基于順序向前選擇算法的制冷系統故障診斷分析
2016-11-05 09:45:02胡永攀李瑛姚熠凱王彩霞
能源研究與信息 2016年2期
關鍵詞:故障診斷
胡永攀+李瑛+姚熠凱+王彩霞
摘要:以一臺制冷量為90冷t(約316 kW)、制冷劑為R134a的離心式制冷機組為實驗對象,從理論上分析該制冷系統的7種典型故障,分析故障征兆與故障間的理論關系,運用基于順序向前選擇(SFFS)算法的封裝模型進行特征選擇,降低乃至消除特征間的相關度,去除信息冗余,獲得不同的能較好表征故障的特征子集.結果顯示:運用SFFS算法時選擇了22個特征,診斷正確率為89.63%,與原特征集的診斷正確率90.36%基本相當,極大地減少了原特征集的特征數,從64維降為22維;在保證故障檢測與診斷正確率的前提下,減少了診斷所需傳感器種類和數量,節約了初始投入成本.
關鍵詞:制冷系統; 順序向前選擇算法; 故障診斷
中圖分類號: TH 311 文獻標志碼: A
Abstract:An refrigeration system with a 90 t centrifugal chiller using R134a as refrigerant and its seven typical faults were analyzed theoretically.The relationship between the symptoms and faults was attained.The encapsulation model based on sequential forward order feature selection(SFFS) algorithm was adopted for feature selection,which could find better feature subset for reducing or even removing the feature correlation and eliminating the redundancy.The results showed that 22 features were selected by SFFS algorithm and diagnosis accuracy of 89.63% was achieved,which was close to the diagnosis accuracy of 90.36% for original feature set.But it could significantly eliminate the features of original feature set from 64 to 22.Due to the guarantee of the accuracy of fault detection and diagnosis,the type and quantity of sensor could be reduced.The first investment cost could be saved.
Keywords:refrigeration system; sequential forward order feature selection algorithm; fault diagnosis
制冷系統一旦發生故障,會造成環境的舒適性或所要求的冷凍溫度得不到保證,嚴重的將導致系統設備損壞.其次,當制冷系統運行在故障狀態時,系統能耗往往增大,造成能源浪費.因此,對制冷系統的故障機理進行研究,建立有效、準確的故障診斷模式對實現制冷系統的實時在線監控、故障先兆預測和優化運行十分重要[1].
近年來,制冷系統故障診斷的方法隨著人工智能、計算機、模式識別、數據通訊、信號分析處理等技術的發展而不斷完善和更新[2].常用的診斷方法有經典專家系統[3]、模糊理論[4]、神經網絡[5]等.直接運用上述方法對制冷系統進行故障檢測與診斷,需要測量的過程變量較多, 這意味著需要更多的傳感器,進而使成本增加,而且變量維數過大,相互之間具有較強的相關性和冗余,影響識別的準確性.高維數據也對數據的測量、存儲,以及訓練和應用時間提出了更高的要求,以至在一些情況下,根本不能滿足這類要求.因而,選擇合適的特征描述模式或樣本不僅對模式識別的精度、樣本數和訓練時間等諸多方面都有較大影響,而且對分類器的構造也起著十分重要的影響.正是由于上述原因,使得對特征選擇的研究變得非常有必要.
1 制冷系統故障診斷的特征選擇
制冷系統是一個變量多、耦合性強、非線性的熱力學系統,系統參數之間存在一定的相關性、模糊性和不確定性.同一種故障的原因可能會表現出多種不同的故障征兆,同一故障征兆也可能在多種不同的故障中表現,而且彼此之間存在著一定的因果關系.制冷系統一旦出現故障,需要監測的參數多,獲得的數據集特點表現為多特征、高噪聲、非線性,這給故障診斷帶來了極大的挑戰.
假設系統可能發生n種故障,并將正常運行的狀態設為N0,n種故障所處的狀態分別設為N1、N2…Nn.狀態Ni對應的可測特征向量Si=[Si1,Si2…Sim],診斷的過程即為由可測特征向量Si求出Ni所處狀態的過程.
在實際應用中,
如果可測特征向量維數高,樣本數量大,無論從計算復雜程度、系統監測成本還是故障診斷效果來看,都是不適宜的.
特征選擇是從一組數量為D的特征中選擇出數量為m(D>m)的一組最優特征.采用基于順序向前選擇算法對制冷系統進行故障診斷的特征選擇,不僅能極大地減少數據集的維數,簡化計算,降低設備投入初成本,還能有效地保證診斷效果.
2 模擬故障實驗
2.1 模擬故障實驗簡介
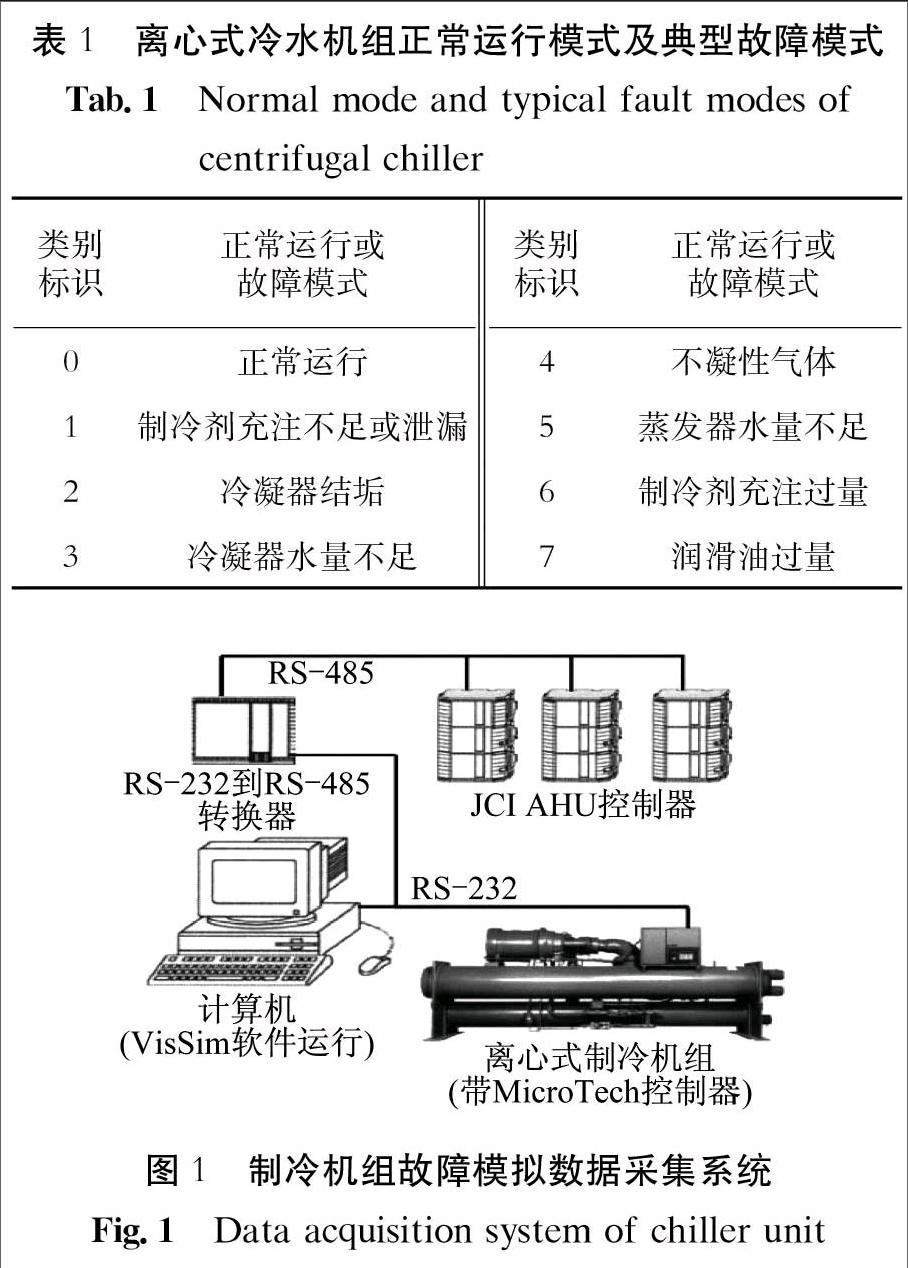
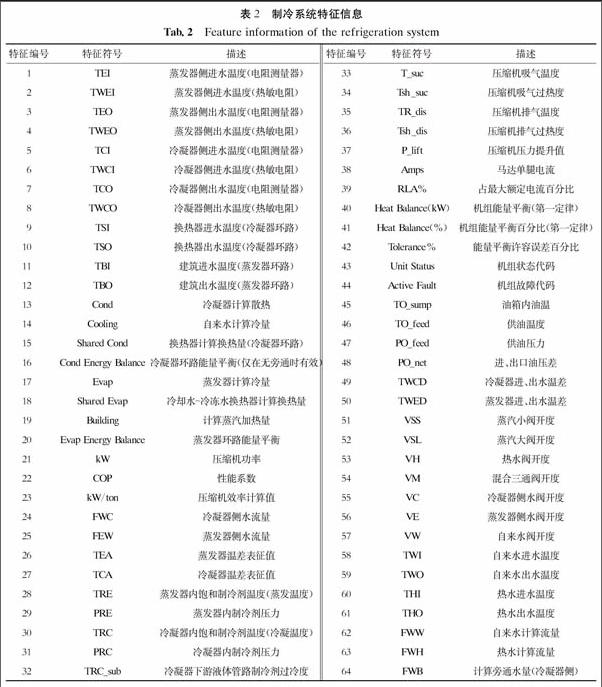
本文數據源于ASHRAE的制冷系統故障模擬實驗.實驗裝置為一臺制冷量為90冷t(約316 kW)、制冷劑為R134a的離心式制冷機組.其中,冷凝器和蒸發器均為殼管式換熱器,管程走水,下進上出,冷凝器側制冷劑上進下出,蒸發器側制冷劑下進上出,分別模擬正常運行模式及7種典型單發故障模式.為了便于分析,表1給出了離心式冷水機組正常運行模式及典型故障模式.制冷機組故障模擬數據采集系統如圖1所示,采集時間間隔10 s.獲取的制冷工況下正常運行及各故障模式模擬實驗終態時的特征參數有64個,如表2所示,其中:16個參數由VisSim軟件實時計算得到;48個參數由傳感器直接測得,包括29個溫度、5個壓力、5個流量、7個閥位開度、電流和壓縮機功率.為保證實驗測量值的準確性,同時采用電阻測量器、熱敏電阻對蒸發器側進、出水溫度,冷凝器測進、出水溫度四個關鍵值進行測量.
2.2 制冷系統故障的理論分析
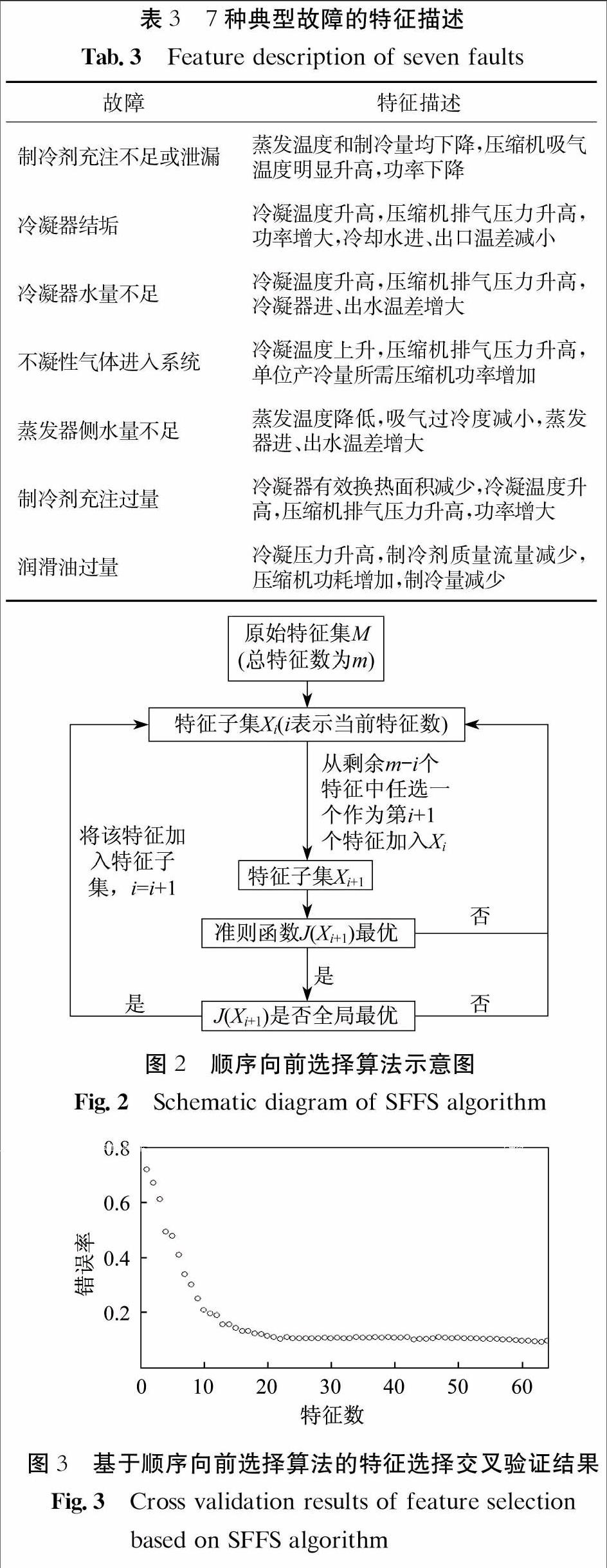
系統發生故障時,各參數偏離正常工況的程度與故障程度有關,一般故障越嚴重,參數偏離越嚴重.本文模擬了制冷系統正常運行及7種典型故障模式.7種典型故障的特征描述如表3所示。7種故障中,某些故障對熱力狀態的影響有一定的相似性,如冷凝器結垢、冷凝器水量不足、制冷劑充注過量、不凝性氣體進入系統等均可導致冷凝壓力和溫度、排氣壓力升高;蒸發器側水量不足和制冷劑充注不足均可導致蒸發壓力和溫度降低.所有故障均會導致不同程度的制冷量下降,壓縮機功率增加,系統性能系數降低,嚴重的甚至導致壓縮機燒毀等事故,所以故障必須早發現,早排除.
3 基于順序向前選擇算法的封裝模型
順序向前選擇(SFSS)算法是一種尋找近似最優特征的漸進搜索算法.該算法采用一種“自下而上”的搜索方法,初始化的目標特征集為空集,每次計算時向特征集中增加一個特征,當達到要求時,所得到的特征集合就作為特征選擇結果.圖2為順序向前選擇算法示意圖.設原始特征集為M,假設當前特征子集Xi包含i個特征,然后對剩余的每一個未入選的特征分別計算其準則函數J(Xi+1),選擇使J(Xi+1)全局最優的特征加入特征子集Xi以生成新的特征子集Xi+1,然后重復上述步驟,直到找到滿足要求的特征數時算法結束.本文算法通過Matlab軟件實現.
4 基于順序向前選擇算法的特征選擇結果分析
將基于順序向前選擇算法的封裝模型與線性判別分析(linear discriminant analysis,LDA)算法相結合,對在上述正常運行及7種故障模式下獲得的64維36 000個樣本組成的特征集進行特征選擇,以期選擇出能夠很好表征原始特征集的特征子集.LDA算法是一種常用的信號處理方法,對應于Matlab軟件中的“Classify”函數,其并不直接以訓練誤差作為目標函數,因此難以找到最優的分類子空間.將LDA算法與順序向前選擇算法進行封裝,通過順序向前選擇算法調節LDA算法中類間矩陣特征值的大小,可達到搜索最佳特征子空間的效果.
圖3為特征數為1~64時,十折交叉驗證的錯誤率.十折交叉驗證時將64維36 000個樣本組成的數據集分成10等份,輪流對其中1份做測試,9份做訓練,10次測試結果的均值作為對算法精度的估計,以便得到可靠穩定的模型.從圖3中可見,當特征數從1依次增加到22后,錯誤率達到最低;當選擇特征數在23~42個之間時,錯誤率基本保持不變;繼續增加特征數,錯誤率略微下降;采用全部特征(64個)時的錯誤率與22個特征時的基本相當,即64維與22維的診斷性能相近.這意味著在進行故障診斷時,可以極大地減少傳感器的數量.基于順序向前選擇算法選擇的特征如表4所示.
順序向前選擇算法是在剩余特征中選擇與已選特征子集構成評價整體預測性能為最佳的新特征子集.從表4中可以看出:編號為48的特征符號PO_net最先被選中,說明當只選擇一個特征組成特征子集時,PO_net對表1所列制冷系統7種典型單發故障描述效果最佳;其次,在剩余特征中選擇加入的VE與PO_net所形成的兩個特征的特征子集對7種典型故障的描述效果最好;隨后依次加入的是FWC、冷凝器內制冷劑飽和溫度與冷凝器側出水溫度之差TCA,其可以代表傳熱溫差;接著是TO_sump、PO_feed、VSS等.從特征選擇的結果可知,特征符號TRC和PRC分別位列第61和64,TRE和PRE分別位列第28和37,說明蒸發器內的參數相比冷凝器內的參數優先被選入.因此,就所研究的7種典型故障而言,蒸發器側參數比冷凝器側參數更具表征性.
取SFFS算法選擇的前22個特征組成的特征集為最優特征集,由最優特征集和未經降維處理的原特征集分別得到故障診斷的總體診斷正確率和各類故障的診斷正確率,結果如圖4所示.從圖中可知,雖然原特征集的總體診斷正確率比運用SFFS算法的略高,但采用SFFS算法能夠極大地減少原特征集的特征數(64個降為22個).一旦表征特征選定,其余非表征性特征則不需要監控,從而大大減少了傳感器的使用數量,降低了初始投入成本.
由基于順序向前選擇算法的特征選擇結果可以看出,前6個被選中的特征分別是編號為48、56、24、27、45、47的PO_net、VE、FWC、TCA、TO_sump和PO_feed.分別將隨機樣本點以二維形式顯示于圖5中,橫坐標均為正常及各類故障的類別標識,縱坐標為各個特征的值.從圖5(b)中可以看出,在出現蒸發器水量不足故障時,特征VE完全獨立于其他故障時的樣本值,即VE可以明確指示蒸發器水量不足故障;從圖5(c)可以看出,在出現冷凝器水量不足故障時,FWC完全獨立于其他故障時的樣本值,即FWC可以明確指示冷凝器水量不足故障;由圖5(d)可以發現,在特征TCA為13~17 ℃時,該特征可以明確指示系統中含有不凝性氣體,說明該特征對指示不凝性氣體故障有重要意義.采用同樣的分析方式可以發現,PO_net、PO_feed對指示冷凝器結垢、TO_sump對指示潤滑油過量均有重要意義.
5 結 論
特征選擇的結果表明,采用基于順序向前選擇算法的封裝模型,從64個原始特征中篩選出22個最佳表征特征.進一步分析所選擇的22個最佳表征特征發現,就所研究的7種典型故障而言,蒸發器側參數比冷凝器側參數更具表征性;FWC可以明確指示冷凝器水量不足故障;VE可以明確指示蒸發器水量不足故障;TCA對指示不凝性氣體故障有重要意義;PO_net、PO_feed對指示冷凝器結垢有重要意義;TO_sump對指示潤滑油過量有重要意義.表征特征一經選定,其余非表征性特征則不需要監控,從而大大減少了傳感器種類和數量,降低了初始投入成本.
參考文獻:
[1] 韓華,谷波,任能.基于主元分析與支持向量機的制冷系統故障診斷方法[J].上海交通大學學報:自然科學版,2011,45(9):1355-1361.
[2] 鮑士雄,陳麗萍.制冷系統故障診斷若干方法研究[J].制冷學報,1997(4):28-32.
[3] 馬鳴遠.人工智能與專家系統導論[M].北京:清華大學出版社,2007.
[4] 周平,錢積新.模糊推理方法在控制系統故障診斷中的應用研究[J].化工自動化及儀表,2005,32(1):23-25.
[5] 劉相艷,谷波,黎遠光.基于并行感知器的制冷系統故障診斷分析[J].上海交通大學學報:自然科學版,2005,39(8):1233-1239.
猜你喜歡
一重技術(2021年5期)2022-01-18 05:42:10
水泵技術(2021年3期)2021-08-14 02:09:20
裝備制造技術(2020年3期)2020-12-25 05:22:30
制造技術與機床(2018年11期)2018-11-23 01:07:42
電子制作(2018年10期)2018-08-04 03:24:46
制造技術與機床(2017年10期)2017-11-28 05:20:43
重慶工商大學學報(自然科學版)(2015年10期)2015-12-28 07:43:58
振動工程學報(2014年2期)2014-03-01 01:15:22
振動、測試與診斷(2014年5期)2014-03-01 01:14:21
振動、測試與診斷(2014年4期)2014-03-01 01:14:00
