如何使用Oracle數據庫分區表
2016-11-26 03:02:38
網絡安全和信息化 2016年11期
引言:隨著互聯網技術以及互聯網商業的發展,大數據條件下高并發量、海量數據的性能直接影響著用戶的網上應用。如何處理好這種海量數據,已經成為任何數據庫管理系統必須面對的挑戰。本文討論的內容就是如何在生產實際中處理海量數據。
Oracle作為一種數據庫,處理海量數據最基本的方法就是“分而治之”,即將海量表拆成小表,具體技術而言就是采用分區表的形式拆分大表,從而提高用戶在海量數據環境下的用戶體驗,減少DBA維護的時間和精力成本從而有效降低海量數據處理的復雜度。
分區表與海量數據
海量數據的特點是在高并發環境下的高數據量,這樣就造成傳統的單表(具有單獨的段標識)很大。如此大的數據量,極有可能引起數據訪問以及管理的各種問題。

圖1 分區表示意圖

圖2 高效歸檔海量數據分區表示意圖
Oracle解決這種海量數據的方法是利用分區表技術。所謂的分區表就是依據分區主鍵而創建的多個獨立的表。對應用而言它只是一個表,而在底層是由幾個獨立分區組成,每個分區具有自己的段標識以及段的高水位線。圖1是按照時間分區的分區表示意圖。從圖1可以看出,分區表在物理上是獨立的存儲段,其優點是:其一,數據分布到多個獨立的段中,單個段的損壞不影響其他段的數據,提高了段的可用性;其二,對每個分區實施單獨的備份和恢復策略,提供了段管理的靈活性;其三,不同的物理分區可以存儲到不同的物理磁盤上從而來分散I/O,提高了數據I/O性能。
分區表與數據歸檔
對歷史數據的備份在成熟的信息化應用系統中占有十分重要的地位。對歷史數據進行歸檔,降低其數據量,消除磁盤碎片,可以使得系統高效運行。
在有數據需要歸檔時,分區表的作用就發揮出來,按照時間進行分區,對于數據歸檔,數據維護,數據的可用性都有好處。圖2是分區表高效歸檔海量數據示意圖。
在生產實際中,經常需要按照時間進行歷史數據歸檔,隨著數據量的快速增長,需要歸檔這些歷史數據,如果此時采用了時間分區,前提是該表有時間字段作為分區主鍵,就很容易使用分區技術快速高效地實現數據歸檔。如當前表為T-CURR是按照表中T-date字段的分區表,每個月一個分區,可按照如下步驟實現數據歸檔:先創建中間臨時表T-MID。然后創建歷史分區表T-HIST。最后進行分區交換。
這里的歷史表T-HIST和當前的表T-CURR結構相同,唯一區別就是名稱不同。而中間臨時表T-MID與需要交換的分區具有相同的表結構。下面是具體的交換過程:

這樣通過兩次分區交換完成當前表中分區d1中的數據歸檔,此時使用including indexes包含索引段的交換,如果是本地索引則不需要重建歷史歸檔表中的本地索引,這里的without validation指出不需要數據驗證,這樣就不需要在交換前對T-MID中的數據進行全表掃描,提高分區交換的效率。
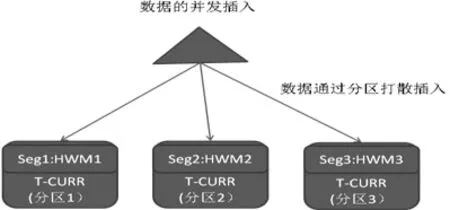
圖3 分區表示意圖
分區表解決高水位推進問題
海量數據環境下,高并發量的數據對單表而言會數據存儲空間的不足造成高水位推進的問題,從而影響到數據的并發處理。而通過分布表技術可以有效化解這個難題。在生成系統中會出現enq:HW或者enq:FB等待事件,在RAC集群環境下出現大量gc current grant等待事件,這些都是和高水位推進相關的等待事件。
當數據插入分區表時,如果表段的空間不足會首先格式化一組新數據塊,只有格式化完成才能繼續插入數據,否則當前數據插入的會話會出現等待HW/FB鎖的等待。
可以想象在海量數據環境下,高并發量、高數據量的特點必然因為這種等待的加劇,從而影響數據插入的性能。此時如果合理使用分區表即可有效緩解這種等待。一旦將表分區,則每個分區具有獨立的段標識,對應獨立的高水位線管理。這樣就將數據插入均衡到多個分區中,從而有效緩解HW鎖的爭用。
圖3為高水位推進打算之后的分區表示意圖,其說明高水位推進打算之后的示意圖,并發環境下使用分區表時每個分區表一個高水位線,避免了單個段的高水位等待問題。
分區表與RAC集群環境
在RAC集群環境下,有效提高了數據的高可用性、可擴展性、負載均衡等,提高了系統處理海量數據的能力。結合集群環境的實際,需要考慮如何有效使用好分區表。合理的分區表使用可以減少實例間的數據爭用。減少節點之間的網絡流量,從而優化整個集群系統的性能。
如果條件允許,采用應用分區是十分有效的較少集群實例間數據流量的方法,它可以極大減少表的global buffer busy等待。即將每個區域的用戶綁定到服務器連接池組中的某個固定的實例,固定的實例只用來訪問一個固定區域用戶的分區,這樣就極大較少了實例對相同數據塊的爭用,從而避免global buffer busy帶來的爭用問題。
如果條件不允許使用應用分區,則需要詳細分區訪問該海量表的SQL語句特點,從而設計對應的分區方案。如果SQL的謂詞中大量的出現某個字段的=條件,則可以選擇該字段作為HASH分區的主鍵,從而盡最大可能將數據打算,這樣通過將數據打散到不同的分區中,從而有效減少熱快沖突的概率,提高整個集群的性能。
如何實施分區
1 選擇分區主鍵
在使用分區技術時,合理的分區主鍵與分區粒度的選擇十分重要,否則很難發揮分區表的優勢。
分區主鍵是指實現表分區的字段,如表中的T_date字段實現按照時間分區。分區粒度是分區大小,如按照時間分區是以月為單位還是以年為單位,這些直接影響分區優勢的發揮。
總之在設計分區前要根據業務需要,制定滿足性能、維護等需求的分區方案,選擇好分區主鍵與分區粒度。
分區主鍵的選擇主要考慮分區目的。如果是歸檔數據顯然使用時間字段實現范圍分區;如果主要是打散數據分解全局數據沖突可以考慮謂詞中的對應字段作為分區主鍵。即分區主鍵的選擇原則是它是否經常出現在查詢語句的謂詞條件中。
如果在系統上線之后實現分區,此時DBA不清楚那些SQL經常訪問,以及如何訪問這些海量表,所以需要不斷的分區共享池中的SQL語句,分區過濾條件和連接條件,從而合理判斷分區主鍵。在選擇了分區主鍵之后,必須保證該字段是非空的。
2 選擇分區粒度
在確定了分區主鍵之后,就需要考慮分區粒度的選擇。而分區粒度的選擇沒有固定的原則,適合系統需要就好,更好的服務于應用系統就是好的分區,但是這也是分區粒度的難點。不同目的采用不同分區方法。以下列舉三個目的作為說明:
(1)便于維護:需要考慮多大的分區維護起來方便,滿足維護時間窗口的條件,如果分區歸檔要求15分鐘完成,則顯然對分區粒度的大小有限制,這需要做實驗分區,從而滿足自己系統軟硬件條件的容量限制。
(2)便于歸檔:歸檔頻率需要考慮,即多久歸檔一次,顯然歸檔周期就是分區粒度需要考慮的首要因素
(3)便于提高性能:需要考慮表的范圍掃描的范圍高概率發生在哪個時間范圍內, 這樣根據多數數據查詢的掃描時間范圍設計分區粒度比較好。
總結
本文分析了如何在高并發量以及高數據量的環境下提高數據訪問性能。Oracle數據庫通過分區表技術可以有效解決這個難題。
分區技術的使用需要針對具體場合以及結合分區表的特點作出合理的分區粒度以及分區鍵的選擇。在RAC集群環境下合理使用應用分區可以極大減少實例之間數據通信以及實例間協商的開銷,從而提高RAC的整體性能。
