大數據云環境下TDS和BUG混合k-匿名化方法
2016-11-30 08:22:03范曉峰閆鳳劉洋
電信科學 2016年7期
范曉峰 ,閆鳳 ,劉洋
(1.內蒙古商貿職業學院,內蒙古 呼和浩特 010070;2.內蒙古農業大學職業技術學院,內蒙古 包頭 014109;3.呼和浩特職業學院,內蒙古 呼和浩特 010050)
大數據云環境下TDS和BUG混合k-匿名化方法
范曉峰1,閆鳳2,劉洋3
(1.內蒙古商貿職業學院,內蒙古 呼和浩特 010070;2.內蒙古農業大學職業技術學院,內蒙古 包頭 014109;3.呼和浩特職業學院,內蒙古 呼和浩特 010050)
針對一般子樹匿名化方法處理大數據效率低和伸縮性較差的問題,提出了一種可伸縮的自下向上的泛化(BUG)方法,并在此基礎上,結合已有的自上向下的特化(TDS),形成一種混合方法。在提出的方法中,k-匿名作為隱私模型,TDS和BUG都是基于映射化簡開發組成,并通過云的強大計算能力來獲得較高的伸縮性。提出的映射化簡BUG只需在幾次泛化循環之后就可插入一個新的泛化候選,不會影響另一個泛化的信息損失。考慮到工作負載平衡點K與匿名參數k的復雜關系,將映射化簡的BUG和TDS結合形成混合方法。實驗結果驗證了本文方法的有效性,與TDS和BUG相比,混合方法的效率和可伸縮性大為提高。
云計算;子樹匿名化;大數據;泛化;特化;映射化簡
1 引言
目前,云計算和大數據[1]具有顛覆性的趨勢,對IT信息產業和研究領域都產生了重要影響[1,2]。云計算可以通過使用大量電腦彈性地提供大規模的計算和存儲能力,使用戶能夠在沒有大量基礎設施的情況下合理地配置大數據應用。為了開發公共云平臺提供的優勢,越來越多的大數據應用移入云端,因此,如何保護這些數據集的隱私成為一個重要的挑戰,在云上分析和分享數據集之前,迫切需要處理數據隱私的問題。
對數據的隱私保護已經獲得了廣泛的研究,并取得了一定的進展。k-匿名[3]和I-多樣性[4]分別是測量隱私敏感信息、對抗記錄鏈接攻擊和屬性鏈接攻擊程度的兩種基本隱私模型。而一些匿名化操作可用于匿名化數據集,如抑制[5]、泛化[6]和分解[7]等,本文采用泛化來匿名化數據集。關于泛化,一般有4種:全域泛化[5]使一個屬性的所有域值泛化到分類樹的同一級上;子樹泛化[8]需要所有的子域值,但分類樹中所有的中間節點都沒有被泛化;多維泛化[9]在泛化域值時考慮了多個屬性;細胞泛化[10]是局部重新編碼并將相同的實例泛化到域值的不同級別中。
前3種泛化都需要全部重新編碼,而細胞泛化不需要。本文主要討論子樹泛化方法,不同于多維或細胞泛化方法,子樹泛化可以產生一致的匿名數據,該數據可以直接用于現存的數據挖掘和數據分析工具。一般有兩種方法可以實現子樹匿名化,即自上而下的特化(top-down specialization,TDS)和自下而上的泛化(bottom-up generalization,BUG)。迄今為止,研究者們為TDS和BUG提出了一系列的方法。
[11]提出了一種分布式的TDS方法,然而該方法主要關注其他評估的隱私保護而不是伸縮性問題。該方法仍采用信息獲得作為搜索標準,導致其數據效用低。
參考文獻[12]利用映射化簡通過TDS來實現大數據匿名化需要的密集型運算。但是,自上而下的特化在k-匿名參數很小的情況下比自下而上的泛化的執行速度還要慢。
為了研究隱私保護中的匿名化算法伸縮性和效率,參考文獻[13]引入多屬性支持的k-匿名方法,利用可伸縮的決策樹和采樣技術來獲得較高的伸縮性和效率。然而,該方法可以用于多維泛化方案,不能為子樹泛化。
參考文獻[14]提出了一種基于BUG的方法,利用索引數據結構來提高效率,從而不能在云環境中達到較高的伸縮性和并行化。因此,如何開發帶有映射化簡的BUG算法,從而提升伸縮性和效率是一個有前途的方法,但缺少對指定的k-匿名參數的準確獲得。
目前,現有的TDS和BUG方法分別是為了子樹泛化方案而開發。兩者都缺少對使用者指定的k-匿名參數的了解。事實上,k-匿名參數的值可以影響其性能。如果參數k較大,TDS更合適,而BUG的性能會較差;當 k較小時,情況相反。同時考慮到映射簡化廣泛應用于各種數據處理應用程序來增加伸縮性和效率[15]。本文針對大數據中的子樹匿名化提出了一種聯合了TDS和BUG的高度可伸縮的混合方法。當給定一個數據集時,該方法可以通過對比使用者規定的k-匿名參數和來自數據集的閾值自動決定哪個組成進行匿名化。本文的主要貢獻有3條:
· 通過自動選擇TDS和BUG,提升子樹數據匿名化
的伸縮性和效率;
·為BUG設計了一組創新的映射化簡任務,以一種
高度伸縮性的形式推導計算;
· 提出了在一次循環中執行多個泛化操作,推進BUG
的并行處理能力和伸縮性。
2 子樹泛化方案
本節簡要介紹子樹泛化,表1所示為一些基本符號和標記,一個分類樹TTi的葉節點值是D中記錄的原本屬性值,使用QI作為準標識符。為不失一般性,本文采用k-匿名化[3]作為隱私模型,對于任意qid∈QID,QID(qid)必須為0或至少為k,以便一個準標識符不會與至少k-1個準標識符區分開。
在子樹泛化方案中,可以采用兩個操作,即BUG泛化和TDS特化。泛化操作就是在分類樹中用中親值取代域值,而特化操作是用所有的子值取代域值。泛化在形式上的表示為 gen:Child(q)→q,而特化表示為spec:q→Child(q),其中,q∈DOMi為一個域值,集合Child(q)包含了q的所有子域值。利用匿名級的概念[3]來捕獲匿名化的程度,AL匿名化程度用域值集的矢量表示,即AL=
為了選出匿名化過程中最好的操作,通過搜索標準測量候選的泛化或特化,使用信息/隱私權衡作為本文方法的搜索標準,即分別為TDS的信息增益/隱私損失(IGPL)和BUG的信息損失/隱私增益(ILPG)。
考慮到泛化gen:Child(q)→q,泛化的ILPG計算如下:
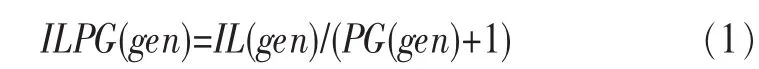
其中,IL(gen)是執行 gen后的信息損失,PG(gen)代表隱私增益,兩者都是通過來源于數據集的統計信息計算得到,Rx表示可以泛化成x屬性值的原始記錄集,|Rx|是Rx中數據記錄的數量,I(Rx)是Rx的熵。IL(gen)定義如下:

表1 基本符號標識和定義
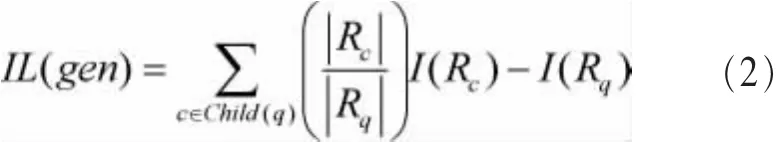
Ad(gen)表示執行 gen后的匿名,而 Ab(gen)是執行 gen之前的匿名,gen的隱私增益計算如下:
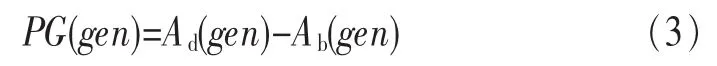
映射化簡是一種可延伸的容錯數據處理結構,具有簡易性、伸縮性和容錯性3種主要特征。映射化簡任務包含兩個原函數:map和reduce,通過鍵值對(key,value)的數據結構定義。map函數可以表示為map:(k1,v1)→(k2,v2),map采用(k1,v1)作為輸入,輸出另一中間鍵值(k2,v2)。這些中間的鍵會作為reduce的輸入而消耗。reduce函數在形式上可以表示為reduce:(k2,list(v2))→(k3,v3),即 reduce采用了中間值 k2及其對應值list(v2)作為輸入并輸出另一對(k3,v3)。通常(k3,v3)列是映射化簡獲得的結果。map和reduce函數都是用戶根據其特定應用程序決定。
3 提出的混合泛化
本節主要描述映射化簡的自下而上泛化(MRBUG),實際的映射化簡程序包含了map和reduce函數,用一個驅動程序來協調映射化簡任務,然后提出了一種混合泛化方法。
3.1 自下而上泛化的映射化簡驅動程序
匿名化的自下而上泛化是一種循環過程,最低匿名級包括分類樹最低級別中的內域節點。每一次循環包括4個主要步驟,即檢測當前數據集是否滿足匿名要求、計算ILPG、尋找最佳的泛化以及根據選擇的最佳泛化方法泛化數據集。
本文為ILPG計算設計映射化簡任務,由于匿名級的概念是一個數據集匿名化狀態,因此不需要將數據集具體泛化到每次循環。算法1為自下而上的泛化映射化簡(BUGMR)驅動程序。
算法1 MRBUG驅動程序
輸入 數據集D,匿名級AL0,匿名參數k
輸出 最終匿名化數據集D*
(1)通過任務ILPG計算為每個關于AL0的泛化初始化搜索標準;
(2)當?gen,Ab(gen)<k;(3)從所有的可用泛化候選中確定可用泛化集AGSet;(4)?gen∈AGSet,將gen標識為不活躍從而在當下匿名級上執行gen;
(5)如果?gen∈AGSet,?gen∈SGSet(gen),那么 gen已經標識為不活躍;
(6)向NGSet中插入一個新的泛化gen New:Child(q)→q,其中,Child(q)={qi|gen:Child(qi)→qi,gen∈SGSet(gen)}
(7)移除SGSet(gen)中的所有泛化;
(8)結束條件;
(9)ALi+1←ALi;通過 ILPG計算為 ALi+1中的所有活躍泛化候選更新ILPG值;
(10)結束如果;
(11)根據ALi通過任務數據泛化將D泛化到D*
算法1的細節如下:首先,預設所有泛化的ILPG值(第1行);第2行檢測當下匿名化數據集是否滿足k-匿名化的需要;第3行識別表示為AGSet的可用泛化集。基本上,AGSet包括最高ILPG值,只根據上述BUG方法的第3步最佳泛化genBest。但是本文在一次循環中執行多次泛化,從而提高并行化和效率的程度,這將在第3.2節中詳細描述。第4行通過將其標識為不活躍來執行AGSet中的泛化過程。將一個泛化過程標識為不活躍意味著在接下來的循環中將不再考慮該泛化過程,理論上在數據集上實現匿名化。當SGSet(gen)中的泛化都標識為不活躍時,將會在匿名級中插入一個新的更高級別的泛化取代不活躍的泛化(第 5~7行)。由于檢測 AGSet中的多泛化,因此很有可能產生多個新的泛化。第9行更新了每個活躍泛化的隱私增益,這是因為AGSet中執行的泛化可能會改變數據集的匿名。而且,如果已經插入了新的泛化,那么就需要計算信息損失,即NGSet≠ 。第11行根據最終的匿名級,匿名化數據集。
第1、9行需要的ILPG估算包括訪問原始數據集和計算數據集的統計信息。第11行也需要處理所有數據集。本文利用映射化簡來執行這些情況下的密集型運算。本文設計了映射化簡任務:為完成第1、9行所需的計算,進行ILPG估算任務,為獲得第11行中的具體匿名化,進行數據泛化任務。
3.2 執行泛化的并行性
一些觀察值也可以有助于設計出有效的ILPG的映射化簡任務。自下而上的泛化在幾次泛化循環之后插入一個新的泛化候選。另一個是根據式(2)泛化,不會影響另一個泛化的信息損失。根據這個觀察值,本文可以在一次循環中考慮多個泛化候選,從而提高本文提出方法的并行性。然而,執行一次泛化可能會改變數據集的匿名,并影響每個泛化候選的隱私增益。為了確定一次循環可以同時考慮哪些候選,本文給出下列定義。
定義1 (匿名標識符)如果|QIG(qid)|=minqid′∈QID|QIG(qid)′|,那么準標識符 qid就是一個匿名準標識符,其中,|·|表示 QI-組的大小。
具有一個匿名準標識符的QI-組的大小取決于定義1中的數據集匿名化。值得注意的是,在一個匿名級中可能具有多個匿名準標識符。AQISet表示匿名準標識符的集合。本文定義關鍵詞泛化如下。
定義 2 (關鍵的泛化)如果?q′∈Child(q),q′∈∪qid∈AQISet{qi|qi=Proji(qid),1≤i≤m}那么泛化 gen:Child(q)→q是關鍵的,其中,Proji(qid)是qid的第i個坐標。
CGSet表示關鍵泛化的集合,即 CGSet=∪qid∈AQISet{qi|qi=Proji(qid),1≤i≤m}。 非關鍵泛化的集合表示為 NCGSet,且,根據上述定義得出:
如果一個泛化gen∈CGSet,執行該泛化可能會改變數據集的匿名,即Ap(gen)-Ab(gen)可能會大于0。相反,如果gen∈NCGSet,Ap(gen)-Ab(gen)=0,則 PG(gen)=0。
假設所有泛化候選都根據ILPG值進行分類,則本文可以在第一個關鍵泛化之前同時執行所有候選而不影響匿名化的結果。為了確定在相同的循環中可以泛化哪些關鍵泛化,給出下列定義。
定義3 (競賽泛化)假設所有泛化候選根據ILPG值進行分類。第一個關鍵泛化及其之后的持續關鍵泛化都是競賽泛化。這些一起構成了競賽泛化的集合,表示為RGSet。
第一個關鍵泛化可以在相同的循環中明確執行,而RGSet中的其他泛化不能,值得注意的是,執行關鍵泛化可能會影響候選的ILPG值,因此需要強制更新ILPG值。為了確定RGSet中一次循環的可用關鍵泛化,算法2中給出了一個子程序。ACGSet表示合成的可用關鍵泛化集,即ACGSet中的泛化以及第一個關鍵泛化之前的泛化可以在一次循環中執行。在該算法中,使用一個優先序列來保持關于ILPG的泛化分類。
算法2 確認可用泛化
輸入 RGSet,AQISet
輸出 ACGSet
(1)Queue← ,其中,Queue是關于ILPG的優先排隊;
(2)如果 RGSet= ;
(3)Queue←gmin,gmin∈RGSet且 gmin有著最低的 ILPG;
(4)ACGSet←gmin;
(5)如果 Queue≠ ;
(6)g←Queue 且 RGSet←RGSet/{g};
(7)Queue←∪qid∈{qid′|qid′containsgandqid′∈AQISet}{qi|qi=Proji(qid),1≤i≤m}/{g};
(8)AQISet←AQISet/{qid|qid′contains g};
(9)結束如果;
(10)結束如果
在將所有活躍泛化候選進行分類并識別了關鍵泛化之后,可以獲得輸入參數RGSet。根據算法2中其他輸入參數即AQISet,來確定CGSet。因此,確定AQISet是算法2的關鍵。第3.3節給出了如何在映射化簡任務IPLG估算中確定AQISet。一旦確定AQISet,就可以輕松構建可用泛化集 AGSet。
3.3 ILPG估算任務
IPLG估算任務負責算法1第1行中的ILPG初始化以及第9行中的ILPG更新。ILPG初始化所需要的算法和ILPG更新所需算法十分相似。算法3描述了ILPG估算中的map函數,而算法4顯示了reduce函數。在算法3和算法4中,“#”用來確定是否發出一個密鑰來計算信息增益或匿名損失。“$”用來區分一個密鑰是為了計算Ap(spec)還是Ab(spec)。
算法3 ILPG估算中的map
輸入 數據記錄(IDr,r),r∈D;匿名級,NGSet
輸出 中間鍵值對(key,count)
(1)對于 r中的每個屬性值 vi,找出其在當下 AL中的泛化 geni。pi為 geni中的中親,且 ci是 vi本身或者 pi′的子集也是 vi′的前身;
(2)如果 geni∈NGSet,那么發出(<pi,ci,sv>,count);
(3)構 建 準 標 識 符 qid=<q1,q2,…,qm> ,其 中 ,
(4)對于每個 i∈[1,m],用 qi在 qid中的中親 pi取代qi,如果 qi=ci,產生結果準標識符 qid*發出 (<qid*,pi,#>,count)
算法3的細節:對于ILPG初始化,NGSet是關于AL0的所有初始泛化集合,對于ILPG更新,根據算法1的第6行設置。算法3的第6行根據當前的匿名級,將一個原始記錄轉換為其匿名形式。為了計算式(2)中信息損失估算|Rd|、|(Rd,sv)|、|Rb|和|(Rb,sv)|,第 2 行向 reduce 函數發射鍵值對進行信息損失計算,在執行其他泛化或插入一個新的泛化時,泛化的信息損失將不會受到影響,而隱私增益則由于數據集匿名化的改變而受到影響。
算法3的第3行的目的在于在執行一個泛化前,找出數據集的匿名,即Ab(gen),第4行在執行一次泛化之后發射鍵值對來獲得該匿名,即Ad(gen)。由于Ab(gen)在整體中是唯一的,本文只是反射了當下的準標識符qid進行統計。至于Ad(gen),將發射qid的潛在匿名準標識符來計算不同活躍泛化候選的Ad(gen)。在獲得了Ad(gen)和Ab(gen)后,可以根據式(3)更新每個泛化的隱私增益。
算法4 ILPG估算中的reduce
輸入 中間鍵值對(key,list(count))
輸出 信息增益 (gen,IL(gen))和匿名(gen,Ab(gen),AQISet),泛化的(gen,Ad(gen))
(1)對于每個 key,sum←∑count;
(2)對于每個 key,if key.sv≠#,更新統計計算;
(3)|(Rb,sv)|←sum,|Rb|←sum+|Rb|,|(Rd,sv)|←sum+|(Rd,sv)|,|Rd|←sum+|Rd|;
(4)如果子集c中的所有敏感值都到達,那么計算I(Rd);
(5)如果親本p中的所有子集c都到達,那么計算I(Rd)和 IL(gen),發射(gen,IL(gen));
(6)對于每個 key,if key.sv≠#,更新匿名:
(7)如果 key.c=$,且 sum<Ad(gen)那么更新當下匿名:Ad(gen)←sum;
(8)如果 key.c≠$;
(9)如果 sum<Ab(gen),更新 gen 的潛在匿名:Ab(gen)←sum 和 AQISet←key.c;
(10)如果 sum=Ab(gen),那么更新:AQISet←{key.c}∪AQISet;
(11)發射(gen,Ad(gen))且發射(gen,Ab(gen),AQISet)
算法4中描述的reduce函數主要聚合估算信息損失和隱私增益的統計信息。由于鍵值對在傳輸給reducer workers之前通過映射化簡內置機制進行分類,該reduce函數可以依次計算泛化的信息損失而不需要大量記憶來保存統計信息。因此,reduce函數在計算信息損失上具有很強的伸縮性。
計算數據集匿名的本質特征是找出QI-組的最小值。第二部分,第6行和第11行,目的在于計算隱私增益以及確定AQISet。在并行執行泛化的前后,reducer workers會找出局部最小QI-組大小。通過比較reducer workers的輸出可以獲得驅動程序的整體大小。在處理和構建AQISet中會記錄具有最小組大小的QI-組的準標識符。值得注意的是,AQISet在確定下一個循環的可用泛化中起到十分重要的作用。綜上所述,ILPG估算reduce函數在信息損失和隱私增益計算中都具有較高的伸縮性。在獲得信息損失和隱私增益后就可以根據式(1)計算ILPG的值。
3.4 結合TDS和BUG
本文將自下而上泛化的映射化簡(MRBUG)和自上而下特化的映射化簡(MRTDS)[12]結合在一起,在使用者指定匿名參數k后確定使用哪個組成來匿名化數據。混合方法可以自動給出系統參數k,如果k≥K,那么選擇MRTDS,否則選擇MRBUG。
一旦確定了工作負載平衡點K,混合方法就可以確定選擇哪個組成。如果k>K,那么選擇MRTDS,這是因為MRBUG會引發更多計算;而如果k<K,則選擇MRBUG。算法5簡略描述如下:
算法5 混合算法
輸入 數據集D,k-匿名參數
輸出 匿名數據集
(1)如果 k≥K,那么用 MRTDS匿名化 D;
(2)否則,用MRBUG匿名化 D
找出K的精確值較為困難,這是由于K主要依賴于數據集的一些性能,如數據分配和偏態。然而并不需要獲得精確值,這是因為當k在K附近取值時,MRTDS和MRBUG的性能區別很小。
4 實驗評估
4.1 實驗設置
為了評估提出方法的效率,將其與參考文獻[12]中的MRTDS和MRBUG進行比較,本文方法用Hyb表示,取混合英文單詞Hybrid的前3個字母,3種方法的執行時間分別表示為 THyb、TTDS和 TBUG。當 k>K 時,THyb和 TTDS相似;而當k<K時,THyb和TBUG相似,估計K會引發額外開支,但是這與映射化簡任務中進行的計算相比非常微小。
實驗在U-Cloud的云環境下進行,U-Cloud是一種經常測試使用的云計算環境。圖1顯示了U-Cloud的系統概述,在硬件和Linux操作系統(Ubuntu)上安裝了可以虛擬化的基礎設施,并提供可以統一計算和存儲資源的KVM虛擬化軟件[16,17]。為了創建虛擬化數據中心,安裝了負責虛擬化管理、資源調度、任務分配和與用戶的交互的OpenStack開源云環境。
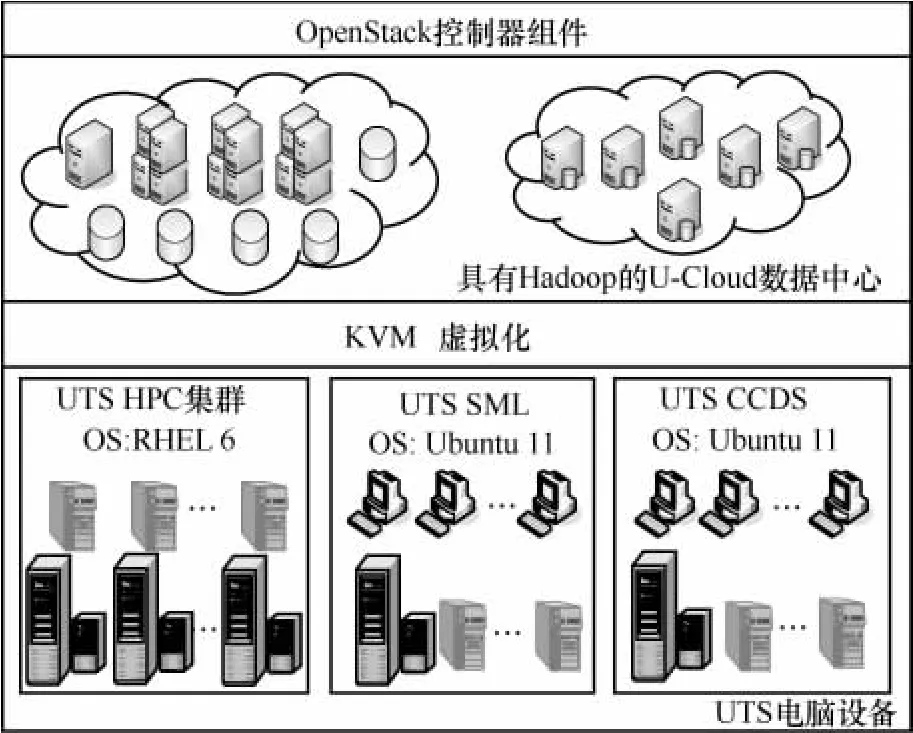
圖1 U-Cloud的系統概述
所有方法都在Java和標準Hadoop MapReduce API中實現。Hadoop集群包含20個具有2個虛擬CPU和4 GB內存的m1型媒介。每一輪實驗重復20次,計算20次的均值作為測量結果。
4.2 實驗結果與分析
本文測量了隨著匿名參數k改變的執行時間THyb、TTDS和TBUG,數據集的大小設置為1 000 MB。該數據集包含1.1×107個數據記錄,參數 α 為 0.5。
圖 2 所示為 THyb、TTDS和 TBUG隨著 k 在 0~1.1×107之間變化而發生的變化。為了表示簡潔,k用exp表示,即k=1.1×10exp,所有exp的取值范圍為 0~7。從圖 2可以看出,混合算法的執行時間保持在一定水平之下,而MRTDS和MRBUG在k較小和較大時引發了較高的執行時間。此外,THyb曲線的左邊部分十分靠近TBUG,而右邊部分十分靠近TTDS,這是由于混合算法利用MRTDS和MRBUG作為具體計算的組件。因此,實驗結果表明,本文的混合算法相較于現有方法,能夠在不考慮k-匿名參數的情況下較大地提高了子樹匿名化的性能。

圖2 執行時間隨著匿名參數k的改變
5 結束語
本文研究了云上大數據子樹匿名化的伸縮性問題,并提出了一種結合了自上向下的特化(TDS)和自下而上的泛化(BUG)的混合方法。該混合方法通過比較用戶指定的k-匿名參數和負載平衡點自動選擇兩個組件中的一個。通過一系列特意設計的MapReduce任務,實驗結果表明,與現有方法相比,本文方法極大地提高了子樹數據匿名化的伸縮性和效率。
在云環境中,由于數據集體積越來越大,數據分析、分享和挖掘中的隱私保護是一項具有挑戰性的研究課題,本文未來計劃進一步探討伸縮性的隱私保護感知分析和大規模數據集的調集。
參考文獻:
[1]戚建國.基于云計算的大數據安全隱私保護的研究 [D].北京:北京郵電大學,2015.QI J G.Research on security privacy protection of large data based on cloud computing[D].Beijing:Beijing University of Posts and Telecommunications,2015.
[2]康瑛石,鄭子軍.大數據整合機制與信息共享服務實現[J].電信科學,2014,30(12):97-102.KANG Y S,ZHENG Z J.Big data integration mechanism and information sharing service realization[J].Telecommunications Science,2014,30(12):97-102.
[3]徐勇,秦小麟,楊一濤,等.一種考慮屬性權重的隱私保護數據發布方法[J].計算機研究與發展,2012,49(5):913-924.XU Y,QIN X L,YANG Y T,et al.A QI weighted-aware approach to privacy preserving publishing data set[J].Journal ofComputerResearch and Development,2012,49(5):913-924.
[4]MACHANAVAJJHALA A,GEHRKEJ,KIFER D,etal.L-diversity:privacy beyond k-anonymity[J].ACM Transactions on Knowledge Discovery from Data,2007,1(1):24-32.
[5]李明慶.一種基于抽樣確定泛化區間的K-匿名算法 [D].哈爾濱:哈爾濱工程大學,2013.LI M Q.A K-anonymity algorithm based on sampling to determine the generalized interval [D].Harbin:Harbin Engineering University,2013.
[6]WANG K,FUNG B C M,YU P S.Handicapping attacker’s confidence:an alternative to k-anonymization[J].Knowledge&Information Systems,2007,11(3):345-368.
[7]TERROVITIS M,MAMOULIS N,LIAGOURIS J,et al.Privacy preservation by disassociation [J].Proceedings of the Vldb Endowment,2012,5(10):944-955.
[8]黃春梅,費耀平,李敏,等.基于多維泛化路徑的 K-匿名算法[J].計算機工程,2009,35(2):154-156.HUANG C M,FEI Y P,LI M,et al.K-anonymity algorithm based on multi-dimensional generalization path [J]. Computer Engineering,2009,35(2):154-156.
[9]FUNG B C M,WANG K,YU P S.Anonymizing classification data for privacy preservation [J].IEEE Transactions on Knowledge&Data Engineering,2007,19(5):711-725.
[10]RAJALAKSHMI V,MALA G S A.Anonymization based on nested clustering for privacy preservation in data mining[J].Indian Journal of Computer Science&Engineering,2013,34(3):856-861.
[11]MOHAMMED N,FUNG B C M,HUNG P C K,et al.Centralized and distributed anonymization for high-dimensional healthcare data[J].ACM Transactions on Knowledge Discovery from Data,2010,4(4):885-900.
[12]ZHANG X,YANG L T,LIU C,et al.A scalable two-phase top-down specialization approach for data anonymization using MapReduce on cloud [J].IEEE Transactions on Parallel&Distributed Systems,2014,25(2):363-373.
[13]呂品,鐘珞,于文兵,等.MA-Datafly:一種支持多屬性泛化的k-匿名方法[J].計算機工程與應用,2013,49(4):138-140.LV P,ZHONG L,YU W B,et al.MA-Datafly:k anonymity approaches forsupporting multi-attribute generalization[J].Computer Engineering and Applications, 2013, 49(4):138-140.
[14]劉盼盼.基于聚類的數據匿名發布技術研究 [D].西安:西安電子科技大學,2013.LIU P P.Research on technology of data anonymous publishing based on clustering[D].Xi’an:Xidian University,2013.
[15]CUI X,ZHU P,YANG X,et al.Optimized big data K-means clustering using map reduce[J].Journal of Super Computing,2014,70(3):1249-1259.
[16]王笑帝,張云勇,劉鏑,等.云計算虛擬化安全技術研究[J].電信科學,2015,31(6):1-5.WANG X D,ZHANG Y Y,LIU D,et al.Research on security of virtualization on cloud computing[J].Telecommunications Science,2015,31(6):1-5.
[17]KVM[EB/OL].(2011-04-10)[2012-02-10].http://www.linux-kvm.org/page/Main_Page.
Hybrid k-anonymity approach based on TDS and BUG under the environment of big data cloud
FAN Xiaofeng1,YAN Feng2,LIU Yang3
1.Inner Mongolia Business&Trade Vocational College,Hohhot 010070,China 2.Vocational and Technical College of Inner Mongolia Agricultural University,Baotou 014109,China 3.Hohhot Vocational College,Hohhot 010050,China
As the issue of low efficiency and poor scalability in general sub-tree anonymous method of treating big data,a bottom-up generalization(BUG)method with scalability was proposed,and on this basis,combined with the existing top-down specialization(TDS),a hybrid approach was formed.In the proposed method,k-anonymity was being as a privacy model,the compositions of TDS and BUG were developed with mapping simplification,and higher scalability through powerful cloud computing capabilities were achieved.The proposed mapping simplification BUG could insert a new candidate after several cycles of generalization,and would not affect information loss of another generalization.Given the complexity of the relationship between workload balancing point K and anonymous parameter k,mapping simplifications of BUG and TDS were combined to form a hybrid approach.Experimental results demonstrate the effectiveness of the proposed method and compared with TDS and BUG,the efficiency and scalability of hybrid method are greatly improved.
cloud computing,sub-tree anonymous,big data,generalization,specialization,mapping simplification
TP391
A
10.11959/j.issn.1000-0801.2016135
2016-03-03;
2016-04-23

范 曉 峰 (1982-),女 ,內 蒙 古 商 貿 職 業 學 院講師,主要研究方向為大數據、云計算。

閆鳳(1982-),女,內蒙古農業大學職業技術學院講師,主要研究方向為大數據。

劉洋(1975-),女,呼和浩特職業學院講師,主要研究方向為大數據。
猜你喜歡
兒童故事畫報(2019年5期)2019-05-26 14:26:14
中華手工(2017年2期)2017-06-06 23:00:31
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
中外會展(2014年4期)2014-11-27 07:46:46
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
祝您健康(1987年2期)1987-12-30 09:52:28
