類標噪聲研究綜述
2016-09-23 05:51:42宋磊磊
現代計算機 2016年3期
宋磊磊
(四川大學計算機學院,成都 610065)
類標噪聲研究綜述
宋磊磊
(四川大學計算機學院,成都610065)
0 引言
文本分類被廣泛應用于信息檢索與其他知識管理系統中。一些常用的用于解決文本分類的有監督方法包括:樸素貝葉斯[1-2]、支持向量機[3-4]、K近鄰[5]和最大熵模型[6]。
文本分類任務需要大量的被正確標注的訓練數據集,這些標注數據集往往來自人工標注或者遠距離監督方法。然后,不管是人工還是自動的標注,都會不可避免地引入類標噪聲,對分類器的構建產生嚴重的影響。因此,研究有效地處理噪聲方法就變得十分重要。主流的方法主要分為兩種,第一種是去噪研究,即首先識別噪聲實例,進而直接刪除噪聲數據以保證數據的“純度”;第二種是容噪研究,與去噪算法不同的是,該思路假設噪聲實例同樣可以對分類器提供積極影響,前提是從模型的角度合理的挖掘其積極因素。
1 類標噪聲處理策略
1.1去噪算法研究
早期的類標噪聲處理思路主要集中在如何準確的識別出噪聲實例,借用的模型有最近鄰算法[7]、C4.5[8]、概率主題模型[9]和類別數據分布[10]。以下對前兩個方法進行介紹:
(1)最近鄰算法去噪
該方法利用最近鄰算法制定啟發式規則識別噪聲實例。總的數據集為T,包括n個實例P1…n,每個實例P 有K個最近的鄰居P.N1...k。P的“敵對”近鄰集P.E被定義為與P具有不同類標的最近實例。P.A1...a表示包括最近鄰集中包括P的實例的集合。那么,假如實例P被刪除時,P.A1...a中的實例被分類判斷正確,則說明實例P是噪聲數據,應該被去除。具體的算法如圖1所示。

圖1 最近鄰算法去噪
(2)C4.5去噪
該方法利用C4.5決策樹算法來進行噪聲識別,它的直觀假設是當我們獲得可靠的規則時,噪聲實例與正常實例表現出了不同的特點,通常噪聲實例會被可靠規則所覆蓋,但是卻產生錯誤的類標。基于以上的假設,該方法首先將整個數據集E分成若干個子集。對于每個子集,學習一個決策樹模型Ri并從中選擇可靠的規則集GRi,接著利用GRi評價整個數據集E。對于具體某個實例Ik,定義兩個錯誤計數變量和,它們共同決定改實例是否為噪聲數據。具體的框架流程如圖2所示。
1.2容噪算法研究
去噪算法存在著潛在的風險,特別是當模型錯誤的識別了噪聲數據,而把真正的噪聲實例保留下來作為標準訓練集時。可想而知,此時的去噪算法不但沒有達到清理噪聲的目的,而且還加劇了噪聲數據對分類模型的影響。因此,噪聲處理的重心開始向容噪研究方法轉移。其中,比較典型的容噪算法包括改進的支持向量機[11]、BayesANIL[12]和Probabilistic Kernel Fisher method[13]。以下介紹前兩個方法:
(1)改進的支持向量機
該方法在原有支持向量機的基礎上僅僅對核矩陣進行修改,達到了容忍噪聲的目的。我們知道,標準的SVM優化函數可以表示為:
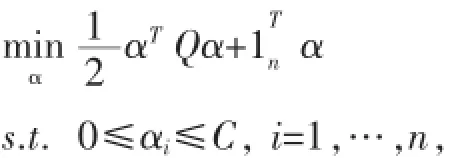
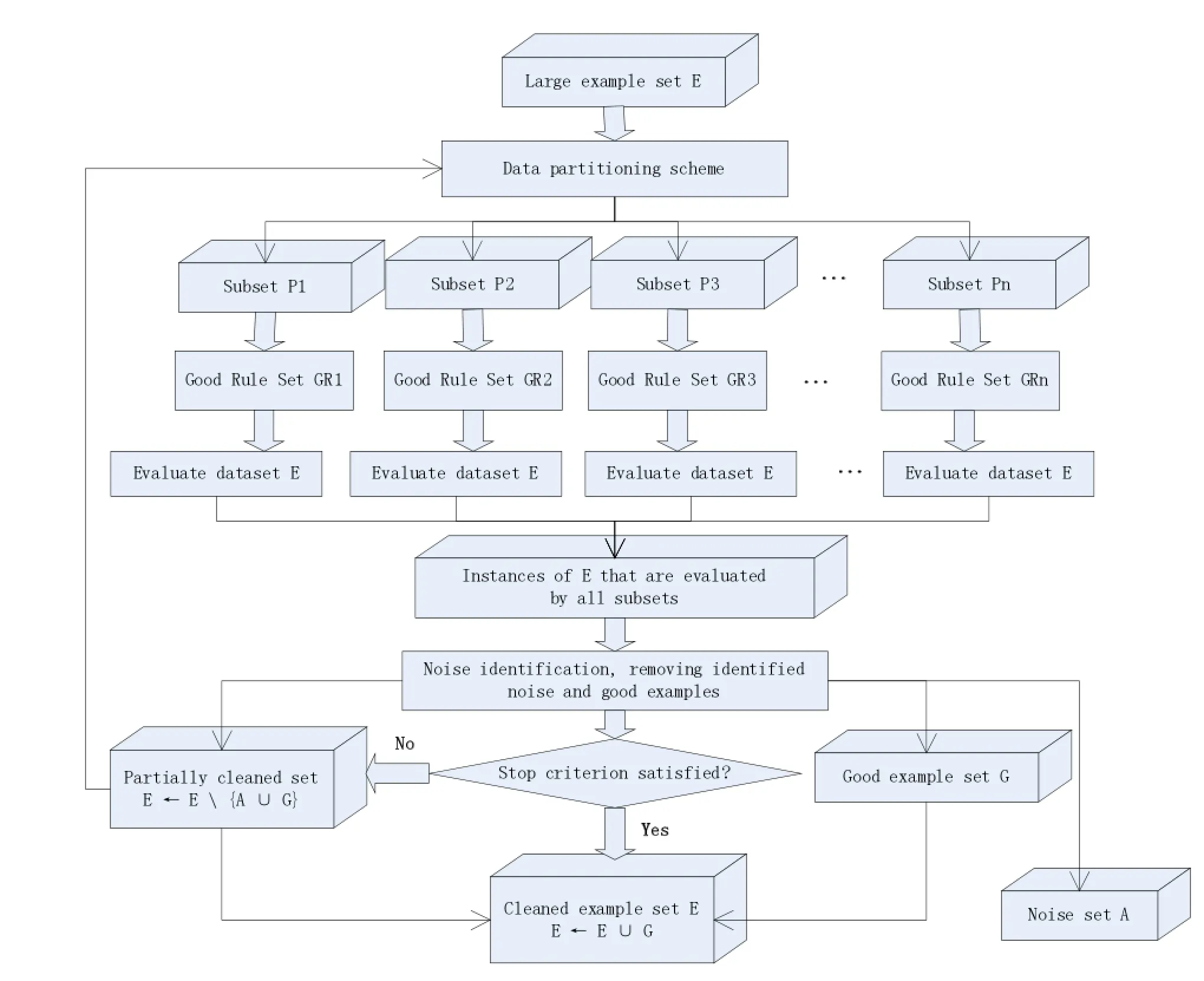
圖2 C4.5去噪
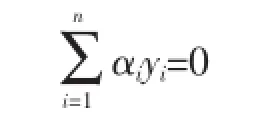
其中,Q=KoyyT,K為核矩陣。本文對每個實例xi引入了翻轉變量εi,從而使得Q發生變化,最終影響SVM的優化函數為如下所示:
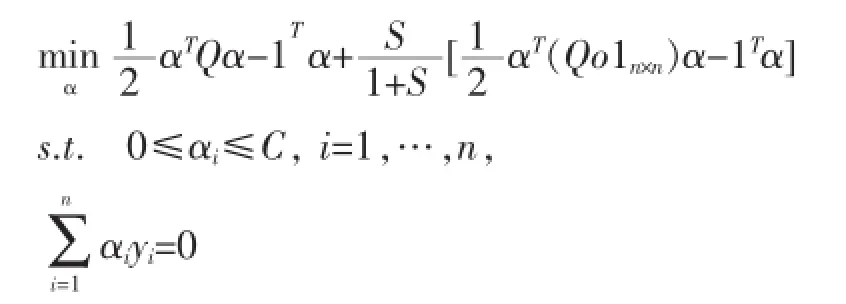
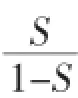
(2)BayesANIL
該方法對生成的角度對噪聲數據進行建模,模型可簡單表示成Z→D→W,三個變量分別表示實例類標、實例以及實例的詞袋子。其中P(w|d)與<d,z>為可觀測值,P(d,z)為潛在變量值,也是本文需要估計的變量值,該值可以直觀地理解為實例d在多大程度上屬于z類。因此,本文利用EM算法對潛在變量進行估計,最終將P(d,z)運用到樸素貝葉斯和支持向量機分類器中,取得了不錯的效果。
對于樸素貝葉斯分類器,關鍵在于估計詞在類別條件下的概率:
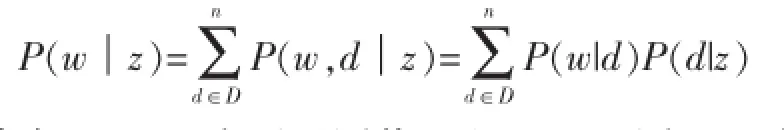
其中,P(w|d)為可觀測值,而P(d|z)可由EM估計的P(d,z)得到。此種方法的優勢還在于P(w|z)不需要平滑處理。
對于支持向量機分類器,我們可以改變每個實例的損失代價,讓那些值得信賴的類標數據盡量被判別正確,而對于那些潛在的噪聲數據設置一個較小的損失代價。形式化表示如下,Ci為損失代價。
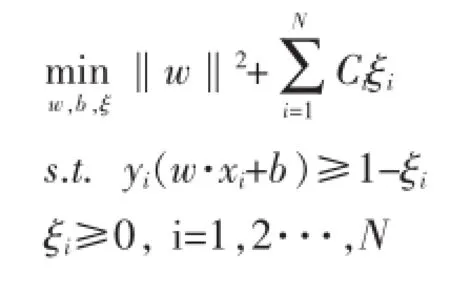
2 結語
隨著網絡數據量的爆炸式增長,如何利用大數據,從中挖掘出有價值的資源變得更加迫切。機器學習作為一種行之有效的方法在實際運用中需要大量的人工參與,例如為分類器標注大量的數據。而人工參與不可避免帶來數據噪聲,這是現有分類算法所不能容忍的。因此,大量的研究者開始設計不同的策略消除噪聲的影響。早期的研究主要關注如何正確識別噪聲實例。遺憾的是,去噪思路在實際運用中引入了潛在的風險,這才將研究的重心向容噪算法轉移。但即使同是容噪算法,在處理不同問題、噪聲水平不同時也表現不一。
[1]Lewis D D.Naive(Bayes)at Forty:The Independence Assumption in Information Retrieval[M].Machine Learning:ECML-98.Springer Berlin Heidelberg,1998:4-15.
[2]McCallum A,Nigam K.A Comparison of Event Models for Naive Bayes Text Classification[C].AAAI-98 Workshop on Learning for Text Categorization,1998,752:41-48.
[3]Joachims T.Text Categorization with Support Vector Machines:Learning with Many Relevant Features[M].Springer Berlin Heidelberg,1998.
[4]丁世飛,齊丙娟,譚紅艷.支持向量機理論與算法研究綜述[J].電子科技大學學報,2011,40(1):2-10.
[5]Yang Y.An Evaluation of Statistical Approaches to Text Categorization[J].Information Retrieval,1999,1(1-2):69-90.
[6]Nigam K,Lafferty J,McCallum A.Using Maximum Entropy for Text Classification[C].IJCAI-99 Workshop on Machine Learning forInformation Filtering,1999,1:61-67.
[7]Wilson D R,Martinez T R.Instance Pruning Techniques[C].ICML.1997,97:403-411.
[8]Zhu X,Wu X,Chen Q.Eliminating Class Noise in Large Datasets[C].ICML.2003,3:920-927.
[9]林洋港,陳恩紅.文本分類中基于概率主題模型的噪聲處理方法[J].計算機工程與科學,2010,32(7):89-92.
[10]李湘東,巴志超,黃莉.文本分類中基于類別數據分布特性的噪聲處理方法[J].現代圖書情報技術,2014,30(11):66-72.
[11]Biggio B,Nelson B,Laskov P.Support Vector Machines Under Adversarial Label Noise[C].ACML.2011:97-112.
[12]Ramakrishnan G,Chitrapura K P,Krishnapuram R,et al.A Model for Handling Approximate,Noisy or Incomplete Labeling in Text Classification[C].Proceedings of the 22nd International Conference on Machine Learning.ACM,2005:681-688.
[13]Li Y,Wessels L F A,de Ridder D,et al.Classification in the Presence of Class Noise Using a Probabilistic Kernel Fisher Method [J].Pattern Recognition,2007,40(12):3349-3357.
Class Label Noise;Denoising Algorithm;Robustness Algorithm
Research Overview of Class Label Noise
SONG-Lei-lei
(College of Computer Science,Sichuan University,Chengdu 610065)
1007-1423(2016)03-0020-04
10.3969/j.issn.1007-1423.2016.03.005
宋磊磊(1991-),男,貴州貴陽人,碩士研究生,研究方向為數據挖掘
2015-12-15
2016-01-10
在機器學習中,類標噪聲難以避免的存在于標注數據里,這樣的噪聲數據會對分類器等模型的建構產生嚴重的影響。因此,越來越多的研究者把類標噪聲算法研究作為分類器效果提升的一個突破口。針對解決問題思路的不同,提出并改進許多行之有效的噪聲處理模型。其中,按照解決思路的不同,可將噪聲處理算法分為去噪算法與容噪算法。
類標噪聲;去噪算法;容噪算法
In machine learning,the class label problem is unlikely to be completely excluded in labelled dataset which would deteriorate classifier construction.Therefore,most of researchers are focusing on this problem for more reliable classification algorithms.There are lots of effective approaches for the class label problem according to different solutions.We can divide them into denoising and robustness directions.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
科技傳播(2019年22期)2020-01-14 03:06:54
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
