人工智能改變搜索引擎優(yōu)化的速度超乎想象
2016-11-14 19:06:15約翰·蘭普頓
飛碟探索 2016年11期
約翰·蘭普頓
現在,人人都對谷歌的人工智能系統有所耳聞,這款人工智能計算系統是迄今美國加州山景城最新、最尖端的計算技術。然而,許多人或許并沒有意識到該系統改變搜索引擎、優(yōu)化行業(yè)的速度之快。本文將借助一些實例,說明當原有的搜索引擎優(yōu)化程序不再有效時,若要在商業(yè)領域贏得搜索引擎優(yōu)化戰(zhàn)役、站在領軍者的行列,應當采取哪些措施。
那么,什么是人工智能?
總體而言,人工智能可分為三類:
1.狹義人工智能:針對特定任務設計的人工智能程序(例如在國際象棋比賽中擊敗世界冠軍的人工智能程序)。
2.通用人工智能:可執(zhí)行任何任務的人工智能程序。一旦人工智能程序如同人類一般執(zhí)行各項任務,我們便將其認定為通用人工智能。
3.超級人工智能:任務執(zhí)行能力普遍高于一般水平(超出了普通人的能力)。
目前提及的谷歌人工智能系統和谷歌現行的機器計算法,都屬于狹義人工智能。
事實上,狹義人工智能技術問世已經有一段時間了。你可曾想過,電子郵件系統中的垃圾郵件過濾程序就屬于狹義人工智能的范疇。下面將介紹幾種我比較青睞的人工智能技術程序:谷歌翻譯、IBM沃森計算系統、由亞馬遜出品的“向顧客推薦產品”的酷炫程序、自動駕車程序,當然了,還有倍受青睞的谷歌人工智能系統。
狹義人工智能具備多種運算方法,正如佩德羅·多明戈斯在《主算法》一書中所言,試圖打造完美ANI程序的數據科學家可大體分為五大“陣營”:符號學家、聯系論者、進化論者、貝葉斯統計學者和類比學家。
谷歌人工智能系統正是聯系論者的結晶。他們認為,知識以編碼的形式存儲于大腦神經元之間。而人工智能系統采用的具體策略正是這些專家所稱的反向傳播技術,也被稱作深層強化學習技術。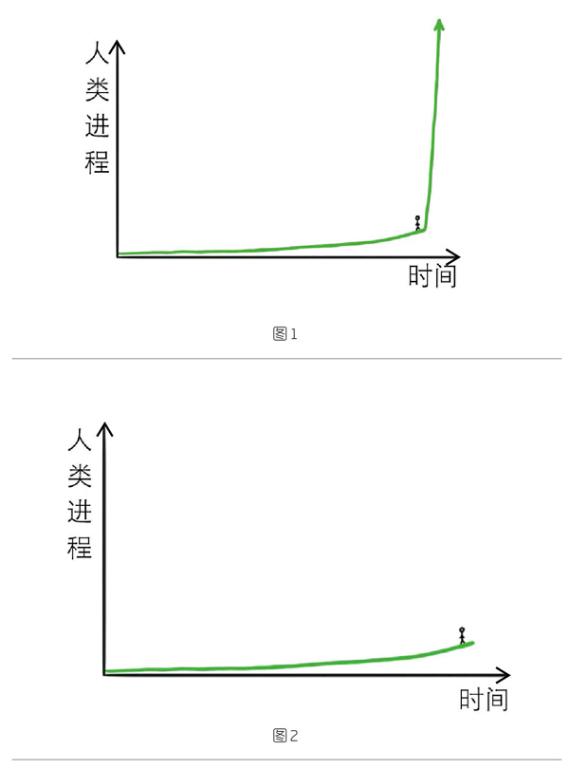
聯系論者聲稱,這種策略具備從一切原始數據獲取知識的能力,正因如此,它具備將知識汲取過程自動化的能力。很顯然,谷歌在這一點上持相同看法。2014年1月26日,谷歌宣布收購深層強化學習技術,在本質上,這項技術實屬反向傳播產品。
因此,在談論人工智能系統技術的時候,我們可以告訴人們它包含狹義人工智能的一項特殊技術,即反向傳播技術,或者深層強化學習技術。既然我們已經解決了“什么是人工智能”的問題,那么接下來的問題便是,這一領域的進展如何?更重要的是,人工智能系統究竟是如何改變搜索引擎的?
技術(和人工智能)的迅猛發(fā)展
蒂姆·厄班在他的文章《人工智能變革:超級人工智能之路》中對科技發(fā)展做出的解釋比其他解釋都要略深一籌。
回顧歷史,就會發(fā)現技術進步的曲線如圖1所示。
但是,正如厄班所言,在現實中,個人無法看清圖像上所處位置右邊的上升趨勢(也就是未來的上升趨勢)。因此,圖2所示才是圖中人當時的真實感覺。
也就是說,人類力圖預測未來的時候,總是低估了未來的種種可能性。這是因為他們往往著眼于所處位置左邊的圖景,而不是右邊的未來趨勢。
然而,現實情況是,隨著時間的推移,人類的發(fā)展進程越來越快。雷·庫茲韋爾將這種趨勢稱為“加速循環(huán)法則”。這一原創(chuàng)理論背后的科學原理在于:與不太發(fā)達的社會相比,由于發(fā)達社會更為先進,因此能以更快的速率繼續(xù)向前發(fā)展。當然啦,人工智能的發(fā)展和目前先進技術的增長速度也是如此。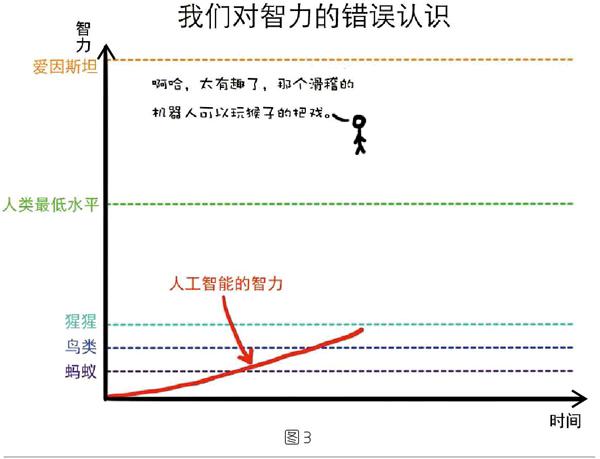
目前的計算資源也體現了這種越來越快的速度,我們可以清楚地看到,并能直接感受到,高級運算和計算機都獲益于“加速循環(huán)法則”。更加令人震驚的是:在未來某個節(jié)點,一臺節(jié)約型電腦的運算能力不僅會超過個人,而且會超過全人類運算能力的總和。
事實上,按照現在的趨勢看來,我們將能在2025年左右實現通用人工智能(AGI)。很明顯,技術發(fā)展的速度越來越快,從許多方面來看,大多數人都會對此措手不及。
超智能的崛起
正如上文所述,谷歌的人工智能系統只是一種狹義人工智能形式。這意味著,盡管狹義人工智能程序在某一特定領域超越了個人,卻只屬于相對較弱的人工智能形式。
然而,這種“弱勢”人工智能很可能輕易地轉化為某種令我們手足無措的事物,而且轉化速度之快出乎我們的預料。
你可以從圖3中清楚地看到,盡管在某一特定任務中屬于超智能等級,但是在多數情況下,谷歌的人工智能系統在智力等級量表中所處的級別是:相當不夠智能。
但是,如果將“加速循環(huán)法則”應用于人工智能后會發(fā)生什么?蒂姆·厄班帶領我們體驗了一場思想實驗之旅:
“即使人工智能在智力方面不斷地接近人類,但在我們看來,它也只是比原來聰明了一點兒,這就和我們看待動物是一樣的。當人工智能的智力水平終于達到人類最低水平的時候(即尼克·博斯特倫所說的“村野白癡”水平),我們通常的反應是:“哇哦,就像個傻瓜一樣。簡直太可愛了!”現在唯一確定的是,在宏大的智力圖譜上,從“村野白癡”到“愛因斯坦”,人類智力圖譜的范圍實際上十分狹窄。所以說,只要達到“村野白癡”的智力水平,就可以聲稱人工智能成了通用人工智能,或許突然之間它會比愛因斯坦更加聰明,但我們無法預知究竟會發(fā)生什么。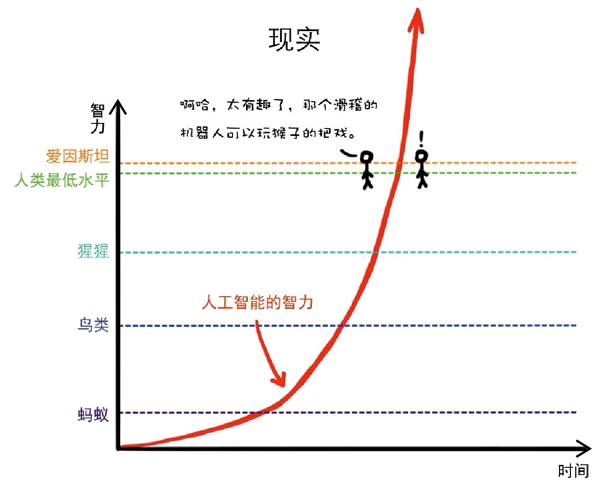
那么,對搜索引擎優(yōu)化行業(yè)和我們身邊的人工智能而言,這種趨勢究竟意味著什么呢?
搜索引擎優(yōu)化發(fā)生了永久性的變革
在預測未來之前,不妨先談談人工智能系統改變搜索引擎優(yōu)化的方式。我曾與斯科特·斯托弗促膝交談,他是我在卡耐基梅隆大學的校友、朋友,市場策劃公司的現任首席技術官,也是創(chuàng)始人之一,這家公司為全球500強企業(yè)搜索引擎優(yōu)化團隊提供搜索引擎模型。作為一名搜索引擎工程師,他對過去的10年有著獨特的見解,而大部分搜索引擎行業(yè)的專業(yè)人士并未意識到這些。談到谷歌公司開始將重點放在人工智能領域時,他為搜索引擎優(yōu)化行業(yè)提了幾點建議。
1.如今使用的回歸分析存在嚴重缺陷
目前,回歸分析是搜索引擎優(yōu)化行業(yè)最大的缺陷。每當谷歌的排名榜發(fā)生較大的變化時,很多預言家便應運而生。通常毫無例外的是,一些數據科學家和搜索引擎優(yōu)化行業(yè)知名公司的首席技術官就會信誓旦旦地斷言,谷歌排名最近出現的變化“確有緣由”。他們通常所做的分析包括追溯事件發(fā)生前數月間的排名數據,然后查看各家網站的排名發(fā)生了怎樣的變化。
這些數據科學家利用回歸分析法時,都是指出受到影響(正面或負面)的一種具體類型的網站,并且得出十分確定的結論,認為谷歌最新的計算方法變化轉型來自這些網站分享的具體類型算法(內容或反向鏈接等)。
然而,目前谷歌的運行方式已經不是這樣了。作為一款機器學習法或深層強化學習法產品,谷歌人工智能系統的運行機制截然不同。
谷歌公司內部仍有許多核心算法。人工智能系統的工作任務在于:充分了解這些核心算法如何混合搭配才能更適用于不同類型的搜索結果。例如,在某些搜索結果中,人工智能系統或許知道最重要的信號是標簽標題。
增加對標簽標題匹配算法的關注度,可能會帶來更好的搜索體驗。然而,換一種搜索結果后,同一信號帶來的搜索體驗或許根本談不上良好,甚至是極其糟糕的。因此,在另一種垂直搜索中,也許另一種算法,即網頁排名更有效。
這也就意味著,針對不同的搜索結果,谷歌都會提供截然不同的混合運算法。現在我們終于明白,脫離搜索結果所處的大環(huán)境后,針對各個網站進行的回歸分析為什么存在極大的缺陷。
正因如此,當今的回歸分析必須借助特定的搜索結果來進行。斯托弗提出了一種搜索建模路徑,可以衡量谷歌的計算法發(fā)生的變化。首先,對于特定的關鍵字搜索,可以通過快照的方式,拍下之前搜索引擎模型的調整情況。然后,在發(fā)現排名變化之后,重新調整搜索引擎模型,顯示出前后兩種搜索引擎模型設置的變量。通過此種方法,在排名發(fā)生變化的時候,我們就可以清楚地看到哪種算法升級了,哪種降級了。
2.人類力圖預測未來時,總是低估未來的種種可能性
了解了這類相關知識后,我們可以致力改進搜索引擎優(yōu)化的特定部分,針對不同的搜索結果搜索相關網站。但是,這種方法將不會(也無法)適用于其他搜索結果。這是因為人工智能系統依據搜索結果(或關鍵字)進行搜索。顧名思義,是為每個搜索結果量身定做的最佳算法。
3.進行市場定位,避免錯誤分類
谷歌意識到,可以教給全新的深層強化學習系統如何辨別“好”網站與“壞”網站。針對各種搜索結果,谷歌會權衡并提供不同的算法。同樣,谷歌公司認識到,每個垂直搜索中都包含“好”網站和“壞”網站。毫無疑問,這是因為不同的垂直搜索擁有的客戶關系管理系統不同、模板不同,整體數據結構也不同。
人工智能系統的運行,實際上等于是學會在各種環(huán)境中進行正確的“設置”。正如你已經猜到的那般,這種設置完全依賴于操作過程中的垂直搜索。因此,舉個例子來說,谷歌知道醫(yī)療健康服務網是醫(yī)療行業(yè)中的知名網站,在排名時想將其置于搜索結果目錄的頂部。任何類似于醫(yī)療健康服務網站點結構的網站都將被歸入“好”網站之列。同理,在醫(yī)療業(yè)搜索中,任何類似于垃圾網站結構的網站都會被劃入“壞”網站之列。
人工智能系統借助深層強化學習能力,對“好”網站和“壞”網站進行分類匯總。設想一下,假如有一家網站不加歸類地雜糅各行各業(yè)的內容,將會出現什么情況呢?
首先,對于深層強化學習系統如何運行的問題,仍必須對諸多細節(jié)進行討論。在將網站區(qū)分為“好”與“壞”兩個陣營之前,人工智能系統必須確定所有網站的具體類型。盡管耐克官網或者醫(yī)療健康服務網上都擁有各種各樣的次級類別,但其總體類型顯而易見,因此這類網站很容易區(qū)分。
但是如何區(qū)分涵蓋多種不同類型內容的那些網站呢?比如指南型系列網站,此類網站涵蓋的信息種類繁多、龐雜。針對這種情況,深層強化學習系統根本無能為力。那么谷歌對這些網站采用了哪些數據呢?回答是:看起來可能很隨意。谷歌可能會選擇其中的某種信息類型。對于維基百科等知名網站,谷歌可能會放棄分類過程,以確保深層強化學習過程不會降低現有的搜索體驗感受(即所謂的“大而無當”)。
4.搜索引擎優(yōu)化將會極度專業(yè)化
但對不太知名的網站來說,這意味著什么呢?很有可能,機械學習程序會自動對所有網站進行分類,之后再將其與其他網站進行比較。可以說,指南型系列網站看起來近似于醫(yī)療健康服務網。太棒了,不是嗎?
如果分類程序認為一家網站屬于鞋類網站,那么就會將其與耐克的官網(而非醫(yī)療健康服務網)進行比較。結果這家網站的結構看起來很像垃圾鞋類網站,因此這種無所不包的網站可能被輕易地標記為垃圾網站。如果操作指南型網站涵蓋不同領域,那么就很容易使每種類型都仿佛接近本行業(yè)內領先的樣子,一定要進行市場定位。
5.反向鏈接令人不安
現在,讓我們來看看反向鏈接受到了什么樣的影響。基于上述分類程序,堅持“鏈接近鄰”原則尤為重要,如果垂直搜索中的同類反向鏈接配置有所出入,人工智能系統便會即刻感知到。
仍然以上述的例子為證。假設一家公司擁有一個鞋類網站。根據我們的常識,人工智能系統的深層強化學習系統會嘗試將其各個方面與最佳鞋類網站或最差鞋類網站進行比較。因此,順理成章,這家網站的反向鏈接配置會與最佳或最差網站的反向鏈接配置進行對比。
我們也可以這樣說,信譽良好的鞋類網站擁有來自相關臨近領域的反向鏈接,即運動類網站、保健類網站和時尚類網站。
目前,該公司的搜索引擎優(yōu)化團隊決定開始從近鄰中尋求反向鏈接,并增添了新的近鄰——汽車業(yè),這是由于公司的首席執(zhí)行官之前與汽車業(yè)有關系。該公司的設計十分“巧妙”,他們在汽車網站上構建了一個交叉銷售網頁,“買車簽約即送新鞋”,點擊后就會鏈接到該公司的新款鞋。完全不著痕跡,不是嗎?
人工智能系統將會注意到這一點,注意到這種反向鏈接配置看起來與信譽良好的鞋類網站截然不同。而更糟糕的是,大量垃圾鞋類網站也有汽車網站的反向鏈接配置。哇!
就這樣,在不了解“正確”的反向鏈接配置是什么的情況下,人工智能系統已經對搜索引擎的搜索結果做出了“好”與“壞”的判斷。新的售鞋網站已經被標記為垃圾網站,瀏覽量開始暴跌。
搜索引擎優(yōu)化和人工智能的未來前景
正如我們在討論加速循環(huán)法則時談到的那樣,人工智能系統和其他人工智能將會在未來某個時刻超越人腦。而現在,無人知曉科技將引領我們走向何方。
不過,有些事情是確定無疑的:
任何競爭激烈的關鍵字設置都需要自檢;
大多數網站將需要進行市場定位,防止被錯誤分類;
所有網站都應該模仿本領域內一流網站的結構和要素。
在某些方面,深層強化學習方法使搜索引擎優(yōu)化變得更加簡單。人工智能系統及同類技術幾乎與人腦相當,它們遵循的規(guī)則十分簡潔明了:不再出現漏洞。
在其他方面,前路略為坎坷。搜索引擎優(yōu)化領域將極度專業(yè)化,分析學和大數據成為日常運營的基本準則。對任何不熟悉這些方法的搜索引擎優(yōu)化而言,還有很多工作要做,需要奮力猛追。而對擁有相應技能的技術人員來說,數目可觀的薪金指日可待。
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發(fā)展導向(2021年12期)2021-07-22 08:06:48
建材發(fā)展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
商界(2019年12期)2019-01-03 06:59:05
IT經理世界(2018年20期)2018-10-24 02:38:24
小康(2017年16期)2017-06-07 09:00:59
南風窗(2016年19期)2016-09-21 16:51:29
中國衛(wèi)生(2015年12期)2015-11-10 05:13:38
新疆大學學報(自然科學版)(中英文)(2014年2期)2014-11-06 07:49:12
