基于OPM的數據依賴關系分析研究
2016-10-22 06:54:08董宇超張文生
微型電腦應用 2016年6期
董宇超,張文生
基于OPM的數據依賴關系分析研究
董宇超,張文生
如何對數據起源語義信息進行分析是數據起源追蹤領域的關鍵問題之一。基于OPM,在建立的數據起源依賴關系概念及其操作的基礎上,提出了一種數據依賴關系分析方法,利用細化操作和合成操作分析數據依賴關系,并具體給出數據依賴細化算法和合成算法。實驗表明,提出的方法,具有完備的語義和多項式級別的算法復雜度,存儲耗費也有所降低,可以滿足不同用戶對于不同抽象層次數據起源信息查詢的需求,很好地提高了數據起源追蹤的有效性和針對性。
數據依賴關系;數據起源;細化操作;合成操作;數據起源開放模型
0 引言
近幾年,隨著大數據管理的迫切需要,數據起源追蹤[1][2][3][4]成為嶄新的國內外研究熱點。數據起源又稱為數據血統、數據世系、數據溯源、數據譜系、數據血緣和數據來源等,是對數據處理的整個歷史的信息,包括數據產生和隨著時間推移而演變的整個過程。在抽象級別上,起源是一種依賴關系,描述數據產品是如何得到的,相關的數據和過程的作用是什么,角色是什么。
目前,數據起源依賴關系分析的主流模型之一為OPM(The Open Provenance Model)[5][6],OPM是數據起源開放模型,支持各種起源技術的互操作。OPM 基于有向無環圖,表示數據產品和計算中關聯的過程,以及他們之間的因果依賴關系。
通過OPM能夠得到數據和數據的因果依賴關系,但是不同的用戶想要看到的因果依賴關系是不同的,有的想看全局的概貌,有的想看局部的細節。為此,本文基于OPM,對數據起源中數據依賴關系進行深入分析,引入細化和合成操作,提出一種數據起源中數據依賴的分析方法,完成數據依賴關系在全局和不同層次的局部之間靈活轉換,形成不同的依賴關系視圖,滿足不同用戶對于不同抽象層次數據起源信息查詢的需求。具體貢獻包括:
(1)為了有效支撐數據依賴關系分析,針對數據依賴存在的不同情況,定義數據依賴、部分數據依賴、完全數據依賴等。在此基礎上,定義數據依賴的細化和合成操作,并進一步根據部分數據依賴、完全數據依賴分別深入定義,完成通過數據依賴關系分析生成用戶視圖的基礎體系;
(2)為了實現數據依賴從概貌到細節的轉化,針對部分數據依賴、完全數據依賴不同情況,提出數據依賴的細化規則,并給出具體細化算法,形成數據依賴關系從抽象到具體的分析;
(3)為了實現數據依賴從細節到概貌的轉化,針對部分數據依賴、完全數據依賴不同情況,提出數據依賴的合成規則,并給出具體合成算法,形成數據依賴關系從具體到抽象的分析;
(4)從語義完備性、存儲耗費、提出算法復雜度三個方面,與直接使用OPM進行數據依賴分析進行對比,說明提出的分析方法具有優勢。
1 數據依賴關系定義及操作
數據起源依賴關系在本質上是數據起源的語義信息,本文在前期研究中提出的數據起源追蹤架構下[7],基于OPM關于因果關系定義的基礎上,給出數據起源依賴關系和數據依賴關系定義,然后,具體定義了數據依賴關系的細化和合成操作。
1.1數據依賴關系
定義1 數據起源依賴關系 定義為一個6元組
DP_Dependency=(Data_Set,Process_Set,
Data_Data_Dependency,Data_Process_Dependency,
Process_Data_Dependency,
Process _Process_Dependency),其中
(1)Data_Set是數據的集合;
(2)Process_Set是過程的集合;
(3)Data_Data_Dependency:Data_Set → Data_Set,
是數據到數據的映射關系,稱為數據依賴關系;
(4)Data_Process_Dependency:Data_Set → Process _Set,是數據到過程的映射關系,稱為過程對數據依賴關系,即過程依賴于數據,數據是過程的輸入;
(5)Process_Data_Dependency:Process_Set → Data _Set,是過程到數據的映射關系,稱為數據對過程依賴關系,即數據依賴于過程,數據是過程的輸出。過程對數據依賴關系和數據對過程依賴關系統稱為控制依賴關系;
(6)Process_Process_Dependency:Process_Set →Pr -ocess_Set,是過程到過程的映射關系,稱為過程依賴關系。
對應于OPM,WasGeneratedBy和Used表示的是控制依賴關系,WasDerivedFrom表示的是數據依賴關系,WasInformedBy表示的是過程依賴關系。
定義2 數據依賴對于一個給定的源數據Source_Data,存在依賴序列s=﹤Source_Data,D1,D2,…Dn,Sink_Data﹥,滿足:
Source_Data,D1, D2, …, Dn, Sink_Data ∈ Data_Set;
(1)有e0,e1,…,en∈ Data_Data_Dependency, ei=Data_Data_Dependency (ei-1), 0 ≤ i ≤n。
(2)則s為Source_Data的一個數據依賴,即Source_Data由Sink_Data演化而來。
定義3完全數據依賴 對于給定的數據Source_Data和Sink_Data,Source_Data數據依賴于Sink_Data,Source_Data={I1,…,In},Sink_Data={O1,…,Om},如果O1,…,Om→Ii, i ≤ n,則I1,…,In完全依賴于O1,…,Om,即Source_Data完全數據依賴于Sink_Data,記作Source_DataSink_Data。
定義4部分數據依賴 對于給定的數據Source_Data和Sink_Data,Source_Data數據依賴于Sink_Data,Source_Data={I1,…,In},Sink_Data={O1,…,Om},如果Oi→Ij,i≤m,j≤n,則Source_Data的一項數據依賴于Sink_Data的一項,稱Source_Data部分數據依賴于Sink_Data,記作Source_DataSink_Data。
1.2數據依賴細化與合成操作
定義5 數據起源依賴關系細化操作 DP_Dep1、DP_Dep2是兩個數據起源依賴關系,定義DP_Dep1的細化DP_Dep2,記為DP_Dep1﹤DP_Dep2,具體如下:
(1)Data_SetDP_Dep1? Data_SetDP_Dep2
(2)Process_SetDP_Dep1? Process_SetDP_Dep2
(3)Data_Data_DependencyDP_Dep1? Data_Data_DependencyDP_Dep2
(4)Data_Process_DependencyDP_Dep1? Data_Process_DependencyDP_Dep2
(5)Process_Data_DependencyDP_Dep1? Process_Data_DependencyDP_Dep2
(6)Process_Process_DependencyDP_Dep1? Process_Process_DependencyDP_Dep2
定義6 數據起源依賴關系合成操作 DP_Dep1、DP_Dep2是兩個數據起源依賴關系圖,定義DP_Dep1的合成DP_Dep2,記為DP_Dep1﹥DP_Dep2,具體如下:
(1)Data_SetDP_Dep1? Data_SetDP_Dep2
(2)Process_SetDP_Dep1? Process_SetDP_Dep2
(3)Data_Data_DependencyDP_Dep1? Data_Data_DependencyDP_Dep2
(4)Data_Process_DependencyDP_Dep1? Data_Process_DependencyDP_Dep2
(5)Process_Data_DependencyDP_Dep1? Process_Data_DependencyDP_Dep2
(6)Process_Process_DependencyDP_Dep1? Process_Process_DependencyDP_Dep2
定義7 數據依賴的細化 對于給定的數據Source_Data和Sink_Data,Source_Data={I1,…,In},Sink_Data={O1,…,Om},如果 Source_Data和Sink_Data滿足完全依賴關系dep1,Source_Data和Sink_Data滿足部分依賴關系dep2,那么dep2是dep1的細化,記作dep1﹤dep2。
定義8 數據依賴的合成 給定數據依賴關系圖DGraph=(Node_Set,Edge_Set, Role_Set),通過完全數據依賴的合成和部分數據依賴合成得到的新的數據依賴關系New_DG,稱New_DG是DGraph的一個數據依賴的合成,記作DGraph﹥New_DG。
定義9完全數據依賴的合成 給定數據依賴圖DGraph=(Node_Set, Edge_Set, Role_Set),如果?Child_DP ?Dgraph,Child_DP=(N,E,R),N? Node_Set,E ? Edge_Set,R ? Role_Set,滿足N=Ns∪Nf,Ns={Ns1,Ns2,…, Nsi},是邊起點集合, Nf={Nf1,Nf2,…, Nfj},是邊終點集合,則圖(N,E)是完全二分有向圖。如果R都是完全數據依賴,那么Ns中結點合并成一個結點s, Nf中結點合并成一個結點f,集合E中的邊合并成一條邊e=<s,f>,記生成的圖Dgraph-Child_DP + ({s,f},e,role)為New_DG,則New_DG是DGraph的一個完全數據依賴的合成,其中role為完全數據依賴。
定義10部分數據依賴的合成 給定數據依賴圖DGraph=(Node_Set, Edge_Set,Role_Set),如果?Child_DP?Dgraph,Child_DP=(N,E,R),N ? Node_Set,E ?Edge_Set,R ? Role_Set,滿足N=Ns∪Nf,Ns={Ns1,Ns2,…,Nsi},是邊起點集合, Nf={Nf1,Nf2,…, Nfj},是邊終點集合,則圖(N,E)是完全二分有向圖。如果R都是部分數據依賴,那么Ns中結點合并成一個結點s, Nf中結點合并成一個結點f,集合E中的邊合并成一條邊e=<s,f>,記生成的圖Dgraph-Child_DP + ({s,f},e, role)為New_DG,則New_DG是DGraph的一個部分數據依賴的合成,其中role為部分數據依賴。
定義11參數 在一個過程Process的執行過程中,如果輸入Parameter是過程執行的參數,不產生直接對應的輸出數據;或者是過程執行的數據,產生對應的輸出數據,但輸出數據只是中間產品。則Parameter不再籠統的稱作輸入數據,而是稱作參數。
2 數據依賴關系分析
則不進行任何替換。
算法具體執行過程如表1所示:

表1 數據依賴的細化規則及算法
針對不同用戶的不同層次數據依賴關系的需求,提出了一種數據依賴關系分析方法,基于細化和合成操作,設計了一系列數據依賴細化與合成規則,并且具體給出了細化與合成算法。
2.1數據依賴的細化規則及算法
首先定義數據依賴的細化規則,如下所示。
規則1 輸入數據和參數規則 對于給定的數據Source_Data和Sink_Data,Source_Data={I1,…,In},Sink_Data={O1,…,Om},Source_DataSink_Data,如果有一個Oi是參數,i≤m,則將Source_DataSink_Data替換為在參數Oi的條件下,{I1,…,In}{O1,…,Oi-1,Oi+1,…,Om}。如果Oi都是輸入數據,i≤m,則不進行任何處理。
規則2 完全數據依賴規則 對于給定的數據Source_Data和Sink_Data, Source_Data={I1,…,In},Sink_Data={O1,…,Om}, Source_DataSink_Data。如果滿足Oi→Ij,i≤m, j≤n,則將Source_DataSink_Data替換為Source_DataSink_Data。如果不滿足Oi→Ij,i≤m,j≤n,則不進行任何替換。
規則3 部分數據依賴規則 對于給定的數據Source_Data和Sink_Data, Source_Data={I1,…,In},Sink_Data={O1,…,Om}, Source_DataSink_Data,
1. 初始化數據變量Source_Data和Sink_Data,Source_Data={I1,…,In},Sink_Data={O1,…,Om}, i ≤m, j ≤ n;
2. 初始化Dep=Data_Data_Dependency-{Source_Data→Sink_Data};
3. 初始化變量role;
4. 初始化變量i=1;
//細化階段
5. do {
6. do {
7. if (Oi是parameter) 根據規則1處理;
8. i=i + 1;
9. }While (i ≤ m)
10. switch (role類型) {
11. case 完全數據依賴:根據規則2處理;break;
12. case 部分數據依賴:根據規則3處理;break;
13. }
14. Dep=Dep-{Source_Data→Sink_Data};
15. 將數據依賴圖中下一個依賴關系的數據存放在變 量Source_Data和Sink_Data中;
16. 初始化變量role;
17. 初始化變量i=1;
18.}While (Dep不為空)
return 得到細化數據依賴圖。
2.2數據依賴的合成規則及算法
首先定義數據依賴的合成規則,如下所示。
規則4完全數據依賴合成規則 數據集合{I1,…,In}和{O1,…,Om},滿足完全依賴,i≤m, j≤n。如果記Source_Data={I1,…,In},Sink_Data={O1,…,Om}, 則原依賴關系替換成Source_DataSink_Data。
規則5部分數據依賴合成規則 對于數據集合{I1,…,In}和{O1,…,Om},部分依賴滿足,i≤m, j≤n。如果記Source_Data={I1,…,In},Sink_Data={O1,…,Om},則原依賴關系替換成Source_DataSink_Data。
算法具體執行過程如表2所示:

表2 數據依賴的合成規則及算法

Node_Set=Data_Set;Edge_Set=Data_Data_Dependency;Role_Set={完全數據依賴,部分數據依賴};Data_Data_Dependency Data_Set×Data_Set。輸出:細化的數據依賴圖//初始化階段1. 初始化數據依賴圖Data_Data_Dependency_ Graph,包括Data_Set, Data_Data_Dependency和Role_Set ;2. 初始化數據變量Source_Data;3. 初始化Dep=Data_Data_Dependency;4. 初始化變量role;//合成階段5. do{6. 取數據依賴圖中與Source_Data有完全依賴關系的結點,根據規則4處理;7. 數據依賴圖中與Source_Data有部分依賴關系的結點,根據規則5處理;8. 取下一個結點存入Source_Data;9.}While (數據依賴圖沒有遍歷完)10. 得到合成數據依賴圖。
3 性能分析
本文從實現層上對OPM進行細化,利用細化或合成操作,分析數據依賴關系,滿足不同用戶對于數據起源追蹤不同視圖的需求。本文提出的數據依賴關系分析方法具體有如下3個方面的優勢:
(1)語義性
本文基于依賴關系分析的需求,進行數據起源語義信息的標注,標注的結果即是數據起源的控制依賴關系,從控制依賴關系著手,根據規則,得到數據依賴。所以,其數據依賴語義性是完備的。例如圖1所示:

圖1 控制依賴圖
控制依賴圖,得到數據依賴圖。如圖2所示:

圖2 數據依賴圖
(2)存儲耗費
本文針對數據起源依賴關系分析,進行數據起源信息的標注(標注的結果即為控制依賴關系),與OPM中數據起源信息的標注相比,需要的存儲空間相對減少了。例如圖1所示的控制依賴圖,為了起源依賴關系分析,其存儲耗費為S=Data_Store + Process_Store + Data_Process_Store
=8+6+14=28,而OPM存儲耗費為S=Data_Store + Process_Store + Data_Process_Store + Data_Data_Store + Process_ Process_Store=8+6+14+8+6=42,則本文方法與OPM方法的存儲耗費百分比為28/42=2/3,具體如圖3所示:
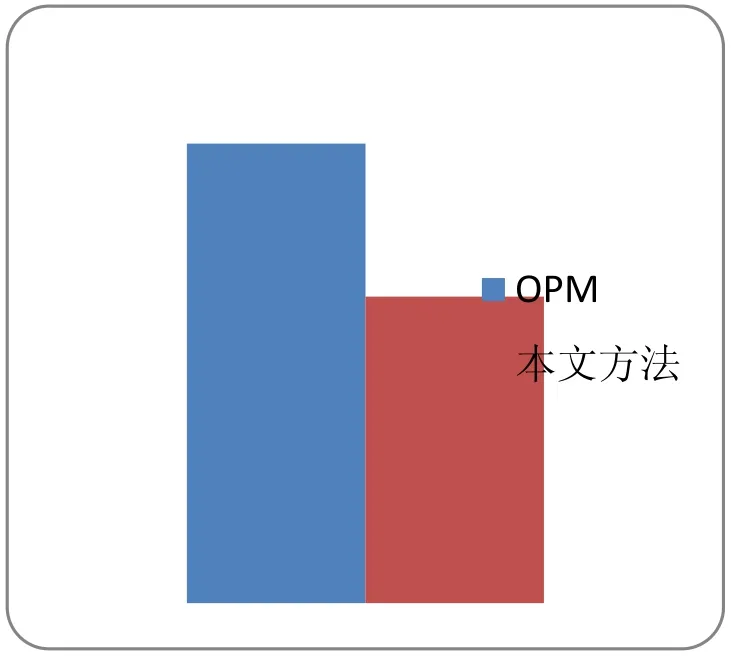
圖3 存儲空間耗費比較
(3)算法復雜度
本文方法依據OPM中因果依賴關系,利用細化或合成操作進行分析,獲得數據起源追蹤中數據依賴的不同視圖,滿足用戶不同層次起源信息的需求。方法中不論是細化算法還是合成算法,其算法復雜度都是多項式級別的,具體為:
細化依算法采用每兩個結點進行比較的思路,假設有n個結點的數據依賴圖Dep_Graph,則對兩個結點的依賴關系進行細化。當Dep_Graph每兩個結點都有邊的情況下,是需要計算最多的時候。而在這種情況下,算法的復雜情況是,所以算法的復雜度是O(n2)。
合成算法采用廣度優先搜索來搜索到每一個結點的相鄰結點,進行是否是二分圖判斷,根據判斷的三種情況分別進行完全依賴合成、部分依賴合成和不合成處理。算法的復雜度由廣度優先搜索、二分圖判斷和合成處理三部分組成。如果在一個圖中得到最優的數據依賴的合成,即得到最大的二分圖,那么復雜度是NP-hard的。如果采用只是對一個結點搜索相鄰結點,然后進行判斷處理的方式,則算法的復雜度是多項式級別的。
4 總結
本文基于OPM,從依賴關系的角度,定義了數據起源的語義信息,提出了一種數據起源追蹤中數據依賴關系分析的方法,利用細化和合成操作進行具體分析,給出了具體的規則和算法。最后,通過分析說明,本文提出的方法具有完備的語義,耗費的存儲空間較少,算法復雜度是多項式級別的,有效提高了數據起源追蹤的有效性和針對性。
[1] Y. L. Simmhan, B. Plale, D. Gannon, A Survey of Data Provenance Techniques, Technical Report TR-618,Com -puter[J] Science Department, Indiana University, 2005
[2] Freire, Juliana, David Koop, and Luc Moreau, eds. Provenance and Annotation of Data and Processes: Second International Provenance and Annotation Workshop[C],IPAW 2008, Salt Lake City, UT, USA, June 17-18, 2008. Vol. 5272. Springer, 2008.
[3] 高明, 金澈清, 王曉玲, 等. 數據世系管理技術研究綜述[J]. 計算機學報, 2010, 33(3): 373-389.
[4] Glavic Boris, Dittrich Klaus. Data provenance: A categorization of existing approaches// Proceedings of the 6th MMC Workshop of BTW 2007[J]. Aachen, Germany,2007:227-241.
[5] Luc Moreau,Natalia Kwasnikowska, Jan Van den Bussche,The Foundations of the Open Provenance Model[M],Technical report, University of Southampton, April 2009
[6] Moreau L, Clifford B, Freire J, et al. The open provenance model core specification (v1. 1)[J]. Future Generation Computer Systems, 2011, 27(6): 743-756.
[7] Xu Guoyan, Wang Zhijian,Yang Li. Tracking Framework of Data Provenance Based on Semantic Annotation .2012 International Conference on Computer Science and Service System, CSSS 2012, 406-409[J].
Research on Data Dependency Analysis Based on OPM
Dong Yuchao1, Zhang Wensheng2
(1. Computer and Information College, HoHai University, Nanjing 211100, China;2. East China Yixing Pumped Storage Power Co. Ltd., Yixing 214205, China)
How to analyze semantic information of data provenance is one of the key issues in the field of data provenance tracking. In this paper, according to the OPM, a data dependency analysis method is put forward based on introducing the concept and operation of data provenance dependency. Data dependencies are analyzed using refinement operation and synthetic operation in the proposed method, and in detail refinement algorithm and synthetic algorithm are given. Experiment shows that the method proposed has the perfect level of semantics, the algorithm complexity of polynomial, and reduced storage cost. The proposed method can satisfy different users query demand for different levels of abstraction data provenance information. The effectiveness of data provenance tracking is well improved.
Data Dependency; Data Provenance; Refinement Operation; Synthetic Operation; OPM
TP311
A
1007-757X(2016)06-0003-05
2016.02.10)
國家科技支撐計劃項目(編號:2013BAB06B04)、中國華能集團公司總部科技項目(編號:HNKJ13-H17-04)、江蘇水利科技項目(No.2013025)資助.
董宇超(1989-),男,山西省朔州市,河海大學,計算機與信息學院,碩士,研究方向:大數據管理、Web服務、數據挖掘,南京,211100張文生(1969-),男,華東宜興出水蓄能有限公司,學士,研究方向:電力系統信息通信,宜興,214205
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
海峽姐妹(2020年9期)2021-01-04 01:35:44
VOGUE服飾與美容(2020年9期)2020-09-02 14:47:26
幸福(2018年33期)2018-12-05 05:22:42
Coco薇(2017年11期)2018-01-03 20:59:57
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
中國科技信息(2016年14期)2016-07-31 21:16:32
山東青年(2016年1期)2016-02-28 14:25:25
當代修辭學(2014年3期)2014-01-21 02:30:44
