用電信息采集系統的數據庫服務器運行指標監測與性能分析
2016-12-16 06:40:17王立斌王洪瑩
河北電力技術 2016年5期
趙 佩,王立斌,李 翀,王洪瑩,張 超
(國網河北省電力公司電力科學研究院, 石家莊 050021)
?
用電信息采集系統的數據庫服務器運行指標監測與性能分析
趙 佩,王立斌,李 翀,王洪瑩,張 超
(國網河北省電力公司電力科學研究院, 石家莊 050021)
為提升運維效率,保證穩定運行,通過對用電信息采集系統主站服務器日志和數據庫負荷報告的日常分析經驗總結,提出系統運行指標監測和性能分析方法,以期為支撐海量數據挖掘與深化應用,提升采集系統運行與管理效率等方面奠定堅實基礎。
智能電網;采集系統;運行指標監測;性能分析
1 概述
用戶用電信息采集系統(簡稱“采集系統”)以智能電能表和通信網絡為基礎支撐[1],覆蓋購供售三側關口,對各項電氣量數據進行實時精確采集,為電網運營管理提供了準確的海量數據支撐,是智能電網的核心組成部分。
隨著智能電網的發展,智能電能表快速接入,系統主站承擔了越來越多的工單調試、接入和采集任務,以及數據統計、推送和發布壓力,所以,采集系統的穩定運行對智能電網建設、電網運營管理、各項電氣量數據實時精確采集至關重要[2]。
以下通過對服務器日志和數據庫負荷報告的日常分析經驗總結,根據采集系統主站實際配置情況,提出系統運行指標監測和性能分析方法,并介紹了常用的運維工具,運維人員可進行參考,從而全面提高運維效率、分析防范系統異常、準確定位故障源頭、及時協調實施消缺、總結系統運維經驗、保障安全穩定運行。
2 采集系統主站配置參數
采集系統主站在運服務器配置如表1所示。
從上述配置可以看出生產數據庫服務器配置較低,而生產數據庫服務器承擔著采集各項電氣數據的報文入庫、電量/線損/成功率的統計計算、數據推送查詢庫和其他系統,以及與其他系統間的接口交互推送,是采集系統主站中重要的組成部分,所以生產數據庫服務器的運行指標需要重點監測分析。
3 運行指標監測
由于系統主站的生產數據庫服務器運行情況是監測重點,所以運行指標監測工作需要分為服務器指標監測和數據庫指標監測兩部分,2種指標分別體現服務器宏觀性能和數據庫軟件運行情況,而且2種指標之間各有側重,存在著一定關聯。
表1 采集系統主站部分服務器配置

服務器類型配置數量運行情況生產數據庫IBMP570小型機,32核處理器,128GB內存,AIX5.3操作系統,Oracle10g數據庫2設備運行已有6年,近期負荷居高不下甚至出現數據庫實例重啟現象查詢數據庫SUNT5-8小型機,1024核處理器,2TB內存,Solaris10操作系統,Oracle11g數據庫2設備性能高,運行壓力小,故障率極低前置集群16臺刀片服務器和10臺曙光I840PC機26運算處理效率高,單點故障影響小,可靠性高應用集群4臺浪潮TS860高性能PC機4運算處理效率高,單點故障影響小,可靠性高關口系統6臺刀片服務器和6臺DELLR910PC機12運算處理效率高,單點故障影響小,可靠性高測試系統6臺DELLR710PC機6運算處理效率高,單點故障影響小,可靠性高…………………
3.1 運行指標監測內容
3.1.1 服務器運行指標
服務器運行指標中需要關注CPU和內存使用情況。由于每天的CPU負載率和內存使用率會有波動,所以服務器的運行指標監測內容包括:CPU負載率:包括兩節點每日的CPU平均負載率和最高負載率,并根據CPU運算類別分為User%(用戶使用率)、Sys%(系統使用率)、Wait%(等待事件占用率)、Idle%(空閑CPU負載率)、CPU%(CPU總使用率)5個維度,其中CPU%=User%+Sys%。內存占用率:包括兩節點每日內存占用率的平均值、最大值和最小值,并根據內存使用類別分為Realfree%(真實內存剩余百分比)、Virtualfree%(虛擬內存剩余百分比)、Comp%(計算內存占比)、Realuse%(物理內存使用率)、Virtualuse%(虛擬內存使用率),其中Realuse%=100%-Realfree%、Virtualuse%=100%-Virtualfree%。3.1.2 數據庫運行指標
數據庫運行指標中需要關注每個實例硬解析、CR值和AAS值。
a. 硬解析:如果一條待執行的SQL語句沒有在Oracle的共享池中,那么它將被重新解析,大量的硬解析會產生解析爭用,造成CPU資源消耗。
b. CR(Consistent Read)值:用來表征數據庫兩實例間同步差異的指標,與網絡、節點間的數據交互有關。
c. AAS(Average Active Session)值:DB time與Elapsed Time的比值,用來體現數據庫的負載程度,如果負載較高或者等待事件較多,AAS值就會變大。
3.2 運行指標監測方法
為做好采集系統支撐,保證系統穩定運行,主站運維管理部門需安排專人與系統實施廠家開發部DBA和現場運維工程師組成系統運行指標監測與消缺工作組,通過每天查看系統生產庫服務器NMON負荷曲線和數據庫AWR報告,持續監測采集系統服務器各項運行性能指標和異常情況,及時發現、處理系統異常,對消耗系統資源的SQL語句進行修改完善,實時跟蹤優化進度,并統計優化效果、積累運維經驗。
系統正常情況下,運行指標的監測頻率為每天查看并記錄,對于日常導出的負荷曲線和根據各項運行指標數據繪制生成的圖表都保存留檔。另外,定期編寫階段性分析報告,根據重大操作前后的指標情況階段性分析,得出系統性能改善情況,總結運維經驗。各項運行指標的具體監測方法如下。
3.2.1 服務器運行指標監測方法
3.2.1.1 NMON概述
NMON是一種在AIX與各種Linux操作系統上廣泛使用的監控與分析工具。NMON所記錄的信息比較全面,它能在系統運行過程中實時地捕捉系統資源的使用情況,并且能輸出結果到文件中。
實際工作中,NMON有3種常用的使用模式,分別是實時監控、后臺監控和定期監控模式。通過后臺監控和定期監控,可以得到擴展名為NMON的監控文件,這些文件記錄著系統資源的數據,需要配合分析工具進行解讀。NMON analyser.xls可以將NMON文件轉化為Excel文件,并生成統計圖,直觀顯示系統資源情況。在NMON結果中打開相應標簽頁結合系統實際設置,可以進一步確定造成問題的原因。NMON能夠提供CPU、內存、硬盤、網絡等各方面的信息,對于運行指標的監控和分析工作能夠提供很好的數據支持。
3.2.1.2 使用NMON文件監測方法
在使用NMON文件監測服務器運行指標的具體操作方法如下。
a. 使用遠程命令行工具(如SSH Secure shell Client等),以root用戶登陸數據庫服務器兩節點,找到NMON文件存放路徑,將后綴名為.NMON的文件下載。
b. 使用NMON Analyser工具,選擇NMON文件待分析完成后,輸入規范的文件名即可生成包含CPU、內存指標和相應負荷曲線的Excel文件。
c. 針對生成的Excel文件中“SYS_SUMM”、“MEM”工作表中的CPU負荷率和內存使用率數據,以及“CPU_ALL”、“PAGE”中的圖表進行拷貝存檔。
d. 當有停機操作、重啟數據庫等重大操作時,在隨后進行實時監控,并對比操作前后的服務器運行指標變化。
3.2.2 數據庫運行指標監測方法
3.2.2.1 AWR概述
查看AWR(Automatic Workload Repository)是進行日常數據庫性能評定、問題SQL發現的重要手段,熟悉掌握AWR報告,是做好開發、運維DBA工作的重要基本功。
AWR報告的原理是基于Oracle數據庫的定時鏡像功能。默認情況下,Oracle數據庫后臺進程會以一定間隔(1 h)收集系統當前狀態鏡像,并且保存在數據庫中。生成AWR報告時,只需要制定進行分析的時間段(開始鏡像編號和結束鏡像編號),就可以生成該時間段的性能分析情況。
3.2.2.2 使用AWR監測方法
在使用AWR監測數據庫運行指標的具體操作方法如下。
a. 使用遠程命令行工具(如SSH Secure shell Client等)以Oracle用戶登陸數據庫服務器兩節點用戶后,進入SQL命令行。執行 @ORACLE_HOME/rdbms/admin/awrrpt.sql 命令進入AWR報告生成步驟。
b. 輸入報告類型(一般使用html類型),報告天數,開始、結束鏡像快照,輸入規范的AWR報告文件名即可生成AWR報告文件。
c. 進入oracle用戶的目錄下找到生成的AWR報告,下載后可用瀏覽器打開查看AWR報告。
d. 將兩節點AWR報告中的《Load Profile》部分第8條Hard Parse(硬解析值)、《Global Cache and Enqueue Services - Workload Characteristics》部分的第7條Avg global cache cr block flush time(CR值),開頭部分DB Time和Elapsed比值(AAS值)進行記錄,繪制生成曲線圖表。
e. 當有停機、重啟數據庫等重大操作時,在隨后進行實時監控,并對比操作前后的數據庫運行指標變化。
4 性能分析方法
根據目前生產數據庫服務器硬件配置情況和日常業務,制定一種適合采集系統實際情況的分析方法,列舉各個指標的參考區間。運維人員在對數據庫服務器的各項運行指標監測分析過程中,可按照制定的參考區間開展指標評判。
4.1 CPU負載
由于生產數據庫服務器除操作系統軟件造成的基礎負荷(Sys%)外,安裝了Oracle數據庫作為主要軟件使用CPU計算資源,體現在CPU負載中的User%占比。考慮采集系統生產庫工作原理和實際硬件配置情況,分析CPU負載情況的參考值如表2所示。
表2 CPU負載情況分析參考值

CPU指標名稱參考值User10%~70%Sys5%~20%Wait0%~10%Idle10%~85%AVG(CPU%)30%~50%MAX(CPU%)65%~85%相鄰兩日CPU%變化率±20%
4.2 內存占用變化
采集系統生產庫服務器設置maxperm%和maxclient%參數為Oracle數據庫合理分配內存空間[3],同時根據AIX操作系統內存管理機制,頁面淘汰基于LRU算法,內存使用率較高也并非異常,所以分析相鄰兩日內存占用平均值變化情況更有價值,分析內存占用變化情況的參考值如表3所示。
表3 相鄰兩日內存平均值變化情況分析參考值 %

內存指標名稱參考值Real_free±1Virtual_free±2Comp±2Real_use±1Virtual_use±2TOTAL(MEM)±2
4.3 數據庫運行指標
數據庫作為采集系統生產庫服務器的核心軟件,數據庫指標的變動會對服務器運行造成較大影響,相反如果服務器資源緊張,也會對數據庫指標造成很大影響,所以數據庫運行指標也要設定參考區間。經過綜合考慮,分析數據庫運行情況的參考值如表4所示。
表4 數據庫運行指標情況分析參考值
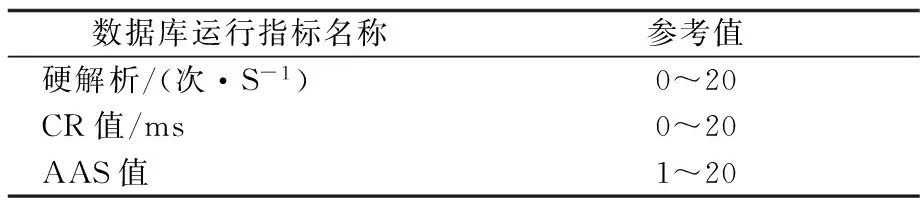
數據庫運行指標名稱參考值硬解析/(次·S-1)0~20CR值/ms0~20AAS值1~20
5 運維工具
為了做好指標監測,提高運維效率,縮短故障響應時間,運維人員應選擇使用方便高效的運維工具同樣重要。推薦使用的運維工具如下:
a. 錄像機OS Watcher。OS Watcher可以記錄在系統中的各類操作,每小時的信息單獨打包成一個gzip壓縮文件。類似AIX系統的NMON日志文件,OSW可以將每個時刻的系統狀態記錄歸檔,可以快速定位故障。該工具可以通過使用startOSW.sh命令啟動,stopOSW.sh命令結束。錄像機OS Watcher默認保留3天的數據,可以手動設置保留天數,如果使用了Oracle RAC,可以通過配置prvnet,記錄網絡心跳的狀態。
b. 監視器oratop。oratop和Unix/Linux里top命令類似,實時展現數據庫的相關信息,使用方便簡單。
c. ora。與oratop不同,ora完全是響應式的,集成了諸多需要執行一長串SQL語句才能實現功能查詢。這個工具為Oracle開發,DBA在使用過程中可以根據自己的需要,增加新的功能點,在問題分析過程中最快速的得知數據庫對象的情況,做出相應的處理抉擇。
d. SQL Developer。前述1-3的運維工具是命令行工具,可以在不方便用圖形界面時使用。SQL Developer該工具是可以在圖形化界面使用的工具。
e. ORAchk。之前被稱為RACcheck,之后擴展了檢查范圍,改名為ORAchk,它是在數據庫系統進行健康檢查的一個專用工具,主要用來檢查軟件的配置是否符合要求以及一些最佳實踐是否被應用。通過這個工具,用戶可以方便地、自動化地對自己的系統進行健康檢查和評估。Oracle還為Exadata用戶提供了exachk工具。
f. RDA(Remote Diagnostic Agent)。oracle用來收集、分析數據庫的工具,該工具的運行不會改變系統的任何參數,RDA收集的相關數據非常全面,可以簡化我們日常監控、分析數據庫的工作,RDA比ORAchk更加復雜和全面,支持的模塊更多。Oracle Support也建議我們在反饋相關問題時,提供RDA收集的數據,這樣可以為快速解決問題提供一個有力的保證。
g. RMAN。RMAN是數據庫工程師維護常用的工具。用RMAN,不僅要定期做備份,每年應至少進行一次恢復驗證,避免備份失效。
h. OEM。OEM企業管理器從8i的單機版到近期的OEM13c CC(Cloud Control),界面和交互變得更加友好,而且不僅Oracle數據庫,其他監控和管理的事務,幾乎都可以在OEM工具中定制。
6 結束語
采集系統運行指標監測和系統性能分析是一項長期開展的工作,涉及到服務器、操作系統、數據庫等方面的各項技術。全面提高運維效率,做好采集系統的運行指標監測和性能分析工作,可對充分發揮采集系統支撐海量數據挖掘與深化應用,穩步提升采集系統運行與管理效率等方面起到積極的促進作用。
[1] 劉 征.電力用戶用電信息采集系統的研究與應用[J].大科技,2013(18):27-28.
[2] 梁 波,楊銘海.用電信息采集系統架構及功能應用(一)[J].農村電工,2013(2):41-43.
[3] 劉長生,孟 松.oracle數據庫參數優化與分析.電腦知識與技術[J].2004(26):8-10.
本文責任編輯:丁 力
Operation Indicators Monitoring and Performance Analysis of Database ServerBased on Power User Electric Energy Data Acquire System
Zhao Pei,Wang Libin,Li Chong,Wang Hongying,Zhang Chao
(State Grid Hebei Electric Power Research institute,Shijiazhuang 050021,China)
In order to promote operation and maintenance efficiency, and guarantee the stability of the system, operation indicators monitoring and performance analysis methods are given in this paper after analyzing and summarizing server logs and database workload repositories of the system master,which establishes a solid foundation to support massive data mining,application deepening,operation and management efficiency promotion of the system and so on.
Smart Grid; acquire system; operation indicators monitor; performance analysis
2016-05-16
趙 佩(1990-),男,助理工程師,主要從事用電信息采集系統建設推進和優化研究工作。
TM76
B
1001-9898(2016)05-0025-04
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
北京測繪(2020年12期)2020-12-29 01:33:58
電子制作(2018年18期)2018-11-14 01:48:24
家庭影院技術(2017年9期)2017-09-26 03:41:45
財經(2017年2期)2017-03-10 14:35:35
山東工業技術(2016年15期)2016-12-01 05:31:22
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
