基于卷積神經網絡的圖像生成方式分類方法
2016-11-03 08:01:42李巧玲關晴驍趙險峰
網絡與信息安全學報 2016年9期
李巧玲,關晴驍,趙險峰
(1. 中國科學院信息工程研究所信息安全國家重點實驗室,北京 100093;2. 中國科學院大學,北京 100049)
基于卷積神經網絡的圖像生成方式分類方法
李巧玲1,2,關晴驍1,2,趙險峰1,2
(1. 中國科學院信息工程研究所信息安全國家重點實驗室,北京 100093;2. 中國科學院大學,北京 100049)
提出一種采用卷積神經網絡對自然圖像和文檔掃描圖像進行分類的方法,通過卷積和池化操作提取兩類圖像具有高區分度的特征,融合后得到分類判決結果。實驗結果表明,所提出的分類方法在SKL圖像庫上分類精度超過93%。圖像預處理對模型的精度以及模型訓練收斂所需時間具有積極效果,經過圖像預處理后訓練的卷積神經網絡模型對圖像文字大小和圖像格式頑健。
卷積神經網絡;圖像生成方式;內容模式分類;多媒體安全
隨著數字圖像處理技術和機器學習領域的快速發展,存在大量按照生成方式對圖像內容模式進行識別的工作,其中大多數工作集中在區分自然圖像和計算機生成圖像(computer graphics)[1~3]。文獻[1]提取基于小波直方圖的144維特征,輸入到FLD(fisher linear discriminant)分類器對計算機生成圖像和自然圖像進行分類。文獻[2]通過建立基于一階和高階小波統計量的統計模型,揭示計算機生成圖像和自然圖像之間微妙的不同。在沒有任何人工標注的前提下,文獻[3]通過訓練卷積神經網絡模型利用圖像顏色、光照和內容的協調性分類自然圖像和合成圖像。在眾多的網絡傳輸圖像中,自然拍攝圖像和掃描文檔圖像占到較大的比例,而這2種圖像成像方式、內容以及統計特性均有不同。因此,如果不加區分,容易造成一些系統的誤檢測率增高,如文檔掃描圖像將極大程度地增加隱寫分析系統的虛警率,而自然圖像由于其豐富的內容,對用于檢測文檔圖像中密級標識的密標檢測系統也將帶來影響。與自然圖像和計算機生成圖像的識別方法相比,針對自然圖像和掃描圖像的分類手段相對較少。文獻[4]是為數不多的檢測掃描圖像和自然圖像的工作,但該工作與之前大部分區分自然圖像和計算機生成圖像的工作類似,采用較為傳統的技術路線,利用隱寫分析特征和分類器實現。文獻[4]根據圖像生成過程的差異性提取不同特征。計算給定圖像固定模式噪聲的殘差,利用噪聲殘差的相關統計量構造15維的特征向量。使用SVM分類器對圖像內容模式進行分類,分類精度達到89.4%。
傳統的用于分類自然圖像和文檔掃描圖像的方法雖然可以達到比較高的準確率,但仍然存在一定的弊端:計算單元有限,無法支持大規模數據集的訓練,對于特征的表達有限。當掃描圖像經過JPEG壓縮之后再提取15維特征時,文獻[4]分類的準確率發生明顯下降。研究過程中發現,對于自然圖像和文檔掃描圖像的分類問題具有以下2個難點。
1) 文檔圖像存在字體和字號多樣性、版式多樣性等問題,且大量的表格、插圖、紙張底紋、文檔背景、掃描時的旋轉、文檔紙張的污損等均會對分類造成較大的影響。
2) 自然圖像中的紋理區域、標牌字符、某些符號等,也容易對識別準確率造成影響。
傳統的分類方法難以完全對這些問題頑健,由于其特征設計一般依賴于人為經驗,因此難以設計出對以上問題均具有較好頑健性的特征。自然圖像和文檔圖像種類極其豐富,本文試圖使用另一種技術途徑解決該問題,即使用大量多樣的訓練樣本涵蓋以上多種情況,并使用學習能力較強的方法獲取對以上多種條件均頑健且更具區分能力的檢測模型。
基于上述事實,本文提出一種高速高精度圖像類型識別的方法,主要針對自然圖像和文檔掃描圖像進行分類。該方法采用深度卷積神經網絡(CNN, convolutional neural network),利用多層卷積獲取對圖像內容模式具有高區分度的特征,并融合得到分類判決信息,為內容安全性檢測提供先驗依據,減少后續不必要的檢測,提高內容安全性檢測系統的準確性。圖像分類與安全性檢測過程如圖1所示。本文圍繞利用卷積神經網絡分類自然圖像和掃描文檔進行探討,重點探討采用多種圖像預處理方法、學習方法對檢測精度和模型訓練收斂速度的影響,并通過實驗驗證了合理的預處理對于模型的收斂速度和準確率具有積極作用。本文還對文檔掃描圖像的字體大小和圖像格式的頑健性問題進行了相關實驗論證。利用卷積神經網絡對自然圖像和文檔掃描圖像進行分類,具有較好的精度和實時性,可應用于網絡在線媒體數據監控等領域,具有重要且廣泛的應用價值。
2 卷積神經網絡簡介
2.1 符號系統定義
為保證敘述的嚴謹性,首先定義本文所使用的符號系統,各符號在下文中,如無特別說明,則默認為本節所定義。本文涉及的符號系統主要如下。
定義訓練樣本(x, y),x為神經網絡的輸入,在本實驗中x為輸入到網絡的圖像。y表示x的類別。(xi, yi)為第i個訓練樣本。S=((x1, y1), (x2,y2)…(xn, yn))為整個訓練樣本集合。使用w和b對神經網絡所有參數進行表示,在卷積神經網絡中w代表卷積核,b表示偏置向量。

圖1 圖像分類后進行安全檢測
2.2 神經網絡
神經網絡作為機器學習的一門重要技術,從早期的感知機到目前蓬勃發展的深度學習,已有了數十年的發展。神經網絡的應用涉及各個領域,如語音識別、機器翻譯、人臉識別等。神經網絡是通過模仿動物神經元之間傳遞、處理信息的模式。由簡單的處理單元(神經元)相互連接構成一個復雜的網絡結構,整個神經網絡是一個復雜的非線性系統。其變換過程可以描述為

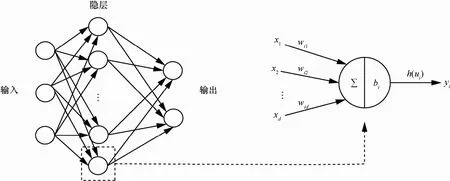
圖2 神經網絡模型以及單個神經元信息處理過程
h為非線性激活函數,常見的激活函數有Tanh、Sigmoid等。w、v分別為輸出層和隱層的權重矩陣,尺寸分別為n×m、m×d,n為輸出的類別數。b、c分別為輸出層和隱層的n維和m維偏置向量。如圖2左側所示,神經網絡對輸入的d維向量,經過隱層投影成一個m維的向量,再輸入到分類器進行分類。
神經元是神經網絡的基本組成單元,每個神經元是一個多輸入單輸出的信息處理單元,圖2右側為單個神經元的信息處理過程,該過程可以簡單表示為
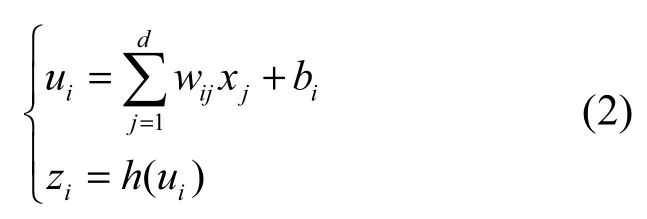
將(x1,x2,…,xd)輸入到神經元i,每個輸入單元都進行加權平均,權值系數和偏置都是經過訓練學習而來。zi為第i個神經元的輸出,h為非線性激活函數,神經網絡通過引入非線性的激活函數使網絡能夠學習出更好的特征表達,解決線性模型所不能解決的問題。
神經網絡是一個分層的有向圖,同層節點之間沒有連接,節點之間不能越層連接。上層輸入經過非線性變換后作為下層神經元的輸入。隱層的數目,每層神經元的個數以及非線性函數的選擇是構成神經網絡的關鍵。神經網絡使用BP算法從大量訓練樣本中學習出統計規律,從而對未知事件做預測。只含有較少隱層的神經網絡稱為淺層模型,其局限性在于有限的計算單元,對特征的表示能力有限。當前,神經網絡已發展為深度模型,與淺層模型相比,深度模型通過構建多個隱層利用海量的訓練數據,自動地學習更有用的特征,提升最終分類或預測的準確性。2.3節介紹的卷積神經網絡屬于該類深度模型。
2.3 卷積神經網絡
深度神經網絡通過有監督或者無監督的方式學習層次化的特征表達,對物體進行從底層到高層的特征描述。卷積神經網絡是深度神經網絡主流結構之一。最早出現在20世紀80年代,最初應用于手寫數字識別,取得了很好的效果。卷積神經網絡是在多層神經網絡的基礎上發展起來的針對圖像分類而特別設計的一種深度學習方法。該網絡的布局更加接近于生物神經網絡。對于圖像這種多維向量可以直接輸入到網絡,無需進行復雜預處理。
卷積神經網絡在傳統的神經網絡上加入卷積和池化層,并引入了局部感受野、權值共享的機制,大大減少了待訓練的參數量。卷積層利用卷積核的移動來提取上層輸入的局部特征,然后非線性組合這些特征得到下層的輸入,逐層對圖像特征進行抽象。卷積使圖像原信號增強,并且降低噪聲,保持了圖像的空間信息,因而特別適合于對圖像進行表達;池化層利用圖像的局部相關性原理,對卷積后的特征圖進行子抽樣,在大大減小數據處理量的同時保留圖像的有用信息,并且保證特征圖像對于旋轉、平移等變換具有一定的頑健性,常見的池化方法有Max Pooling、Mean Pooling。Max Pooling選擇圖像區域的最大值作為池化后的值;Mean Pooling計算圖像區域的平均值作為池化后的值。
文獻[5]提出了一種特征可視化的方法,通過提取各層的特征圖像進行可視化。探討卷積神經網絡每層對圖像所做的具體操作。卷積神經網絡通過逐層迭代,提取特征。文獻[5]認為卷積神經網絡中下層的卷積主要提取圖像的淺層特征,如邊緣、顏色、紋理等信息。越往上層提取的特征越高級。對特征的可視化,可以進一步對網絡結構進行調優。

卷積神經網絡在語音識別和圖像處理方面有著獨特的優越性,使其成為當前語音識別和圖像識別領域的研究熱點。以Lecun[6]提出的“LeNet-5”為代表的卷積神經網絡,在手寫數字識別任務上取得了不錯的效果,Kussl等[7]提出的采用排列編碼技術的神經網絡在人臉識別和小物體識任務上有較好的應用。但目前神經網絡在自然圖像和文檔掃描圖像分類任務上的應用還存在空白,本文以經典的“LeNet-5”為原型設計了“ScanNet”,使用卷積神經網絡對數字圖像的內容模式進行分類。
3 針對簡單分類任務卷積神經網絡一般構建及其性質初步分析
隨著硬件性能的提升和算法的不斷優化,卷積神經網絡已從只能完成簡單的分類任務發展到能夠超越人類識別能力的水平[8]。針對不同復雜度的分類任務,往往需要構建不同的網絡結構。對于簡單的分類任務,一般會使用較少的卷積、池化和Relu(rectified linear unit)[9]非線性層,每層使用較少的卷積核數目來提取不同類別間的差異性特征。要完成較難的分類任務,神經網絡的結構更加復雜,網絡參數量更大,需要的操作種類更多。
相對于早期卷積神經網絡中使用最多的Tanh、Sigmoid非線性函數而言,Relu[9]:f(x)=max(0,x)非線性函數可以增加隱層單元的稀疏性,減少計算量,加速網絡收斂,并且Relu函數不存在飽和區域,反向傳播時,避免了梯度消失的問題。
當訓練樣本不足,網絡參數過多時模型會出現過擬合的現象。構建網絡時為了防止過擬合現象的發生,一般采用在損失函數中加入L1或L2正則化項、early stopping、dropout[10]等技術。dropout以一定的概率將隱層的神經元暫時從網絡中丟棄,丟棄就是對這些神經元的權重系數暫時不做更新,但是權值仍然保留,以便接下來輸入的樣本對其進行微調。
GPU的發展提升了計算機的計算能力。為了充分利用GPU強大的計算能力,目前訓練神經網絡時采用批梯度下降代替原有的梯度下降和單樣本的隨機梯度下降,一次隨機使用一批(mini-batch)樣本的梯度對參數進行微調。當一小批樣本包含的圖像數目越多,訓練所需的GPU顯存會相應增加。每一小批圖像在選擇時引入了隨機性,使網絡從概率的角度考慮始終可以收斂。與使用單個樣本的隨機梯度下降法相比,批梯度下降每次可處理的數據量增多,提高了GPU的利用率,訓練過程的效率得到了很好提升。與一次使用所有樣本更新參數的梯度下降相比,計算開銷減小,訓練所需時間縮短。帶有動量[11](momentum)參數的隨機梯度下降法使網絡的收斂速度變得更快。

其中,vk、vk+1分別為第k次和第k+1次優化時梯度下降的速率,a為學習速率,r為動量參數。加入動量參數后下降速率相對于常規的方法要更大,需要相應地減小學習速率。一般動量初始化為0.5,當模型趨于穩定時逐漸增加動量到0.9。使用帶有動量參數的隨機梯度下降法,每一步梯度下降的量都需要參考前一步下降的量,使網絡能夠更快收斂,并且減小收斂到局部最優點的可能性。
卷積神經網絡模型訓練的速度和模型的精度受到多種因素的影響。如訓練數據間往往存在較大的數值差異,使訓練過程中誤差下降不穩定,網絡學習速率變慢甚至不收斂等。對數據進行減均值、z-score 標準化、白化操作可以消除不同特征分量之間的數值大小差異,改善網絡的學習性能。減均值的計算如下。

4 實驗環境及網絡結構設置
4.1 實驗環境
本文實驗所使用訓練樣本和測試樣本圖像均來自SKL圖像庫。SKL圖像庫包含4 000張自然拍攝圖像和1 500張文檔掃描圖像。表1列出了用于建立SKL圖像庫所使用的拍攝設備和掃描設備名稱。所有相機拍攝圖像均采用RAW和JPEG這2種格式存儲。掃描儀分別設置3種不同的分辨率:100×100 dpi、300×300 dpi、600×600 dpi,掃描文檔存儲為JPEG格式。圖3和圖4 分別為SKL圖像庫中典型的自然圖像和文檔掃描圖像示例。

表1 圖像生成設備

圖3 典型自然圖像

圖4 典型掃描文檔
訓練樣本包含1 600張圖像,其中800張JPEG格式的自然圖像,文檔掃描圖像800張。測試樣本包含600張圖像,JPEG格式的自然圖像300張,掃描文檔圖像300張,正負樣本分布均衡。實驗在Ubuntu 14.04上進行,訓練過程利用兩塊NVIDIA GTX TITAN X,采用CUDA和GPU并行計算提升卷積神經網絡的訓練速度。
4.2 ScanNet網絡結構以及參數設置
適當的卷積神經網絡結構對于實現特定的分類任務至關重要。本文涉及的分類任務主要需要表達自然圖像與掃描文檔的區分信息,從視覺表觀而言,兩類圖像在局部和全局均存在具有區分能力的信息,需要建立從局部表達到全局綜合的網絡模型。因此,本文分別使用卷積層和全連接層達到以上目的。以經典的LeNet-5為原型設計了ScanNet結構,如表2所示,ScanNet包含3層卷積以及2層全連接。本文利用深度學習框架Caffe(convolutional architecture for fast feature embedding)[12]搭建ScanNet。Caffe是一款開源的深度學習框架,擁有通用性強、性能高、代碼可讀性好等特點,支持多種數據類型,并且支持多GPU并行。
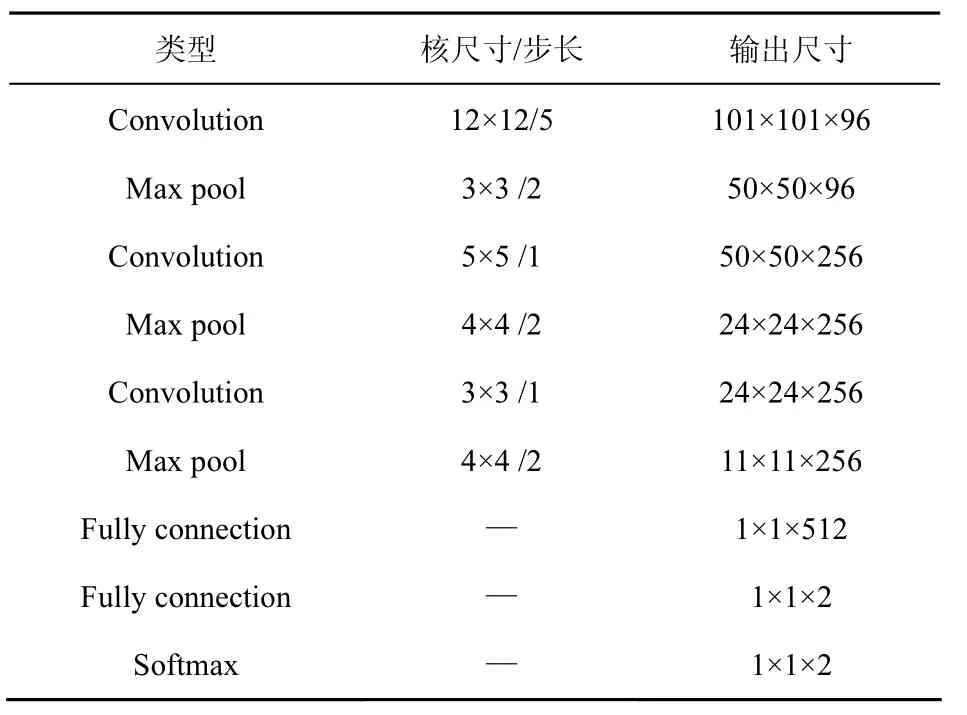
表2 ScanNet網絡結構
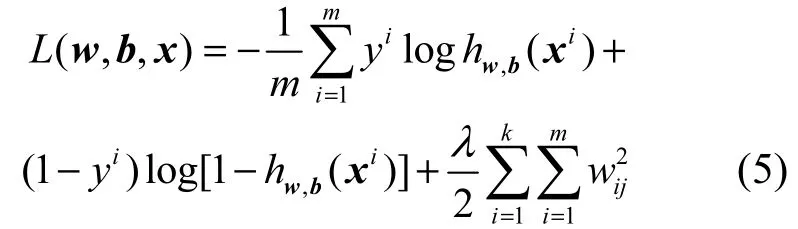
在ScanNet中,網絡每層卷積后連接有Relu非線性層和LRN歸一化層,經過歸一化后每層的輸入更加穩定,網絡學習速度更快。經過不斷的調優,設定初始學習速率為0.000 1。通過迭代學習,損失函數會逐漸接近最小值,與此同時需要減小學習速率。因此,實驗每迭代500次學習速率降為原來的。實驗為一個二類概率分類問題,損失函數為其中,yi標簽取值為0或者1(0標簽代表掃描文檔,1標簽代表自然拍攝圖像)。,()i hwbx為Softmax分類器輸出將xi預測為第yi類的概率。以上損失函數為加入了正則化項的二類概率損失,等式右側第二項為正則化項。正則化項的加入使上式能夠更容易得到全局最優解,防止模型過擬合,實驗λ=0.000 5。m為一次輸入到網絡的圖像數。
使用帶有動量參數的隨機梯度下降來學習網絡的參數,將動量固定為0.9,綜合考慮網絡的學習速度和GPU的顯存,設置每一小批樣本包含32張圖像。通過對比實驗發現對于目前的分類任務網絡結構是否使用dropout操作對于模型在測試樣本上的測試精度沒有影響。
4.3 樣本歸一化對模型的影響及模型頑健性實驗論證
本文主要圍繞卷積神經網絡在識別數字圖像的內容模式方面的應用展開了研究。本文就圖像減均值歸一化操作對于模型的訓練速度、測試精度的影響做了進一步的實驗論證。實驗總共訓練2個模型,在網絡結構和配置參數相同的情況下,模型A未對輸入的訓練樣本和測試樣本進行減均值中心化處理,模型B對訓練樣本和測試樣本的每個像素點都分通道進行第3節所述的減均值預處理,經過歸一化的訓練樣本間具有更加相似的分布,網絡的訓練過程更加高效。由于卷積神經網絡只能處理固定尺寸的圖像,訓練樣本和測試樣本圖像的尺寸不一,還需對圖像進行尺寸處理。一般通過縮放、裁剪、扭曲將圖像變換到網絡要求的尺寸。在需要圖像整體特征時通過扭曲可以保留整張原始圖像信息。對于本分類任務而言無需圖像的整體特征,經過縮放和裁剪之后自然圖像和掃描圖像之間的差異性特征不會發生改變。因此,本文在訓練過程中首先將訓練樣本的原始圖像縮放到600×600大小,再使用512×512大小的窗口對縮放之后的圖像進行中心和四角的裁剪。在保證特征不變的前提下,同時增加兩類樣本的數量。并對訓練樣本進行隨機置亂以保證訓練出的分類模型對類別預測無傾向性。測試樣本圖像直接通過尺度縮放到512×512大小。
圖5刻畫損失函數與訓練迭代次數之間的關系,隨著迭代次數的增加損失函數逐漸下降并最終達到穩定,當損失函數保持穩定時模型達到收斂。如圖5所示,訓練樣本和測試樣本未進行歸一化操作時,網絡需進行800次迭代達到收斂,在測試樣本上的最優測試精度為0.97;但進行歸一化操作之后,經過400次迭代模型便達到穩定,并且此時的測試精度可以達到0.99,訓練的效率要明顯高于未經過歸一化的數據。通過進一步的實驗發現經過歸一化操作訓練得到的模型對于掃描文件字符大小的頑健性要強于未經過歸一化操作訓練得到的模型。
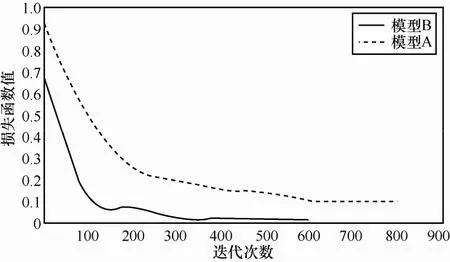
圖5 模型A與模型B迭代次數和損失函數關系

圖6 模型B預測過程
使用模型B對100張掃描文檔和自然圖像進行分類。待分類圖像包含掃描文檔和自然圖像各50張,自然圖像編號為1~50,掃描圖像編號為51~100。圖6為模型B對一張圖像進行預測的基本流程。將待分類圖像輸入網絡之前先進行減均值、尺寸變換等預處理,然后再輸入到神經網絡對圖像類型進行預測。圖7為模型B Softmax層對100張圖像輸出的分類概率。分類時使用一塊NVIDIA GTX TITAN X,每張圖像分類平均耗時0.7 s,當增加GPU的數量,通過多線程可增加一次性預測分類的圖像張數。圖中圓形代表被誤分的自然圖像,菱形表示被錯誤分類的掃描圖像,三角形代表預測類型為自然圖像,矩形表示預測類型為文檔掃描圖像。分類混淆矩陣如表3所示,模型B的平均準確率可達到94.0%。對未能正確分類的掃描文檔圖像分析發現這類圖像具有明顯的共性是不含文字。卷積神經網絡模型為數據驅動的模型,模型的準確率依賴于數據集包含的圖像種類和數量。造成模型對此類圖像無法正常分類的原因可能是由于訓練樣本中不包含這類不含文字的文檔圖像,導致無法正確提取具有高區分度的特征。后續實驗可以將此類圖像加入到訓練樣本中,豐富訓練樣本類型,以達到更高的識別準確率。

表3 模型B混淆矩陣

圖7 模型B分類概率
文檔圖像存在字體和字號多樣性、版式多樣性等問題。本文還從模型對掃描文檔的文字大小、圖像存儲格式的頑健性這2個方面進行了研究。掃描文檔文字大小選用八號到初號不同大小的字符,模型B分類結果的準確率可以達到97%。模型A識別的準確率只能達到50%。用模型B對JPEG、TIFF、BMP、PNG格式的圖像進行分類,識別的準確率也可達到97%。
以上兩組實驗表明,經過歸一化預處理的模型對于文檔字符的大小,以及圖像的格式具有很強的頑健性。這對于后續對圖像進行安全檢測具有深遠意義。
5 結束語
圖像類型的日益豐富,對隱寫分析、圖像內容取證、失泄密檢查等圖像內容安全檢測技術提出了挑戰。為了應對圖像安全檢測技術面臨的挑戰,適應媒體類型多樣性的現狀,本文使用卷積神經網絡按照圖像的生成方式對圖像進行類型分類。通過卷積和池化操作提取自然圖像和文檔掃描圖像間具有高區分度的特征,構建高速高精度圖像類型識別系統。所提出的分類方法在SKL圖像庫上的分類精度超過93%。訓練的卷積神經網絡模型對于圖像文字大小和圖像格式頑健。本文通過對比實驗驗證了圖像預處理對于模型的精度以及模型訓練收斂所需時間具有積極效果。
感知圖像的類型有助于提高圖像安全檢測的精度,對后續的安全檢測具有顯著意義。除了自然圖像和文檔掃描圖像,計算機合成圖像與屏幕截圖在進行安全檢測前也需要按照生成方式分類。后續實驗還會將計算機合成圖像和屏幕截圖加入到訓練樣本中,構建更加復雜的網絡結構,訓練出能對更多內容模式的圖像進行準確分類的模型。目前實驗使用1 600張圖像進行訓練,后續實驗將繼續豐富訓練樣本的數量和類型,通過大樣本訓練出更加高精度的模型。
[1] WANG Y, MOULIN P. On discrimination between photorealistic and photographic images[C]//IEEE International Conference on Acoustics Speech and Signal Processing. 2006.
[2] LYU S, FARID H. How realistic is photorealistic[J]. IEEE International Conference on Signal Processing, 2005, 53(2): 845-850.
[3] ZHU J Y, KRAHENBUHL P, SHECHTMAN E, et al. Learning a discriminative model for the perception of realism in composite images[C]//IEEE International Conference on Computer Vision. 2015: 3943-3951.
[4] KHANNA, N, CHIU G T C, ALLEBACH J P, et al. Forensic techniques for classifying scanner, computer generated and digital camera images[C]//IEEE International Conference on Acoustics,Speech and Signal Processing. 2008: 1653-1656.
[5] MAHENDRAN A, VEDALDI A. Understanding deep image representations by inverting them[C]//IEEE Conference on Computer Vision and Pattern Recognition. 2015: 5188-5196.
[6] LECUN Y, BOTTOU L, BENGIO Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998,86(11): 2278-2324.
[7] KUSSUL E, BAIDYK T, WUNSCH II D C. Permutation coding technique for image recognition system[M]. Neural Networks and Micromechanics, 2010: 47-73.
[8] KAIMING H, XIANGYU Z, SHAOQING R, et al. Delving deep into rectifiers: surpassing human-level performance on imagenet classification[C]//IEEE International Conference on Computer Vision. 2015: 1026-1034.
[9] NAIR V, HINTON G E. Rectified linear units improve restricted boltzmann machines[C]//The 27th International Conference on Machine Learning. 2010: 807-814.
[10] SRIVASTAVA N, HINTON G, KRIZHEVSKY A, et al. Dropout: a simple way to prevent neural networks from overfitting[J]. The Journal of Machine Learning Research, 2014, 15(1): 1929-1958.
[11] SUTSKEVER I, MARTENS J, DAHL G, et al. On the importance of initialization and momentum in deep learning[C]//The 30th International Conference on Machine Learning. 2013: 1139-1147.
[12] JIA Y, SHELHAMER E, DONAHUE J, et al. Caffe: convolutional architecture for fast feature embedding[C]//The ACM International Conference on Multimedia. 2014: 675-678.

關晴驍(1984-),男,湖南湘潭人,博士,中國科學院信息工程研究所助理研究員,主要研究方向為多媒體內容安全、通信隱寫分析。

趙險峰(1969-),男,安徽淮北人,博士,中國科學院信息工程研究所研究員、博士生導師,主要研究方向為信息安全事件檢測分析的理論與技術,包括信息隱藏及其檢測、網絡安全異常行為檢測、大數據安全分析以及相關技術在內容保護、版權保護和系統防護等中的應用。
Image generation classification method based on convolution neural network
LI Qiao-ling1,2, GUAN Qing-xiao1,2, ZHAO Xian-feng1,2
(1. State Key Laboratory of Information Security, Institute of Information Engineering, Chinese Academy of Sciences, Beijing 100093, China;2. University of Chinese Academy of Sciences, Beijing 100049, China)
Using convolution neural network which though convolution and pooling extracting features of high distinguish ability and then make fusion for classification of natural images and scanned documents. Experimental results show that the classification accuracy of the proposed classification method is more than 93% on the SKL image database. The model is highly robust to font sizes and image formats. Through contrast experiment validated that preprocessing of image has a positive effect on the accuracy of the model and the time cost on training.
convolution neural network, image generation mode, content pattern classification, multimedia security
1 引言
當前,網絡圖像類型日益豐富,這導致圖像安全檢測容易出現被測圖像和檢測模型失配問題,媒體失配問題使圖像安全檢測方法的性能大大降低。造成圖像類型日益豐富的主要原因是圖像生成方式較多,這包括拍攝設備拍攝、計算機生成、掃描儀掃描等,為了使圖像安全檢測技術適應媒體類型多樣性的現狀,技術上需要按照生成方式對圖像進行類型分類,感知圖像的類型可以為后續安全檢測提供先驗知識,有助于提高后續圖像安全檢測的精度和效率。
s: The National Natural Science Foundation of China (No.61303259, No.U1536105), The Strategic Pilot Science and Technology Project of the Chinese Academy of Sciences (No.XDA06030600), The Key Project of Institute of Information Engineering, Chinese Academy of Sciences (No.Y5Z0131201)
TP37
A
10.11959/j.issn.2096-109x.2016.00096
2016-07-16;
2016-08-09。通信作者:李巧玲,liqiaoling@iie.ac.cn
國家自然科學基金資助項目(No.61303259, No.U1536105);中國科學院戰略性先導科技專項課題基金資助項目(No.XDA06030600);中國科學院信息工程研究所重點基金資助項目(No.Y5Z0131201)
李巧玲(1992-),女,湖北宜昌人,中國科學院信息工程研究所碩士生,主要研究方向為信息對抗理論與技術。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
