空間數(shù)據(jù)挖掘的高效和有效的聚類方法
2016-09-20 02:47:14胡馨元殷守林劉杰沈陽師范大學(xué)科信軟件學(xué)院沈陽110034
現(xiàn)代計算機 2016年6期
關(guān)鍵詞:數(shù)據(jù)挖掘方法
胡馨元,殷守林,劉杰(沈陽師范大學(xué)科信軟件學(xué)院,沈陽 110034)
空間數(shù)據(jù)挖掘的高效和有效的聚類方法
胡馨元,殷守林,劉杰
(沈陽師范大學(xué)科信軟件學(xué)院,沈陽110034)
0 引言
空間數(shù)據(jù)挖掘[1-2]是指從空間數(shù)據(jù)庫中抽取沒有清楚表現(xiàn)出來的隱含的知識和空間關(guān)系,并發(fā)現(xiàn)其中有用的特征和模式的理論、方法和技術(shù)。空間數(shù)據(jù)挖掘和知識發(fā)現(xiàn)的過程大致可分為以下多個步驟:數(shù)據(jù)準(zhǔn)備、數(shù)據(jù)選擇、數(shù)據(jù)預(yù)處理、數(shù)據(jù)縮減或者數(shù)據(jù)變換、確定數(shù)據(jù)挖掘目標(biāo)、確定知識發(fā)現(xiàn)算法、數(shù)據(jù)挖掘、模式解釋、知識評價等,而數(shù)據(jù)挖掘只是其中的一個關(guān)鍵步驟。但是為簡便,人們常常用空間數(shù)據(jù)挖掘來代替空間數(shù)據(jù)挖掘和知識發(fā)現(xiàn)。
在空間數(shù)據(jù)處理過程中,采用所有的算法都會遇到兩個問題:第一,用戶和專家必須為算法提供空間層次概念結(jié)構(gòu),這可能并不在一些應(yīng)用中使用;第二,兩種算法進行空間探索主要通過在一定程度層次結(jié)構(gòu)上以一個更大的地區(qū)在一個更高的水平合并區(qū)域。這兩個問題對于很多應(yīng)用來說,它很難知道一個先驗的層次結(jié)構(gòu)是否是最適合的。
在聚類分析中有兩種著名的算法即圍繞中心點的劃分和大型應(yīng)用中的聚類方法。
空間數(shù)據(jù)挖掘的兩個主要算法SD(Clarans)和NSD(Clarans)[3-4]。
SD(Clarans):Spatial Dominant Approach空間占主導(dǎo)地位的方法。
NSD(Clarans):Non-Spatial Dominant Approach非空間占主導(dǎo)地位的方法。
為了解決這些問題,我們探索了聚類分析技術(shù)是否適用。在過去三十年中聚類分析一直是個被研究的對象,而且成功應(yīng)用在很多領(lǐng)域上。對于空間數(shù)據(jù)挖掘,我們在這里使用的方法僅用于空間屬性,那些自然相似概念的存在如歐幾里得、曼哈頓距離。正如本篇文章所展示的,聚類分析對于空間數(shù)據(jù)挖掘非常有效,作為更有效的考慮,我們發(fā)展研究自己的聚類分析算法叫做CLARANS,它為了研究大數(shù)據(jù)集而被設(shè)計。
1 基于分割的聚類方法
1.1圍繞中心點的劃分方法(PAM)
它的基本思想:為找到k個集群,它的方法就是為每個集群確定一個代表對象。這個代表對象稱為中心點它是最集中位于集群中的對象。一旦這個中心點被選中了,每一個非選擇的最相似的對象以中心點歸類[5-7]。假如Oj是一個非被選擇的對象,Oi就是一個中心點,我們就說Oj屬于由Oi代表的聚類。如果d(Oj,Oi)=minOed(Oj,Oe),其中minOe代表所有中心點Oe中的最小值。d(Oa,Ob)代表Oa到Ob的距離。
所有的相異點的值給出作為PAM的輸入,最后聚類的效率由一個對象和一個中心點的平均值測出。為了尋找這個k個中心點,PAM以任意的一個k對象開始,在每一步中只要能夠提高聚類的效率就進行Oi和Oh的互換,為了計算兩者之間互換的影響,PAM對所有非選擇性對象Oj計算Cjih的消耗。下面列出了Oj存在的幾種情況:
(1)假設(shè)Oj屬于Oi的聚類 ,讓Oj比Oh更加相似于Oj2,也就是d(Oj,Oh)≥d(Oj,Oj2),Oj2更接近于Oj,因此,如果Oi被Oh取代了成為中心點,那么Oj屬于Oj2的一個聚類。互換成本可以寫成Cjih=d(Oj,Oj2)-d(Oj,Oi)。
(2)Oj比Oh并不相似于Oj2也就是d(Oj,Oh)<d (Oj,Oj2)。如果Oi被Oh取代了成為中心點,那么Oj屬于Oh的一個聚類此時Cjih=d(Oj,Oi)-d(Oj,Oj2)。
(3)假設(shè)Oj接近于除了Oi展示的聚類 ,讓Oj2接近于那個中心點,而且讓Oj比Oh更接近于Oj2,因此,即使Oi被Oh取代了,Oj會一直聽停留在Oj2的一個聚類中。互換成本可以寫成Cjih=0。
(4)假設(shè)Oj屬于Oj2的聚類 ,但是Oj比Oh并不接近于Oj2,用Oh取代Oi會引起Oj跳躍到Oh的一個聚類中,因此,如果Oi被Oh取代了成為中心點,那么Oj屬于Oj2的一個聚類。互換成本可以寫成Cjih=d(Oj,Oh)-d (Oj,Oj2)。
1.2圍繞中心點的劃分算法步驟
(1)任意選擇k個代表對象。
(2)Oi被選定了,Oh沒有被選中,計算所有的Oi消耗成本。
(3)選擇Oi和Oj這一對中心點符合minOi,Oh,TCih如果最小值是負的就用Oh取代Oi并且回到第二步。
(4)否則,對于每一個非被選擇的對象找到最相似的對象。
實驗結(jié)果表明,PAM適合小的數(shù)據(jù)集而不適合大的。在第二第三步中一共有k(n-k)對Oi和Oh,對于每一對中心點,
計算TCih需要檢查(n-k)個非選擇點,那兩步的時間復(fù)雜度是O(k(n-k)2),但是這樣過于復(fù)雜,因此出現(xiàn)了CLARA(Clustering Large Applications,大型應(yīng)用中的聚類方法)。
2 CLARA算法
①對于i=1,2,3,4,5重復(fù)以下步驟。
②從所有數(shù)據(jù)集中隨機畫一個40+2k對象的樣本,讓PAM算法找到k個中心點。
③對于所有數(shù)據(jù)集中的Oj對象,確定k個中心點哪一個更接近于Oj。
④計算包含在以上步驟中的相異聚類點的平均值,如果這個值小于目前的最小值用這個值取代那個最小值,保留在第二步中找到的k個中心點作為目前最好的一組中心點集。
⑤返回到第一步開始新的交互尋找。
PAM:時間復(fù)雜度是O(k(n-k)2)。
CLARA:時間復(fù)雜度是O(k(k+40)2+k(n-k))。
3 一種基于隨機搜索的聚類算法——CLARANS

另外,令Sa是一組對象,子圖GSa,k由子集合Sa構(gòu)成。如果M原始圖形Gn,k中的最小節(jié)點,而且M并不包含在GSa,k中,那么M永遠不會在GSa,k的搜索中找到。
CLARA在搜索的開始,畫了一個樣本的節(jié)點,而CLARANS在每一個搜索的步驟中畫了一個鄰居的樣本。
(1)分割聚類算法步驟
①輸入?yún)?shù)numlocal(局部最小值),maxneighbor(局部最大值)初始化i=1,mincost為一個大數(shù)值;
②在Gn,k中設(shè)置一個任意節(jié)點current;
③令j=1;
⑤如果S有一個很低的消耗,令current=S,回到第三步;
⑥否則,j+1。如果j≤maxneighbor回到第四步;
⑦否則j>maxneighbor,讓current和mincost的消耗做一個比較,如果current消耗少于mincost,令min鄄cost=current(cost消耗),并且令bestnode=current;
⑧i+1,如果i>numlocal,輸出bestnode和halt,否則返回到第二步。
由以上可以看出,CLARANS有兩個參數(shù)鄰居的最大值和局部的最小值。局部最大值越高,CLARANS越接近PAM,每個局部最小值的搜索也越長。這樣一個局部最小值更高的特性將會有更少的地方需要取得最小值。在CLARANS里面設(shè)置numlocal=2,maxneighbor設(shè)置成一個在250和k(n-k)的1.25%之間比較大的值。PAM和CLARANS的比較結(jié)果如圖1所示。
CLARA產(chǎn)生聚類的特性,CLARANS進行了數(shù)值規(guī)范。隨著k=5,10,20增大CLARA的誤差也越來越大,而CLARANS方法的誤差不變。如圖2所示。
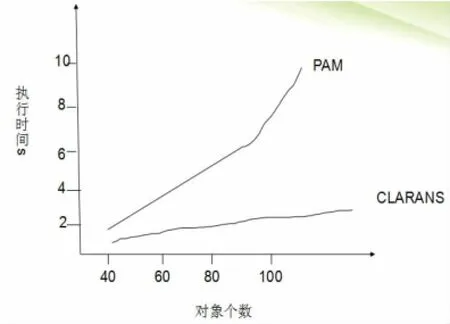
圖1 PAM和CLARANS的比較結(jié)果
考慮到相同的時間,CLARANS在所有情況下很明顯勝過CLARA。當(dāng)k(聚類的個數(shù))從5增加到20的時候二者之間的誤差由4%到20%。隨著k的增大它們之間的誤差可以通過對二者彼此的復(fù)雜分析很好的被解釋。
CLARA的時間復(fù)雜度是O(k3+nk)可以說明CLARA的有一個很大消耗。但是對象個數(shù)的越多二者之間的誤差也就越小。總之,我們已經(jīng)有實驗表明CLARANS 比CLARA更有高效性。
4 結(jié)語
本文提出了一種基于隨機搜索的聚類算法稱為CLARANS,實驗部分說明了此方法的有效性,比現(xiàn)有的數(shù)據(jù)挖掘算法能快速有效的發(fā)現(xiàn)新的數(shù)據(jù),因此,CLARANS算法是一個非常有前途應(yīng)用的算法,在數(shù)據(jù)挖掘方面將會起到很大的作用。
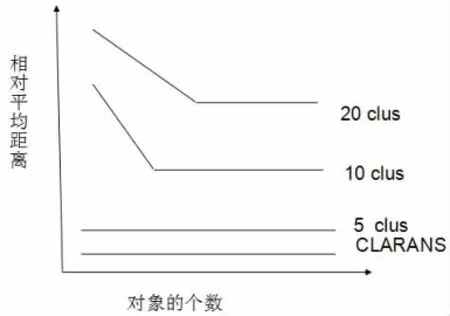
圖2 CLARA和CLARANS誤差比較
[1]周海燕.空間數(shù)據(jù)挖掘的研究[D].中國人民解放軍信息工程大學(xué),2003.
[2]王海起,王勁峰.空間數(shù)據(jù)挖掘技術(shù)研究進展[J].地理與地理信息科學(xué),2005,04:6-10.
[3]孫志偉,趙政.SOFM神經(jīng)網(wǎng)絡(luò)在處理非空間屬性中的應(yīng)用[J].計算機應(yīng)用,2006,11:2667-2669+2673.
[4]孫志偉,趙政.DBSCAN在非空間屬性處理上的擴展[J].計算機應(yīng)用,2005,06:1379-1381.
[5]吳文亮.聚類分析中K-均值與K-中心點算法的研究[D].華南理工大學(xué),2011.
[6]Tianhua Liu,Shoulin Yin.An Improved K-means Clustering Algorithm for Kalman Filter[J].ICIC Express Letters Part B:Applications,2015,6(10):2687-2692.
[7]徐金寶.核函數(shù)在劃分聚類中的應(yīng)用與實現(xiàn)[J].電腦知識與技術(shù),2013,27:6185-6188.
[8]殷守林,劉天華,李航.基于模擬退火算法的卡爾曼濾波在室內(nèi)定位中的應(yīng)用研究[J].沈陽師范大學(xué)學(xué)報(自然科學(xué)版),2015,01:86-90.
[9]李強,何衍,蔣靜坪.一種基于隨機游動的聚類算法[J].電子與信息學(xué)報,2009,03:523-526.
[10]陳東輝.基于目標(biāo)函數(shù)的模糊聚類算法關(guān)鍵技術(shù)研究[D].西安電子科技大學(xué),2012.
Spatial Data Mining;Partitioning Clustering Method;Random Search
Efficient and Effective Methods in Spatial Data Mining
HU Xin-yuan,YIN Shou-lin,LIU Jie
(Software College,Shenyang Normal University,Shenyang 110034)
1007-1423(2016)06-0015-04
10.3969/j.issn.1007-1423.2016.06.004
胡馨元(1990-),女,遼寧鐵嶺人,沈陽師范大學(xué)碩士研究生,研究方向為數(shù)據(jù)挖掘,企業(yè)信息化
殷守林(1990-),男,河南濮陽人,碩士研究生,研究方向為數(shù)據(jù)挖掘、網(wǎng)絡(luò)安全。E-mail:910675024@qq.com
劉杰(1966-),男,博士,教授,遼寧沈陽人,沈陽師范大學(xué)碩士研究生導(dǎo)師,研究方向為數(shù)據(jù)挖掘,軟件工程
2015-12-17
2016-02-15
空間數(shù)據(jù)挖掘可能隱式的存在于空間數(shù)據(jù)庫中。探索聚類方法是否對于空間數(shù)據(jù)挖掘有一定的幫助。為此,提出一種基于隨機搜索的新的聚類方法——分割聚類方法。使用分割聚類方法也研究出兩種空間數(shù)據(jù)挖掘算法。經(jīng)過分析與驗證,在分割聚類方法的幫助下,這兩種算法非常有效且會發(fā)現(xiàn)很難找到與當(dāng)前空間數(shù)據(jù)挖掘算法有重復(fù)之處。再者,分割聚類方法和那些存在的聚類方法相比較,實驗表明分割聚類方法具有高效性。
空間數(shù)據(jù)挖掘;分割聚類方法;隨機搜索
Spatial data mining may be the implicit existence in spatial database.Explores that whether the clustering method is useful for spatial data mining,proposes a new clustering method based on random search named partition clustering method.Using partition clustering method also develops two kinds of spatial data mining algorithms.After analysis and validation,with the help of the partition clustering method,the two kinds of algorithm is very effective and it is difficult to find same parts with the current spatial data mining algorithm. Moreover,compared with the existing clustering methods,experiment results of partition clustering method show that clustering segmentation method is very effective.
猜你喜歡
大眾投資指南(2021年35期)2021-02-16 01:06:26
兒童故事畫報(2019年5期)2019-05-26 14:26:14
電力與能源(2017年6期)2017-05-14 06:19:37
中國中醫(yī)藥信息雜志(2016年7期)2016-12-01 06:07:55
Coco薇(2016年2期)2016-03-22 02:42:52
信息通信技術(shù)(2015年6期)2015-12-26 01:16:46
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
河南科技(2014年23期)2014-02-27 14:18:43
