一種面向CASA的分布式數據存儲策略
2016-12-26 08:40:06過匯卿樂嘉錦
計算機應用與軟件 2016年11期
過匯卿 王 梅 樂嘉錦
(東華大學計算機科學與技術學院 上海 201620)
?
一種面向CASA的分布式數據存儲策略
過匯卿 王 梅 樂嘉錦
(東華大學計算機科學與技術學院 上海 201620)
隨著天文設備的進步發展,對海量天文數據處理形成了新的挑戰。為使當前主流的天文數據分析軟件可以有效處理海量數據,提出一種適用于射電天文處理上層應用的分布式數據存儲策略DDSS(Distributed Data Storage Strategy)。首先,設計分布式數據存儲策略的系統框架。其次,設計混合分片列式存儲方法,在保留列存儲查詢優勢的同時提升了數據導入的速度。進一步,通過維護基于相對位置映射的元數據來快速讀取包含大量數據的天文陣列數據,顯著地提升了天文處理應用底層數據讀寫的吞吐量。最后,通過實驗證明了該方法的有效性。
分布式 天文 陣列數據
0 引 言
伴隨著信息爆炸,大數據時代已經走入各行各業,在諸如天文學、物理學、社會科學等行業中正源源不斷的產生真正的海量大數據。然而,這些行業在解決大數據所帶來數據讀寫與處理緩慢問題的方法卻滯后于其數據產生的速度。在射電天文領域,隨著射電望遠鏡設備的飛躍發展,望遠鏡所能觀測和產生的數據量早已超出了當前主流的天文學數據處理軟件的承載能力。為此,急需將計算機數據處理的前沿技術如列存儲、分布式等應用到當前成熟的處理軟件中,以應對海量天文數據所帶來的挑戰和沖擊。
射電天文領域中,天文學家主要采用的數據處理軟件有AIPS,AIPS++以及CASA等。其中,CASA[1]是當前主流的射電天文數據處理和分析軟件。它由AIPS++發展而來,提供基于二維表的數據模型來處理和分析射電天文數據。CASA通過調用casacore[2]庫中封裝的原AIPS++處理程序,實現各種數據分析和處理。然而,由于casacore底層實現的限制,只可以單節點串行地處理數據,這使得CASA需要極高的單點硬件性能。并且由于其不具備擴展性,難以應對大數據流量下高效的數據讀寫需求。
另一方面,正如大部分科學數據,射電天文數據包含大量的陣列數據,近年來,針對以陣列(Array)為主要數據形式的科學數據庫也得到了廣泛的研究。如基于傳統關系模型的陣列數據庫SciDB[3,4]以及基于Hadoop的數據庫SciHadoop[5,6]等。SciDB是一個針對科學數據的分布式數據庫,其數據模型是基于多維的陣列,這樣就打破了傳統數據庫固定表結構的限制,使其具備了對陣列進行的操作運算的功能。SciHadoop將科學家輸入的基于陣列數據模型的邏輯查詢語句轉化為map/reduce程序進行執行。上述研究均對陣列數據的分布式存儲和查詢進行了研究,然而其并非針對射電天文數據處理,因此其查詢難以滿足天文領域對陣列數據的眾多運算。若使用其提供的上層接口與天文軟件對接,由于接口調用使得數據吞吐率低,影響了性能。
針對上述問題,本文提出了面向海量天文數據處理,適用于射電天文學數據分析軟件CASA的分布式數據存儲策略DDSS。DDSS通過重寫CASA底層的文件存儲管理模塊,在不修改任何上層應用接口的情況下解決了其只支持集中式、串行的數據讀寫機制,實現了并行化讀寫數據和分布式存儲數據。DDSS首先根據陣列數據類型與普通數據類型混合的特點,采用了行列混合分片的方法,分片時保證每個數據片段大小均勻,在不影響寫入效率的同時保留了其讀取某一屬性的高效性。進一步,在寫數據的同時,維護基于數據相對位置映射的元數據文件,以提高陣列數據讀取時的效率。實驗測評表明,所提策略在寫數據與讀數據的吞吐量都有了顯著的提高,其數據寫入性能提升了6.8倍,數據讀取性能提升了3.4倍。同時也驗證了陣列數據的大小并不會影響系統的性能,系統具有較好的可擴展性。
1 CASA簡介
CASA是一個融合了射電天文數據圖形化、數據分析、數據處理等功能的綜合軟件包,其內部的數據格式以CASA TABLE的二維表形式存在[7]。其按屬性可以分為三種,分別是ArrayColumn(AC)、IndexColumn(IC)和ScalarColumn(SC)。ArrayColumn存放各種數據類型的陣列數據,IndexColumn和ScalarColumn存放普通類型的數據,類似傳統數據庫中的屬性。在CASA TABLE中,大量的表數據往往集中在ArrayColumn中。如表1所示,表1為一張5列10 000行的CASA TABLE。其中前4列分別為int、int、float和double類型的普通數據,第五列為4×5的int型陣列數據。雖然ArrayColumn只有一列,但可計算出其占全表大小的80%。
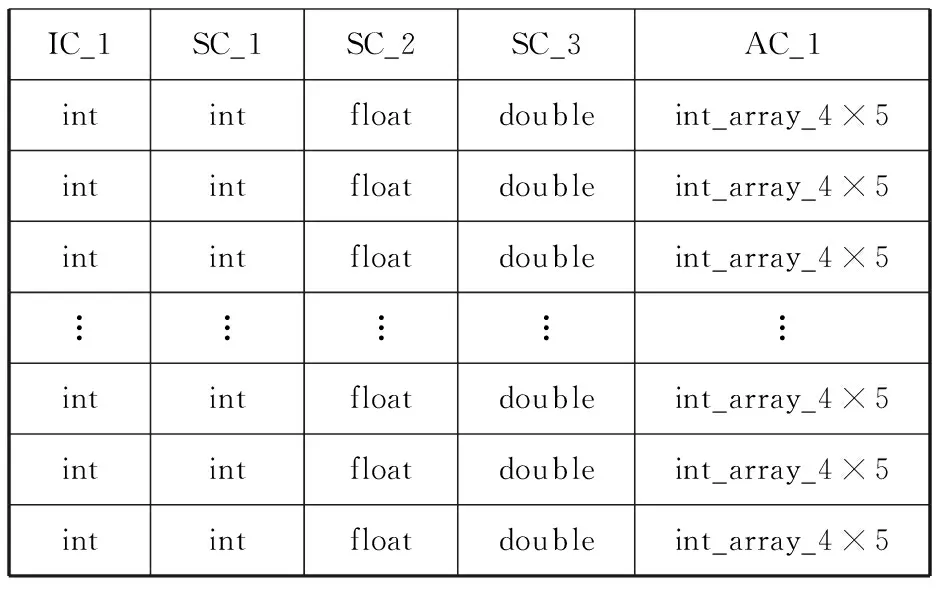
表1 CASA TABLE示例表
CASA提供了底層數據存儲類StorageManager,使得其可以被二次開發來替換原始的數據讀寫方式,從而進行I/O優化。StorageManager是CASA核心庫即casacore中負責數據讀寫的模塊,其決定了數據的存儲方式、位置、元數據信息等。目前,CASA中調用的StorageManager只支持集中式環境下串行的數據I/O,導致了I/O效率低下、無法擴展、硬件要求高等問題,已經難以滿足當前海量射電天文數據的處理需求。
2 系統框架
為了無縫支持CASA系統,DDSS結合CASA環境編寫而成,其與CASA以及casacore庫的整體結構與數據流入流出過程如圖1所示。圖1中虛線框中即為的主要模塊,包括數據劃分模塊、數據分配模塊、重寫后的CASA存儲管理(DDSS_StMan)模塊和數據流出的接口。系統的工作流程為:數據先經過劃分,經數據分配模塊分配到各個節點,各個節點的存儲管理器DDSS_StMan負責數據的寫入和讀出。
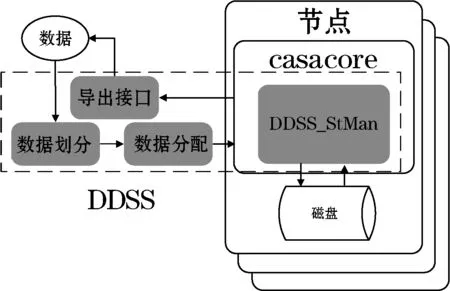
圖1 DDSS框架圖
形式化描述如下:
定義1CASA TABLE形式的數據集D={F1,F2,…,F|D|}。其中,Fi表示按照數據分片策略stfrag得到的數據片段,F1,F2,…,F|D|應滿足F1∪F2∪…∪F|D|=D且Fi1∩Fi2=φ(i1≠i2,0≤i1,i2≤|D|)。
定義2節點集N={N1,N2,…,N|N|}。
其中,Nk表示系統中第k個存儲節點。數據集D依照數據分配策略stallo分配到各個節點,每個節點Nk所得到的數據D_Nk可以表示為D_Nk=stallo(stfrag(D),N)。當上層需要數據時,各個節點同時通過存儲管理器(DDSS_StMan)模塊從磁盤中取出數據,轉換成CASA TABLE的格式,完成過濾后流入導出接口。上層CASA應用可以直接調用各節點接口中的數據,完成其所需要的操作。
DDSS面向的是海量實時流入的CASA TABLE數據(如圖1所示),因此無論是數據劃分還是數據存儲管理都必須考慮到以下問題:1) 數據對象是CASA TABLE,該數據以陣列類型數據為主,同時也包含普通數據類型;2) 盡可能提高并行執行度,來提供數據讀寫的效率。為此,本文將進一步詳細介紹數據劃分模塊及重寫后的CASA存儲管理模塊。而數據分配模塊主要采用一致性哈希算法[8,9]完成數據分配[10],在此不再贅述。
3 混合分片列式存儲策略
在CASA TABLE中,由于大部分數據量傾斜在ArrayColumn中,ArrayColumn往往會是所關注的焦點,在大量實際應用中,都需要對ArrayColumn中的陣列數據進行讀取,此時列存儲是十分適合這類場景的。然而,若采用直接的列存儲,將數據垂直劃分后用多進程分別寫入不同列的方法,會使得某個進程需要寫入大量的數據,而其他所有進程寫入少量的數據,造成并行效率低的問題。因此,本文采用混合分片列式存儲策略。
混合分片列式存儲[11]是指在滿足定義1的前提下將數據集D先進行水平劃分,再進行垂直劃分。其與行列混合存儲的不同之處在于垂直劃分后的數據片段F1,F2,…,F|D|分別根據屬性名的不同,存于不同的文件之中。這樣既解決了列存儲在寫入效率的不足,同時卻保持了列存儲的形式,可以發揮列存儲在讀取某單一屬性如CASA TABLE中實際數據存放的ArrayColumn列效率高的優勢。如圖2所示,Table為一張8行三列的CASA TABLE,以三行為一個水平劃分,按此劃分通過下文的分配策略分配到每個節點,然后以列為單位,寫進程分別將數據寫入對應列名的文件中如tableIC_1、tableSC_1和AC_1中,從而實現了列存儲。在分布式環境下,數據片段Fi根據分配策略stallo分配到滿足定義2的節點集N。相同屬性的數據片段Fi會
在各個節點被寫入相同路徑的文件中。當數據不斷增加,以追加的方式的到來時,新的數據也會以追加的方式寫入同一列名的文件夾中。
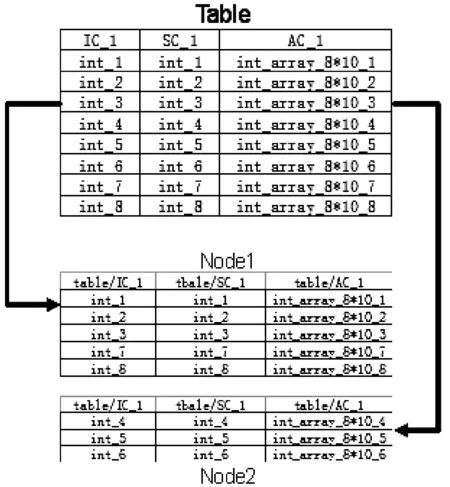
圖2 數據表分片圖
在進行數據分析,讀取磁盤數據時,雖然每個節點儲存列文件中的不同分片數據并不連續,但是單個分片內的數據是以順序的方式存儲中的。通常CASA TABLE中的數據會以時間或者天線頻道排序,這樣當天文學家需要某個時間段或者某個頻道的陣列數據時,就只需要在某一個節點讀取數據,節省了多節點元組重構和通信的網絡開銷。
4 數據存儲管理器——DDSS_StMan
DDSS_StMan是DDSS中負責數據讀寫和管理的模塊。由于casacore中原有的存儲管理器(StorageManager)并不支持分布式環境。DDSS_StMan重寫了StorageManager使其支持分布式與并行的環境,并且使用基于相對位置映射的元數據,加快陣列數據讀取的速度。
4.1 支持分布式環境的DDSS_StMan
casacore中原有的存儲管理器在設計時數據讀寫是單進程、串行處理的。同時,由于casacore庫中全局的元數據文件以表為單位來創建,但在分布式環境下,我們對數據表進行劃分,但casacore中的元數據信息卻并不支持因數據表劃分而再次劃分元數據文件,這便在寫數據時造成了元數據文件沖突。在DDSS _StMan為了支持分布式環境,在數據讀寫時提供了支持多進程的接口,并記錄了各個節點數據的全局信息。于此同時其數據讀寫不再依靠casacore中所使用的元數據信息,以避免在分布式環境中所造成的各種元數據信息錯誤。當寫入數據時,每個進程得到其劃分后的數據之后,開始寫入數據,并記錄相關信息,完成基于相對位置映射的元數據。當讀取數據時,不再從casacore庫中所使用的元數據信息來尋找數據,而是通過之前維護的相對位置映射元數據來完成數據尋址,進行數據讀取。
4.2 基于相對位置映射的元數據
在節點接收數據的水平分片后,將其垂直劃分,根據之前的分配算法用相應的進程寫入磁盤。在應用壞境中,進程需要讀取ArrayColumn中的某一行或某幾行。在列存儲中,讀取節點上單獨列所有內容,是非常便捷的,但是當進行選擇性讀取的時候,往往需要從頭遍歷該列的數據文件,從而產生巨大的開銷。傳統的索引技術并不適用與陣列數據,而一些基于陣列數據的索引大多針對某一陣列內部數據。因此,本文提出了一種在寫入陣列數據的同時,維護該列陣列各陣列相對位置的元數據信息,來快速定位該陣列在文件中的位置。如圖3所示。每個ArrayColumn的陣列數據文件都會有一個對應的元數據文件,元數據文件中的指針與陣列數據文件中的陣列一一對應。當得到元數據文件中指針的位置時,便可以將位置信息映射到陣列數據文件中,再通過位置信息直接讀取需要的陣列。DDSS中,使用行號作為元組重構的鍵值,元數據文件中也會記錄相應的行號信息。
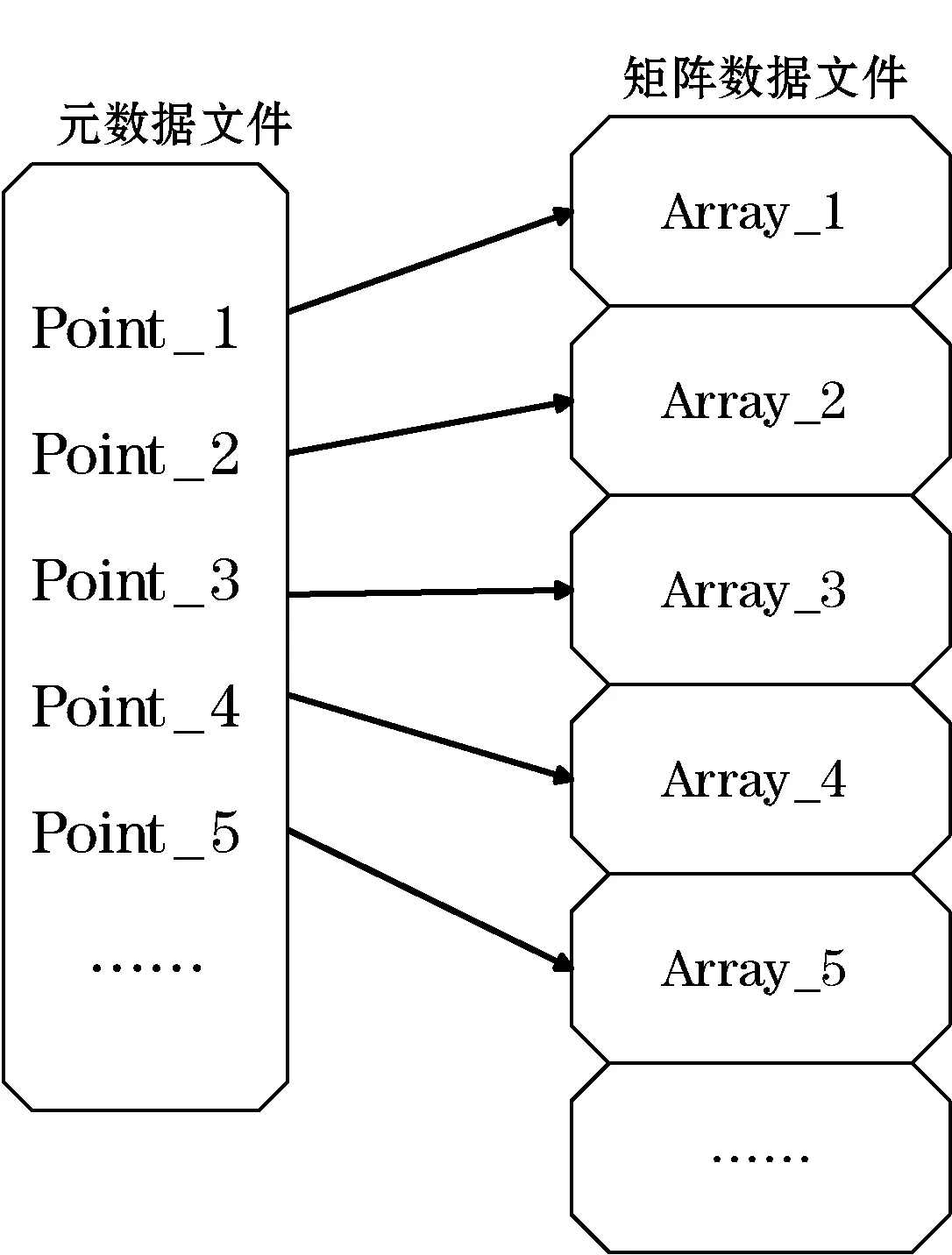
圖3 指針與數據的相對位置映射圖
實現上述的功能需要重寫CASA存儲管理器,尤其是修改其中的put與get函數。在put函數中需要添加寫元數據文件的功能,而在get函數中需要先讀取元數據文件,確認所需數據的實際地址映射。再根據映射關系map函數來確定實際數據的儲存位置。最后,讀取相應的陣列數據文件中所需要的陣列數據。
4.3 相對位置映射方法設計
ArrayColumn以列存儲的方式,用字節流寫入磁盤之中,設每個陣列大小為SA字節,總共寫入k行,即k個陣列。同時,在元數據文件中寫入指針,指針大小遠遠小于陣列大小,設指針大小為SP字節總共寫入k行,即k個指針,其中SP< (1) 通過P_Pos的值,可以推導出對應陣列在陣列文件中的起始字節位置P_SB: P_PS=P_Pos×SA×k (2) 得到陣列起始位置P_SB后,在讀取陣列文件時,使用lseek(filename,P_SB)函數直接從該陣列所在的位置讀取SA個字節即可。 令式(1)與式(2)的計算函數為P_SB=Map(pki),基于運用基于位置映射的元數據來選取陣列數據的算法如下: 算法1:FindArray(int Row_id) 輸入:元組重構的行號。 輸出:該元組的陣列。 1readbuffer_meta[n];2readbuffer_array[m];3read(metadata,readbuffer_meta);4while(readbuffer_meta[i]!=NULL)5 if(Row_id==readbuffer_meta[i])6 pki==I;7 break;8 i++;9P_SB=Map(pki);10lseek(ArrayData,P_SB);11read(ArrayData,readbuffer_array);12returnreadbuffer_array; 該方法在傳統的數據庫中針對傳統數據并沒有任何效果,反而可能會影響讀取效率,然而針對CASA TABLE中的ArrayColumn卻非常適合。因為CASA TABLE中絕大部分數據量傾斜在ArrayColumn中,ArrayColumn中的一個陣列所占的存儲空間往往可以達到MB級別。而元數據文件的總大小往往只有KB級別。在實驗中發現,一個1 GB左右大小的數據文件所對應的元數據文件約為5 KB。鑒于這種情況,全掃描元數據文件所帶來的開銷幾乎可以忽略不計,但卻可以快速定位陣列數據文件中相應陣列的位置,避免了大量的陣列文件掃描的開銷。 DDSS通過上述方法將數據取出,并依賴casacore完成部分節點內處理后傳遞至導出接口,上層即可直接運用接口中的數據,完成相應操作。 5.1 實驗環境 實驗采用centos 6.4(Final)和casacore-1.5.0作為軟件環境。硬件采用2個服務器作為節點,每個服務器擁有2個4核的CPU(Intel Xeon CPU E5-2609 2.40 GHz),32 GB內存,和Broadcom NetXtreme BCM5750 千兆網卡。實驗數據采用MWA[12]天文項目中數據,共23列,陣列型數據5列(即CASA TABLE中的ArrayColumn),陣列大小為4×384的浮點型數據,占整張表數據量的99.98%。同時,為了測試DDSS與casacore中標準存儲模式在不同數據規模下的性能,將陣列型數據復制擴大,并且應實驗需要,數據在內存中生成。 5.2 實驗結果和分析 本文實驗對比了CASA使用casacore庫中標準的數據存儲管理器模塊(STANDARD)與CASA使用DDSS的I/O能力,驗證兩者的表現。每組實驗運行3次,取平均結果。 實驗一分別測試了標準情況下與DDSS在單機串行環境和多節點并行下,針對不同數據量的讀寫性能。圖4(a)中的數據量為9.5 GB,比較了單節點串行環境下STANDARD與DDSS的讀寫性能。圖4(b)中數據量為38 GB,比較了STANDARD與DDSS在單節點串行和多節點并行的讀寫能力,其中DDSS的并行環境為2個節點。每個陣列大小均約為1 MB。 圖4 實驗結果 結合圖4分析可得,在串行環境下,無論數據量或大或小,DDSS的數據寫入性能都率優于STANDARD,其隨著數據量的增大,兩者耗時的比例幾乎不變,DDSS比STANDARD快1.2倍左右。但是在數據讀取方面DDSS則比CASA在大量數據環境下有了顯著的提升,單機和集群兩種情況分別比STANDARD快了5.6倍和6.8倍,可見列存儲和基于位置映射的讀取數據方式是十分有效的。并且當數據量不斷擴大時,DDSS的效果會更加優越。在分布式環境中,DDSS十分有效地提升了數據寫入的速度,比STANDARD快了3.4倍。當數據量較小的情況下,本文方法讀取數據的效果提升的較少,其原因是分布式環境下,每個節點得到的數據量減少,在數據量不大的情況下,效果并不十分顯著。總結可得,通過分布式并行處理有效地減少了數據的讀寫時間。 實驗二測試了陣列為1、2、4 MB時系統的讀寫數據時間。數據的總量為38 GB保持不變,每個實驗按照陣列大小改變其記錄條數。如圖5所示,可以發現在數據總量不變的情況下,更改單個陣列的大小對系統的讀寫性能幾乎沒有影響,這說明DDSS可以靈活滿足各種大小的陣列數據,適合各種天文場景的應用。 圖5 DDSS應對不同大小陣列的吞吐量圖 本文提出了適應主流射電天文軟件CASA的底層分布式數據存儲策略。在不改變任何上層應用層的條件下,使其支持分布式環境,將數據進行混合方片后采用列存儲的方法,重寫數據儲存管理器并維護基于相對位置映射的元數據,提升CASA軟件的底層I/O讀寫效率。最后通過一系列實驗驗證了所提方法DDSS的有效性。在未來的研究中,針對ArrayColumn和列存儲,可以對陣列數據進行數據壓縮,進一步提高讀寫效率。另外重點關注于進程安全問題,在保證并行效果的同時,完善其對進程安全的控制,提高系統的健壯性和可靠性。 [1] McMullin J P,Waters B,Young W,et al.CASA Architecture and Applications[C]//Astronomical Data Analysis Software and Systems XVI ASP Conference Series,2007,376:127. [2] Diepen G N J V.Casacore Table Data System and its use in the MeasurementSet[J].Astronomy and Computing,2015,12:174-180. [3] Zetics P,Jose S.Overview of sciDB:large scale array storage,processing and analysis[C]//Proceedings of the 2010 ACM SIGMOD International Conference on Management of data,2010,NY,USA:ACM,2010:963-968. [4] Yao Y,Bowen B,Dalya B,et al.SciDB for High-Performance Array-Structured Science Data at NERSC[J].Computing in Science & Engineering,2015,17(3):44-52. [5] Buck J,Watkins N,LeFevre J,et al.SciHadoop:array-based query processing in Hadoop[C]//Proceedings of International Conference for High Performance Computing,Networking,Storage and Analysis,2011,NY,USA:ACM,2011. [6] Buck J,Watkins N,Levin G,et al.SIDR:structure-aware intelligent data routing in Hadoop[C]//Proceedings of the International Conference on High Performance Computing,Networking,Storage and Analysis,2013,NY,USA:ACM,2013. [7] 危兵,王鋒,鄧輝,等.CASA混合編程技術分析與功能擴展研究[J].天文技術與研究,2014,11(1):46-53. [8] Hong T,Wu Ya,Cao B,et al.A dynamic data allocation method with improved load-balancing for cloud storage system[C]//Proceedings of the 31st AIAA International Communications Satellite Systems Conference (ICSSC),2013,Shanghai,China,2013:220-225. [9] 巴子言,吳軍,馬嚴.基于虛節點的一致性哈希算法的優化[J].軟件,2014(12):26-29. [10] Eswaran K. Placement of records in a file and file allocation in a computer network[C]//Proceedings of IFIP Congress on Information Processing.Stockholm,Sweden,1974,304-307. [11] Floratou A,Patel J,Shekita E,et al.Column-oriented storage techniques for MapReduce[J].VLDB Endowment,2011,4(7):419-429. [12] Tingay S,Goeke R,Bowman J D,et al.The Murchison Widefield Array:The Square Kilometre Array Precursor at Low Radio Frequencies[J].Publications of the Astronomical Society of Australia,2012,30(30):109-121. A DISTRIBUTED DATA STORAGE STRATEGY FOR CASA Guo Huiqing Wang Mei Le Jiajin (SchoolofComputerScienceandTechnology,DonghuaUniversity,Shanghai201620,China) With the progress and development in astronomical equipments,to process massive astronomical data forms the new challenge.In order to make current mainstream astronomical data analysis software can effectively deal with massive data,we proposed a distributed data storage strategy (DDSS) applicable for radio astronomy to deal with upper application.First we designed the system framework of DDSS.Then we designed the hybrid method of partitioning and columnar storage,while preserving the advantage of column-store in data query,the speed of data import is promoted as well.Furthermore,by maintaining the relative position mapping-based metadata to quickly read astronomical array data containing large amount of data,the I/O throughput of astronomy when processing underlying data of applications is significantly improved.Finally,through experiment we testified the effectiveness of the proposed method. Distribution Astronomy Array data 2015-10-13。過匯卿,碩士生,主研領域:數據倉庫和分布式技術。王梅,副教授。樂嘉錦,教授。 TP3 A 10.3969/j.issn.1000-386x.2016.11.007
5 實驗與分析
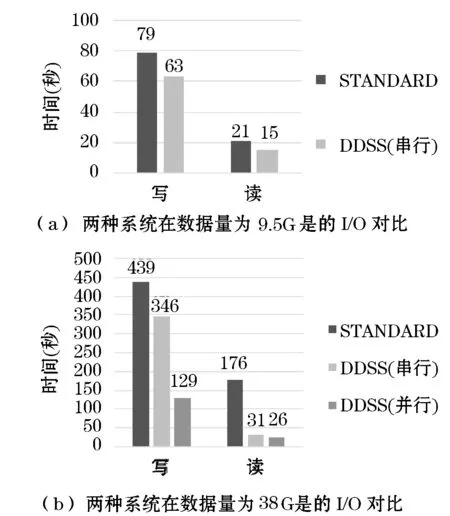
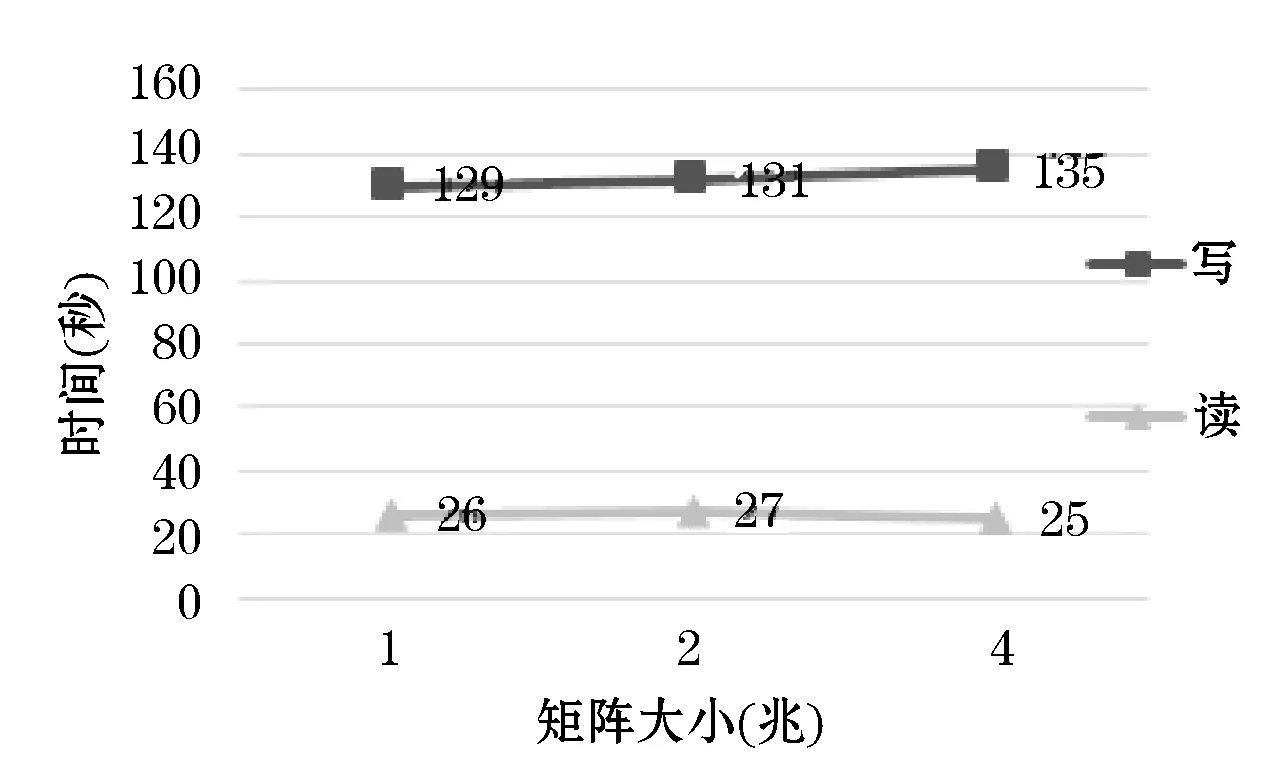
6 結 語
