晉城礦區3號煤層深部含氣量預測
2016-09-23 05:11:53姜偉
科技與創新 2016年15期
姜偉
摘 要:為了探討深部煤層含氣量的有效預測方法,將支持向量機學習方法應用到了預測模型的建立中。以晉城礦區3號煤層為研究對象,以淺部煤層數據為基礎,建立了含氣量預測模型,并用煤層深部實測數據對模型進行了檢驗,精度可滿足生產需要,這為煤儲層深部含氣量預測提供了新思路。
關鍵詞:煤層深部含氣量;壓裂技術;建模樣本;Matlab
中圖分類號:P618.13 文獻標識碼:A DOI:10.15913/j.cnki.kjycx.2016.15.112
煤層含氣量是煤儲層評價的基本參數之一,是開發潛力評價、有利區預測和選擇開發方案重要依據。結合晉城礦區煤層氣井的生產實踐,當煤層埋深超過800 m時,受地應力的影響,壓裂縫延伸的長度和高度都受到了限制,壓裂效果大打折扣。隨著連續油管分段壓裂、滑套工具串分段壓裂等新型壓裂技術的成熟,壓裂改造能力有了很大的提高。在此情況下,人們開始關注后備區埋深大于800 m的區域,但由于前期深部測試樣品較少,且對深部煤層含氣量的分布規律認識不足,所以,對煤儲層深部含氣量的預測是非常重要的。
1 支持向量機學習法
支持向量機學習法是由Vapnik率先提出的,是基于統計學理論的一整機器學習方法。其基本思想是高維特征空間內的線性回歸,是從線性可分條件下的最優分類超平面發展而來的。給定建模樣本數據點集:
. (1)
式(1)中:xi為輸入變量;yi為目標變量。
通過機器學習,可找到一個非線性函數f(x)。此時,不僅應滿足yi=f(xi),且對于檢驗樣本集{xn+1,xn+2,…,xn+m}而言,其預測值誤差應在可接受的范圍內。在實際應用中,沒必要求得f(x)的解析表達式,只需要借助Matlab軟件的SVM工具箱即可。f(x)可通過核函數的選擇和相關參數的選取來確定。結合經驗選取合適的核函數后,應調節相關參數,直至預測精度令人滿意為止。
2 建立含氣量預測模型
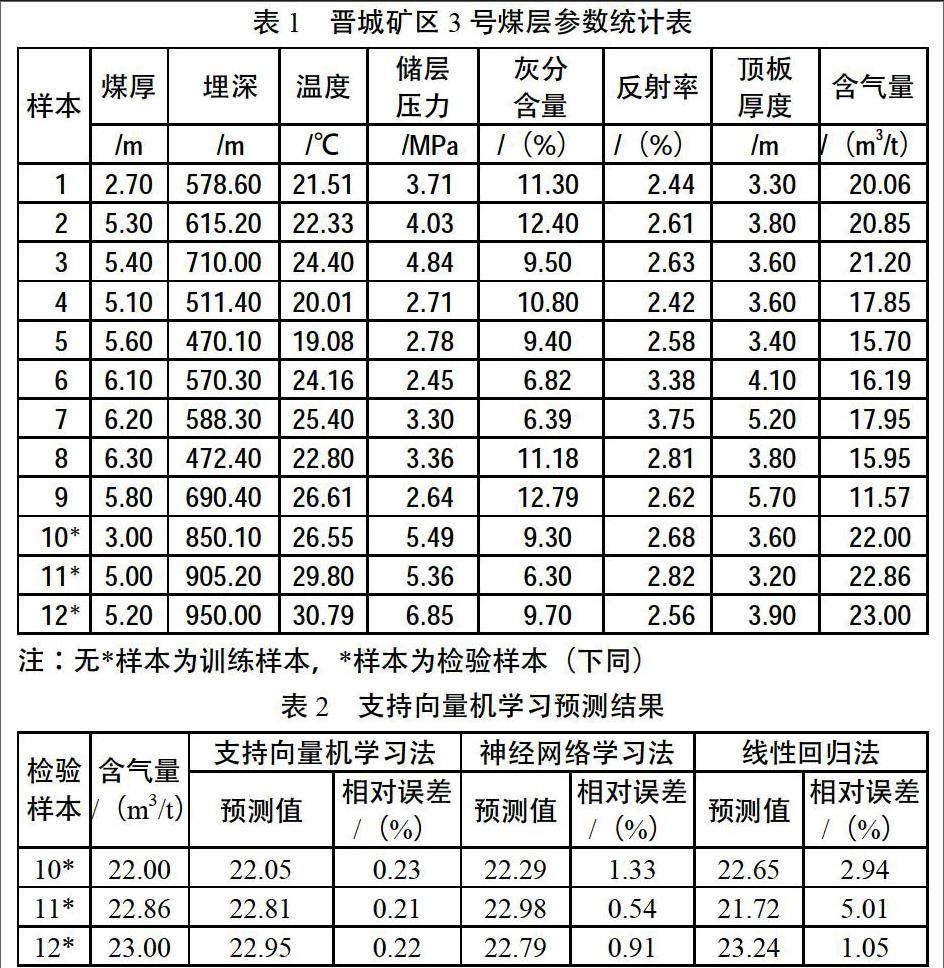
晉城礦區是19個首批煤炭國家規劃礦區之一,是我國重要的無煙煤生產基地,位于沁水盆地的東翼南端,隸屬于沁水煤層氣田。礦區主要煤系地層為二疊系下統山西組(P1s)和石炭系上統太原組(C3t),平均厚度為136.02 m。含煤15層,煤層總厚度為14.67 m,含煤系數為10.8%.3號煤層位于山西組中下部,上距K8砂巖約30 m,下距9號煤層48 m。煤厚4.45~8.75 m,平均厚度為6.31 m,含氣量為15.3~27.2 m3/t,為目前主要開采層位。為了對3號煤層深部含氣量進行預測,根據前期煤田勘探孔資料,選取了7個參數(煤層厚度、儲層溫度、鏡質組最大反射率、煤層灰分含量、儲層流體壓力、煤層埋藏深度、直接頂板厚度)作為影響煤儲層氣含量的因素進行數學建模。晉城礦區3號煤層的參數如表1所示。
以9個埋深小于800 m的數據樣本建立了預測模型,并以上述7個影響因素為預測模型的輸入變量,含氣量為輸出變量。在Matlab軟件的SVM工具中進行處理,通過多次模型參數試驗,最終核函數選用了徑向基核函數,不靈敏參數ε的值選擇為0.05,參數γ的值選擇為0.1,懲罰參數C的值選擇為10 000.應用3個埋深大于800 m的樣本對預測結果進行檢驗,以檢查預測精度是否滿足要求。預測值的絕對誤差小于0.05 m3/t,相對誤差小于3%.神經網絡和多元線性回歸為目前較為常用的含氣量預測方法。分別建立了3個隱藏層,建立了持續次數為500次的神經網絡模型和7元線性回歸模型。通過預測誤差的對比可以看出,支持向量機學習預測精度的方法優于其他兩種方法。其原因有2點:①數據樣本小。訓練樣本只有9個,神經網絡模型未經過充分的訓練,易陷入局部極值,②部分次要的輸入變量導致影響因素過于離散,最終使預測結果的精度降低。具體如表2所示。
3 結束語
綜上所述,模型預測精度法優于神經網絡法和線性回歸法,可支持向量機方法對小樣本、非線性、多因素數據的建模,為深部含量預測提供了新思路。因此,在煤層氣勘探程度較低的區域,可基于煤田鉆孔資料對煤儲層含氣性進行初步評價。
參考文獻
[1]連承波,趙永軍,漢林,等.煤層含氣量的主控因素及定量預測[J].煤炭學報,2005,30(06).
[2]方瑞明.支持向量機理論及其應用分析[M].北京:中國電力出版社,2007.
[3]孟召平,田永東,雷旸.煤層含氣量預測的BP神經網絡模型與應用[J].中國礦業大學學報,2008,37(04).
〔編輯:張思楠〕
