面向數(shù)據(jù)中心網(wǎng)絡(luò)的高速數(shù)據(jù)傳輸技術(shù)
2016-11-29 03:42:25秦宣龍李大剛陳遠(yuǎn)磊
軟件 2016年9期
關(guān)鍵詞:優(yōu)化
秦宣龍,李大剛,都 政,陳遠(yuǎn)磊
(1. 北京大學(xué)深圳研究生院 信息工程學(xué)院,廣東深圳 518055;2. 國(guó)家超級(jí)計(jì)算深圳中心(深圳云計(jì)算中心)高性能計(jì)算部,廣東深圳 518055)
面向數(shù)據(jù)中心網(wǎng)絡(luò)的高速數(shù)據(jù)傳輸技術(shù)
秦宣龍1,李大剛1,都政2,陳遠(yuǎn)磊2
(1. 北京大學(xué)深圳研究生院 信息工程學(xué)院,廣東深圳518055;2. 國(guó)家超級(jí)計(jì)算深圳中心(深圳云計(jì)算中心)高性能計(jì)算部,廣東深圳518055)
數(shù)據(jù)中心是云計(jì)算和大數(shù)據(jù)應(yīng)用的基礎(chǔ)設(shè)施,目前數(shù)據(jù)中心網(wǎng)絡(luò)基本都是采用TCP/IP協(xié)議并基于以太網(wǎng)技術(shù)搭建。隨著以太網(wǎng)的提速,TCP/IP協(xié)議及其實(shí)現(xiàn)方式已經(jīng)無(wú)法適應(yīng)高速數(shù)據(jù)傳輸?shù)男枨螅蔀榫W(wǎng)絡(luò)性能進(jìn)一步增長(zhǎng)的瓶頸。在分析了現(xiàn)有數(shù)據(jù)中心網(wǎng)絡(luò)的特點(diǎn)以及網(wǎng)絡(luò)實(shí)現(xiàn)的開(kāi)銷和性能之后,文章對(duì)多種網(wǎng)絡(luò)性能優(yōu)化技術(shù)進(jìn)行了比對(duì)和總結(jié),并且分析了下一步的研究方向。
TCP;數(shù)據(jù)中心網(wǎng)絡(luò);以太網(wǎng);RDMA
本文著錄格式:秦宣龍,李大剛,都政,等. 面向數(shù)據(jù)中心網(wǎng)絡(luò)的高速數(shù)據(jù)傳輸技術(shù)[J]. 軟件,2016,37(9):01-07
0 引言
隨著云計(jì)算和大數(shù)據(jù)應(yīng)用的不斷發(fā)展,互聯(lián)網(wǎng)中的計(jì)算和存儲(chǔ)服務(wù)越來(lái)越依賴于數(shù)據(jù)中心。近年來(lái)國(guó)內(nèi)許多學(xué)者針對(duì)數(shù)據(jù)中心在不同場(chǎng)景之下的應(yīng)用也展開(kāi)了廣泛研究[30-33]。數(shù)據(jù)中心大多基于成熟且廉價(jià)的服務(wù)器和以太網(wǎng)設(shè)備搭建,采用廣泛使用的TCP/IP協(xié)議來(lái)完成數(shù)據(jù)的傳輸。隨著以太網(wǎng)技術(shù)的快速發(fā)展以及數(shù)據(jù)中心應(yīng)用對(duì)網(wǎng)絡(luò)性能需求不斷上升,通常我們通過(guò)帶寬、延遲和CPU占有率來(lái)作為性能指標(biāo),而TCP越來(lái)越成為數(shù)據(jù)傳輸?shù)男阅芷款i。TCP主要帶來(lái)兩個(gè)方面的問(wèn)題,首先是數(shù)據(jù)在網(wǎng)絡(luò)傳輸過(guò)程中遇到的挑戰(zhàn)。TCP的傳輸控制機(jī)制依賴于端到端反饋,并采用重傳機(jī)制來(lái)實(shí)現(xiàn)可靠傳輸,對(duì)數(shù)據(jù)中心常見(jiàn)的短流來(lái)講調(diào)整過(guò)于緩慢;再加上慢啟動(dòng)和丟包時(shí)的速率減半帶來(lái)的流量劇烈變化,其過(guò)于繁雜的算法機(jī)制并不適用于數(shù)據(jù)中心高帶寬低延遲的情況,對(duì)于網(wǎng)絡(luò)性能而言這都是需要提升和解決的問(wèn)題。另一個(gè)方面整個(gè)TCP/IP協(xié)議棧在主機(jī)端都是通過(guò)Socket軟件實(shí)現(xiàn),整個(gè)數(shù)據(jù)傳輸過(guò)程需要CPU的參與,在高包速率情況下會(huì)大量占用CPU時(shí)間,甚至使得CPU變成數(shù)據(jù)傳輸?shù)钠款i。另外在Socket的架構(gòu)下數(shù)據(jù)會(huì)在系統(tǒng)內(nèi)存、處理器緩存和網(wǎng)卡緩存之間來(lái)回進(jìn)行拷貝,給服務(wù)器的CPU和內(nèi)存帶來(lái)嚴(yán)重的負(fù)擔(dān)。這些因素都會(huì)造成數(shù)據(jù)中心網(wǎng)絡(luò)性能受損,為此研究者們嘗試了不同思路來(lái)解決這個(gè)問(wèn)題。首先提出了對(duì)TCP協(xié)議的優(yōu)化,Jeonghoon[19]提出了TCP速率調(diào)整的算法,Hammann[20][27]提出了ECN標(biāo)記算法,Tang[21]提出了DMA零拷貝技術(shù)等等,這些對(duì)TCP和主機(jī)端的改進(jìn)在一定程度上都改善了傳輸性能。
為了更進(jìn)一步提升數(shù)據(jù)中心網(wǎng)絡(luò)性能,本文綜述了目前常見(jiàn)的網(wǎng)絡(luò)性能優(yōu)化方式,第二章節(jié)論述了在保持?jǐn)?shù)據(jù)中心網(wǎng)絡(luò)整體架構(gòu)不變的情況下采用硬件實(shí)現(xiàn)來(lái)提速網(wǎng)絡(luò)處理能力的典型技術(shù)。在第三章節(jié)論述了從網(wǎng)絡(luò)協(xié)議優(yōu)化的角度來(lái)針對(duì)性地改進(jìn)數(shù)據(jù)中心網(wǎng)絡(luò)傳輸性能的主要方法。第四章節(jié)更進(jìn)一步論述了將RDMA技術(shù)引入以太網(wǎng)架構(gòu)的主要方案及其特點(diǎn)。最后進(jìn)行了總結(jié)。
1 TCP硬件加速方案
隨著以太網(wǎng)的速度提升,帶來(lái)更高的帶寬,但是TCP/IP協(xié)議是無(wú)法滿足高帶寬下數(shù)據(jù)中心網(wǎng)絡(luò)的高帶寬、低延遲,低CPU占有率等需求的,這些標(biāo)準(zhǔn)也是對(duì)網(wǎng)絡(luò)性能的衡量方式,而且TCP協(xié)議在主機(jī)端的處理占用了大量CPU,當(dāng)包處理量很高的時(shí)候?qū)W(wǎng)絡(luò)性能影響極大,在這一部分如果做到進(jìn)一步優(yōu)化,那對(duì)網(wǎng)絡(luò)性能是一個(gè)極大的好處,考慮到硬件的處理速度快,使用硬件來(lái)處理部分TCP協(xié)議會(huì)對(duì)性能有一個(gè)極大的提升。
1.1TCP引擎卸載技術(shù)(TCP offload engine, TOE)
TOE是基于傳統(tǒng)以太網(wǎng)結(jié)構(gòu)下的一種TCP加速技術(shù),由于數(shù)據(jù)在主機(jī)內(nèi)的來(lái)回拷貝,中斷處理給CPU帶來(lái)過(guò)高的負(fù)載,TOE技術(shù)的中心思想是利用硬件來(lái)分擔(dān)CPU對(duì)TCP/IP協(xié)議的處理所造成負(fù)擔(dān),其做法就是將部分TCP協(xié)議遷移至網(wǎng)卡中減少主機(jī)上CPU對(duì)協(xié)議棧的校驗(yàn)和檢查等處理的需求,減少系統(tǒng)總線之間的數(shù)據(jù)復(fù)制,在處理程序的時(shí)候和傳統(tǒng)的網(wǎng)卡每發(fā)送一個(gè)數(shù)據(jù)包就中斷一次不同,它通過(guò)運(yùn)行一個(gè)完整的數(shù)據(jù)處理進(jìn)程后才觸發(fā)一次中端,以此來(lái)減少主機(jī)CPU的中斷次數(shù),通過(guò)上述的方式TOE大大提升了TCP/IP的效率。
K. Kant[7]對(duì)比了使用TOE和不使用TOE情況下網(wǎng)絡(luò)的吞吐率,在傳輸速度越快的網(wǎng)絡(luò)下吞吐率提升就越明顯。
W. Feng[8]在MTU為1500和9000的情況下對(duì)比了延遲,在兩種情況下TOE對(duì)延遲都只提高了2微秒左右,但是對(duì)CPU的占有率下降非常大。尤其是在多服務(wù)器和多流的情況下帶寬從無(wú)TOE的3000 Mbps上升到7000Mbps.
Jeffrey[9]從基本性能和部署兩個(gè)問(wèn)題上描述了TOE并不是很適合現(xiàn)有的網(wǎng)絡(luò)。作者指出TOE作為一種TCP改進(jìn)方式無(wú)疑是成功的,但是在實(shí)際上性能和各方面因素卻導(dǎo)致了他日漸衰退的趨勢(shì)。
首先從基本性能上來(lái)說(shuō),由于TOE是硬件上的實(shí)現(xiàn),其更新?lián)Q代的速度可能比不上CPU性能的增加速度,通過(guò)硬件做TCP引擎卸載代價(jià)過(guò)大,Sarker[10]指出現(xiàn)在的NIC系統(tǒng)產(chǎn)品速度可能還不夠快,TOE會(huì)影響到真實(shí)環(huán)境下的性能甚至增加延遲,同時(shí)由于網(wǎng)卡和主機(jī)接口的復(fù)雜性,不兼容性,短時(shí)間的TCP連接都會(huì)導(dǎo)致浪費(fèi)額外的性能。從部署上來(lái)說(shuō),基于RAM的可用性TOE可能會(huì)有些許限制,使其擴(kuò)展性受損,同時(shí)由于硬件出現(xiàn)問(wèn)題導(dǎo)致的錯(cuò)誤以及質(zhì)量問(wèn)題都很難保證。
1.2Intel加速技術(shù)(intel acceleration technology, IOAT/IOAT2)
從TOE的思想出發(fā),使用硬件來(lái)減少CPU的占有率是一個(gè)可行的方法,從多個(gè)角度去降低整個(gè)系統(tǒng)花費(fèi)對(duì)網(wǎng)絡(luò)性能提升必然更加有優(yōu)勢(shì),IOAT就是為此提出的。
IOAT(intel acceleration technology)也是Intel為了應(yīng)對(duì)網(wǎng)絡(luò)I/O瓶頸,IOAT是第一代intel I/O加速技術(shù),是一種平臺(tái)化策略,因特爾I/O加速技術(shù)表達(dá)了“以應(yīng)用為中心的服務(wù)器觀點(diǎn)”,即I/OAT是將整個(gè)平臺(tái)的整體優(yōu)化作為解決I/O開(kāi)銷的方案。
Intel I/OAT分析了現(xiàn)有操作系統(tǒng)帶來(lái)的問(wèn)題,提出了從三個(gè)方面進(jìn)行優(yōu)化:
· 降低系統(tǒng)開(kāi)銷(System overhead)
· 實(shí)現(xiàn)流線型內(nèi)存訪問(wèn)(Memory access)
· 優(yōu)化TCP/IP協(xié)議計(jì)算(TCP/IP processing)
IOAT采用增強(qiáng)型的DMA技術(shù),在主機(jī)端加入了TOE的方式,使得在數(shù)據(jù)復(fù)制時(shí)的時(shí)間更少以提升CPU的利用率,同時(shí)也對(duì)TCP協(xié)議進(jìn)行了改進(jìn),優(yōu)化數(shù)據(jù)包的分離,使得數(shù)據(jù)得到更快的處理。IOAT的優(yōu)化是整個(gè)系統(tǒng)可能在某一方面優(yōu)化的力度不夠,但是多個(gè)方位同步實(shí)現(xiàn),確實(shí)提供了更加高效的網(wǎng)絡(luò)數(shù)據(jù)傳輸。I/OAT作為一項(xiàng)開(kāi)源技術(shù)對(duì)硬件的支持需求很高,還需要操作系統(tǒng)和特殊的驅(qū)動(dòng)這些都是亟待考慮的問(wèn)題。
IOAT2在IOAT的基礎(chǔ)上增加了多端口,虛擬化,網(wǎng)絡(luò)存儲(chǔ),應(yīng)用快速響應(yīng),增加了附加協(xié)議,附加平臺(tái)級(jí)加速,增加了高級(jí)緩存訪問(wèn)(DCA),MSI-X終端快速響應(yīng)等機(jī)制進(jìn)一步優(yōu)化整個(gè)平臺(tái)的性能。
Intel公司[11]給出了在不使用優(yōu)化的狀態(tài)下CPU的利用率,文中可以看出I/O大小在8KB左右就出現(xiàn)了I/O瓶頸,系統(tǒng)開(kāi)銷、內(nèi)存訪問(wèn)和TCP處理對(duì)CPU利用率從60%下降到30%,在使用IOAT技術(shù)后,對(duì)比了IOAT和普通以太網(wǎng)下CPU的利用率,明顯可以看出CPU的占有率下降,而吞吐率上升。Intel公司[12]從性能上對(duì)IOAT技術(shù)與TOE技術(shù)進(jìn)行了論證與分析,在吞吐率和延遲上的性能IOAT都遠(yuǎn)勝于TOE,這兩種基于硬件優(yōu)化網(wǎng)絡(luò)性能的方式針對(duì)有特殊需求的網(wǎng)絡(luò)使很有意義的,但是對(duì)于目前傳統(tǒng)的以太網(wǎng)而言想要大規(guī)模部署代價(jià)過(guò)于高昂,研究者期望尋找一種在以太網(wǎng)架構(gòu)下獲得高質(zhì)量網(wǎng)絡(luò)的方式。
2 面向數(shù)據(jù)中心的TCP協(xié)議優(yōu)化
硬件帶來(lái)的網(wǎng)絡(luò)性能優(yōu)化是毋庸置疑的,但是部署起來(lái)過(guò)于麻煩,研究者們更希望在已有的軟件基礎(chǔ)上進(jìn)行優(yōu)化來(lái)獲得性能提升,為此首先要了解數(shù)據(jù)中心的流量結(jié)構(gòu)特征。
數(shù)據(jù)中心內(nèi)部常用的網(wǎng)絡(luò)拓?fù)淙鐖D1所示,應(yīng)用數(shù)據(jù)在節(jié)點(diǎn)處來(lái)進(jìn)行頻繁交互,而數(shù)據(jù)中心的龐大流量會(huì)給節(jié)點(diǎn)帶來(lái)巨大的負(fù)載,從而引起丟包,吞吐量降低的問(wèn)題,進(jìn)而可能會(huì)造成連接中斷,延遲上升,同時(shí)數(shù)據(jù)中心大量采用Partition/ Aggregate的工作模式,高層將自己的deadline分為若干片向下傳遞,由下層完成,而無(wú)法完成時(shí)則會(huì)放棄任務(wù),這帶來(lái)的時(shí)延代價(jià)和響應(yīng)問(wèn)題是用戶無(wú)法接受的。
尤其是在數(shù)據(jù)中心網(wǎng)絡(luò)中的短流的比例占90%,TCP Incast現(xiàn)象在高帶寬、低延遲,短流多的情況下更易發(fā)生,造成性能浪費(fèi)嚴(yán)重。
但是傳統(tǒng)的TCP/IP協(xié)議是無(wú)法保證數(shù)據(jù)中心的性能的,由于TCP的“貪婪性”,TCP在發(fā)送流量是以盡最大可能交付,所以很有可能在傳輸過(guò)程中引發(fā)擁塞,TCP產(chǎn)生擁塞丟包后會(huì)進(jìn)行重發(fā),M.Allman[1]指出TCP在重傳初期會(huì)經(jīng)歷慢開(kāi)始的階段,所以數(shù)據(jù)在傳輸時(shí)發(fā)生擁塞導(dǎo)致重傳,會(huì)使性能大幅下降,表現(xiàn)在交換機(jī)的隊(duì)列長(zhǎng)度產(chǎn)生震蕩。同時(shí)因?yàn)槟壳暗慕粨Q機(jī)出于商業(yè)考慮大部分是淺緩存交換機(jī),而且其緩存是在端口間共享,因此某一個(gè)端口的短流很容易因?yàn)槿鄙倬彺媸艿狡渌丝诘拇罅鞯挠绊懀@都會(huì)大大增加數(shù)據(jù)傳輸在網(wǎng)絡(luò)的延遲。
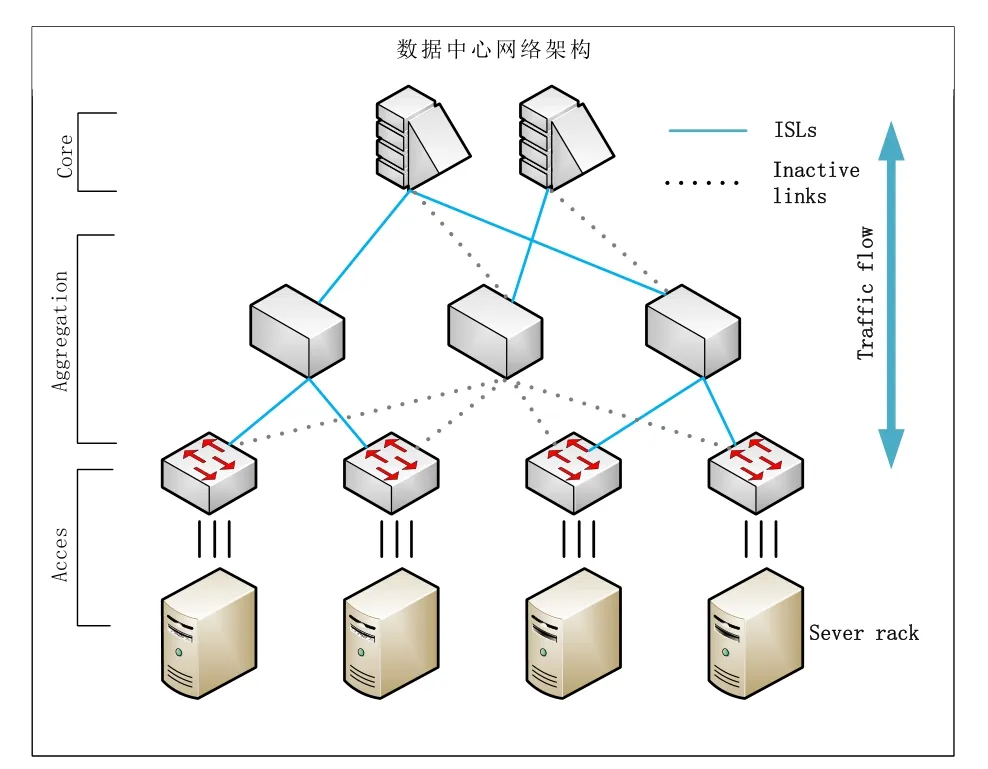
圖1 數(shù)據(jù)中心網(wǎng)絡(luò)架構(gòu)圖
而且針對(duì)TCP的突發(fā)流量其效果也并不好,所以對(duì)TCP協(xié)議的改進(jìn)就顯得很重要,本章詳細(xì)描述了DCTCP、D2TCP、L2DCT并進(jìn)行了總結(jié)。
2.1DCTCP
DCTCP使用了一個(gè)非常簡(jiǎn)單的活動(dòng)管理隊(duì)列的機(jī)制,僅僅使用了標(biāo)記門限K這一個(gè)參數(shù),當(dāng)隊(duì)列的長(zhǎng)度超過(guò)門限K就用CE標(biāo)記這個(gè)數(shù)據(jù)包,否則就不打標(biāo)記,這樣發(fā)送端就可以根據(jù)標(biāo)記的數(shù)據(jù)包的比例調(diào)整窗口的大小,當(dāng)標(biāo)記的值越多則下一次發(fā)送窗口就降低更多。
M. Alizadeh[4]在文中得出的實(shí)驗(yàn)結(jié)果可以看出,在1Gbps的帶寬下TCP和DCTCP的吞吐量都在0.95Gps左右,鏈路利用率都接近100%,但是DCTCP的隊(duì)列長(zhǎng)度基本保持在20個(gè)包左右,而TCP的隊(duì)列長(zhǎng)度比DCTCP的十倍還要大,在帶寬為10Gbps下TCP算法的隊(duì)列長(zhǎng)度抖動(dòng)的情況非常嚴(yán)重遠(yuǎn)遠(yuǎn)超于DCTCP,綜上DCTCP能實(shí)低延遲和和一定突發(fā)流量的容忍能力,在吞吐量上比TCP維持更高且穩(wěn)定的吞吐量。
DCTCP依賴于ECN標(biāo)記進(jìn)行多位反饋,需要依賴于支持這個(gè)功能的商業(yè)交換機(jī),在早期搭建的數(shù)據(jù)中心中采用的交換機(jī)有可能缺乏對(duì)ECN功能的支持,從而影響到DCTCP的部署。
2.2D2TCP
D2TCP在設(shè)計(jì)時(shí)就明確了兩個(gè)目標(biāo),不需要調(diào)整交換機(jī)硬件和支持傳統(tǒng)的TCP協(xié)議,D2TCP算法通過(guò)ECN的標(biāo)記數(shù)量和數(shù)據(jù)流的截止時(shí)間提供的信息通過(guò)伽馬函數(shù)來(lái)調(diào)節(jié)擁塞窗口的大小。D2TCP可以根據(jù)截至?xí)r間的不同讓數(shù)據(jù)流獲得不同優(yōu)先級(jí),截止時(shí)間比較遠(yuǎn)的流放棄帶寬讓截止時(shí)間快到的流保證流可以在截止時(shí)間內(nèi)完成傳輸,這對(duì)有時(shí)延要求的流來(lái)說(shuō)效果是顯著的。
B. Vamanan[5]得出的實(shí)驗(yàn)結(jié)果可以看出,DCTCP中的流在傳輸過(guò)程被授予相同帶寬,而D2TCP中的其他流帶寬全部下降這樣使得第一個(gè)流的完成時(shí)間縮短,整個(gè)傳輸過(guò)程大約減少了400ms的時(shí)延,對(duì)突發(fā)數(shù)據(jù)流的容忍能力和帶寬都有一定程度提升,比DCTCP錯(cuò)過(guò)截止時(shí)間的比率降低了75%。
2.3L2DCT
L2DCT也是通過(guò)ECN顯示擁塞反饋來(lái)進(jìn)行發(fā)送窗口的調(diào)控同時(shí)兼容現(xiàn)有TCP協(xié)議。L2DCT通過(guò)數(shù)據(jù)流的大小定義優(yōu)先級(jí),通過(guò)數(shù)據(jù)流的擁塞程度和權(quán)重來(lái)調(diào)整發(fā)送窗口,權(quán)重取決于以及發(fā)送的數(shù)目,這些權(quán)重隱式定義了流的優(yōu)先級(jí),當(dāng)流的數(shù)據(jù)量變大時(shí)算法就會(huì)將他的優(yōu)先級(jí)調(diào)低。由于短流的數(shù)量龐大,L2DCT更加關(guān)注短流的完成時(shí)間,當(dāng)長(zhǎng)流和短流并存的時(shí)候,長(zhǎng)流會(huì)放棄自己部分帶寬給短流,通過(guò)這種方式來(lái)減少數(shù)據(jù)流的完成時(shí)間。
A. Munir[29]中得出的實(shí)驗(yàn)結(jié)果來(lái)看,L2DCT相比于DCTCP數(shù)據(jù)流傳輸平均完成時(shí)間提高了50%,相比于TCP協(xié)議提高了95%,錯(cuò)過(guò)截至?xí)r間的百分率約為TCP的30%,在突發(fā)流量的情況和高負(fù)載下長(zhǎng)流的性能下長(zhǎng)流的吞吐量會(huì)下降。
L2DCT和D2TCP都是為了盡量少的deadline miss,所以犧牲了一部分長(zhǎng)流的性能,對(duì)于時(shí)延敏感的應(yīng)用有效,而不同的應(yīng)用可能采取別的權(quán)重分配方式,也有人可以將長(zhǎng)流分割為短流作為進(jìn)一步研究方向。
3 基于RDMA的新型協(xié)議
3.1RDMA的技術(shù)來(lái)源
為了更高效的提高網(wǎng)絡(luò)性能,研究者們認(rèn)為TCP的網(wǎng)絡(luò)僵化、協(xié)議創(chuàng)新困難、配置復(fù)雜、流量管理繁瑣、安全問(wèn)題凸顯,服務(wù)盡力而為無(wú)法保證服務(wù)質(zhì)量。根據(jù)擺脫TCP協(xié)議、從新的網(wǎng)絡(luò)架構(gòu)下獲得高質(zhì)量網(wǎng)絡(luò)服務(wù)的想法,研究者提出了不基于TCP/IP和以太網(wǎng)的專有網(wǎng)絡(luò)技術(shù)。現(xiàn)在的主流的高速互聯(lián)網(wǎng)絡(luò)互聯(lián)技術(shù)有Fiber Channel和Infiniband,一般專用與存儲(chǔ)集群。
Infiniband又稱為無(wú)限帶寬技術(shù),是一種異于傳統(tǒng)網(wǎng)絡(luò)架構(gòu)的新體系,Buyya[15]在文中對(duì)Infiniband的體系結(jié)構(gòu)做了詳細(xì)的介紹,IB基于鏈路層的流控機(jī)制和先進(jìn)的擁塞控制機(jī)制可以防止擁塞,完全的CPU卸載功能,基于硬件的傳輸協(xié)議,內(nèi)核旁路技術(shù)都保證了可靠傳輸,在IB體系架構(gòu)里,網(wǎng)絡(luò)總線DMA技術(shù)以RDMA的形式體現(xiàn),服務(wù)器之間通過(guò)RDMA來(lái)實(shí)現(xiàn)數(shù)據(jù)高效的傳輸,TCA(通道適配器)結(jié)合RDMA技術(shù)也在主機(jī)端優(yōu)化了網(wǎng)絡(luò)性能,可以使得CPU直接移動(dòng)其他服務(wù)器上的數(shù)據(jù),這可以帶來(lái)更高的效率和靈活性。
Fibre Channel是一種靈活的、擴(kuò)展性強(qiáng)的高速數(shù)據(jù)傳輸接口,光纖通道具有很高的傳輸帶寬,無(wú)論是在銅線或者是光纖上數(shù)據(jù)率大約是現(xiàn)在的通信接口的250倍,它的目的就是使用最低的延遲最快的速度進(jìn)行傳輸,但是和IB一樣安裝復(fù)雜需要特殊的IB交換機(jī),可擴(kuò)展的成本較高,傳輸和普適性方面顯得很笨拙,于是研究者們將FC技術(shù)和RDMA協(xié)議結(jié)合起來(lái),將FC搬遷至以太網(wǎng)實(shí)現(xiàn)。
3.2RDMA技術(shù)特征
針對(duì)RDMA給IB和FC帶來(lái)的網(wǎng)絡(luò)性能提升,但是卻需要特殊的硬件支持,為了使網(wǎng)絡(luò)更加具有普適性,在結(jié)合的RDMA技術(shù)所帶來(lái)的優(yōu)越的特性進(jìn)行了調(diào)研。
RDMA(Remote Direct Memory Access, RDMA)遠(yuǎn)程數(shù)據(jù)存儲(chǔ)存取起源于DMA,DMA可以使設(shè)備不經(jīng)過(guò)CPU直接和系統(tǒng)內(nèi)存交換數(shù)據(jù),為了使這種性能能在整個(gè)網(wǎng)絡(luò)中使用,又將可靠傳輸協(xié)議固化到網(wǎng)卡(稱為RNIC),通過(guò)這兩種途徑數(shù)據(jù)在傳輸時(shí)不經(jīng)過(guò)內(nèi)核和部分TCP協(xié)議直接從源主機(jī)的存儲(chǔ)區(qū)發(fā)送到目的主機(jī)的存儲(chǔ)區(qū),避免了主機(jī)內(nèi)部之間的重復(fù)拷貝,這也形成了RDMA的兩大主要特點(diǎn),零拷貝技術(shù)(Zero-copy)和內(nèi)核旁路技術(shù)(Bypass)。零拷貝技術(shù),使數(shù)據(jù)在接收發(fā)送時(shí)直接進(jìn)入緩存而不需要網(wǎng)絡(luò)層之間的拷貝。內(nèi)核旁路技術(shù),從用戶空間直接訪問(wèn)和控制設(shè)備內(nèi)存,避免了數(shù)據(jù)從設(shè)備拷貝到內(nèi)核,又再一次從內(nèi)核拷貝至用戶空間。RDMA的數(shù)據(jù)拷貝計(jì)傳輸實(shí)現(xiàn)流程如圖2所示
有CPU的參與,就減少了CPU的占有率。同時(shí)在RDMA中數(shù)據(jù)處理事離散的消息而不是以一個(gè)流的方式,消除了應(yīng)用程序區(qū)分不同流的信息的需要,這些特點(diǎn)都使得RDMA成為一種數(shù)據(jù)移動(dòng)處理的高效方式,在低延遲,高帶寬,低CPU占有率的場(chǎng)景下RDMA的應(yīng)用非常常見(jiàn),比如HPC, Cloud Computing, Storage and Backup system等等由于解放了CPU網(wǎng)絡(luò)性能得到巨幅提升。
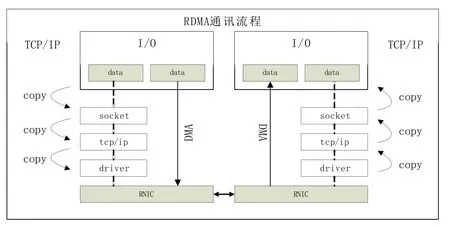
圖2 RDMA通訊協(xié)議棧
沒(méi)這些新型的計(jì)算機(jī)網(wǎng)絡(luò)模型在網(wǎng)絡(luò)性能上確實(shí)也得到了顯著的增加,但是由于新型體系結(jié)構(gòu)網(wǎng)絡(luò)模型的更改,RDMA協(xié)議在傳統(tǒng)的TCP/IP體系下是不支持的,原有在TCP上的服務(wù)因?yàn)镾ocket適合協(xié)議端口綁定的原因,就無(wú)法繼續(xù)在新的體系架構(gòu)下,如果想要新的網(wǎng)絡(luò)模型支持這種應(yīng)用,勢(shì)必需要提供新的Socket,這樣代價(jià)也隨之而來(lái)。但是由于傳統(tǒng)TCP體系結(jié)構(gòu)的落后,導(dǎo)致現(xiàn)在網(wǎng)絡(luò)的性能很差,應(yīng)用數(shù)據(jù)在網(wǎng)絡(luò)體系上傳輸?shù)乃俣葲](méi)有達(dá)到理想中的需求,這也逐漸成為網(wǎng)絡(luò)性能的瓶頸。新引入的RDMA技術(shù)雖然能夠達(dá)到數(shù)據(jù)傳輸?shù)男枨螅怯捎赟ocket的不同,所以可能需要針對(duì)這項(xiàng)技術(shù)提供專門的RDMA應(yīng)用,考慮到應(yīng)用大規(guī)模部署在以太網(wǎng)中,所以直接革新式的制作新的應(yīng)用顯然代價(jià)過(guò)于高昂。
從上述的論述中可以得出我們?cè)诳紤]網(wǎng)絡(luò)性能的同時(shí)也要考慮到現(xiàn)實(shí)的應(yīng)用場(chǎng)景,隨著以太網(wǎng)速度提升至40Gbps以上,相比于IB和FC的速度也毫不遜色,所以如果將RDMA協(xié)議布置到傳統(tǒng)以太網(wǎng)中,那么無(wú)論是網(wǎng)絡(luò)的性能還是從實(shí)用上來(lái)說(shuō)都會(huì)得到質(zhì)的飛躍。
3.3iWARP(internet Wide Area RDMA Protocol)技術(shù)
傳統(tǒng)以太網(wǎng)的從應(yīng)用處理到操作系統(tǒng)的開(kāi)銷,網(wǎng)絡(luò)處理,I/O處理,線路延遲等一系列流程導(dǎo)致延遲快速積累,但是隨著以太網(wǎng)的提速延遲大大下降,直逼毫秒級(jí)延遲,完全可以滿足現(xiàn)有的網(wǎng)絡(luò)架構(gòu),如果將RDMA技術(shù)布置在以太網(wǎng)上必然能帶來(lái)性能的大幅提升。
iWARP是一個(gè)計(jì)算機(jī)網(wǎng)絡(luò)中的協(xié)議,能夠通過(guò)以太網(wǎng)實(shí)現(xiàn)遠(yuǎn)程數(shù)據(jù)直接訪問(wèn)。iWARP在設(shè)計(jì)上就是為了適用于現(xiàn)有的TCP傳輸,利用傳統(tǒng)TCP協(xié)議達(dá)到可靠傳輸,由于RDMA提供了應(yīng)用程序到應(yīng)用程序之間直接通信的能力,跳過(guò)了操作系統(tǒng),實(shí)現(xiàn)遠(yuǎn)程內(nèi)存應(yīng)用程序的訪問(wèn),使得IWARP低延遲變得可能,同時(shí)由于IWARP使用普通交換機(jī)就可以完成RDMA,所以對(duì)比Ether fabric這種私有技術(shù)和IB特殊的體系結(jié)構(gòu),顯然更加具有普適性,但是帶來(lái)的代價(jià)就是,IWARP協(xié)議族使用了一個(gè)復(fù)雜的混合層。
在2007年,IETF發(fā)布了五個(gè)RFC標(biāo)準(zhǔn)定義iWARP,如圖4所示,在RFC標(biāo)準(zhǔn)中[22-26]中詳細(xì)解釋了iWARP的協(xié)議分工,在DDP(Data Placement Protocol)層上定義了遠(yuǎn)程數(shù)據(jù)直接存取協(xié)議,這個(gè)協(xié)議告訴RDMA如何讀寫數(shù)據(jù),MPA層上的DDP定義了如何將數(shù)據(jù)不通過(guò)間接緩存區(qū)直接放入上層協(xié)議的接收緩存區(qū)等。從圖3可以清楚的看出有無(wú)iWARP協(xié)議對(duì)整個(gè)數(shù)據(jù)處理的影響。數(shù)據(jù)直接在硬件部分通過(guò)iWARP協(xié)議尋址定位到用戶空間,避免了內(nèi)存拷貝。

圖3 iWARP和傳統(tǒng)架構(gòu)下數(shù)據(jù)處理方式

圖4 iWARP網(wǎng)絡(luò)協(xié)議棧
iWARP協(xié)議主要組件包括了DDP(direct data placement,實(shí)現(xiàn)數(shù)據(jù)傳輸零拷貝),RDMA(RDMA讀和RDMA寫),MPA(Maker PDU Aligned framing,數(shù)據(jù)單元組幀以確保和TCP的消息邊界),這種架構(gòu)使得RDMA在現(xiàn)有的網(wǎng)絡(luò)中傳輸變的可能,由于iWARP是通過(guò)TCP/IP的RDMA,也享受了TCP/IP提供了可靠的通信路徑,支持多地子網(wǎng)尋址功能,以及TCP/IP帶來(lái)的可擴(kuò)展性。iWARP由硬件執(zhí)行TCP/IP的處理,從應(yīng)用里完全提取出網(wǎng)絡(luò)協(xié)議占的處理,同時(shí)由于傳統(tǒng)網(wǎng)絡(luò)對(duì)TCP的支持我們?cè)趥鹘y(tǒng)網(wǎng)絡(luò)中部署的應(yīng)用可以直接使用,這種方式大大減少了我們?cè)谟布Y源等方面的消耗。
Rashti[17]在10Gbps以太網(wǎng)下對(duì)比了iWARP和Infiniband的性能,實(shí)驗(yàn)顯示消息字節(jié)在1byte到1Kbyte的情況下iWARP在時(shí)延和帶寬的性能都是比Infiniband高的。這也說(shuō)明在高速的網(wǎng)絡(luò)下即使不適用新的體系結(jié)構(gòu)我們?nèi)耘f可以通過(guò)RDMA技術(shù)來(lái)實(shí)現(xiàn)性能的提升。而將RDMA應(yīng)用到以太網(wǎng)上無(wú)論從網(wǎng)絡(luò)性能的角度還是經(jīng)濟(jì)適用上都是一個(gè)不錯(cuò)的選擇。
3.4RoCE(RDMA over Converged Ethernet)技術(shù)
隨著IEEE提出的數(shù)據(jù)中心橋接技術(shù)(Data Center Bridging, DCB),使得數(shù)據(jù)鏈路層性能急劇提升。
由于DCB提供了擁塞控制,在iWARP的TCP,SCTP和RDDP中提供的擁塞控制功能就變得冗余起來(lái),在DCB中,TCP慢啟動(dòng)行為能夠被減弱或者移除,因此在DCB中布置一個(gè)最合適的協(xié)議來(lái)減少iWARP的復(fù)雜性和布置問(wèn)題,RoCE就是在這種情況下提出來(lái)的。
IEEE數(shù)據(jù)中心橋接技術(shù)主要包括基于優(yōu)先級(jí)的流量控制(Priority-based Flow Control, PFC),量化擁塞通知(Quantized Congestion Notification, QCN)在DCB技術(shù)支撐下實(shí)現(xiàn)了無(wú)損以太網(wǎng),以及對(duì)RDMA的支持。
RoCE基于融合以太網(wǎng)的RDMA是一種可以極低延遲在無(wú)損以太網(wǎng)絡(luò)上提供高效數(shù)據(jù)傳輸?shù)臋C(jī)制,由于RoCE以及RoCEv2的提出使RDMA更加高效的運(yùn)行在以太網(wǎng)上,RoCEV2是對(duì)IB協(xié)議棧的一種改進(jìn)和增強(qiáng),保留了IB的傳輸層,使用IP和UDP封裝代替了IB的網(wǎng)絡(luò)層,同時(shí)使用以太網(wǎng)代替了IB的鏈路層,在UDP報(bào)頭中加入了ECMP,為了有效的運(yùn)轉(zhuǎn)RoCE同時(shí)提供了無(wú)損的第二層。圖5為RoCE的網(wǎng)絡(luò)協(xié)議棧,相比于iWARP復(fù)雜的網(wǎng)絡(luò)層,RoCE的模型顯得更加簡(jiǎn)單。
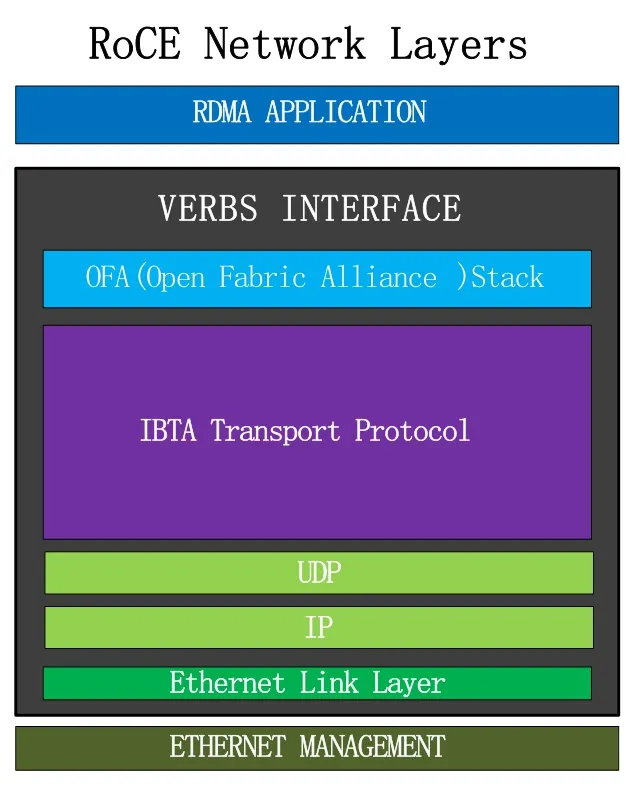
圖5 RoCE網(wǎng)絡(luò)協(xié)議棧
相比于iWARP,一個(gè)包僅僅觀察他的UDP目的地端口的值和IANA分配的端口值是否匹配,就可以知道他是否為ROCE包,這種方式在很大程度簡(jiǎn)化了流量分析和管理。
iWARP使用傳統(tǒng)TCP協(xié)議棧共享端口,所以會(huì)限制了它的高消費(fèi)和布置的難度。ROCE包頭封裝了IP和UDP,意味著RoCE可以在L2和L3層運(yùn)行,可以在L3層路由可以使RDMA帶來(lái)構(gòu)造多子網(wǎng)的功能,同時(shí)由于Soft-RoCE的布置,RoCE可以通過(guò)軟件布置而不需要本地硬件,這使得ROCE可以在數(shù)據(jù)中心獲得更加靈活的性能。
在文獻(xiàn)[18]中Mellanox對(duì)RoCE和iWARP進(jìn)行了性能的比較,在消息字節(jié)大小為100B的情況下,平均延遲相差20微秒,99%的情況下RoCE的延遲比iWARP低40微秒,同時(shí)RoCE具有更低的CPU占用率。
4 總結(jié)
本文從TCP協(xié)議和主機(jī)端的數(shù)據(jù)傳輸方式分析了傳統(tǒng)的網(wǎng)絡(luò)結(jié)構(gòu)的弊端,總結(jié)了幾種高效的網(wǎng)絡(luò)性能提升的方式.
第一類方法考慮到硬件的處理效率,直接將部分協(xié)議搬遷至硬件實(shí)現(xiàn)提高網(wǎng)絡(luò)性能,這種方式比較直接,但是需要特殊的硬件支持,不適用于大規(guī)模布置,而且硬件更新?lián)Q代的速度非常快,接口常常難以兼容,接口設(shè)置復(fù)雜。第二類方法考慮在以太網(wǎng)下對(duì)協(xié)議優(yōu)化,在不改變整個(gè)架構(gòu)的基礎(chǔ)上做出的性能提升,可擴(kuò)展性強(qiáng),而且由于以太網(wǎng)的普遍使用,適用性很強(qiáng),但是這樣做仍舊出于傳統(tǒng)的TCP體系下,TCP本身就是一個(gè)笨拙的體系結(jié)構(gòu),在TCP的改進(jìn)雖然有效,但是隨著以太網(wǎng)的提速也慢慢顯出不適。第三種方法是將RDMA的想法應(yīng)用在以太網(wǎng)上,RDMA的思想源于IB,但是由于應(yīng)用不兼容,體系不同,將RDMA部署在以太網(wǎng)上是一種趨勢(shì),而且從數(shù)據(jù)分析來(lái)看,RDMA確實(shí)提高了網(wǎng)絡(luò)帶寬,降低了延遲,減少了CPU的占有率,對(duì)于網(wǎng)絡(luò)性能的提升是很可觀的,基于以太網(wǎng)的結(jié)構(gòu)又可以讓它輕易擴(kuò)展,是當(dāng)下提升網(wǎng)絡(luò)性能的一種較優(yōu)的方式。
[1] M.Allman, V.Paxson,E Blanton.TCP congestion control. RFC 5681.
[2] Y.Zhu, H.Eran, D.Firestone, C.Guo. Congestion Control for Large-Scale RDMA Deployments. In SIGCOMM Computer Communication Review, New York, USA, 2015:Volume 45 Issue 4
[3] S.Floyd.TCP and Explicit Congestion Notification. In ACM SIGCOMM Computer Communication Review, New York, USA, 1994: Volume 24 Issue 5.
[4] M.Alizadeh, A Greenberg, DA Maltz, J Padhye. Data Center Tcp. In ACM SIGCOMM Computer Communication Review, New York, USA, 2010: Volume 40 Issue 4.
[5] B. Vamanan, J.Hasan, TN Vijaykumar. Deadline-aware Datacenter Tcp. In ACM SIGCOMM Computer Communication Review, New York, USA, 2012: Volume 42 Issue 4.
[6] S.Joy, A Nayak. Improving Flow Completion Time for Short Flows In Datacenter Networks. In IFIP/IEEE International Symposium on Integrated Network Management (IM), Ottawa. ON.
[7] K. Kant. TCP Offload Performance for Front-end Servers. In Global Telecommunications Conference, USA, 2003: volume 6
[8] W. Feng, P. Balaji, L.N Bhuyan, D.K. Panda. Performance characterization of a 10-Gigabit Ethernet TOE. In Symposium on High Performance Interconnects, 2005.
[9] J.C Mogul, P. Alto. TCP offload is a dumb idea whose time has come, 9th Workshop on Hot Topics in Operating Systems, senix Assoc, 2003.
[10] P. Sarker, K. Voruganti. Storage over IP: Does hardware support help? In Proc. 2nd USENIX Conf. on File and Storage Technologies, San Francisco, CA, 2003.
[11] Intel. White Paper. Accelerating High-Speed Networking with Intel?I/O Acceleration Technology. http://www.intel.com/content/www/xr/en/io/i-o-accelerationtechnology-paper.html
[12] Intel. Competitive Guide. Competitive Comparison Intel?I/O Acceleration Technology vs. TCP Offload Engine. http://www.intel.com/content/www/us/en/wireless-network/a ccel-technology.html
[13] J. Shu, B. Li, Weimin Zheng. Design and Implementation of an SAN System Based on the Fiber Channel Protocol. In IEEE Transaction on Computers, 2005: volume 54.
[14] K. Malavalli, High-speed Fiber Channel Switching Fabric services, In Proceedings of the SPIE,USA,1992:Volume 1577
[15] R. Buyya, T.Cortes, H. Jin, An Introduction to the InfiniBand Architecture(http://www.infinibandta.org), In IEEE Press, 2001.
[16] A. Vishnu, A.R Mamidala, W Jin, D.K Panda, Performance modeling of subnet management on fat tree InfiniBand networks using OpenSM, 19th IEEE International Parallel and Distributed Processing Symposium, 2005.
[17] M.J. Rashti, A. Afsahi, 10-Gigabit iWARP Ethernet: Comparative Performance Analysis with InfiniBand and Myrinet-10G, In 2007 IEEE International Parallel and Distributed Processing Symposium, Long Beach, CA, 2007.
[18] Mellanox. White Paper. RoCE vs. iWARP Competitive Analysis Brief. http://www.techrepublic.com/resource-library/whitepapers/ro ce-vs-iwarp-competitive-analysis-brief/.
[19] J. MO, R. La, V. Anantharam, J. Walrand, Analysis and comparison of TCP Reno and Vegas,In IEEE INFOCOM, 1999.
[20] T. Hamann, J. Walrand, A new fair window algorithm for ECN capable TCP (new-ECN), In INFOCOM, Tel Aviv, 2000.
[21] D. Tang, Y. Bao, W.Hu, M. Chen, DMA cache: Using onchip storage to architecturally separate I/O data from CPU data for improving I/O performance, In 16th International Symposium on High-Performance Computer Architecture, Bangalore, 2010.
[22] R. Recio, B. Metzler P. Culley, J. Hilland, D. Garcia. A Remote Direct Memory Access Protocol Specification. RFC 5040, 2007.
[23] H. Shah J. Pinkerton R. Recio P. Culley, Direct Data Placement over Reliable Transports, RFC 5041,2007.
[24] J. Pinkerton E. Deleganes, Direct Data Placement Protocol (DDP)/Remote Direct Memory Access Protocol (RDMAP) Security, RFC 5042,2007.
[25] C. Bestler, R. Stewart, Stream Control Transmission Protocol (SCTP)/Direct Data Placement (DDP) Adaptation, RFC 5043, 2007.
[26] P. Culley, U. Elzur, R. Recio, S. Bailey, J. Carrier, Marker PDU Aligned Framing for TCP Specification, RFC 5044, 2007.
[27] K. Ramakrishnan, S. Floyd, and D. Black. The addition of explicit congestion notification (ECN). RFC 3168.
[28] Riesbeck, C.K. & Martin, C.E, Direct Memory Access Parsing. In J. Kolodner & C. Riesbeck (Eds) Experience, Memory and Reasoning, 1986.
[29] A. Munir, I. A Qzai, Z.A Uzmi, A. Mushtaq, S. N Ismail, M. S Iqbal, B. Khan, Minimizing flow completion times in data centers, In INFOCOM, Turin, 2013
[30] 王曉艷. 基于云計(jì)算的數(shù)據(jù)中心建設(shè)探討[J]. 軟件, 2014, 35(2): 129-130
[31] 錢育蓉, 于炯, 英昌甜, 等. 云計(jì)算環(huán)境下新疆遙感應(yīng)用數(shù)據(jù)中心的挑戰(zhàn)與機(jī)遇[J]. 軟件, 2015, 36(4): 58-61
[32] 信懷義, 安衛(wèi)杰. 金融數(shù)據(jù)中心數(shù)據(jù)備份必要性及其機(jī)制研究[J]. 軟件, 2015, 36(12): 72-75
[33] 張宇翔. 面向質(zhì)量評(píng)估的高校教學(xué)數(shù)據(jù)中心數(shù)據(jù)模塊的設(shè)計(jì)與實(shí)踐[J]. 軟件, 2016, 37(4): 51-53
High Speed Data Transport Technology for Datacenter Network
QIN Xuan-long1, LI Da-gang1, DU Zheng2, CHEN Yuan-lei2
(1. School of Electronic and Computer Engineering, Peking University Shenzhen Graduate School, Shenzhen 518055, China; 2. Department of High Performance Computing, National Supercomputing Center in Shenzhen, Shenzhen 518055, China)
Data center is the common infrastructure for cloud computing as well as big data application. At present almost all data center network use TCP/IP protocol running on Ethernet technology. With the increase in speed of Ethernet, the TCP/IP protocol and its way of implementation has been unable to meet the requirements of high speed data transmission and is even becoming the bottleneck of the network performance. After analyzing the characteristics of the existing data center network and the real-life performance of the network implementation, this paper will compare and summarize a variety of network performance optimization technologies, and then analyze the future research directions.
TCP; Datacenter Network; Ethernet; RDMA
TP393.03
A
10.3969/j.issn.1003-6970.2016.09.001
國(guó)家重點(diǎn)研發(fā)計(jì)劃“資源準(zhǔn)入和分級(jí)標(biāo)準(zhǔn)體系建設(shè)”(2016YFB0201401);深圳市公共技術(shù)服務(wù)平臺(tái)項(xiàng)目“深圳市工業(yè)設(shè)計(jì)云服務(wù)平臺(tái)”(GGJS20150429172906635);深圳市技術(shù)攻關(guān)項(xiàng)目“重20150075:面向智能城市管理的大數(shù)據(jù)智能分析關(guān)鍵技術(shù)研究”(JSGG2015051214574248)
秦宣龍(1993-),男,研究生,主要研究方向:數(shù)據(jù)中心網(wǎng)絡(luò);都政(1981-),男,高級(jí)工程師,主要研究方向:高性能計(jì)算、云計(jì)算與大數(shù)據(jù)分析;陳遠(yuǎn)磊(1988-),男,工程師,主要研究方向:大數(shù)據(jù)分析處理技術(shù)。
通訊聯(lián)系人: 李大剛(1975-),男,助理教授,主要研究方向:高性能網(wǎng)絡(luò)及分布式存儲(chǔ)技術(shù)。
猜你喜歡
房地產(chǎn)導(dǎo)刊(2022年5期)2022-06-01 06:20:14
能源工程(2022年1期)2022-03-29 01:06:28
建材發(fā)展導(dǎo)向(2021年12期)2021-07-22 08:06:48
建材發(fā)展導(dǎo)向(2021年7期)2021-07-16 07:07:52
中學(xué)生數(shù)理化(高中版.高二數(shù)學(xué))(2021年12期)2021-04-26 07:43:48
中學(xué)生數(shù)理化(高中版.高考數(shù)學(xué))(2021年12期)2021-03-08 01:28:50
今日農(nóng)業(yè)(2020年16期)2020-12-14 15:04:59
消費(fèi)導(dǎo)刊(2018年8期)2018-05-25 13:20:08
家庭影院技術(shù)(2018年4期)2018-05-09 07:07:41
電子制作(2017年20期)2017-04-26 06:57:45
