說話人識別中語速魯棒性研究
2016-12-23 07:26:01朱紫陽彭亞雄
網絡安全與數據管理 2016年7期
朱紫陽,賀 松,彭亞雄
(貴州大學 大數據與信息工程學院,貴州 貴陽 550025)
?
說話人識別中語速魯棒性研究
朱紫陽,賀 松,彭亞雄
(貴州大學 大數據與信息工程學院,貴州 貴陽 550025)
如今,說話人識別技術已經比較成熟,但依然有很多因素影響說話人識別系統的穩定性。本文針對說話速度對說話人識別的影響進行了一系列的研究工作。通過模型空間分布可視化和語音頻譜觀察兩方面來分析不同語速語音的差距。然后,提出了最大似然線性回歸(MLLR)和Constraint MLLR(CMLLR)的方法對模型和特征進行變換,使訓練端和測試端的語音特征互相接近匹配。通過實驗發現,MLLR和CMLLR能較好地提高說話人識別系統中語速魯棒性。
說話人識別;語速魯棒;模型空間分布可視化;MLLR;CMLLR
1 不同語速對系統識別率的影響分析
訓練集和測試集的語音語速不同是否會對說話人識別系統魯棒性造成影響,造成的影響大不大,本節將分別從模型特征和語音頻譜方面對不同語速進行分析。這里把語速分為普通語速、快語速和慢語速三種。
1.1 語音特征分布具象化
說話人識別[1]是生物模式識別[2]的一種,是根據語音特征進行識別的方法。語音特征是按幀提取的,這些特征在音素空間上的分布就表征了一個人的語音信息。所以,通過音素空間的不同分布,可以描述人在語音上的不同。GMM-UBM模型[3]是用很多高斯混合來擬合特征的分布,每一個混合表示了一個特征聚類分布,而且這個混合的均值μ就表示特征分布的中心。因此,不同語速在特征上的區別對說話人區分造成的影響就可以用模型均值向量在空間上的偏移來表達。
在GMM-UBM系統中,三種語速都取同一個高斯混合(這里都取第二個混合),用t-sne非線性降維方法[4]將提取的混合的均值向量從高維降到二維平面,可以說是把模型對特征的描述能力壓縮,然后用python的畫圖模塊使語音特征分布具象化,如圖1所示。
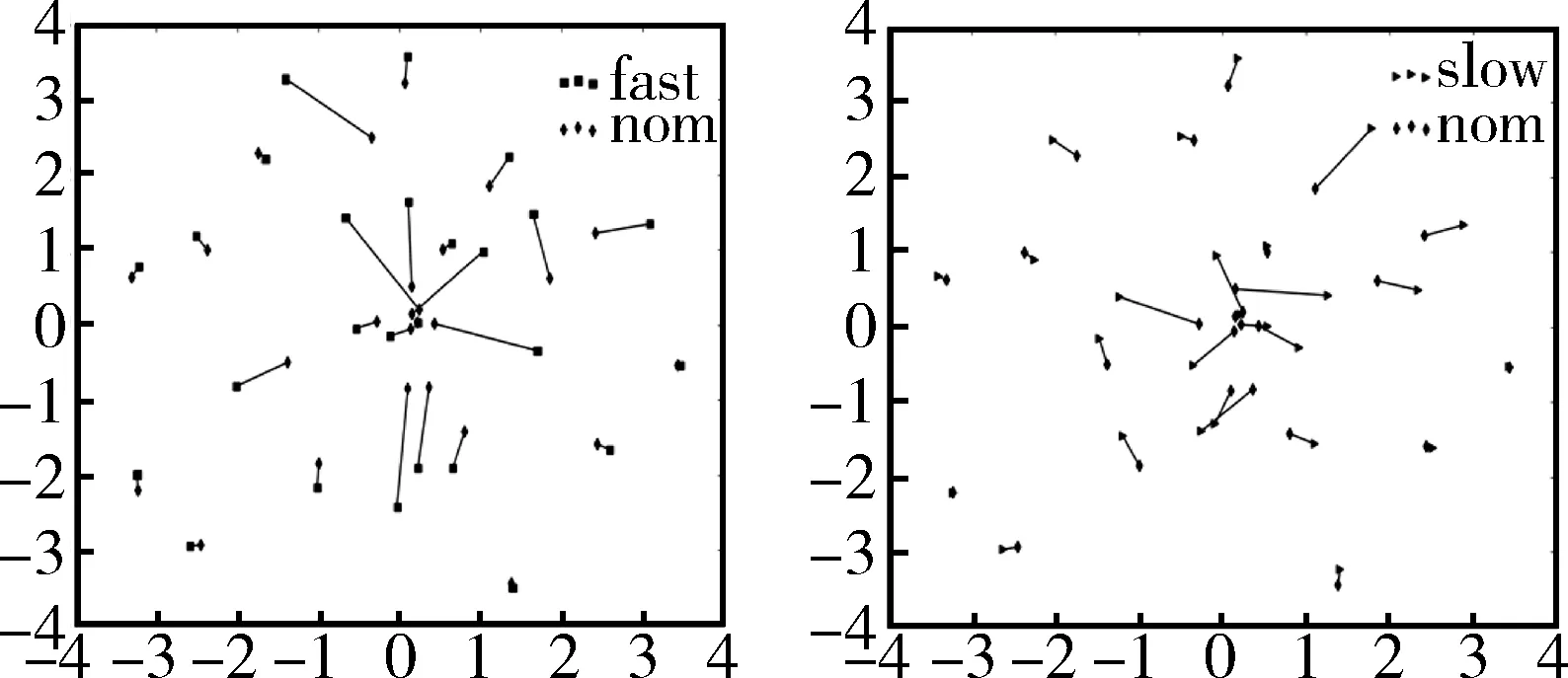
圖1 快語速(左)和慢語速(右)相對于普通語速的偏移
在圖1中,兩張子圖分別表示了快語速和慢語速相對普通語速的偏移。同一個人的不同語速模型由一根線條進行連接,這根線條的長短就表示了模型偏移的距離。從圖中可以看出,快、慢語速相對普通語速有著明顯的偏移。當然每個人偏移的距離各不相同,這是因為不同的人其語速的快慢程度也不同。總的來說,從圖中可以看出,語速對說話人識別系統有著很大的影響,這從后面實驗的baseline可以看出。
1.2 語音頻譜圖
上面的內容總體分析了不同語速下模型的偏移,很直觀地描述了語速對系統的影響。本節針對語音信號層面進行觀察和分析,尋找不同語速下語音信號發生的變化并總結規律。
選擇同一個人在不同語速下的同一個數字語音片段,將這三段語音用praat[5]進行頻譜繪制,結果如圖2所示。
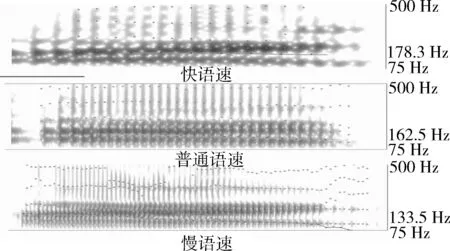
圖2 不同語速下同一個數字‘2’的頻譜圖
從圖2可以看出3個頻譜具有明顯的區別:
(1)圖中底部的橫線代表基頻(pitch),最右側中間數字則是計算出來的平均基頻。可以看出快語速的平均基頻要大于普通語速,而慢語速的平均基頻則小于普通語速。并且慢語速的基頻在句尾有明顯的下降趨勢。
(2)圖中分布點表示共振峰,可以看出相較于慢語速,普通語速和快語速的共振峰結構更加有規律,慢語速的共振峰結構相對比較混亂。
(3)慢語速的能量分布在低頻部分非常密集且在高頻部分也有明顯的能量分布。普通語速與快語速的能量基本都分布在低頻部分,并且普通語速在低頻段的能量分布相對于快語速要更加明顯一些。
這些差異性在其他的語速語音中也存在,所以此處假設語速對語音頻譜的影響是有一定的共同特點的。本文把3種不同的語速特征當做3個獨立的子空間來描述。
從頻譜圖中的區別可以看出,語速對語音頻譜帶來了明顯變化,可以認為快語速和慢語速攜帶了清晰的語速區分性信息,這些信息會混淆說話人的區分性信息。用普通語速訓練的模型覆蓋不了這些語速區分性信息,當測試語音中含有語速區分性信息時,必然造成匹配性變差,從而影響系統的識別性能。
2 語速的特征和模型轉換
2.1 語速的區分性信息
從上節得出一個假設,語速特征是一個獨立的子空間,并且和普通語速空間存在一定的對應關系。那么語速區分性信息實質上是兩個不同子空間的偏移。因此,可以通過一組語速依賴的線性變換來進行兩個特征空間的相互投影,以此來學習這種語速區分性信息。一般來說有兩種方案進行映射。
(1)把普通語速訓練的模型投影到兩種語速空間,讓其攜帶語速的區分性信息,提高模型對語速的表達能力。對于模型M(s,r)來說,其中s表示說話人,r表示語速,在訓練模型M(s,r)時,提出一種語速依賴的轉變方法,其定義如下:
M(s,r)=Lr(M(s))
其中,Lr是通過分離出的開發集的語速數據訓練出來的,所以與參加測試的說話人沒有關系。
(2)把攜帶語速區分性信息的測試語音特征經過映射后,變換到普通語速(中性)的空間,削弱這些特征中的語速區分性信息,相對地增強對說話人的區分性信息的描述能力。對于特征Xt(s,r)來說,t是特征的序號。訓練一個語速無關的變換,定義如下:
Xt(s,r)=Lf(Xt(S))
其中Lf和Lr一樣是一個與說話人無關的線性變換,且它們擁有同樣的訓練過程。本文選用MLLR方法實現語速特征空間的相互轉化,用一種簡單的線性模型來模擬語音中對語速區分性信息的分離及添加過程。
2.2 線性語速空間變換
MLLR[6-7]最早由劍橋語音小組提出,用來解決信道不匹配下的語音識別。這個方法可以用比較少的訓練數據學習出兩組數據之間共性特征的不同之處。通過MLLR可以減小兩組數據因共性特征不同所致的數據分布偏移。
在對模型進行變換時,用MLLR計算一組語速依賴的線性變換Lr,然后把普通語速的GMM-UBM說話人模型變換到語速依賴的模型M(s,r)上。這樣模型就可以引入語速的區分性信息,最終減小訓練語音和測試語音由于語速差距帶來的不匹配。在GMM-UBM模型中,最能體現說話人區分性的是各種混合中的均值向量,所以在對模型變換時只研究均值向量的變化,認為協方差矩陣不變。根據MLLR方法,可以得到:
(1)
其中,μr是指第r個高斯分量的均值向量,ξr是與μr相對應的擴展的均值向量。L是涉及偏移的三角矩陣,代表了語速的變換。然后用最大似然方法來優化L得到最終的偏移矩陣。
上面的方法中,只對模型的均值向量進行了更新,然而這并不全面,此處還要加上一定的約束條件,即實現模型均值和方差的同步更新,這就是Constraint MLLR(CMLLR)[8]方法。CMLLR方法認為說話人模型的均值和方差是用同樣的變換矩陣進行變換的,這樣的變換就等價于在特征空間對特征進行變換。本文就是把帶有語速區分性信息的特征投影到普通語速空間,以削弱特征中語速的信息。
2.3 語速空間的投影矩陣訓練
對模型進行變換的MLLR和對特征進行變換的CMLLR具有同樣的訓練過程,差別在于使用時,前一個用于變換訓練端的普通語速模型,后一個用于變換測試端的語速特征。訓練過程如圖3所示。

圖3 變換矩陣訓練過程
先從語音數據中提取出一部分語音作為開發集,用來訓練出語速空間投影矩陣的參數。開發集中的這些數據不參與最后的測試,并且把快慢兩種語速分開進行訓練,最后得到兩個變換矩陣。開發集中的普通語速語音為每個說話人訓練一個對應的模型,對于快慢兩種語速,基于得到的普通語速說話人模型,采用快慢語速特征來訓練兩個對應的線性變換矩陣。
在測試集上進行識別的過程中,一種是基于MLLR的模型投影方法,用訓練得到的變換矩陣將普通語速說話人模型和UBM模型投影到對應的語速空間上,使其帶上語速區分性信息,然后對帶語速區分性信息的測試語音進行識別。另一種是基于CMLLR的特征變換,把帶語速區分性信息的測試語音通過變換矩陣投影到普通語速空間,然后在普通語速的模型上進行識別。兩種不同方案如圖4所示。

圖4 變換矩陣的應用
3 實驗
實驗數據選用已經錄制好的語速數據庫,共30人,其中男女各15人,包含了3種語速,每種語速22句話,12句用來訓練說話人模型,10句用來測試識別。說話人識別系統基于經典的GMM-UBM模型設計。特征為13維MFCC特征加上其一階導數和二階導數共39維。同時用倒譜均值和方差歸一化方法來減少信道、背景噪音等造成的影響。
作為baseline,說話人以不同語速的語音直接在普通語速GMM-UBM模型上進行測試。由于要選出10人做開發集訓練線性變換矩陣,所以選取20個說話人進行全交叉測試,經過識別打分后,用EER來衡量系統的性能。
為了測試MLLR和CMLLR方法,用10人訓練變換矩陣。然后用變換矩陣對剩余20人的語音特征或模型進行變換,最后用變換后的模型或特征進行識別打分。
Baseline和MLLR/CMLLR方法的實驗結果如表1。

表1 baseline、MLLR和CMLLR實驗結果
實驗結果驗證了語速特征可以當成一個獨立子空間的假設,因此可以用線性模型去學習這種語速空間之間的偏移。從表1可以看出,快語速在MLLR方法上EER相對baseline下降了0.1%,在CMLLR方法上EER相對baseline下降了0.19%。慢語速在MLLR方法上EER相對下降了0.13%,在CMLLR方法上EER相對下降了0.21%。可見這種模型和特征的線性變換起到了比較大的作用。而且,CMLLR對系統性能的提高比MLLR更明顯。這是由于MLLR在引入語速區分性信息時也在一定程度上降低了說話人的區分性能力。
4 結束語
本文通過MLLR和CMLLR對語速特征及模型進行了線性變換,然后用變換所得的模型及特征進行識別打分,目的在于解決說話人識別中語速魯棒性問題。從實驗結果看出,MLLR/CMLLR對系統的魯棒性有很好的提高。但是,當有語速語音預留時,訓練模型的階段并沒有充分利用這些語速語音。因此,后面研究可以把語速語音經過投影矩陣變換后再和普通語速語音結合,以訓練出更具表述能力的模型。
[1] 吳朝暉,楊瑩春. 說話人識別模型與方法[M] . 北京:清華大學出版社,2009.
[2] 王雨晴,謝曉堯.基于生物模式識別的網絡身份認證研究[J] .微型機與應用,2014,33(18):42-44.
[3] 熊振宇.大規模、開集、文本無關說話人辨認研究[D] . 北京:清華大學,2005.
[4] MAATEN L V D,HINTON G. Visualizing data using t-SNE[J]. Journal of Machine Learning Research , 2008(9): 2579-2605.
[5] 葉志騰.應用Praat軟件分析成人嗓音聲學參數[D] . 福州:福建醫科大學,2009.
[6] LEGGETTER C J,WOODLANG P C. Maximum likelihood linear regression for speaker adaptation of continuous density hidden Markov models[J]. Computer Speech & Language, 1995(9): 171-185.
[7] STOLCKE A,KAJAREKAR S S,FERRER L,et al. Speaker recognition with session variability normaliization based on MLLR adaptation transforms[J]. Audio, Speech, and Language Processing, IEEE Transactions on. 2007, 15(7): 1987-1998.
[8] 別凡虎.說話人識別中區分性問題的研究[D]. 北京:清華大學,2015.
Research on speaking rate robustness in speaker recognition
Zhu Ziyang, He Song, Peng Yaxiong
(Big Data and Information Engineering Institute, Guizhou University, Guiyang 550025, China)
Recently, speaker recognition has been matured, but there are still so many factors impact the sability of speaker recognition system.This paper mainly researches the influence of speaking rate on speaker recognition. Through making distribution of model space visualization and observing the print of frequency spectrum to analyse gap of the different speed voice. Then, we propose the method of Maximum Likelihood Leaner Regression (MLLR) and Constraint Maximum Likelihood Leaner Regression (CMLLR) to transform the model and feature. It is aimed at making training and testing mutual match. Through the experiment, we find that the MLLR and CMLLR can improve the robustness in speaker recognition with different speaking rate.
speaker recognition; speaking rate robustness; model space visualization; MLLR; CMLLR
TN 912.34
A
1674-7720(2016)07- 0054- 03
朱紫陽,賀松,彭亞雄.說話人識別中語速魯棒性研究[J].微型機與應用,2016,35(7):54-56.
2015-12-01)
朱紫陽(1990-),男,碩士研究生,主要研究方向:語音識別、說話人識別。
賀松(1974-),通信作者,男,碩士,副教授,主要研究方向:信號處理。E-mail:814919860@qq.com。
彭亞雄(1963-),男,副教授,主要研究方向:信號處理。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
光學精密工程(2016年6期)2016-11-07 09:07:19
中外會展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:19:15
