基于SolrCloud的分布式相似性檢測系統
2016-12-16 08:48:00蔣佳洲北京師范大學株洲附屬學校株洲412000
海峽科技與產業 2016年10期
蔣佳洲 北京師范大學株洲附屬學校 株洲 412000
基于SolrCloud的分布式相似性檢測系統
蔣佳洲 北京師范大學株洲附屬學校株洲412000
文檔相似性檢測中,很多文本的資源是碎片化存儲,實現全局的文本查重,在沒有統一管理的情況下,不可能短時間將數據集中,數據仍舊是分散存儲,為實現全局的檢查,采用基于SolrCloud的分布式查重。論文在b位Minwise Hash的基礎上,提出了彈性細粒度相似性檢測方法;通過分析多粒度特征提取的特點,設置項目模板進行正則表達式匹配,提升了相似性檢索的效率,最后通過系統實現驗證該系統的有效性。
SolrCloud;相似性檢測;哈希;分布式
0 引言
隨著信息時代的發展,數字文檔(如基金項目申報文檔,論文文檔,網頁等)呈幾何級數增長的同時,由于其本身的易復制性,導致項目重復申請,論文抄襲,網頁重復等不良現象頻頻出現;大量相似文檔的存在和數據孤島數量不斷的增加,也降低了信息檢索的效率和精度。在這種情況下,研究高性能的分布式相似性檢測系統顯得尤為重要。
Minwise Hash[1]算法作為目前主流的海量集合相似度估計算法,經過不斷改進[2],在信息檢索中得到廣泛應用[3]。Li等人[4]提出的b位Minwise Hash在Minwise Hash算法的基礎之上通過降低存儲空間和計算時間進一步提高了算法的效率。同時,b位Minwise Hash也是對集合估計算法的一種理論創新,在三者相似性檢測[5]、大型線性支持向量機[6]以及基于最大似然估計的估計算法[7]等領域有了新的應用發展[8]。論文在b位Minwise Hash的基礎上,提出了一種細粒度文檔相似性快速檢測方法,并將其應用到分布式相似性檢測系統中,介紹它的系統框架、系統關鍵技術難點和解決方案以及軟件實際使用效果。
1 系統的架構
1.1基于SolrCloud的分布式系統
(1)SolrCloud是基于Solr和 ZooKeeper的分布式搜索方案。該方案具有集中配置、自動容錯、近實時搜索、負載均衡等特點。系統為滿足全局相似性檢查,基于SolrCloud提出一種分布式文檔相似檢測方案,較好解決跨數據源相似性檢測問題。這種分布式查重方式核心算法應用了b位Minwise Hash,兼顧檢測的精度和效率,結合彈性細粒度,對各類數據進行加工處理,準確匹配各章節,將文檔最小原子鎖定到句子級,形成海量句子指紋庫;每個數據站點間的傳輸通道和統一的傳輸接口規范。
把所有的索引集合視為一個總索引庫,將總索引庫分為三個索引片,分別存放在三個站點,即為主索引庫,并且,考慮到平臺的健壯性,為每個索引片增設了一個備份,即為從索引庫。各個索引庫之間的聯系通過ZooKeeper提供的服務協調。
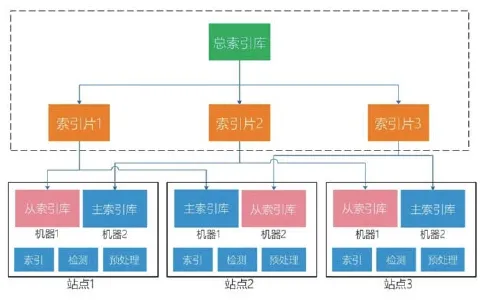
圖1 基于SolrCloud,ZooKeeper的檢測系統架構圖
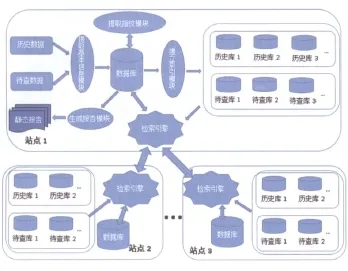
圖2 跨部門檢測模式
(2)聯盟式檢測的模式。如圖2所示,站點1是查重系統站點,主要進行預處理數據,計算相似度。站點2和站點3主要是作為跨部門的數據采集點,在站點1需要的時候傳輸歷史數據至站點1,站點將獲得自身數據庫以外的待對比歷史庫,以期獲得更準確的查重結果。
(3)數據的檢測流程。如圖3所示,包含以下兩個流程。
1)本地檢測:將待查庫的文本發給本地引擎,對文本中每個段落進行計算相似性,檢索出相似的段落。
2)遠程檢測:系統中站點表保存了所有站點的IP地址及端口。索引庫表保存了能夠訪問到的遠程所有索引庫的信息。
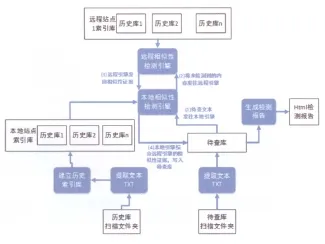
圖3 檢測流程
在兩種檢測的基礎上實現跨站點檢測步驟:以與遠程站點1的歷史庫1比對為例。
第一步:用戶選擇遠程站點,系統訪問站點表,獲取遠程站點1的IP。然后向遠程站點1發送請求獲取站點1可供查的索引庫列表。
第二步:用戶選擇歷史庫1,系統在任務表中新建檢測任務。
第三步:本地檢測引擎掃描數據庫,獲取檢測任務信息,檢測完后,沒有找到的句子,再將句子的指紋加密發送到遠程站點1,遠程站點1的引擎接收后檢測。
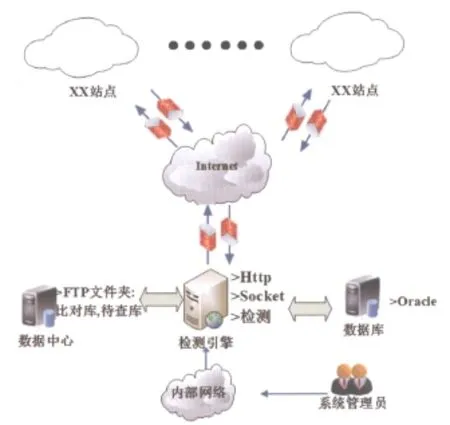
圖4 系統網絡拓撲結構圖
第四步:遠程站點1查完將檢測結果發回本地站點,本地結合遠程站點1的相似性證據一起寫回待查表。
1.2系統的網絡拓撲結構
由于相似性檢測系統通常都是單位內部人員使用,因此系統一般部署在內部局域網環境中。當然,對于大眾用戶的相似性檢測需求,系統也可以對Internet開放。
本文構建系統部署的網絡拓撲結構如圖4所示。
2 系統的關鍵技術
2.1確定檢測粒度
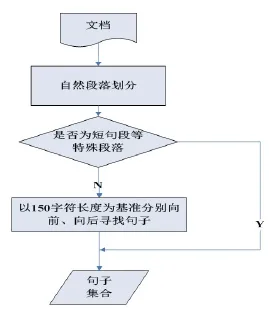
圖5 確定檢測粒度流程圖
細粒度文檔相似性檢測,通常是將文檔切割為多個自定義長度的文本塊集合,通過相關檢索,計算并獲取每個文本塊與文本集合中的文本的相似程度。如果文本塊的長度選擇過大,則計算準確度不高,容易遺漏多方抄襲部分內容的情況。同時,如果文本塊長度選擇太小,也會造成時間和空間的開銷過大。
在文檔切割的過程中,通常會首先按照自然段對文檔進行初步的劃分,這是由于自然段可以表達作者相對完整的思想,同時也提供了對文檔結構的換行。而另一方面,大部分抄襲者也都是選擇以段落為單位進行抄襲的。然而,文檔中通常也會存在一些很長的自然段。例如,在論文中又包括了引言、研究方法和內容、實驗結果、討論和結論等,每項內容又包括了段、句子、文本塊、詞等,這些特征都是多層次的。大量過長自然段和多層次特征的存在使得單單基于自然段落的劃分是行不通的。
如圖5所示,通過將自然段落切分為150字符左右的“句子”作為檢測單元粒度。同時對于特殊的獨句段,短句段等段落,這類段落通常具有很強的同義性,使用頻度很高,并且通常在文章中是起起承轉合的作用而與文檔的核心內容無關。因此,對于這類段落不進行相似性的檢測。
2.2細粒度指紋索引的建立
實際上文檔相似性檢測就是文檔間“句子”指紋的海明距離的范圍檢索。令細粒度的檢測單位“句子”的指紋為100位的海明碼指紋(fs,1-fs,100),將k=100位指紋進行分組,分為m=5組(20,20,20,20,20,20)[11]。如(1)所示,則一個具有s個長句的文檔D可以表示為:

文檔數為n的文檔集M表示為:

其中fn,s,k為第n個文檔的第s個句子對應的第k位海明碼。若每個分組命名為{A,B,C,D,E},則定義向量VA,VB,VC,VD,VE。
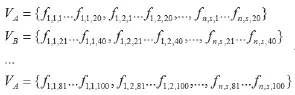
分別對向量VA,VB,VC,VD,VE建立m=5個B+樹索引。
在實際的系統應用中,可以利用數據庫管理技術在指定的表中建立m=5個字段,并對這5個字段分別建立INDEX索引。論文采用了lucene4.9的版本來建立索引,Lucene作為一種全文檢索引擎架構,具有優秀的檢索效率,增量插入和刪除等操作非常方便。
2.3細粒度相似性比對

步驟2:分別在m=5個B+樹上執行查詢條件(3),執行查詢條件后的集合定義為Set(Pre_Query)。
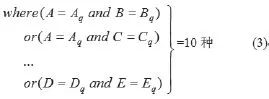
步驟3:對Set(Pre_Quer y)中的所有元素進行Disthamm距離計算,將所有滿足條件:Disthamm<rhamm的加入集合Set(Query)中。其中上述rhamm為海明距離的閾值。
2.4系統相似性實施效果
為測試聯盟式相似性檢測的實際效果,論文在普通PC機上搭建起分布式處理平臺,其中一臺主機和三臺機器子節點。本章采用的實驗數據來至知網的的1萬論文文檔對,將數據分為數據集1,數據集2和數據集3,每個數據集大小不同,每個數據集都有一定的重復率。通過三個不同的數據集的實驗,可以有效的評估出聯盟式檢測的性能。數據集詳情如表1所示。數據集1,數據集2和數據集3的實驗結果分別如表2,3所示。
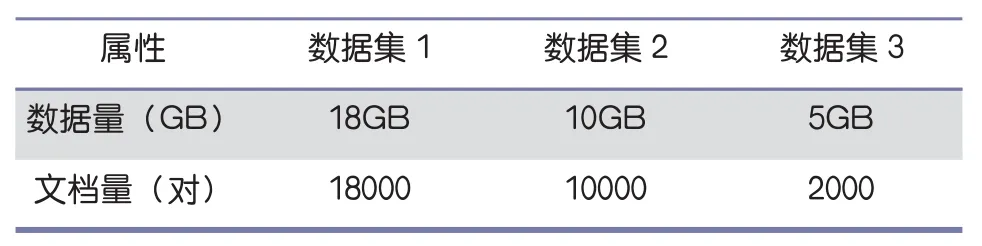
表1 數據集詳情
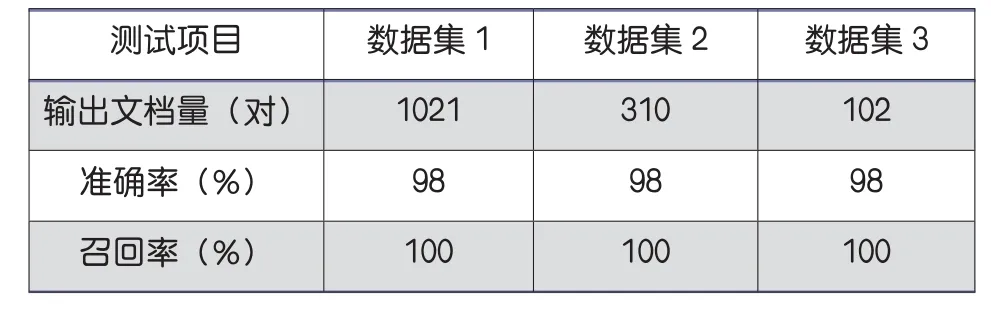
表2 閾值R0=0.3時,單個數據集相似性檢測效果

表3 閾值R0=0.3時,3個數據集聯盟相似性檢測效果
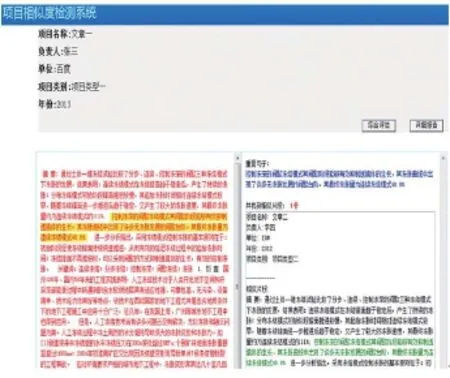
圖6 (a) 一對多相似性證據顯示

圖6 (b) 一對一相似性證據顯示
三個數據集存在重復數據,要對數據進行相似性檢測,首先要讀取將要存儲的文件數據,然后將文件數據進行處理,求出文件的特征指紋,將指紋與索引表進行匹配,最后計算出文檔的相似度。如表2,3所示,聯盟式相似性檢測的結果表明,三個數據集獨立的相似性檢測輸出文檔對共為1333,三個數據集聯盟相似性檢測輸出文檔對2100,多輸出了767份文檔對,證明了跨數據源抄襲現象的存在。因此,在以后的查重工作中,根據實際情況有必要進行跨數據源檢測,提升項目查重的整體效果。
如圖6所示,系統給出的相似性證據界面,其中包括一對一直觀比對顯示以及一對多的細粒度抄襲證據顯示。
3 結語
分組指紋的彈性細粒度檢測主要解決了文檔內容的分區查重問題,讓結果更加智能和準確;聯盟式相似性檢測主要解決了不同數據源聯合查重的問題,使得異源抄襲也無所遁形。本論文的工作對分布式相似性檢測系統的推廣起到了一定作用。
[1] Broder A Z, Charikar M, Frieze A M, et al. Min-wise independent permutations [J]. Journal of Computer Systems and Sciences, 2000, 60(3): 630-659
[2] Feigenblat G,Porat E,Shiftan A.Exponential time improvement for min-wise based algorithms.SODA '11 Proceedings of the Twenty-Second Annual ACM-SIAM Symposium on Discrete Algorithms,SIAM,2011.57-66
[3] Kane DM,Nelson J,Woodruff DP.An optimal algorithm for the distinct elements problem.PODS '10 Proceedings of the twenty-ninth ACM SIGMOD-SIGACT-SIGART symposium on Principles of database systems.NY, USA:ACM,2010.41-52
[4] Li P,K?nig AC.B-bit minwise hashing[A]. In Proceedings of the 19th international conference on World Wide Web, pages 671-680. ACM, 2010.
[5] Li P,K?nig AC,Gui W.B-bit minwise hashing for estimating three-way similarities.Neural Information Processing Systems (NIPS) BC, Canada:Vancouver.2010
[6] Li P,Moore J,K?nig AC.B-bit minwise hashing for large-scale linear SVM.Neural Information Processing Systems (NIPS) BC,Canada:Vancouver.2011
[7] Li P,K?nig AC.Accurate Estimators for improving Minwise Hashing and b-bit Minwise Hashing.Technical Report,New York:Cornell university library,2011
[8] Li P, K?nig AC.Theory and applications of b-bit minwise hashing [J]. Communications of the ACM, 2011, 54(8): 101-109
[9] T.Bray,J.Pao Li,CM.Sperberg-McQueen.Extensible markup language(XML) 1.0 W3C recommendation.Technical report,W3C,1998.
[10] E Hatcher.,O Gospodnetic,M McCandless.softsearch2.googlecode.com. 2004
[11] 袁鑫攀,龍軍,張祖平,桂衛華.Near-duplicate document detection with improved similarity measurement [J].Journal of Central South University of Technology 中南大學學報(英文版),2012,19(8):2231?2237
TP301.6
A
10.3969/j.issn.1000-386x.2013.01.001
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
北京測繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(2019年12期)2019-12-25 03:06:46
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
