一種基于數據劃分實現分布式SPARQL查詢的方法
2016-11-08 08:33:39杜方
計算機應用與軟件 2016年10期
杜 方
(寧夏大學數學計算機學院 寧夏 銀川 750021)
?
一種基于數據劃分實現分布式SPARQL查詢的方法
杜方
(寧夏大學數學計算機學院寧夏 銀川 750021)
當海量RDF數據存儲在分布式平臺上時,數據劃分的策略將直接影響海量數據的查詢效率。為了提高分布式平臺上的海量數據查詢效率,提出一種基于分布式平臺的有效數據劃分方法。該方法根據RDF數據圖的特征將數據分布在集群的各個節點上,并在此基礎上對SPARQL查詢語句進行分解,實現高效的分布式查詢。算法在云平臺上實現,并在真實的RDF數據集上對算法進行了測試。實驗結果證明,與基準方法相比,該算法在查詢效率上有很大的提高。
RDF數據SPARQL查詢分布式查詢數據劃分數據分布云平臺
0 引 言
隨著語義網的不斷發展,網絡上涌現出大量的RDF數據集,如Freebase[1]、DBPedia[2]、Linked Open Data[3]等。這些數據的RDF三元組的數量通常都在10億甚至百億以上,海量的數據為RDF數據查詢帶來了新的挑戰。SPARQL[4]查詢是W3C推薦的一種RDF數據查詢語言,它的語法與SQL語句的語法相似,但不包括from子句。目前效率最高的SPARQL查詢方法是由Neumann等人所提出的RDF-3X查詢引擎[5]。但RDF-3X是針對單個節點上的靜態RDF數據集所設計,該方法在RDF三元組的主語、謂詞和賓語上建立spo、sop、pso等六種順序的完備索引,在單個節點上將數據冗余存儲在六個B+樹結構中。完備的索引以及數據冗余在很大程度上提高了查詢效率,但是當面對海量、動態的RDF數據時,冗余的集中式存儲將成為瓶頸,RDF-3X的效率優勢將不復存在。
RDF-3X在集中式環境下實現RDF數據的查詢處理。早期的研究均采用集中式處理,例如3-store[6]、Sesame[7]、jena2[8]等,這些研究都采用傳統的關系數據庫存儲和管理RDF數據,借助關系數據庫的成熟技術實現對RDF數據的查詢。但傳統數據庫技術在處理海量數據查詢時效率低下,特別是RDF數據查詢中包含大量的自連接,這使得傳統方法無法有效處理查詢。
也有一些研究者提出了在分布式平臺上實現對海量RDF數據的處理,例如較早的方法YARS[9]將其方法擴展到分布式平臺上,提出了YARS2[10]方法;Stuckenschmidt等人也在文獻[11]中提出了分布式RDF查詢處理的方法。這兩種方法在分布式平臺的每個節點上仍采用關系數據庫存儲和管理RDF數據,因此仍然無法真正避免大量自連接帶來的問題。分布式平臺上的RDF查詢處理包括兩部分:數據分布和查詢分解。在文獻[12]中,Huang等人根據RDF圖將距離近的邊和點分布在一個機器節點上,查詢時根據謂詞將查詢語句分解成可并行的的子查詢,然后將子查詢提交至相關節點。文獻[13]首先按照謂詞對RDF數據進行垂直劃分,對于大的數據分布再按照賓語進行二次劃分。Myung等人[14]根據RDF圖結構直接將數據分布在云平臺上,文獻[15]按照鍵值對來分布數據。查詢時通常將SPARQL查詢語句分解為多個星型子查詢,然后將這些子查詢提交至相關節點進行處理。還有一些研究者考慮從查詢語句本身的特點對其進行分解。文獻[16]將鏈式SPARQL查詢語句分解為多個星型查詢,在分布式處理時每次迭代過程僅處理其中的一個星型子查詢,最后再將這些子查詢結果進行進一步處理。文獻[17]事先對常用的一些分析性查詢進行預定義,將出現頻率高的對應實體名稱預存至一張表,并在表上創建索引,這樣一些常用的查詢可以得到預先處理。但這些劃分方法均不考慮數據間的邏輯關系,數據較為平均地分布在各節點上。當進行復雜查詢時,仍然會產生大量的中間結果需要在多個節點中傳遞,從而影響查詢效率。
本文提出一種有效的RDF數據劃分策略。該方法根據RDF數據集所形成的圖的特征對數據進行劃分,數據分布在云平臺的各節點上,在考慮數據語義關系的同時兼顧節點間的負載平衡。處理查詢請求時,將查詢分解至語義相關的對應節點,而語義不相關的節點將不參與查詢處理。這樣利用數據分布裁剪查詢的搜索空間,在很大程度上減少了節點間的通信。對于一些簡單的SPARQL星型查詢,通常很少的節點甚至單個節點就可以實現查詢處理。對于分布式平臺上的數據處理,通信代價是影響處理效率的一個很大因素。本文提出的方法有效地減少了通信代價,提高了查詢效率。本文的主要貢獻在于:
1) 提出了一種有效的數據劃分方案。該方案根據RDF數據圖的特征實現數據劃分,然后依據數據分片的大小將其分布至云平臺的各個節點,分布時同時考慮各節點間的負載平衡。
2) 提出了一種查詢處理及優化的方法。該方法在數據劃分的基礎上,將查詢分解至相關節點,實現查詢的并行處理。
3) 在構造數據集和實際數據集上進行了實驗。實驗結果表明,本文所提出的方法能夠很好地提高查詢效率,證明了方法的有效性。
1 基于RDF數據圖的劃分策略
數據的劃分策略包括兩部分:一是如何將海量數據進行劃分,二是如何將這些劃分后的數據合理地分布至平臺中的各個計算機節點。本節將從這兩個方面來討論本文所提出的方法。
1) RDF數據圖
每條RDF數據都是一個形如

圖1 RDF數據圖
定義1實體的模式
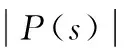
例如:圖1(b)中實體的模式為{borninplace,Awarded,YearofBirth,Researcharea}。RDF實體的模式在本文中也泛稱為RDF數據的模式。 一個實體的模式即為該實體對應圖中邊上的標記的集合,該集合反映了實體語義的核心內容。

2) 保持語義的數據劃分
分布式平臺上數據的劃分需要考慮兩個主要因素:機器的負載平衡和網絡通信總量[18]。為使機器負載平衡,需將數據盡可能地平均劃分,將其分布至分布式集群中的各個節點,但這樣劃分會使得查詢涉及很多節點,因此并不能保證節點間的通信總量盡可能少。若僅考慮網絡通信總量,則可將密集子圖放在同一機器節點,但這樣可能導致機器負載的極端不平衡。如果將一個機器節點上的數據稱為一個數據分片,并設查詢涉及的數據分片數量為N,則查詢的代價可用式(1)來衡量:

(1)

由于分布式計算的啟動代價和查詢計劃的生成代價相對固定, 因此α可看作常量。而執行查詢的代價主要與查詢的搜索空間大小、中間結果的大小以及機器節點間進行連接操作時的讀寫代價有關。中間結果的大小主要影響節點內的數據讀寫時間,在分布式環境下這部分代價可忽略不計;搜索空間的大小與數據分片的大小有直接關系;節點間連接操作的讀寫代價主要與查詢涉及的分片的數量有關,因此影響查詢代價的主要因素為查詢所涉及的數據分片的數量以及數據分片的大小。
RDF數據上的查詢為語義查詢。如果能夠結合數據語義對RDF數據集進行劃分,將語義相關的數據盡可能地劃分為同一個數據分片,那么將在很大程度上減少查詢相關分片的數量。因此需要找到一種保持語義的數據劃分方法實現RDF的數據分布。
RDF數據語義主要體現為實體的模式,例如從圖1(b)可以看出,實體AlbertEinstein的模式{borninplace,Awarded,YearofBirth,Researcharea}體現了該實體在數據集中的核心內容。為了保持語義,按照實體的模式對RDF數據集進行劃分,即相同模式的實體劃分在一起,模式對應圖中的邊,在劃分時以邊帶入鄰接點,則保證了語義的完整。但是RDF數據集中的數據來自于大量不同的網頁,因此實體的模式也多種多樣,即使是相同類型的數據也通常會有不完全相同的謂詞。如果直接按照模式對數據進行劃分,則會產生數量巨大的數據分片,無法將這些分片直接分布至有限的機器節點。通過數據分析發現,同類型或相似類型的RDF數據通常會有相似的模式[19]。根據文獻[19]中的方法,首先對RDF實體進行聚類,將模式相似的實體聚類到一起,聚類時的相似度取值是影響聚類結果的重要因素。RDF數據集中的實體數量大,若相似度太高,則得到的聚類數目太多,無法高效處理查詢;但若相似度太低,聚類中的不相關實體太多,同樣無法提高查詢效率,因此需要合理地設計相似度來控制聚類的數目。同時,若每個聚類中RDF三元組數量過多,則查詢時搜索空間可能過大,影響查詢效率。在文獻[19]中通過實驗給出了相似度閾值及聚類中三元組數目參數值,在本文的方法中我們仍然采用同樣的數值作為聚類參數,在保證每個聚類中實體足夠相似的基礎上控制聚類的大小。
算法1保持語義的RDF數據初次劃分方法SHRDFPA
輸入:待劃分的RDF數據集,DS
輸入:聚類的模式相似度閾值,?
輸入:每個聚類中包含的實體數量閾值,δ
輸出:初次劃分后的數據聚類集合R1,R2,…,Rn
1.將DS中每個RDF三元組的主語s作為key,謂詞p:賓語o作為value,即
2.將聚集后的實體集合中每個實體的謂詞集合P作為key,主語s作為value,即
3.對P中的實體按照所包含三元組的數量降序排列
4.將P1劃分至R1,R1寫入R集合,并令R(D1) =P1
5.forP集合中除P1外的每個Pido
6.forR集合中的每個Rjdo
7.if(Pi與P(Rj)的相似度≥? 并且Rj中的實體數量≤δ)
8.將Pi劃分至Rj
9.P(Rj) =P(Rj) ∪Pi
10.else新建一個Rk
11.將Pi劃分至Rk,
12.Rk寫入D集合
13.P(Rk) =Pi
14.endfor
15.endfor
16.輸出集合R
對于每個聚類結果Ri,將Ri中實體模式的并集作為Ri的模式,寫作P(R)。數據的初次劃分以Ri為單位,即每個Ri作為一個基本數據分片。算法1為云平臺上保持語義的RDF數據初次劃分方法。
算法第1行至第3行首先對待劃分的RDF數據集進行預處理,包括將數據集中的RDF三元組聚集為實體,并將模式相同的實體聚集為模式集合,然后將模式集合中的實體按照三元組數量進行降序排列。算法第4行首先將P1劃分至第一個聚類分片,在接下來的雙重循環中考查模式集合中的每個Pi。若該Pi與已有的聚類Rj的模式相似度大于閾值,并且該聚類中的實體數量小于閾值,則將Pi放入該聚類,否則Pi將放入新的聚類中(算法第5行至第15行)。
3) 數據分布策略
對于RDF數據集來說,劃分后的網絡通信總量主要與查詢時節點間的通信次數有關,若查詢時涉及的數據分片過多,則查詢時中間結果的讀寫會造成巨大的網絡通信代價。文獻[19]的實驗表明,對RDF數據集聚類后查詢涉及的聚類數目通常在較小范圍,因此可以考慮將一個聚類劃分為一個數據分片的方法,以此來減少網絡通信總量。但這樣的劃分方法會導致以下問題:(1)RDF數據集中存在較嚴重的數據傾斜問題,以BTC數據集為例,實體數量在前三位的聚類就占數據集實體總數的50%;如果直接將初次劃分的結果Ri作為數據分片分布至每個機器節點,會產生極大和極小的數據分片,造成機器負載的極端不平衡;(2) 在大的Ri上進行查詢處理時,由于搜索空間太大,不能有效地提高查詢效率;(3) 在大的Ri上建立和維護索引都較困難,數據的更新更會帶來不可忽視的代價,使得方法不具有良好的可擴展性。因此在數據分布時需要對數據量較大的Ri進行再劃分,而將較小的聚類進行組合,在減少通信代價的同時盡可能均衡機器負載。
設某個聚類Ri中的實體數量為NR,則當NR>φ時對Ri進行再劃分,φ為閾值,其值可由式(2)計算得到:
(2)
其中NE為RDF數據集中的實體總數,Np為云平臺中的機器節點數量,λ為(0,1]之間的可調規范化因子。λ的取值需要參照網絡帶寬w,當w較大時,并行時的通信代價小,則可將λ調小,反之則可將λ調大。再次劃分采用哈希劃分法:設有需要進行再劃分的聚類Ri,對Ri中RDF實體的主語進行哈希運算,實現再次分片得到劃分集合ρ。無需再次劃分的聚類與這些再次劃分后的每個ρj構成的集合將被分布在分布式平臺的各個機器節點上,屬于同一個R的ρj會被分配到不同機器節點上,同一個機器節點上的數據為一個數據分片D。劃分后的數據分片Di中所包含R的模式的并集為Di的模式,寫作P(D)。這樣的數據劃分及分布以實體為單位,同一個實體在同一個機器節點上,既保持了實體的語義,又保證了SPARQL查詢中的星型查詢能夠在單個節點上執行,同時使得涉及不同實體的查詢能夠盡可能并行執行,從而在很大程度上提高查詢效率。圖2為一個數據劃分與分布示意圖。

圖2 數據劃分與分布示意圖
2 查詢處理與優化
SPARQL查詢分為星型查詢和鏈式查詢,圖3(a)和(b)分別為星型查詢和鏈式查詢的例子。一個鏈式查詢可以分解為多個獨立的星型查詢,因此星型查詢是SPARQL查詢的基本查詢處理單位。來自用戶的鏈式查詢經過語法與語義處理后被重寫為多個星型查詢,這些星型查詢之間以s-o連接(o-o連接可以再分解為兩個星型查詢)。例如圖3(b)中的鏈式查詢可以分解為以?x、?y和?p為中心的三個星型查詢,這三個查詢間均以s-o連接。分解后的查詢由查詢優化器給出連接的先后順序。在執行查詢時,根據預先建立的謂詞倒排索引,按照查詢語句的謂詞集合將語句提交至查詢相關分片所在機器節點,并行處理后得到中間結果。

圖3 SPARQL查詢
定義2查詢相關分片
設有數據分片集合D及查詢q,q涉及到的謂詞集合為P(q),則查詢相關分片定義為{Di|Di∈D∩(P(Di)?P(q))}。
分布式平臺的每個機器節點上均配置RDF-3X查詢引擎,保證分解后的查詢語句能夠在每個節點上高效地執行。并行執行后的中間結果直接存儲在分布式平臺上,這樣既保證有節點故障時仍然能夠正確執行查詢,同時防止中間結果過大無法放入內存。
查詢優化器根據連接變量之間的沖突來決定連接的順序,無沖突的連接查詢可以并行執行,而有沖突的連接需要按照連接變量之間的依賴關系先后執行。例如圖3(b)中以?y為中心的星型查詢與以?p為中心的星型查詢之間無沖突,可并行執行;而以?y為中心的星型查詢與以?x中心的星型查詢之間有沖突,?y的執行依賴于?x的結果。此時一個可行的執行方案是首先得到?x的結果,然后并行執行以?p為中心和以?y為中心的星型查詢。
3 實驗分析
3.1實驗環境
實驗在8個機器節點組成的云平臺上進行,機器CPU均為Intel雙核1.86GHz,內存為3GB至8GB不等,分布式環境為Hadoop1.0.4,每個節點上裝載RDF-3X0.3.7。
實驗選取的真實RDF數據集為BTC(BillionTripleChallenge)[20],BTC數據集包含了來自DBPedia、Yago、Freebase等12個RDF數據集中的數據,共有超過32億的RDF三元組。該數據集中有95 898個不同的謂詞,經過去重、去噪音的初步處理后,保留其中10億多條三元組作為實驗數據。
用來進行對比實驗的RDF數據集為目前最為常用的測試數據集LUBM(LehighUniversityBenchmark)[21]。LUBM是以大學為本體的構造數據集,數據集的大小可根據用戶需求設置相關參數得到。本實驗中的LUBM數據集包含197 986個大學的相關信息,共11億條RDF三元組,其中包括18個謂詞、2.17億個實體。
3.2數據分布測試實驗
在這部分實驗中,我們采用三種方法對BTC數據集進行劃分,分別為直接哈希劃分、直接聚類劃分以及在聚類結果的基礎上進行再劃分。其中直接哈希劃分是指根據實體的主語進行哈希分布;直接聚類劃分是按照數據集的聚類結果進行數據分布;在聚類結果的基礎上進行再劃分是本文所提出的方法,三種方法的對比試驗結果如圖4所示。從實驗結果可以看出,直接哈希分布和直接聚類分布均會出現嚴重的數據傾斜問題,這是由于BTC數據集中的實體分布存在明顯的長尾現象。在前面的工作[19]中,對BTC中實體所包含三元組數量進行了統計,其中包含三元組最多的兩個實體占整個數據集三元組總數的30%,而用本文方法再劃分后,各節點上數據基本處于均衡狀態。

圖4 三種數據劃分方法比較
3.3查詢效率測試實驗
這部分實驗中,我們與目前在云平臺實現RDF數據查詢的方法MR-RDF[15]進行了比較,查詢實驗分別在BTC和LUBM兩個數據集上進行。
3.3.1LUBM上的查詢效率測試實驗
在LUBM上的查詢實驗共選取了8個查詢語句:Q1-Q8。這些查詢語句分為3組,其中查詢1、4為簡單的星型查詢,查詢2、6、7為包含一個s-o連接的鏈式查詢,查詢3、5、8為包含多個s-o連接的復雜鏈式查詢。實驗結果如表1所示,從實驗結果中可以看出本文方法總體查詢效率明顯優于MR-RDF。其中Q2、Q4、Q6-Q8查詢的效率比MR_RDF方法快10~30倍,其原因主要在于:1) 通過監控發現這幾個查詢均被分解至大于等于4個節點,這樣的分布保證了各節點間的負載均衡,并行度高;2) 由于分布均衡所以中間結果小,降低了通信代價;3) 從查詢語句本身來看,這幾個查詢均包含常見謂詞和賓語,利用聚類可以預先對搜索空間進行較大幅度裁剪,進一步提高查詢效率。本文方法在查詢Q3和Q5上的執行效率也要明顯優于MR-RDF。Q3和Q5中包含復雜的連接查詢,MR-RDF方法需要多次MapReduce迭代任務才能處理這樣的查詢。而我們的方法直接在云平臺上通過節點調度實現分布式處理,減少了MapReduce的任務啟動時間,因此提高了查詢效率。Q1為簡單的星型查詢,且其結果集較大,本文方法和MR-RDF都需要大量的時間向HDFS寫結果數據,因此本文方法和MR-RDF方法相比,效率只是稍有提高。

表1 LUMB上的查詢效率測試結果(單位:秒)
3.3.2BTC上的查詢效率測試實驗
BTC上的查詢語句也分為三組(具體語句見附錄中查詢Q9-Q15),其中Q9和Q11為僅包含一個s-o連接的鏈式查詢,Q10和Q13為包含未知謂詞的查詢,Q12、Q14和Q15為包含多個連接的復雜鏈式查詢。實驗結果如表2所示,同樣從實驗結果可以看出,在真實數據集BTC上,本文方法要明顯優于MR-RDF。
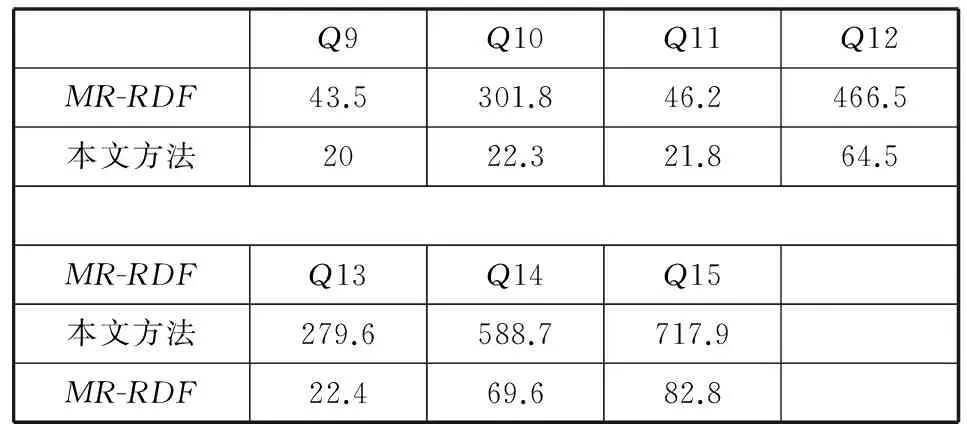
表2 BTC上的查詢效率測試結果(單位:秒)
由于BTC數據集中的謂詞數量比LUBM多,因此查詢時的中間結果遠小于LUBM上的查詢。從總體查詢結果中可以看出,BTC上的查詢時間明顯小于LUBM上的查詢時間。特別是Q10和Q13由于中間結果很小,因此本文方法遠遠優于MR-RDF。
3.4可擴展性測試實驗
為了測試方法的可擴展性,我們在實驗中分別改變LUBM數據集的大小和云平臺中節點的數目,圖5為預處理(包括數據劃分和分布)的時間對比。

圖5 預處理的時間對比結果
圖5(a)所示為改變云平臺中的節點數量,測試在不同節點數量下預處理時間的變化。圖5(b)是在節點數目為20,數據量為50GB時,與文獻[12]中的方法進行預處理時間的對比。從(a)實驗結果可以看出,當云平臺中節點數量增加時,預處理時間大量減少。(b) 的實驗結果表明,當數據大小和節點數目固定時,本文的方法預處理時間遠遠小于文獻[12]中的方法。這是因為文獻[12]對數據進行預處理的時間主要用在三元組的分布,圖劃分方法的復雜導致數據分布耗費大量時間,而本文的方法相對簡單,因此在時間上有很大提高。
圖6給出了處理復雜查詢Q5的效率,并與文獻[14]中的方法進行了對比。

圖6 可擴展性實驗——與文獻[14]對比
Q5為包含多個連接的復雜查詢,從實驗結果可以看出,當云平臺中節點數量從2增加至32個時,本文的方法在查詢處理效率上有顯著的提高。同時對比文獻[14]中的MRLUBM方法,本文的方法整體優于MRLUBM。這是因為首先隨著節點數量的增加,數據可以分布在更多的節點上,更好實現并行,同時有效減少中間結果的大小,因此查詢時間呈明顯的下降趨勢。而MRLUBM在進行查詢處理時需要不可忽視的MapReduce啟動時間,因此在整體上所需的查詢處理時間較多。圖5和圖6的實驗均證明了本文方法具有良好的可擴展性。
4 結 語
本文提出了一種有效的基于云平臺的RDF數據劃分方法,該方法在對數據劃分時既保持了RDF數據的語義特征,又保證數據分布的均衡性。實驗證明,本文方法能夠有效提高查詢效率,并具有良好的可擴展性。總體上來說,本文方法主要受中間結果影響,中間結果較小時,本文方法在查詢效率上具有明顯優勢;而當中間結果大時,由于需要大量的I/O時間和節點間的通信代價,本文方法雖仍然優于對比方法,但效果不夠明顯。因此未來的工作將進一步針對中間結果較大的查詢進行研究和方法改進。
[1]Freebase[OL] .2015-1-6.http://www.freebase.com/.
[2]DBPedia[OL].2015-1-6.http://dbpedia.org/.
[3]LinkedOpenData[OL].2015-1-8.http://linkeddata.org/.
[4]SPARQL[OL].2015-1-30.http://www.w3.org/TR/rdf-sparql-query/.[5]NeumannT,WeikumG.RDF-3X:arisc-styleengineforRDF[C]//Proceedingsofthe34thInternationalConferenceonVeryLargeDataBases,Auckland,NewZealand,2008.USA:ACM,2008,1(1):647-659.
[6]HarrisS,GibbinsN.3store:Efficientbulkrdfstorage[C]//Proceedingsofthe1stInternationalWorkshoponPracticalandScalableSemanticSystems,SanibelIsland,2003.USA:CEUR-WSpress,2003,89:1-15.
[7]BroekstraJ,KampmanA,HarmelenFV.Sesame:agenericarchitectureforstoringandqueryingrdfandrdfschema[C]//InternationalSemanticWebConference,Sardinia,Italy2002.London:Springer,2002:54-68.
[8]WilkinsonK,SayersC,KunoHA,etal.EfficientRDFstorageandretrievalinjena2[C]//ThefirstinternationalworkshoponSemanticWebandDatabases,Berlin,Germany,2003:131-150.
[9]HarthA,DeckerS.Optimizedindexstructuresforqueryingrdffromtheweb[C]//Proceedingsofthe3rdLatinAmericanWebCongress,BuenosAires,Argentina,2005.USA:IEEEComputerSociety,2005:71-80.
[10]HarthA,UmbrichJ,HoganA,etal.Yars2:afederatedrepositoryforqueryinggraphstructureddatafromtheweb[C]//Proceedingsofthe6thInternationalSemanticWebConference(ISWC)andthe2ndAsianSemanticWebConference(ASWC),Busan,Korea, 2007.Berlin:Springer,2007:211-224.
[11]StuckenschmidtH,VdovjakR,HoubenGJ,etal.IndexstructuresandalgorithmsforqueryingdistributedRDFrepositories[C]//Proceeingsofthe13thInternationalConferenceonWorldWideWeb,NewYork,USA, 2004.USA:ACMPress,2004:631-639.
[12]HuangJW,AbadiDJ,RenK.Scalablesparqlqueryingoflargerdfgraphs[C]//ProceedingsoftheVLDBEndowment,Seattle,USA,2011,4(11):1123-1134.
[13]TranT,WangHF,HaaseP.Hermes:datawebsearchonapay-as-you-gointegrationinfrastructure[J].WebSemantics:Science,ServicesandAgentsontheWorldWideWeb,2009,7(3):189-203.
[14]MyungJ,YeonJ,LeeSG.Sparqlbasicgraphpatternprocessingwithiterativemapreduce[C]//Proceedingsofthe2010WorkshoponMassiveDataAnalyticsontheCloud,Raleigh,USA, 2010.USA:ACMpress,2010:1-6.
[15]HusainMF,McGlothlinJP,MasudMM,etal.Heuristics-basedqueryprocessingforlargeRDFgraphsusingcloudcomputing[J].IEEETransactionsonKnowledgeandDataEngineering,2011,23(9):1312-1327.
[16]KimH,RavindraP,AnyanwuK.FromSPARQLtomapreduce:thejourneyusinganestedtriplegroupalgebra[C]//ProceedingsoftheVLDBEndowment,Seattle,USA,2011,4(12):1426-1429.
[17]KotoulasS,UrbaniJ.SPARQLqueryansweringonasharednothingarchitecture[C]//ProceedingsoftheWorkshoponSemanticDataManagement,the36thInternationalConferenceonVeryLargeDataBases(SemData@VLDB2010),Singapore, 2010.USA:CEUR-WSpress,2010:1-6.
[18] 張俊林.大數據日知錄:架構與算法 [M].北京:電子工業出版社,2014.
[19]DuF,ChenYG,DuXY.Partitionedindexesforentitysearchoverrdfknowledgebases[C]//Proceedingsofthe17thInternationalConferenceonDatabaseSystemsforAdvancedApplications,Busan,SouthKorea,2012.Berlin:Springer,2012:141-155.
[20]BillionTripleChallenge[OL].2015-2-1.http://challenge.semanticweb.org/.
[21]GuoYB,PanZX,HeflinJ.Lubm:abenchmarkforOWLknowledgebasesystems[J].WebSemantics:Science,ServicesandAgentsontheWorldWideWeb,2005,3(2-3):158-182.
AN APPROACH FOR IMPLEMENTING DISTRIBUTED SPARQL QUERY BASED ON DATA PARTITION
Du Fang
(School of Mathematics and Computer Science,Ningxia University,Yinchuan 750021,Ningxia,China)
When billions of RDF data are stored on distributed platform, the strategy of data partitioning is to directly affect the efficiency of massive data query. In order to improve the query efficiency on distributed platform, we proposed a distributed platform-based efficient data partitioning method. The method places data onto each node in computer cluster according to the feature of RDF data chart, and parses SPARQL query sentence on this basis to achieve efficient distributed query. The algorithm was implemented on cloud computing platform, and has been tested on real RDF dataset. Experimental results demonstrated that the method introduced in the paper achieved great improvement in query efficiency compared with benchmark method.
RDF dataSPARQL queryDistributed queryData partitioningData placementCloud computing platform
2015-04-22。國家自然科學基金項目(61363018)。杜方,副教授,主研領域:智能信息管理,數據庫技術。
TP311
A
10.3969/j.issn.1000-386x.2016.10.006
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
兒童故事畫報(2019年5期)2019-05-26 14:26:14
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
