幾種基于MOOC的文本分類算法的比較與實現
2016-11-29 03:42:29劉鑫昊譚慶平唐國斐
軟件 2016年9期
劉鑫昊,譚慶平,曾 平,唐國斐
(國防科學技術大學 計算機科學與技術學院,湖南 長沙 410073)
幾種基于MOOC的文本分類算法的比較與實現
劉鑫昊,譚慶平,曾平,唐國斐
(國防科學技術大學 計算機科學與技術學院,湖南 長沙410073)
機器學習是人工智能的主要內容之一,文本分類正是機器學習中典型的監督學習場景。而機器學習在在線教育平臺中的應用正是現階段的發展趨勢。首先介紹了文本分類的背景及意義,文本分類系統中的文本預處理部分,介紹了信息增益算法、主要成分分析等相關技術;文本分類的分類算法部分,主要介紹了AdaBoost技術。在遵循文本分類流程的基礎上,設計了一個3模塊文本分類系統:一、中文分詞及去停止詞模塊;二、文本向量化及特征降維模塊;三、分類器模塊。文本分類系統的具體實現上,全部采用開源工具完成,使用Ansj實現模塊一,Weka實現模塊二、三。按照文本分類流程,利用文本分類系統進行了實驗,并對實驗中得到的數據進行了分析和總結。為了提升最后的分類效果,在特征降維這一步中,添加了IG-LSA(信息增益(IG)-潛在語義分析(LSA))的混合降維方法。
文本分類,機器學習,特征選擇,特征抽取
本文著錄格式:劉鑫昊,譚慶平,曾平,等. 幾種基于MOOC的文本分類算法的比較與實現[J]. 軟件,2016,37(9):27-33
1 引言
在當今的信息時代,Internet已經大規模普及,借助互聯網技術的發展,每天我們所生活的這個世界都會出現大量的信息,信息的增長速度絕對是前人無法想像的,而這其中,各種電子文檔、電子郵件和網頁一方面豐富著網絡,另一方面也對信息管理提出了更高的要求。在這樣的條件下,本文致力于處理MOOC在線教育平臺中課程、課件以及相關論壇中的討論信息,對先關信息進行處理、分析,以便于得到有用的信息,對老師和學生提出改進性的建議,便于MOOC在線教育平臺更好的發展。而利用機器完成自動文本分類,時間和資源開銷得到有效控制的情況下,文本分類效果也能滿足人們對分類的需求。除此之外,文本分類技術在信息過濾、信息檢索、文本數據庫、數字化圖書館、搜索引擎等諸多領域也都得到了廣泛的應用。
本文對文本分類[1]算法進行了研究,文本分類的主要流程如圖1.1所示,本文設計實現了一個多分類文本分類系統,采用不同特征抽取,結合不同分類算法進行實驗,分析對比了實驗結果,給出了結論,給出一種最具有時效性的,能夠短期內滿足需求的解決方法——分類器組合。

圖1 .1 文本分類流程
文章重點介紹了文本預處理、分類器選擇、分類器優化以及實驗四個部分,介紹了中文分詞[2]、去停止詞,文本表示(即轉換為更適合機器學習的向量空間模型( VSM)),以及為了降低特征維度所采用的幾個特征提取算法:信息增益IG,潛在語義分析LSA,主成分分析PCA。以及屬Booosting類算法的Addaboost算法。最后進行全文總結。
2 文本預處理
在進行文本分類時,由于文本文件中的文本內容以字符串的形式存儲,無法直接被計算機處理用于文本分類,所以,必須對所用文本數據進行處理,轉換為計算機能直接處理,適用于文本分類的形式,而這一過程,稱之為文本預處理。主要包括中文分詞、去停止詞、詞頻統計等。這里重點介紹信息增益、潛在語義分析和主要成分分析。
2.1信息增益
信息增益(information gain)[3,4]是特征選擇時常用的一個評估算法,在信息增益中,重要性的衡量標準就是特征能夠為分類系統帶來信息的多少,一個特征帶來的信息越多,信息量越大,該特征越重要。

信息增益是針對一個個特征而言的,計算信息增益,就是看一個系統中,存在特征ti和不存在特征ti時系統的信息量各是多少,其差值就是就是特征ti帶給系統的信息量,即增益。存在特征ti時系統的信息量可直接由熵值計算公式得出。而系統不含特征ti的熵值無法直接得到,所以采用固定ti的方法得到,即將特征ti固定為每一個可能取值Xi,算出此時熵值,然后根據概率Pi取均值。
2.2潛在語義分析
潛在語義分析LSA[5](Latent Semantic Analysis)屬于特征抽取類算法,它首先利用統計計算的方法,先行分析數據集,進而提取出詞與詞之間潛存的語義結構,并使用這種潛在的語義結構,表示詞和文本,以消除詞之間的相關性和簡化文本向量,最終實現降維的目的。
潛在語義分析的基礎是奇異值分解SVD[6](Singular Value Decomposition),利用SVD把高維的向量空間模型(VSM)表示的文本映射到低維的潛在語義空間中。SVD是線性代數中一種重要的矩陣分解,是矩陣分析中正規矩陣酉對角化的推廣。在信號處理、統計學等領域有重要應用。
假設M是一個m×n階矩陣,其中的元素全部屬于域K,也就是實數域或復數域。如此存在一個分解使得:

X:m×m階酉矩陣;Y:半正定m×n階對角矩陣;Z*:Z的共軛轉置,是n×n階酉矩陣。這樣的分解稱作M的奇異值分解。Y對角線上的元素Yi,i即為M的奇異值。常見做法是由大到小排列奇異值。如此由M唯一確定Y(X、Z仍不能確定)。
2.3主要成分分析
主成分分析PCA(Principal Component Analysis),是一種特征提取常用的方法。主成分分析將多個變量通過線性變換以選出較少個數重要變量。主成分分析PCA主要方法是通過對協方差矩陣進行特征分解[7],以得出數據的主成分(即特征向量)與它們的權值(特征值[8])。
在很多情況下,特征與特征之間具有一定的相關關系,當兩個特征之間有一定相關關系時,可以理解為這兩個特征代表的類別的信息有一定的重疊。主成分分析PCA對于原有特征集,重新構建盡可能少特征的新特征集,并且使得新特征集中的這些新特征是兩兩不相關的,而且這些新特征在反映類別的信息方面盡可能保持原有的信息。
主成分分析作為一種分析、簡化數據集的技術,經常用于減少數據集的維數,同時保持數據集中的對方差貢獻最大的特征。這是通過保留低階主成分,忽略高階主成分做到的。這樣低階成分往往能夠保留住數據的最重要方面。但是,這也不是一定的,要視具體應用而定。由于主成分分析依賴所給數據,所以數據的準確性對分析結果影響很大。
主成分分析PCA是最簡單的以特征量分析多元統計分布的方法。其結果可以理解為對原數據中的方差做出解釋:哪一個方向上的數據值對方差的影響最大?換而言之,PCA 提供了一種降低數據維度的有效辦法;如果分析者在原數據中除掉最小的特征值所對應的成分,那么所得的低維度數據必定是最優化的(這樣降低維度也必定是失去信息量最少的方法)。
3 分類器的選擇
目前很多分類算法被研究者從不同角度提出,判斷不同分類算法的好壞可以由準確率、速度、健壯性、可伸縮性、可解釋性等幾個標準來衡量。經典的分類算法在不同的領域取得成功,比如貝葉斯算法、決策樹算法、支持向量機算法等。針對MOOC在線教育平臺的數據處理中,通過實驗發現,相比于其他算法,Adaboost算法在處理這些數據上有一定的優勢。因此這里具體介紹一下Adaboost算法。
Adaboost[9]是英文“Adaptive Boosting”(自適應增強)的縮寫,是一個能提高文本分類算法效果的一種迭代算法,Adaboost屬于Boosting類算法[10]的代表算法,Adaboost本身并不分類,而是旨在由弱分類器構成強分類器。Boosting方法是一種在弱分類算法基礎上提高準確度的方法,它是一種框架算法,首先對樣本集S操作獲得樣本子集S1,然后用弱分類算法在樣本子集S1上訓練生成的基分類器C1。將弱分類算法生成的基分類器C1放于Boosting框架中,通過Boosting框架對訓練樣本集的操作,得到新的訓練樣本子集S2,用該樣本子集S2去訓練生成基分類器C2每得到一個樣本集Si就用該基分類算法在該樣本集Si上產生一個基分類器Ci,這樣在給定訓練輪數n后,就可產生n個基分類器,然后Boosting框架算法將這n個基分類器進行加權融合,產生一個最后的結果分類器,在這n個基分類器中,每個單個的分類器C1的識別率不一定很高,但集合后的強分類器有很高的識別率,這樣便提高了弱分類算法的識別率。在產生單個的基分類器時可用相同的分類算法,也可用不同的分類算法,這些算法一般是不穩定的弱分類算法,如神經網絡(BP),決策樹(C4.5)等。

圖1 Boosting算法流程
圖1中,矩形代表過程,平行四邊形代表數據。總數據集S根據分發權值Di得到子數據集Si,經過訓練得到基分類器Ci,得到下一個基分類器Ci+1對應的數據集分發權重Di+1。最終將所有基分類器整合,得到一個強分類器C。實際使用中,由于事先很難知道弱分類算法分類正確率的下限,所以Boosting算法在解決實際問題時有重大缺陷。AdaBoost解決了這一問題,文章以DSAE(降噪稀疏自動編碼器)為弱分類器基本原型,調整層數以及激勵函數種類構造不同條件下的弱分類器,使用NLPIR分詞系統提取文本特征,TF-IDF作為詞語的權值,根據該權值來選擇特征次,并統計詞頻作為文本特征訓練集。AdaBoost方法使用的弱分類器只要不是隨機概率0.5,最終模型都會得到提高,因為即使使用的弱分類器準確率小于0.5,只要權值Wi取負數,最終模型也會提高準確率。
AdaBoost每一輪利用前一個分類器分錯的樣本Si,訓練一個新的弱分類器Ci,直到的錯誤率小于某一個閾值。每一個訓練樣本最終都會被賦予一個相應權重Di,對應被其中某分類器選入訓練集的概率。已經被準確地分類的樣本點,會有更低概率被選入下一個訓練集中;反之,概率就提高。如此通過不斷迭代的方式,AdaBoost方法最終能“聚焦”于那些弱分類器較難分樣本上。在具體實現時,最初每個樣本的權重都一樣,每次迭代,根據權重選取樣本點,進而訓練分類器Ci正確分類樣本的權重。更新過權重的樣本集又用于下一輪迭代,不斷跌待下去直到達到制定閾值。
4 實驗的設計與實現
這里的實驗主要分為三個部分,分別是分詞及去停止詞模塊、特征降維模塊和分類器模塊。
4.1分詞及去停止詞模塊
分詞及去停止詞模塊承擔對中文文本的分詞及去停止詞兩個操作,輸入為語料庫中的文檔,輸出為已完成中文分詞及去停止詞的文檔。
中文分詞采用漢語詞法分析系統ICTCLAS (Institute of Computing Technology,Chinese Lexical Analysis System)的java實現,工具Ansj。ICTCLAS由中國科學院計算技術研究所發布,無論是準確率還是處理速度都較同類算法有很大的優勢。是目前最好的中文分詞開源系統。分詞系統中的分詞數據結構采用tire樹結構,也就是詞典樹,一種哈希樹變種。常見應用于統計和排序大量的字符串(不僅限字符串),所以也常被搜索引擎系統用于文本的詞頻統計。
4.2特征降維模塊
文本向量化及降維模塊將原始的多文檔形式的語料庫轉換為單一文件,內部結構為VSM[11],然后在此基礎上實現特征提取。輸入為包含多文檔的文件夾,各類文檔文件存放于類同名子文件夾中。輸出為單文件。模塊功能的具體實現由調用Weka完成,先將文件夾轉化為單文件,然后統計計算生成詞的TF-IDF值,并以此作為VSM的權值把的數據向量化,轉化為VSM,最后得到單文件的ARFF(Weka定義及使用的機器學習用文件格式)文件,而其中SMO優化算法(Sequential minimal optimization)[12],由Microsoft Research的John C.Platt在1998年提出,并稱為最快的二次規劃優化算法,特別針對線性SVM和數據稀疏性能更優。
降維使用的算法方面, 特征選擇和特征抽取算法都會采用,特征選擇算法方面,考慮到以詞作為特征,選擇了信息增益IG算法[13],因為其對詞特征的評估比較適合;特征提取算法方面,主題模型類算法選擇了潛在語義分析LSA,非主題模型類算法采用了主成分分析PCA,這兩個算法都能適用于文本分類的任務。
一般情況下,特征選擇和特征抽取兩者在一個分類任務里只有一種會被采用,兩種方法各有自己特點、優劣,但是很少有直接兩者一起使用的。所以,本次實驗,增加了一個特征選擇和特征抽取兩者混合使用進行降維的方法,稱之為IG-LSA,具體為先使用IG進行初步降維,然后使用LSA進一步降維這樣混合的兩步降維方法。先使用IG進行初步降維后特征集的平均熵值較之前能得到提高,這樣的特征集再使用LSA進行在此降維,理論上,得到的數據集相較僅使用LSA得到的數據集在分類器上能有更好的表現。
4.3分類器部分
分類器模塊實現訓練分類器及測試分類器的功能。訓練部分,輸入為已經過降維處理的數據集,選擇目標分類算法后利用訓練數據即可獲得一個對應的分類器;測試部分,輸入測試數據,并用訓練所得的分類器進行測試,輸出測試結果。
訓練及測試的具體實現由Weka[14]提供的強大機器學習算法集合提供,文本分類可用算法眾多,綜合考慮各算法的優缺點后,選擇了樸素貝葉斯[15]、決策樹算法[16],由于支持向量機在分類問題上表現優異,是最好的分類器之一,所以選擇了SVM作為第3種分類算法,考慮到樸素貝葉斯以與決策樹并不穩定,所以將樸素貝葉斯、決策樹與優化后的AdaBoost算法結合進行了對比實驗。
5 實驗結果及分析
5.1數據集
中文語料庫選擇:《Coursera研究數據集》。 選取文本類別及數量見表1,文本皆存放在所屬類同名子文件夾內,5個子文件夾存放于resource文件夾內。經過轉化后得到了可用于文本分類的“vsm.arff”,統計信息見表2。

表1 實驗用語料

表2 vsm.arff統計信息
對vsm.arff進行特征提取,采用的特征提取算法及保留特征集大小見表3. 最后得到的數據見表4,共80個數據集。

表3 特征抽取情況

表4 特征抽取后得到的數據集
IG50代表對vsm.arff使用IG,保留50個特征,得到IG50.arff;
IG-LSA,IG-PCA設定為使用IG時保留特征量為1000,然后使用LSA,PCA進一步降維;
IG1000LSA5代表對vsm.arff使用IG保留1000個特征,然后使用LSA得5個特征,得到IG1000L SA50.arff;
5.2評估標準
P(Precision):準確率,分類后,在某一特定類中,分對文本數/實際分到該類文本總數。
R(Recall):召回率,分類后,在某一特定類中,分對文本數/應分到該類文本總數。
F-Measure又稱為F-Score,信息檢索時常用的評價標準,計算公式為:

其中β是參數,P是精確率(Precision),R是召回率(Recall)。當參數β=1時,就是最常見的F-1:

5.3實驗結果
5.3.1樸素貝葉斯分類器實驗結果
由F-1數據圖2可以看出,當使用樸素貝葉斯分類器時,隨著保留的特征數量下降,IG得到的數據集在樸素貝葉斯分類器上的表現也隨之下降,其他三種方法LSA、IG-LSA和IG-PCA則隨著保留特征數量的下降F-1值逐漸上升,但是使用IG總體準確率依舊較其他三種特征抽取方法更高,僅當特征保留數降至20,IG方法的F-1值被其他三種方法所超過。

表5 樸素貝葉斯分類器

圖2 樸素貝葉斯分類器F-1折線圖
5.3.2決策樹分類器實驗結果
圖3,決策樹分類器F-1值折線圖中,IG方法F-1值隨特征保留量減少而下降,且特下降幅度逐漸增大。LSA、IG-LSA、IG-PCA三種方法則隨著特征保留量的下降,F-1值呈輕微穩定上升趨勢。特征保留量小于50時,IG方法表現降至4種方法最差一位。

表6 決策樹分類器

圖3 決策樹分類器F-1折線圖
5.3.3支持向量機分類器實驗結果
從圖4可以看到,支持向量機分類器的實驗部分,使用IG-LSA得到的數據集在分類器中的表現十分優秀,F-1值已達99%以上。LSA和IG-PCA兩種方法最終實驗結果F-1值也能達到92.7%~94.4%。從數據來看,隨著特征保留量減少,4種方法的表現都隨之下降。IG-LSA下降幅度極低,LSA和IG-PCA兩種方法較小,從94%左右下降到92%左右。IG方法下降較大,且下降幅度逐漸增大。

表7 支持向量機分類器

圖4 支持向量機分類器F-1折線圖
使用SMO已有相當高的準確率,所以AdaBoost實驗部分只結合樸素貝葉斯和決策樹進行實驗。
5.3.4Adaboost-樸素貝葉斯分類器實驗結果
圖5中,IG1,IG-LSA1折線為Adaboost-樸素貝葉斯分類器實驗結果,IG2,IG-LSA2折線為樸素貝葉斯分類器實驗結果。從圖中可以看出,使用IG時,僅當特征量為200時,使用AdaBoost對樸素貝葉斯分類算法有提高作用,當特征保留量更小時,使用AdaBoost沒有提高作用。使用IG-LSA時,AdaBoost對樸素貝葉斯分類算法提升很大,不過提升幅度逐漸減少。

表8 Adaboost-樸素貝葉斯分類器

圖5 Adaboost算法對比實驗F-1實驗圖
5.3.5Adaboost-決策樹分類器實驗結果
圖6中,IG1,IG-LSA1折線為Adaboost-決策樹分類算法實驗結果,IG2,IG-LSA2 折線為決策樹分類算法實驗結果。從圖中可以看出,使用IG時,使用改進后的AdaBoost對決策樹分類算法有提高作用,但是隨著特征維數降低而減少。使用IG-LSA時,使用改進后的AdaBoost對決策樹算法有較大的穩定提升。
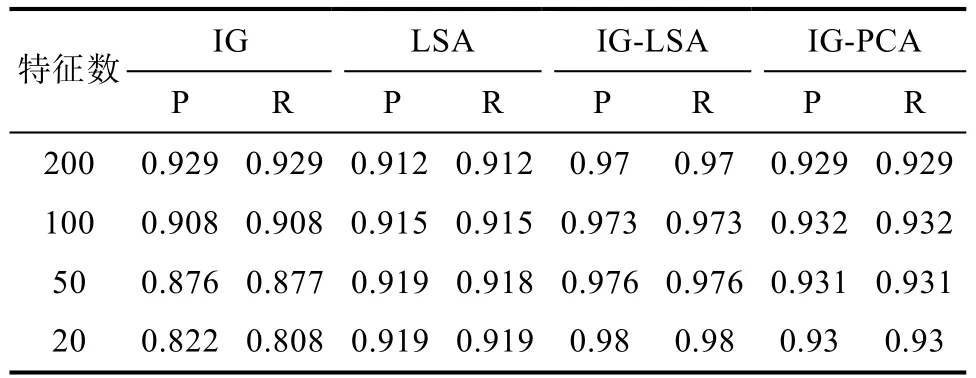
表9 Adaboost-決策樹分類器

圖6 Adaboost-決策樹對比實驗F-1折線圖
5 結束語
從5個分類實驗的F-1值折線圖可以看出,使用IG時,所有分類器的表現都隨著特征保留量的下降而下降,而使用特征抽取類算法如LSA,IG-PCA,IG-LSA時,隨著特征保留量的下降,各分類器上的表現呈上升或保持原有水平。實驗結果表明,當直接使用詞作為特征時,分類表現與特征保留量呈正相關關系,若計算機處理能力能夠接受的情況下,使用特征選擇降維時應盡可能保留多的特征。
使用AdaBoost技術對分類算法的表現有一定的提升,當使用IG作為降維算法,提升幅度與特征數呈正相關,當特征數降至一定程度后,AdaBoost技術帶來的提升可以基本忽略不計;但是使用IGLSA作為降維算法時,AdaBoost技術對分類算法能帶來穩定的提升,且提升程度較高。
實驗結果可以看到,IG-LSA的混合降維方法,無論相比IG還是LSA,得到的數據集在分類器上的表現都比較優秀。詞與詞之間往往是存在聯系的,而特征抽取方法旨在消除這種聯系,重構出詞與詞之間沒有聯系的新特征集。而在特征保留量較多時,LSA,IG-PCA,IG-LSA在分類器上的表現反而較低。這說明,當特征保留量較多時,LSA,IG-PCA,IG-LSA方法構建出的新特征集含有較多無法完全消除詞與詞之間聯系的新特征,這些多余的特征不僅不能幫助提高分類表現,反而拖累了分類的結果。
對比IG-LS與LSA算法,可以看到IG-LSA數據集在分類器上的表現遠好于LSA數據集,而LSA數據集相比IG數據集在分類器上的表現各有優劣。LSA基于統計分析原數據集以構建新特征集,但是即使去掉了停止詞,原數據集的特征集中往往依舊包含不少對分類沒有貢獻或貢獻很低的詞特征,整體的平均貢獻度不高,對含有不少低貢獻詞特征的特征集進行統計分析重構出的新數據集往往達不到理想的分類效果。但是先使用信息增益對詞特征進行篩選,得到只保留對分類貢獻較大的1000個詞特征的新數據集IG1000,這樣新的數據集中保留的詞特征平均貢獻度更高。對新數據集IG1000進行統計分析重構出的新特征集,在分類器上的表現相對LSA和IG方法都提高很多。
[1] Su Jinshu, ZhangBofeng, Xu Xin. Advances in Machine Learning Based Text Categorization [J]. Journal of Software, 2006, 17(9): 1848-1859.
[2] Long Shuquan, Zhao Wenzheng, Tang Hua. Overview on Chinese Segmentation Algorithm[J].Computer Knowledge and Technology, 2009, 5(10): 2605-2607.
[3] F. Sebastiani. Machine learning in automated text categorization[J] ACM Computing Surveys, 34(1): 1-47, 2002.
[4] 李玲, 劉華文, 徐曉丹,等. 基于信息增益的多標簽特征選擇算法[J]. 計算機科學, 2015, 42(07): 52-56.
[5] Evangelopoulos N E. Latent semantic analysis[J]. Annual Review of Information Science & Technology, 2013, 4(6): 683-692.
[6] Lange K. Singular Value Decomposition[M]. Wiley StatsRef: Statistics Reference Online. John Wiley & Sons, Ltd, 2010: 129-142.
[7] DNA AI,LAN Laboratory. Wiley Interdisciplinary Reviews: Computational Statistics[M]. 2010.
[8] PJA Shaw. Multivariate statistics for the environmental sciences[J]. 2003.
[9] AdaBoost[M].Encyclopedia of Biometrics. Springer US, 2009: 9-9.
[10] Dong Lehong, Geng Guohua, Zhou Mingquan. Design of auto text categorization classfier based on Boosting algorithm[J]. Computer Application, 2007, 27(2): 384-386.
[11] Li Yanmei, Guo Qinglin, Tang Qi. Similarity computing of document based on VSM[C]. Application Research of Computers. 2007.
[12] Platt J C. Sequential Minimal Optimization: A Fast Algorithm for Training Support Vector Machines[C]. Advances in Kernel Methods-support Vector Learning. 1998: págs. 212-223.
[13] Zhang Yufang, Chen Xiaoli, Xiong Zhongyang. Improved approach to weighting terms using information gain[J]. Computer Engineering and Applications, 2007(35): 159-161.
[14] Frank E, Hall M, Holmes G, et al. Weka-A Machine Learning Workbench for Data Mining[M]. Data Mining and Knowledge Discovery Handbook. 2009: 1269-1277.
[15] White, Myles. J. Machine learning for hackers[M].
[16] Yang Xuebing, Zhang Jun. Decision Tree and Its Key Techniques[J]. Computer Technology and Development, 2007, 17(1): 43-45.
Comparision and Implementation of Serveral MOOC-Based Text Classification
LIU Xin-hao, TAN Qing-ping, ZENG Ping, TANG Guo-fei
(Academy of Computer Science and Technology, National University of Defense Technology, Changsha Hunan, ZipCode 41000, China)
Machine learning is one of the main content of artificial intelligence, text classification is a typical supervised learning scene. The development trend of machine learning in online education platform is the stage of the application. This paper firstly introduces the background and significance of text classificatio, The text preprocessing part, include the introductions of the text preprocessing part. mentioned Information Gain, Principal Componet Anlysis and anyother technology. The classification algorithm part, include the introductions of AdaBoost technology. Designed a text classification system consists of three module: module one, Chinese segmentation and stop word removal module; module two, text to vector and feature dimension reduction module; module three, classifier module. Completed the implementation of text classification system by using open source tools, Ansj and Weka. According to the text classification process, carried out experiments by using text classification system, and the experimental data obtained are analyzed and summarized. In order to improve the performance of classification, in feature dimension reduction step, added IG-LSA (information gain-latent semantic analysis) method.
Text classification; Machine learning; Feature selection; Feature extraction
TP181
A
10.3969/j.issn.1003-6970.2016.09.007
國家自然課基金項目(61930007);國家“八六三”高技術研究發展計劃基金項目(2015BA3005)。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
小學教學參考(2015年20期)2016-01-15 08:44:38
