第三方支付粗糙復雜網絡知識發現方法研究*
2016-08-31 09:06:32曹黎俠黃光球西安建筑科技大學管理學院西安700552西安工業大學理學院西安70032
計算機與生活 2016年8期
曹黎俠,黃光球,李 艷.西安建筑科技大學 管理學院,西安 700552.西安工業大學 理學院,西安 70032
第三方支付粗糙復雜網絡知識發現方法研究*
曹黎俠1,2+,黃光球1,李艷1
1.西安建筑科技大學 管理學院,西安 710055
2.西安工業大學 理學院,西安 710032
CAO Lixia,HUANG Guangqiu,LIYan.Research on the third-party payment rough complex networks knowledge discovery methods.Journal of Frontiers of Computer Science and Technology,2016,10(8):1143-1153.
摘要:第三方支付平臺的可持續發展是一個錯綜復雜的問題,解決問題的關鍵之一是平臺潛在客戶的挖掘。建立了第三方支付粗糙復雜網絡,通過對該粗糙復雜網絡的上下近似度、度分布和度的概率主值的研究,構建了第三方支付粗糙復雜網絡知識發現模型,給出了基于粗糙集理論的時間序列分析法的求解方法。第三方支付粗糙復雜網絡知識發現方法的研究,為第三方支付平臺潛在客戶的挖掘提供了定量化可操作的方法。提出了粗糙復雜網絡的有關概念,以及第三方支付粗糙復雜網絡的度分布,為第三方支付有關問題的研究奠定了理論基礎;知識發現方法的研究,適應了動態知識系統更新的需求,因此有著廣泛的應用前景。
關鍵詞:第三方支付;粗糙復雜網絡;時間序列分析;知識發現
1 引言
經濟發展的最高境界,不是做產品,不是重質量,也不是搞標準,而是打造平臺。近幾年來,第三方支付企業之所以成功,一個很重要的原因就是將產品做成了一個平臺,或者說平臺就是他們真正意義上的產品。這種借助于互聯網的能力是其他銷售模式都無法相提并論的,然而第三方支付企業的可持續發展問題的研究目前也只限于一些定性化的分析和主觀性的決策[1-3]。有些學者指出第三方支付平臺可持續發展的關鍵,是解決效益問題、風險問題和平臺交易的監管問題[4-5],但是現有的對平臺效益、風險和交易監管問題的研究成果都只是從經濟學原理、經驗管理等領域給出的定性化結論,缺乏定量化和系統化的結果,也沒有人從理論上給出與第三方支付平臺交易中參與者的決策行為相關的論證[6-9]。
第三方支付平臺的效益、風險和監管都是在交易中產生的,而平臺交易是以信息網絡為媒介,具有網絡規模龐大、節點復雜性、連接結構復雜性、網絡時空演化過程復雜性等特點,因此,第三方支付平臺交易實質是復雜網絡中的交易活動。鑒于以上原因,本文以復雜網絡理論為基礎,對平臺交易中的效益問題、風險問題和監管問題進行研究。遺憾的是,現有的復雜網絡理論都是針對確定性的節點和連接結構而言[9],不能滿足第三方支付平臺交易中的不確定因素與節點和連接結構對知識具有的不可分辨性的需求。這樣,現有的復雜網絡理論就出現了應用上的局限性。目前,國內外關于不確定性復雜網絡的研究,僅有的一些成果[10-11]也只是對粗糙屬性圖的性質進行探索,還沒有針對實際粗糙復雜網絡進行的研究。因為粗糙集理論是處理不確定性問題非常好的一種數學理論,所以本文首先構建第三方支付粗糙復雜網絡,通過對該粗糙復雜網絡統計特征的研究,建立知識發現模型,實現第三方支付平臺粗糙復雜網絡潛在客戶的挖掘。
知識發現的核心是數據挖掘,常用的數據挖掘技術有傳統主觀導向系統、傳統統計分析、神經元網絡(neural network,NN)技術、決策樹、進化式程序設計、遺傳算法和非線性回歸方法等[12-14]。近年來,軟計算和不確定信息處理方法的研究,也促使數據挖掘技術向更深層次發展,即Web數據挖掘[15-16]。有關文獻指出[17-20],基于Web的數據挖掘和Web知識表述作為數據挖掘和數據倉庫的一個新主題,是一個新興的研究領域,至今還沒有形成成熟的理論和技術。Web數據挖掘中的不完整性和不確定性問題,模糊數學和基于概率方法的證據理論是處理這類問題的兩種方法,但這些方法有時需要一些數據的附加信息或先驗知識,而這些信息有時并不容易得到。本文運用粗糙集理論與方法處理Web數據挖掘中的不完整性和不確定性問題,克服了上述兩種方法處理問題的弊端,具有一定的理論研究意義和實際應用價值。本文基于粗糙集理論的第三方支付復雜網絡知識發現方法的研究,希望能夠為平臺交易的參與者提供一些定量化的決策依據和方法。
2 第三方支付粗糙復雜網絡的建立
考慮到第三方支付平臺交易實際上是由商家及其銷售的商品和服務以及顧客組成的復雜網絡,該網絡是以商家和商家經營的商品為節點,以網址的鏈接為邊。顧客訪問某一節點,具有不確定性,該節點與哪些節點相連具有不可分辨性,因此稱第三方支付平臺交易網絡為粗糙復雜網絡。
定義1在復雜網絡中,如果節點(或連邊)關于某關系具有不可分辨性,則稱這樣的復雜網絡為粗糙復雜網絡;粗糙復雜網絡根據粗糙性產生的原因,可以分為粗糙節點復雜網絡和粗糙邊復雜網絡。
定義2在粗糙復雜網絡RCN中,設X是節點(或邊)集U的一個子集,R為U上的一個等價關系,稱為下近似粗糙節點(或邊)復雜網絡,記為;稱為上近似粗糙節點(或邊)復雜網絡,記為。
第三方支付平臺交易粗糙網絡中,設商家和商品構成了知識庫U,X?U,R是U上的決策關系,且這種決策具有反身性、對稱性和傳遞性,則R={購買,收藏,瀏覽}。一般情況下,顧客購買前先收藏,則購買的商品和商品的鏈接形成了第三方支付下近似粗糙復雜網絡,收藏的商品和商品的鏈接形成了第三方支付上近似粗糙復雜網絡;瀏覽并未收藏的商品組成了以顧客決策行為為知識分類的負域。顧客訪問某商品,對同一商家的商品瀏覽的概率遠遠大于不同商家的商品,因此該粗糙復雜網絡實質形成了以商家為社團的復雜網絡。
根據第三方支付平臺運營的實際狀況,提煉出以下特點:
(1)某一交易平臺共有m個商家,每一商家經營同類Vi個產品;
(2)顧客在瀏覽某一商品時,往往會以較大的概率在同一商家的商品中去選擇,以較小的概率選擇不同商家的商品,商家相互之間可以進行信息共享;
(3)顧客在訪問商品的頁面時可能會隨機地由此及彼地瀏覽商品,也許購買,也許收藏,也許只是瀏覽;
(4)顧客在購買前,首先收藏同類質量和品質相當的商品,然后選擇銷售量(下近似粗糙網絡的度)比較大的購買。
這樣,在商品和商家構成的這個復雜網絡中,以顧客訪問、收藏和購買為等價關系,構建了第三方支付平臺交易的粗糙復雜網絡,當m=4,Vi(i=1,2,3,4) 取20~30間的整數時,第三方支付粗糙復雜網絡如圖1所示。圖1黑色節點表示商家銷售的商品,紅色節點分別為4個商家;黑色節點中與商家相連的節點是顧客已購買的商品,其余的為顧客收藏而沒有購買的商品;有連邊沒有標出的節點是顧客瀏覽且未收藏的商品。
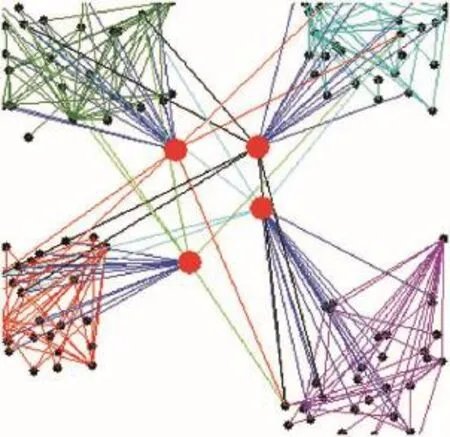
Fig.1 The third-party payment rough complex networks圖1 第三方支付粗糙復雜網絡
3 第三方支付粗糙復雜網絡的知識發現模型
3.1第三方支付粗糙復雜網絡的粗糙度分布
3.1.1度分布的定義
在復雜網絡中,節點Vi的鄰邊數目ki稱為節點Vi的度;網絡中所有節點度的平均值,稱為網絡的平均度:
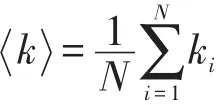
定義p(k)為網絡中度為k的節點在網絡中所占的比率,稱為網絡度分布。
但是上述度的定義并未考慮節點的權重。特別是在第三方支付平臺網絡中,度相同的不同節點在網絡中的地位不同,帶給商家和平臺管理者的效益也可能差別很大。鑒于此,本文給出一種新的度定義——網絡的加權平均度k*,可以克服文獻[21]定義的弊端。

其中,N表示網絡節點總數;ωi是節點權重;ki是節點度。
在本文中,ωi代表商品或商家類別權重。
定義5下近似粗糙復雜網絡的節點-Vi的鄰邊數目-ki稱為節點-Vi的下近似粗糙度;對網絡中所有節點的下近似粗糙度求平均,可得網絡的下近似粗糙平均度-k*:


3.1.2度分布
為考慮網絡的度分布,隨機性地收集了淘寶網站上銷量較好的50個不同品牌手機的度,經過大量的調研,它們的連接關系如圖2所示。圖2是天貓商城被購買的手機的一個關聯網絡圖,也是圖1的一個下近似網絡圖,經過統計得到該下近似網絡圖的度及其概率分布如表1所示。
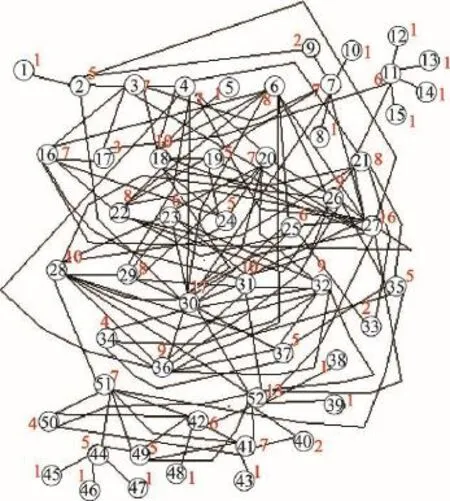
Fig.2 The third-party payment under-approximate rough networks圖2 第三方支付下近似粗糙網絡
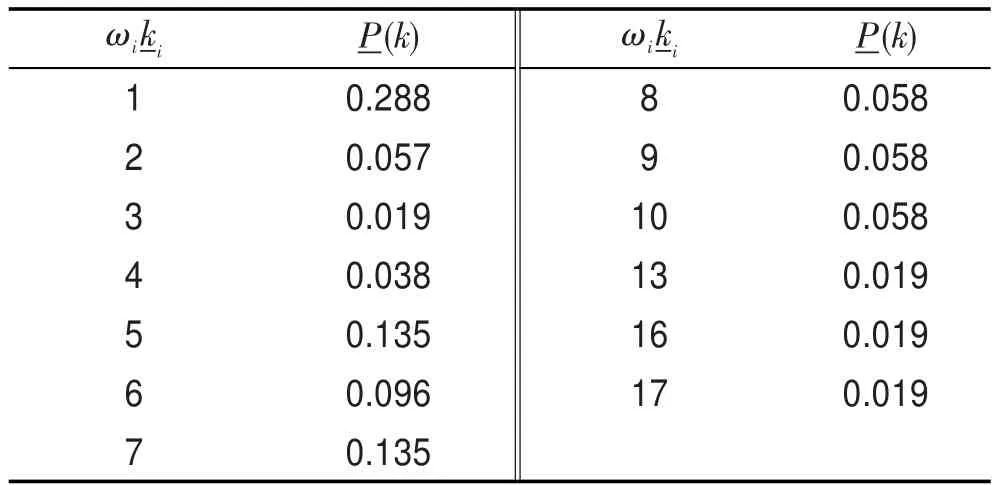
Table 1 Probability distribution table of underapproximate degree表1 下近似度的概率分布表
從度的概率分布散點圖可以看出度的概率分布曲線符合指數為負數的冪函數曲線,在雙對數坐標系下這些點基本上都分布在一條斜率為負的直線附近。根據非線性回歸分析,得到度分布的回歸曲線為-P(-k)=0.158 9-k-0.611。
由回歸分析的顯著性檢驗可知,回歸模型和回歸方程都是顯著的,但模型的擬合優度一般,這是由于收集的數據比較少所致。由此可知,第三方支付粗糙復雜網絡的下近似度服從冪律分布。同理可得,第三方支付粗糙復雜網絡的上近似度服從冪律分布。因此,有下述定理。
定理1第三方支付粗糙復雜網絡的下近似度和上近似度都服從冪律分布。
文獻[21]指出,冪律分布的γ越小,網絡的度分布越不均勻,度大的節點會非常突出,統計得到的網絡平均路徑與網絡實際平均路徑越接近,網絡搜索適合用最大度搜索法。顯然,如果以加權度大于網絡平均加權度的節點作為研究對象,滿足條件的節點會非常多,就會增大搜索空間,降低數據搜索的速度。說明了簡單地以加權度大于網絡平均加權度的方法來挖掘顧客,會增加平臺的工作量和運營成本,因此顧客的挖掘問題是平臺提高效益需要解決的關鍵問題之一。
3.2第三方支付粗糙復雜網絡的知識發現模型
在第三方支付粗糙復雜網絡中,平臺管理者為了吸引顧客通常會給所有的注冊會員發送促銷信息和優惠券,但這樣做顯然具有非常大的盲目性,也難以收到預期的效果。因此,平臺的管理者很希望能夠挖掘出一批潛在的顧客,為此他們做了各種嘗試,也收到了一些效果。但是這些措施都是根據經驗而得到的一些結論,缺乏科學性的依據。建立起第三方支付平臺的知識發現模型,解決平臺潛在客戶的挖掘問題是一個非常有意義的研究課題。
關于Web知識發現的研究,已經有了一些成果,但是至今還沒有形成成熟的理論和技術[20];至于粗糙復雜網絡的知識發現的研究,現有的文獻表明,還很少有人涉及這個領域。為此,做以下定義。
根據統計學原理,樣本分布在第一分位點Q1和第三分位點Q3之間的數目占樣本總數的50%,不妨把度k介于此部分的概率命名為度的概率主值。
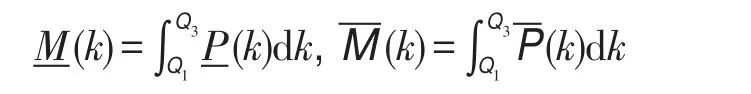
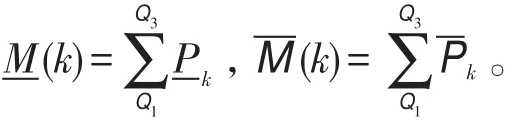
定義8滿足式(4)的節點稱為下近似關鍵節點(key nodes),滿足式(5)的節點稱為上近似關鍵節點。
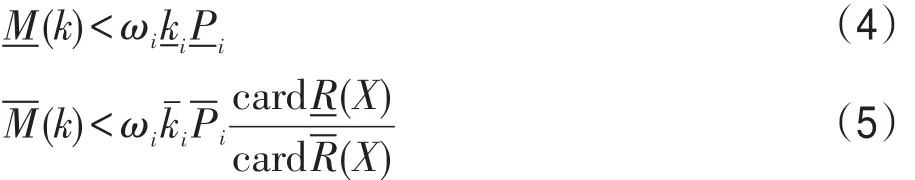
在粗糙復雜網絡中,關鍵節點的尋找可以沿著網絡的最短路徑去搜索。
定義9稱關鍵節點的購買者和收藏者為明星顧客;在此規定,只有明星顧客,才有可能成為潛在的顧客。
明星顧客的尋找可以分別在下近似粗糙網絡和上近似粗糙網絡中運用最大度搜索法確定,這里的度是指本文定義的加權網絡度。
有了上述定義,就可以建立第三方支付粗糙復雜網絡在動態知識系統中的知識發現模型,模型的創建包含以下3個階段。
階段1數據準備階段
數據準備又可分為3個步驟:數據選取、數據預處理和數據轉換。
在第三方支付粗糙復雜網絡中隨機選取若干個節點統計其下近似度和上近似度,計算其下近似度分布和上近似度分布,下近似度的概率主值和上近似度的概率主值;以最大加權度節點為源節點,確定其到其余節點的最短路徑,沿著網絡的最短路徑,依據式(4)和式(5)確定關鍵節點,關鍵節點的個數依據網絡的規模確定;對每一個關鍵節點,利用最大度搜索法統計其明星顧客近4期購買商品的數量、價格和收藏的商品價格和數量,形成目標數據;然后利用粗糙集的屬性約簡和決策規則的提取方法對目標數據中的噪音數據、不完整及不一致進行預處理[22],形成挖掘樣本數據庫;最后利用屬性約簡方法減小數據搜索空間,對挖掘樣本數據進行適當的轉換。
階段2數據挖掘階段
運用時間序列分析法對第三方支付粗糙復雜網絡動態知識系統進行知識發現研究,從明星顧客中挖掘出潛在的顧客。挖掘算法的基本思想如下:
(1)計算每位明星顧客近4期中每期購買和收藏的商品價值總額=價格×數量,i是第i個明星顧客,j是第 j期,i=1,2,…,j=1,2,3,4。
(2)通過所有明星顧客購買和收藏量的時間序列的中心化移動平均數的計算,消除時間序列的季節因素和不規則波動的影響[23],再用消除季節影響的時間序列確定每位明星顧客購買總額和收藏總額的趨勢值。
(3)計算每位明星顧客的定基消費指數:
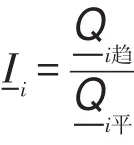
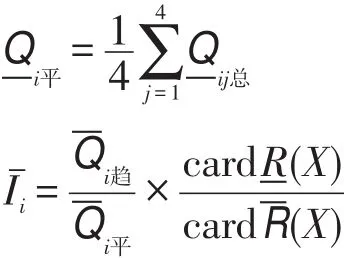
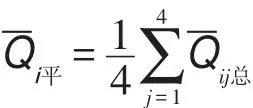
(4)根據每個明星顧客的消費指數,將消費指數大于等于1的確定為潛在的顧客。
階段3模式解釋/評價
通過實例直接用數據來檢驗其準確性。
第三方支付粗糙復雜網絡中,不僅存在著信息不完全性和數據冗余,而且數據的信息量大,具有動態變化的特征。該模型的構建以知識發現方法為主線,以時間序列分析和粗糙集的知識約簡、屬性規則的提取為理論支撐,提出了基于粗糙集理論的時間序列分析挖掘方法。在此之前的研究,還沒有同時兼顧數據的不完整性和知識系統動態性的相關結果。此外,本文的知識發現方法研究目標明確,挖掘算法針對的數據很少出現模糊性,而只有不可分辨的特點。運用粗糙集理論完成前期對數據的處理,消除了冗余數據、錯誤數據和缺省數據,保證了統計資料的真實可靠性;減少了時間序列分析法的運算量,提高了運算速度,適應了動態知識系統數據不斷累加的需求。
3.3第三方支付粗糙復雜網絡的知識發現方法的算法設計
輸出:潛在顧客potential customers。
步驟1變量賦值:

節點賦值:
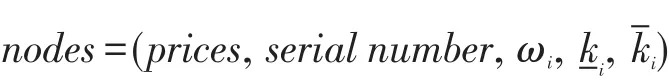
明星顧客賦值:
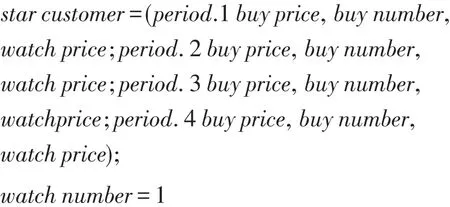
步驟3以最大加權度節點為源節點,運用Dijkstra算法確定其到其余節點的最短路徑,并隨機地在源節點到其余節點的最短路徑上搜索,滿足式(4)或式(5)的節點,存入key nodes;當遍歷網絡中所有節點或是key nodes中的節點數等于100時停止搜索。
步驟4對于key nodes中的所有節點,搜索其所有的購買者和收藏者,取其并集得到star customer set,連同它們近4期購買或收藏的商品價格和購買數量存入star customer,取收藏的數量均為1。
步驟5用知識約簡和屬性規則的提取對star customer中的噪音數據、不完整及不一致數據進行預處理,減少搜索空間,形成挖掘樣本數據庫sample database。
根據步驟4整理的數據,組成信息表;再將初始數據信息進行分類,刪除star customer中的噪音數據、不完整數據,合并具有不可分辨關系的對象,然后進行屬性約簡,得到約簡屬性集;選取屬性約簡后的信息表,得到各規則的核值;根據核值表產生約簡規則組合,形成挖掘樣本數據庫sample database。
步驟6計算每位明星顧客近4期中每期購買和收藏的商品價值總額:

步驟7運用時間序列分析法消除季節因素和不規則波動的影響,確定每位明星顧客下一期購買總額的趨勢值。
步驟8計算每位明星顧客的定基消費指數:

步驟9滿足-Ii≥1或-Ii≥1的明星顧客i,即為潛在顧客potential customers。
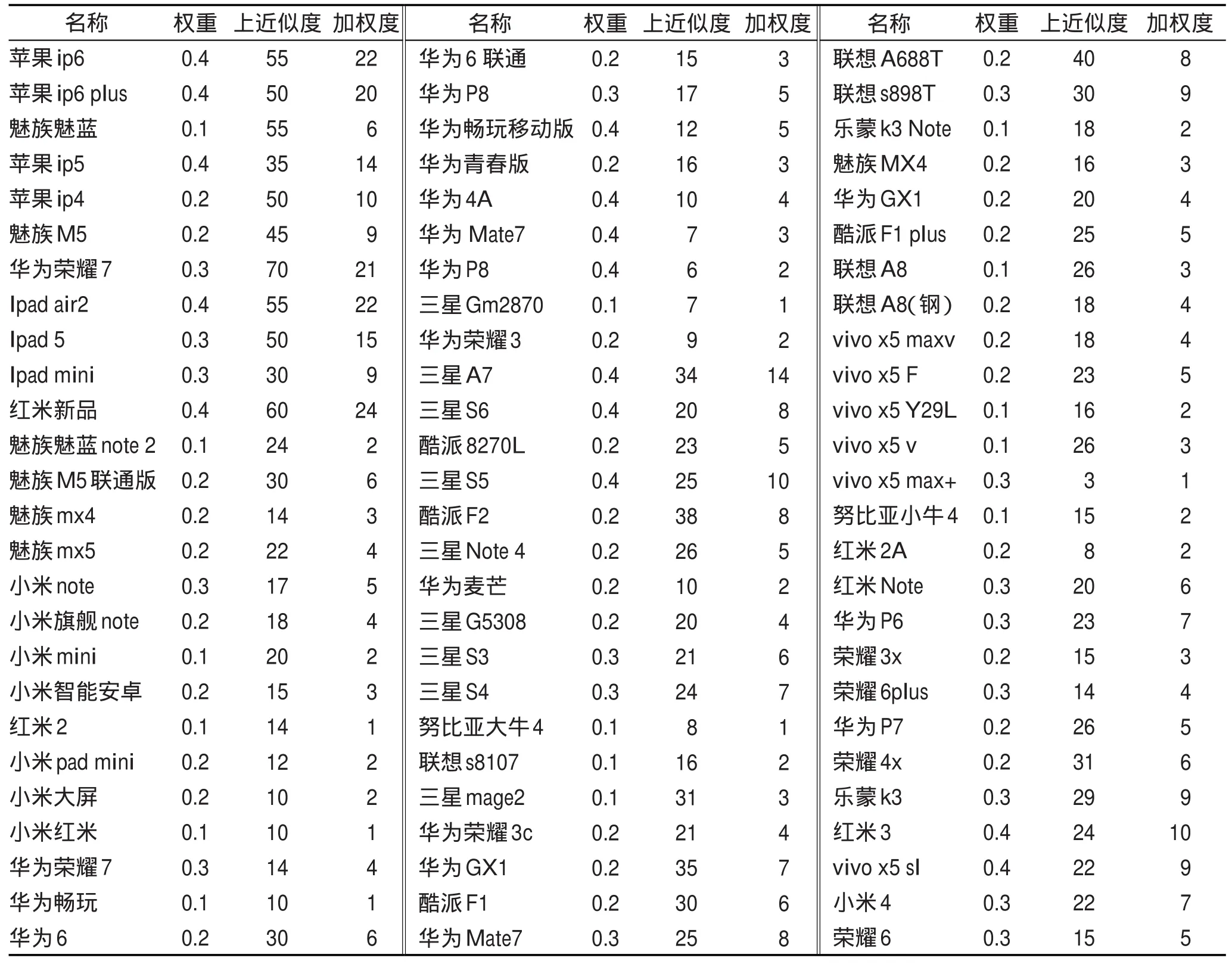
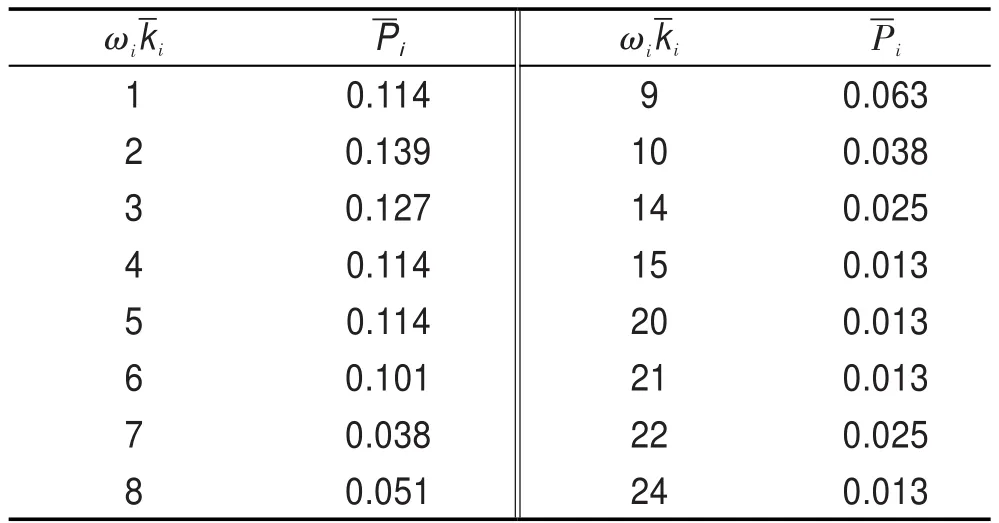
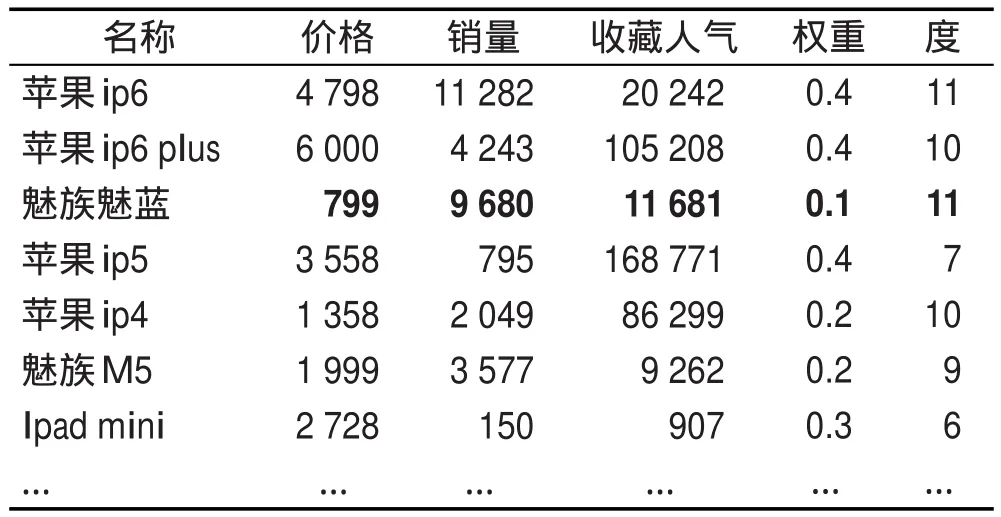
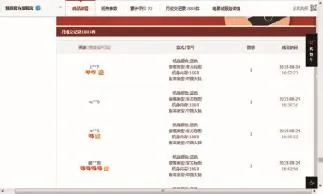
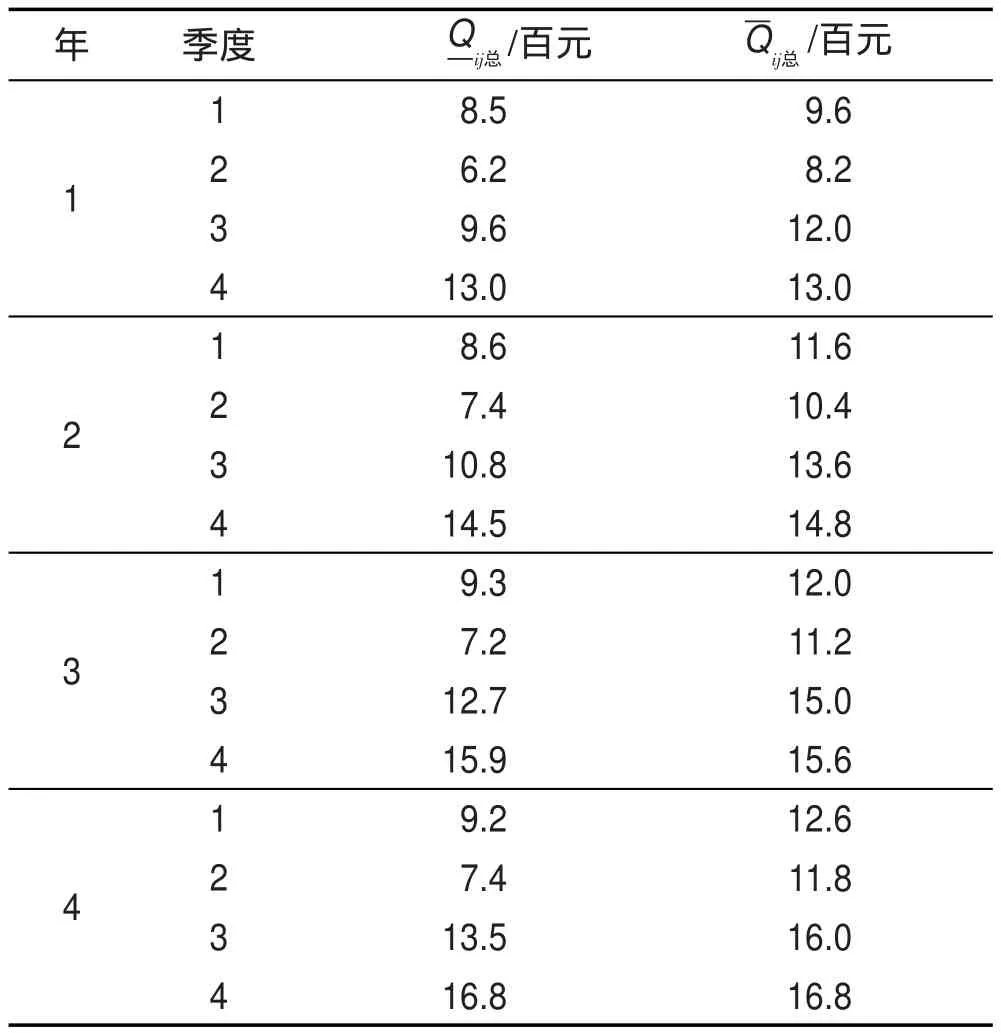
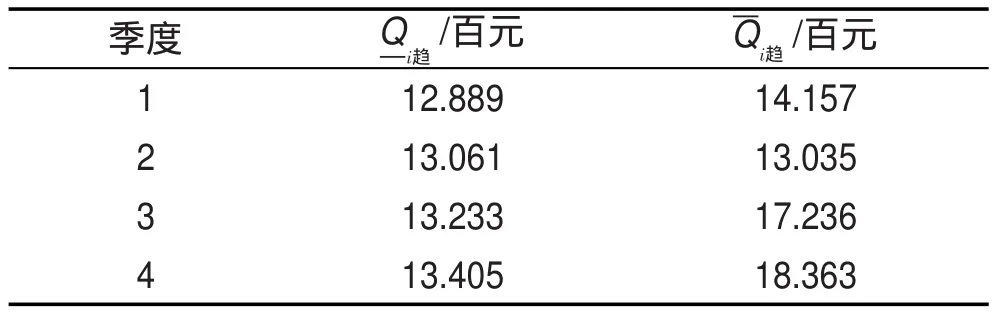
對n個節點的粗糙復雜網絡來講,如果決策屬性有c個,下近似粗糙復雜網絡節點數是n1,上近似粗糙復雜網絡節點數是n2,知識約簡與屬性規則提取后的決策屬性有d(d 從淘寶天貓商城收集到了經營蘋果、魅族、小米、華為、三星等品牌共4個商家78個商品組成的粗糙復雜網絡的上近似粗糙網絡圖,網絡結構類似于圖1,除去圖1負域中的連邊,統計出每個節點的價格、銷售量、收藏的人氣指數、上近似度、下近似度和節點價格的權重。其中上近似粗糙網絡的節點度、權重如表2所示。 由表2確定表3,根據非線性回歸分析法得到上近似度分布-P(k)=0.279k-0.991。 按以下步驟完成該粗糙復雜網絡的知識發現。 步驟1計算下近似度和上近似度的概率主值: 步驟2在網絡節點上搜索,滿足式(4)或式(5)的節點,存入key nodes,-k={5,6,7,9,10的節點};結果見表4,即: key nodes={三星Note 4,小米note,華為P8,華為暢玩移動版,酷派8270L,酷派F1 plus,vivo x5F,華為P7,榮耀6,魅族魅藍,魅族M5聯通版,三星S3,酷派F1,華為6,紅米Note,榮耀4x,三星S4,華為GX1,華為P6,小米4,蘋果ip4,魅族M5,Ipad mini,三星S5,聯想s898T,紅米3} 步驟3對于key nodes中的所有節點,搜索其所有的購買者和收藏者取其并集,連同他們近4期購買或收藏的商品價格和購買數量存入star customer。 在此,以魅族魅藍為例,表4是在網絡上收集的節點的有關信息,可以看出魅族魅藍的購買者月銷量9 680,收藏的人氣指數為11 681,數目比較多。此時可以隨機地搜集每100名購買的顧客作為1組,先組內求并集,再組間求并集,存入star customer。 在網絡上搜索出購買者如圖3所示。 根據圖3,可以得出購買者的名稱,然后平臺管理者可以對購買者近4期的購買總額進行匯總。計算每位明星顧客近4期中每期購買和收藏的商品價值總額: 以lixia1210這個帳號為例,近4年該用戶季度消費情況如表5所示。 步驟4利用屬性約簡和決策規則的提取對star customer中的噪音數據、不完整及不一致數據進行預處理,減少搜索空間,形成挖掘樣本數據庫sample database。 由于每位顧客購買的歷史記錄,除了顧客本人外,只有平臺管理者才可以從顧客的賬號里得到真實的數據,在此只能說明運算的過程。 Table 2 Nodes and weights table of the third-party payment up-approximation rough complex networks表2 第三方支付上近似粗糙復雜網絡的節點度和權重統計表 Table 3 Probability distribution table of up-approximate degree表3 上近似度的概率分布表 Table 4 Nodes information table of up-approximation rough complex network表4 上近似粗糙復雜網絡節點信息表 步驟5運用時間序列分析法消除季節因素和不規則波動的影響,確定每位明星顧客下一年購買和收藏總額的趨勢值。 Fig.3 Schematic diagram of Meizu Meilan buyers圖3 魅族魅藍的購買者示意圖 Table 5 Lixia1210 consumer records in nearly four years表5 lixia1210近4年的消費記錄 根據時間序列分析法,計算b0和b1的公式為: 式中,Tt為t期時間序列的值;n為時期數。 得到顧客lixia1210的線性趨勢成分表達式為: 因此,顧客第5年的季度趨勢值見表6。 Table 6 Quarterly trend values of lixia1210 in the fifth year表6 顧客lixia1210第5年的季度趨勢值 步驟7由樣本數據庫sample database中所有滿足的顧客構成潛在顧客集potential customers set。 本算例只是說明方法的有效性,在實際網絡中,數據的搜集必須得到平臺管理者的支持,然后通過計算機程序來實現知識發現方法的整個過程。算法的運算復雜度由最大度搜索法、最短路徑搜索法、時間序列分析法、屬性約簡和決策規則的提取確定,近似為是上近似粗糙復雜網絡的度。 第三方支付平臺的知識發現問題是一個錯綜復雜的問題,由于平臺交易的客戶信息具有不完整性和冗余性,現有的研究還沒有給出一種有效的定量化的方法。通常情況下,管理者根據經驗和一些定性化的建議進行決策,顯然增加了操作的盲目性,也增加了運營成本。 本文構建了第三方支付的粗糙復雜網絡,定義了粗糙復雜網絡的上下近似度、度分布和度的概率主值,證明了第三方支付粗糙復雜網絡的上近似度和下近似度都服從冪律分布的結論,最后建立了第三方支付平臺客戶挖掘的知識發現模型,根據冪律分布網絡的特點給出了知識發現方法。仿真實例說明了本文的客戶挖掘方法是有效可行的。與現有運營管理方式相比,本文的知識發現模型具有以下三方面的優越性:(1)關鍵節點的選擇比隨機挑選度比較大的節點更加合理,關鍵節點考慮了節點的效益,同時也減少了操作的盲目性;(2)明星顧客的設置算法,運用了粗糙集的屬性約簡和決策規則提取方法對數據進行預處理,減少了搜索空間,提高了數據搜索的速度和結果的精確度;(3)運用時間序列分析法找到潛在客戶,是經過嚴格的數學推導的,科學可行,適應了動態知識系統更新的需求。因此,本文知識發現方法滿足了第三方支付平臺發展的需求,可以解決第三方支付平臺潛在客戶的挖掘問題。 References: [1]Han Guohong.The third-party payment development in ten years:a literature review[J].Enterprise Economy,2012(388): 95-98. [2]Zhao Shuo,Zhao Yang.Research of the third-party payment platform and Internet banking development issues[J].Journal of Commercial Economic,2015(11):81-82. [3]Liao Yuping.Research of risk regulation and development on Internet financial in China—P2P platform,Balance Bao, third-party payment example[J].Economics and Management,2015,29(2):51-57. [4]Zhu Shanhong,Kuang Tao.E-commerce model and platform based on the third-party[J].Journal of Chemical and Pharmaceutical Research,2014,6(3):863-868. [5]Zhu Shanhong,Shi Qingmin.Research of third-party E-commerce risk and measures[J].Advanced Materials Research,2014, 926-930:3882-3885. [6]Yang Ling,Shuai Qinghong.Profitability analysis of the thirdparty Internet payment platform[J].Computer Application Research,2014,31(3):773-775. [7]Li Beiwei,Zhang Xinqi,Wang Ya,et al.Information ecosystem analysis of our third-party electronic trading platform—based on the perspective of complex networks[J].Information Science,2014,32(7):78-82. [8]Duan Wenqi.Scale of critical users of third-party e-commerce platform based on a complex network[J].China Management Science,2014,22(12):93-101. [9]Wang Xiaofan.Research on network scientific development [J].Control Science and Engineering,2014:111-118. [10]Zhang Chunying,Guo Jingfeng.Rough property graph model and application of Web social networks[J].Computer Engineering and Science,2014,36(3):517-523. [11]Zhang Chunying.Social network based on attribute figure modeling and theoretical studies of situation analysis[D]. Qinhuangdao:Yanshan University,2013:17-30. [12]Ye Lisha,Wang Xuedong,Fang Jin.Research of network information resources knowledge discovery mechanism[J]. Modern Information,2014,34(8):160-163. [13]An Haizhong,Zheng Lian,Wang Guangxiang.Situation and prospects for rough sets knowledge discovery[J].Computer Measurement&Control,2003,11(2):81-83. [14]Zhao Xiaolin,Hao Gang,Hu Changzhen,et al.A discovery method of the dirty data transmission path based on complex network[J].Applied Mechanics and Materials,2014,651-653:1741-1747. [15]Ferretti S.Gossiping for resource discovering:an analysis based on complex network theory[J].Future Generation Computer Systems,2013,29(6):1631-1644. [16]Azadeh A,Saberi M,Jiryaei Z.An intelligent decision support system for forecasting and optimization of complex personnel attributes in a large bank[J].Expert Systems with Applications,2012,39(16):12358-12370. [17]Bell L,Chowdhary R,Liu J S,et al.Integrated bio-entity network:a system for biological knowledge discovery[J].PLoS ONE,2011,6(6):e21474. [18]Baurley J W,Conti D V,Gauderman W J,et al.Discovery of complex pathways from observational data[J].Statistics in Medicine,2010,29(19):1998-2011. [19]Zhou Xuezhong,Chen Shibo,Liu Baoyan,et al.Development of traditional Chinese medicine clinical data warehouse for medical knowledge discovery and decision support[J].Artificial Intelligence in Medicine,2010,48(2/3):139-152. [20]Vicient C,MorenoA.Unsupervised topic discovery in microblogging networks[J].Expert Systems with Applications,2015, 42(17/18):6472-6485. [21]Guo Shize,Lu Zheming.Basic theory of complex networks [M].Beijing:Science Press,2012:43-45. [22]Zhang Wenxiu,Wu Weizhi,Liang Jiye,et al.Rough set theory and methods[M].Beijing:Science Press,2001:3-10. [23]Liu Jinlan.Management statistics[M].Tianjin:Tianjin University Press,2011:150-157. 附中文參考文獻: [1]韓國紅.第三方支付發展的十年回顧:一個文獻綜述[J].企業經濟,2012(388):95-98. [2]趙爍,趙楊.第三方支付平臺以及互聯網金融發展問題研究[J].商業經濟研究,2015(11):81-82. [3]廖愉平.我國互聯網金融發展及其風險監管研究——以P2P平臺、余額寶、第三方支付為例[J].經濟與管理,2015, 29(2):51-57. [6]楊玲,帥青紅.第三方互聯網支付平臺的盈利分析[J].計算機應用研究,2014,31(3):773-775. [7]李北偉,張鑫琦,王亞,等.我國第三方電子交易平臺信息生態系統特性分析——基于復雜網絡的視角[J].情報科學,2014,32(7):78-82. [8]段文奇.基于復雜網絡的第三方電子商務平臺臨界用戶規模研究[J].中國管理科學,2014,22(12):93-101. [9]汪小帆.網絡科學發展研究[J].控制科學與工程,2014: 111-118. [10]張春英,郭景峰.Web社會網絡的粗糙屬性圖模型及應用[J].計算機工程與科學,2014,36(3):517-523. [11]張春英.基于屬性圖的社交網絡建模與態勢分析理論研究[D].秦皇島:燕山大學,2013:17-30. [12]葉麗莎,王學東,方婧.網絡信息資源知識發現機理研究[J].現代情報,2014,34(8):160-163. [13]安海忠,鄭鏈,王廣祥.粗糙集知識發現的研究現狀和展望[J].計算機測量與控制,2003,11(2):81-83. [21]郭世澤,陸哲明.復雜網絡基礎理論[M].北京:科學出版社,2012:43-45. [22]張文修,吳偉志,梁吉業,等.粗糙集理論與方法[M].北京:科學出版社,2001:3-10. [23]劉金蘭.管理統計學[M].天津:天津大學出版社,2011: 150-157. CAO Lixia was born in 1971.She is a Ph.D.candidate at School of Management,Xi’an University of Architecture and Technology,and an associate professor at Xi’an Technological University.Her research interests include rough set,complex networks,operation research and cybernetics,management decision analysis and game theory,etc. 曹黎俠(1971—),女,陜西西安人,西安建筑科技大學管理學院博士研究生,西安工業大學副教授,主要研究領域為粗糙集,復雜網絡,運籌學與控制論,管理決策分析及博弈論等。 HUANG Guangqiu was born in 1964.He is a professor and Ph.D.supervisor at School of Management,Xi’an University of Architecture and Technology,the consultant expert of the Government of Xi’an and the assessment expert of National Natural Science Foundation.His research interests include e-business and network security, information management,systems engineering,complex system simulation and control,decision optimization and management,etc. 黃光球(1964—),男,西安建筑科技大學管理學院教授、博士生導師,西安市專家咨詢團特聘專家,國家自然科學基金項目評審專家,教育部博士點基金項目評審專家,管理科學與工程以及計算機科學技術領域權威期刊審稿專家,主要研究領域為電子商務與網絡安全,信息管理,系統工程,復雜系統仿真與控制,決策優化與管理等。 LI Yan was born in 1984.He is a Ph.D.candidate at School of Management,Xi’an University of Architecture and Technology.His research interests include information confrontation,network security and systems engineering,etc. 李艷(1984—),男,蒙古族,河北承德人,西安建筑科技大學管理學院博士研究生,主要研究領域為信息對抗,網絡安全,系統工程等。 *The Natural Science Basic Research Program(Key)of Shaanxi Province under Grant No.2015JZ010(陜西省自然科學基礎研究計劃(重點));the Decision-Making Advisory Issue of Xi?an Science&Technology Association under Grant No.201517(西安市科協決策咨詢課題);the Social Science Fund Project of Shaanxi Province under Grant No.2014P07(陜西省社會科學基金項目);the Science Plan Project of Education Department of Shaanxi Province under Grant No.16JK1369(陜西省教育廳科學計劃研究項目). Received 2015-12,Accepted 2016-02. CNKI網絡優先出版:2016-02-03,http://www.cnki.net/kcms/detail/11.5602.TP.20160203.1126.006.html 文獻標志碼:A 中圖分類號:TP182;N945.12 doi:10.3778/j.issn.1673-9418.1512036 Research on the Third-Party Payment Rough Complex Networks Knowledge Discovery Methods* CAO Lixia1,2+,HUANG Guangqiu1,LI Yan1 Abstract:Sustainable development of the third-party payment platform is a very complex problem,the key of problem is the mining of potential customers in trading platform.This paper establishes the third-party payment rough complex networks,defines rough approximation degree,the probability principal value of complex networks and degree distribution,constructs a rough model of knowledge discovery,and gives a method based on rough set theory for knowledge discovery.The research on rough complex networks knowledge discovery method provides a quantitative and actionable method,which can solve the potential customers mining issues of the rough complex networks.This paper presents the concepts of rough complex networks,as well as degree distribution of the third-party payment rough complex networks,which lay the theoretical foundation for the third-party payment issues.The research on knowledge discovery method adapts to the needs of dynamic knowledge system updates,so there is a broad application prospect. Key words:the third-party payment;rough complex networks;time series analysis;knowledge discovery4 仿真模擬
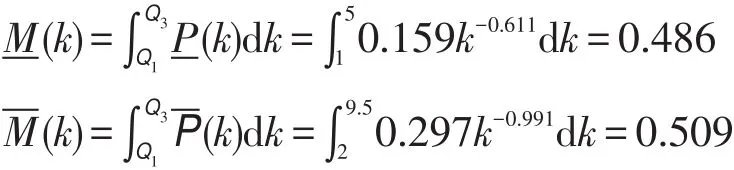
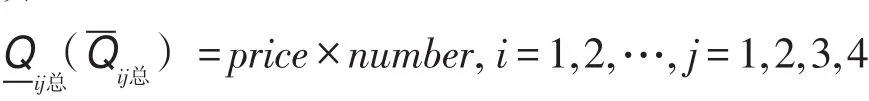
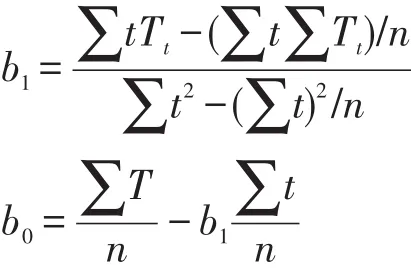
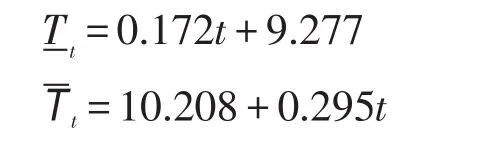
5 結論



1.College of Management,Xi?an University ofArchitecture and Technology,Xi?an 710055,China
2.College of Science,Xi?an Technological University,Xi?an 710032,China
+Corresponding author:E-mail:caolx_8@163.com
