高校科研信息管理中設(shè)備推薦系統(tǒng)算法分析
2016-11-09 02:30:31楊紫曦徐建良
網(wǎng)絡(luò)安全與數(shù)據(jù)管理 2016年16期
關(guān)鍵詞:化學(xué)實(shí)驗(yàn)
楊紫曦,徐建良
(中國(guó)海洋大學(xué) 信息科學(xué)與工程學(xué)院,山東 青島 266100)
?
高校科研信息管理中設(shè)備推薦系統(tǒng)算法分析
楊紫曦,徐建良
(中國(guó)海洋大學(xué) 信息科學(xué)與工程學(xué)院,山東 青島 266100)
針對(duì)當(dāng)前高校科研管理實(shí)際,研究對(duì)比了多種主流數(shù)據(jù)挖掘推薦算法的適用性,挑選出適合設(shè)備數(shù)據(jù)條件的推薦算法,并進(jìn)行算法實(shí)際使用分析。最后,將基于內(nèi)容過(guò)濾的推薦算法、基于用戶(hù)的協(xié)同過(guò)濾的推薦算法和基于條目的Slope One算法結(jié)合使用,互相補(bǔ)充,實(shí)現(xiàn)算法各性能的提高,完成高質(zhì)量的推薦。
推薦算法;數(shù)據(jù)挖掘;設(shè)備推薦
引用格式:楊紫曦,徐建良.高校科研信息管理中設(shè)備推薦系統(tǒng)算法分析[J].微型機(jī)與應(yīng)用,2016,35(16):16-19.
0 引言
近年來(lái)國(guó)內(nèi)高校信息技術(shù)的應(yīng)用發(fā)展迅速,對(duì)高校的科研管理的要求越來(lái)越高。為了更有效地管理和規(guī)范高校科研資源,實(shí)現(xiàn)教師和專(zhuān)家的有效、便捷使用,助力科研水平的提升,信息技術(shù)在高校科研管理中充當(dāng)非常重要的作用。
教師和專(zhuān)家根據(jù)項(xiàng)目需求進(jìn)行設(shè)備申購(gòu)采備時(shí),需要花大量的時(shí)間和精力來(lái)進(jìn)行設(shè)備挑選工作。對(duì)比各種相似設(shè)備的區(qū)別和各項(xiàng)指標(biāo),斟其利弊,才能決定所要購(gòu)買(mǎi)的設(shè)備,大大延誤了科研時(shí)間。
因此,本文比較各種推薦算法的優(yōu)勢(shì)、劣勢(shì)、可行性并結(jié)合專(zhuān)家設(shè)備系統(tǒng)的特性進(jìn)行選擇,最終確定將三種過(guò)濾算法結(jié)合使用,同時(shí)進(jìn)行算法實(shí)際使用的分析。
1 數(shù)據(jù)挖掘與推薦系統(tǒng)
1.1數(shù)據(jù)挖掘
數(shù)據(jù)挖掘(Date Mining)就是從大量的、不完全的、有噪聲的、模糊的、隨機(jī)的實(shí)際應(yīng)用數(shù)據(jù)中,提取隱含在其中的、人們事先不知道但又是潛在有用的并最終可理解的信息和知識(shí)的非平凡過(guò)程[1]。這些知識(shí)中包含了概念、規(guī)則等內(nèi)容。數(shù)據(jù)挖掘是一門(mén)綜合性的技術(shù),它包括了機(jī)器學(xué)習(xí)、數(shù)據(jù)庫(kù)、統(tǒng)計(jì)學(xué)、數(shù)據(jù)可視化等多個(gè)研究領(lǐng)域。數(shù)據(jù)挖掘從海量數(shù)據(jù)中獲取有用的知識(shí),其處理的數(shù)據(jù)各不相同,可能有確定格式,或者是無(wú)確切格式。例如,處理數(shù)據(jù)庫(kù)中的數(shù)據(jù)時(shí),數(shù)據(jù)是有條理有格式的,而網(wǎng)絡(luò)上的文章、音樂(lè)、視頻卻是格式各異、無(wú)確定形式的。因此需要使用不同的解決方式。數(shù)據(jù)挖掘涉及各種領(lǐng)域的科學(xué)方法,如聚類(lèi)方法、關(guān)聯(lián)分析、協(xié)同過(guò)濾、神經(jīng)網(wǎng)絡(luò)等。所以,數(shù)據(jù)挖掘是在大量模糊數(shù)據(jù)但是蘊(yùn)含一定真實(shí)知識(shí)數(shù)據(jù)的基礎(chǔ)上,排除其模糊、干擾,從中提取出有用且確切的知識(shí)數(shù)據(jù)的過(guò)程[2]。
1.2推薦系統(tǒng)
推薦系統(tǒng)是使用數(shù)據(jù)挖掘的良好實(shí)踐,是針對(duì)用戶(hù)的有針對(duì)性挖掘。推薦系統(tǒng)通過(guò)處理用戶(hù)的行為數(shù)據(jù)、推測(cè)用戶(hù)的行為習(xí)慣、歷史偏好,依據(jù)一定的約定與規(guī)律,將待推薦條目推薦給用戶(hù)。因?yàn)檫@種行為是系統(tǒng)主動(dòng)發(fā)起的,不需要用戶(hù)自己輸入關(guān)鍵詞,所以與傳統(tǒng)搜索系統(tǒng)大不相同。系統(tǒng)通過(guò)不斷的信息收納與機(jī)器學(xué)習(xí),建立算法推薦模型,然后利用這個(gè)模型來(lái)推測(cè)用戶(hù)的興趣偏好,從而在已有的條目中選擇偏好程度較高的若干條目推薦給用戶(hù)。評(píng)分推薦是一種比較可靠的推薦模式,個(gè)性化定制推薦可以概括成對(duì)用戶(hù)未評(píng)分過(guò)的條目的評(píng)分估計(jì)問(wèn)題,最終得出的推薦列表是一個(gè)以系統(tǒng)評(píng)估分?jǐn)?shù)排序的條目集合。對(duì)于那些沒(méi)有考慮評(píng)分的系統(tǒng),系統(tǒng)會(huì)根據(jù)用戶(hù)信息、用戶(hù)歷史行為痕跡來(lái)推測(cè)用戶(hù)興趣偏好較高的多個(gè)條目,最終產(chǎn)生一個(gè)推薦結(jié)果。
不同推薦系統(tǒng)的推薦過(guò)程是不一樣的,它們會(huì)采取不同的處理方式來(lái)處理不同的數(shù)據(jù)源信息,推薦系統(tǒng)產(chǎn)生推薦結(jié)果后,利用各種形式展現(xiàn)給用戶(hù),如果用戶(hù)滿(mǎn)意度比較高,大大便利了用戶(hù)的使用,則用戶(hù)會(huì)非常樂(lè)意使用這個(gè)系統(tǒng),時(shí)間一長(zhǎng)會(huì)對(duì)系統(tǒng)產(chǎn)生使用慣性,產(chǎn)生良好的使用效果。
2 高校科研信息管理中設(shè)備推薦系統(tǒng)算法分析
2.1數(shù)據(jù)規(guī)模與算法依據(jù)分析
高校科研設(shè)備管理系統(tǒng)數(shù)據(jù)結(jié)構(gòu)不同于網(wǎng)上購(gòu)物平臺(tái)。我校設(shè)備管理系統(tǒng)中存在4 000多個(gè)教師用戶(hù),以及近三萬(wàn)條設(shè)備申購(gòu)記錄和相關(guān)信息(包括千余個(gè)設(shè)備、設(shè)備參數(shù)、供應(yīng)商等),并涉及9 000多個(gè)項(xiàng)目信息。關(guān)聯(lián)的科技處管理系統(tǒng)里還有教師成果如論文、專(zhuān)利在內(nèi)的近萬(wàn)條數(shù)據(jù)可供使用。數(shù)據(jù)庫(kù)中有超過(guò)460 MB的信息。
所有的設(shè)備申購(gòu)記錄中存在這樣的特點(diǎn):(1)設(shè)備的特殊性,設(shè)備不同于商品,購(gòu)買(mǎi)量和價(jià)格普遍高于網(wǎng)絡(luò)購(gòu)物平臺(tái)的商品,購(gòu)買(mǎi)原因不只是愛(ài)好更是因?yàn)轫?xiàng)目需求以及工作需要,所以應(yīng)該另行分析。(2)數(shù)據(jù)稀疏性問(wèn)題,各專(zhuān)家申購(gòu)數(shù)量差距較大,部分教師只有極少的申購(gòu)數(shù)量甚至沒(méi)有申購(gòu)。(3)專(zhuān)家差異性,各專(zhuān)家教師所屬學(xué)科背景差異較大,所申購(gòu)的設(shè)備可能毫無(wú)共性和推薦價(jià)值。所以,在推薦算法的選取中必須結(jié)合高校設(shè)備管理系統(tǒng)的數(shù)據(jù)結(jié)構(gòu)和數(shù)據(jù)特點(diǎn)來(lái)做針對(duì)性的推薦。
以下對(duì)各種算法的可行性和適應(yīng)性進(jìn)行分析。
使用基于關(guān)聯(lián)規(guī)則的推薦算法時(shí),由于數(shù)據(jù)量的不足,系統(tǒng)通過(guò)數(shù)據(jù)分析后難以準(zhǔn)確得出專(zhuān)家對(duì)設(shè)備的關(guān)聯(lián)興趣結(jié)果,關(guān)聯(lián)規(guī)則集合R完成度低。由于最小支持度和最小置信度的限制,部分較冷門(mén)設(shè)備不能進(jìn)入關(guān)聯(lián)規(guī)則集,限制了推薦的召回率。基于關(guān)聯(lián)規(guī)則的推薦對(duì)專(zhuān)家之間和設(shè)備之間的關(guān)系分析較少,推薦的針對(duì)性不足。
基于內(nèi)容過(guò)濾的推薦需要從基礎(chǔ)數(shù)據(jù)中挖掘出設(shè)備的相似度。由于科研系統(tǒng)中設(shè)備跨度小,屬于同一范疇的設(shè)備較多,所以那些與專(zhuān)家用戶(hù)興趣偏好相似的設(shè)備很容易就出現(xiàn)在推薦列表中,而且大部分專(zhuān)家用戶(hù)的興趣偏好比較穩(wěn)定,具有明確的設(shè)備申購(gòu)方向,推薦效果會(huì)非常出色,能夠起到很好的個(gè)性化推薦的作用,所以本文的設(shè)備推薦系統(tǒng)將會(huì)應(yīng)用基于內(nèi)容過(guò)濾的推薦方法。
在高校設(shè)備管理系統(tǒng)實(shí)際使用中,經(jīng)常會(huì)有這樣的情況:部分專(zhuān)家用戶(hù)的申購(gòu)可能會(huì)出現(xiàn)與已購(gòu)設(shè)備相差較大的設(shè)備,其興趣遍布較廣,不局限于某幾種類(lèi)型。這種情況使用基于內(nèi)容過(guò)濾推薦將無(wú)法完成較好的推薦。所以,增加基于協(xié)同過(guò)濾的推薦算法將會(huì)產(chǎn)生很好的效果。
基于協(xié)同過(guò)濾的推薦算法根據(jù)挖掘的數(shù)據(jù)信息并有效利用專(zhuān)家與專(zhuān)家、設(shè)備與設(shè)備之間的聯(lián)系進(jìn)行推薦。
通過(guò)基于用戶(hù)的協(xié)同過(guò)濾挖掘?qū)<遗c專(zhuān)家之間的相似性,找到興趣相似的專(zhuān)家用戶(hù)群,利用近鄰的興趣偏好進(jìn)行推薦,成功解決部分專(zhuān)家興趣遍布廣泛?jiǎn)栴},為專(zhuān)家推薦新設(shè)備。
引入基于條目的協(xié)同過(guò)濾算法能挖掘出各設(shè)備與設(shè)備的潛在關(guān)聯(lián),不僅計(jì)算效率高,也能解決稀疏性和冷啟動(dòng)的問(wèn)題。
2.2各算法實(shí)際使用分析
2.2.1基于關(guān)鍵詞的內(nèi)容過(guò)濾設(shè)備推薦算法
專(zhuān)家和設(shè)備使用相同的詞庫(kù),各自對(duì)應(yīng)多個(gè)關(guān)鍵詞,專(zhuān)家的興趣關(guān)鍵詞和設(shè)備的特征關(guān)鍵詞之間的相似度是該算法的關(guān)鍵。關(guān)鍵詞模型舉例如圖1所示。
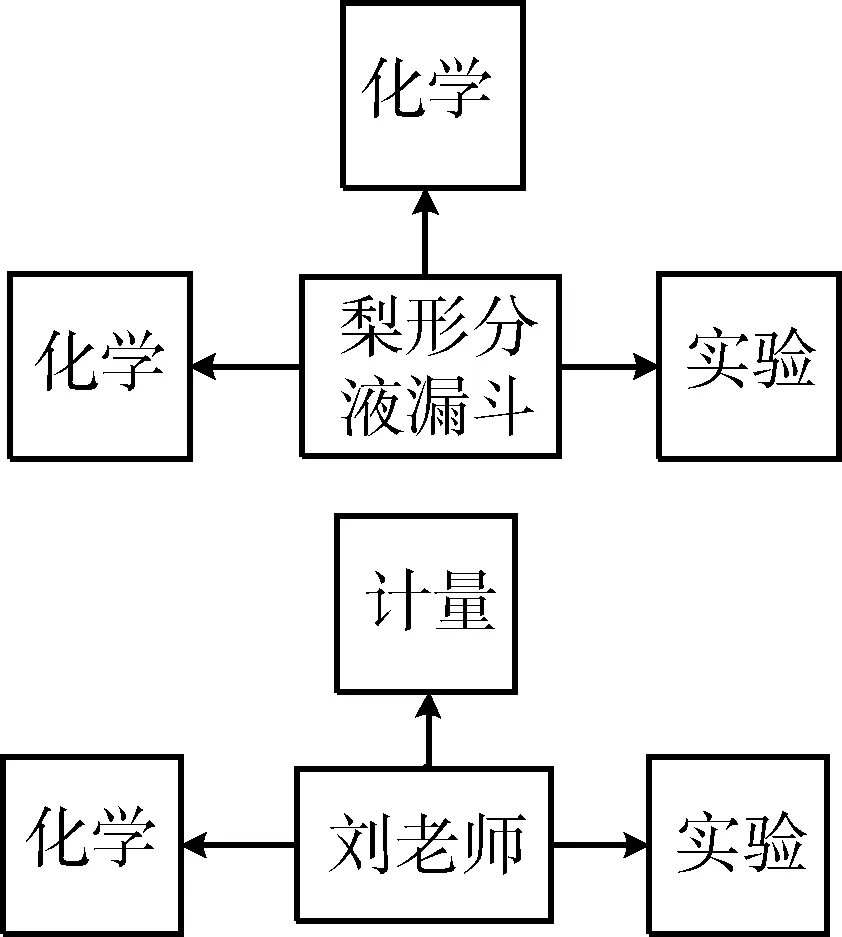
圖1 關(guān)鍵詞模型舉例
圖1中,“化學(xué)”、“實(shí)驗(yàn)”關(guān)鍵詞通過(guò)設(shè)備的特征信息或者專(zhuān)家的基本信息獲取,也有部分來(lái)自于專(zhuān)家或者管理員的手動(dòng)標(biāo)記。設(shè)備“ 梨形分液漏斗”的關(guān)鍵詞為“化學(xué)”、“實(shí)驗(yàn)”。“梨形分液漏斗”被“化學(xué)”標(biāo)記過(guò)兩次,與兩個(gè)“化學(xué)”關(guān)鍵詞相連。劉老師被三個(gè)關(guān)鍵詞標(biāo)記過(guò):“化學(xué)”、“實(shí)驗(yàn)”、“計(jì)量”各一次。
標(biāo)注的次數(shù)之和為各關(guān)鍵詞的權(quán)重分值。可知,“梨形分液漏斗”的關(guān)鍵詞“化學(xué)”、“實(shí)驗(yàn)”其權(quán)重為2和1。專(zhuān)家劉老師的三個(gè)關(guān)鍵詞“化學(xué)”、“實(shí)驗(yàn)”、“計(jì)量”權(quán)重都為1。
對(duì)上述分析進(jìn)行數(shù)學(xué)抽象:
E={J1,J2…,Jn}
D={K1,K2…,Kn}
在上述公式中,E和D分別為專(zhuān)家特征向量和設(shè)備特征向量。Ki為關(guān)鍵詞的權(quán)重分值。
得到專(zhuān)家和設(shè)備的特征向量之后,需要求得之間的相似關(guān)系,可利用余弦公式:
(1)
得出相似關(guān)系,將相似度最高的Top-N作為推薦結(jié)果,完成基于內(nèi)容過(guò)濾的設(shè)備推薦。
2.2.2基于專(zhuān)家用戶(hù)的協(xié)同過(guò)濾設(shè)備推薦算法
基于用戶(hù)的協(xié)同過(guò)濾的核心依據(jù)是:某一部分愛(ài)好相同的用戶(hù)有很大可能性對(duì)其他東西興趣偏好也類(lèi)似。
基于專(zhuān)家用戶(hù)的協(xié)同過(guò)濾推薦算法步驟為:通過(guò)最近鄰查詢(xún)找到專(zhuān)家的相似專(zhuān)家群,利用相似專(zhuān)家群的評(píng)價(jià)來(lái)推測(cè)該專(zhuān)家的評(píng)價(jià),對(duì)最近鄰集合進(jìn)行改進(jìn),得出的結(jié)果由后續(xù)Slope One算法使用。
基于用戶(hù)的協(xié)同過(guò)濾推薦算法的主要目標(biāo)包括:用戶(hù)數(shù)據(jù)建模、用戶(hù)相似度計(jì)算及專(zhuān)家相似群的歸類(lèi)和評(píng)價(jià)的推測(cè)。
(1)專(zhuān)家設(shè)備評(píng)價(jià)矩陣的生成
具體實(shí)現(xiàn)步驟如下:
①?gòu)臄?shù)據(jù)庫(kù)ExpertDeviceCount表中獲取單個(gè)專(zhuān)家的申購(gòu)數(shù),將申購(gòu)數(shù)轉(zhuǎn)化為評(píng)分值,建立用戶(hù)的設(shè)備評(píng)分偏好特征向量,評(píng)分計(jì)算公式如式(2)所示:
Score(e,d)=ln(1+Be,d)
(2)
式(2)中,Score(e,d)為評(píng)分函數(shù),即為專(zhuān)家e對(duì)設(shè)備d的評(píng)分。Be,d為專(zhuān)家e對(duì)設(shè)備d的申購(gòu)量。
②重復(fù)上述步驟,計(jì)算每個(gè)專(zhuān)家的設(shè)備評(píng)分偏好特征向量。
③以每一個(gè)設(shè)備評(píng)分偏好特征向量為行構(gòu)建設(shè)備評(píng)分矩陣。
(2)用戶(hù)相似度計(jì)算和專(zhuān)家相似群歸類(lèi)
具體實(shí)驗(yàn)步驟如下:
①?gòu)膶?zhuān)家設(shè)備評(píng)分矩陣中每一行取出得到專(zhuān)家的設(shè)備興趣偏向評(píng)分特征向量。
②將當(dāng)前專(zhuān)家的設(shè)備評(píng)分特征向量與同一聚類(lèi)中所有其他專(zhuān)家的評(píng)分特征向量求相似,利用余弦公式(1),得到當(dāng)前專(zhuān)家與聚類(lèi)中所有專(zhuān)家的相似度。
③將聚類(lèi)中所有專(zhuān)家按其與當(dāng)前專(zhuān)家的相似度高低從大到小排序。
④從排序列表中取出前N名專(zhuān)家作為最近鄰專(zhuān)家群。
(3)改進(jìn)生成最近鄰集合
具體實(shí)驗(yàn)步驟如下:
①將項(xiàng)目成果參與矩陣每一行取出,表示專(zhuān)家項(xiàng)目成果參與向量。
②遍歷計(jì)算聚類(lèi)中其余所有專(zhuān)家項(xiàng)目成果參與向量與當(dāng)前專(zhuān)家的相似度。相似度計(jì)算參照公式(1)。
③將結(jié)果按相似度大小排序。
④取出前N位加入最近鄰集合中。
2.2.3基于設(shè)備條目的協(xié)同過(guò)濾設(shè)備推薦Slope One算法
利用基于專(zhuān)家用戶(hù)的協(xié)同過(guò)濾,得出最近鄰集合,在給出一個(gè)初步推薦后,將利用Slope One算法給出最終推薦。
(1)得到初步推薦結(jié)果
采用基于用戶(hù)的協(xié)同過(guò)濾算法,得到初步推薦結(jié)果。
(3)
(2)計(jì)算近鄰用戶(hù)平均相似性
因?yàn)楹罄m(xù)計(jì)算將專(zhuān)家的相似值與Slope One算法融合計(jì)算,所以需要計(jì)算最近鄰集合中用戶(hù)與當(dāng)前用戶(hù)的平均相似度,生成“用戶(hù)-項(xiàng)目”相似度矩陣。計(jì)算公式如式(4)所示:
(4)其中v表示除了專(zhuān)家e以外的其他申購(gòu)過(guò)設(shè)備d的專(zhuān)家;sim(e,v)表示專(zhuān)家e與專(zhuān)家v的相似度;Ud表示所有申購(gòu)過(guò)設(shè)備d的用戶(hù)數(shù)。由于Ud中包括當(dāng)前專(zhuān)家e,因此減去1。
(3)計(jì)算項(xiàng)目平均偏差矩陣
要運(yùn)用Slope One算法還需知道設(shè)備之間的平均偏差,構(gòu)建平均偏差矩陣。平均偏差計(jì)算公式如式(5)所示:
(5)
其中,ej、ei表示專(zhuān)家e對(duì)設(shè)備j和設(shè)備i的購(gòu)買(mǎi)次數(shù),Sj,i(x)表申購(gòu)過(guò)設(shè)備i、j的專(zhuān)家集合,card(Sj,i(x))表示專(zhuān)家集合數(shù)量。
設(shè)備平均偏差描述的是同時(shí)申購(gòu)過(guò)這一設(shè)備的兩專(zhuān)家的數(shù)量偏差,偏差越小,表明兩專(zhuān)家對(duì)這一設(shè)備的需求量越接近。
(4)預(yù)測(cè)用戶(hù)對(duì)目標(biāo)項(xiàng)目的評(píng)分
求出設(shè)備間的平均偏差之后,根據(jù)加權(quán)Slope One算法公式可以對(duì)專(zhuān)家進(jìn)行當(dāng)前設(shè)備的評(píng)分預(yù)測(cè)。
加權(quán)Slope One算法的出發(fā)點(diǎn)是以共同申購(gòu)過(guò)兩個(gè)設(shè)備的專(zhuān)家數(shù)量作為權(quán)重,雖有一定的精確度提高,但是忽略了專(zhuān)家用戶(hù)的相似度。下面分析專(zhuān)家用戶(hù)的相似度對(duì)Slope One算法預(yù)測(cè)結(jié)果影響。
假如同時(shí)有40個(gè)專(zhuān)家對(duì)設(shè)備i和設(shè)備j購(gòu)買(mǎi)數(shù)相同,用專(zhuān)家集cij表示,同樣,也有40名專(zhuān)家對(duì)項(xiàng)目i和q購(gòu)買(mǎi)數(shù)量相同,用cik表示。這種情況下,使用加權(quán)Slope One算法預(yù)測(cè)購(gòu)買(mǎi)數(shù)是相同的。但是cij和cik的平均相似度不相等,若cij大于cik很多的話,其參考意義更大[3]。
所以本文加入專(zhuān)家相似度的影響,綜合Slope One算法來(lái)給出最終預(yù)測(cè)。利用之前所計(jì)算的設(shè)備評(píng)分偏差和專(zhuān)家平均相似性,由式(6)得到基于協(xié)同過(guò)濾設(shè)備的推薦結(jié)果,即評(píng)分值:
(6)
其中,S(e,i)表示專(zhuān)家間的平均相似度。
2.3生成推薦結(jié)果
上述各步驟給出了加入專(zhuān)家相似度的加權(quán)Slope One算法推薦設(shè)備評(píng)分,將按照評(píng)分給出基于兩種協(xié)同過(guò)濾推薦算法的結(jié)合推薦結(jié)果。
使用Top-N方法,根據(jù)預(yù)測(cè)評(píng)分將設(shè)備進(jìn)行排序,選擇評(píng)分最高的前N臺(tái)設(shè)備加入最終推薦列表。
2.4對(duì)推薦結(jié)果進(jìn)行匯總
最終的推薦列表包括基于關(guān)鍵詞內(nèi)容過(guò)濾的推薦結(jié)果和基于兩種協(xié)同過(guò)濾設(shè)備推薦的推薦結(jié)果。基于關(guān)鍵詞內(nèi)容過(guò)濾的算法結(jié)果為專(zhuān)家與設(shè)備的相似度值sime,d(e,d),基于協(xié)同過(guò)濾的推薦算法結(jié)果為評(píng)分值p(e)j。為得到最終匯總結(jié)果,需再進(jìn)行一次關(guān)于設(shè)備專(zhuān)家相似度的結(jié)合。如式(7)所示:
p(e,d)j=sime,j(e,j)×p(e)j
(7)
其中p(e)j為基于協(xié)同過(guò)濾算法得出的當(dāng)前專(zhuān)家對(duì)設(shè)備j的評(píng)分。
按照p(e,d)j的大小從高到低進(jìn)行排序,最終得到輸出給專(zhuān)家的推薦結(jié)果列表。
3 結(jié)論
基于內(nèi)容過(guò)濾的推薦需要從基礎(chǔ)數(shù)據(jù)中挖掘出設(shè)備的相似度,由于科研系統(tǒng)中設(shè)備跨度小,屬于同一范疇的設(shè)備較多,因此那些與專(zhuān)家用戶(hù)興趣偏好相似的設(shè)備很容易就出現(xiàn)在推薦列表中,而且大部分專(zhuān)家用戶(hù)的興趣偏好比較穩(wěn)定,具有明確的設(shè)備申購(gòu)方向,推薦效果會(huì)非常出色,能夠很好地起到個(gè)性化推薦的作用
高校設(shè)備管理系統(tǒng)整體購(gòu)買(mǎi)量較大,設(shè)備數(shù)據(jù)量較大,直接使用基于設(shè)備條目的協(xié)同過(guò)濾遍歷整個(gè)申購(gòu)數(shù)據(jù)計(jì)算量過(guò)大,效率很低,所以本文先基于專(zhuān)家用戶(hù)的協(xié)同過(guò)濾思想尋找專(zhuān)家之間關(guān)聯(lián),找到最近鄰關(guān)系,再對(duì)最近鄰結(jié)果進(jìn)行基于設(shè)備條目的協(xié)同過(guò)濾分析,大大優(yōu)化了計(jì)算復(fù)雜性。
三種算法的結(jié)合使用,在準(zhǔn)確率和召回率方面都對(duì)推薦引擎性能有較大的提高。
[1] 林德軍. 基于Slope One改進(jìn)算法推薦模型的設(shè)計(jì)與實(shí)現(xiàn)[D]. 北京:北京郵電大學(xué), 2012.
[2] 范永健. 基于數(shù)據(jù)挖掘的電子商務(wù)推薦系統(tǒng)模型研究[D].邯鄲: 河北工程大學(xué),2009.
[3] 朱建平, 范霄文, 張志強(qiáng). 數(shù)據(jù)挖掘的技術(shù)與商業(yè)定義及其研究對(duì)象[J]. 統(tǒng)計(jì)教育, 2004(1):7-10.
Analysis of device recommendation system algorithm in university scientific research information management
Yang Zixi,Xu Jianliang
(Institute of Information Science and Engineering, Ocean University of China, Qingdao 266100, China)
Considering the practical applicability of university scientific research management, the applicability of several mainstream data mining recommendation algorithms were compared in this paper. We choose suitable algorithm for the device data condition, and analyze actual usability of this alorithm. Finally, we achieve the improvement of the performance of algorithm and complete the high quality recommendations by the combination of recommendation algorithm based on content filtering, recommendation algorithm based on user collaborative and algorithm based on item slope one.
recommendation algorthm; data mining; device recommendation
TP311.1
A
10.19358/j.issn.1674- 7720.2016.16.004
2016-03-30)
楊紫曦(1991-),男,在讀碩士研究生,主要研究方向:軟件工程與智能信息系統(tǒng)。
徐建良(1969),男,博士,教授,主要研究方向:計(jì)算復(fù)雜性理論、計(jì)算機(jī)軟件與理論 。
猜你喜歡
小獼猴智力畫(huà)刊(2022年9期)2022-11-04 02:31:42
中學(xué)生數(shù)理化·中考版(2022年11期)2022-02-16 07:01:20
小哥白尼(趣味科學(xué))(2019年6期)2019-10-10 01:01:50
科技知識(shí)動(dòng)漫(2017年7期)2017-08-09 19:52:45
科技知識(shí)動(dòng)漫(2017年5期)2017-05-11 21:34:16
科技知識(shí)動(dòng)漫(2017年4期)2017-04-15 22:24:55
科技知識(shí)動(dòng)漫(2017年2期)2017-02-06 20:59:46
科技知識(shí)動(dòng)漫(2016年10期)2016-10-18 20:35:00
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
