一種深度模型行人檢測方法
2016-12-21 09:24:45郭秋滟
實驗室研究與探索 2016年8期
郭秋滟, 李 欣
(1. 西昌學院 汽車與電子工程學院, 四川 西昌 615013; 2. 清華大學 深圳研究生院, 廣東 深圳 518055)
?
一種深度模型行人檢測方法
郭秋滟1, 李 欣2
(1. 西昌學院 汽車與電子工程學院, 四川 西昌 615013; 2. 清華大學 深圳研究生院, 廣東 深圳 518055)
提出一種新的深度模型,通過多個階段的后向傳播來聯合訓練多階段分類器實現行人檢測。該模型可將分類器的得分圖輸出存儲在局部區域中,并將其作為上下文信息來支持下一階段的決策。通過設計具體的訓練策略,深度模型可對硬性樣本進行挖掘來分階段訓練網絡,進而模擬串聯分類器。此外,每個分類器可在不同的難度水平上處理樣本,并通過無監督預訓練和專門安排的各階段有監督訓練來對優化問題正規化,提高了行人檢測的可靠性。理論分析表明該訓練策略有助于避免過擬合。基于3個數據集(Caltech, ETH和TUD-Brussels)的實驗結果也驗證了該方法優于當前其他最新算法。
串聯式分類器; 行人檢測; 深度模型; 上下文信息
0 引 言
行人檢測[1-2]是多種重要應用領域基本的計算機視覺問題之一。由于存在視角變化、姿態、光照、遮擋等各種挑戰,行人檢測難度很大,只簡單利用一種整體分類器難以有效實現行人檢測。例如,側面視角下行人視覺線索不同于正面視角下的視覺線索。單個檢測器難以有效同時捕獲兩個視覺線索。為了處理行人復雜的外觀變化,許多方法選擇一組分類器分階段做出行人和非行人決策[3]。不同分類器負責不同樣本。串聯式分類器往往采取序列訓練策略。使用早先階段無法有效分類的硬性樣本來訓練后續階段的分類器。
直觀來說,因為這些分類器通過緊密交互可以產生協同作用,所以我們希望對這些分類器進行聯合優化。此外,雖然早期分類器無法對硬性樣本做出最終決策,但是它們的輸出所提供的上下文信息可用于支持后續階段的決策。然而,由于參數太多,訓練樣本相對較少,所以分類器容易出現訓練數據過擬合問題。為了對大量分類器參數進行聯合訓練,本文提出一種深度模型,既可對這些分類器進行聯合學習,又可防止訓練過程同時出現過擬合問題。
對行人檢測問題已展開了研究,如文獻[4]針對單幅圖像中的行人檢測問題,提出了基于自適應增強算法(Adaboost) 和支持向量機(SVM)的兩級檢測方法, 應用粗細結合的思想有效提高檢測的精度。文獻[5] 提出了一種新的顏色自相似度特征(CSSF),在顏色通道上計算兩個選定的矩形塊的比值衡量自相似性。文獻[6]針對HOG特征檢測準確率高、計算量大的特點,通過對HOG特征的結構進行調整,提出了使用Fisher特征挑選準則來挑選出有區別能力的行人特征塊,得到MultiHOG特征。文獻[7-20]提出多種特征來提升行人檢測性能。這些方法利用尺寸可變滑動窗口來掃描圖片,進而將行人檢測看成一種分類任務。人們已經提出了多種生成性和區分性分類方法。生成性方法,如文獻[7-9],計算一個窗口圍住一位行人的概率。區分性分類器,比如文獻[10-13]中的boosting分類器和文獻[14-16]中的SVM,試圖通過參數來將陽性和陰性樣本分開。因為行人外觀具有多樣性,所以多篇文獻利用了混合模型[17-19],混合模型通過有監督或無監督聚類來訓練分類器。近期,深度模型已經成功應用于手寫數字識別、對象分割、人臉識別和場景理解、對象檢測和識別領域。文獻[20-24]利用深度模型進行多階段特征的無監督學習。然而,他們沒有在每個階段添加額外的分類器,而且分類得分沒有在不同階段之間作為上下文信息進行傳輸。因此,構建了深度模型和多階段分類器間的聯系,進而對串聯分類器進行聯合優化,有效地提高了行人檢測的可靠性,最后仿真實驗結果也表明了該方法的優越性。
1 深度模型架構
1.1 特征準備
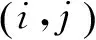
(1)
圖1給出了31個箱子的區分性功率。丟棄了區分性最低的6個箱子。因此,利用每個區塊有25個維度的HOG特征來降低計算量。



圖1 31維HOG特征的區分性(DPk值見圖下)
為了利用局部區域中的上下文信息,本文深度模型采用11個金字塔3 × 3空間局部區域中的檢測得分。因為一個行人窗口包含15 × 5 × 36特征,所以通過利用15 × 5 × 36過濾器來過濾局部17 × 7 × 36特征金字塔,可以獲得具體某一金字塔的3 × 3檢測得分。圖2給出了從3種窗口尺寸中構建特征圖的一個示例。鑒于篇幅所限,我們這里只給出了11個金字塔中的3個金字塔。

圖2 規模不同的3個特征金字塔中構建特征圖
1.2 基于深度學習架構的推理
圖3給出了深度學習架構。整個架構基于圖2所示的特征圖。我們對同一特征圖f采用不同的過濾器Fi然后獲得不同的得分圖si。在該圖中,有2層隱藏層,采用了3個分類器。為了方便起見,我們將輸入層得分圖s0看成是h0。
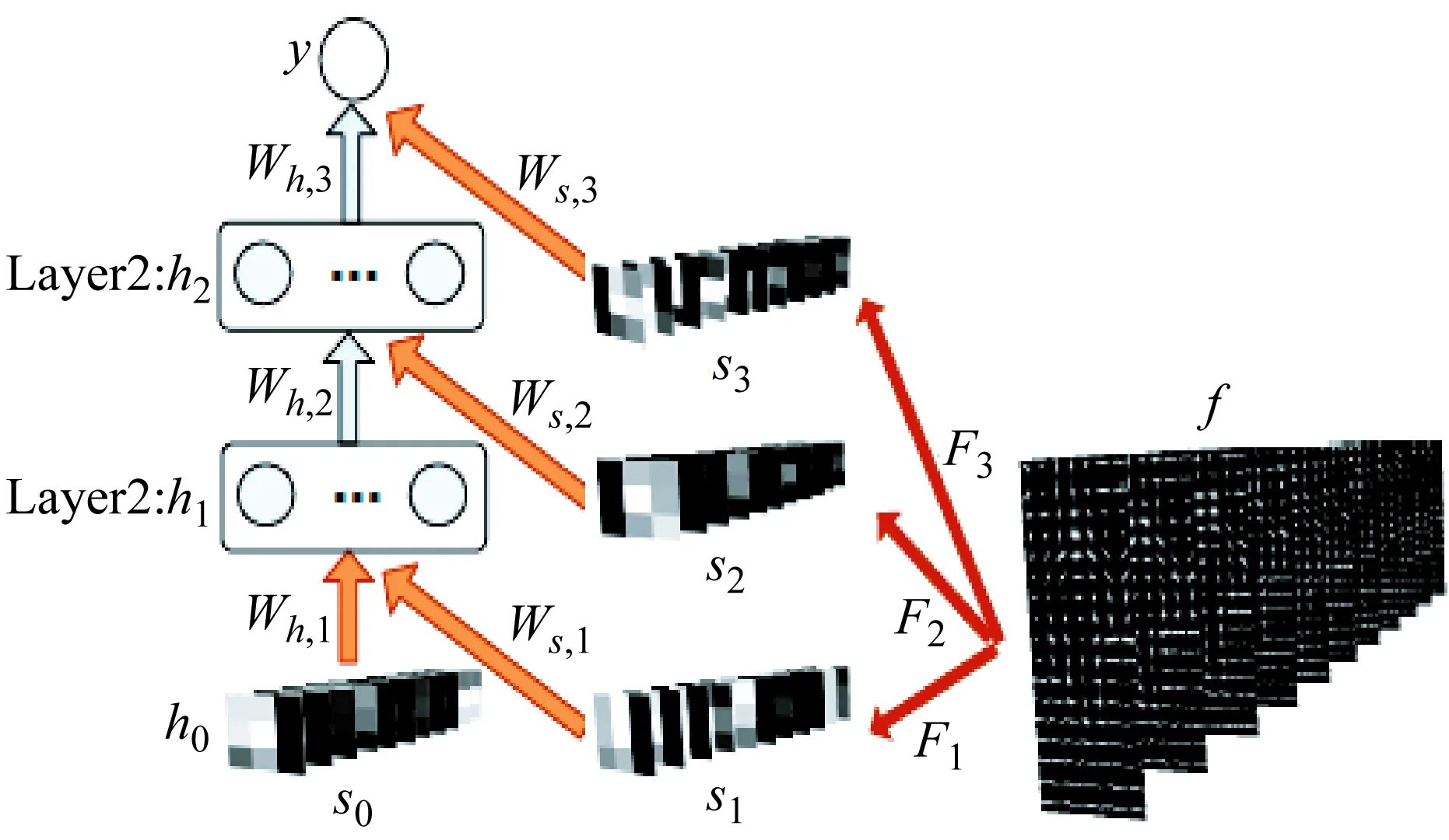
圖3 深度學習架構
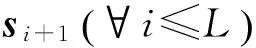
將這些節點連接起來的權重分為3種:①Fi+1表示第i層用于過濾特征圖及獲得得分圖si+1的分類器。②Wh,i表示將隱藏節點hi-1和hi連接起來的權重(轉移矩陣)。③Ws,i表示將得分圖si和隱藏節點hi連接起來的權重。因為輸入s0被看成是h0,所以h0和h1間的權重矩陣表示為Wh,1。
輸入特征圖f有11個金字塔,每個金字塔為17 × 7 × 36特征。該輸入可用于不同層訓練的多個分類器中。在推理階段,分類器Fi+1可對特征圖f進行過濾,并輸出得分圖si+1:
(2)
其中:?表示過濾操作。通過利用線性SVM訓練而得的分類器F0過濾特征圖f,可獲得初始得分圖s0。F0固定,s0可用作上下文檢測得分信息。
利用式(2)求得得分圖si后,si和hi-1可與hi中的隱藏節點完全相連,于是有:
(3)
(4)
最后,窗口包含行人的概率為:
(5)
1.3 深度模型的分階段訓練
算法1對訓練步驟進行了總結。算法包括兩步。首先通過去除所有層中的追加分類器來訓練深度模型,以便到達優質初始化點。對經過簡化的上述模型進行訓練可避免過擬合。然后,挨個增加每一層上的分類器。在每個階段t,對直到第t層的所有當前分類器進行聯合優化。每一輪優化可在先前訓練階段到達的優質初始點周圍發現一個更優局部最小值。
步驟1.1(算法1中的第1和2行):采用文獻[25]中的逐層無監督預訓練方法來訓練連環隱藏轉移矩陣Wh,i+1。在該步驟中,設置Ws,i+1=0,Fi+1=0且i=0,…,L。
步驟1.2(算法1第3行):BP用于微調所有Wh,i+1,其中Ws,i+1=0,且Fi+1=0。
步驟2.1(算法1第4行):對過濾器Fi+1(i=0,…,L)進行隨機初始化,以便搜索出下一步中的區分性信息。
步驟2.2(算法1中的第5~7行):通過BP后向傳播逐步對串聯過濾器Fi+1(i=0,…,L)進行訓練。在階段t,對直到第t層的分類器Fi+1和權重Ws,i+1(?i≤t)進行聯合更新。
算法1:分階段訓練。
線性SVM濾波器:W0
隱藏層數量:L
輸出:轉移矩陣:Wh,i+1,Ws,i+1
新濾波器:Fi+1,i=0,…,L
將Ws,i+1和Fi+1中的元素設置為0;
對所有轉移矩陣Wh,i+1進行無監督預訓練;
通過BP來微調所有轉移矩陣Wh,i+1,同時保持Ws,i+1和Fi+1為0;
對Fi+1隨機初始化;
fort=0 toLdo
利用BP來更新第0層至第t層間的參數,即Fi+1,Wh,i+1,Ws,i+1,0≤i≤t;
end
輸出Wh,i+1,Ws,i+1,Fi+1,i=0,…,L
1.4 理論分析
1.4.1 步驟1的分析
因為Ws,i設為0,故步驟1可看成是利用輸入s0、隱藏節點hi和標識y對深度置信網絡(DBN)[25]進行訓練。步驟1.1用于進行無監督預訓練,步驟1.2用于微調。在該步驟中,DBN網絡利用線性SVM獲得的上下文得分圖作為輸入來訓練樣本。該DBN網絡可對大部分樣本進行正確分類。
1.4.2 步驟2的分析
步驟2訓練策略的屬性描述如下:

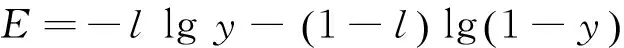
(6)
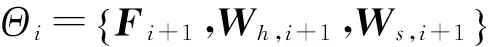
(7)
將第n個訓練樣本表示為xn。將其標簽估計表示為yn,其真實標簽表示為ln。算法1中的步驟2.2對式(7)中的參數Θi進行訓練。在循環t開始時,Ws,i+1=0。如果yn=ln,即訓練樣本已經被正確分類,則對樣本xn來說式(7)中的dθi,j為0。因此,先前階段被正確分類的樣本不會影響參數更新。對于被錯誤分類的樣本,估計誤差越大,dθi,j的值越大。參數更新主要取決于被錯誤分類的樣本的影響。因此,在訓練策略下,每個階段引入一個新的分類器來幫助處理被錯誤分類的樣本,而正確分類的樣本不會對新的分類器產生影響。這就是本文多階段訓練的核心思想。
(2) 在步驟2.2第t階段對t+1個分類器(即i=0,…,t時它們的參數Θi)進行聯合優化,以便這些分類器可更好地互相之間展開協作。
(3) 深度模型可保留特征的上下文信息及檢測得分。卷積分類器Fi利用上下文特征(用金字塔覆蓋行人周圍較大區域的特征),以獲得得分圖。得分圖是第2層上下文信息,我們將得分在局部區域的分布傳輸給下個隱藏層。不同層中的得分圖聯合處理分類任務。傳統的串聯分類器往往丟失這些信息。如果檢測窗口在早先串聯階段被否決,則其特征和檢測得分無法用于下一階段。
(4) 整個訓練階段有助于避免過擬合。首先采取非監督方式對轉移矩陣Wh,i進行預訓練,這可提高泛化能力。有監督分階段訓練可認為是向參數施加正規化約束,即在早期訓練策略中要求部分參數為0。在每個階段,利用先前訓練策略到達的優質點對整個網絡初始化,追加的濾波器對被錯分的硬性樣本進行處理。在先前訓練策略中有必要設置Ws,t+1=0且Ft+1=0;否則,它將成為標準的BP。在標準的BP中,即使是簡單的訓練樣本也可能對各個分類器造成影響。不會根據它們的難度水平將訓練樣本分配給不同的分類器。整個模型的參數空間很大,很容易進行過擬合。
2 仿真實驗
在訓練和測試階段,利用HOG和CSS特征及一個線性SVM分類器來生成得分圖作為底層的輸入。利用一個保守閾值來修剪樣本,降低計算量。在3×3窗口中生成每一層的得分圖,將11個金字塔與對齊后的最大得分圖進行融合,作為得分圖中心。與文獻[14]類似,我們利用對數平均丟失率來衡量總體性能,其中對數平均丟失率表示范圍在10-2~100且在對數空間均衡分布的9個FPPI率的均值,并利用文獻[14]中的評估代碼繪出丟失率和每幅圖像的錯判量(FPPI)之間的關系。
2.1 總體性能
在如下3個公共數據集上進行實驗:Caltech數據集、ETHZ數據集及TUD-Brussels 數據集。我們只關注合適的子集,即含有50像素或更高、未遮擋或部分遮擋的行人圖像。深度模型(ContDeepNet)行人檢測方法與目前較為典型的行人檢測算法做比較:VJ[21], Shapelet[18], PoseInv[14], ConvNet-U-MS[20],FtrMine[11], HikSvm[15], HOG[7], MultiFtr[24], Pls[19],HogLbp[23], LatSvm-V1[12],LatSvm-V2[13],MultiFtr+CSS[22],FPDW[11],ChnFtrs[10],DN-HOG[16],MultiFr+Motion[22],MultiResC[17],CrossTalk[9], Contextual Boost[8]。
2.1.1 Caltech數據集的性能比較
使用Caltech訓練數據集作為訓練數據,并用Caltech測試數據集進行測試。圖4給出了實驗結果。被比較算法已經采用了多種特征,比如Haar-like特征、形狀子特征( shapelet )、HOG、LBP和CSS。其中,文獻[8,13]采用基于部位的模型、文獻[7,23]采用線性SVM、文獻[15]采用內核SVM、文獻[8,9,10,21]采用串聯分類器、文獻[16,20]采用深度模型、文獻[12]中的MultiResC和文獻[8]中的上下文增強(Contextual-Boost)算法與本文類似,采用HOG+CSS作為特征。上下文增強(Contextual-Boost)算法雖然采用串聯分類器,但是沒有對分類器進行聯合優化,它們的對數平均丟失率為48%。所有現有算法中,這兩種算法的對數平均丟失率最低。與MultiResC和上下文增強(Contextual-Boost)算法相比,ContDeepNet算法的對數平均丟失率下降到45%,性能提升了3%。
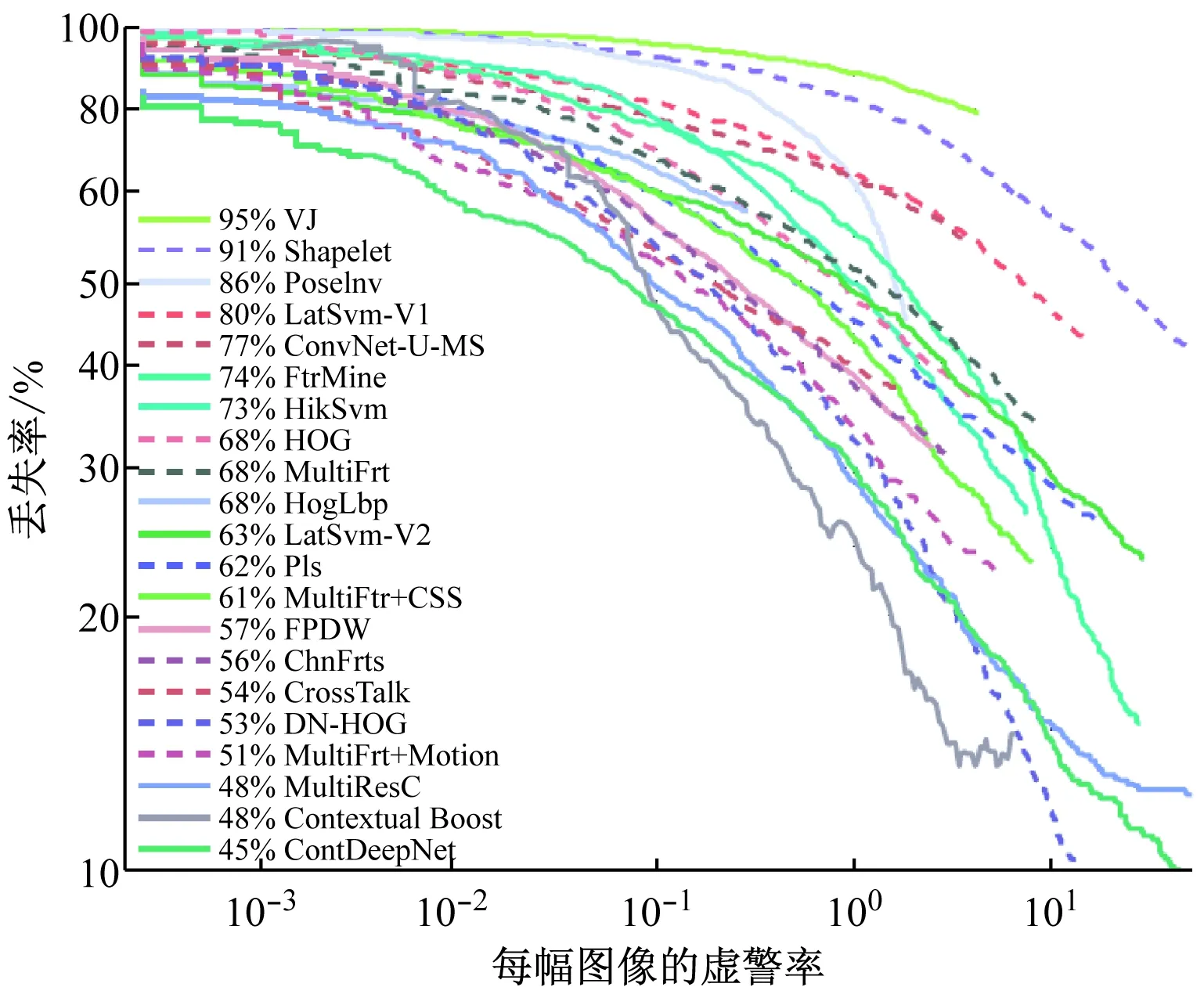
圖4 Caltech測試數據集的性能比較
2.1.2 ETHZ數據集的性能比較
圖5給出了對ETHZ行人數據集的實驗結果。與大多數算法利用INRIA訓練數據集進行訓練并利用ETHZ數據集進行測試類似,深度模型也利用INIRA訓練數據集進行訓練。ConvNet-U-MS表示文獻[20]中給出的卷積網絡模型運行結果。ConvNet-U-MS是當前所有算法中對數平均丟失率最低的算法,但是與ConvNet-U-MS相比,ContDeepNet方法的對數平均丟失率為48%,性能提升了2%。ConvNet-U-MS利用一種深度模型來學習低層次特征,但是它既沒有利用上下文得分,也沒有利用多階段分類器。
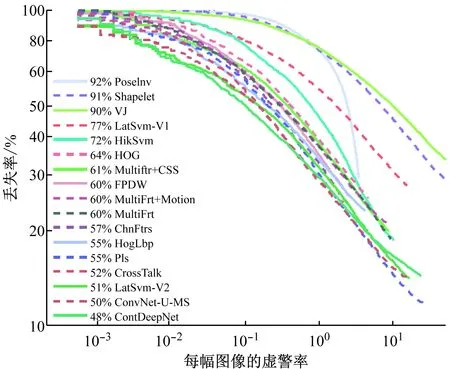
圖5 ETHZ數據集的性能比較
2.1.3 TUD-Brussels數據集的性能比較
圖6給出了TUD-Brussels行人數據集的實驗結果。利用INRIA訓練數據集進行模型訓練。本文算法的對數平均丟失率為63%。有部分算法的性能優于本文算法。這些算法利用的特征更多。性能最優的MultiFtr+Motion[22]算法利用了運動特征。
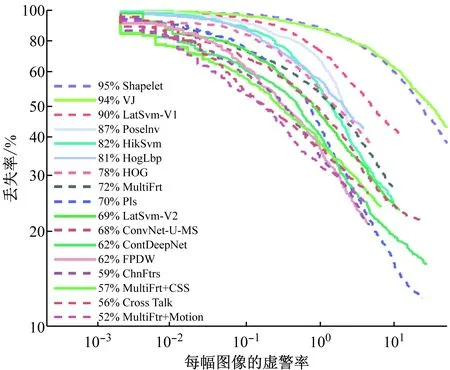
圖6 TUD數據集的性能比較
2.2 架構比較
采用不同架構時的實驗結果,比較兩種3層深度網絡的性能。第1個網絡表示為DeepNetNoFilter,未額外采用分類器。第2種網絡即為本文采用了3個額外分類器的ContDeepNet網絡。兩種網絡在其他方面均相同,利用Caltech訓練數據集進行訓練,利用Caltech測試數據集進行測試。如圖7所示,當包含額外分類器時,對數平均丟失率下降了6%。
圖8給出了被ContDeepNet正確分類但是被DeepNetNoFilter錯誤分類的檢測樣本。這些樣本是從兩種算法300個檢測樣本中選擇出來的檢測得分最高的樣本。追加的分類器有助于本文深度模型處理硬性樣本。例如,公交燈、輪胎和樹干的虛警現象被正確排除,側視、模糊、被遮擋的行人和行進中的自行車的漏警現象被正確檢測出來。
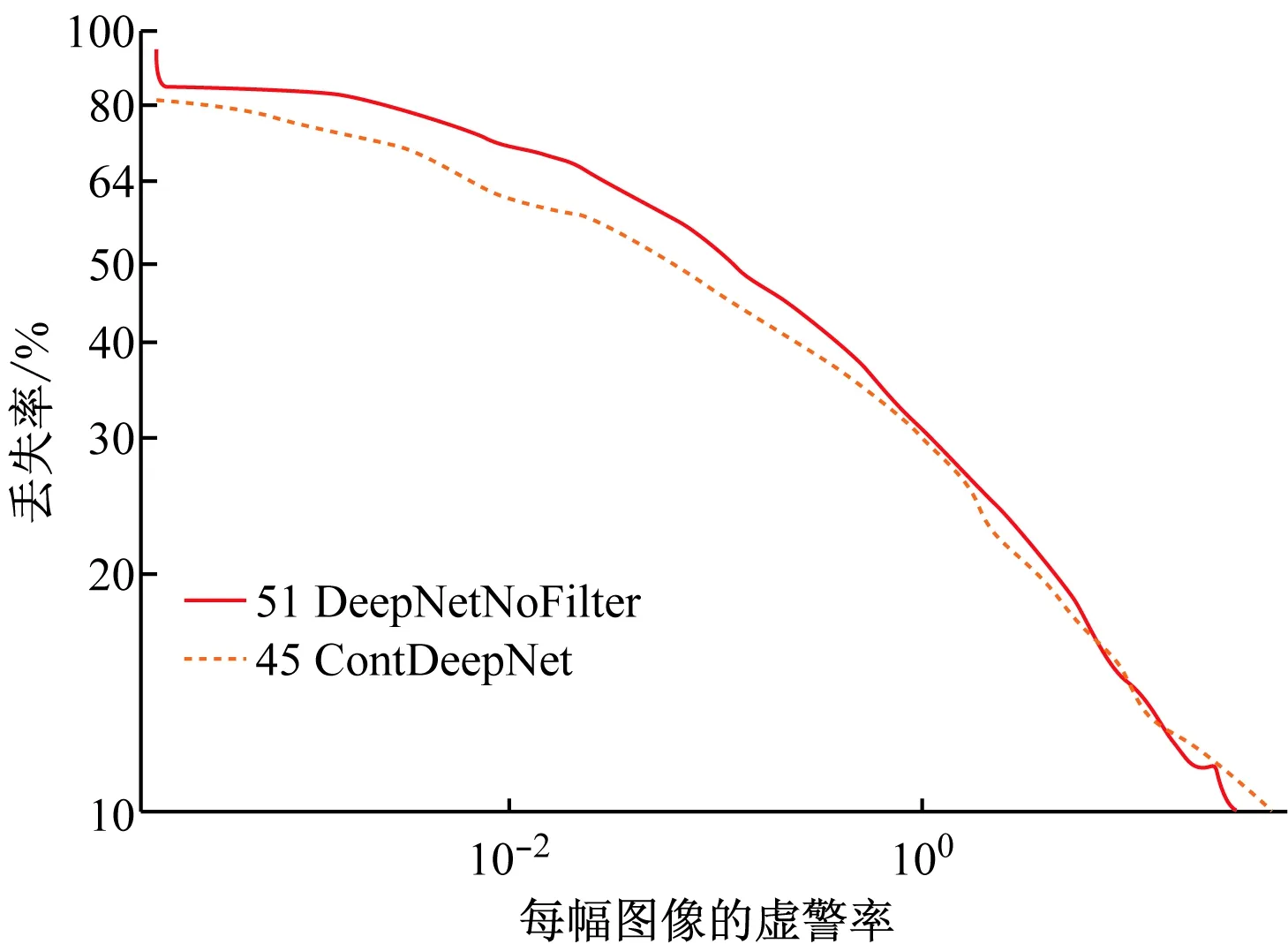
圖7 不同深度架構對Caltech測試數據集的性能比較

圖8 被DeepNet-NoFilter錯誤分類但被ContDeepNet正確分類的檢測結果
2.3 訓練策略的比較
在架構與ContDeepNet相同、但訓練策略不同的條件下展開一組實驗。其中,BP表示整個網絡只利用BP策略進行訓練,不經逐層預訓練對所有參數隨機初始化,然后通過后向傳播來對所有轉移矩陣和過濾器進行同步更新。PretrainTransferMatrix-BP算法采用文獻[26]中的方法對所有轉移矩陣進行無監督預訓練,然后通過BP方法對整個網絡進行微調。Multi-stage表示本文所提訓練策略,它采用逐階段BP策略而不是標準BP策略來訓練整個網絡。圖9的實驗結果證明了本文訓練策略的有效性。
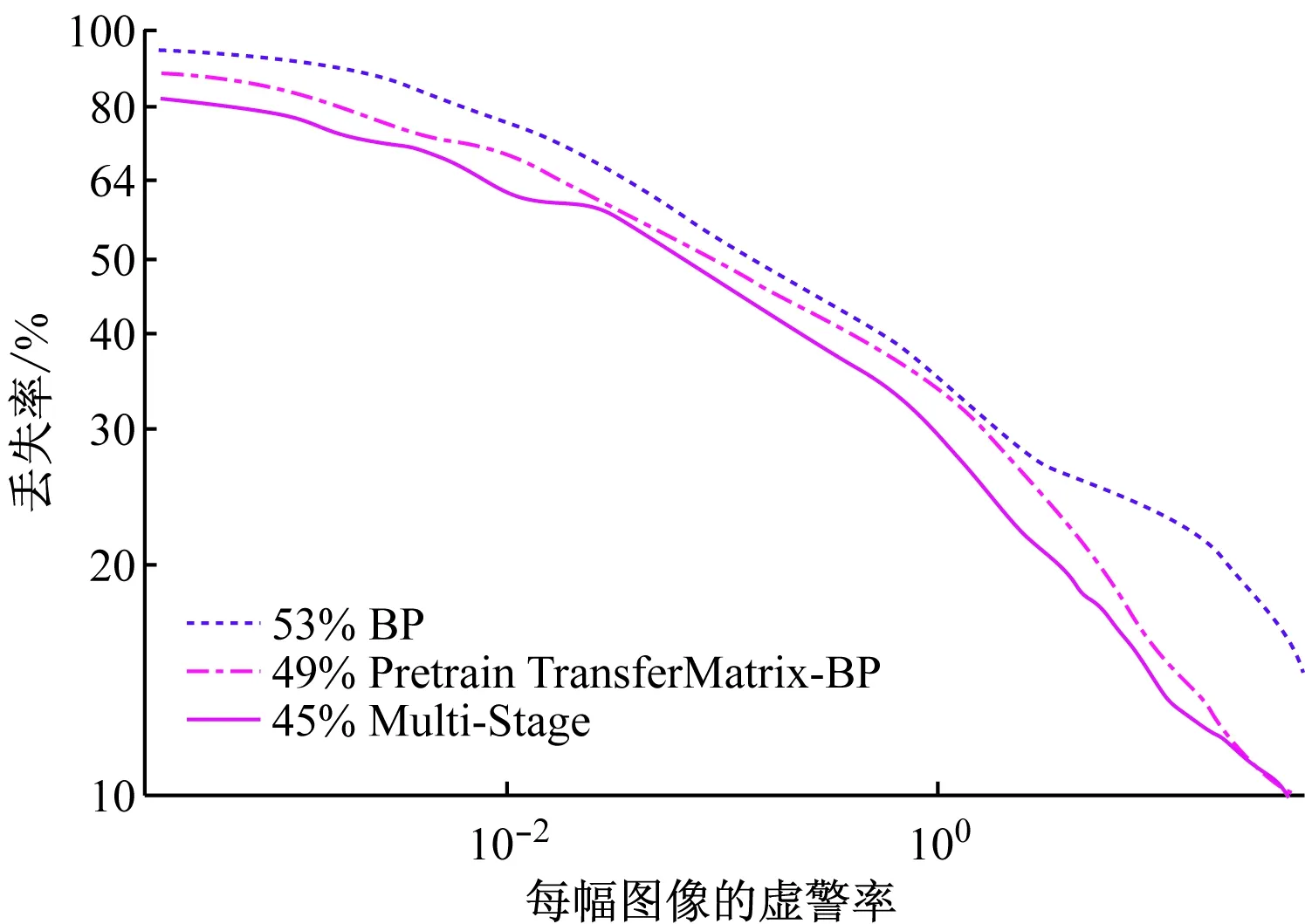
圖9 架構與ContDeep-Net相同但訓練策略不同時對Caltech測試數據集的運行結果
3 結 語
提出了一種新的多階段上下文深度模型,并針對行人檢測設計了專門的訓練策略。該模型可對串聯分類器進行模擬。來自特征圖和得分圖的金字塔上下文信息可在串聯分類器中傳播。通過多階段后向傳播,對深度模型中的所有分類器進行聯合訓練。通過無監督預訓練和專門設計的多階段有監督訓練策略,避免過擬合,有效提高了行人檢測的準確性。下一步工作重點是對復雜背景下人體動作識別進行研究,提出一種基于定位的人體聯合姿態跟蹤和動作識別算法。
[1] 蘇松志, 李紹滋, 陳淑媛, 等. 行人檢測技術綜述[J]. 電子學報, 2012, 40(4): 814-820.
[2] 陳 銳, 彭啟民. 基于穩定區域梯度方向直方圖的行人檢測方法[J]. 計算機輔助設計與圖形學學報, 2012, 24(3): 372-377.
[3] Benenson R, Mathias M, Timofte R,etal. Pedestrian detection at 100 frames per second[C]∥Computer Vision and Pattern Recognition (CVPR), 2012 IEEE Conference on. IEEE, 2012: 2903-2910.
[4] 種衍文, 匡湖林, 李清泉. 一種基于多特征和機器學習的分級行人檢測方法[J]. 自動化學報, 2012, 38(3): 375-381.
[5] 曾波波, 王貴錦, 林行剛. 基于顏色自相似度特征的實時行人檢測[J]. 清華大學學報(自然科學版), 2012, 52(4): 571-574.
[6] 田仙仙, 鮑 泓, 徐 成. 一種改進 HOG 特征的行人檢測算法[J]. 計算機科學, 2014, 41(9): 320-324.
[7] Dalal N, Triggs B. Histograms of oriented gradients for human detection[C]∥IEEE Computer Society Conference on Computer Vision and Pattern Recognition(CVPR2005). IEEE, 2005: 886-893.
[8] Ding Y, Xiao J. Contextual boost for pedestrian detection[C]∥IEEE Conference on Computer Vision and Pattern Recognition (CVPR2012). IEEE, 2012: 2895-2902.
[9] Dollár P, Appel R, Kienzle W. Crosstalk cascades for frame-rate pedestrian detection [M]. Computer Vision. Springer Berlin Heidelberg, 2012: 645-659.
[10] Dollár P, Tu Z, Perona P,etal. Integral Channel Features [J].BMVC. 2009, 2(3): 510-518.
[11] Dollár P, Tu Z, Tao H,etal. Feature mining for image classification[C]∥IEEE Conference on Computer Vision and Pattern Recognition (CVPR2007). IEEE, 2007: 1-8.
[12] Felzenszwalb P, McAllester D, Ramanan D. A discriminatively trained, multiscale, deformable part model[C]∥IEEE Conference on Computer Vision and Pattern Recognition (CVPR2008). IEEE, 2008: 1-8.
[13] Felzenszwalb P F, Girshick R B, McAllester D,etal. Object detection with discriminatively trained part-based models [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2010, 32(9): 1627-1645.
[14] Lin Z, Davis L S. A pose-invariant descriptor for human detection and segmentation [M]. Computer Vision. Springer Berlin Heidelberg, 2008: 423-436.
[15] Maji S, Berg A C, Malik J. Classification using intersection kernel support vector machines is efficient[C]∥IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2008). IEEE, 2008: 1-8.
[16] Ouyang W, Wang X. A discriminative deep model for pedestrian detection with occlusion handling[C]∥IEEE Conference on Computer Vision and Pattern Recognition (CVPR2012). IEEE, 2012: 3258-3265.
[17] Park D, Ramanan D, Fowlkes C. Multiresolution models for object detection [M]. Computer Vision-ECCV 2010. Springer Berlin Heidelberg, 2010: 241-254.
[18] Sabzmeydani P, Mori G. Detecting pedestrians by learning shapelet features[C]∥IEEE Conference on Computer Vision and Pattern Recognition (CVPR2007). IEEE, 2007: 1-8.
[19] Schwartz W R, Kembhavi A, Harwood D,etal. Human detection using partial least squares analysis[C]∥IEEE 12th international conference on Computer vision. IEEE, 2009: 24-31.
[20] Sermanet P, Kavukcuoglu K, Chintala S,etal. Pedestrian detection with unsupervised multi-stage feature learning[C]∥IEEE Conference on Computer Vision and Pattern Recognition (CVPR2013). IEEE, 2013: 3626-3633.
[21] Viola P, Jones M J, Snow D. Detecting pedestrians using patterns of motion and appearance [J]. International Journal of Computer Vision, 2005, 63(2): 153-161.
[22] Walk S, Majer N, Schindler K,etal. New features and insights for pedestrian detection[C]∥IEEE conference on Computer vision and pattern recognition (CVPR2010). IEEE, 2010: 1030-1037.
[23] Wang X, Han T X, Yan S. An HOG-LBP human detector with partial occlusion handling[C]∥12th International Conference on Computer Vision. IEEE, 2009: 32-39.
[24] Wojek C, Schiele B. A performance evaluation of single and multi-feature people detection [M]. Pattern Recognition. Springer Berlin Heidelberg, 2008: 82-91.
[25] Hinton G, Osindero S, Teh Y W. A fast learning algorithm for deep belief nets [J]. Neural Computation, 2006, 18(7): 1527-1554.
Research on a Pedestrian Detection Scheme Based on Deep Model
GUOQiu-yan1,LIXin2
(1. School of Automotive and Electronic Engineering, Xichang College, Xichang 615013, China;2. Graduate School of Shenzhen, Tsinghua University, Shenzhen 518055, China)
The existing pedestrian detection schemes are based on cascaded classifiers, hence it has too many parameters and low reliability of detection. In this paper, we propose a new deep model that can jointly train multi-stage classifiers through several stages of back propagation to achieve pedestrian detection. It keeps the score map output by a classifier within a local region, and uses it as contextual information to support the decision at the next stage. Through a specific design of the training strategy, this deep architecture is able to simulate the cascaded classifiers by mining hard samples to train the network stage-by-stage. However, each classifier handles samples with different difficulty levels, and unsupervised pre-training and specifically designed stage-wise supervised training are used to regularize the optimization problem for the reliability of pedestrian detection. Both theoretical analysis and experimental results show that the training strategy helps to avoid over-fitting. Experimental results on three datasets (Caltech, ETH and TUD-Brussels) show that the presented approach outperforms the state-of-the-art approaches.
cascaded classifiers; pedestrian detection; deep model; contextual information
2015-07-06
國家自然科學基金項目資助(61371138/F010403)
郭秋滟(1981-),女,四川隆昌人,講師,研究方向:圖像處理、計算機視覺。
E-mail: 929138392@qq.com
TP 391
A
1006-7167(2016)08-0121-06
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
