基于海量數據的用戶點擊模式識別
2016-09-12 06:40:16林湘粵北京郵電大學信息與通信工程學院碩士研究生張昕宇北京郵電大學信息與通信工程學院碩士研究生
信息通信技術與政策 2016年8期
林湘粵 北京郵電大學信息與通信工程學院碩士研究生張昕宇 北京郵電大學信息與通信工程學院碩士研究生
?
基于海量數據的用戶點擊模式識別
林湘粵北京郵電大學信息與通信工程學院碩士研究生
張昕宇北京郵電大學信息與通信工程學院碩士研究生
移動互聯網的高速發展,產生了大量的話單數據,其中蘊含的用戶行為模式為移動運營商和人類信息社會的發展帶來了機遇和挑戰。本文介紹了基于云計算的海量數據挖掘技術下用戶點擊模式挖掘的過程,并分析了點擊模式挖掘的結果及其帶來的價值。
移動互聯網;用戶行為模式;先驗算法;云計算;模式挖掘
1 引言
移動互聯網的快速發展,帶領中國走向了信息化時代。用戶利用智能設備隨時隨地連接著移動互聯網,并通過其產生了大量話單數據,大數據時代已經到來。移動互聯網中的海量數據,反映著人們日常行為的方方面面,在大規模的用戶通過智能手機產生的上億規模流量的話單數據當中,如何從中挖掘出用戶的行為特點,將用戶的行為總結成行為模式用以描述用戶的特征,是當前大數據應用的一個熱點。
移動互聯網用戶的點擊行為模式挖掘是將用戶主動點擊的網址鏈接總結成點擊模式的過程。這些總結的點擊模式能夠反映用戶真實的上網意圖,反映用戶真實的上網點擊行為。用戶點擊模式的挖掘能夠有助于理解用戶真實的網站訪問偏好,可以有助于商家對用戶的有效推送,同時也能夠利用識別的結果進行網頁質量的分析。將移動互聯網的點擊信息采用處理、清洗和挖掘的方式,可以發現點擊者的點擊模式,提取出點擊使用者的個人特點和喜好,為不同喜好類別的用戶設計不同的網頁頁面,在恰當的網頁頁面為用戶提供用戶自己所喜歡的特定廣告,并為用戶推送和用戶特點相匹配的商業資訊和新聞,從而增強商家的競爭力。用戶點擊模式挖掘具有極其高的商業價值和現實意義。
2 點擊模式挖掘
隨著移動互聯網技術的發展和智能終端在市場上的擴張,越來越多的人們通過智能終端連接到移動互聯網,人們訪問移動互聯網的相關信息蘊含著用戶的相關喜好、用戶的行為等,同時也蘊含著移動互聯網本身的一些特征。所以越來越多的研究者采用原始的數據挖掘技術去挖掘移動互聯網背后的潛在信息。然而大多數移動互聯網數據挖掘的技術都是基于網頁本身,只關注一些特殊文本和網頁關鍵字,基于用戶訪問的URL本身的研究和挖掘很少。
首先,基于點擊識別的算法,從大量的流記錄話單中識別出了點擊URL。為了進一步對URL的內部規律進行挖掘和研究,將點擊URL的規則進行提取,用這些提取出來的點擊URL規則代替點擊URL,從而極大地縮小點擊URL數據表的數量,節省存儲空間,同時發現點擊URL規則的內部規律。
2.1點擊模式挖掘創新點
本文基于Apriori算法,并對其進行了改進,以適應點擊模式挖掘算法。傳統的利用Apriori算法的挖掘當中,最終展現序列的形式包含有序性、可重復性。在此方法中,為適應URL有序的且具有層級關系的數據結構,最終展示的序列還具有固定位置特性。即
原始Apriori算法包括兩個部分:頻繁項的產生和規則的發現。用戶點擊模式挖掘算法,只要產生了頻繁序列項即是產生了規則,沒有單獨的規則發現階段。
另外,對于候選項的產生方法中,和原始算法也有所不同。候選項的產生原則應當避免產生太多不必要的候選,同時必須確保候選項集的集合是完備的,此外還不應該產生太多重復候選項集。
在原始算法候選項的產生方法中,Fk-1*Fk-1方法:
在每兩個頻繁項合并產生新的候選項的時候,對產生的候選項直接篩選,原始算法只根據支持度計數方法過濾,點擊URL識別算法不僅根據支持度計數方法過濾,還根據置信度進行過濾,而且根據兩方面的置信度進行過濾。
2.2點擊模式挖掘相關定義
點擊URL規則的提取,采用數據挖掘理論當中關聯分析和頻繁項集產生的方法進行提取和逐層發現。并沒有完全照搬關聯分析和頻繁項集產生的Apriori算法,而是將算法進行了改進,研究出有層級順序的規則提取算法,以適應URL當中每一項之間有特定順序這一主要特點。同時,最終采取的URL規則是極大頻繁項集。
首先,定義序列這個概念,它具有如下4個性質:
性質一:序列中的元素是有層級的。一個序列中的元素從前到后依次是第0,1,2,3……層級,一個元素在不同層級上代表著不同的序列,如
性質二:序列中的某一個層級的元素允許為空。如果某一個層級的元素為空,則用*代替。
性質三:序列中的元素是有序的,調換順序,即產生新的一個序列,如
性質四:序列中的元素允許相同,如
(1)項(i):將URL以“/”分割,一個URL分割后的每一個元素,都是一個項。
(2)項集(iSets):由若干個項組成集合為一個項集。
(3)事務(t):每一個URL為一個事務。
(4)事務集(tSets):具有0個或多個事務的集合為一個事務集。
(5)層級(level):將URL以“/”分割,一個URL分割后的第i個元素,即是第i層級。層級針對一個項而言。
(6)長度(length):一個URL規則當中含有非空項的個數,即是該URL規則的長度。長度針對一個URL規則而言。
(7)支持度計數(σ):規則在事務集當中的出現次數。
(8)支持度。
(9)置信度(Confidence):確定新規則在包含原規則的事務集當中出現的頻繁程度。
基于以上定義,序列中的每個元素就是項,每個URL抽象成的序列就是事務,項的位置序號代表著這個項的層級,一個序列中非空元素的個數是一個序列的長度,k-序列是長度為k的序列。序列中的元素的個數和序列的長度可以是不同的,如
2.3點擊模式挖掘方法
首先,頻繁項集的產生主要依靠支持度計數原則。在此頻繁項集產生階段,只產生長度為2的序列,并且此序列的第0個元素一定不為空。初始規則的產生分兩個步驟:
(1)初始候選項的產生:產生每一個長度為2的子序列。
(2)初始候選項的篩選:設子序列的支持度為δ,該規則為頻繁項的判斷原則為:δ>δs。
然后,對點擊模式進行擴展。長度為j+1的序列由長度為j的序列和長度為2的序列構成,一旦產生新的序列,產生它的兩個父序列就可以由新的序列替代,即最后取得是極大頻繁項。URL規則的擴展過程,采用邊產生新規則邊篩選的方法。假設規則G1層級為Level1,長度為Length1(Length1=j);規則G2層級為Level2,長度為Length2(Length2=2)。規則的擴展包括兩個步驟:
(1)候選項的產生:G1與G2兩個規則合并產生候選G3,且有如下原則:Level2>Level1。
(2)候選項的篩選:G3是新產生的規則,它被判別為頻繁項的原則:(a)δG3>δs;(b)δG3/δG1>δc;(c)δG3/δG2>δc。
由之前的算法步驟產生了不同長度的序列,即不同長度的規則,由于一旦產生新的序列,產生它的兩個父序列就可以由新的序列替代,即最后取得是極大頻繁項,所以要對最后的所有規則進行篩選,篩選出極大頻繁項,即極大長度的規則。
至此,點擊url模式挖掘算法得以實現。
3 點擊模式挖掘結果
3.1數據說明
所采集到的流量數據來自運營商,數據的采集地理位置在中國一個大型城市。該城市的人口數量有400萬人左右,一天的數據量在1T左右。數據所采集的移動互聯網骨干網的網絡結構圖如圖1所示。在移動互聯網當中,有3個主要的組成部分,即移動設備、接入網絡、骨干網絡。
研究所使用的數據集通過流量監控系統TMS設備進行采集,TMS設備連接著圖中所示的Gn接口。將報文按照五元組{源IP,目的IP,源端口號,目的端口號,傳輸協議}的規則進行解析,流是一段時間內具有相同五元組的一系列報文的集合。由于數據量的巨大,解析好的流記錄,會上傳到Hadoop集群的分布式存儲文件系統HDFS當中。
3.2點擊模式挖掘結果評價
基于點擊URL的識別結果,進行點擊模式的挖掘。在支持度和置信度的選擇上,選擇在模式挖掘結果的F1值最大的時候所對應的支持度和置信度。所以,在本文中,點擊URL的模式挖掘的支持度為0.1,置信度為0.5。在這個閾值設定下,點擊的模式挖掘結果如表1~6所示。
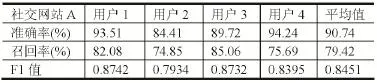
表1 社交網站A點擊模式識別結果
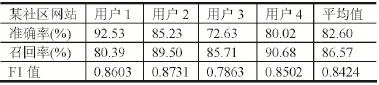
表2 某社區網站點擊模式識別結果

表3 社交網站B點擊模式識別結果
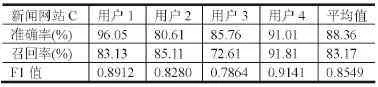
表4 新聞網站C點擊模式識別結果
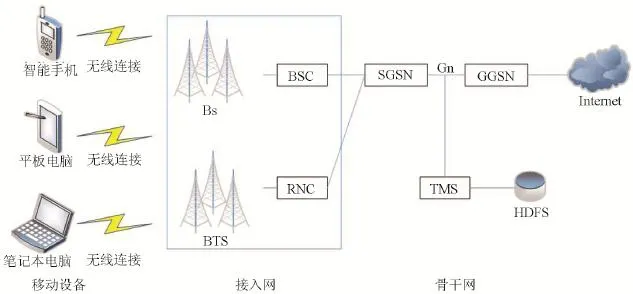
圖1 2G和3G網絡數據采集網絡結構圖
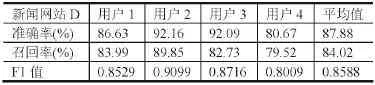
表5 新聞網站D點擊模式識別結果
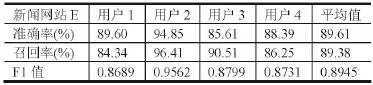
表6 新聞網站E點擊模式識別結果
從試驗結果可以看出某社交網站A的F1值平均為0.8451,某社交網站B的F1值平均為0.8500,某社區網站的F1值平均為0.8424,新聞網站C的F1值平均為0.8549,新聞網站D的F1值平均為0.8588,新聞網站E 的F1值平均為0.8945。可以看出,所有Host對應的F1值的平均值均在0.85左右,識別的結果較好。
4 結束語
隨著移動互聯網的快速發展和互聯網上信息的爆炸式增長,網站和網頁越來越成為人們在日常生活中分享信息,交流想法,休閑娛樂的重要平臺。通過用戶的行為規律為用戶構建用戶畫像,發現他獨特的喜好,改善商家所給出的業務和應用,具有極高的商業價值和現實意義。而用戶上網的點擊行為是移動互聯網用戶行為模式挖掘中相當重要的部分。
本文提供的點擊URL模式挖掘方法改進了原有的Apriori算法,使新的方法能夠適應URL的有序的同時是帶有層級關系的數據結構。利用挖掘的點擊模式,可以發現用戶點擊網頁的真實意圖,為移動運營商提供隱形的有意義的用戶上網點擊行為的信息和用戶點擊網頁的興趣點,對提升網頁的質量有著至關重要的作用。
User click pattern recognition for massive data
LIN Xiangyue,ZHAN GXinyu
With the rapid development of the Mobile Internet,massive user data has been produced,in which the user behavior model has brought both challenges and opportunities.This paper details the process of user click pattern mining based on cloud computing.By the way,the result and the commercial valueit would brought have been given as well.
mobile internet;user behavior model;apriori algorithm;cloud computing;pattern mining
2016-04-10)
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
幸福(2018年33期)2018-12-05 05:22:42
Coco薇(2017年11期)2018-01-03 20:59:57
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
商用汽車(2016年11期)2016-12-19 01:20:16
中國科技信息(2016年14期)2016-07-31 21:16:32
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年10期)2015-02-27 07:55:08
