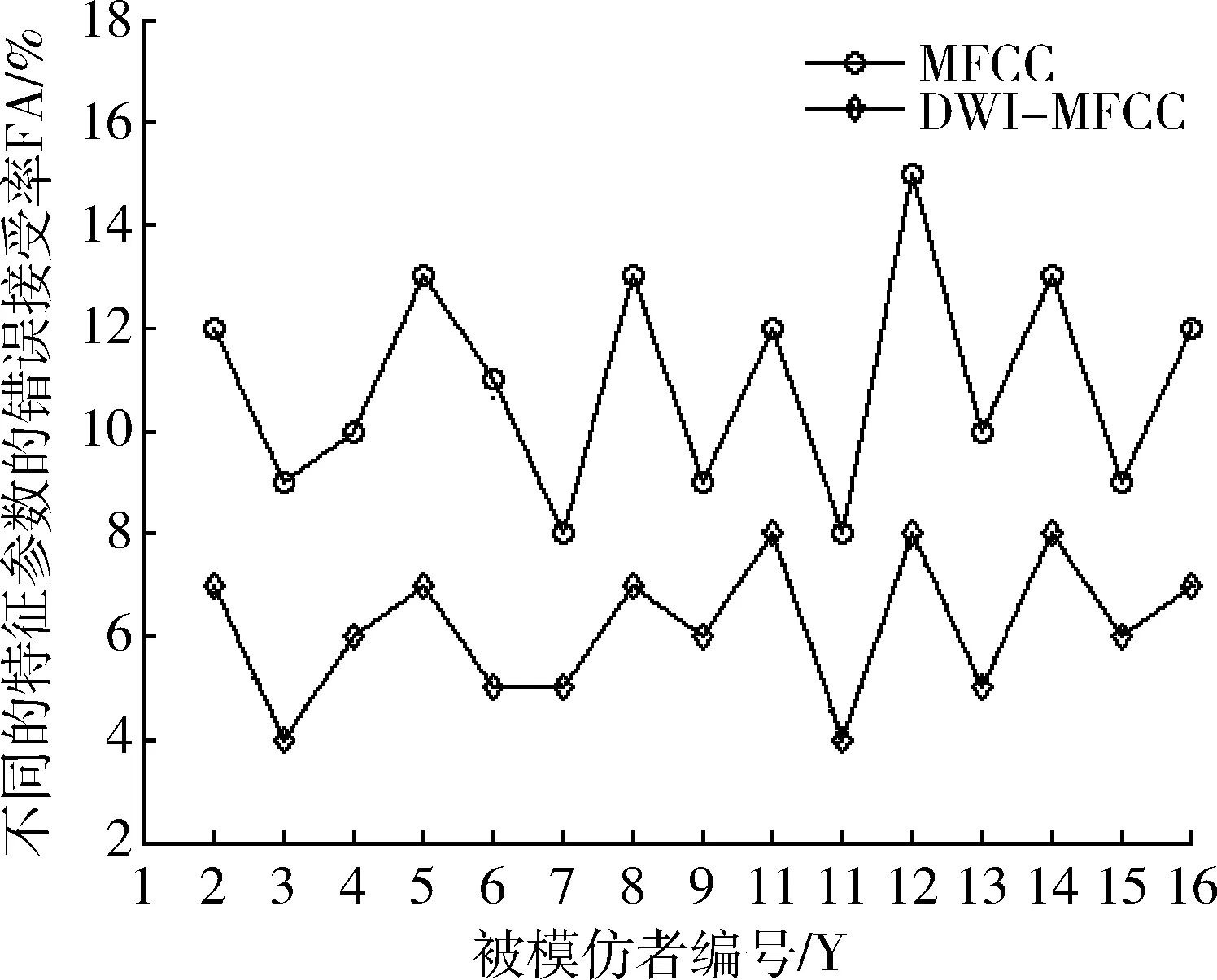
圖4 采用不同特征參數的錯誤接受率(FA%)對比
從圖4可知,MFCC的錯誤接受率曲線處于DWI-MFCC的曲線上方,即DWI-MFCC參數的錯誤接受率比MFCC參數的低,從而更有力地說明DWI-MFCC的區分性能比MFCC的要好。
4結論
本文通過對MFCC特征參數的分布分析,提出了加權MFCC,同時結合離散小波變換引入了DWTWC,根據增減分量法,提出了DWI-MFCC。從理論和實驗兩個方面對特征參數的有效性進行了分析,同時采用SVM對反蓄意模仿系統進行匹配分析。實驗表明,本文提出的DWI-MFCC相比于傳統的MFCC,對語音模仿的區分能力更強,有更好的識別性能。
參考文獻
[1] 李建文,張晉平.基于改進語音特征提取方法的語音識別[J].微電子學與計算機,2009,26(7):230-233.
[2] 柯晶晶,周萍,景新幸,等.差分和加權Mel倒譜混合參數應用于說話人識別[J].微電子學與計算機,2014,31(9):89-91.
[3] 吳迪,曹潔,王進花.基于自適應高斯混合模型與靜動態聽覺特征融合的說話人識別[J].光學精密工程,2013,21(6):1598-1604.
[4] 陳明義,余伶俐,朱晗,等.基于特征參數融合的語音情感識別方法[J].微電子學與計算機,2006,23(12):168-171.
[5] 田永紅. 一種優化的語音特征參數提取方法仿真[J]. 計算機仿真,2013,30(12):162-165.
[6] 吳麗芳. 語音轉換系統中特征參數的研究[D].南京:南京郵電大學,2013.
[7] 楊陽,毛永毅,鄭敏,等.基于小波變換的AOA定位算法[J].微型機與應用,2014,33(3):47-49,54.
[8] 胡沁春,何怡剛,何靜,等.高斯類小波變換的開關電流頻域法實現[J].電子技術應用,2014,40(1):44-46.
[9] 曹孝玉. 說話人識別中的特征參數提取研究[D].長沙:湖南大學,2012.
[10] 張璇. 基于Fisher準則的說話人識別特征參數提取研究[D].長沙:湖南大學,2013.
*基金項目:國家自然科學基金資助項目(61363005);國家自然科學基金資助項目(61462017);廣西研究生教育創新計劃資助項目(YCSZ2015152)
中圖分類號:TP391.42
文獻標識碼:A
DOI:10.19358/j.issn.1674- 7720.2016.12.007
(收稿日期:2016-02-29)
作者簡介:
唐宗渤(1986-),男,助理工程師,主要研究方向:語音信號處理與智能控制。
周萍(1961-),女,碩士,教授,主要研究方向:語音識別與智能控制研究。
王茂蓉(1990-),女,碩士研究生,主要研究方向:語音識別與反蓄意模仿。
Research of characteristic parameters extraction in speaker recognition system of anti-deliberate imitation
Tang Zongbo1, Zhou Ping2, Wang Maorong2, Liu Jijin2
(1.Department of Information Science and Technology, Guilin University of Electronic Technology, Guilin 541004, China;2.Department of Electric Engineering and Automation, Guilin University of Electronic Technology, Guilin 541004, China)
Abstract:When imitators deliberately imitate the speaker’s voice, and they have high similarity, speaker recognition system may be deceived. The extraction of feature parameters is key in speaker recognition, which directly affects the recognition performance. MFCC is one of the most popular feature parameters, but due to it only reflects static characteristics of voice, we introduce weighted MFCC to extract parameters of more individual voice. In combination with discrete wavelet transform, we introduce the DWTWC. According to increase or decrease in weight method, DWI-MFCC is proposed. The experimental result shows that the DWTWC is better than MFCC in distinguishing speech similarity.
Key words:feature parameter; MFCC; deliberate imitation; method of increasing or decreasing the component
