基于Weka的江蘇13個(gè)地級(jí)市溫度聚類分析
2016-12-17 13:19:49孫濤高軍暉
科技創(chuàng)新導(dǎo)報(bào) 2016年21期
孫濤+高軍暉

摘 要:該文利用機(jī)器學(xué)習(xí)軟件Weka,對(duì)江蘇13個(gè)地級(jí)市的溫度數(shù)據(jù)進(jìn)行聚類分析研究。我們的數(shù)據(jù)來自中國(guó)氣象數(shù)據(jù)網(wǎng),采用1981—2010年日平均氣溫。我們?cè)赪eka中分別用HierarchicalCluster、SimpleKMeans、Cobweb三種方法按3個(gè)簇進(jìn)行聚類。從三種聚類方法得出的結(jié)果來看,第1、2種方法結(jié)果更加相近,第3種方法更加細(xì)致,導(dǎo)致每個(gè)情況各成一類。對(duì)照溫度聚類的結(jié)果和城市之間的空間距離,蘇北城市之間的溫度互相之間更加靠近,蘇中、蘇南城市由于處于長(zhǎng)江兩側(cè),互相之間溫度也更加靠近。
關(guān)鍵詞:聚類分析 Weka 城市溫度
中圖分類號(hào):TP391 文獻(xiàn)標(biāo)識(shí)碼:A 文章編號(hào):1674-098X(2016)07(c)-0092-03
氣溫是重要的氣候指標(biāo),對(duì)人類的生產(chǎn)生活狀況以及農(nóng)業(yè)生產(chǎn)都有著非常重要的影響,并且在自然科學(xué)領(lǐng)域中建立的諸多氣候模型中,氣溫已經(jīng)成為一個(gè)不可或缺的影響因素,因此有關(guān)氣溫空間分布規(guī)律的研究一直都是地理、氣象、生態(tài)等研究和應(yīng)用領(lǐng)域廣泛關(guān)注的熱點(diǎn)問題之一[1]。影響氣溫分布的主要因素包括:宏觀的地理?xiàng)l件,觀測(cè)點(diǎn)的海拔高度、地形(坡向、坡度等)、下墊面性質(zhì)等,其中尤以海拔高度和地形的影響最顯著[2]。
聚類分析是數(shù)據(jù)挖掘的重要研究?jī)?nèi)容[3,4],是計(jì)算機(jī)科學(xué)中較為前沿的研究方式,因?yàn)榈乩怼庀蟮葦?shù)據(jù)有時(shí)間性和空間性并具的特點(diǎn),所以聚類分析方法在地理數(shù)據(jù)研究上從傳統(tǒng)上的空間聚類發(fā)展成帶有時(shí)間性質(zhì)的時(shí)空聚類,其中代表性的聚類分析方法有基于密度的,有基于層次的,還有基于劃分的,比如FCM算法[5,6],在聚類分析與地理結(jié)合研究這方面,國(guó)外學(xué)者如Bilgin T T等對(duì)土耳其的氣象站每日的溫度數(shù)據(jù)進(jìn)行了聚類分析,得到趨勢(shì)相同的溫度區(qū)域,從而根據(jù)土耳其的氣溫特性進(jìn)行氣象區(qū)域劃分[7];Moller-Levet等[8]利用模糊c均值聚類算法對(duì)短時(shí)間序列進(jìn)行了聚類[9]。
1 數(shù)據(jù)來源
該文所有數(shù)據(jù)均來自中國(guó)氣象數(shù)據(jù)網(wǎng)[10],使用的溫度為1981—2010年日平均氣溫,單位:℃。
獲取數(shù)據(jù)時(shí),共有9列數(shù)據(jù),分別是城市、日序、累年日平均氣溫、累年平均日最高氣溫、累年平均日最低氣溫、累年日平均水汽壓、累年20-20時(shí)日降水量、累年08-08時(shí)日降水量、累年日平均風(fēng)速。
該文基于平均氣溫做數(shù)據(jù)分析,時(shí)間是365天,城市為江蘇省13所地級(jí)市。數(shù)據(jù)采集時(shí)的城市排序?yàn)椋簾o錫、蘇州、常州、徐州、連云港、鹽城、淮安、南京、揚(yáng)州、泰州、南通、宿遷、鎮(zhèn)江。
由于部分地級(jí)市數(shù)據(jù)并未給出,所以,該文中的數(shù)據(jù)由地理位置最近的相關(guān)縣級(jí)市或區(qū)的數(shù)據(jù)代替,常州數(shù)據(jù)由金壇代替,宿遷數(shù)據(jù)由宿豫代替,鎮(zhèn)江數(shù)據(jù)由丹陽代替,南通數(shù)據(jù)由于本身產(chǎn)生時(shí)間分段難以處理,由通州代替。
2 聚類分析介紹
我們這里借用MBA智庫百科[11]來描述聚類分析。聚類分析,英文Cluster Analysis,是根據(jù)“物以類聚”的道理,對(duì)樣品或指標(biāo)進(jìn)行分類的一種多元統(tǒng)計(jì)分析方法。它們討論的對(duì)象是大量的樣品,要求能合理地按各自的特性來進(jìn)行合理的分類,沒有任何模式可供參考或依循,即是在沒有先驗(yàn)知識(shí)的情況下進(jìn)行的。聚類分析起源于分類學(xué),在古老的分類學(xué)中,人們主要依靠經(jīng)驗(yàn)和專業(yè)知識(shí)來實(shí)現(xiàn)分類,很少利用數(shù)學(xué)工具進(jìn)行定量的分類。隨著人類科學(xué)技術(shù)的發(fā)展,對(duì)分類的要求越來越高,以致有時(shí)僅憑經(jīng)驗(yàn)和專業(yè)知識(shí)難以確切地進(jìn)行分類,于是人們逐漸地把數(shù)學(xué)工具引用到了分類學(xué)中,形成了數(shù)值分類學(xué),之后又將多元分析的技術(shù)引入到數(shù)值分類學(xué)形成了聚類分析。
聚類是將數(shù)據(jù)分類到不同的類或者簇的一個(gè)過程,所以同一個(gè)簇中的對(duì)象有很大的相似性,而不同簇間的對(duì)象有很大的相異性。聚類分析的目標(biāo)就是在相似的基礎(chǔ)上收集數(shù)據(jù)來分類。聚類源于很多領(lǐng)域,包括數(shù)學(xué)、計(jì)算機(jī)科學(xué)、統(tǒng)計(jì)學(xué)、生物學(xué)和經(jīng)濟(jì)學(xué)。在不同的應(yīng)用領(lǐng)域,很多聚類技術(shù)都得到了發(fā)展,這些技術(shù)方法被用作描述數(shù)據(jù),衡量不同數(shù)據(jù)源間的相似性,以及把數(shù)據(jù)源分類到不同的簇中。
聚類分析計(jì)算方法主要有如下幾種:分裂法(partitioning methods),層次法(hierarchical methods),基于密度的方法(density-based methods),基于網(wǎng)格的方法(grid-basedmethods),基于模型的方法(model-based methods)。
3 數(shù)據(jù)分析方法
Weka[12]的全名是懷卡托智能分析環(huán)境(Waikato Environment for Knowledge Analysis),是一款免費(fèi)的、非商業(yè)化的、基于JAVA環(huán)境下開源的機(jī)器學(xué)習(xí)以及數(shù)據(jù)挖掘軟件。Weka作為一個(gè)公開的數(shù)據(jù)挖掘工作平臺(tái),集合了大量能承擔(dān)數(shù)據(jù)挖掘任務(wù)的機(jī)器學(xué)習(xí)算法,包括對(duì)數(shù)據(jù)進(jìn)行預(yù)處理,分類,回歸、聚類、關(guān)聯(lián)規(guī)則以及在新的交互式界面上的可視化。選擇HierarchicalCluster聚類方法,操作流程如下[13]:
加載天氣-江蘇.csvs數(shù)據(jù)集,切換到Cluster選項(xiàng)卡,單擊Choose按鈕,在打開的算法選擇對(duì)話框中,選擇HierarchicalCluster聚類算法。
設(shè)置相似度度量方法。單擊Choose按鈕后面的算法文本框,在設(shè)置算法屬性對(duì)話框中,設(shè)置距離函數(shù)distanceFu nction為歐氏距離EuclideanDistance,設(shè)置num集群nu mClusters為3。
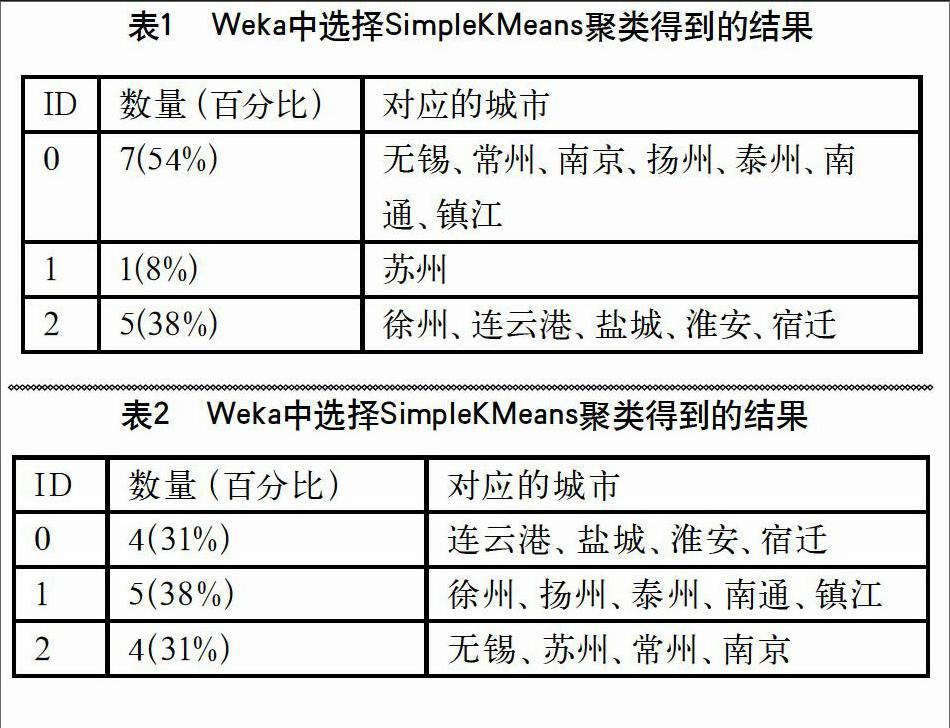
在Cluster mode面板中選擇Use training set選項(xiàng),單擊Start按鈕執(zhí)行挖掘,結(jié)果如表1所示。
在Result-list(right-click for options)列表中選擇本次訓(xùn)練條目,右擊,從彈出的快捷菜單中選擇Visualize tree命令,打開分層聚類樹,如圖1所示。
從空間角度看,蘇北城市之間的溫度互相之間更加靠近,蘇中、蘇南城市由于處于長(zhǎng)江兩側(cè),互相之間溫度也更加靠近,靠近太湖的幾個(gè)城市中,只有蘇州市一個(gè)離群值,推測(cè)有由于蘇州的地理位置在長(zhǎng)江和太湖之間,以及蘇州市內(nèi)湖泊較多使得溫度產(chǎn)生了偏離。
4 討論
考慮到不同的聚類方法結(jié)果可能不一樣,我們有必要選擇其他的方法進(jìn)行聚類。
使用Weka中的SimpleKMeans聚類方法。與第1 種方法相比,加入了隨機(jī)種子,數(shù)量為3。其他參數(shù)如下: displayDevs:False,distanceFunction:EuclideanDist ance -Rfirst-last,dontReplaceMissingValues: False,maxTterations:500,numClusters:3,preserveInstancesOrder:False。得到的聚類結(jié)果如表2所示。
使用Cobweb聚類方法。與第1種方法相比,加入了隨機(jī)
種子,數(shù)量為3。其他參數(shù)如下:acuity:1.0,cuteoff:0.002
8209479177387815,saveInstanceData:False。結(jié)果與前面兩種方法有很大的差別。除了無錫、泰州、南通、鎮(zhèn)江4個(gè)城市在一個(gè)簇里面,其他9個(gè)城市分別形成一個(gè)簇。圖2是對(duì)應(yīng)的聚類樹。
從三種聚類方法得出的結(jié)論看,第1、2種方法結(jié)果更加相近,第3種方法更加細(xì)致,導(dǎo)致每個(gè)情況各成一類。
5 結(jié)語
該文利用機(jī)器學(xué)習(xí)軟件Weka,對(duì)江蘇13個(gè)地級(jí)市的溫度數(shù)據(jù)進(jìn)行聚類分析研究。
首先回顧了其他學(xué)者對(duì)氣候數(shù)據(jù)進(jìn)行聚類分析的工作,接著,我們分別描述了數(shù)據(jù)來源和聚類分析的原理。在數(shù)據(jù)分析部分,我們用HierarchicalCluster進(jìn)行聚類分析,指定3個(gè)簇。得到的結(jié)果是無錫、常州、南京、揚(yáng)州、泰州、南通、鎮(zhèn)江7個(gè)城市在一個(gè)簇里面,徐州、連云港、鹽城、淮安、宿遷5個(gè)城市在一個(gè)簇里面,蘇州單獨(dú)在一個(gè)簇里面。
考慮到不同的聚類方法結(jié)果可能不一樣,我們?cè)谟懻摬糠诌€利用SimpleKMeans、Cobweb兩種方法對(duì)同樣的數(shù)據(jù)進(jìn)行聚類。我們發(fā)現(xiàn)第1、2種方法結(jié)果更加相近,第3種方法更加細(xì)致,導(dǎo)致每個(gè)情況各成一類。
對(duì)照溫度聚類的結(jié)果和城市之間的空間距離,蘇北城市之間的溫度互相之間更加靠近,蘇中、蘇南城市由于處于長(zhǎng)江兩側(cè),互相之間溫度也更加靠近。
參考文獻(xiàn)
[1] 曾燕,邱新法,何永健,等.復(fù)雜地形下黃河流域平均氣溫分布式模擬[J].中國(guó)科學(xué),2009,39(6):774-786.
[2] 袁淑杰,谷曉平,廖啟龍,等,貴州高原復(fù)雜地形下月平均日最高氣溫分布式模擬[J].地理學(xué)報(bào),2009,64(7):888-896.
[3] 馮立娟.基于Web數(shù)據(jù)挖掘的推薦系統(tǒng)算法研究[D].河北:河北工程大學(xué),2014.
[4] 屈家安,曹杰.主成分分析與聚類分析在青島夏季氣溫變化研究中的應(yīng)用[J].大氣科學(xué)學(xué)報(bào),2014,37(4):517-520.
[5] Dunn J.C.Well-separated clusters and the optimal fuzzy partitions[J].Cybernet,1974(4):95-105.
[6] Bezdek J.C.Pattern recognition with fuzzy objective function algorithns[J].Plenum Press,1981,22(1171):203-209.
[7] Bilgin T T,Camuren A Y.A Data Ming Application on Air Temperature DataBase[J].Lecture Notes in Computer Science,2005(3261):68-76.
[8] C S Moller levet,F(xiàn) Klawonn,KH Cho,et al.Fuzzy clustering of short time-series and unevenly distributed sampling points[C]//Proceedings of the 5th International Symposium on Intelligent Data Analysis.2003.
[9] 謝娟英,蔣帥,王春霞,等.一種改進(jìn)的全局K-均值聚類算法[J].陜西師范大學(xué)學(xué)報(bào):自然科學(xué)版,2010,38(2):18-22.
[10] 聚類分析[EB/OL].http://wiki.mbalia.com/wiki/.
[11] 氣候數(shù)據(jù)源:http://data.cma.cn/.
[12] Weka 3:Date Mining Software in Java [EB/OL].http://www.cs.waikato.ac.nz/ml/weka/.
[13] 戴紅,常子冠,于寧.數(shù)據(jù)挖掘?qū)д揫M].清華大學(xué)出版社,2015.
