分布式系統數據時序更新方法
2016-10-21 16:08:10于興平李洪建于騰飛畢衛紅
軟件工程 2016年5期
關鍵詞:數據庫
于興平 李洪建 于騰飛 畢衛紅
摘 要:隨著科學技術的發展,計算機分布式系統在維持數據庫的一致性的問題上廣泛應用。在商用系統中,通常在數據中大量的數據需要經常更新,并且現在流行不間斷服務,有必要為用戶提供在線交易并行一次性更新服務。針對當前對大量數據更新效率不高的問題,提出了一種分布式系統中大批量數據時序更新方法,通過時序更新的方法避免一次性更新和在線事務之間的沖突,先在本地交易執行,然后一次提交聯合數據庫,減少了交易時間的占用,有著更高的處理效率。實驗證明這種在分布式系統中更新數據方法與分批處理方法相比,數據更新執行時間,在每1000次更新執行時間會減少為原來的1/80,有很高的應用價值。
關鍵詞:數據庫;分布式系統;批量處理;分布式事務
中圖分類號:TP399 文獻標識碼:A
Abstract:With the development of science and technology,distributed systems are extensively applied in maintaining database consistency.In business systems,mass data need to be updated frequently.Since non-stop service is growing in popularity,it is quite necessary to provide online transaction service with once-and-for-all update to users.To deal with the low update efficiency of mass data,the paper proposes a time-sequence update method of mass data in distributed systems,which can effectively avoid the conflict between the once-and-for-all update and the online transactions.The transactions will be firstly conducted locally before submitting the joint database,which reduces the occupation time of transactions and brings higher processing efficiency.Experiments show that,through the method of updating data in distributed systems(compared with the batch processing method),the execution time can be reduced by 1/80 in every 1000 updates.
Keywords:database;distributed systems;batch processing;distributed transaction
1 引言(Introduction)
隨著計算機網絡的日益發展和商業系統的跨地域分布使得數據存儲和應用變得愈加分布化,分布式數據庫技術對比傳統的集中式數據庫技術在可靠性、可用性和時間響應方面有著更多的優越性,因此在實際中得到了廣泛應用[1]。國內外專家和學者一直致力于基于分布式數據庫的數據更新問題的研究,如增量式更新算法[2],其原理是在原有規則的基礎上,去除那些不滿足條件的舊規則,發現滿足條件的新規則,目的是盡量減少計算量[3];基于并行分層式鏈路分布式數據更新方法[4],其原理是通過建立了并行分層式鏈路,具有鏈路分層的同時又有補償的并行鏈路,采用投票法“一票多次性否決”規則,解決在訪問分布式數據庫情況下網絡開銷過大、數據庫互聯復雜、數據更新時保證一致性困難等問題[5]。但是由于上述算法的復雜性,因此本文提出了時序更新大批量數據的方法。此方法使用擴展的交易時間數據庫來避免一次性更新數據的進程和用戶在線事務之間的沖突。
2 分布式系統更新方法及其相關研究(Distributed system update method and its related research)
2.1 在分布式系統中傳統的更新方法
通過分布式事務更新處理分支機構的多個數據庫的數據,這種交易系統一般具有兩階段提交的功能[6],即準備階段和提交階段[7],對比一階段提交,即從應用程序向數據庫發出提交請求到數據庫完成提交后直接將結果返回給應用程序,兩階段提交雖然在執行同樣的事務時會消耗更多時間[8],但是這種操作在一個分布式系統中的穩定性比較高,這對于分布式系統是十分重要的。
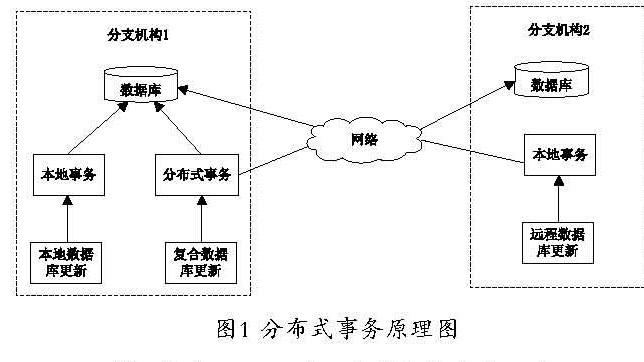
典型的分布式交易系統如圖1所示,數據庫的每一個分支機構儲存當前分支機構的數據,用戶通過分布式網絡更新當前機構和其他機構的數據,將獨立數據庫更新交易定義為本地交易[9]。分布式系統下的數據庫管理系統中,當有一個進程從一個機構移動一個數據塊到另外的機構,這個數據塊的分布式事務的操作同時執行,當一個數據庫中數據減少時,另外一些機構數據庫中會相應的增加了相應的數據,整個系統保持數據量的完整性[10]。
2.2 數據更新研究
本文提出的通過分時更新的方法實現大量分布式數據的更新,其更新列表和交易處理時間數據庫表關系Rt如式(1)所示。
式(1)中Ta表示數據庫中的數據添加時間;Td表示數據庫中的數據刪除時間;K表示主鍵;A顯示的其他屬性。
當數據刪除時,通過設置數據邏輯刪除,刪除時從左開始記錄。在事務處理時,在時間t設置的數據用Q(t)表示,如式(2)所示。
式(2)中,屬性q[Ta]表示q數據庫數據增加的時間,屬性q[Td]表示q數據庫數據刪除的時間,隨著時間的改變而改變,Q(t)如式(2)所示,為兩條件的交集。
分時更新大量數據方法原理圖如圖2所示,按時間序列數據庫更新后的數據的變化如下:首先,批量數據更新查詢過去更新時間tq的數據,并且存儲它更新后的結果到未來時間tu。其次,在線登記與批量數據更新同時執行,更新當前時間的數據。由于時間不同,批量數據更新和在線事務處理之間沒有沖突,本文方法進行一次性更新,既使用了批處理更新又使用了OB更新。本文的目標表的關系Rt擴展為Re表示,如式(3)所示。
添加的Re的屬性如下所示。
(1)Tp:更新數據的處理順序的時間。
(2)P:過程類。這表明更新數據的過程,包括OB更新、在線登記和批處理更新。
(3)D:刪除標志,表示查詢的數據是否是刪除的對象,它的邏輯值集為{真,假}。
3 分布式系統中數據更新(Update the data in the distributed system)
當使用在線批量更新時,如果執行完全成功,更新有效,如果執行失敗,則會恢復更新前的狀態。對于此項操作,本文添加了下面的批處理更新管理表。如圖3所示,在每個分之機構的數據庫中,數據庫管理表是業務和Re的關系表,表的右側是相應的Re的屬性。
(1)提交時間表(d0t_commit):它儲存時間b的更新,當批處理更新和OB更新使得每個目標表開始有效的時候。它儲存了圖2中的時間tu,當批處理更新完成的時候設置tu,如果失敗,則不會設置時間tu,而且這些更新結果在批處理更新估計完成時間內不會被查詢。
(2)批處理管理表(d0t_batch):它儲存三種時間類型去控制為每個目標的批處理更新,包括批處理進程的開始時間q、查詢時間tq和更新時間b,更新時間與目標委托時間表同時更新,當暫時更新開始時,在處理進程之前建立更新時間。
(3)掩碼數據表(d0t_mask):批處理更新時,向批處理更新的目標數據表存儲在線輸入的主鍵t,與Rt中的K進行通信,管理在線輸入的狀態。
4 實驗及評估(The experiment and evaluation)
為了評估在分布式系統中測試更新的效率,本文通過實驗建立的分支機構的數據庫聯動數據,在分布式環境中通過兩臺服務器建立一個本地服務器和一個遠程服務器,采用兩臺服務器來模擬兩個數據中心,構建測試所需的網絡分布式環境。
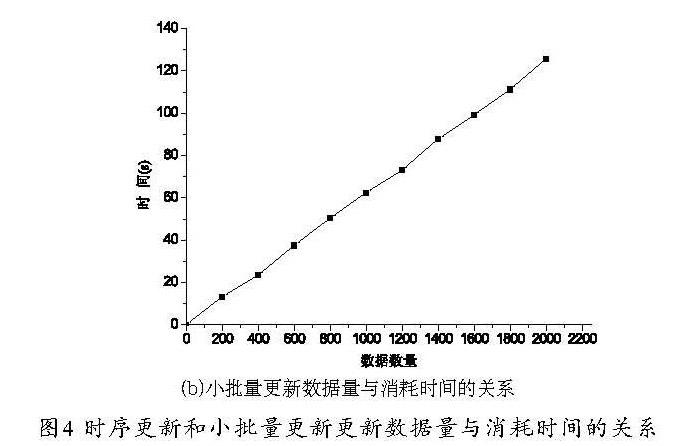
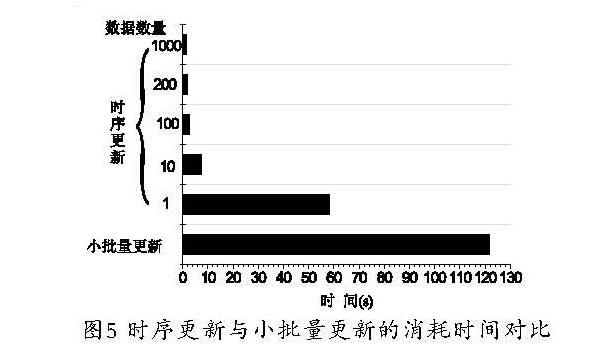
使用MySQL創建數據庫,InnoDB作為存儲引擎,使用JDBC來訪問MySQL。創建虛擬的大批量股票數據為分析對象,每只股票的數據量為5萬條數據,如表2所示,在實驗中在數據庫管理列表中移動了2 000只股票一年的交易信息的數據庫數據,遠程服務器開始時存儲10 000只的數據庫,如圖5所示的時序進行數據處理,并對本文方法與小批量數據更新方法進行對比分析。
5 實驗驗證(Experimental verification)
利用時序更新方法的數據更新試驗中,每增加200只股票的數據進行一次實驗,得到如圖4(a)所示的實驗結果,同樣小批量更新,每增加200只股票的數據進行一次實驗,得到如圖4(b)所示的實驗結果,對于時序更新方法,更新消耗的時間會隨著每次更新登記數量的改變而變化,如圖6所示,在時序更新中登記提交1 000只股票的數據量的更新的效率超過小批量更新的80倍。
如圖5所示,本文提出的時序更新方法僅在后處理過程中需要使用分發式事務,這個批處理更新的過程可以被靈活的完成,在更新效率方面是高效的,在系統方面是的高效的和安全的。
6 結論(Conclusion)
隨著互聯網和分布式處理技術的發展,商業系統中的分布式和一站式服務得到廣泛的應用,大型商業系統中經常需要進行大批量數據更新。本文在分布式系統中運用了時序更新的方法,在建立更新表前進行預處理,插入一個記錄到每一個批處理管理表,通過記錄時間序列來避免一次性更新和在線服務之間的沖突,實驗證明這種在分布式系統中更新數據方法與分批處理方法相比,數據更新執行時間,在每1 000次更新執行時間會減少為原來的1/80,與傳統的小批量更新方法相比,本文的方法具有更高的效率,安全可靠性也得到一定增強。
參考文獻(References)
[1] 王習特,等.BOD:一種高效的分布式離群點檢測算法[J].計算機學報,2016,39(1):36-51.
[2] 秦秀磊,張文博,魏峻.云計算環境下分布式緩存技術的現狀與挑戰[J].軟件學報,2013,24(1):50-66.
[3] Qingliang,et al.A complete coalition logic of temporal knowledge for multi-agent systems[J].Frontiers of Computer Science,2015,9(1):75-86.
[4] 于彥偉,等.時空軌跡大數據分布式蜂群模式挖掘算法[J].計算機工程與科學,2016,38(2):255-262.
[5] 郭昆,等.NoSQL數據庫間數據交換代價研究[J].計算機工程與科學,2016,38(1):33-40.
[6] 朱保鋒,蘇小玲.大型網絡異常數據庫的快速數據定位模型仿真[J].微電子學與計算機,2016(2):140-143.
[7] 錢曉軍,范冬萍,吉根林.物聯網差異數據庫中的故障數據快速挖掘仿真[J].計算機仿真,2016(1):301-304.
[8] 朱明,李躍新.流數據環境下基于k集合覆蓋的分布式標簽共現算法[J].計算機應用研究,2016(2):428-430.
[9] 張曉琳,等.一種分層自適應快速K-means算法[J].計算機應用研究,2016(2):421-423.
作者簡介:
于興平(1982-),女,本科,講師.研究領域:分布式系統,分布智能.
李洪建(1979-),男,本科,講師.研究領域:計算機教育教學,分布式系統.
于騰飛(1987-),男,碩士生.研究領域:分布式系統,大數據.
畢衛紅(1960-),女,博士,教授.研究領域:分布式系統,數融合.
猜你喜歡
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
華東師范大學學報(自然科學版)(2017年1期)2017-02-27 13:41:08
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
財經(2015年3期)2015-06-09 17:41:31
財經(2014年21期)2014-08-18 01:50:18
財經(2014年6期)2014-03-12 08:28:19
財經(2013年6期)2013-04-29 17:59:30
