軟件定義網絡中TCP偽擁塞問題探究
2017-02-21 11:45:14邰冬哲
計算機研究與發展 2017年1期
邰冬哲 張 庭 劉 斌
(清華大學計算機科學與技術系 北京 100084)(tdz13@mails.tsinghua.edu.cn)
軟件定義網絡中TCP偽擁塞問題探究
邰冬哲 張 庭 劉 斌
(清華大學計算機科學與技術系 北京 100084)(tdz13@mails.tsinghua.edu.cn)
軟件定義網絡(software-defined networking, SDN)將控制平面與轉發平面分離,通過控制器配置交換機流表項來實現網絡的靈活控制,極大地提高了網絡帶寬利用率.隨著SDN的蓬勃發展,越來越多的高校和公司開始部署SDN.同時SDN也面臨著一些傳統IP網絡中不存在的問題,如一些原本在IP網絡中運行良好的協議在SDN網絡中性能卻受到了嚴重的影響,TCP協議就是其中之一.從SDN的工作機制出發,通過3個場景闡明了SDN在proactive工作模式下依然存在Packet-In短時間內高速并發的可能性.總結并實驗驗證了高速并發的Packet-In以及流表更新時舊表項需重排列的特性都會使數據包在SDN網絡中產生較大時延.實驗結果表明,當TCAM支持4 000個流表項時,最壞情況下僅由新插入流表項優先級原因導致已有流表項的重排列就能使單次傳輸時延達到10 s,并發的高速Packet-In則會使時延加大.以實驗為基礎,揭示了由于SDN網絡特性造成的偽擁塞現象,即傳統TCP在SDN網絡中面臨兩大問題:1)TCP建立連接困難;2)TCP協議傳輸低效.最后通過對實驗現象進行分析,提出了解決SDN網絡中TCP低效問題可能的工作方向.
軟件定義網絡;傳輸控制協議;時延;主動模式;擁塞
① TCAM(ternary content addressable memory)是一種3態內容存儲器,支持wildcard查找,可以在1個時鐘周期內給出查找結果.
為了實現網絡的靈活管理、提高網絡性能、降低管理成本,軟件定義網絡(software-defined networking, SDN)被提出并得到了廣泛的研究.SDN將交換機控制平面(control plane)與數據平面(data plane)分離,利用控制器通過南向接口向數據平面上的流表下載規則(rule),從而指導數據包轉發.由于TCAM①查找速度快且支持wildcard,因此當前大量商用硬件SDN交換機都采用TCAM存放流表[1-2].目前應用最廣泛的南向接口是OpenFlow[3].1條規則可以包含1個或多個字段(field),并伴有對匹配到的數據包進行操作的動作(action).
由于SDN控制器具有集中控制并掌握全局信息的特性,一些在傳統IP網絡中難以處理的問題在SDN中得到了很好的解決[4].由于流表缺失時SDN交換機需要與控制器通信才能指導數據包的轉發,可能造成較大時延,因此研究人員圍繞SDN交換機和控制器開展了很多的測量工作[5-6].通過將SDN的工作模式設定成主動模式,控制器和交換機很多性能問題得以解決.
TCP提供面向連接的傳輸服務,需要經過3次握手才能建立連接.傳統的TCP已經能夠穩定地運行在IP網絡中,面臨的擁塞問題也得到了充分的研究[7-8].但是在SDN網絡中,SDN的網絡特性是否會影響TCP的性能,目前并沒有工作能很好地說明.
本文提出并實驗驗證了SDN網絡中TCP可能存在的偽擁塞現象,并對偽擁塞現象產生的原因進行了深入的分析.偽擁塞現象使得TCP在建立連接時出現問題,同時在TCP連接建立之后可能使傳輸效率降低.在本文第4節,我們提出了解決該問題的可能方法.
1 動機與問題描述
1.1 SDN的工作模式
SDN支持2種工作模式:被動模式(reactive)和主動模式(proactive).
1) reactive工作模式.所謂被動模式,是指任何在交換機流表中找不到匹配項的數據包,都以Packet-In的形式發送給控制器,由控制器根據策略生成流表項后,通過Flow-Mod下發到交換機.在reactive模式下,SDN的網絡管理將會更加靈活.但是交換機的性能很容易受到控制器的處理速度、交換芯片與Local CPU之間的帶寬等因素的影響[5].因此在當前網絡基礎設施下,工業界普遍偏向于proactive的工作模式[1].
2) proactive工作模式.控制器將所有流表項計算出,并提前下發到交換機流表中(盡管該交換機可能還未轉發過該流表項對應的數據包).受TCAM大小所限,如果當前已知的流表項全部提前下發到交換機,需要存放在交換芯片的片上存儲.由于以上原因,TCAM一般充當高速緩存(cache).數據包到達后,先在TCAM中查找,如果沒有匹配則從片上存儲中進行查找轉發.相比于reactive模式,proac-tive模式能在一定程度上解決controller與switch之間通信時延較大的問題.
但是我們觀察到即使SDN網絡工作在proactive模式下,也無法完全避免交換機產生Packet-In.為驗證這一結論,以下列舉了工作在proactive模式下短時間內快速產生Packet-In的3種情況.
情況1. 動態主機配制協議(dynamic host configuration protocol, DHCP)導致Packet-In快速產生.由于IP地址數量有限,很多網絡(如清華大學校園網)都采用DHCP的工作模式,即相同的IP在不同的時間點可能分配給不同的用戶.在SDN網絡中,新的用戶接入到網絡時,必須要通過Packet-In產生DHCP請求來獲取IP地址.在基于SDN的無線網絡中這種現象尤其嚴重,移動用戶從1個無線區域A移動到無線區域B,IP地址將會被重新分配,這時移動用戶將會再次產生Packet-In進行DHCP請求.在網絡規模較大、用戶較多的情況下,DHCP有可能造成Packet-In的高速并發.
情況2. 虛擬機批量遷移.由于主機資源不足等原因,經常需要對虛擬機進行遷移,從1臺主機遷移到另外1臺主機.當前的虛擬化工具都提供遷移組件(如VMware,Xen,KVM等),這種情況在數據中心網絡中經常出現.在SDN網絡中,虛擬機的批量遷移需要密集地產生Packet-In來完成舊流表項的失效和新的流表項的建立過程.
情況3. SDN主要的功能就是實現網絡的靈活控制,SDN網絡中控制器上很多應用都需要結合網絡實時信息(如鏈路利用率)來制定策略.如文獻[9]中的負載均衡(load balance)策略需要交換機不斷地將鏈路利用率等信息上傳到控制器.此時,無疑將產生實時的、持續的Packet-In分組到控制器.
1.2 SDN性能瓶頸分析
圖1展示了SDN交換機數據包處理流程.數據包從端口1進入交換機,交換芯片將分組頭送入TCAM上的流表進行查找,找到則根據相應的action進行操作.如果在TCAM中沒有相應的匹配項,則交換芯片將數據包上傳到Local CPU,Local CPU將數據包封裝成Packet-In,通過交換機上的OpenFlow Agent上傳到控制器.控制器通過其處理邏輯下發Flow-Mod到交換機上的OpenFlow Agent,進而傳到交換芯片將其插入到流表,指導后續數據包轉發.
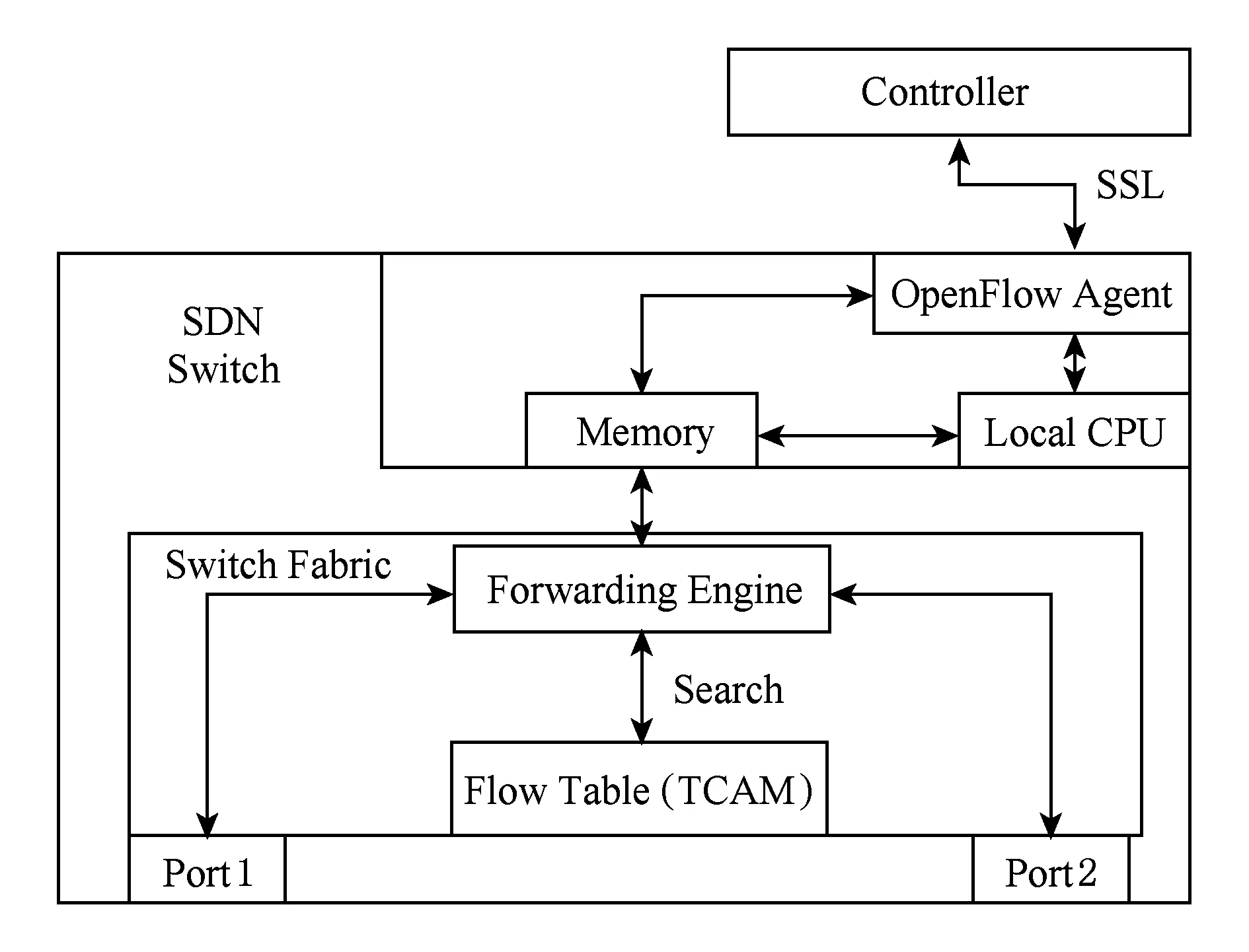
Fig. 1 Processing flow chart for arrival packets in SDN圖1 SDN交換機中數據包處理流程
從整體角度看,在SDN網絡中有很多因素可能導致數據包在1個交換機中處理時延較大.總結起來有如下5點:
1) 當網絡拓撲在某1段時間變動較大且會產生很多DHCP請求,或者用戶定制的策略導致交換機需要不斷通過Packet-In將網絡實時信息上傳到控制器時,可能使交換機上Local CPU的計算能力或者Local CPU與交換芯片的帶寬成為瓶頸,造成時延較大.本文第3節的實驗結果表明,單個交換機上400個Packet-In以1 000 pps(packets per second)的速度產生時可引起高達1.4 s的時延.
2) TCAM上規則變化耗時較長導致時延增大.He等人[5]的工作表明,TCAM中的表項發生更新會對轉發時延產生較大的影響.當規則優先級按照一定規律變化時,時延變大的現象尤其明顯.造成這種現象的主要原因是TCAM中需要保留規則的重排列.本文第3節的測量結果顯示,當TCAM的大小達到4 000個表項時,插入1條流表項在最壞情況下能引發高達9.52 s的時延.
3) 控制器與交換機之間SSL鏈接通信性能不理想造成時延.
4) 控制器上用戶App排隊時延較大,導致Flow-Mod生成時間較長,使得數據包等待時延過大.
5) 鏈路擁塞等因素造成時延較大.這些因素在IP網絡中也同樣存在,鑒于該因素不是SDN網絡特有的問題,本文的研究中暫不予考慮.
采用proactive模式解決了以上因素3和因素4這2種因素造成時延較大的問題.在proactive工作模式下,由于產生Packet-In的數目顯著減小,因素1所帶來的壓力減輕.但在一些特殊情況下,如特殊的策略要求、網絡拓撲變化較頻繁時,因素1仍然可能成為系統性能的制約因素.
受TCAM大小限制,不可能所有流表項都放在TCAM中,因此無論proactive還是reactive模式,TCAM中的流表項都會頻繁地換入換出,因此因素2都將會成為時延較大潛在的原因[10].以清華大學校園網為例,共70 000端口、2 700無線熱點、10萬用戶終端.根據對清華網關截取的Trace進行分析,以5元組標識的并發流可以達到兆級別.在這種網絡規模下,即使采用proactive工作模式,商用TCAM仍然無法存儲所有流表項,流表項仍將會從TCAM中頻繁地換入換出,造成很大的時延.
1.3 SDN中TCP面臨的問題
TCP提供面向連接的、可靠的網絡傳輸服務.由于SDN的網絡特性,TCP在SDN網絡中面臨著其在IP網絡中不會出現的問題.SDN網絡的一些特點,使得數據包可能在鏈路輕負載的情況下使數據包產生較大的時延,導致TCP端節點誤認為鏈路產生擁塞,從而對TCP性能產生較大的影響,本文稱之為偽擁塞現象.
SDN對TCP性能的影響主要包括2部分:TCP建立連接困難與TCP傳輸效率低下.
1) TCP建立連接困難
如圖2所示,TCP在通信前必須通過3次握手建立連接[11].客戶端發出SYN數據包的同時設定了1個計時器,當計時器歸零時如果服務器端的SYN+ACK包沒有返回,客戶端將再次發送SYN數據包建立連接,同時計時器的設定值不斷變大.服務器端發送SYN+ACK后也會設定相應的計時器,計時器超時后也會造成SYN+ACK數據包重傳.
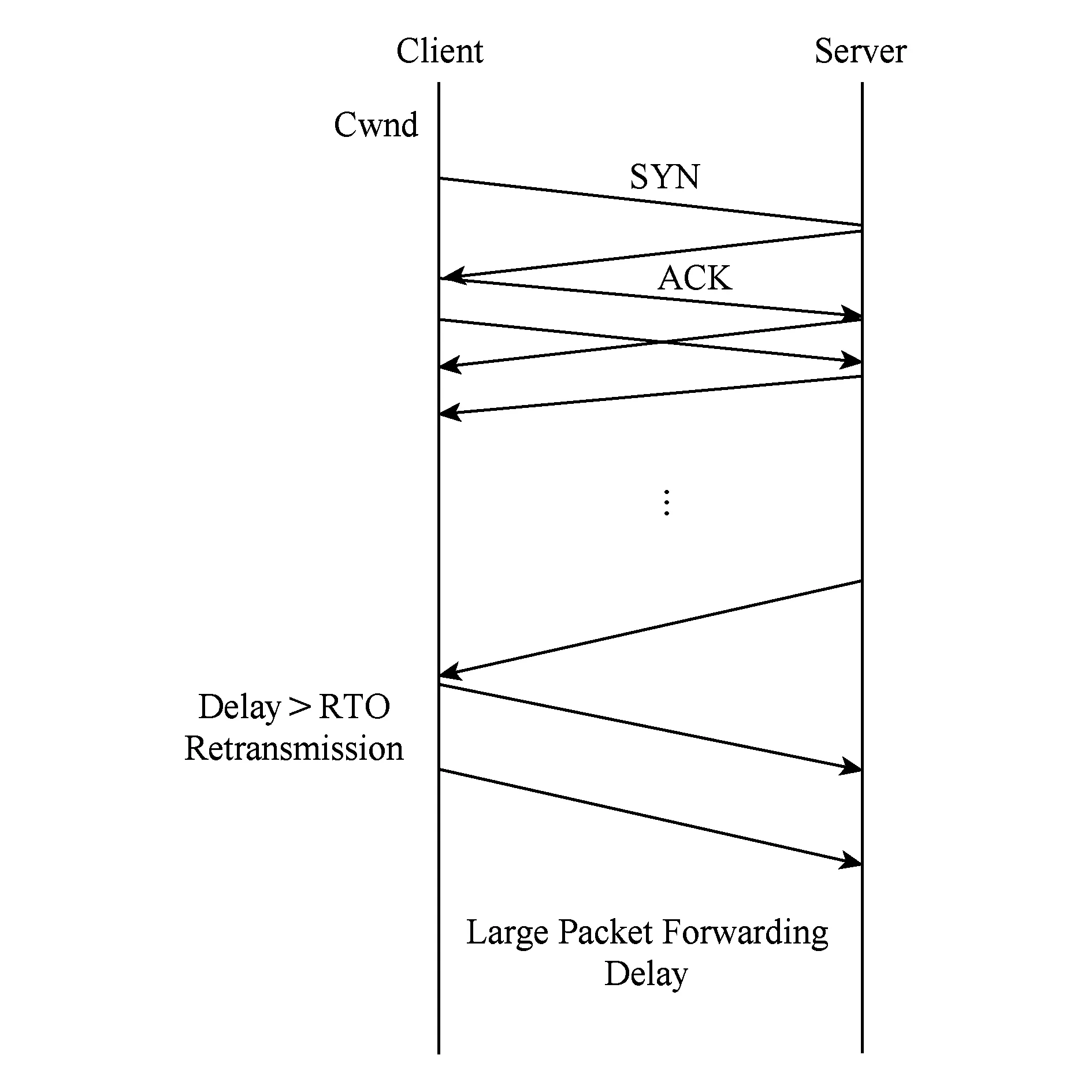
Fig. 2 TCP working principles圖2 TCP工作原理圖
由于建立TCP連接的握手包較小,在傳統IP網絡中(特別是在輕負載情況下)一般不會造成握手包重傳.但是在SDN網絡中,即使網絡狀況很好,TCAM的更新以及Packet-In并發等原因也都可能造成小數據包產生很大時延,從而導致握手包被多次重傳.
本文第3節的測量結果表明,即使在同1個SDN網絡中最簡單的拓撲情況下,僅由于流表項的重排列就有可能使得數據包往返時延(round-trip time, RTT)達到將近20 s,而短時間的Packet-In并發產生現象有可能會加大時延,因此在SDN網絡中很有可能TCP多次嘗試連接才能成功.
2) TCP傳輸效率低下
在商用的SDN交換機中,由于TCAM價格昂貴導致其規模無法做到很大(一般為幾千個).因此無論在proactive模式還是reactive模式下,流表中的表項都需要動態地換入換出.網絡中產生Packet-In數目較大或者換入的流表項由于優先級原因導致舊表項需要遷移時,則會造成TCP數據包的時延急劇增加,進而造成復原時間目標(recovery time objective, RTO)超時重傳.
TCP自身具有擁塞控制能力[12],能夠根據數據包返回信息動態地調整發送窗口大小.但在SDN網絡中,即使鏈路狀況良好,也可能造成RTT時間較長,使終端誤判網絡擁塞,從而使得窗口減小,甚至有可能長時間維持在1,這樣就可能會極大地降低TCP的傳輸性能.
2 SDN時延影響因素分析及驗證
2.1 實驗參數
實驗采用了PICA8 3297交換機,TCAM擁有4 000個表項,在流表匹配時轉發時延平均為50 μs.控制器為floodlight,OpenFlow協議為v1.0,運行在Ubuntu 12.04 LTS上.發包程序由libnet實現,抓包程序由libpcap實現,編寫語言為C.實驗拓撲如圖3所示:
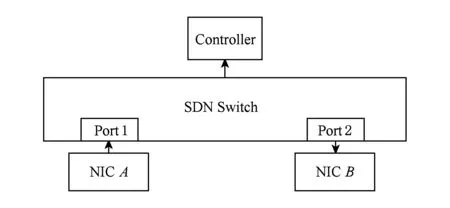
Fig. 3 Measurement topology for testing SDN packet delay圖3 測量SDN數據包時延的拓撲圖
如1.2節所述,通過采用proactive模式,將所有流表項存放到交換芯片的存儲上,使得以上因素3和因素4這2點問題不存在.2.2節和2.3節主要通過實驗驗證高速并發Packet-In以及流表項優先級對時延的影響.
2.2 高速Packet-In對時延的影響
在SDN控制平面與轉發平面分離的情況下,為了展示網絡瓶頸所在,我們測量了新流(hit-miss)在各個環節的時延分布情況,實驗拓撲圖同樣如圖3所示.
初始流表為空,網卡A按照指定的速度發出新流到SDN交換機,由于在流表中沒有找到匹配項,交換機會產生相應數目的Packet-In.控制器根據流表生成策略生成Flow-Mod,下發到交換機,TCAM裝載相應流表項指導后續數據包到達網卡B.網卡B接收相應的數據包計算時延.由于每個流只含有1個數據包,因此發送數據包的速度可被認為是產生Packet-In的速度.
令Ts為網卡A捕獲數據包x的時間,Tr為網卡B捕獲數據包x的時間,總傳輸時延為Tt=Tr-Ts.設控制器上捕獲x對應的Packet-In的時間為Tp,控制器網卡捕獲Flow-Mod的時間為Tf,則控制器上的處理時延為Tc=Tf-Tp.設定總的新流數目為400,隨著并發速度從10 pps增長到5 000 pps,各個環節的平均時延分布如表1所示.每個數據流的時延情況如圖4所示.
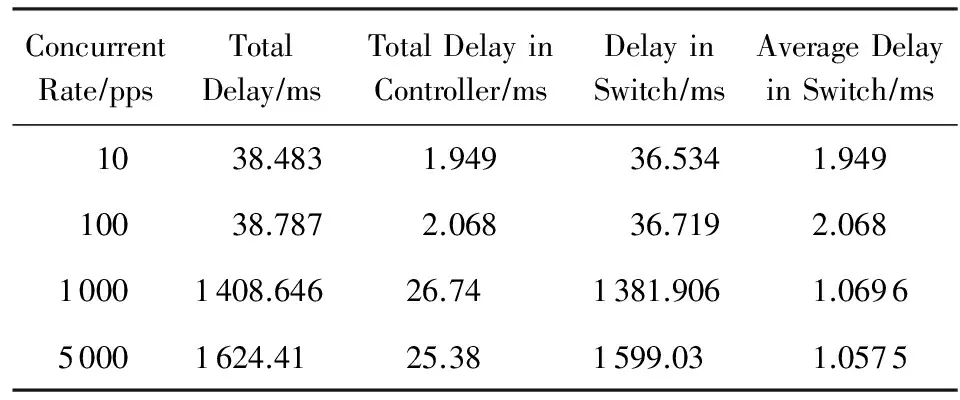
Table 1 Delay Distribution When Table Miss

Fig. 4 Packet delay in specific new flow generate rate圖4 一定速度下新流的時延
數據顯示,新流總數一定時,隨著新流的并發速度加快,數據包的平均時延不斷增大.在5 000 pps速度下,最大時延達1.624 s.隨著并發速度的提高,交換機上Packet-In會批量上傳到控制器,造成一些數據包總的時延變長.如表1中,當速度達到5 000 pps時,Packet-In在控制器上的平均耗時為25.38 ms,這是因為有25個Packet-In在交換機上按組上傳到控制器,25.38 ms為控制器處理25個Packet-In的時間.控制器處理每個新流的平均時延基本沒變,均為1~2 ms.
通過對圖4進行分析,發現新流產生速度較快時,如1 000 pps,5 000 pps,數據包時延呈現階梯式增長;當速度較慢時,數據包時延抖動很劇烈,如在速度為10 pps,100 pps的情況下.后續的所有時延相關的實驗都展示了這種特點.
這一現象很可能是由于交換機處理Packet-In的策略造成的:Packet-In達到一定數目時,再上傳到控制器;如果超過一定長度的等待時間,即使沒有達到相應的數目,也要上傳到控制器.這樣,發送較慢時,Packet-In產生速度未觸及瓶頸,但抖動很大,數據包時延呈周期性變化;當發送較快時,超出Packet-In產生瓶頸,排隊時間越來越長,時延呈階梯狀增長.
當并發速度加快時,總體時延Tt顯著變大,但是控制器處理每個新流的平均時延幾乎沒變.說明當Packet-In較小且并發速度在一定范圍內時,SDN瓶頸是在交換機而不是在控制器.為了驗證這種觀點,我們用CBench工具[13]對控制器進行了測試.為了避免控制器與交換機之間通信性能的干擾,在floodlight所在主機上配置了CBench.測試模擬了16臺交換機,每臺交換機虛擬連接了1 000臺主機,進行10次循環測試,每次循環測試持續10 s,時延測試在吞吐量模式下進行.實驗結果顯示,10組測試結果中最小吞吐量為360 817.77次s,最大吞吐量為403 931.03次s,平均也有390 514.08次s,這說明在本文實驗范圍內的Packet-In速度下,controller生成和下發規則的能力不會成為系統瓶頸.
2.3 流表項優先級變化對時延的影響
為了測量TCAM中流表項優先級在更新時對數據包時延的影響,基于拓撲圖3進行了流表項優先級相關的實驗.設初始情況下TCAM流表為空,共4 000個新流,每個新流包含1個數據包.數據包以10 pps的速率按照優先級依次遞增、遞減、不變3種模式發出,最終得出實驗結果如圖5所示.
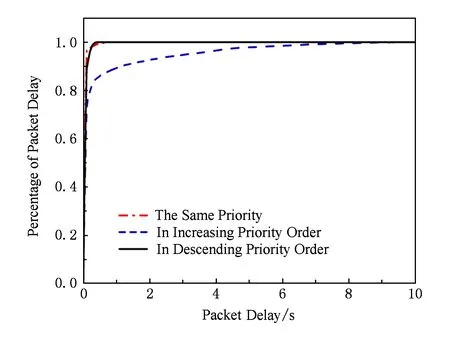
Fig. 5 Packet delay in three kinds of flow entries priority change mode when rate=10 pps圖5 rate=10 pps時3種流表項優先級變化的時延
實驗結果表明,當插入的流表項優先級不變或者優先級遞減時,處理時延幾乎不變.但是在插入優先級遞增時,隨著插入流表項數量的增加處理時延顯著變大,最大可達到9.648 s.
調研結果顯示,不同的交換機TCAM中流表項的組織方式不同[5].PICA8的白盒交換機采用Boradcom公司的交換芯片.該交換芯片在TCAM中按優先級從高到低組織流表項.當流表項優先級隨著插入順序遞增時,每1個插入的流表項優先級都要比TCAM中已有的流表項優先級高.當TCAM中流表項達到一定規模后,新插入的流表項會導致大量已有表項的移動,從而造成較大延時.
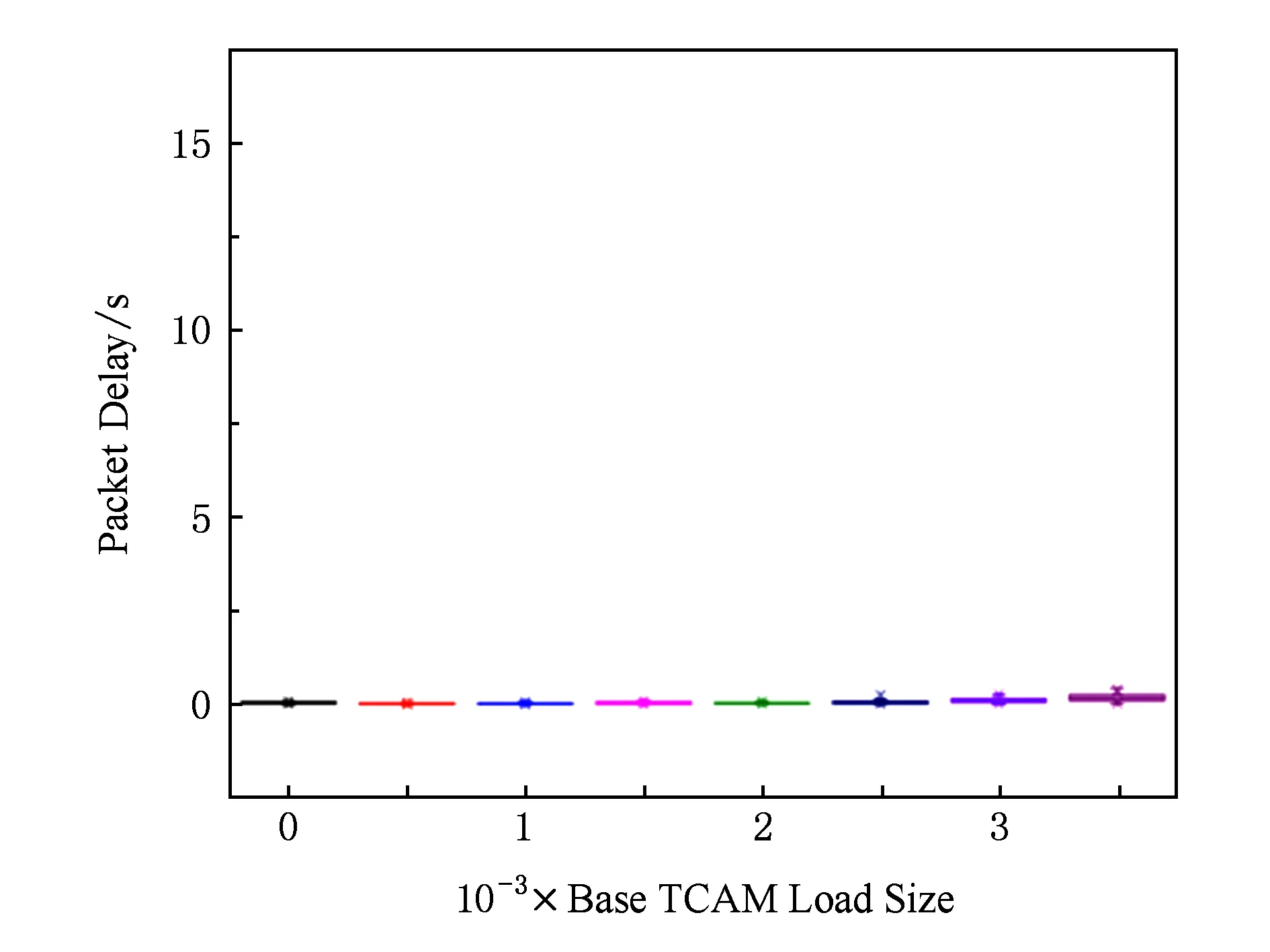
為了更直觀地展示實驗結果,我們進行了更進一步的實驗.設定TCAM流表中已有指定數目的流表項,然后分別按照不變、降序、升序的優先級順序發送100個新流,發送速度為10 pps,統計相應的時延情況,分別如圖6~8所示.

rate=10 pps,num=100Fig. 6 Packet delay with the same priority圖6 優先級不變、不同表規模的數據包時延
圖6~8中的數據顯示,隨著基礎表項不斷增加,優先級遞增的實驗組延遲明顯增加.相比而言優先級不變或者減小的實驗組則變化很小,實驗結果驗證了上述觀點.
交換機時延與優先級的特性很大程度上依賴于交換芯片對TCAM中流表的組織形式.如果交換芯片按照低優先級在前,那么實驗結果將完全相反.同時值得注意的是,即使在proactive模式下,也必將伴隨著頻繁的換入換出,也會因為優先級的原因造成相應的時延.已有算法會對流表的數據結構進行改造[4,14],可以降低流表中表項的移動次數,但是這是以降低存儲的利用率和增加算法的復雜度為代價的,同時也不能完全避免流表中表項的移動.因此,本文提到的問題依舊存在.
rate=10 pps,num=100Fig. 7 Packet delay when the priority decreases圖7 優先級遞減、不同表規模的數據包時延
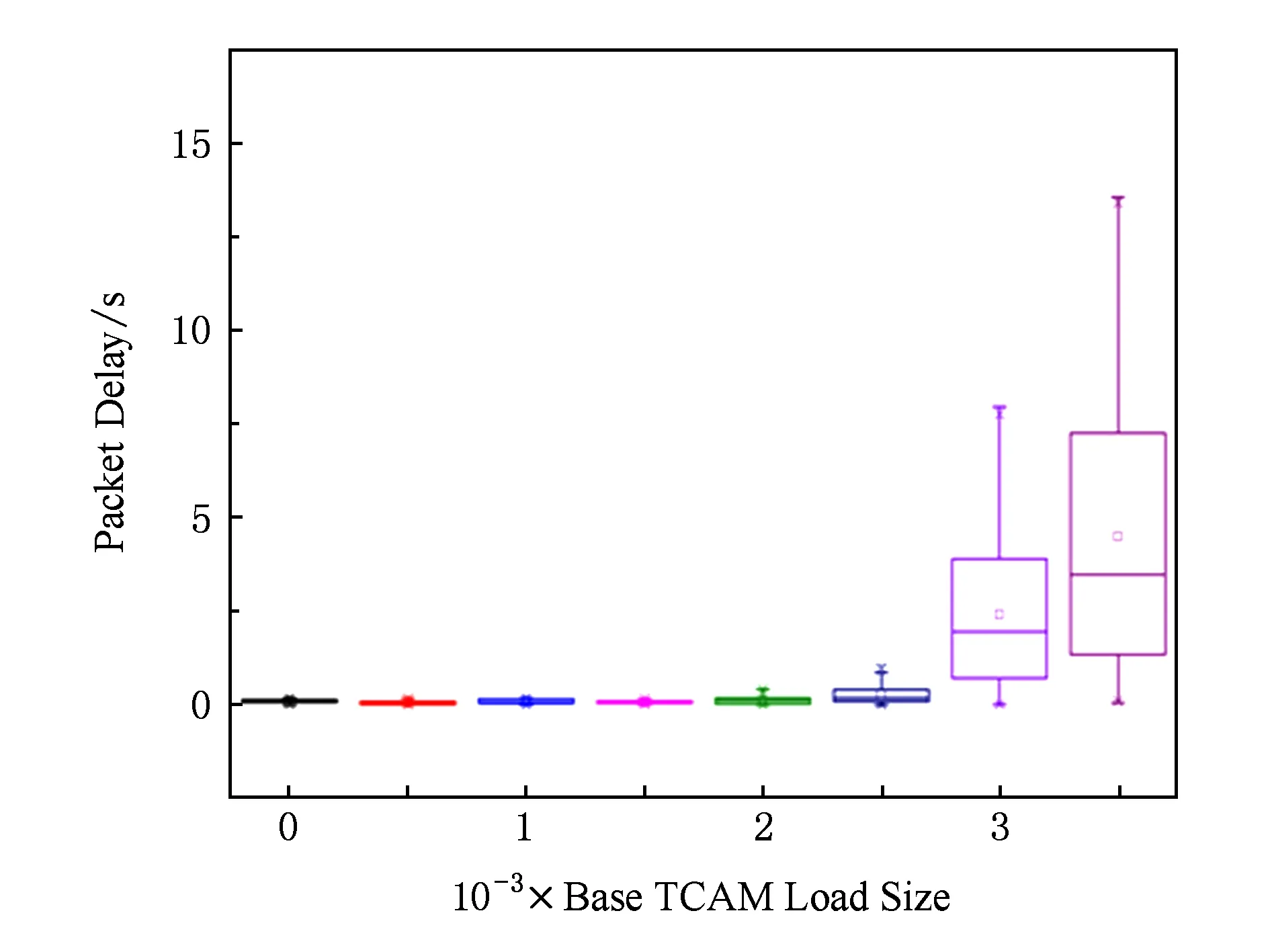
rate=10 pps,num=100Fig. 8 Packet delay when the priority increases圖8 優先級遞增、不同表規模的數據包時延
3 對TCP的針對性測量分析
如1.3節所述,SDN工作模式可能為TCP帶來2類問題,分別為建立連接困難與傳輸低效.
在建立連接時,客戶端在第i(i=1,2,3…)個SYN數據包發出后,如果在Di時間內還未收到SYN+ACK,將會再次發送SYN數據包.在伯克利系統中D1即首次重發時間為5.8 s,D2=24 s,最大值為75 s[15].
在連接建立后,TCP進行數據傳輸.發送端第j次發送的數據包在Ej(j=1,2,…)時間內還未收到接收方反饋,發送端將會判斷鏈路出現擁塞,發送窗口將以“線性加、乘性減”為原則劇烈減小,從而影響發送性能.實際上,此時很有可能不是真正發生擁塞,只是上述SDN網絡特性導致時延很大,造成偽擁塞.伯克利系統實現版本之一E1=1.5 s,E2=3 s,依次倍增,最大值為64 s[15].
3.1 對TCP建立情況的分析
為了準確描述TCP建立連接在SDN網絡中所面對的問題,我們按照拓撲圖3進行了握手過程中往返時延的測量.在rule優先級遞增的情況下,網卡A向網卡B按照指定的速度發送250個SYN,網卡B收到后立刻對網卡A返回1個相應的SYN+ACK,忽略主機協議棧耗時統計往返時延.
從圖9,10,11可知,在流表項優先級隨插入順序遞增時,TCAM中原有流表項數目達到一定規模后,相同的并發速度下往返時延呈階梯式增長.同時,由圖12~15可見,隨著速度增加,時延在不斷地變大.根據第2節的實驗結果分析,在上述負載情況下,控制器上時延很小,絕大多數時延消耗在交換機上.

Fig. 9 RTT when TCAM load=500 and rules priority increases圖9 TCAM load=500優先級遞增時的往返時延

Fig. 10 RTT when TCAM load=2 000 and rules priority increases圖10 TCAM load=2 000優先級遞增時的往返時延
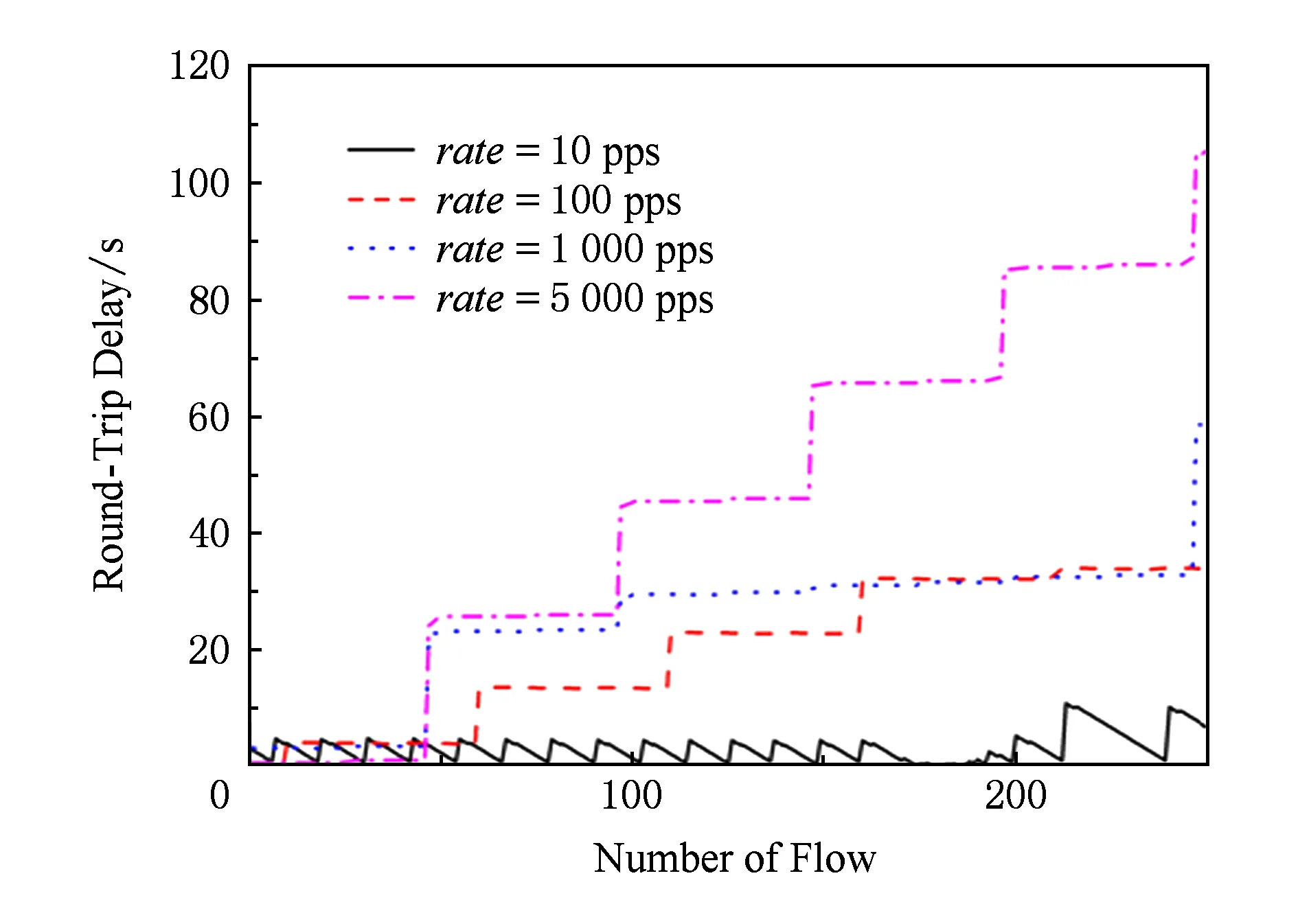
Fig. 11 RTT when TCAM load=3 500 and rules priority increases圖11 TCAM load=3 500優先級遞增時的往返時延

Fig. 12 RTT when Packet-In rate=10 pps圖12 Packet-In rate=10 pps不同流表規模往返時延
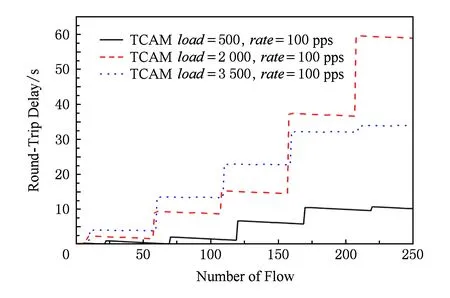
Fig. 13 RTT when Packet-In rate=100 pps圖13 Packet-In rate=100 pps不同流表規模往返時延
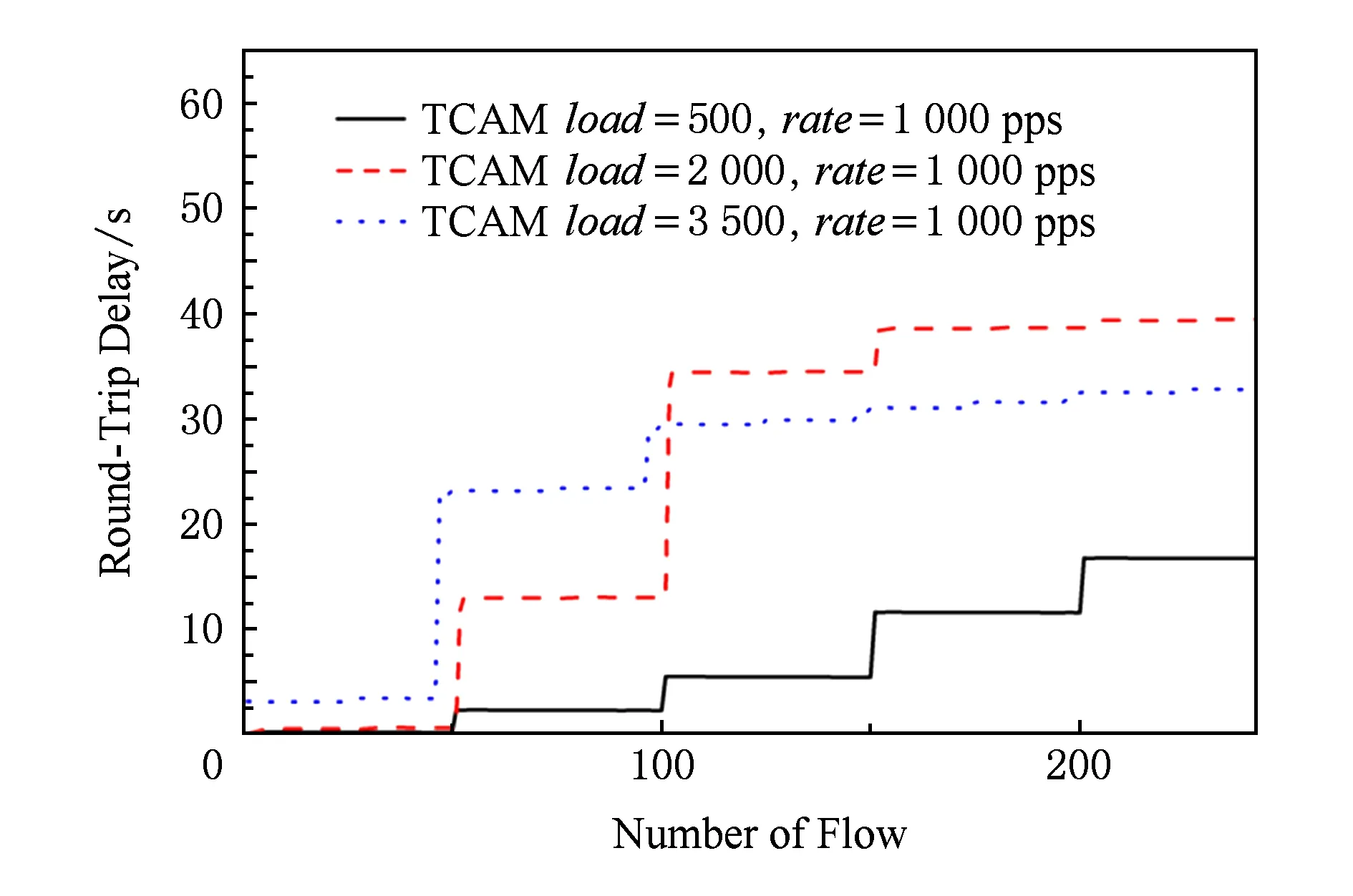
Fig. 14 RTT when Packet-In rate=1 000 pps圖14 Packet-In rate=1 000 pps時不同流表規模往返時延
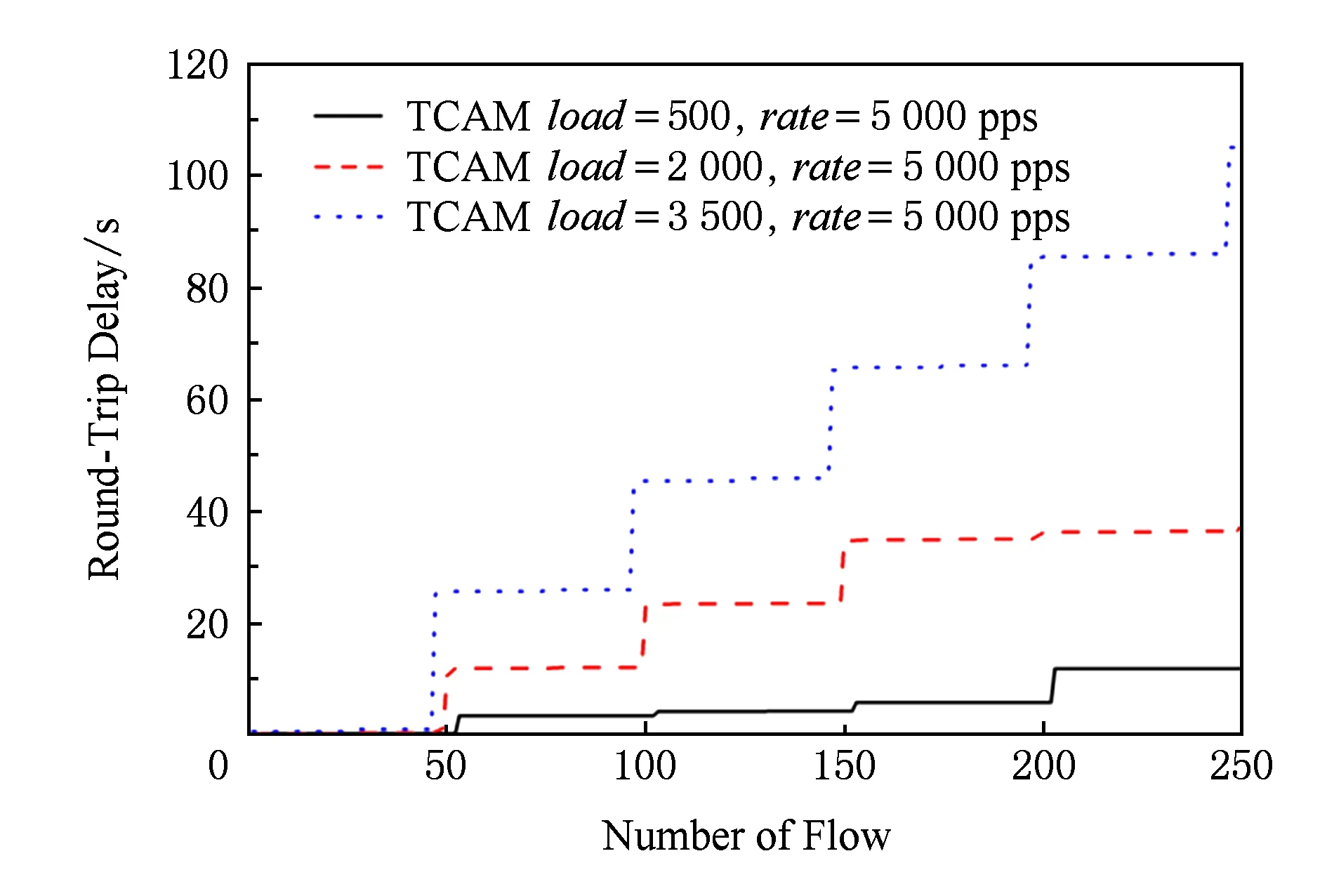
Fig.15 RTT when Packet-In rate=5 000 pps圖15 Packet-In rate=5 000 pps時不同流表規模往返時延
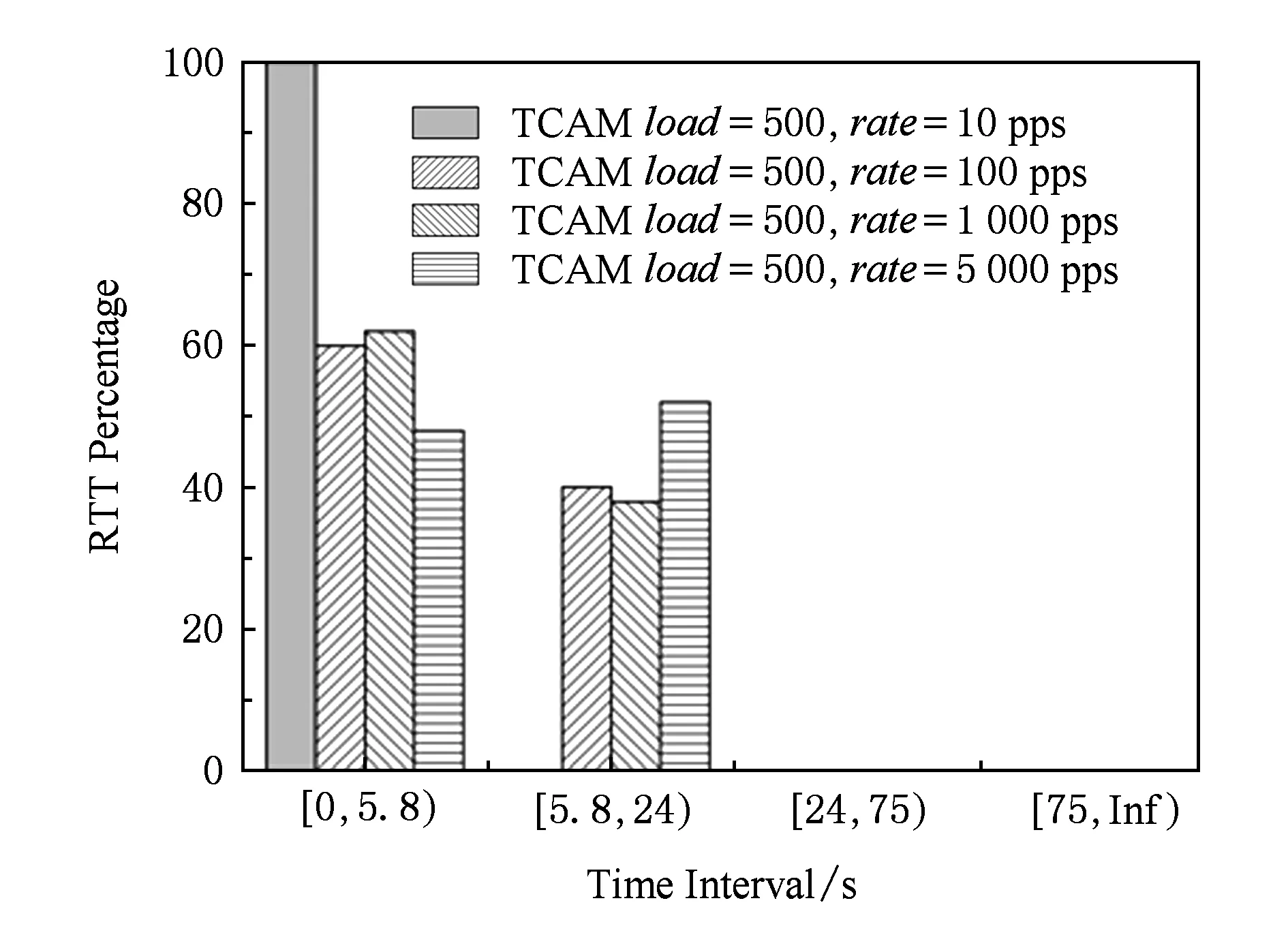
Fig. 16 RTT distribution figure when TCAM load=500圖16 TCAM load=500時不同速度下往返時延分布圖

Fig. 17 RTT distribution figure when TCAM load=2 000圖17 TCAM load=2 000時不同速度下往返時延分布圖

Fig. 18 RTT distribution figure when TCAM load=3 500圖18 TCAM load=3 500時不同速度下往返時延分布圖
按照伯克利系統實現參數進行分析,首先在優先級遞增情況下,不同并發速度對應的往返時延分布直方圖分別如圖16~18所示.當并發速度為10 pps,TCAM中已有流表項為500和2 000個流表項的情況下,所有數據包的往返時延都在5.8 s內,即所有的TCP握手數據包都能在初始RTO(5.8 s)內返回而不必重傳.當并發速度為10 pps、初始流表項為3 500個時,單次數據包的往返時延有10%超出了5.8 s,即需要再次發送握手包.在10 pps的Packet-In速度下,隨著基礎流表裝載規模變大,圖16~18這3幅直方圖相比分布重心不斷右移,說明往返時延不斷增大,成功建立連接發送握手包的期望次數不斷變大.同時,在一定基礎流表裝載規模下,同一張分布直方圖的重心也在右移,說明在基礎流表裝載規模一定時,隨著Packet-In速度加快,成功建立連接需要發送的SYN數據包的期望數目不斷增大.以基礎流表裝載規模為3 500個表項為例,當建立連接速度為10 pps時,處于0~5.8 s,5.8~24 s,24~75 s,75~Inf的數據包占比分別占比90%,10%,0%,0%,隨著Packet-In產生速度加快,0~5.8 s即不需重傳的數據包占比不斷減小,同時需要重傳的數據包占比不斷增大.當Packet-In速度達到5 000 pps時,這一比例已經分別達到20.4%,0%,60%,19.6%.即不需重傳的握手包只占20.4%,且有19.6%的數據包超過了75 s,最高達105.51 s,存在無法完成TCP連接建立的可能性.
值得注意的是,TCP連接需要經過3次握手才能建立,所以在建立過程中很有可能發生多次重傳,造成建立連接困難.
3.2 對TCP傳輸性能的分析
TCP連接建立后TCAM中存在對應的流表項.在規模稍大的網絡中,并發流的數目可以達到幾兆甚至幾十兆(如清華校園網2011年并發流就達到兆級別),TCAM中的流表項會被頻繁地換入換出.換入的過程中由于優先級造成的表項移動或者其他新流的產生,都會使TCP傳輸數據產生較大時延,超出RTO后可能導致TCP發送窗口減小,甚至有可能退化成停等協議,從而影響TCP的性能.
我們按照拓撲圖3進行了數據發送過程中往返時延的模擬測量.在規則(rule)優先級遞增的情況下,網卡A向網卡B按照指定的速度發送250不同的流,每個流包含1個數據包,網卡B收到后立刻給網卡A返回1個相應的ACK,忽略主機協議棧耗時統計總的往返時延.初始流表里的流表項都不能匹配這些流,需要在交換芯片的片上存儲中進行查找,換入TCAM.統計TCP發送實驗中從數據包發出到ACK返回時間間隔如圖19所示:
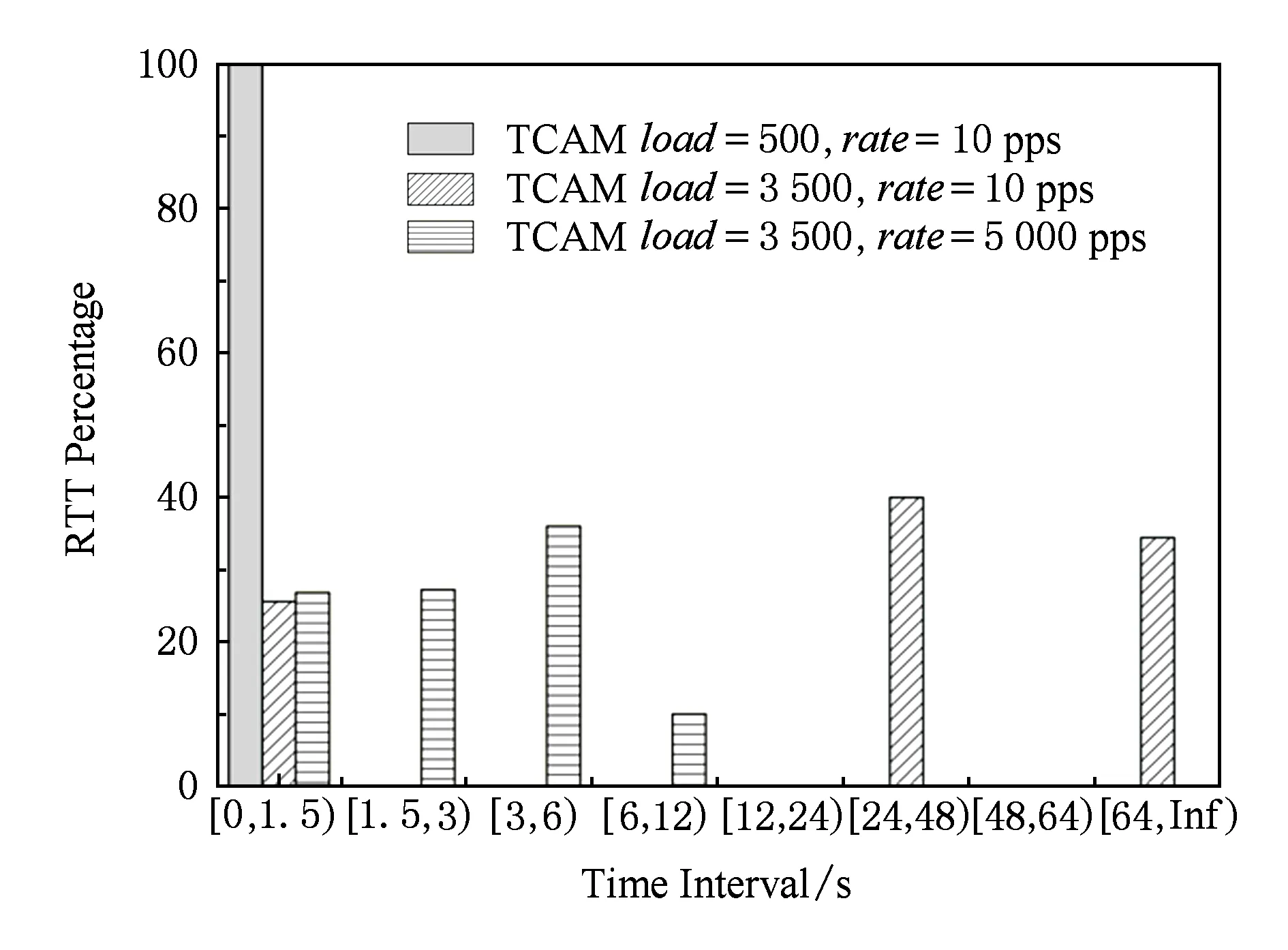
Fig. 19 RTT distribution diagram圖19 往返時延分布圖
通過對圖19的數據進行分析,在初始流表裝載3 500個流表項時,在10 pps的發送速度下有73.2%的可能性會產生重傳或者多次重傳;在2 500個流表裝載、5 000 pps發送速度的情況下,有些數據包甚至超出了最長等待時間75 s.重傳造成窗口不斷減小,使得TCP一直處于低效的工作狀態.
在3.1節和3.2節的實驗中,我們在1個SDN網絡中最簡單的拓撲情況下進行了實驗,發現TCP面對各種問題.在實際網絡中,TCP連接可能要在多個SDN自治域之間建立,經歷多個交換機和控制器,因此TCP所面臨的問題將會更加嚴重.
4 總 結
實驗結果表明:SDN網絡中TCP產生偽擁塞主要由交換機造成.無論主動模式還是被動模式,SDN網絡由于Packet-In短時間內高速并發、優先級不同導致流表項大規模移動等原因,都會導致基于TCP的鏈接產生偽擁塞現象,造成性能下降.
SDN網絡中數據包時延較大的原因,一方面是由于SDN交換機的處理速度跟不上Packet-In的產生速度,主要瓶頸體現在交換機的Local CPU性能較低以及CPU與交換芯片之間的帶寬限制[5],因此需要不斷提高CPU性能和傳輸帶寬,同時盡量減少二者之間的通信,如將頻繁訪問的流表放在交換芯片的片內存儲中而不是放在Local CPU管理的內存中;另一方面原因是由交換芯片對TCAM的流表項組織方式造成的.探究如何組織TCAM上的表項,使其最大限度地降低流表項優先級特征造成的時延也成為我們下一步工作的重點.
最后,可以從TCP協議本身入手.實驗結果顯示,當前的TCP在SDN中很容易產生RTO超時,“線性加、乘性減”的窗口變化原則在SDN中是否依舊適用?如何更好地設計適用于SDN-TCP的RTO?如何設計適用于SDN網絡的TCP窗口變化模式?也是未來我們研究的工作重點.
[1]Big Switch. Modern OpenFlow and SDN[EBOL]. [2015-12-15]. http:www.bigswitch.comblog20140502modern-openflow-and-sdn-part-i
[2]Pica8. PicOS OpenFlow[EBOL]. [2015-12-15]. http:www.pica8.comwp-contentuploads201509openflow-tutorials-1.pdf
[3]McKeown N, Anderson T, Balakrishnan H, et al. OpenFlow: Enabling innovation in campus networks[J]. ACM SIGCOMM Computer Communication Review, 2008, 38(2): 69-74
[4]Yan Bo, Xu Yang, Xing Hongya, et al. CAB: A reactive wildcard rule caching system for software-defined networks[C]Proc of the 3rd Workshop on Hot Topics in Software Defined Networking. New York: ACM, 2014: 163-168
[5]He Keqiang, Khalid J, Gember-Jacobson A, et al. Measuring control plane latency in SDN-enabled switches[C]Proc of the 1st ACM SIGCOMM Symp on Software Defined Networking Research. New York: ACM, 2015: 25-30
[6]Jiang Guolong, Fu Binzhang, Chen Mingyu, et al. Survey and quantitative analysis of SDN controllers[J]. Journal of Frontiers of Computer Science and Technology, 2014, 8(6): 653-664 (in Chinese)(江國龍, 付斌章, 陳明宇, 等. SDN控制器的調研和量化分析[J]. 計算機科學與探索, 2014, 8(6): 653-664)
[7]Luo Wanming, Lin Chuang, Yan Baoping. A survey of congestion control in the Internet[J]. Chinese Journal of Computers, 2001, 24(1): 1-18 (in Chinese)(羅萬明, 林闖, 閻保平. TCPIP 擁塞控制研究[J]. 計算機學報, 2001, 24(1): 1-18)
[8]Jiang Wengang, Sun Jinsheng, Wang Zhiquan. A random back-off TCP congestion control algorithm[J]. Acta Electronica Sinica, 2011, 20(7): 1689-1692 (in Chinese)(姜文剛, 孫金生, 王執銓. 隨機回退的 TCP 擁塞控制算法[J]. 電子學報, 2011, 20(7): 1689-1692)
[9]Namal S, Ahmad I, Gurtov A, et al. SDN based inter-technology load balancing leveraged by flow admission control[C]Proc of the 8th Future Networks and Services. Piscataway, NJ: IEEE, 2013: 1-5
[10]Miao Rui, Zafar A Q, Cheng-Chun Tu, et al. SIMPLE-fying middlebox policy enforcement using SDN[J]. ACM SIGCOMM Computer Communication Review, 2013, 43(4): 27-38
[11]Padhye J, Firoiu V, Towsley D F, et al. Modeling TCP Reno performance: A simple model and its empirical validation[J]. IEEEACM Trans on Networking, 2000, 8(2): 133-145
[12]Jacobson V. Congestion avoidance and control[J]. Communication Review, 1988, 32(4): 314-329
[13]Sherwood R, Kok-Kiong Y A P. CBench: An open-flow controller benchmarker[JOL]. 2010 [2013-05-13]. http:www.openflow.orgwkIndex.phpOflops
[14]Zhang Bin, Yang Jiahai, Wu Jianping, et al. Efficient searching with parallel TCAM chips[C]Proc of the 35th Local Computer Networks (LCN). Piscataway, NJ: IEEE, 2010: 228-321
[15]Wright G R, Stevens W R. TCPIP Illustrated[M]. Upper Saddle River, NJ: Addison-Wesley Professional, 1995

Tai Dongzhe, born in 1990. Received his BSc degree in computer science and technology from Tsinghua University, Beijing, China in 2013. MSc from Tsinghua University, Beijing, China. His main research interests include SDN and NDN.

Zhang Ting, born in 1990. PhD candidate at the Department of Computer Science and Technology, Tsinghua University. His main research interests include high performance switchesrouters and software-defined networking (zhangting825@gmail.com).

Liu Bin, born in 1964. Received his MSc and PhD degree in computer science and engineering from Northwestern Polytechnical University, Xi’an, China in 1988 and 1993, respectively. Currently professor and PhD supervisor of Tsinghua University, Beijing, China. Member of CCF. His main research interests include high-performance switchesrouters, network processors, named data networking and software-defined networking.
The Pseudo Congestion of TCP in Software-Defined Networking
Tai Dongzhe, Zhang Ting, and Liu Bin
(DepartmentofComputerScienceandTechnology,TsinghuaUniversity,Beijing100084)
software-defined networking (SDN) separates the control plane and the data plane, and this kind of separation can achieve flexible control via deploying fine-grained rules on the flow tables in switches, while potentially improving the utilization of network bandwidth. With the development of SDN, more and more campus and enterprise network begin to deploy network based on SDN. During this procedure, SDN has encountered some problems which don’t exist in the traditional IP network. For example, some protocols used in the existing IP network are subject to great challenge in SDN based network, such as TCP, which is the most basic protocol in TCPIP network. First, we make a penetrating analysis on the working mechanism of SDN, and three examples are given to illustrate that it is quite possible to generate large volume of Packet-In messages even in proactive mode. Then experiments are carried out and the results show that the end-to-end TCP connections have experienced a large delay caused by the SDN unique operations such as re-organizing of rules in TCAM and fast Packet-In message generating. In the worst case, the delay caused by the reordering of the rules can reach up to 10 seconds when the TCAM contains 4 000 flow entries in our experiments. Based on the experimental results, we highlight two major problems when applying traditional TCP protocol in SDN networks: one is that it is hard to establish the connection, and the other is the transmission inefficiency. Through the analysis of the experimental results, we propose the possible direction to solve TCP inefficiency issue in SDN.
software-defined networking (SDN); transmission control protocol (TCP); delay; proactive mode; congestion
2015-12-21;
2016-03-22
國家自然科學基金重點項目(61432009) This work was supported by the Key Program of the National Natural Science Foundation of China (61432009).
劉斌(liub@mail.tsinghua.edu.cn)
TP393
