
應用心理學中的個體指向方法:理論、技術與挑戰
2017-01-12 17:00:38楊之旭辛自強
心理技術與應用 2016年12期
楊之旭+辛自強

摘 要 作為整體互動觀的派生方法,個體指向方法不同于變量指向方法,它主張以個體為中心,目的是識別具有同質性的個體亞組。整體互動觀中的整體主義強調系統具有不可還原性、不可分解性和自組織性,互動主義主張系統內與系統間的成分交互影響。個體指向分析技術包括聚類分析、配置頻次分析、ISOA、LICUR、潛在類別分析和混合增長模型等。該方法最初多被應用于發展心理學領域,近年來被越來越多地用于組織行為學和社區心理學等應用心理學領域。未來的個體指向研究應該規范術語使用,在描述現象的同時增加對現象的預測,并且嘗試同時使用個體指向方法與變量指向方法。
關鍵詞 個體指向方法;整體互動觀;配置頻次分析;ISOA;LICUR;ROPstat
分類號 B84-06
DOI: 10.16842/j.cnki.issn2095-5588.2016.12.006
1 引言
在過去幾十年里,許多有影響力的心理學理論強調了從整體的和互動的視角研究個體發展的重要性(如 Cairns, 1979; Magnusson, 1985)。這種視角主張個體是一個整體,個體的先前行為、基因構成和環境因素作為一個統一整體而運作,因此不能孤立地看待它們對個體心理、行為與發展過程的影響。然而,作為當前科學心理學最普遍使用的方法,變量指向方法(常用技術是相關分析,方差分析和回歸分析等)沒有將個體看作整體,而是假設個體是可互換的單元,除了隨機誤差之外,他們在行為發展上不存在質或量的差異(Block, 1971),即總體具有同質性。事實上,在心理學中,總體中的個體常常是異質的,因此應該重視以個體為中心的完整分析(辛自強, 2013)。個體指向方法(person-oriented approach)是一種以個體為中心的分析方法,它的重要任務是確定心理或行為發展的個體差異或異質性(Bergman & Magnusson, 1997)。本文將從理論、技術和挑戰等方面系統回顧個體指向方法,另外特別闡明該方法在應用心理學領域的應用現狀與前景。
本文之所以確定介紹上述幾部分,是因為考慮到國內個體指向研究存在的三方面問題。
第一,在理論與技術方面,盡管個體指向理論是個體指向方法的一部分,但是國內較少有文章系統介紹個體指向方法的理論基礎,這不利于研究者在理論的指導下使用個體指向方法。關于數據處理技術,國內的個體指向研究大多使用基于模型的聚類方法(如,陳亮, 張文新, 紀林芹, 陳光輝, 魏星, 常淑敏, 2011),較少使用傳統的聚類方法、ISOA、LICUR和配置頻次分析。然而,這幾種技術也常被用于個體指向研究(如,Garcia, MacDonald, & Archer, 2015),并且這些技術可以通過新近開發出來的用戶友好型軟件ROPstat執行(Vargha, Torma, & Bergman, 2015)。因此,本文一方面將系統地介紹整體互動觀,另一方面除了介紹基于模型的聚類方法,還將介紹其他幾種技術的原理、步驟及其在ROPstat軟件中的實現方法,以期為個體指向研究者提供模板。
第二,在應用研究領域,當前國內研究者主要將個體指向方法應用于發展心理學(如陳亮, 文新, 紀林芹, 陳光輝, 魏星, 常淑敏, 2011; 趙景欣, 劉霞, 申繼亮, 2008),較少將其用于應用心理學研究,但是個體指向方法近年來已經被越來越多地應用于組織行為學(如,Crocetti, Avanzi, Hawk, Fraccaroli, & Meeus, 2014; Mkikangas & Kinnunen, 2016; Meyer, Stanley, & Vandenberg, 2013)與社區心理學(如,Bogat, Leahy, von Eye, Maxwell, Levendosky, & Davidson II, 2005; Bogat, 2009; von Eye, Bogat, & Rhodes, 2006)等應用心理學分支學科。因此,本文將主要介紹該方法在組織行為學與社區心理學中的應用現狀及前景。
第三,在方法新進展方面,盡管國內已有文章介紹個體指向方法(紀林芹, 張文新, 2011; 劉堅, 2009),但是近五年該方法又有新發展。除了上文提到的進展,進展還體現在個體指向方法領域的專業期刊Journal for Person-oriented Approach于2014年創刊,在此平臺之上理論和方法均有所革新。此外,個體指向方法面臨新的挑戰(Bergman, 2015; Bergman & Lundh, 2015; Laursen, 2015)。因此,本文將梳理上述進展、挑戰與解決方案。
綜上所述,本文的第二部分回顧整體互動觀,第三部分梳理六種個體指向數據分析技術,第四部分評述個體指向方法在應用心理學領域,特別是組織行為學與社區心理學中的應用現狀與前景,第五部分小結該方法的現存問題及解決方案。
2 理論內容
2.1 整體互動觀
個體指向方法是個體發展的整體互動系統觀(a holistic interactionistic system view)的派生方法。整體互動系統觀由Magnusson(1988)提出,將個體視為有機的不可分割的整體,其中互動的成分共同運作,在此過程中形成一個功能性的系統。因此,應該關注作為整體的個體而非部分的變量。
該理論的提出受到三個來源的影響(Bergman & Magnusson, 1997):
(1) 生命科學的發展揭示了生物過程與行為、心理、社會因素相互作用的過程,這使得整合行為的多重解釋(如,心理的、生物的與環境的視角)成為可能。
(2) 來源于自然科學(混沌理論、突變理論與一般系統論)的非線性發展系統方法和模型被引入心理學中。
(3) 縱向研究的復興提供了綜合的追蹤數據,使得整體互動范式的實行成為可能。
整體主義(holism)和互動主義(interactionism)居于整體互動觀的核心。需要指出的是,盡管“整體主義”和“互動主義”這兩個術語在不同學科(如,物理學、生物學、哲學和心理學等)已經有較長的歷史,整體互動觀中的一些觀點并非Magnusson首創,但是Magnusson似乎是較早的將整體主義和互動主義整合進一個統一理論框架的心理學家(Lundh, 2015)。
Magnusson的整體主義主要涉及理論問題,即整體和部分的關系。它包括三個假設:不可還原性、不可分解性和自組織性(Lundh, 2015)。其中,不可還原性聚焦于整體,指“整體有超越屬于它的部分的性質(Magnusson, 1990, p.197)”,即整體性質不能還原為部分性質之和。不可分解性聚焦于部分,指 “個體的不同方面的功能,因它們在完整個體的綜合功能中發揮的作用而獲得意義(Magnusson, 2001, p.155)”,即各個部分的功能不能脫離其在整體功能中發揮的作用而獨立存在。自組織性是“開放式系統的一個特征”,指“新的結構與模式從現有結構與模式中涌現的過程(Bergman & Magnusson, 1997, p.293)”。上述三種性質也是一個整體性系統的性質。
Magnusson的互動主義主要涉及實證問題,即不同因素之間如何互動,以導致在一個系統中有變化產生。Magnusson認為“互動是開放式系統在各個水平上的中心原則(Magnusson, 1990, p.196)”,強調互動是復雜的、雙向的。這意味著“區分自變量與因變量未必有意義,因為一個成分在另一個成分關聯的過程中,可能既是原因也是結果(Magnusson, 1990, p.197)”。互動可能是同一系統之內的不同成分之間的交互影響,也可能是不同系統之間的交互影響。
2.2 理論原則
基于整體互動觀,Bergman和Magnusson(1997)提出了個體指向方法的5個原則,后來被Sterba和Bauer(2010)概括為6個關鍵詞。據此,本文將個體指向方法的5個理論原則總結如下:
(1) 個體獨特性。在一定程度上,發展過程對個體是獨特的,這暗示著不同個體的發展可能是異質的。
(2) 復雜互動性。發展過程是復雜的,它包含許多不同水平上的因素,這些因素以一種復雜的方式相互關聯著。因為多種因素復雜地相互作用,不太可能找到足以解釋某一心理或行為的單一因素。
(3) 個體內變化的個體間差異性。不同個體的心理/行為發展可能形成幾種不同的軌跡,同一軌跡之內的個體遵循的發展路徑差異較小,不同軌跡之間的個體的發展路徑差異較大。
(4) 模式概括性與整體主義。模式概括性是指,發展過程總是包含多個因素,多個因素的聯合可以被描述為模式(patterns)或剖面(profiles);模式或剖面通常被用來描述個體,不同的個體可能屬于相同或不同的剖面組(profile groups)。整體主義是指,某一因素在心理與行為發展中的作用取決于它和其他因素的互動,離開了其他因素和互動,無從理解這一因素的意義(紀林芹, 張文新, 2011)。因此我們只能通過研究多種因素的聯合,即模式或剖面,來理解這些因素的意義。
(5) 模式有限性。描述個體的模式或剖面的數量是有限的。一些模式比其他模式或預期的更經常出現,被稱為典型(type);一些模式比其他模式或預期的更不經常出現,被稱為特例(antitype; Bergman, Magnusson, & El-Khouri, 2003)。“典型”與“特例”這兩個術語常常與一種具體的個體指向分析技術——配置頻次分析——關聯在一起。類似于“特例”,Bergman和Magnusson(1997)將更不經常發生的模式稱為“白點”(white spots)。尋找特例或白點常常是個體指向研究者感興趣的內容。
關于最后一個原則中提到的特例,盡管是個體指向方法的興趣點之一,但是并不是變量指向方法的關注點,變量指向方法一般會篩除異常值,計算不同個體的得分均值,最終得出最典型的結果。接下來,本文將對比這兩種方法。
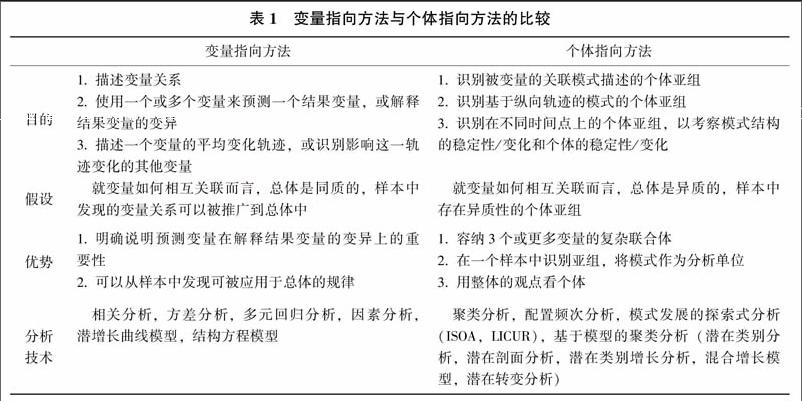
2.3 變量指向方法與個體指向方法的比較
變量指向方法與個體指向方法的差異如表1,至少包括目的、假設、優勢與分析技術4個方面。
由表1可見,個體指向方法與變量指向方法互為補充,各有側重地回答不同的研究問題。換言之,個體指向方法并不能替代變量指向方法。為了全面探討某一問題,許多研究同時包含這兩類方法(如,von Eye, Bogat, Rhodes, 2006; Zhang, Xin, Ding, & Lin, 2013; 趙景欣, 劉霞, 申繼亮, 2008)。例如,Zhang,Xin,Ding和Lin(2013)為探討2至5年級小學生類推理能力的發展,一方面,使用變量指向方法,證明類推理能力隨年級增長的規律;另一方面,使用個體指向方法,識別出兒童在三種類推理任務中表現的典型與特例,發現了兒童剛剛開始掌握不同推理能力的時間點。為了進一步說明兩種方法的關系,本文將在第四部分結合應用心理學的特定主題舉例;在此之前將介紹個體指向方法的主要數據分析技術(如表1)。
3 數據分析技術
3.1 聚類分析
聚類分析(clustering analysis)根據個體在一組變量上反應的相似性,將個體分類到相同或不同的亞組,保證亞組內同質性較高,同時亞組間異質性較高(Rand, 1971)。在個體指向背景中,聚類分析的主要目的是識別涌現出的典型模式,這些典型模式可以被看作一個過程的結果,即吸引子狀態(Bergman, Magnusson, & El-Khouri, 2003)。
3.1.1 殘差分析
在進行聚類分析之前,往往需要識別并刪除多變量異常值,即殘差個案。如上所述,典型模式是經常被觀測到的模式,它們產生于待研究的過程的核心性質。此外,還有一些罕見的觀察模式,它們產生于過程的邊緣性質、不常見的個體生活事件,或者測量誤差。這種模式下個案是殘差個案,它們一旦納入聚類分析,就可能扭曲屬于典型模式的個案的分類結構(Bergman, 1988),因此應該刪除這些殘差個案。具體而言,需要對比成對被試的模式,如果一個個案沒有表現出與預先決定數量的其他個案的相似性,即它與最臨近個案之間的距離超過距離閾值,那么這個被試被確定為一個殘差。其中,距離閾值越小越嚴格。殘差數量一般不超過樣本量的3%(Bergman, Magnusson, & El-Khouri, 2003)。
3.1.2 執行程序
在個體指向背景中,常用的聚類分析包括兩種類型:
(1) 層次聚類分析,尤其是Ward層次聚類分析。Ward層次聚類分析的思想來源于方差分析,目的是使得各個類別中的離差平方和較小,而不同類別之間的離差平方和較大。其執行步驟是,首先確定距離的基本定義,以及類別之間的距離的計算方式,然后按照距離的遠近,把距離較近的數據依次合并,直到所有數據歸為一個類別。由于聚類結果可能存在層次關系,因此被稱為層次聚類法。該方法傾向于使得各個類別的樣本量相近,同時允許變量是連續變量或分類變量。
(2) 非層次聚類分析,尤其是K-means重新定位分析。其執行步驟是:
首先,指定聚類的類別數量(K的含義);接著,根據分析者指定的聚類中心或數據本身結構的中心初步確定原始中心點;
然后,逐一計算各案例到類別中心點的距離,按照最近原則將各個案例歸入各個類別,并計算各類別的新中心點(用均值表示,means的含義);
再次,按照新的中心位置,重新計算各案例離中心類別中心點的距離,并重新歸類,更新類別中心點;
最后,重復上個步驟,直到達到一定的收斂標準。非層次聚類法要求變量是連續變量,并且對變量的多元正態性和方差齊性要求較高。
在個體指向分析中,常常以Ward層次聚類分析為起點,進一步進行K-means重新定位分析,其中目標被重新定位,以便使被解釋的誤差平方和百分比(percent explained error sum of squares, EESS%)最大化,類別間異質性最小化(Bergman, Magnusson, & El-Khouri, 2003)。
3.1.3 聚類方案的質量評估與選擇
不同于一般的聚類分析,在個體指向方法框架下,當檢驗聚類方案的內部效度時,類別內同質性往往比類別間異質性更重要。這是因為,基于個體指向理論的預期,典型模式的數值僅僅在變量的一個子集中有差別,這暗示著類別與類別可能離得不遠。據此,Vargha, Bergman和Takcs(2016)總結了常用的3類聚類質量系數,這些指標可以用于選擇最佳聚類數量。
(1) 最常用的聚類質量系數是EESS%和HCmean。這兩個指標本質上是會聚度(類別內的同質性)指標,僅取決于類別內的距離。會聚度越高,結構越好。EESS%衡量聚類方案的類別內同質性,即相比總的樣本中心,個案離它們各自的聚類中心更近的程度。HCmean是平均聚類同質性,它通過計算個案的配對的類別內距離均值得到,最好小于1,越接近0越好。
(2) 其次是點二列相關系數。這本質上是總體分離度(類別間的異質性)指標,分離度取決于類別內與類別間的配對距離。在好的聚類方案中,屬于相同類別的配對客體之間的距離比屬于不同類別的配對客體之間的距離更近。點二列相關系數的值越大越好。
(3) 只有在特殊情況下使用最小分離指標,如silhouette系數。silhouette系數同時考慮內聚度與分離度,值越大,表示相比最近的其他類別中心,個案離自己所屬類別的中心更近。Silhouette系數大于0.5表示合理的分類,小于0.2表示數據沒有顯示出聚類結構(Kaufman & Rousseeuw, 1990)。
此外,當使用多種方法進行聚類,需要對比不同聚類結果時,還可以使用下面的三種方法:
(1) 使用Rand指數衡量兩種聚類方法的總的相似性。其計算原理是考慮所有配對的樣本,并且計算被分配到相同或不同的類別中的配對數量(Rand, 1971)。Rand指數越接近1,表明兩種結果越相似,越接近0,表明兩種結果越不同。
(2) 使用精確超幾何檢驗進一步對比不同聚類結果的差異。首先將兩種聚類的不同分類進行交叉組合,每個組合有一定數量的個案,個案數量即是觀察頻次。其次基礎模型會產生出一個參照(即,一個估計的期望單元格頻次),將其與觀察單元格頻次比較。如果某個單元格包含的觀察頻次比模型預期的頻次顯著更多,那么這個交叉類別構成一個典型;如果觀察頻次的頻次顯著更少,那么這個交叉類別構成一個特例。
(3) 使用單樣本t檢驗對比原始數據的質量系數與模擬的隨機數據的質量系數。首先通過數據模擬,生成隨機數據。隨機數據可以由輸入變量的獨立隨機組合的數值組成,或由獨立隨機均勻分布變量組成,或由獨立隨機正態分布變量組成。然后使用單樣本t檢驗原始數據的質量系數是否都顯著好于隨機數據的質量系數均值。這種t檢驗的獨立迭代次數最好超過100(Vargha,Bergman,& Takcs, 2016)。
3.1.4 軟件與實例
個體指向聚類分析比常規聚類分析包含更多方法與步驟,ROPstat是較少的可滿足需要的軟件。具體而言,在該軟件中:
(1) Residue模塊用于識別與刪除殘差;
(2) Hierarchal模塊和K-means模塊用于分別進行層次/非層次聚類;
(3) K-means模塊用于計算聚類方案質量系數及其顯著性;
(4) Exacon模塊計算Rand指數,并進行超幾何精確檢驗對比聚類方案(Vargha, Torma, & Bergman, 2015; Vargha,Bergman, & Takcs, 2016)。個體指向方法框架下的聚類分析應用實例見Garcia,MacDonald和Archer(2015)或Vargha,Bergman和Takcs(2016)。
由于聚類分析是一種啟發式的聚類技術,有一定局限性,其替代方法是基于模型的聚類方法(model-based clustering methods),例如潛在類別分析(本文3.5部分)和混合增長模型(本文3.6部分),這類技術通過比較統計模型確定最優聚類方案。盡管如此,聚類分析的優點是對數據模型不要求約束性假設,而且符合個體指向方法的理論原則。當變量是數值變量,且研究具有探索性質時,聚類分析仍是常用的個體指向數據分析技術。
3.2 配置頻次分析
配置頻次分析(configural frequency analysis, CFA)適用于多變量交叉分類的分析,變量是分類變量(von Eye, Mair, & Mun, 2010)。“配置”指單元格所代表的模式。CFA的目標是通過顯著性檢驗,將單元格內的觀察頻次與期望頻次比較,識別典型與特例——前者指觀察頻次比期望頻次顯著更高的配置,后者指觀察頻次比期望頻次顯著更低的配置。
3.2.1 執行程序
一般CFA的執行程序包括五步(von Eye, Mair, & Mun, 2010):
第一步,選擇基礎模型,估計期望頻次。CFA的基礎模型是一個隨機模型,該模型估計一個配置預期發生的概率。大多數CFA的基礎模型是對數線性模型,該模型假設分類變量之間具有獨立性(變量獨立性假設)。與之相反,CFA的前提假設是變量之間相互關聯,旨在發現典型和特例。只有當對數線性模型的變量獨立性假設被拒絕時,才能進行CFA。
第二步,確定偏離于模型的變量獨立性假設的標準。當前大多數CFA采用的是依賴于邊際頻次的方法。其中一種依賴于邊際的度量指標是Pearson χ2檢驗中的Φ系數。Φ系數衡量兩個二分變量之間的關系強度,即衡量偏離于兩變量獨立的基礎模型的程度。
第三步,選擇顯著性檢驗的類型。在任意抽樣方案之下,可使用的顯著性檢驗包括Pearson χ2檢驗,z檢驗和精確二項式檢驗。在乘積-多項抽樣方案之下,可使用的顯著性檢驗包括Lemacher精確檢驗和近似超幾何檢驗。
第四步,在控制α之后進行顯著性檢驗,識別典型與特例。無論將CFA用于探索研究還是驗證研究,都需要進行多個顯著性檢驗,對每個配置分別進行觀察頻次與期望頻次的比較。當對所有配置進行大量的顯著性檢驗時,存在利用偶然機會的高風險。為了防止α膨脹,CFA總是會使用控制顯著性閾值α的程序。傳統方法是Bonferroni法,調整后的α=α / t。其中t是所有變量的交叉分類的單元格數量。假如有288個單元格,將α設定為0.05,那么α*等于0.0001736。由于這種方法比較保守,當前使用較多的方法是Holm法。
第五步,典型與特例的識別與解釋。進行顯著性檢驗之后會涌現出一定數量的典型和特例,需要解釋這些典型和特例的含義。
CFA適用于對橫截面數據進行分析,確定典型或特例。此外,CFA也適用于分析縱向數據,對預測變量和結果變量的關系,以及不同變量發展變化間的聯系進行分析。例如CFA的變式之一,預測配置頻次分析(von Eye & Bogat, 2005)。該模型也是一種識別典型和特例的分類數據分析技術,但是它被用于識別預測變量(一般按時間順序重復測量)的一個特定配置與結果變量的關系。預測配置頻次分析的基礎模型中包括預測變量與結果變量,解釋了重復測量之間的一階和二階自相關。與CFA的一般程序類似,當發現基礎模型的獨立性假設被拒絕時,可以認為結果不能被預測變量的主效應及預測變量之間的相關所解釋,因此預期典型或特例存在,進而識別這些典型與特例。
3.2.2 軟件與實例
ROPstat軟件中的CFA模塊可以執行CFA,其基礎模型是對數線性模型;關于偏離模型的變量獨立假設的標準,采用的是依賴于邊際頻次的方法;顯著性檢驗的類型是精確二項式檢驗;校正α的方法是Holm法。如果想設定其他條件或使用其他的CFA檢驗方法,可考慮使用von Eye開發的CFA程序(http://www.dgps.de/fachgruppen/methoden/mpr-online/issue4/art1)。
PCFA的應用實例參見Martinez-Torteya, Bogat, von Eye和Levendosky(2009)。另外,von Eye,Mair和Mun(2010)包括CFA的各種變式及其應用實例。CFA的應用實例如Zhang,Xin,Ding和Lin(2013)。他們使用CFA探討兒童類推理能力的發展。來自小學4個年級(2~5年級)的兒童完成了三種類推理任務,分別是類包含、替代包含與二元律任務,每種任務有4個題目,每個題目有4個選項。對于每個題目,兩個變量(年級與答案)組成16個可能的配置(年級變量共4個水平,為2、3、4、5;答案變量共4個水平,更多、一樣多、更少、不確定)。
為了方便比較,本文分別選取3類類推理任務中的第1個題目,將CFA的結果重新整理,見表2。其中CI 1是類包含任務,題目為“世界上的蘋果比水果更多,蘋果和水果一樣多,還是蘋果比水果更少?還是你不確定?”;VI 1是替代包含任務,題目為“世界上的梨子比非香蕉更多,梨子和非香蕉一樣多,還是梨子比非香蕉更少?還是你不確定?”;LD1 是二元律任務,題目為“世界上的非水果比非梨子更多,非水果和非梨子一樣多,非水果比非梨子更少?還是你不確定?”。3個題目的正確答案均是“更少”。
由表2結果可知,對于所有題目,一階CFA模型的χ2檢驗結果都是顯著的,CFA的基礎模型被拒絕。這表明,對于所有項目,兒童的答案與年級均存在交互作用。因此進一步檢驗個體單元格。其中Bonferroni校正α等于0.003125(α
瘙 毐 =0.05 / t, t=16)。結果表明,在類包含任務上,2年級兒童在3類題目的正確答案上均出現特例,即更不可能回答正確,并且在錯誤答案(“一樣多”)上出現典型,即更可能回答錯誤;3~5年級兒童在正確答案上出現典型,而在錯誤答案(“一樣多”)上出現特例,即他們更可能回答正確,更不可能出錯。在替代包含與二元律任務上,僅有5年級兒童的正確答案上出現典型,即他們比其他年級的兒童更可能給出正確答案。綜上所述,2年級兒童還沒有掌握3種類推理能力,兒童到了5年級才掌握二元律的類推理能力。
3.3 ISOA技術
ISOA(I-States-as-Objects-Analysis; Bergman & El-Khouri, 1999; Bergman, Nurmi, & von Eye, 2012)適用于探究模式的短期發展問題,它假設隨著時間推移,從屬于每個類別的樣本比例可能發生變化,即個體可能改變他們從屬的類別,但是分類結構不隨時間變化,即相同的分類結構在所有的時間點上保持一致。ISOA處理的數據一般包括一個由不同個體組成的樣本,這些個體在一系列相同的變量上被重復研究幾次。關鍵的概念是i狀態(i-state),即一個個體在一個特定時間上的變量數值模式。ISOA技術旨在進行模式發展分析,即描述樣本中的個體在不同時間點的不同典型模式的頻率(結構的穩定性與變化)和一般發展模式(個體的穩定性與變化)。
3.3.1 執行程序
ISOA的執行步驟是(Bergman & El-Khouri, 1999):
第一步,重新整理數據集,將同一個個體根據時間點的不同拆分成不同的子個體(subindividuals),即列出所有的i狀態。如果有k個測量時間點,樣本量為N,那么每個個體被拆分成k個子個體,因此數據中有N×k個i狀態。
第二步,進行殘差分析,識別并刪除殘差集。殘差集類似于一系列多變量異常值,指通過歐式距離平方的均值測得的與所有其他客體都不相似的i狀態。
第三步,對所有剩余的所有i狀態進行聚類分析,識別出一定數量的類型,其中每個i狀態屬于分類中的一個類型,這個類型被稱為典型i狀態(typical i-state)。
第四步,將數據從以每個i狀態為一個個案調整為以一個被試為一個個案。
第五步,基于聚類分析的類別進行模式發展分析。這是ISOA技術的重點,其焦點有2個:
(1) 頻次(結構)穩定性/變化。如果頻次穩定性高,那么在不同時間點上的,從屬于不同典型i狀態的樣本比例應該類似。另外,也可以對比不同的時間點涌現的典型/特例,如果相似度高,那么模式的頻次穩定性高(Laursen, Furman, & Mooney, 2006)。
(2) 個體穩定性/變化。指在不同的時間點,被試屬于相同的/不同的類別。方法是檢驗所有的兩個臨近時間點的典型i狀態的交叉表(Bergman, Nurmi, & Von Eye, 2012)。如果有k個時間點,u個典型i狀態,那么有k-1個u×u交叉表。為了識別典型i狀態的發展軌跡的典型/特例,需要對交叉表中的每個單元格進行精確超幾何檢驗,觀察不同時間點的哪些典型i狀態組合比預期更可能發生(典型)或更不可能發生(特例)。
個體穩定性/變化的結果經常被描述為流程圖,其中左側為時間點1的典型i狀態,右側依次排列時間點2,3…k的狀態,中間用線條連接,線條上標注典型i狀態在不同時間點保持不變與發生轉變的可能性,實線(虛線)表示比隨機模型預期的更可能(不可能)發生。這種模式發展流程圖的實例可參考Laursen和Hoff(2006)進行的一項持續兩年的追蹤研究,他們考察了美國丹佛都會區青少年在10和12年級時的感知到的社會支持模式的穩定性與變化。
3.3.2 前提檢驗
ISOA假定分類系統具有時間不變性,即同一套典型模式可描述不同時間點的所有數據。為了檢驗這個前提是否成立,可以使用三類指標(Bergman,Nurmi,& Von Eye, 2012):
(1) 結構不變性。指ISOA涌現的典型i狀態與在特定的時間點涌現類別的相似度。這里的“相似”是指一個典型ISOA的i狀態的質心(centroid,即均值向量的中心)與在特定時間點涌現的一個類別的質心相似。相似度即兩個質心的距離,通過計算兩個質心之間的歐式距離平方的均值(averaged squared Euclidian distance, ASED)得來。結構不變性需要在每個時間點單獨研究,首先觀察每個時間點的每個典型i狀態與對應的特定時間點的類別之間的ASED的中位數和數值范圍,然后檢驗所有ASED是否足夠小。對z標準化的數據,ASED低于0.25是一個可接受的相似度。
(2) 類別成員資格不變性。指ISOA的聚類方案和特定時間點的聚類方案之間的類別成員資格的相似度。這種相似度可以通過兩類指標衡量:第一類使用個案的配對為分析的基本單位,例如Rand系數和點二列相關系數(Rand, 1971);第二類指標基于兩種聚類方案的交叉表,以被試個案為分析基本單位,如Cramér-s V(1999)。
(3) 相對類別同質性。指從ISOA涌現出的典型i狀態可以像特定時間點的聚類方案產生的同質性類別一樣好的程度。衡量方式是對比在時間點i的ISOA聚類方案和時間點i的聚類方案產生的EESS%。如果二者的EESS%相似,那么可以認為相對類別同質性較好。
如果上述前提得到支持,可以使用ISOA。如果得不到支持,可使用一種替代性技術——LICUR。
3.3.3 軟件與實例
在ISOA技術中,與聚類分析有關的軟件實現方法在上文已做介紹。ROPstat還可以實現:
(1) Time separation模塊用于執行上述ISOA程序的第一步;
(2) Time fusion模塊用于執行第四步;
(3) Exacon模塊和CFA模塊用于執行第五步;
(4) Centroid模塊用于檢驗結構不變性假設;
(5) K-means模塊檢驗成員資格不變性與相對同質性類別假設。應用實例見Bergman,Nurmi和von Eye(2012)或Hiatt, Laursen, Mooney和Rubin(2015)。
3.4 LICUR技術
在使用LICUR(Linking of cluster after removal of residue; Bergman,Magnusson,& El-Khouri, 2003)時,需要分別對每個時間點的變量進行聚類分析,之后通過對比一個時間點的聚類方案與其他時間點的聚類方案,評估模式發展的結構穩定性/變化與個體穩定性/變化。這兩種穩定性/變化的概念與ISOA中類似。與ISOA類似,LICUR中的穩定性/變化也可以通過流程圖表示。
3.4.1 執行程序
LICUR的執行步驟是(Bergman, Magnusson, & El-Khouri, 2003):
第一步,對每個時間點的數據分別進行殘差分析,識別并刪除聚類變量的數值模式與樣本中其他個體都不匹配的個體。
第二步,對每個時間點的數據使用Ward層次聚類分析。聚類方案的有效性可以通過上文提到檢驗方法評估。聚類數量的決定方法還可以參考Bergman,Magnusson和El-Khouri(2003)提出的四個標準:
(1) 聚類方案在理論上有意義,而且明顯不同且在理論上可區分的兩個類別,沒有在最后的聚類方案中被合并為一個類別。
(2) 類別數量最好不超過15個,通常不少于5個。
(3) 在聚類方案中,EESS%的突然降低可能代表這種方案包括的類別不夠多,這種方案不是最理想的。
(4) EESS%最好超過67%。參照上述標準,得到一種最佳聚類方案。如果想要盡可能地獲得同質性類別,Ward聚類方案可以被當作起點,進一步進行K-means重新定位聚類分析。
第三步,將兩個臨近時間點的聚類方案連接成為交叉表,檢驗結構與個體穩定性/變化:
(1) 結構穩定性/變化指在不同時間點發現的模式的相似性/變化。如果這種相似性高,那么在兩個的時間點的聚類的質心距離(如歐式距離平方的均值,ASED)較小。
(2) 個體穩定性/變化反映了個體的模式發展路徑,即從一個時間點的某個類別轉變到后一個時間點的相同或不同類別。需要對交叉表中每個單元格進行精確超幾何檢驗,這種檢驗中的比率是觀察頻次與期望頻次的比值,表示從一個類別轉換到相同/不同類別的可能性。通過這種檢驗可以發現模式發展路徑中的典型與特例。
3.4.2 軟件與實例
在LICUR技術中,與聚類分析有關的軟件實現方法在上文已做介紹。ROPstat還可以實現:
(1) Centroid模塊用于檢驗結構穩定性/變化;
(2) Exacon模塊用于檢驗個體穩定性變化。LICUR技術的應用實例如Trost和EI-Khouri(2008)。這項研究使用縱向數據,探討同一批瑞典女性在10歲、13歲和43歲三個時間點的學業表現和心理問題的模式發展路徑。
3.5 潛在類別聚類分析
潛在類別分析(latent class analysis, LCA)與潛在剖面分析(latent profile analysis, LPA)可以合稱為潛在類別聚類分析(latent class cluster analysis, LCCA; Vermunt & Magidson, 2002)。與聚類分析相比,LCCA有更多的擬合指數對不同的分類結果進行評價和比較,從中選出最合適的聚類方案,并計算相應的后驗概率將被試分配到各潛在類別中(張潔婷, 焦璨, 張敏強, 2010)。LCA與LPA的相同之處是潛變量都是分類變量,不同之處是LCA的外顯變量是分類變量,LPA的外顯變量是連續變量;LCA的模型是概率分布,LPA的模型是密度分布。因為兩種方法的原理和實行步驟相似,本文將主要介紹LCA的模型原理與實行程序。
3.5.1 模型原理
LCA的基本思想是用較少的、互斥的潛在類別變量來解釋各外顯變量的各種反應的概率分布,潛在類別變量中每種類別對外顯變量的反應都有特定傾向(邱皓政, 2008)。換言之,LCA試圖用一個潛分類變量X來解釋K個外顯類別變量的關系,使得外顯變量的關系在經過X的估計后能夠維持其局部獨立性。
3.5.2 執行程序
LCA的執行步驟如下(邱皓政, 2008):
第一步,估計初始模型(只有一個類別的模型)。類別為1的模型即零模型,此時沒有在外顯變量背后設定潛變量。此時使用卡方顯著性檢驗(Pearson χ2檢驗, G2檢驗)進行模型適配度檢驗,顯著的卡方值(如p<.001)代表外顯變量之間的相互關聯未能被解釋,因此需要潛變量來解釋。
第二步,逐步增加類別數目,進行不同模型的參數估計,計算模型適配性。關于參數估計,LCA中模型求解的方法主要是極大似然法,其迭代過程一般采用EM、NR等不同算法。同時,需要計算不同類別數目的聚類方案對應的模型擬合的指標,包括:
(1) 卡方檢驗的卡方值及其顯著性。當潛變量類別數目由1繼續增加,卡方統計量一般會逐步減少,當達到一定數目后,模型達到良好適配(p>0.05)。
(2) 信息評價標準,如AIC、BIC。AIC適用于模型優劣的比較,其計算由極大似然算法來推倒,值越小表明適配越好;BIC彌補了AIC沒有考慮樣本量的問題,BIC比AIC更適用于樣本數達到數千人以上,或模型中參數數量較少時(Lin & Dayton, 1997)。
(3) Entropy。Entropy指數是衡量分類精確程度的指標,取值介于0到1,越接近1代表分類的精確度越高。Lubke和Muthén(2007)發現,entropy低于0.6一般表示錯誤地對大約20%或更多的被試進行了分類,entropy等于0.80及以上表明對至少90%的被試進行了正確分類。
(4) BLRT(bootstrap likelihood ratio test)和LMR檢驗。這兩個指標用來比較潛在類別模型的擬合差異。BLRT檢驗bootstrap抽樣獲得k個類別與k-1個類別的模型的對數似然比差異,LMR方法檢驗k個類別與k-1個類別的模型的對數似然比差異,如果差異p值達到顯著水平,那么可以認為k個類別比起k-1個類別的方案有了明顯改善。有研究(Nylund, Asparouhov, & Muthén, 2007)發現LMR檢驗傾向于高估類別的數目,BLRT在正確識別類別的正確數目方面有更高的精確性。
第三步,進行模型適配性檢驗與差異檢驗,決定最優模型。通過綜合比較第二步得出的卡方檢驗不顯著的那些模型中的信息評價標準(越小越好)、Entropy(越大越好)、BLRT和LMR檢驗(顯著則代表k個類別優于k-1個類別),同時兼顧理論、模型簡約性和結果可解釋性(Jung & Wickrama, 2008),決定最佳的類別數目。
第四步,進行類別的命名與參數估計結果整理。在決定最優模型之后,需要報告參數估計的結果,即報告潛在類別概率與條件概率,應用條件概率對潛在類別進行命名。
第五步,進行分類并決定各觀察值的歸屬類別。經過上述步驟,可以得到潛在類別與外顯變量的對應關系,進一步將觀察值分到不同的類別中。此后,可以進行變量指向的分析,即檢驗不同類別的個體在其他變量上的差異。
3.5.3 軟件與實例
邱皓政(2008)使用LCA對SARS期間心理與行為問題進行探索式分析,其中包含執行LCA各步驟的Mplus程序語句(pp.69-86)。
3.6 增長混合模型
增長混合模型(growth mixture modeling, GMM)用于處理群體異質增長問題(Muthén & Muthén, 2000),它可以彌補潛增長曲線分析(latent growth curve analysis, LGCA)和潛在類別增長分析(latent class growth analysis, LCGA)的缺點。這是因為LGCA是一種變量指向方法,它無法描述遵循不同發展軌跡的個體亞組;LCGA是一種個體指向方法,它盡管可以描述發展軌跡不同的個體亞組,但是不允許參數增長存在亞組內變異;相比而言,GMM既可以描述不同的變化類,又能夠自由估計類別內的變異。
具體而言,LGCA使用的模型是潛增長曲線模型(latent growth curve modeling, LGCM),它假定群體中所有個體來自于同一個總體,因此可以用同一個平均增長軌跡(軌跡的截距和斜率相等)描述所有個體的心理或行為增長軌跡。然而,在更大的總體中,個體間的差異較大,其增長軌跡不能用同一個平均增長軌跡描述。這時,可以替代LGCA的方法是LCGA。LCGA使用的模型是潛在類別增長模型(latent class growth modeling, LCGM),LCGA通過將潛在類別變量引入潛增長曲線模型,描述不同潛在類別的增長軌跡,即不同的潛變化類。此時,LCGM將每個類別內的增長因子的方差和協方差估計值固定為0,也就是假定同類別內的個體享有相同的平均增長軌跡。然而,同類別的增長軌跡仍然可能有個體間變異。這時候需要用GMM替代LCGA,因為GMM既估計同一個類別內的平均增長軌跡,又估計增長因子的變異。上述分析表明,LGCA往往是GMM分析的起點,LGCM和LCGM均是GMM的特例。
3.6.1 模型原理
GMM通過兩類潛變量描述個體之間增長趨勢的差異(劉紅云,2007; 王孟成, 畢向陽, 葉浩生, 2014):
(1) 分類潛變量,將群體分成互斥的潛在類別亞組,以便描述群體的變化類;
(2) 連續潛變量,描述初始差異(隨機截距)和發展趨勢(隨機斜率)。包含這兩種潛變量的模型是最基本的GMM。GMM也可以加入協變量和結局變量,協變量影響分類潛變量、增長截距/斜率和結局變量,分類變量影響結局變量。這里的協變量也可以稱為自變量,其數據可以是任何類型(分類、連續或計數)。GMM的觀測變量一般是連續變量,此時默認的參數估計方法是穩健較大似然估計。
3.6.2 執行程序
GMM的執行程序如下(Jung & Wickrama, 2008):
第一步,估計初始模型。GMM的初始模型一般只有一個類別,其中不包括協變量,相當于LGCM。此時常用的模型擬合指數有(Kline, 2015):
(1) CFI和TLI,建議參考值是大于0.90,越大越好;
(2) RMSEA,建議參考值是0.05,越小越好;
(3) AIC和BIC,越小越好。如果LGCM中截距或斜率因子的方差估計值顯著,說明個體在初始水平或增長速度上存在個體間差異(王孟成,畢向陽,葉浩生, 2014),有必要進行GMM。
第二步,在初始模型的基礎上增加類別數目,提取出不同類別的LCGM,對于類別數目不同的模型進行參數估計,計算模型擬合度和模型擬合檢驗。在確定一個GMM模型之前,LCGM是一個有用的初始模型;二者主要的差別在于,LCGM假定在增長因子上沒有類別內變異,GMM可以自由估計類別內變異。LCGM將類別內變異固定為0有助于識別出更清楚的類別,并且計算負擔更少。GMM可以將各亞組內的方差設定為跨類別組等同或自由估計。該步驟中的LCGM和GMM是不包括協變量的無條件模型。
第三步,綜合模型適配性指標和實際意義,決定類別數量。一般需要報告不同模型的卡方統計量、BIC、AIC、Entropy、BLRT和LMR檢驗結果。具體評估方法和LCA相似。
第四步,納入協變量,估計有條件模型,即包含協變量的LCGM和GMM模型,重復上述第二步和第三步。這是因為,如果協變量對增長因子(截距和斜率)和潛在分類變量有直接的影響,那么觀測變量與潛在分類變量的關聯可能出錯,上述步驟中使用的無條件模型可能導致歪曲的結果。因此,需要在上述的無條件模型后估計有條件模型。
第五步,進行類別的命名和參數估計結果整理。在決定最優模型之后,需要報告:
(1) 類別概率,即每個軌跡亞組的人數比例;
(2) 增長因子的估計值,即不同軌跡亞組的截距和斜率均值及其檢驗結果,根據這些信息對類別進行命名;
(3) 后驗概率,即每個個體被正確分類的概率大小,越接近1說明正確分類的可能性越大;
(4) 協變量對軌跡增長的影響的系數估計值與顯著性檢驗,這可以說明自變量對某一心理或行為特質的初始值(截距)和增長速度(斜率)的影響。
第六步,進行分類并決定各觀察值的歸屬類別,以便進一步進行其他類型的分析。
3.6.3 軟件與實例
Jung和Wickrama(2008)全面梳理了執行GMM各步驟的Mplus程序語句(pp.307-315)。GMM的特例——LCGA的實例見魏子晗,詹雪梅和孫曉敏(2015)。該研究描述實驗室情境中腐敗行為的3種變化軌跡,并考察風險概率和可控性對不同變化軌跡的影響。GMM的實例見王孟成,畢向陽和葉浩生(2014)。
4 在應用心理學中的應用現狀與前景
4.1 組織行為學
近年來,個體指向方法被越來越多地應用于組織行為學,或更寬泛意義上的組織科學的研究,其中涉及的主題至少包括工作認同(Crocetti, Ava-nzi, Hawk, Fraccaroli, & Meeus, 2014),工作倦怠(Mkikangas & Kinnunen, 2016),與組織承諾(Meyer, Stanley, & Vandenberg, 2013)。本文將以后兩個主題為例,說明個體指向方法將如何豐富與擴展組織行為學的傳統主題。
4.1.1 工作倦怠研究
關于工作倦怠的研究始于上個世紀70年代中期,40多年來大多數相關研究使用變量指向方法(Leiter, Bakker, & Maslach, 2014)。最近10年,越來越多的倦怠研究開始使用個體指向方法(如,Innanen, Tolvanen, & Salmela-Aro, 2014)。近期,Mkikangas與Kinnunen(2016)系統回顧了近10年發表的,使用個體指向方法研究工作倦怠的24篇論文。這些論文的主題包括:
(1) 倦怠癥狀的個體內模式,即倦怠類型;
(2) 倦怠癥狀的個體內發展軌跡,即倦怠軌跡;
(3) 個體內的幸福指標的模式,即倦怠與幸福指標組合形成的類型。
個體指向研究與以往的變量指向研究相比,既有相似結果也有新發現。相似結果表現在倦怠軌跡上,兩種方法都表明工作倦怠有跨時間的絕對的穩定性(員工的倦怠始終保持在一定的水平)與自比的穩定性(一名員工在不同時間屬于相同的倦怠類型)。新發現體現在,以往的變量指向分析表明倦怠的兩個成分(衰竭與工作怠慢)彼此高度正相關,但是個體指向分析可以發現倦怠的成分之間的關聯模式,經常出現的典型是:
(1) 在三個成分(衰竭、工作怠慢與工作效能感)上得分都很低的亞組;
(2) 在三個成分上得分都很高的亞組;
(3) 與在衰竭與工作怠慢上得分很高,但在工作效能感上得分很低的亞組。
綜合來看,個體指向研究通過揭示個體倦怠的典型與特例,將為變量指向研究提供重要的補充,同時將為工作倦怠研究提供新洞見。值得一提的是,Mkikangas和Kinnunen(2016)綜述到的研究大多是由北歐研究者進行的(占比58%),這與個體指向方法發源于瑞典有關,暗示著工作倦怠的個體指向研究仍處于初期階段。
4.1.2 組織承諾研究
Meyer與Allen(1991)提出組織承諾三成分模型,將組織承諾劃分為情感承諾(個體對組織的情感認同,以下簡稱AC)、規范承諾(與留在組織有關的責任的感知,以下簡稱NC)與持續承諾(個體感知到的離開組織的成本對個體行為的約束,以下簡稱CC)。此后的二十多年里,大部分相關研究使用變量指向方法,探討承諾的三成分(承諾成分)如何預測個體的行為,以及關于不同對象的承諾(承諾焦點)之間的關系。然而,變量指向方法不能解決以下問題:
(1) 承諾成分以及承諾焦點的復雜交互作用;
(2) 待研究的樣本是異質的,存在未被發現的亞組;
(3) 關于承諾的三成分彼此聯合,形成不同剖面的理論命題。為了研究這些問題,越來越多的組織承諾研究者開始使用個體指向方法(Meyer, Stanley, & Vandenberg, 2013)。
與變量指向方法相比,個體指向方法擴展了組織承諾研究的以下主題:
(1) 承諾的多項成分組合形成的亞組。例如,Wasti(2005)使用K-means聚類分析,發現土耳其員工表現出不同的組織承諾剖面組,包括完全承諾(三項分值較高)、不承諾(三項分值較低)、AC占優(AC分值較高)、CC占優(CC分值較高),與AC/CC占優(AC與CC分值較高)等亞組。Somers(2010)后續的研究發現完全承諾組與AC/CC占優組表現出最低的離職率。
(2) 承諾的多個焦點組合形成的亞組。例如,Morin, Vandenberghe, Boudrias, Madore, Morizot和Tremblay(2011)使用潛在剖面分析,分析員工對7個焦點(組織/工作小組/上司/顧客/職業/工作/職業生涯)的AC評分,識別出5個剖面亞組,包括對所有焦點高承諾、對所有焦點低承諾、對上司高承諾并對其他焦點中承諾、對職業生涯高承諾而對其他焦點低承諾,以及對最近的工作環境(組織/工作小組/顧客)高承諾。這些剖面組在績效與組織公民行為方面有所不同。
(3) 承諾的不同成分的個體發展軌跡。例如Kam, Morin, Meyer和Topolnytsky(2016)使用潛在轉變分析(王碧瑤, 張敏強, 張潔婷, 胡俊, 2015)檢驗員工在承諾亞組中的成員資格如何隨著組織變革而變化,調查的時間點1是組織宣布變革之前的1個月,時間點2與時間點1之間間隔8個月。結果識別出5個剖面組,分別是AC/NC占優、AC占優、所有成分中等但AC占優、所有成分中等但CC占優,以及CC占優,并發現員工在不同承諾剖面組中的成員資格具有跨期穩定性。
在上述三個方向中,最后一個方向是當前組織承諾的研究熱點。這是因為當代工作世界中關于承諾的最有趣的問題是員工承諾的個體發展過程(Meyer & Morin, 2016),而且組織行為學中有超越橫截面設計,轉而使用縱向設計的方法學風向轉變(張志學, 鞠冬, 馬力, 2014)。這些條件的共同作用將促使組織承諾研究者越來越多地使用個體指向方法。
4.2 社區心理學
密歇根州立大學的Bogat教授是較早將個體指向方法引入社區心理學的學者。Bogat,Leahy,von Eye,Maxwell,Levendosky和Davidson II(2005)使用配置頻次分析探討社區暴力、親密伴侶暴力與婦女心理健康的關系,這是在社區心理學專業期刊發表的較早的個體指向研究。不久之后,在2008年第116屆APA年會社區心理學分會上,作為美國社區研究與行動協會的主席,Bogat(2009)發表主席致辭,專門論證將個體指向方法引入社區心理學的必要性。其中,個體指向方法與社區心理學的接口可歸納為兩個方面。
4.2.1 社區干預項目評估
社區心理學家經常需要評估社區干預項目的成效。他們通常采用變量指向的方法,將被試隨機分配到干預組與控制組,通過檢驗兩組的差異來評估干預是否達到了預期效果。然而,這種方法的結果可能存在誤導性。
例如,von Eye,Bogat和Rhodes(2006)通過分析一個社區干預項目中的控制組的數據,來探討父母對孩子飲酒的態度如何影響社區青少年的飲酒天數。變量指向分析(方差分析)的結果表明,調查時間與性別對飲酒天數有顯著的交互作用,男孩的飲酒天數在兩次調查之間有所下降,女孩的飲酒天數有所增加。然而,這個交互作用的效果量相當小(偏η2=0.009),這可能是大樣本(N=3558)導致的統計檢驗力異常造成的,同時暗示著樣本中可能存在異質的亞組。事實的確如此,個體指向分析(配置頻次分析)識別出一個典型,包含1500名女孩(占樣本量的64%),她們預期父母對她們飲酒非常沮喪,在前后兩次調查中均報告從未飲酒——她們是不符合總體趨勢的被試亞組。上述分析是基于控制組的數據,但是道理也適用于社區干預項目評估。由此可見,變量指向方法可以發現干預效果的一般趨勢,而個體指向方法可以識別出符合與不符合一般趨勢的亞組,兼用兩種方法將有助于全面評估社區干預項目的效果。
4.2.2 生態視角下的社區心理學研究
個體指向方法與社區心理學中的生態模型有相似之處。社區心理學家Kelly是生態模型的早期倡導者,他認為互依性是生態視角的特點,提倡社區心理學家應該研究人際關系,人與環境的關系,一個社會系統與另一個社會系統的關系(Kelly, Ryan, Altman, & Stelzner, 2000)。整體互動觀也認為,系統中一個成分的某種改變必將影響另一個。根據這種聯系,Bogat(2009)提倡使用個體指向方法研究個體與環境的交互作用。
上文提到的Bogat,Leahy,von Eye,Maxwell,Levendosky和Davidson II(2005)關于社區暴力、親密伴侶暴力與婦女心理健康問題之間的關系的研究即是這種嘗試的案例。Bogat等(2005)使用配置頻次分析,發現社區暴力不能負向預測心理健康水平,這不同于以往變量指向研究的結果。這項研究的意義是,它提醒那些關注社區暴力及其后果的社區心理學家,也提醒支持生態視角的社區心理學家:
第一,變量指向研究的結論可能是對的,但也許不能推廣到其他個體亞組,例如上述研究中的婦女。
第二,變量指向研究整合了很多個體的數據,其結論或許能反映一般趨勢,但也許不能反映總體中的特定個體的變量關系。個體指向方法作為變量指向方法的重要補充,將豐富社區心理學關于個體與環境互依性的研究。
5 問題與挑戰
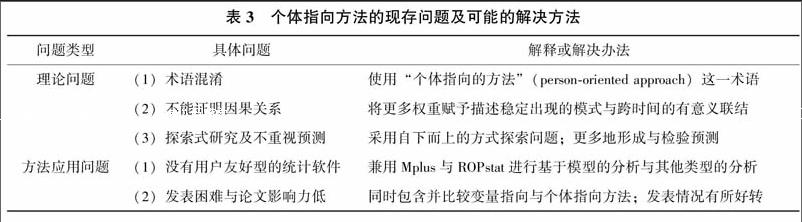
個體指向方法盡管具備上文提到的諸多優勢,并且應用的領域也越來越廣泛,但是仍然存在一些問題與挑戰。其現存問題可分為理論基礎問題與方法應用問題(見表3)。
5.1 理論基礎問題
個體指向方法的理論基礎問題至少包括3個方面:術語混淆、不能證明因果關系,以及方法的探索式性質與不重視預測。
(1) 術語混淆
術語“個體指向的”(person-oriented)有時候被稱為“個體中心的”(person-centered),但是后者指代的并非總是前者。一些論文中提及的個體中心方法等同于個體指向方法(如 Hiatt, Laursen, Mooney, & Rubin, 2015; Laursen, Furman, & Mooney, 2006; Laursen, Pulkkinen, & Adams, 2002; 趙景欣,申繼亮,劉霞, 2008),因為這些論文不僅使用個體指向的數據統計方法,還遵循個體指向的理論觀點。但是一些論文提及的“個體中心的視角”(person-centric perspective)(如,Rupp, Skarlicki, & Shao, 2013)并非指代個體指向方法,而是指組織行為學中的一種以員工為中心的研究視角。不幸的是,個體指向方法由于經常被稱為“個體中心方法”,常被誤認為是個體中心療法(Laursen, 2015),這可能造成“個體指向方法是非實證研究方法”的錯誤判斷。為消除歧義,本文推薦研究者使用“個體指向方法”(person-oriented approach)這一術語來代替“個體中心方法”這一術語。
(2) 不能證明因果關系
因果陳述是許多心理學研究的目標,達成這個目標需要進行實驗,即通過操縱自變量,控制無關變量,排除競爭性解釋,最終找到自變量和因變量之間的因果關系(辛自強,2013)。在心理學的諸多分支學科中,發展心理學或許不是一門實驗科學,因為發展心理學的歷史獨立于實驗心理學,而且發展心理學關心的個體發展問題無法通過實驗回答(辛自強,2009)。具體而言,個體發展的研究常常使用縱向數據,并且使用統計模型來控制混淆變量,這不足以達成因果陳述的目的。與之類似,個體指向方法經常被用于探究個體發展問題,在因果關系方面易受到質疑。
然而,根據整體互動觀,個體發展是一個復雜的過程,很難設想操縱整體中的一個成分,同時卻不影響其他的成分。例如,一名研究者相信小學生極差的學業成績是后來犯罪的原因,那么他如何通過干預學業成績,而不同時改變師生關系或親子關系呢(Bergman & Lundh, 2015)?根據這一邏輯,因果關系中的“操縱”或許是有問題的。因此,研究者或許應該將更少的權重賦予因果關系證明,將更多的權重賦予描述穩定出現的模式與跨時間的有意義的聯結。
(3) 探索式研究及不重視預測
個體指向方法是一種探索式研究方法,并且相比預測更加重視描述,這兩個問題導致研究者對該方法有所抵觸(如,Laursen, 2015; Mkikangas & Kinnunen, 2016)。一個通常的科學程序需要構建一個或多個模型,然后予以檢驗或比較。這種程序常常不能推廣到個體指向研究中,因為相關領域內的大多數研究都是變量指向的,即許多發現來自于個體間變異的標準研究,根據這些研究不能對個體水平的研究做出理論假設(Molenaar, 2004)。同時,個體指向理論或許暗示著我們對于復雜系統的理解還不夠全面,也就是說,待研究的對象可能具有很高的復雜性,此時不大可能構建出一個野心勃勃的模型。綜合上述兩個原因,個體指向研究常常不遵循理論構建與假設檢驗的邏輯,而是采用一個替代性的解決方案,即采用自下而上路徑來探索待研究的問題。
另外,個體指向方法確實重描述而輕預測。事實上,預測很重要,但并非科學的首要目標。例如,在氣象學中,天氣系統的原理已經被很好地理解,但是對天氣的長期預測力卻相當有限(Bergman & Lundh, 2015)。又如,天文學方面的自然歷史學家為了回答“土星由什么組成”等問題,通常需要不斷提高觀測裝置,尋找與思考解決問題的線索,從而做出可靠的結論(辛自強,2009)。上述案例說明描述在科研中同樣重要。盡管如此,已有實證研究使用個體指向方法進行預測。Asendorpf(2003)比較了兒童4~5歲的大五人格類型(由個體指向方法確定)與維度(由變量指向方法確定)對他們17歲的認知能力和成績的預測作用,發現個體指向的評估對長期預測更有優勢。這啟示未來的個體指向研究者應該更多地形成與檢驗預測。
5.2 方法應用問題
個體指向方法的方法應用問題表現在統計軟件的稀缺與論文發表的障礙兩個方面。
(1) 沒有用戶友好型的統計軟件
標準化的統計分析軟件難以進行個體指向分析,因此有必要使用其他的非標準化的統計軟件。然而,因為學者對非標準化統計軟件需求較低,而且缺少個體指向分析軟件的開發者,因此一直以來都缺少進行個體指向分析的用戶友好型統計軟件包。最初出現的統計軟件包是SLEIPNER(Bergman, Magnusson & El-Khouri, 2003),但是這個軟件并不易于使用。基于模型的個體指向分析可以在一些一般性的統計軟件包中進行,例如Mplus可以實行潛在類別分析、潛在剖面分析和增長混合模型等,但是不能實行聚類分析、配置頻次分析、ISOA和LICUR。
近期,Vargha,Torma和Bergman(2015)開發出ROPstat,這在很大程度上解決了個體指向方法沒有用戶友好型軟件的難題。這個軟件是一個一般性的統計軟件包,它既可以進行方差分析與線性回歸分析等變量指向分析,也可以進行聚類分析與配置頻次分析等個體指向分析。值得一提的是,在個體指向框架內,許多科學問題需要用到許多彼此關聯的分析程序,ROPstat是唯一使得這成為可能的軟件包(Bergman, 2015)。ROPstat的便捷性體現在,數據可以很容易地從SPSS或Excel中導入或導出。研究者可以在網站上(www.ropstat.com)免費下載這個軟件試用版,試用版最多處理5個變量與500個個案。想要處理變量更多與樣本量更大的數據集,可以向作者發送電子郵件來免費獲取注冊碼。對比而言,由于ROPstat不能進行基于模型的個體指向分析,本文建議讀者使用Mplus進行基于模型的分析,使用ROPstat進行其他類型的個體指向分析。
(2) 發表困難與論文影響力低
想要將一篇個體指向的實證論文發表在一家好雜志上,有時候可能遇到困難(Bergman, 2015)。其一,一篇實證論文需要在問題提出部分回顧領域內的已有知識,并在討論部分結合已有知識總結意義。但是相關領域內的大量發現建基于變量指向方法,個體指向方法的發現有時很難與之發生關聯。其二,迫于有限的論文版面,編輯不允許作者過多解釋個體指向方法。因此,大多數不熟悉這種方法的讀者無法從論文中獲取關于該方法的完整知識,也很難用已有知識框架理解這些研究發現。對此,一種可行的解決方案是同時包含變量指向與個體指向方法,陳述個體指向方法提供的重要且不同的知識(Bogat, Leahy, von Eye, Maxwell, Levendosky, & Davidson Ⅱ, 2005; von Eye, Bogat, & Rhodes, 2006)。同時,也需要盡力說服雜志審稿人與編輯接受篇幅較長的個體指向論文。
另一方面,一篇個體指向的實證論文發表后的影響力可能不高。Laursen(2015)以自己的經歷為例說明這個問題:他曾經發表過3篇個體指向的實證論文(Hiatt, Laursen, Mooney, & Rubin, 2015; Laursen, Pulkkinen, & Adams, 2002; Laursen & Hoff, 2006),但發現它們很少被閱讀,這讓他沮喪。事實上,截至2016年8月24日,他提及的2002年與2006年發表的兩篇論文已分別被引用81次和93次,他的另一篇對比變量指向與個體指向方法的論文(Laursen & Hoff, 2006)已被引用225次——這些證據表明上述論文已經具備一定的影響力。此外,個體指向論文的發表情況近年來已有所好轉(Bergman, 2015)。這可能是因為變量指向方法不能解決一些問題,例如個體發展有時只能通過聚焦于個體來理解。
參考文獻
陳亮, 張文新, 紀林芹, 陳光輝, 魏星, 常淑敏 (2011). 童年中晚期攻擊的發展軌跡和性別差異: 基于母親報告的分析. 心理學報, 43(6), 629-638.
紀林芹, 張文新 (2011). 發展心理學研究中個體指向的理論與方法. 心理科學進展, 19(11), 1563-1571.
劉紅云 (2007). 如何描述發展趨勢的差異: 潛變量混合增長模型. 心理科學進展, 15(3), 539-544.
劉堅 (2009). 以個體為中心的分析技術在發展心理學中的應用. 碩士學位論文. 東北師范大學.
邱皓政 (2008). 潛在類別模型的原理和技術. 北京: 教育科學出版社.
王孟成, 畢向陽, 葉浩生(2014). 增長混合模型: 分析不同類別個體發展趨勢. 社會學研究, 4, 220-241.
王碧瑤, 張敏強, 張潔婷, 胡俊 (2015). 基于轉變矩陣描述的個體階段性發展: 潛在轉變模型. 心理研究, 8(4), 36-43.
魏子晗, 詹雪梅, 孫曉敏(2015). 腐敗行為的發展軌跡: 一項潛變量混合增長模型研究. 心理科學, 38(6), 1459-1465.
辛自強 (2009). 發展心理學并非實驗科學. 首都師范大學學報(社會科學版), 191(6), 73-79.
辛自強 (2013). 實證社會科學中的因果關系與理論解釋: 我們需要理解的十對概念. 清華大學教育研究, 34(3), 7-15.
張潔婷, 焦璨, 張敏強 (2010). 潛在類別分析技術在心理學研究中的應用. 心理科學進展, 18(12), 1991-1998.
張志學, 鞠冬, 馬力 (2014). 組織行為學研究的現狀: 意義與建議. 心理學報, 46(2), 265-284.
趙景欣, 劉霞, 申繼亮 (2008). 留守青少年的社會支持網絡與其自尊, 交往主動性之間的關系——基于變量中心和個體中心的視角. 心理科學, 31(4), 827-831.
Asendorpf, J. B.(2003). Head-to-head comparison of the predictive validity of personality types and dimensions. European Journal of Personality, 17(5), 327-346.
Bergman, L. R.(2015). Challenges for person-oriented research: some considerations based on Laursen-s article I don-t quite get it…: personal experiences with the person-oriented approach. Journal for Person-oriented Research, 1(3), 163-169.
Bergman, L. R., & El-Khouri, B. M.(1999). Studying Individual Patterns of Development Using I-States as Objects Analysis (ISOA). Biometrical Journal, 41(6), 753-770.
Bergman, L. R., & Lundh, L. G.(2015). The person-oriented approach: Roots and roads to the future. Journal for Person-oriented Research, 1(1-2), 1-6.
Bergman, L. R., & Magnusson, D.(1997). A person-oriented approach in research on developmental psychopathology. Development and Psychopathology, 9(2), 291-319.
Bergman, L. R., Magnusson, D., & El-Khouri, B. M.(2003). Studying individual development in an interindividual context: A person-oriented approach. Psychology Press.
Bergman, L. R., Nurmi, J. E., & von Eye, A. A.(2012). I-states-as-objects-analysis (ISOA): Extensions of an approach to studying short-term developmental processes by analyzing typical patterns. International Journal of Behavioral Development, 36(3), 237-246.
Block, J.(1971). Lives through time. Berkeley, CA: Bancroft.
Bogat, G. A.(2009). Is it necessary to discuss person-oriented research in community psychology? American Journal of Community Psychology, 43(1-2), 22-34.
Bogat, G. A., Leahy, K., von Eye, A., Maxwell, C., Levendosky, A. A., & Davidson II, W. S.(2005). The influence of community violence on the functioning of women experiencing domestic violence. American Journal of Community Psychology, 36(1-2), 123-132.
Cairns, R. B.(1979). Social development: The origins and plasticity of interchanges. San Francisco, CA: Freeman.
Cramér, H.(1999). Mathematical Methods of Statistics. Princeton, NJ: Princeton University Press.
Crocetti, E., Avanzi, L., Hawk, S. T., Fraccaroli, F., & Meeus, W.(2014). Personal and social facets of job identity: A person-centered approach. Journal of Business and Psychology, 29(2), 281-300.
Garcia, D., MacDonald, S., & Archer, T.(2015). Two different approaches to the affective profiles model: median splits (variable-oriented) and cluster analysis (person-oriented). PeerJ, 3, e1380.
Hiatt, C., Laursen, B., Mooney, K. S., & Rubin, K. H.(2015). Forms of friendship: A person-centered assessment of the quality, stability, and outcomes of different types of adolescent friends. Personality and Individual Differences, 77, 149-155.
Innanen, H., Tolvanen, A., & Salmela-Aro, K. (2014). Burnout, work engagement and workaholism among highly educated employees: Profiles, antecedents and outcomes. Burnout Research, 1(1), 38-49.
Jung, T., & Wickrama, K. A. S.(2008). An introduction to latent class growth analysis and growth mixture modeling. Social and Personality Psychology Compass, 2(1), 302-317.
Kam, C., Morin, A. J., Meyer, J. P., & Topolnytsky, L.(2016). Are commitment profiles stable and predictable? A latent transition analysis. Journal of Management, 42(6), 1462-1490
Kaufman, L., & Rousseeuw, P. J.(1990). Finding groups in data: an introduction to cluster analysis. New York, NY: John Wiley & Sons.
Kelly, J. G., Ryan, A. M., Altman, B. E., & Stelzner, S. P.(2000). Understanding and changing social systems: An ecological view. In J. Rappaport & E. Seidman (Eds.), Handbook of community psychology (pp. 133-159). New York: Springer US.
Kline, R. B. (2015). Principles and practice of structural equation modeling. Guilford publications.
Laursen, B.(2015). I don-t quite get it… personal experiences with the person-oriented approach. Journal for Person-oriented Research, 1(1-2), 42-47.
Laursen, B., Furman, W., & Mooney, K. S.(2006). Predicting interpersonal competence and self-worth from adolescent relationships and relationship networks: Variable-centered and person-centered perspectives. Merrill-Palmer Quarterly, 52(3), 572-601.
Laursen, B., & Hoff, E.(2006). Person-centered and variable-centered approaches to longitudinal data. Merrill-Palmer Quarterly, 52(3), 377-389.
Laursen, B., Pulkkinen, L., & Adams, R. (2002). The antecedents and correlates of agreeableness in adulthood. Developmental Psychology, 38(4), 591-603.
Leiter, M. P., Bakker, A. B., & Maslach, C.(2014). The contemporary context of job burnout. In M. P. Leiter, A. B. Bakker, & C. Maslach (Eds.), Burnout at work: A psychological perspective (pp. 1-9). Hove, Sussex: Psychology Press.
Lin, T. H., & Dayton, C. M.(1997). Model selection information criteria for non-nested latent class models. Journal of Educational and Behavioral Statistics, 22(3), 249-264.
Lubke, G., & Muthén, B. O. (2007). Performance of factor mixture models as a function of model size, covariate effects, and class-specific parameters. Structural Equation Modeling, 14(1), 26-47.
Lundh, L. G. (2015), Combining holism and interactionism: Towards a conceptual clarification. Journal for Person-oriented Research, 1(3), 185-194.
Magnusson, D. (1985). Implications of an interactional paradigm for research on human development. International Journal of Behavioral Development, 8(2), 115-137.
Magnusson, D. (1988). Indiviolual development from an Interactional perspective: A longitudinal study. Lawrence Erlbaum Associates, Inc.
Magnusson, D. (1990). Personality development from an interactional perspective. In L. Pervin (Ed. ), Handbook of personality (pp. 193-222). New York: Guilford.
Magnusson, D.(1999). Holistic interactionism: A perspective for research on personality development. In L. Pervin & O. John (Eds. ), Handbook of personality (pp. 219-247). New York: Guilford.
Magnusson, D. (2001). The holistic-interactionistic paradigm: Some directions for empirical developmental research. European Psychologist, 6(3), 153-162.
Mkikangas, A., & Kinnunen, U.(2016). The person-oriented approach to burnout: A systematic review. Burnout Research, 3(1), 11-23.
Martinez-Torteya, C., Bogat, G. A., Von Eye, A., & Levendosky, A. A. (2009). Resilience among children exposed to domestic violence: The role of risk and protective factors. Child Development, 80(2), 562-577.
Meyer, J. P., & Allen, N. J.(1991). A three-component conceptualization of organizational commitment. Human Resource Management Review, 1(1), 61-89.
Meyer, J. P., & Morin, A. J. S. (2016). A person-centered approach to commitment research: Theory, research, and methodology. Journal of Organizational Behavior, 37(4), 584-612.
Meyer, J. P., Stanley, L. J., & Vandenberg, R. J.(2013). A person-centered approach to the study of commitment. Human Resource Management Review, 23(2), 190-202.
Molenaar, P. C.(2004). A manifesto on psychology as idiographic science: Bringing the person back into scientific psychology, this time forever. Measurement, 2(4), 201-218.
Morin, A. J., Vandenberghe, C., Boudrias, J. S., Madore, I., Morizot, J., & Tremblay, M.(2011). Affective commitment and citizenship behaviors across multiple foci. Journal of Managerial Psychology, 26(8), 716-738.
Muthén, B., & Muthén, L. K.(2000). Integrating person-centered and variable-centered analyses: Growth mixture modeling with latent trajectory classes. Alcoholism: Clinical and experimental research, 24(6), 882-891.
Nylund, K. L., Asparouhov, T., & Muthén, B. O. (2007). Deciding on the number of classes in latent class analysis and growth mixture modeling: A Monte Carlo simulation study. Structural Equation Modeling, 14(4), 535-569.
Rand, W. M.(1971). Objective criteria for the evaluation of clustering methods. Journal of the American Statistical Association, 66(336), 846-850.
Rousseeuw, P.(1987). Silhouettes: a graphical aid to the interpretation and validation of cluster analysis. Journal of Computational and Applied Mathematics, 20(1), 53-65.
Rupp, D. E., Skarlicki, D., & Shao, R.(2013). The psychology of corporate social responsibility and humanitarian work: A person-centric perspective. Industrial and Organizational Psychology, 6(4), 361-368.
Somers, M. J.(2010). Patterns of attachment to organizations: Commitment profiles and work outcomes. Journal of Occupational and Organizational Psychology, 83(2), 443-453.
Sterba, S. K., & Bauer, D. J.(2010). Matching method with theory in person-oriented developmental psychopathology research. Development and Psychopathology, 22(2), 239-254.
Trost, K., & El-Khouri, B. M.(2008). Mapping Swedish females- educational pathways in terms of academic competence and adjustment problems. Journal of Social Issues, 64(1), 157-174.
Vargha, A., Bergman, L. R., & Takács, S.(2016). Performing cluster analysis within a person-oriented context: Some methods for evaluating the quality of cluster solutions. Journal of Person-oriented Research, 2(1-2), 78-86.
Vargha, A., Torma, B., & Bergman, L. R.(2015). ROPstat: a general statistical package useful for conducting person-oriented analyses. Journal of Person-oriented Research, 1(1-2), 87-97.
Vermunt, J. K.(2004). Latent profile model. In M. S. Lewis-Beck, A. Bryman, & T. F. Liao (Eds. ), The sage encyclopedia of social sciences research methods (pp. 554-555). Thousand Oakes, CA: Sage Publications.
Vermunt, J. K., & Magidson, J. (2002). Latent class cluster analysis. In J. Hagenaars, & A. McCutcheon (Eds. ), Applied latent class analysis.(pp.89-106). Cambridge: Cambridge University Press.
von Eye, A., & Bogat, G. A. (2005). Logistic regression and Prediction Configural Frequency Analysis-a comparison. Psychology Science, 47(3/4), 326-341.
von Eye, A., Bogat, G. A., & Rhodes, J. E. (2006). Variable-oriented and person-oriented perspectives of analysis: The example of alcohol consumption in adolescence. Journal of Adolescence, 29(6), 981-1004.
von Eye, A., Mair, P., & Mun, E. Y.(2010). Advances in configural frequency analysis. Guilford Press.
Wasti, S. A.(2005). Commitment profiles: Combinations of organizational commitment forms and job outcomes. Journal of Vocational Behavior, 67(2), 290-308.
Zhang, L., Xin, Z., Ding, C., & Lin, C. (2013). An application of configural frequency analysis: The development of children-s class reasoning. Swiss Journal of Psychology, 72(2), 61-70.