一種改進初始中心點的FCM算法
2016-12-22 06:40:40唐德玉曹東楊進
現代計算機 2016年32期
唐德玉,曹東,楊進
(1.廣東藥科大學醫藥信息工程學院,廣州 510006;2.廣州中醫藥大學醫學信息工程學院,廣州 510006)
一種改進初始中心點的FCM算法
唐德玉1,曹東2,楊進1
(1.廣東藥科大學醫藥信息工程學院,廣州510006;2.廣州中醫藥大學醫學信息工程學院,廣州510006)
傳統FCM算法存在聚類初始中心點敏感及迭代次數多的缺點,提出一個改進聚類初始中心點的加強FCM算法。新算法通過數據轉換及排序把數據劃分到合適的簇中,從而找到最好的聚類初始中心點。在給定聚類數目的條件下,通過UCI機器學習數據庫中的兩組數據集進行實驗比較,結果表明采用加強FCM算法比傳統FCM算法收斂速度更快,有較高的準確率和穩定性。
模糊C-均值;目標函數;聚類初始點;數據劃分
廣東省財政專項“中醫藥防治重大疾病臨床科研信息一體化平臺建設項目”、廣東省自然基金項(2016A030310300)、基于協同智能優化的藥物-靶標相互作用預測方法研究
0 引言
K-Means算法是1967年由Mac Queen提出的聚類算法。K-Means方法是一個劃分方法,把數據劃分到K個組[1-2]。將模糊數學應用到K-Means算法,從而發展到使用模糊理論的劃分方法,也就是目前很流行的模糊C-均值(簡稱FCM)[7]聚類算法。該算法已經應用在數據挖掘、模式識別、計算機視覺、醫學圖像等領域,具有重要的理論與實際應用價值。但是K-Means和FCM算法還存在很多共同的問題亟待解決[8]。如聚類數目難確定,初始中心點敏感,迭代次數多,容易陷入局部極值,難以取得全局最優。
針對上述問題,有很多學者提出改進K-Means算法初始中心點的方法[3-6]。而對于FCM算法也出現了很多解決方法。
張慧哲[9]等提出一種計算所有樣本點的距離,先找到最近的兩個樣本點的中心點做為第一個初始中心點,然后根據設置的閾值α,求大于α的所有樣本點距離,并求剩下樣本點的最小值,做為第二個中心點,重復下去,找到所有初始中心點。
匡泰[10]等人為了解決FCM算法初始點不確定,迭代次數多等問題,提出了基于多項式確定初始中心點的算法,該算法的思想是把類中心看成是多項式的根,通過求多項式的解來確定初始中心點。
還有一些方法,例如采用模擬退火算法進行全局優化,首先產生一個初始解作為當前解,然后在當前解的領域中,以概率P(T)選擇一個非局部最優解,并令這個解再重復下去,從而保證不會陷入局部最優。開始時允許隨著參數的調整,目標函數偶爾向增加的方向發展,以利于跳出局部極小區域。
也有使用遺傳算法提高FCM對高維數據的聚類效果,可以設置遺傳算法的適應度函數f=1/(1+J)其中J為FCM目標函數,采用編碼方式表示染色體為A= (a1,a2,a3,…,ac),其中ai為一個聚類中心。確定聚類中心數目,群的大小,交叉概率,突變概率,遺傳次數,計算隸屬度和目標函數,求出適應度函數。循環執行三種遺傳操作:復制,交叉,突變。直到最后獲得最佳聚類中心。該方法可以獲得近似全局解。但其缺點是常常“過早收斂”,不能保證完全獲得最優解,而且執行時間比較長。
此外有根據樣本點與聚類中心相似關系加權提高FCM準確性的方法,其思想是根據相似性理論,為每一個樣本加一個特殊權值讓不同的樣本在聚類中心中起不同的作用。并對歐氏距離加權。使用合并函數求最大聚類數,其思想是提出一個合并函數,使得(c-1)類的類中心依賴于c類的類中心。保證FCM算法相對穩定,執行速度比普通FCM算法稍快,但不是很明顯。給出的方法,算法過于復雜,不適合大數據量應用。
1 傳統FCM模糊聚類算法
給定數據集:X={x1,x2,…,xn},其中每個樣本xi包含d個屬性。
模糊聚類就是要將X劃分為c個類(簇)(2≤c≤n),v={v1,v2,…,vc}為c個聚類中心。在模糊劃分中,每一個樣本不能嚴格地被劃分到某一類(簇),而是以一定的隸屬度屬于某一類(簇)。令U=(uij),i=1,2,…,n,j=1,2,…,c為隸屬度矩陣。
FCM算法基于求解下面的目標函數的最小值:
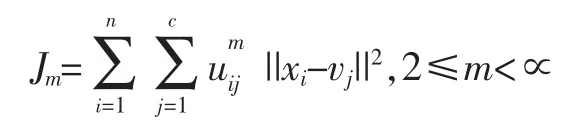
其中m是任意一個大于等于2的實數,uij是在j簇中心的隸屬度,是第i樣本點,vj是簇的中心。
為了獲得Jm最小值,運用Lagrange乘數法求極值,得:
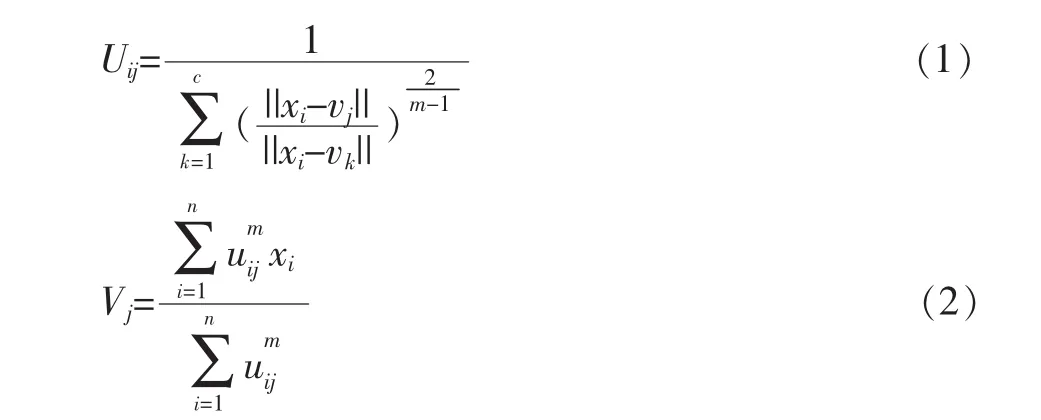
對于(1)式,其中vj為第j個聚類中心點,||xi-vj||表示樣本點xi到中心點vj的歐氏距離。顯然,對于樣本點xi到第j個聚類中心vj距離越近,則uij越大。且滿足如下條件:
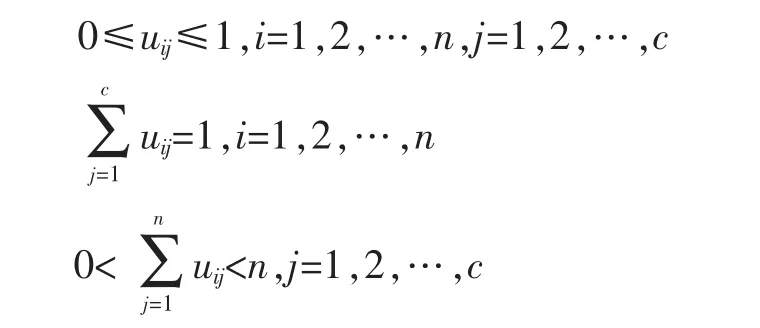
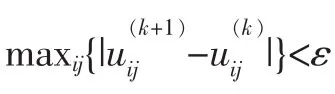
算法的執行步驟如下:
1.初始化U=[uij]矩陣,U(0).
2.在第k步:使用U(k)計算中心向量V(k)=[vj],由(2)算得。
3.更新U(k),獲得U(k+1)。Uij由公式(1)算得。
2 提出的算法
傳統FCM算法是隨機產生[0,1]的隸屬度矩陣,根據隸屬度使用公式(2)找到初始中心點。由于初始中心點是隨機產生的,所以傳統FCM算法迭代次數比較多,當數據比較多時,算法執行很慢。為此我們提出一個加強FCM(enhancing FCM,以下簡稱eFCM算法)聚類算法。該方法是找到最好的初始中心點,改進算法的時間復雜度,并提高算法的準確性。
基本思路是計算數據集中所有樣本點與樣本原點的距離,把數據集中所有樣本點與樣本原點的距離排序。然后把所有排好序的數據樣本點平均劃分到K個子集。在這K個子集中的中間樣本點做為該集合的初始中心點。這些初始中心點會產生更好的唯一的聚簇結果。排序的算法我們考慮用快速排序算法,因為快速排序算法在最壞和最好情況下,平均時間復雜度為O (NlogN)。
首先我們檢查數據集中數據有沒有負值[17],如果數據集中沒有負值,那我們不需要數據轉換;但如果這個數據集里有負值,那么我們必須把數據集里所有數據的負值轉換到正值空間里。轉換的方法是先找到數據集中所有屬性中的數據的最小值(負值),然后讓數據集中所有數據減去最小值。這個轉換是必須的,因為我們提出的這個算法,就是要計算數據集所有樣本點與坐標樣本原點的距離。對于不同的數據樣本點,我們可以獲得幾乎不同的距離。如圖1中a),可以看出在二維空間中四個點(x1,y1),(x2,y2),(x3,y3),(x4,y4)在四個象限中,四個點與原點(0,0)的距離幾乎相等;而數據進行轉換后,四個點全部放在第一象限。此時,四個點與原點(0,0)的距離明顯不同。
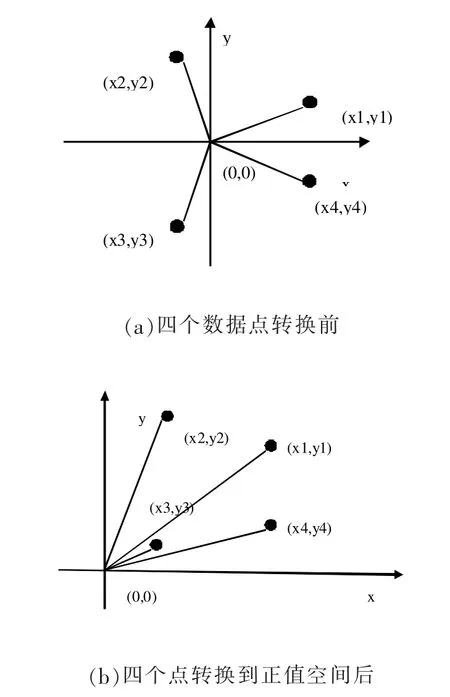
圖1 數據轉換
雖然歐氏距離對球形結構聚類有一定的優勢,但在解決高緯數據問題時,存在一些計算上的弊端。而馬氏(Mahalanobis)距離計算僅涉及協方差矩陣的求逆,不再和特征矢量的維數有關,而是和樣本數目有關,因此在高緯特征空間中帶來計算上的優勢,在無窮維特征空間中解決了計算上存在的問題。所以我們在進行數據劃分時,采納馬氏距離計算樣本原點與數據樣本的距離,然后平均劃分為K個子集。
下一步,求初始中心點。加強FCM算法步驟如下:
輸入:
D={x1,x2,x3,…,xi,…,xm}//m個樣本數據點
d={d1,d2,d3,…,di,…,dn}//一個樣本數據點的n個屬性k//需要的簇的數目
輸出:k個初始中心點
步驟如下:
1.給定的數據集D,如果包括負值和正值的屬性值,那么程序跳轉到2,否則跳轉到4。
2.找到數據集D中屬性值的最小值。
3.數據集D中的所有數據點的值減去最小值。
4.使用馬氏距離計算所有樣本點與樣本原點的距離。
5.根據第4步獲得的距離進行排序。
6.把排好序的數據點分成K個相等的子集合。
7.在每個子集中找到離樣本原點距離為中等的樣本點做為該子集的聚類初始中心點。
8.根據獲得的聚類初始中心點使用公式(1)計算隸屬度。
9.根據獲得的隸屬度使用公式(2)計算新的聚類中心點。
10.計算目標函數值,并計算誤差,如果誤差小于閾值,程序結束。否則跳到8。
3 仿真模擬實驗
為了驗證提出的算法的有效性和準確性,我們使用UCI機器學習中的Iris和Wine數據進行仿真實驗,然后對傳統FCM算法和eFCM算法進行比較。實驗源數據表如表1:
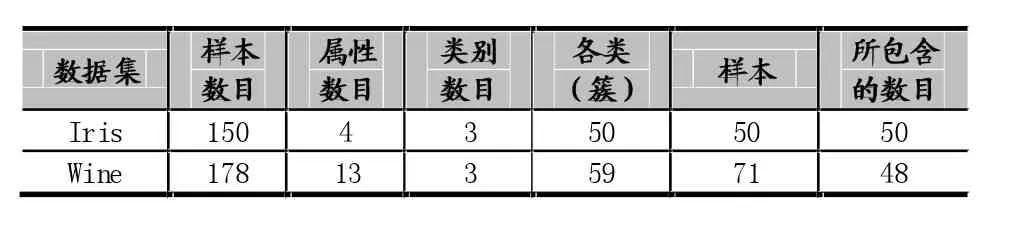
表1 數據源信息
本文實驗環境是,處理器頻率為2.10GHz,內存3G,硬盤120G,使用Windows XP 32位操作系統。開發工具使用MATLAB 7.8。實驗初始化參數如下:隸屬度指數expo=2.0,簇數目clustern=3,迭代最大數目maxiter=100,目標函數值誤差最小閾值為minimpro=1e-6。我們對Iris和Wine數據先對歸一化處理,以減少量綱不同對算法的影響。使用公式Y=(Ymax-Ymin)*(X -Xmin)/(Xmax-Xmin)+Ymin,X為數據原始樣本值,Y為數據規范化后的數據,我們使用Ymin=0,Ymax=1,使所有數據落在[0,1]范圍內。
為了保證實驗的準確性,我們對傳統FCM算法做了7次實驗,計算算法的迭代次數,運行時間及準確率的平均值。而對eFCM算法做了7次實驗,計算運行時間的平均值。
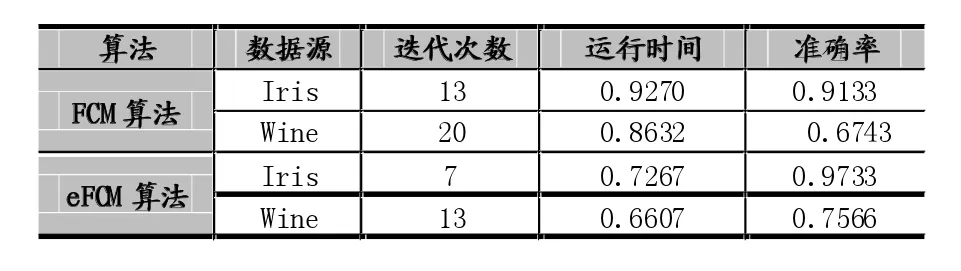
表2 傳統FCM算法與eFCM算法的比較
從表2中結果可以看出,我們提出的eFCM算法的準確率高于普通FCM算法。Iris數據集和Wine數據集都有類標號,每個數據集分為3個類(簇)(見表1)。準確性的計算就是用聚類算法產生的三個簇中的樣本與已知的三個類(簇)中的樣本類別進行比較,計算聚類產生的簇中正確分類的樣本總數。準確率=同一簇中正確分類的樣本總數/同一簇已有樣本總數。比如,見表3,對于Iris數據集中的分類1(簇1),同一簇已有樣本總數=50,FCM聚類產生的同一簇中正確分類的樣本總數=46,其準確率為46/50約為92%;eFCM聚類產生的同一簇中正確分類的樣本總數=50,其準確率為50/50等于100%。總的準確率=所有簇中正確分類的樣本總數/所有簇中已有樣本總數(見表2)。
對于模糊C-Means算法而言,目標值越小,說明聚類的越好。傳統FCM算法產生的第一個初始聚類中心點與穩定后的聚類中心點有很大偏離;eFCM算法產生的第一個初始聚類中心點與最后的聚類中心點接近,所以目標值也很小。對于IRIS數據集中從圖2和圖3可以看出,FCM算法產生的第一個目標值(4.5112),而eFCM算法的第一個目標值(0.6811)。對于Wine數據集中,FCM算法產生的第一個目標值(0.21),而eFCM算法的第一個目標值(0.0843)。這也說明eFCM算法選擇的初始中心點的有效性。加強的eFCM算法比傳統的FCM算法相比,數據樣本分類的準確率有所提高,簇與簇之間的分類清晰,簇內數據樣本更加緊湊,聚類效果更好。如表3可見eFCM算法對3個類正確分類的能力有提高。
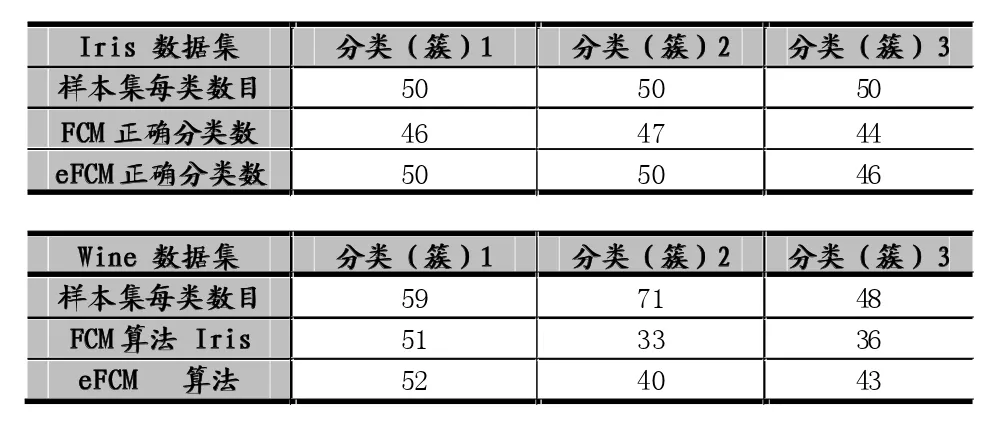
表3 傳統FCM算法與eFCM算法的比較
特別是eFCM算法的運行速度很快。對于Iris數據加強FCM算法只需要迭代7次,而傳統FCM算法要迭代15次;對于Wine數據,eFCM算法只需要迭代12次,而傳統FCM算法要迭代20次。使用MATLAB畫圖顯示了兩個算法目標函數的迭代情況。如圖2和圖3。
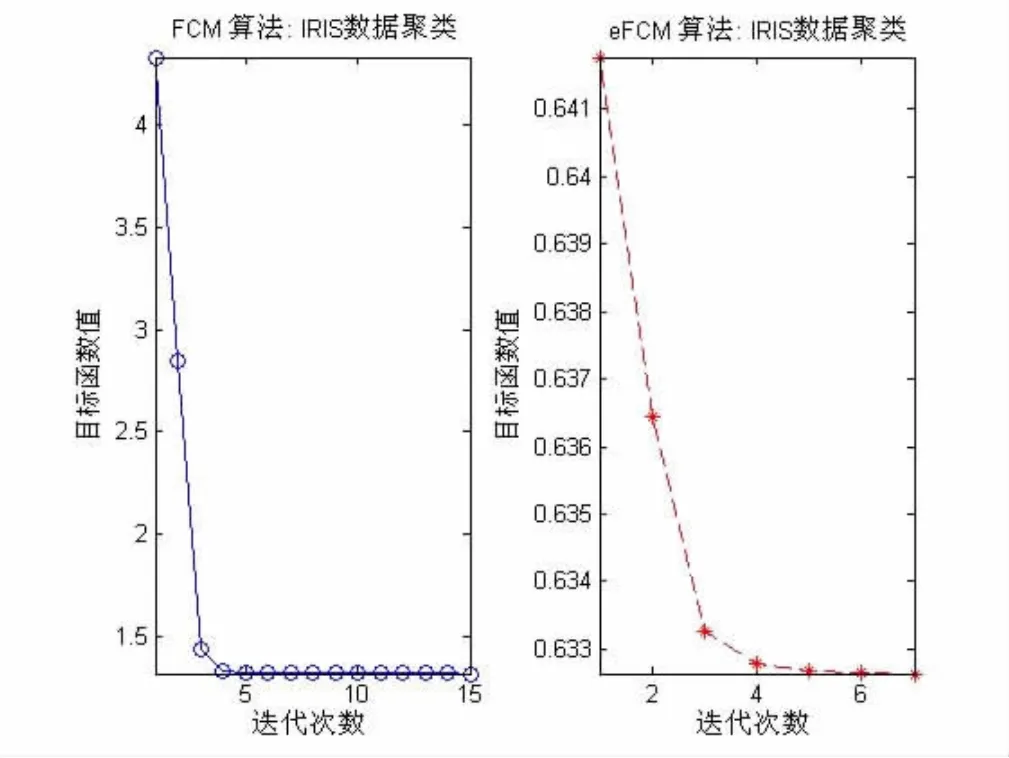
圖2 Iris數據FCM算法和eFCM算法的迭代情況
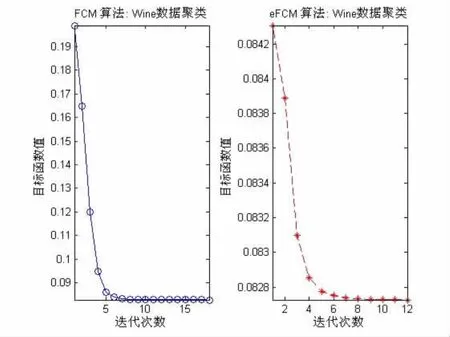
圖3 Wine數據FCM算法和eFCM算法的迭代情況
最后,我們對于傳統FCM和eFCM算法的時間復雜度進行分析,對于傳統FCM算法來說,最大迭代次數需要循環maxiter次,隸屬度計算需要執行clustern*datan*datam次循環,中心點計算也要執行clustern*datan*datam次循環,目標函數是計算所有樣本與中心點的距離,要執行clustern*datan*datam次循環。所以總的執行時間為O(maxiter*clustern*datan*datam)。而目標函數的誤差值小于指定最小值時,程序可以在小于maxiter次循環停止。由于傳統FCM算法初始中心點是隨機產生的,所以要找到最佳的聚類中心點,迭代次數一般都比較多,很多情況下是要maxiter次迭代,而這是循環執行最多的情況。而對于我們提出的eFCM算法在執行時間要O(miniter*clustern*datan *datam),其中miniter< FCM算法也是目前很流行的聚類算法,但FCM算法由于初始中心點是隨機產生的,使得FCM算法執行比較慢,準確性也有所降低。我們提供的eFcm算法與傳統FCM算法相比,更加高效和準確。該方法找到最好的初始中心點,把所有的樣本數據點分配到合適的簇中。而這個數據劃分機制所需要時間復雜度僅為O (NlogN),eFCM算法的時間復雜度為O(miniter*clustern*datan*datam),miniter< [1]A.M.Fahim,A.M.Salem,F.A.Torkey,M.A.Ramadan.An Efficient Enhanced K-Means Clustering Algorithm.Journal of Zhejiang University,10(7):1626-1633,2006. [2]K.A.Abdul Nazeer,M.P.Sebastian.Improving the Accuracy and Efficiency of the K-Means Clustering Algorithm.In International Conference on Data Mining and Knowledge Engineering(ICDMKE),Proceedings of the World Congress on Engineering(WCE-2009),Vol 1,July 2009,London,UK. [3]Chen Zhang,Shixiong Xia.K-Means Clustering Algorithm with Improved Initial Center.in Second International Workshop on Knowledge Discovery and Data Mining(WKDD),pp.790-792,2009. [4]F.Yuan,Z.H.Meng,H.X.Zhangz,C.R.Dong.A New Algorithm to Get the Initial Centroids.Proceedings of the 3rd International Conference on Machine Learning and Cybernetics,pp.26-29,August 2004. [5]Koheri Arai,Ali Ridho Barakbah.Hierarchical K-Means:an Algorithm for Centroids Initialization for K-Means.Department of Information Science and Electrical Engineering Politechnique in Surabaya,Faculty of Science and Engineering,Saga University,Vol.36,No.1,2007. [6]S.Deelers and S.Auwatanamongkol.Enhancing K-Means Algorithm with Initial Cluster Centers Derived from Data Partitioning along the Data Axis with the Highest Variance.International Journal of Computer Science,Vol.2,Number 4. [7]Bezdek J C.Pattem Recogition with Fuzzy Objective Function Algorithms[M].NY:Plenum,1981. [8]Duda R,HartP,Stork D.Pattern Classification(2 nd Edition)[M].New York,USA;John Wiley&Sons,2001. [9]張慧哲.基于初始聚類中心選取的改進FCM聚類算法[J].計算機科學,2009,26(6);206-209. [10]匡泰.FCM算法用于灰度圖像分割的初始化方法的研究[J].計算機應用,2006,26(4);784-786. The traditional FCM algorithm has the defection of sensitivity to the initial cluster center and iterate so more,proposes an enhancing FCM algorithm by improved cluster initial center.A novel algorithm can partition data set into suited clusters through data conversion and sorting,and then find a best initial center.Given the number of cluster,test and compare by two group data set of UCI machining study database,results demonstrate that enhancing FCM algorithm has fast convergence,enhancing accuracy and stability than traditional FCM. Keywords: Fuzzy C-Means;Objective Functiong;Initial Cluster Center;Data Partitioning A FCM Algorithm Based on Improved Initial Cluster Center TANG De-yu1,CAO Dong2,YANG Jin1 (1.Guangdong Pharmaceutical University,College of Medical Information and Engineering,Guangzhou 510006;2.Guangzhou University of Chinese Medicine,Guangzhou 510006) 唐德玉(1978-),男,廣東廣州人,博士,副教授,研究方向為數據挖掘、智能計算、網絡集成 曹東(1975-),男,博士,副院長 楊進(1977-),男,廣東廣州人,碩士,講師,研究方向為數據挖掘、智能計算 2016-09-13 2016-10-204 結語
