大數(shù)據(jù)精準挖據(jù)處理架構(gòu)及預(yù)測模型研究
2016-10-14 06:44:27楊斐艾曉燕張永恒張峰
電子設(shè)計工程 2016年12期
關(guān)鍵詞:模型
楊斐,艾曉燕,張永恒,張峰
(榆林學(xué)院信息工程學(xué)院,陜西榆林719000)
大數(shù)據(jù)精準挖據(jù)處理架構(gòu)及預(yù)測模型研究
楊斐,艾曉燕,張永恒,張峰
(榆林學(xué)院信息工程學(xué)院,陜西榆林719000)
為了提高大數(shù)據(jù)的精準挖據(jù)與預(yù)測能力,解決傳統(tǒng)數(shù)據(jù)挖據(jù)技術(shù)無法適應(yīng)大數(shù)據(jù)處理環(huán)境的問題,利用云計算和大數(shù)據(jù)處理技術(shù),提出了大數(shù)據(jù)精準挖據(jù)處理架構(gòu)及基于BP神經(jīng)網(wǎng)絡(luò)的預(yù)測模型。重點研究了大數(shù)據(jù)處理平臺架構(gòu)、大數(shù)據(jù)分析與表達技術(shù)、基于BP神經(jīng)網(wǎng)絡(luò)的大數(shù)據(jù)挖據(jù)及預(yù)測模型。應(yīng)用結(jié)果表明,該方案結(jié)合云計算平臺和大數(shù)據(jù)挖掘技術(shù),能夠高效的處理海量數(shù)據(jù)的處理和表達,對于銷售數(shù)據(jù)具有一定的預(yù)測能力。
大數(shù)據(jù);數(shù)據(jù)挖據(jù);預(yù)測模型;BP神經(jīng)網(wǎng)絡(luò);銷售數(shù)據(jù)
隨著各種數(shù)據(jù)持續(xù)爆炸式地增長,出現(xiàn)了多源、異構(gòu)及海量的數(shù)據(jù),如果能夠應(yīng)用當前大數(shù)據(jù)處理技術(shù)來對這些數(shù)據(jù)進行挖據(jù),會產(chǎn)生具大的價值[1-2]。
大數(shù)據(jù)的挖據(jù)和分析當前企業(yè)對信息化的重要組成部分,在2011年第一季度,由Gartner公司的Merv Adrian在Teradata Magazine提出大數(shù)據(jù)的定義和應(yīng)用范圍,指出大數(shù)據(jù)是超出當前硬件處理和軟件系統(tǒng)處理能力。大數(shù)據(jù)的處理涉及數(shù)據(jù)的收集、存儲、處理及挖據(jù)和分析技術(shù)。但是大數(shù)據(jù)的多源、異構(gòu)和海量的特征,使得當前的數(shù)據(jù)分析與挖據(jù)方法很難適應(yīng)這種非結(jié)構(gòu)化的數(shù)據(jù)存儲模式[3-4]。
文中在分析大數(shù)據(jù)挖據(jù)需求的基礎(chǔ)上,提出大數(shù)據(jù)挖據(jù)的平臺架構(gòu)及利用BP神經(jīng)網(wǎng)絡(luò)方法進行對大數(shù)據(jù)進行精準挖據(jù)與預(yù)測。
1 大數(shù)據(jù)挖據(jù)技術(shù)框架研究
1.1大數(shù)據(jù)的特征
大數(shù)據(jù)分析相比于傳統(tǒng)的數(shù)據(jù)倉庫應(yīng)用,具有數(shù)據(jù)量大、查詢分析復(fù)雜等特點。大數(shù)據(jù)科學(xué)關(guān)注大數(shù)據(jù)網(wǎng)絡(luò)發(fā)展和運營過程中發(fā)現(xiàn)和驗證大數(shù)據(jù)的規(guī)律及其與自然和社會活動之間的關(guān)系[5]。大數(shù)據(jù)的特點有4個層面:第一,數(shù)據(jù)體量巨大。從TB級別躍升到PB級別。第二,流動速度快。第三,價值密度低,商業(yè)價值高。以視頻為例,連續(xù)監(jiān)控過程中,有用的數(shù)據(jù)僅僅有一兩秒。第四,數(shù)據(jù)種類繁多,如網(wǎng)絡(luò)日志、視頻、圖片、地理位置信息等。業(yè)界將其歸納為4個“V”--volume、velocity、value、variety[6]。物聯(lián)網(wǎng)、云計算、移動互聯(lián)網(wǎng)、車聯(lián)網(wǎng)、手機、平板電腦、PC以及遍布地球各個角落的各種各樣的傳感器,無一不是數(shù)據(jù)來源或者承載的方式。
1.2大數(shù)據(jù)挖據(jù)處理架構(gòu)
為了發(fā)掘并利用大數(shù)據(jù)背后隱含的巨大價值,必須對大數(shù)據(jù)進行有效地組合和管理。從結(jié)構(gòu)特征來講,大數(shù)據(jù)可以分為結(jié)構(gòu)化數(shù)據(jù)和非結(jié)構(gòu)化數(shù)據(jù)。對于結(jié)構(gòu)化數(shù)據(jù),如網(wǎng)絡(luò)上人工建立的知識庫,利用數(shù)據(jù)生成時的層次化對應(yīng)關(guān)系就能夠進行有效地查詢和管理,因而人們總是希望在數(shù)據(jù)生成時就按照特有的結(jié)構(gòu)和模式對數(shù)據(jù)進行整理。大數(shù)據(jù)計算的技術(shù)內(nèi)涵包含3個方面:處理海量數(shù)據(jù)的技術(shù)、處理多樣化類型的技術(shù)、提升數(shù)據(jù)生成與處理速度的技術(shù)。為了更好的精準挖據(jù)海量的數(shù)據(jù),本文結(jié)合當前流行的大數(shù)據(jù)處理技術(shù),設(shè)計了如圖1所示的大數(shù)據(jù)挖據(jù)技術(shù)框架。
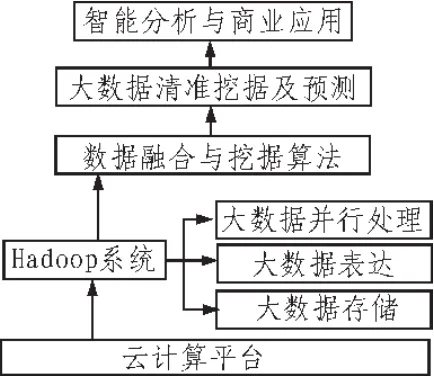
圖1 大數(shù)據(jù)挖據(jù)處理架構(gòu)
在圖1所示的大數(shù)據(jù)挖據(jù)平臺架構(gòu)中,底層處理平臺應(yīng)用目前成熟的云計算平臺架構(gòu),而在大數(shù)據(jù)處理技術(shù)方面,本文結(jié)合Hadoop處理平臺,對大數(shù)據(jù)進行清洗和管理。傳統(tǒng)的文件存儲系統(tǒng)已不能滿足大數(shù)據(jù)存儲的需求,大數(shù)據(jù)計算需要有特定的文件系統(tǒng)以滿足海量文件的存儲管理、海量大文件的分塊存儲等功能。
Hadoop分布式文件系統(tǒng)(Hadoop Distributed File System,HDFS)是Google GFS的一個高度容錯的分布式文件系統(tǒng),它能夠提供高吞吐量的數(shù)據(jù)訪問,適合存儲海量(PB級)的大文件。整個HDFS系統(tǒng)將由數(shù)百或數(shù)千個存儲著文件數(shù)據(jù)片斷的服務(wù)器組成。運行在HDFS之上的應(yīng)用程序必須流式地訪問它們的數(shù)據(jù)集,它不是典型的運行在常規(guī)的文件系統(tǒng)之上的常規(guī)程序。運行在HDFS之上的程序有很大量的數(shù)據(jù)集。這意味著典型的HDFS文件是GB到TB的大小,所以,HDFS是很好地支持大文件。HDFS體系架構(gòu)如圖2所示。
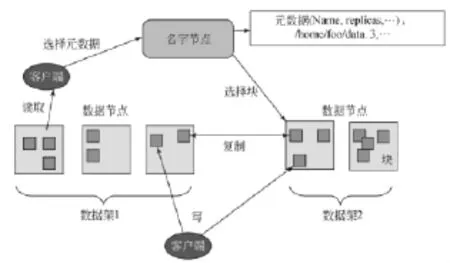
圖2 HDFS體系架構(gòu)
另一個大數(shù)據(jù)存儲技術(shù)就是GFS存儲技術(shù),GFS是一個大型的、對大量數(shù)據(jù)進行訪問的、可擴展的分布式文件系統(tǒng)。GFS具有實時監(jiān)測、容錯、自動恢復(fù)等特點。GFS能夠支持超大文件,每個文件通常包含很多應(yīng)用對象。當經(jīng)常要處理快速增長的、包含數(shù)以萬計的對象、長度達TB的數(shù)據(jù)集時,當處理這些超大超長文件集合時,GFS重新設(shè)計了文件塊的大小,使其能夠有效管理成千上萬KB規(guī)模的文件塊。GFS體系架構(gòu)如圖3所示。
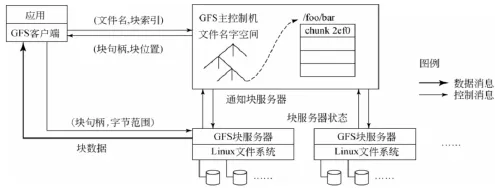
圖3 GFS體系架構(gòu)
在本文提出如圖1所示的大數(shù)據(jù)挖據(jù)平臺架構(gòu)中,除了大數(shù)據(jù)的存儲技術(shù)外,為了進一步分析大數(shù)據(jù)內(nèi)容,還需要實現(xiàn)大數(shù)據(jù)的表達技術(shù)。大數(shù)據(jù)的表達技術(shù)是指在大數(shù)據(jù)存儲基礎(chǔ)之上,對特定的不同類型結(jié)構(gòu)化數(shù)據(jù)進行表示。在大數(shù)據(jù)時代,NoSQL數(shù)據(jù)庫被大量采用。NoSQL指的是非關(guān)系型數(shù)據(jù)庫,是包含大量不同類型結(jié)構(gòu)化數(shù)據(jù)和非結(jié)構(gòu)化數(shù)據(jù)的數(shù)據(jù)存儲。由于數(shù)據(jù)多樣性,這些數(shù)據(jù)存儲并不是通過標準SQL進行訪問的[7]。NoSQL數(shù)據(jù)存儲方法的主要優(yōu)點是數(shù)據(jù)的可擴展性和可用性,以及數(shù)據(jù)存儲的靈活性。典型的NoSQL數(shù)據(jù)庫有Bigtable、HBase等。
BigTable是Google設(shè)計的用來處理海量數(shù)據(jù)的一種非關(guān)系型的數(shù)據(jù)庫。BigTable采用一個稀疏的、分布式的、持久化存儲的多維度排序圖來存儲數(shù)據(jù)。BigTable雖然不是關(guān)系型數(shù)據(jù)庫,但是卻沿用了很多關(guān)系型數(shù)據(jù)庫的術(shù)語,像表(Table)、行(Row)、列(Column)等。BigTable的鍵有三維,分別是行鍵(Row Key)、列鍵(Column Key)和時間戳(Timestamp)[8]。
HBase是一個高可靠性、高性能、面向列、可伸縮的分布式存儲系統(tǒng),利用HBase技術(shù)可在廉價PC Server上搭建起大規(guī)模結(jié)構(gòu)化存儲集群。HBase是Google Bigtable的開源實現(xiàn),類似Google Bigtable利用GFS作為其文件存儲系統(tǒng),HBase利用Hadoop HDFS作為其文件存儲系統(tǒng)。
HBase的數(shù)據(jù)模型如表1所示。
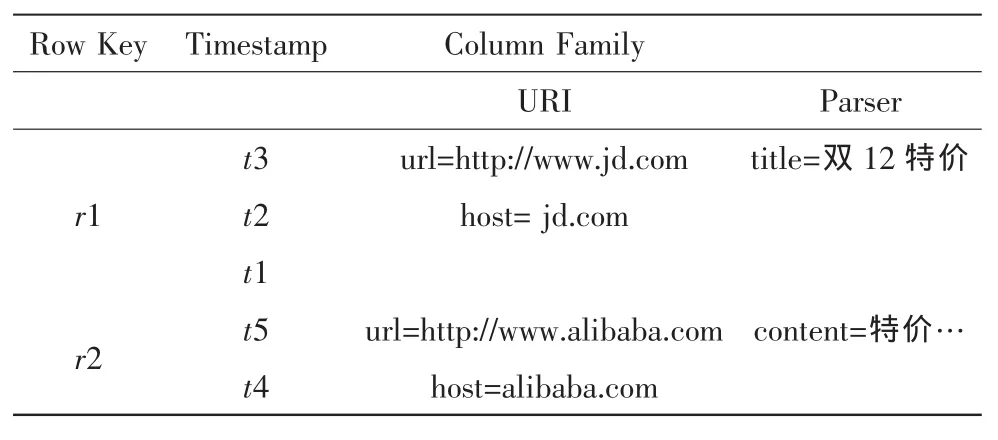
表1 HBase的數(shù)據(jù)模型
在大數(shù)據(jù)并行處理技術(shù)方面,目前使用MapReduce模型來實現(xiàn)。MapReduce任務(wù)的執(zhí)行流程對用戶是透明的。當用戶程序調(diào)用MapReduce函數(shù),就會引起如下操作,Map Reduce執(zhí)行流程如圖4所示。
從MapReduce的任務(wù)執(zhí)行流程可以看出系統(tǒng)框架將大規(guī)模的計算任務(wù)進行劃分然后將多個子任務(wù)指派到多臺工作機器上并行執(zhí)行,從而實現(xiàn)了計算任務(wù)的并行化,進而可以進行大規(guī)模數(shù)據(jù)的處理。
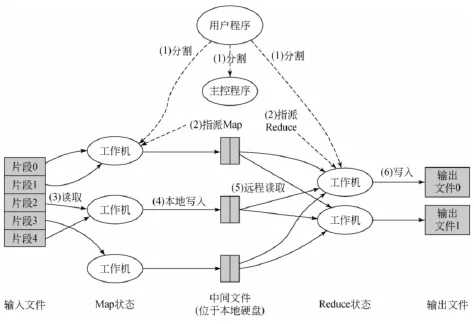
圖4 MapReduce執(zhí)行流程圖
2 基于人工神經(jīng)網(wǎng)絡(luò)的大數(shù)據(jù)挖據(jù)與預(yù)測模型
2.1人工神經(jīng)網(wǎng)絡(luò)方法分析
人工神經(jīng)網(wǎng)絡(luò)對人類神經(jīng)系統(tǒng)的一種模擬,是指由簡單計算單元組成的廣泛并行互聯(lián)的網(wǎng)絡(luò),能模擬生物神經(jīng)系統(tǒng)的結(jié)構(gòu)和功能。組成神經(jīng)網(wǎng)絡(luò)的單個神經(jīng)元的結(jié)構(gòu)簡單、功能有限,但是,由大量神經(jīng)元構(gòu)成的網(wǎng)絡(luò)系統(tǒng)可實現(xiàn)強大的功能。盡管人類神經(jīng)系統(tǒng)規(guī)模宏大、結(jié)構(gòu)復(fù)雜、功能神奇。但其最基本的處理單元卻只有神經(jīng)元。人類神經(jīng)系統(tǒng)的功能實際上是通過大量生物神經(jīng)元的廣泛互聯(lián),以規(guī)模宏大的并行運算來實現(xiàn)的。構(gòu)成人工神經(jīng)網(wǎng)絡(luò)的基本單元是人工神經(jīng)元。并且,人工神經(jīng)元的不同結(jié)構(gòu)和模型會對人工神經(jīng)網(wǎng)絡(luò)產(chǎn)生一定的影響。人工神經(jīng)元是對生物神經(jīng)元的抽象和模擬。所謂抽象是從數(shù)學(xué)角度而言的,所謂模擬是從其結(jié)構(gòu)和功能角度而言的[9]。1934年心理學(xué)家麥卡洛克和數(shù)理邏輯學(xué)家皮茨根據(jù)生物神經(jīng)元的功能和結(jié)構(gòu),提出了一個將神經(jīng)元看成二進制閾值元件的簡單模型,即MP模型,如圖5所示。
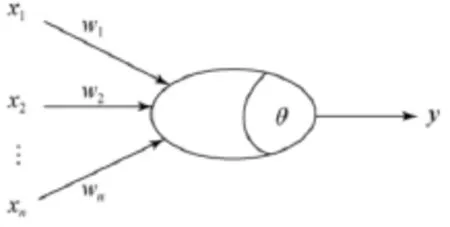
圖5 MP神經(jīng)元模型
在圖5中,x1,x2,…,xn表示某一神經(jīng)元的n個輸入;ωi表示表示第i個輸入的聯(lián)結(jié)強度,也稱為聯(lián)結(jié)權(quán)值;θ為神經(jīng)元的閾值;y為為神經(jīng)元的輸出。可以看出,人工神經(jīng)元是一個具有多輸入,單輸出的非線性器件。它的輸入為
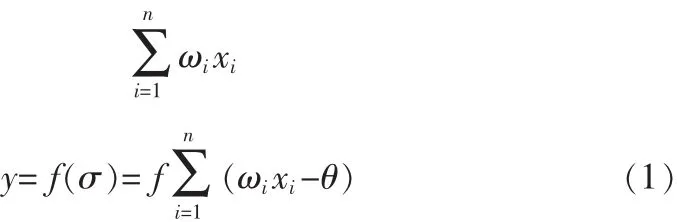
式中,f稱為神經(jīng)元功能函數(shù),也稱作用函數(shù)或激勵函數(shù);θ稱為激活值。
在BP神經(jīng)網(wǎng)絡(luò)中,輸入向量為設(shè)為X=(x1,x2,…,xn),輸出向量設(shè)為Y=(y1,y2,…,ym),輸入層各個輸入到相應(yīng)神經(jīng)元的聯(lián)結(jié)權(quán)值設(shè)為ωij(i=1,2,…,n;j=1,2,…,m)。若假設(shè)各神經(jīng)元的閾值分別是θj(j=1,2,…,m),則各神經(jīng)元的輸出yi(j= 1,2,…,m)分別為
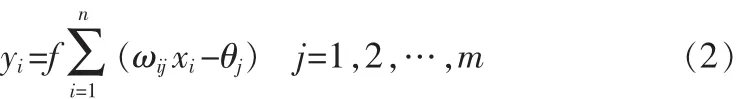
式中,由所有聯(lián)結(jié)權(quán)值ωij構(gòu)成的聯(lián)結(jié)權(quán)值矩陣W為
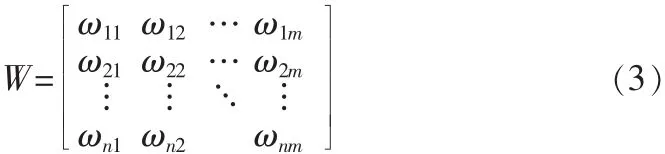
在實際應(yīng)用中,該矩陣是通過大量的訓(xùn)練示例學(xué)習(xí)而形成的。
2.2基于BP神經(jīng)網(wǎng)絡(luò)的庫存銷售預(yù)測
本文實驗使用某電子商務(wù)網(wǎng)站庫存銷售數(shù)據(jù)為預(yù)測值,資料取10年共10萬多組數(shù)據(jù)。實驗數(shù)據(jù)在經(jīng)過大數(shù)據(jù)處理后,形成結(jié)構(gòu)化數(shù)據(jù),部分仿真實驗在MATLAB2012a中實驗。對應(yīng)的資料數(shù)據(jù)項主要包括倉庫名稱、營業(yè)額、員工人數(shù)、利潤和規(guī)模等.對所有的數(shù)據(jù)使用前需要歸一化處理。數(shù)據(jù)歸一化到[-1,1]區(qū)間的公式為:

式中,xn和x表示歸一化前后的序列值;xmax和xmin分別表示原序列x的最大值和最小值。反歸一化公式為
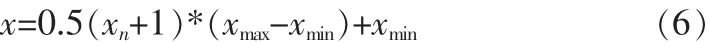
本文使用如下幾個統(tǒng)計量評價預(yù)測模型的預(yù)測精度:
1)平均絕對誤差
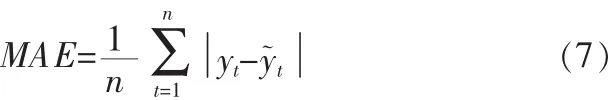
2)平均相對誤差
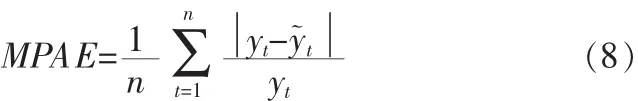
把前5年51 000組歷史數(shù)據(jù)作為訓(xùn)練樣本,每組數(shù)據(jù)包括20個預(yù)測因子和一個原始銷售序列值。把后5年共49000組數(shù)據(jù)作為測試樣本,每組數(shù)據(jù)包括20個輸入因子,對每天的銷售的數(shù)據(jù)值進行預(yù)測。
通過多次試驗,最終確定的BP神經(jīng)網(wǎng)絡(luò)的參數(shù)選擇為:系數(shù)0.65,訓(xùn)練目標0.002,隱層最大神經(jīng)元數(shù)600,最后測試數(shù)據(jù)的真實值和預(yù)測值對比圖如圖6所示。
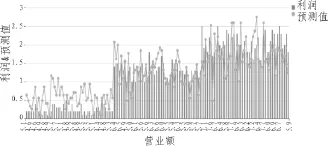
圖6 神經(jīng)網(wǎng)絡(luò)模型真實值與預(yù)測值對比圖
經(jīng)過計算,BP神經(jīng)網(wǎng)絡(luò)的預(yù)測精度指標分別為:MAE= 0.021 2,MPAE=22.32%。從曲線圖和統(tǒng)計指標來看,BP神經(jīng)網(wǎng)絡(luò)模型對于銷售序列預(yù)測具有一定的預(yù)測能力,但是預(yù)測的泛化能力還有待提高。
3 結(jié)論
文中以大數(shù)據(jù)處理與挖據(jù)平臺架構(gòu)為出發(fā)點,研究大數(shù)據(jù)精準挖據(jù)與預(yù)測的技術(shù)與模型。分析了某電子商務(wù)網(wǎng)站庫存銷售數(shù)據(jù),資料取10年共10萬多組數(shù)據(jù)并利用Hadoop技術(shù)平臺,應(yīng)用MapReduce對數(shù)據(jù)進行處理分析,然后應(yīng)用BP神經(jīng)網(wǎng)絡(luò)對數(shù)據(jù)進行了挖據(jù)和預(yù)測處理。
[1]戴禮燦.大數(shù)據(jù)檢索及其在圖像標注與重構(gòu)中的應(yīng)用[D].合肥:中國科學(xué)技術(shù)大學(xué),2013:20-50.
[2]Katiuscia Sacco,Valetina Galletto,Enrico Blanzieri.How has the 9/11 terrorist attack influenced decision making[J]. Applied Cognitive Psychology,2002(9):1113-1127.
[3]Sarafidis Y.What have you done for me lately Release of information and strategic manipulation of memories[J].The Economic Journal,2007,117(3):307-326.
[4]Heyn T,Mazhar H,Seidl A,et al.Enabling computational dynamics in distributed computing environments using a heterogeneous computing template[C].ASME 2011 International Design Engineering Technical Conferences and Computers and Information in Engineering Conference,2012(8): 227-236.
[5]陳芳.云計算架構(gòu)下云政府模式研究[D].武漢:武漢大學(xué),2012.
[6]Howe D,Costanzo M,F(xiàn)ey P,et al.Big data:the future of biocuration[J].2008(9):47-50.
[7]Zhang Feng,Xue Hui-Feng.Big data cleaning algorithms in cloud computing[J].International Journal of Online Engineering,2013,9(3):77-81.
[8]LI Zhong-tao,Weis T.Using zone code to manage a contentaddressable network for distributed simula-tions[C]//Proceedings of 2012 IEEE 14th International Conference on Communication Technology:[s.n.],2012:1350-1358.
[9]Wang Feng,Qiu Jie,Yang Jie,et al.Hadoop high availability through metadata replication[C]//Proceeding of the First International Workshop on Cloud Data Management:[s.n.],2009:37-44.
New mining architecture and prediction model for big data
YANG Fei,AI Xiao-yan,ZHANG Yong-heng,ZHANG Feng
(School of Information Engineering,Yulin University,Yulin 719000,China)
In order to improve the accuracy of big data mining and forecasting ability,to solve the traditional data mining technology cannot adapt to big data processing environment problem,using of cloud services and big data processing technology,a new mining architecture and forecast model for big data model based on BP neural network is proposed.The structure of big data processing platform,big data analysis and expression technology and big data mining and prediction model based on BP neural network is designed.Application results show that the scheme combining cloud service platform and big data mining technology can effectively dealing with massive data processing and expression has a certain predictive ability for the sales data.
big data;data mining;prediction model;BP neural network;sales data
TN391
A
1674-6236(2016)12-0029-04
2015-07-08稿件編號:201507072
榆林學(xué)院科研項目(14YK38),榆林市科技計劃項目(2014cxy-09)
楊斐(1982—),男,陜西榆林人,講師。研究方向:復(fù)雜系統(tǒng)理論與建模,管理系統(tǒng)工程。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網(wǎng)絡(luò)安全與數(shù)據(jù)管理(2022年1期)2022-08-29 03:15:20
導(dǎo)航定位學(xué)報(2022年4期)2022-08-15 08:27:00
中學(xué)生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數(shù)學(xué)備考)(2021年9期)2021-11-24 01:14:36
成都醫(yī)學(xué)院學(xué)報(2021年2期)2021-07-19 08:35:14
新世紀智能(數(shù)學(xué)備考)(2020年9期)2021-01-04 00:25:14
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
