基于多模特征深度學習的機器人抓取判別方法
2016-08-11 06:18:37仲訓杲徐敏仲訓昱彭俠夫
自動化學報 2016年7期
仲訓杲 徐敏 仲訓昱 彭俠夫
基于多模特征深度學習的機器人抓取判別方法
仲訓杲1徐敏1仲訓昱2彭俠夫2
針對智能機器人抓取判別問題,研究多模特征深度學習與融合方法.該方法將測試特征分布偏離訓練特征視為一類噪化,引入帶稀疏約束的降噪自動編碼(Denoising auto-encoding,DAE),實現網絡權值學習;并以疊層融合策略,獲取初始多模特征的深層抽象表達,兩種手段相結合旨在提高深度網絡的魯棒性和抓取判別精確性.實驗采用深度攝像機與6自由度工業機器人組建測試平臺,對不同類別目標進行在線對比實驗.結果表明,設計的多模特征深度學習依據人的抓取習慣,實現最優抓取判別,并且機器人成功實施抓取定位,研究方法對新目標具備良好的抓取判別能力.
機器人抓取判別,降噪自動編碼,疊層深度學習,多模特征
引用格式仲訓杲,徐敏,仲訓昱,彭俠夫.基于多模特征深度學習的機器人抓取判別方法.自動化學報,2016,42(7): 1022-1029
機器人學習抓取是智能機器人研究的重要內容,涉及到智能學習、抓取位姿判別、機器人運動規劃與控制等問題的研究[1[3].近年出現的深度學習算法,在無監督特征學習中取得了顯著效果,深度學習的優越性在于:1)不需要介入人為的干預;2)該方法提高了網絡的深層學習能力,是一種充滿前景的學習算法[4-5].
深度學習首次由Hinton等[6]提出,其基本觀點是采用神經網絡模擬人類大腦特征學習過程.這種無監督特性學習方法借鑒大腦多層抽象表達機制,實現初始特征深層抽象表達,因此避免了特征抽取過程中人為的干預,同時深度學習在一定程度上解決了傳統人工神經網絡局部收斂和過適性問題,受到業內廣泛關注[7[6]、深度波爾曼茲機(Deep Boltzmann machine,DBM)[10]、深度能量模型(Deep energy model,DEM)[11]、自動編碼器(Auto encoder,AE)[12].鑒于深度網絡的強大學習能力,能夠直接從標記或非標記數據集中抽取深層抽象特征,該技術已成功用于圖像識別與檢索[13[15]、自然語言處理[16-17]等領域,而在機器人學習抓取領域還處在起步階段[18-20].
機器人學習抓取判別研究中,基于模型的方法保持著較高熱度,如文獻[21]對目標3D點云進行分割,每個分割部分由一個超二次曲面(Superquadrics,SQ)近似表示,然后用訓練好的人工神經網絡,區分每個部分是否為適合的抓取位置.文獻[22]同樣采用SQ近似表示目標模型,然后用支持向量機(Support vector machine,SVM)對SQ參數和抓取標記進行離線學習.在線測試中,SVM算法給定SQ參數后,將自動搜索有效的抓取位置.文獻[23]采用馬爾科夫場(Markov random field,MRF)對抓取物體進行3D點云建模,MRF的每個節點攜帶最優和次優兩個抓取標記,該方法通過點云標記的最大后驗概率,實現抓取位置識別.文獻[24]研究一種基于局部隨機采樣魯棒幾何描述的3D匹配與位姿估計方法,該方法在噪聲、遮擋測試環境中取得良好的抓取效果.以上方法依賴于物體3D幾何信息,一方面目標幾何模型精度難以保證;另一方面目標模型計算復雜,使得整個系統不顯優勢.與上述基于模型的方法不同,本文研究多模特征深度學習,直接從2D圖像平面判別抓取位姿,不失為一種直觀簡潔的方法.
本文研究多模特征深度學習構建疊層深度網絡,實現機器人抓取位姿最優判別.從問題本質出發,機器人對目標抓取位置的判別屬于機器學習目標識別范疇,因此本文提出深度學習解決機器人抓取判別問題,是一種可行有效的方法,而且避免了傳統學習方法耗時、需人工設計特征等缺點.本文研究目標為:給定抓取目標場景圖,機器人視覺系統通過多模特征深度學習推斷出最優抓取位姿,為此,本文主要研究內容及貢獻包括:1)采用堆疊降噪自動編碼(Denoising auto-encoding,DAE)建立深度網絡模型.在網絡建模中,把測試特征分布偏離訓練特征視為一類噪化,通過引入降噪自動編碼和稀疏約束條件實現網絡權值學習;在網絡學習中,先對訓練數據進行噪化,再對其進行降噪編碼,提高深度網絡對新目標抓取判別的魯棒性能.2)采用Kinect體感傳感器獲取目標RGB及深度多模數據,以融合策略處理多模特征的深層抽象表達.實驗表明,與單模相比,多模特征融合學習大大改善了機器人抓取判別的精確性.3)論文研究的多模特征深度學習模型與6自由度機器人相結合,機器人實現了對不同形狀、不同擺放方向物體的抓取判別與定位,不同情形下的實驗結果驗證了本文研究方法的實用性.
1 機器人抓取判別問題描述
給定抓取目標視覺場景圖(RGB和深度圖),機器人首先對目標進行感知識別(目標分割、提取有效的初始特征),然后推斷出對其實施抓取的最優位姿(抓取位置和方向),針對上述研究目標,機器人抓取判別問題可描述如下:
t時刻機器人獲取抓取目標n維特征序列X(t)=(x1(t),x2(t),···,xn(t)),假設該目標存在τ個可能的抓取G(t)=(g1(t),g2(t),···,gτ(t)),令 “位姿—特征”集 ?i=(gi(t),X(t)),其中gi(t),i=1,2,···,τ表示第i個特定的抓取位姿,給定二值變量有

式(1)指明,在給定目標特征X(t)條件下,gi(t)是否為最優抓取位姿.此時,機器人最優抓取判別問題即轉化為以下概率模型的最大化:

本文采用L層深度學習網絡,構建機器人最優抓取判別模型,其中輸入層的輸出量為:

式中δ(a)=1/(1+exp(-a)).網絡的第l-1層輸出h[l-1](t)作為第l層的輸入,以此類推,各隱含層輸入輸出之間關系為:

式中,上標表示網絡層數,下標表示網絡節點,k[l-1]為第l-1層的節點數.網絡的最后一層(第L層)為邏輯輸出層:

2 基于疊層DAE的多模特征深度參數學習
傳統人工神經網絡面臨一個固有問題,即測試樣本取值分布越接近訓練樣本,網絡的重建輸出效果越好,而當測試樣本分布遠離訓練樣本時,網絡的重建輸出效果則不然[25].若一個訓練好的網絡即便測試樣本遠離訓練樣本,網絡的重建誤差依然能夠保持在較低水平,那么該網絡具備良好的魯棒性或泛化能力.為了提升網絡的魯棒性能,實現對新目標的抓取判別,本文把測試樣本異于訓練樣本看作是被噪聲污染后的結果,在網絡訓練前對訓練特征進行隨機噪化,再對噪化后的特征數據進行降噪編碼,其目的是重建特征的精確復原體.網絡的每一層由一個降噪自動編碼器組成,原理如圖1(a)所示,假設初始特征集X(t)∈Rn被隨機噪聲污染后變為噪化過程可看作一種隨機映射,即:


式Rm中,為W編碼∈偏Rm置×向n為量,n s 個igm特(征a)的為權S值型矩函陣數,b,1即∈sig m(a)=(1+exp(-a))-1.降噪自動編碼器再對進行解碼,得到初始特征集X(t)的重建e,即:

式中,V∈Rm×n為解碼矩陣,b2∈Rn為解碼偏置向量.
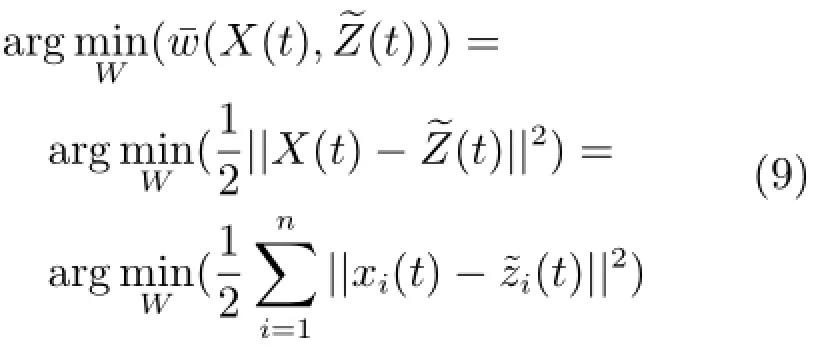
為了進一步提升網絡的學習效率,更好地模擬神經元的激活機制,即神經元只能被感興趣的視覺特征激活,本文在權值學習中引入稀疏約束條件,使得:
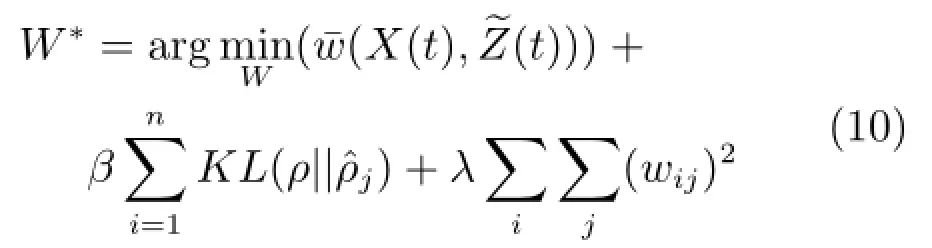

KL方差實現了稀疏約束,當ρ很小時,即可得到初始特征的無冗余完備深層抽象特征集.
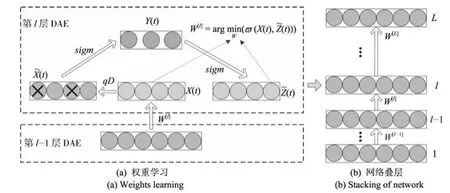
圖1疊層DAE深度學習過程Fig.1 The processing of stacked DAE deep learning
本文采用疊層DAE構建L層深度網絡,其中每一層由一個DAE組成.在疊層學習中,首先采用DAE學習算法,根據式(10)初始化輸入層權值矩陣W[1],從而重建初始特征向量X(t),然后固定W[1],再次采用DAE學習算法初始化W[2],重建第一層輸出向量h[1].依次類推,得到網絡權值變量Θ=(W[1],W[2],···,W[L]).網絡的堆疊學習過程如圖1(b)所示,L個DAE由下往上堆疊構成一個深度網絡,實現從初始輸入數據,逐漸抽取出深層抽象特征.
在堆疊學習中,我們得到一個單模結構的深度網絡,網絡的輸入為單模特征.考慮到多模深度網絡能夠更好地處理多模特征學習問題[11,27],本文采用多模視覺特征,進一步構建多模深度網絡.假設Xi(t)∈Rn為第i個單模深度網絡的輸入特征,表示第i個單模深度網絡輸出,多模深度學習就是要獲取λ個單模深度網絡輸出的有效融合,從而有效提高機器人抓取判別精度,融合方式表示為:

式中,θi∈[0,1]為第i個單模深度網絡輸出融合權值,滿足
3 機器人抓取位姿搜索與判別
為了搜索一個有效的抓取位姿,使得式(2)最優,首先需要確定抓取目標所有可能的抓取,然后利用深度網絡對它們各自可能成為最優抓取的概率進行排序,概率值最大者獲勝.文獻[28]給出了一種增量快速搜索方法,認為抓取位姿搜索其本質是像素概率分類問題,即把概率模型分解成每個像素點屬于最優抓取位姿的概率之和,通過分解計算提高算法的搜索效率.
假設某一已知的抓取位姿g(t)對應的概率模型為P(g(t)),我們把增量△g(t)合并到g(t)中,得到擴展抓取位姿g′(t)=g(t)∪△g(t),與此抓取位姿對應的圖像特征可表示為:

擴展抓取位姿g′(t)的最優判別式,如下:

不失一般性,圖像特征滿足:

式中,φi(I(u,v))表示像素點(u,v)的第i個特征值,通過式(15)可計算出抓取位姿g(t)區域內所有像素點的k個特征之和,于是P(g(t))的計算公式可表示為:

綜上所述,首先定義一個大小與圖像I相同的矩陣F(u,v)∈Rr×c,F(u,v),元素代表圖像I中各像素屬于最優抓取區域的概率矩陣F稱為像素概率矩陣.此時可把最優抓取判別描述為,給定大小為r×c的像素概率矩陣F,在F內部查找一個抓取位姿g(t),使得g(t)區域內包含F子元素之和最大,其本質是在F中查找一個最大和子矩陣F′.本文采用遞增查找算法,使得F′所有元素之和最大,算法實現如下:
算法1.抓取位姿搜索算法
初始化F中子區域F′的大小,即rG和nG固定
初始化當前值sy=f(G)=0,最大s?=f(G?)= 0,i=1

4 實驗結果分析
為了測試本文多模特征深度學習方法在機器人抓取判別中的有效性,首先采用抓取樣本數據,離線訓練所構建的網絡模型.網絡的輸入為多模特征數據集,輸出為目標的最優抓取區域.訓練數據集包含日常生活中的180個物體,總共935幅樣本場景圖,每幅圖像中的抓取目標都標記了3~5個抓取位置.多模特征包括RGB、YUV以及深度特征D三類特征,總共7個通道,我們把標記區域規范化為一個30像素×30像素的圖像塊,所以總的多模特征數為30×30×7=6300.在深度網絡學習過程中,網絡包括2個隱含層,每個隱含層包含300個節點,網絡訓練選用Intel Core i5 1.8GHz處理器,8GB RAM,安裝Windows 8操作系統的個人計算機,在Matlab 2011b環境中訓練時間近1.5小時.
在線抓取判別測試中,采用微軟Kinect體感攝像機,在VS與Matlab交叉編譯環境下,獲取抓取目標RGB圖像和深度圖像,采集到的部分測試數據如圖2所示,代表四類目標物:杯子、盤子、矩形盒、工具.針對不同形狀、大小、擺放方向的測試目標,抓取判別試驗結果如圖3所示,從結果中可看出判別模型參照人的抓取習慣,即矩形盒抓中間、杯子抓杯柄、盤子抓邊緣、工具抓把柄,表明本文研究的多模特征深度學習抓取判別方法具備以下兩個特性:1)針對不同類別的抓取目標,學習算法依據人的抓取習慣,實現抓取位置的最優判別,說明該方法具有一定的智能學習判別特性.2)試驗中部分測試目標不同于網絡訓練樣本,這說明本文構建的多模特征深度學習網具有較好的魯棒特性,即機器人在面臨新的抓取目標時,同樣能夠實現抓取判別.

圖2 抓取判別測試數據Fig.2 Test dataset for potential grasp recognition
為了進一步驗證本文方法的魯棒性能與特性,我們進行以下兩種情形的比較試驗:
情形1.相同訓練特征,不同訓練方法試驗比較,網絡輸入為相同的RGB-YUV-D多模特征,分別采用自動編碼(AE)和本文降噪自動編碼(DAE)方法訓練網絡.在網絡權值學習中忽略式(6),即初始多模特征不進行噪化處理,從而式(7)退化為常規AE編碼,然后用AE方法訓練網絡.這種訓練模式下,網絡在線測試結果如圖4所示,其中圖4(a)測試目標“杯子”、“盤子”、“工具”包含在訓練樣本集中,此時AE和本文DAE方法的試驗結果比較接近,二者抓取判別效果令人滿意.圖4(b)測試目標“接線導軌”、“訂書機”、“測量儀”不包含在訓練樣本中,此時本文DAE方法測試結果明顯優越于AE方法,說明當面臨新目標時,AE網絡的判別效果變差,不能滿足工程要求,而本文DAE網絡依然能夠保持良好的判別效果.試驗結果表明,本文把測試特征偏離訓練特征視為一類噪化,通過引入帶約束的降噪自動編碼方法對目標特征進行學習是一種有效舉措,訓練樣本先噪化再降噪編碼,有效提高了網絡的魯棒性能.

圖3 不同類別目標抓取判別結果Fig.3 Grasp recognition results for variety of targets

圖4AE和本文DAE訓練方法結果比較Fig.4 Results comparison between AE and our DAE training methods
情形2.相同DAE訓練方法,不同訓練特征試驗比較.分別采用RGB-YUV、RGB-D、RGBYUV-D三種特征訓練網絡.首先通過設定某個特征的融合權值θi為0,實現從RGB-YUV-D中剔除某一特征數據,即網絡退化為單模深度網絡,再與本文的多模深度網絡進行比較.試驗結果如圖5所示,可看出RGB-YUV網絡判別效果最差,其次為RGB-D網絡,而本文RGB-YUV-D多模特征網絡判別結果最優,表明本文采取的多模特征融合策略,處理多模特征深層抽象表達真實有效,從而大大改善了網絡的判別精度.

圖5 不同特征融合結果比較Fig.5 Results comparison between different features
本文研究方法與6自由度工業機器人相結合,構建機器人視覺伺服抓取定位試驗平臺,驗證本文方法的實際應用效果.在機器人抓取定位實驗中,深度攝像機安放在機器人的基坐標系中,位置大致為x =200mm,y=150mm,z=680mm,相機成像平面盡量與機器人坐標系Y-軸平行.相機通過USB接口與PC相連,PC通過RS232串口與機器人控制器相連接,構成機器人視覺伺服閉環系統.PC作為上位機主要完成圖像采集、圖像處理及執行抓取判別算法,機器人控制器作為下位機完成機器人運動學運算,同時驅動機器人各個關節.
首先,機器人對不同物體實施抓取判別與定位實驗,結果如圖6所示,機器人根據深度網絡輸出的抓取位姿判別結果(圖6(a)),再實施對其目標抓取定位(圖6(b)),可看出機器人成功實現了對矩形盒和杯子的抓取判別與定位.其次,為了進一步驗證研究方法的可靠性,我們對相同物體、不同擺放方向進行測試,結果如圖7所示,機器人對擺放方向大致為—5?、35?、270?的同一物體成功實施抓取判別與定位.從以上結果可直觀看出,本文研究方法適用于不同形狀、不同擺放姿態物體的抓取判別與定位.值得一提的是,我們沿用了目標識別一貫表示方式,用一個矩形框來表示抓取位姿,同時考慮目標物為剛性物體,在抓取定位精確情況下機器人即可進行簡單的兩指挾持操作,后續工作也將進一步研究機器人多指抓取操作問題.
最后,我們對圖2中四類不同物體、不同擺放方向進行總計96次機器人抓取定位實驗,結果統計如表1所示,從有限代表性實驗中得出機器人抓取定位平均成功率為91.7%,綜上得證本文研究方法的實用性.

圖6 機器人對不同物體實施抓取判別與定位Fig.6 Robot executing grasp recognition and positioning for different targets

圖7 機器人對不同擺放方向物體實施抓取判別與定位Fig.7 Robot executing grasp recognition and positioning for targets with different poses

表1 機器人對不同物體、不同擺放方向抓取定位統計結果Table 1 Results of robot grasp positioning for different targets with different poses
5 結論
本文針對機器人抓取判別與定位問題,給出了疊層多模特征深度學習與融合抓取判別方法.本文把測試特征偏離訓練特征視為一類噪化,通過引入降噪自動編碼和稀疏約束條件實現網絡權值學習,提高了疊層DAE網對新目標抓取判別的魯棒性能.考慮多模視覺特征,采取多模特征融合策略處理多模特征的深層抽象表達,有效改善了網絡的判別精度.試驗表明判別模型依據人的抓取習慣,實現了不同擺放姿態、不同形狀物體的抓取判別,6自由度工業機器人抓取定位實驗驗證了方法的實用性.
References
1 Paolini R,Rodriguez A,Srinivasa S S,Mason M T.A data-driven statistical framework for post-grasp manipulation.The International Journal of Robotics Research,2014,33(4):600-615
2 Jia Bing-Xi,Liu Shan,Zhang Kai-Xiang,Chen Jian.Survey on robot visual servo control:vision system and control strategies.Acta Automatica Sinica,2015,41(5):861-873(賈丙西,劉山,張凱祥,陳劍.機器人視覺伺服研究進展:視覺系統與控制策略.自動化學報,2015,41(5):861-873)
3 Droniou A,Ivaldi S,Sigaud O.Deep unsupervised network for multimodal perception,representation and classification. Robotics and Autonomous Systems,2015,71(9):83-98
4 Gao Ying-Ying,Zhu Wei-Bin.Deep neural networks with visible intermediate layers.Acta Automatica Sinica,2015,41(9):1627-1637(高瑩瑩,朱維彬.深層神經網絡中間層可見化建模.自動化學報,2015,41(9):1627-1637)
5 Qiao Jun-Fei,Pan Guang-Yuan,Han Hong-Gui.Design and application of continuous deep belief network.Acta Automatica Sinica,2015,41(12):2138-2146(喬俊飛,潘廣源,韓紅桂.一種連續型深度信念網的設計與應用.自動化學報,2015,41(12):2138-2146)
6 Hinton G E,Salakhutdinov R R.Reducing the dimensionality of data with neural networks.Science,2006,313(5786):504-507
7 Bengio Y.Learning deep architectures for AI.Foundations and Trends?in Machine Learning,2009,2(1):1-127
8 L¨angkvist M,Karlsson L,Loutfi A.A review of unsupervised feature learning and deep learning for time-series modeling. Pattern Recognition Letters,2014,42:11-24
9 Erhan D,Bengio Y,Courville A,Manzagol P A,Vincent P,Bengio S.Why does unsupervised pre-training help deep learning?Journal of Machine Learning Research,2010,11:625-660
10 Salakhutdinov R,Hinton G.Deep Boltzmann machines.In:Proceedings of the 12th International Conference on Artificial Intelligence and Statistics(AISTATS)2009.Florid,USA,2009.448-455
11 Ngiam J,Khosla A,Kim M,Nam J,Lee H,Ng A Y.Multimodal deep learning.In:Proceedings of the 28th International Conference on Machine Learning.Bellevue,USA,2011.689-696
12 Baldi P,Lu Z Q.Complex-valued autoencoders.Neural Networks,2012,33:136-147
13 Wu P C,Hoi S C H,Xia H,Zhao P L,Wang D Y,Miao C Y.Online multimodal deep similarity learning with application to image retrieval.In:Proceedings of the 21st ACM International Conference on Multimedia.Barcelona,Spain:ACM,2013.153-162
14 Geng Jie,Fan Jian-Chao,Chu Jia-Lan,Wang Hong-Yu.Research on marine floating raft aquaculture SAR image target recognition based on deep collaborative sparse coding network.Acta Automatica Sinica,2016,42(4):593-604(耿杰,范劍超,初佳蘭,王洪玉.基于深度協同稀疏編碼網絡的海洋浮筏SAR圖像目標識別.自動化學報,2016,42(4):593-604)
15 Mohamed A R,Dahl G E,Hinton G.Acoustic modeling using deep belief networks.IEEE Transactions on Audio,Speech,and Language Processing,2012,20(1):14-22
16 Sarikaya R,Hinton G E,Deoras A.Application of deep belief networks for natural language understanding.IEEE/ACM Transactions on Audio,Speech,and Language Processing,2014,22(4):778-784
17 Humphrey E J,Bello J P,LeCun Y.Feature learning and deep architectures:new directions for music informatics. Journal of Intelligent Information Systems,2013,41(3):461-481
18 Yu J C,Weng K J,Liang G Y,Xie G H.A vision-based robotic grasping system using deep learning for 3D object recognition and pose estimation.In:Proceedings of the 2013 IEEE International Conference on Robotics and Biomimetics.Shenzhen,China:IEEE,2013.1175-1180
19 Noda K,Arie H,Suga Y,Ogata T.Multimodal integration learning of object manipulation behaviors using deep neural networks.In:Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems.Tokyo,Japan:IEEE,2013.1728-1733
20 Lenz I,Lee H,Saxena A.Deep learning for detecting robotic grasps.The International Journal of Robotics Research,2015,34(4-5):705-724
21 El-Khoury S,Sahbani A.A new strategy combining empirical and analytical approaches for grasping unknown 3D objects.Robotics and Autonomous Systems,2010,58(5):497-507
22 Pelossof R,Miller A,Allen P,Jebara T.An SVM learning approach to robotic grasping.In:Proceedings of the 2004 IEEE International Conference on Robotics and Automation.New Orleans,USA:IEEE,2004.3512-3518
23 Boularias A,Kroemer O,Peters J.Learning robot grasping from 3-D images with Markov random fields.In:Proceedings of the 2011 IEEE/RSJ International Conference on Intelligent Robots and Systems.San Francisco,USA:IEEE,2011.1548-1553
24 Papazov C,Haddadin S,Parusel S,Krieger K,Burschka D. Rigid 3D geometry matching for grasping of known objects in cluttered scenes.The International Journal of Robotics Research,2012,31(4):538-553
25 Liu Jian-Wei,Sun Zheng-Kang,Luo Xiong-Lin.Review and research development on domain adaptation learning.Acta Automatica Sinica,2014,40(8):1576-1600(劉建偉,孫正康,羅雄麟.域自適應學習研究進展.自動化學報,2014,40(8):1576-1600)
26 Shin H C,Orton M R,Collins D J,Doran S J,Leach M O. Stacked autoencoders for unsupervised feature learning and multiple organ detection in a pilot study using 4D patient data.IEEE Transactions on Pattern Analysis and Machine Intelligence,2013,35(8):1930-1943
27 Vincent P,Larochelle H,Bengio Y,Manzagol P A.Extracting and composing robust features with denoising autoencoders.In:Proceedings of the 25th International Conference on Machine Learning.Helsinki,Finland:ACM,2008. 1096-1103
28 Jiang Y,Moseson,Saxena A.Efficient grasping from RGBD images:learning using a new rectangle representation.In:Proceedings of the 2011 IEEE International Conference on Robotics and Automation.Shanghai,China:IEEE,2011. 3304-3311

仲訓杲博士,廈門理工學院電氣工程與自動化學院講師.主要研究方向為機器學習和機器人視覺伺服.
E-mail:zhongxungao@163.com
(ZHONGXun-GaoPh.D.,lecturer at the School of Electrical Engineering and Automation,Xiamen University of Technology.His research interest covers machine learning and robotic visual servoing.)

徐敏廈門理工學院電氣工程與自動化學院教授.主要研究方向為模式識別和機器人智能控制.
E-mail:xumin@xmut.edu.cn
(XU MinProfessor at the School of Electrical Engineering and Automation,Xiamen University of Technology.His research interest covers pattern identification and intelligent control of robotic.)

仲訓昱博士,廈門大學自動化系副教授.主要研究方向為機器視覺,機器人運動規劃,遙自主機器人.本文通信作者. E-mail:zhongxunyu@xmu.edu.cn
(ZHONG Xun-YuPh.D.,associate professor in the Department of Automation,Xiamen University.His research interest covers machine vision, robot motion planning,mobile and autonomous robotics. Corresponding author of this paper.)

彭俠夫博士,廈門大學自動化系教授.主要研究方向為機器人導航與運動控制,機器學習.
E-mail:xfpeng@xmu.edu.cn
(PENG Xia-FuPh.D.,professor in the Department of Automation,Xiamen University.His research interest covers navigation and motion control of robotic,machine learning.)
Multimodal Features Deep Learning for Robotic Potential Grasp Recognition
ZHONG Xun-Gao1XU Min1ZHONG Xun-Yu2PENG Xia-Fu2
In this paper,a multimodal features deep learning and a fusion approach are proposed to address the problem of robotic potential grasp recognition.In our thinking,the test features which diverge from training are presented as noise-processing,then the denoising auto-encoding(DAE)and sparse constraint conditions are introduced to realize the network′s weights training.Furthermore,a stacked DAE with fusion method is adopted to deal with the multimodal vision dataset for its high-level abstract expression.These two strategies aim at improving the network′s robustness and the precision of grasp recognition.A six-degree-of-freedom robotic manipulator with a stereo camera configuration is used to demonstrate the robotic potential grasp recognition.Experimental results show that the robot can optimally localizate the target by simulating human grasps,and that the proposed method is robust to a variety of new target grasp recognition.
Robot grasping recognition,denoising auto-encoding(DAE),stacked deep learning,multimodal features
10.16383/j.aas.2016.c150661
Zhong Xun-Gao,Xu Min,Zhong Xun-Yu,Peng Xia-Fu.Multimodal features deep learning for robotic potential grasp recognition.Acta Automatica Sinica,2016,42(7):1022-1029
2015-10-16錄用日期2016-05-03
Manuscript received October 16,2015;accepted May 3,2016國家自然科學基金 (61305117),福建省科技計劃重點項目(2014H0047),廈門市科技計劃項目(3502Z20143034),廈門理工學院高層次人才項目(YKJ15020R)資助
Supported by National Natural Science Foundation of China (61305117),theKeyScienceProjectofFujianProvince (2014H0047),theSciencePlanProjectofXiamenCity (3502Z20143034),and the High-level Talent Fund of Xiamen University of Technology(YKJ15020R)
本文責任編委賈珈
Recommended by Associate Editor JIA Jia
1.廈門理工學院電氣工程與自動化學院廈門3610242.廈門大學自動化系廈門361005
1.School of Electrical Engineering and Automation,Xiamen University of Technology,Xiamen 3610242.Department of Automation,Xiamen University,Xiamen 361005
猜你喜歡
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
