基于端系統應用的分組I/O加速技術*
2016-12-23 07:26:03李世星龍永新劉三毛
網絡安全與數據管理 2016年7期
關鍵詞:分配
李世星,楊 惠,龍永新,劉三毛
(1.湖南工業大學 計算機與通信學院,湖南 株洲 412000;2.國防科學技術大學 計算機學院,湖南 長沙 410073)
?
基于端系統應用的分組I/O加速技術*
李世星1,楊 惠2,龍永新1,劉三毛1
(1.湖南工業大學 計算機與通信學院,湖南 株洲 412000;2.國防科學技術大學 計算機學院,湖南 長沙 410073)
在網絡系統中,優化端系統的數據路徑能夠使數據在網絡接口和應用程序之間快速移動。因此,研究基于端系統應用的分組I/O加速技術,對分組I/O的發送和接收路徑分別優化,有助于提高數據移動效率,減少CPU停滯,實現內存并行處理。本文提出分組I/O接收端流親和技術, 分組I/O發送端鏈式發送技術。基于通用多核處理器和FPGA搭建端系統實驗環境,并對分組I/O加速后的端系統進行性能測試,實驗結果表明,采用分組I/O加速技術的端系統,能夠使報文收發性能提升2.14倍。
端系統;多核;數據路徑;FPGA
0 引言
包含多核處理器的端系統,隨著多核處理器處理性能的不斷提升,運行的應用越來越復雜[1]。然而擁有多核、高速處理能力的端系統,并沒有對數據的接收與發送路徑進行優化,端系統接收數據包、發送數據包占據大量的處理時間,數據吞吐率成為制約端系統性能的瓶頸。Intel[2]指出當前多核處理器設計時并未考慮到網絡處理中分組I/O的問題,在獲得了高效網絡處理性能的同時,也伴隨著分組I/O帶來的處理時間長和網卡設計復雜的問題。為了降低網絡應用帶來的I/O開銷,本文提出了基于端系統的分組I/O加速技術。其主要思想是接收數據路徑實現流親和技術,發送數據路徑實現鏈式發送技術。
1 相關研究
針對多核網絡分組處理系統的分組I/O開銷大的問題,Intel為通用多核處理平臺提出了數據平面開發工具套件DPDK[2],為高速網絡設計了一套數據平面庫,提供了統一的處理器軟件編程模式,從而幫助應用程序有效地接收和發送數據,提高分組I/O性能。Packetshader則采用大報文緩沖區的方式[3],靜態地預分配兩個大的緩沖區(SKB控制信息緩沖區和分組數據緩沖區),通過連續存儲每個接收分組的SKB控制信息和分組數據,避免緩沖區申請、釋放以及描述符的轉換操作,有效降低分組I/O開銷和訪存開銷。Netmap[4]通過預分配固定大小緩沖區,采用批處理和并行數據路徑的方法,實現了內存映射,存儲信息結構簡單高效,能夠實現報文的高速轉發。DCA通過處理器硬件支持,將接收網絡分組直接寫入LLC cache,減小CPU訪問分組描述符的延時[5]。而PFQ[6]接收的報文不需要通過標準協議棧處理,直接送入批處理隊列進行批處理。現有研究采用內存映射的零拷貝技術,只能解決拷貝的開銷,不能解決報文緩沖區分配和釋放開銷。
2 分組I/O接收端流親和技術
流親和技術通過構造和維護多個動態鏈表,對端系統應用中報文數據進行處理、傳輸,并以DMA方式寫入內存。
2.1 分組I/O接收端流親和加速模型
本文采取接收報文緩沖區流親和加速模型。將緩沖區描述符分配、回收交由硬件處理,以實現報文零中斷處理。為每一個線程分配一個存儲區鏈表,減少上下文切換開銷,減少線程亂序存儲造成的TLB表頻繁缺失。報文緩沖區描述符管理機制、DMA接收機制將對本文提出的流親和技術具體實現做出詳細說明。
2.1.1 流親和報文緩沖區描述符管理機制
以多核處理器提供線程數是m為例。如圖1所示,先由軟件初始化數據至m個緩沖區塊描述符FIFO,每個內核緩沖區內地址連續,地址大小相等,地址塊大小相等。每個塊地址包含k個地址。在每一個內核緩沖區內通過塊描述符FIFO和偏移計數器分配地址。
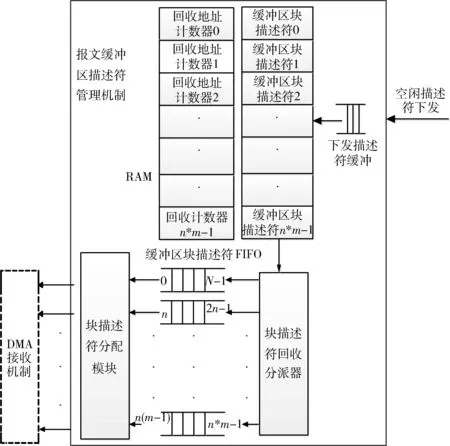
圖1 報文緩沖區描述符管理機制結構示意圖
描述符初始化流程:系統驅動給每個內核緩沖區塊描述符FIFO分配描述符塊地址。每個內核緩沖區分配n個塊地址,內核緩沖區的個數等于CPU提供的線程數m。并給釋放計數器RAM和緩沖區塊描述符RAM中的值都賦0。
描述符回收流程:當空閑描述符下發時,取塊索引號,讀緩沖區塊地址RAM和回收地址計數RAM,當回收地址計數RAM的值為塊地址可存放地址數量的最大值時,回收該塊地址并將計數表的值賦0,否則將計數表的值加1。
描述符分配流程:為m個內核緩沖區實例化m個塊描述符分配模塊。在每個塊描述符分配模塊中,當分配地址偏移計數器的值為k時,從緩沖區塊描述符FIFO中重新取一個塊地址送至塊描述符分配模塊。否則將當前地址寄存器中的地址加1后發送至分配地址緩沖區。m個塊描述符分配模塊可以同時分配地址。
2.1.2 DMA接收機制
接收到下行部件報文時,如圖2所示,根據報文頭部線程號信息獲取地址,如線程號為1,則從1號當前描述符SRAM中取出當前地址,并從1號待分配報文描述符FIFO中取出下一跳地址。將接收的報文與描述符(包括當前地址、下一跳地址)合并,傳送至共享緩沖區。傳輸完成時會保留該線程尾的下一跳地址。下一個報文到達時,將下一跳地址更新為當前地址,通過下一跳地址輪詢處理下一個報文。
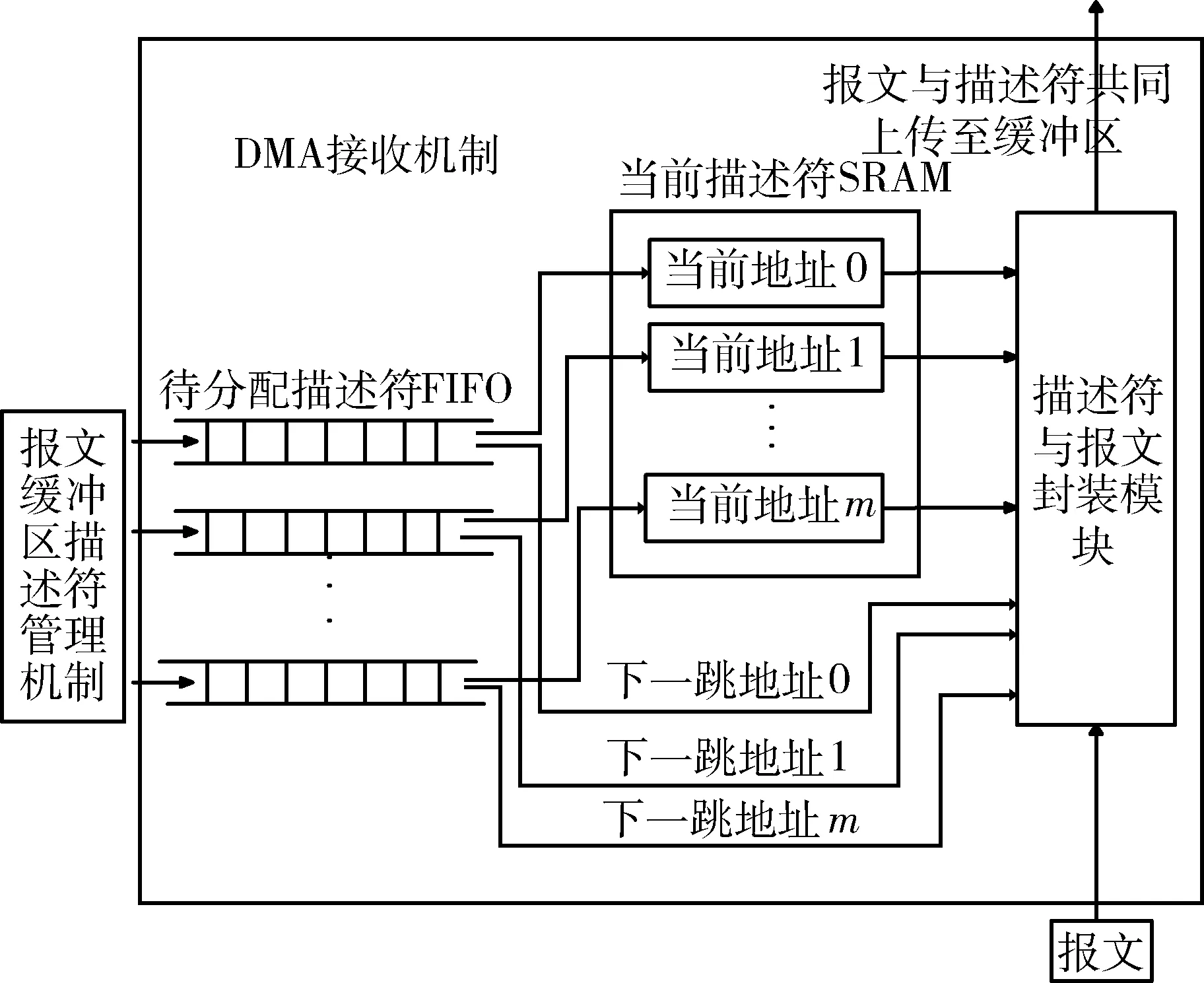
圖2 DMA接收機制結構示意圖
2.2 分組I/O接收端流親和技術數據通路流程偽代碼
(1)初始化
begin
系統驅動將描述符信息寫入m個塊描述符隊列中,將塊地址索引號寫到描述符RAM中,回收地址計數器都置0;
end
(2)從端接收報文到主機流程
begin
if (收到下行部件報文&&待分配報文描述符FIFO不為空)
begin
取出當前地址RAM中的地址作為當前地址,取出待分配描述符FIFO中的地址作為下一跳地址,封裝后上傳;
end
else return;
end
(3)描述符回收流程
begin
if (有空閑描述符下發)
begin
回收塊地址的計數器置0;
清除對應描述符RAM中的地址;
end
else begin
回收塊地址計數器累加;
end
end
3 分組I/O發送端鏈式發送技術
在實現操作系統指定的任意存儲區域報文鏈式發送中,鏈式發送指的是一次DMA讀,讀出一塊描述符,不再是每次DMA讀,讀出一個描述符。這樣可以減少多次DMA讀的開銷,提高發送效率。

圖3 分組I/O發送端數據通路加速結構圖
3.1 分組I/O鏈式發送技術數據通路加速模型
本文提出的每次DMA讀,讀出一塊描述符,讀出的描述符可能大于四拍。這種情況下無法和TCP/IP數據報文區分。本文采取的方法是每次發送DMA讀請求時,寫一個標識存入FIFO,在讀出數據時,同時讀出該FIFO的值,區分是描述塊還是TCP/IP報文,實現鏈式發送。
鏈式發送的實現步驟如下:(1)系統驅動將攜帶21位或者28位DMA地址的描述符,以PCIE寫寄存器的方式寫入FPGA內部邏輯。其中,攜帶21位地址的描述符用于流親和機制中回收基地址,攜帶28位地址的描述符用于構造DMA讀請求,每次DMA讀請求,讀出多個攜帶64位地址的描述符。(2)構造21位、28位、64位DMA地址TLP報文讀請求,每構造一次DMA讀請求往FIFO中寫一次標識。(3)解析、定序PCIE核下發的TLP報文。(4)讀取標識FIFO,區分描述符和數據報文。數據報文直接下發至網絡接口,描述符則將其緩存,再構造TLP報文內存讀請求。分組I/O鏈式發送技術數據通路加速模型如圖3所示。以下將介紹鏈式發送的四個機制。3.1.1 PCIE接收機制
PCIE接收機制為PCIE 應用層I/O部分,將送往系統驅動的數據解析并轉換成相應格式的TLP報文,構造TLP報文讀請求。
3.1.2 PCIE發送機制
PCIE發送機制為PCIE 應用層I/O部分,將從內存讀出的數據解析并轉換成規定格式的報文。
3.1.3 DMA轉發機制
接收PCIE發送機制報文,根據控制位(Ctrl)判斷是描述符還是普通報文。普通報文直接轉發給下行模塊,描述符則轉發給描述符管理機制進行處理。
3.1.4 DMA描述符管理機制
按照信仰觀念和儀式這兩個層面來研究各地的廟會或者叫地方保護神的祭祀民俗,先將它們分開來進行描述,然后再合并為一個事象給予議論,這種做法在以往的博碩士學位論文里經常出現。比如我們研究泰山廟會信仰時,我們可能會先寫關于泰山奶奶是怎么回事兒,與古老的西王母有沒有什么關系,與碧霞元君等其他女神有什么關系,等等。這種考證性研究可能存在著問題,因為對于一般老百姓來說,他們可能并不關心這些神祇之間有沒有關系,他們關心的是我今天來求神,神祇對我來說到底靈驗不靈驗。
描述符管理機制為鏈表回收部分,系統驅動以寫寄存器的方式,寫描述符至DMA描述符管理機制。回收21位DMA地址,其他描述符形成特定格式,轉發至PCIE接收機制進行處理。
3.2 分組I/O鏈式發送數據通路流程偽代碼
begin
if(報文發送描述符緩沖不為空)
begin
將描述符控制塊的28位地址、長度以及控制信息(共128位),以寫寄存器的方式寫入發送引擎中,不回收該描述符;
end
if(根據控制信息判斷發送描述符對應報文為普通報文)
begin
end
else begin
計數器累加并判斷;
構造21位或者28位DMA讀請求;
end
if(Completion報文返回)
begin
判別為普通數據,則轉發至網絡接口;
end
else
begin
構造成64位DMA讀請求;
end
else return;
end
4 性能評估
為有效驗證基于端系統應用的分組I/O加速技術的性能,實驗原型基于國產的高性能通用64位CPU與可編程FPGA實現,分組I/O加速的核心部件在FPGA器件上實現,FPGA型號采用Stratix IV EP4SGX230KF40C2。Ixia網絡測試儀連續發送大小為64 B的報文。由一個萬兆端口接收和發送報文,端系統配置為單線程、雙線程、四線程、八線程四種模式。測試結果如圖4所示,可以看出支持流親和和鏈式發送后,64 B報文吞吐率有明顯的提升,性能最高提升2.14倍。
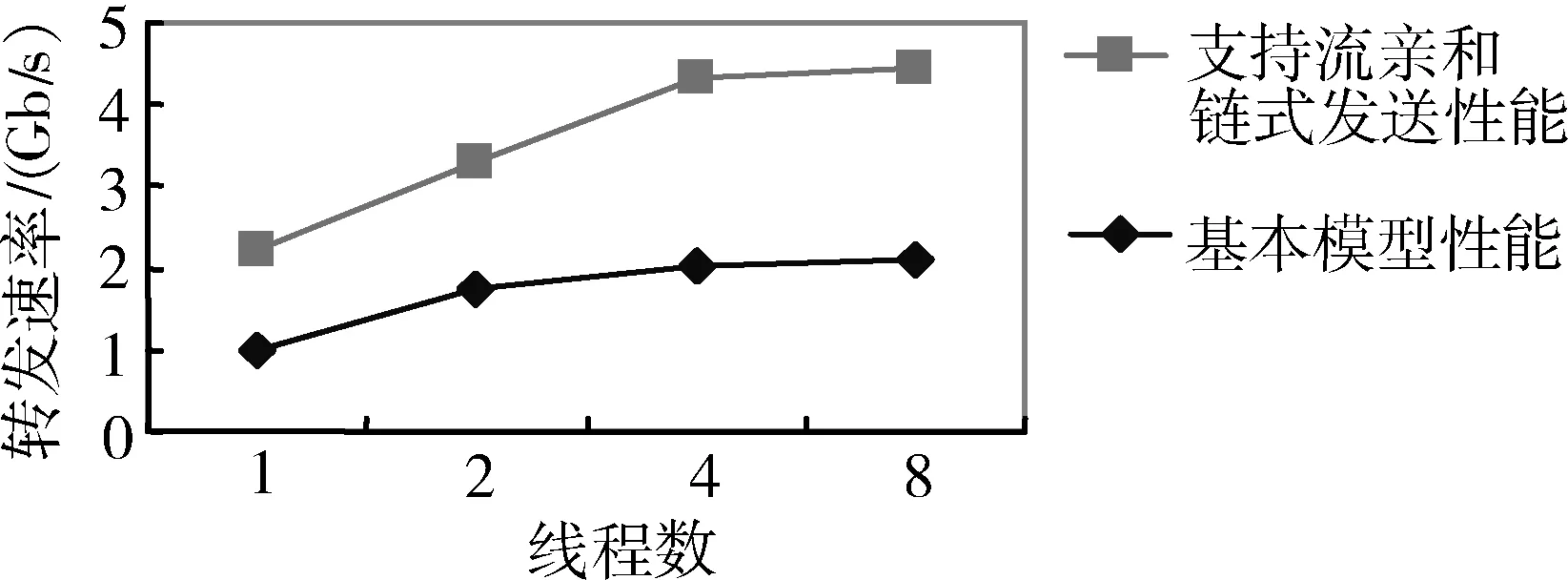
圖4 性能加速比對圖
5 結束語
為了優化端系統數據路徑,使得數據在網絡接口和應用程序之間快速移動,降低分組I/O開銷,本文基于多核處理器和FPGA平臺實現端系統,提出了分組I/O接收端流親和與發送端鏈式發送兩種技術。實驗結果顯示,經由
分組I/O加速后,端系統對于報文吞吐率有明顯的提升,性能最高提升2.14倍。
[1] HAN S, JANG K, PARK K S, et al. PacketShader: a GPU-accelerated software router[C]. ACM SIGCOMM Computer Communication Review,2010:195-206.
[2] Intel. High-performance multi-core networking software design options[R/OL]. [2016-01-06]www.intel.com.
[3] GARC′LA-DORADO J L, MATA F, RAMOS J, et al. High-performance network traffic processing systems using commodity hardware[C]. Data Traffic Monitoring and Analysis, LNCS 7754, 2013: 3-27.
[4] RIZZO L. Netmap: a novel framework for fast packet I/O[C]. In 2012 USENIX Annual Technical Conference, 2012: 2-12.
[5] RIZZO L, Deri L, CARDIGLIANO A. 10 Gbit/s line rate packet processing using commodity hardware: survey and new proposals[EB/OL].[2016-01-06] http://luca.ntop.org/10g.pdf.
[6] BONELLI N, PIETRO A D, GIORDANOS S, et al. On multi-gigabit packet capturing with multi-core commodity hardware[C]. N. Taft and F. Ricciato (Eds.), PAM 2012, LNCS 7192, 2012: 64-73.
Packet I/O acceleration technology based on terminal system application
Li Shixing1,Yang Hui2,Long Yongxing1,Liu Sanmao1
(1.School of Computer and Communication, Hunan University of Technology, Zhuzhou 412000, China;2.School of Computer, National University of Defense Technology, Changsha,410073, China)
In network system, studying on acceleration technology based on packet I/O for terminal system application, optimizing the transfer data paths of packet I/O, will improve the data transfer rate between network interface and program space of user application, reduce the CPU stall and realize high efficient parallel processing. In this paper, we use streaming affinity technology for the packet I/O receiver, and use the chain transmission technology in the packet I/O sender. We develop a common platform with multicore processor and FPGA for terminal system, and make some experiments on sending and receiving packet performance with packet I/O acceleration technology. The experimental results show that the proposed scheme can achieve to 2.14x packet throughput.
terminal system; multicore; data path; FPGA
國家自然科學基金(61170102)
TP393.0
A
1674-7720(2016)07- 0063- 04
李世星,楊惠,龍永新,等. 基于端系統應用的分組I/O加速技術[J].微型機與應用,2016,35(7):63-66.
2016-01-06)
李世星(1990-),男,碩士研究生,主要研究方向:高性能網絡體系和高性能網絡設備研制。
楊惠(1987-),女,博士,助理研究員,主要研究方向:高性能網絡體系和高性能網絡設備研制。
龍永新(1966-),男,副研究員,主要研究方向:信號處理。
猜你喜歡
天水行政學院學報(2022年4期)2022-11-18 09:02:36
艦船科學技術(2022年13期)2022-08-11 09:30:02
鐵道通信信號(2020年9期)2020-02-06 09:15:22
漢語世界(The World of Chinese)(2019年3期)2019-07-01 02:37:48
數學大王·趣味邏輯(2019年5期)2019-06-13 20:27:43
小學科學(學生版)(2019年5期)2019-05-21 01:00:18
中學生數理化·中考版(2018年10期)2018-12-07 00:44:52
經濟技術協作信息(2018年30期)2018-11-22 06:20:24
中央社會主義學院學報(2017年1期)2017-04-16 05:34:07
中國衛生(2014年12期)2014-11-12 13:12:40
