學術社交平臺論文推薦方法
2017-03-02 08:20:19湯志康李春英黃泳航蔡奕彬
計算機與數字工程 2017年2期
湯志康 李春英 湯 庸 黃泳航 蔡奕彬
(1.廣東技術師范學院計算機科學學院 廣州 510665)(2.廣東技術師范學院計算機網絡中心 廣州 510665) (3.華南師范大學計算機科學學院 廣州 510631)
學術社交平臺論文推薦方法
湯志康1李春英2,3湯 庸3黃泳航3蔡奕彬3
(1.廣東技術師范學院計算機科學學院 廣州 510665)(2.廣東技術師范學院計算機網絡中心 廣州 510665) (3.華南師范大學計算機科學學院 廣州 510631)
基于搜索學術論文對研究者造成的困擾問題,在學術論文聚合平臺基礎上提出一種學術社交平臺相似論文推薦方法,給出了推薦方法的總體架構及各部分的詳細設計方案。該方法首先使用ANSJ對論文數據集中的論文進行分詞并統計詞條的TF-IDF,使用這些詞條表示該論文的關鍵信息。其次使用Word2Vec把每一篇論文映射到一個高維向量,使用余弦相似度公式計算其與用戶查詢論文間的相似度,根據相似度結果高低生成論文推薦列表。最后在SCHOLAT論文數據集上通過應用實例以及量化指標分析驗證了該推薦方法的有效性。
學術社交平臺; 論文檢索; 相似論文; 推薦方法
Class Number TP311
1 引言
學術社交網絡平臺主要面向科研工作者,旨在為全球科研工作者提供學術信息服務。平臺提供便利的條件讓科研工作者發布個人學術信息,搜索、分享和推薦相關學術研究成果并追蹤感興趣領域的最新研究動態。學術社交網絡平臺也能使科研工作者可以跨地域、跨單位、跨學科進行學術交流、思想碰撞,從而有效促進科學研究工作的協同高效開展。
隨著學術社交網絡的快速發展,科研人員之間的交流變得更加容易,獲取信息也變得更加方便。學術社交網絡平臺為我們提供極大便利的同時,信息過載已經成為科研工作者所面臨的主要困境之一。如何在學術社交網絡平臺的海量信息中快速精準定位所感興趣的內容,是需要研究的重要課題。推薦系統[1]是目前解決信息過載的有效方法。本文以學術論文的搜索與推薦作為切入點,主要研究基于用戶搜索信息的相似論文推薦問題。
當前提供學術論文檢索的平臺很多且都比較成熟。國內比較著名的有中國知網、萬方數據庫和百度學術等。國外則細分到各個學科領域,以計算機學科為例,有Springer、ACM、ScienceDirect、Microsoft Academic Search等。如果一名科技工作者想要搜索一篇學術論文,需要選擇某一種搜索引擎進行搜索,倘若搜索的結果不理想,則需要繼續選擇其他的搜索引擎進行查找。這樣,研究者為找到自己需要的學術論文,通常需要頻繁切換搜索平臺,耗費了大量的時間資源,也給科研工作者帶來諸多不便。另外,學術論文的檢索本身是繁瑣和耗時的,檢索某一主題時還可能遺漏一些重要的學術成果,尤其一些較新的具有重要參考價值的成果。因此,本文提出一種基于學術社交平臺的學術論文推薦方法,該推薦方法以學術社交網絡平臺中聚合了其它多個平臺論文的搜索引擎為基礎,科技工作者通過這個搜索引擎提供的統一入口,可以方便快捷地檢索出來自多個學術論文搜索引擎平臺的數據,基于已有的研究成果和數據集,針對用戶選擇的搜索結果給出與選擇結果相似的論文推薦列表。
2 相關工作
隨著科技論文數量的快速增長,如何快速有效地在海量的論文數據集中進行精準定位找到自己想要的學術論文。對于一個給定的查詢主題,系統自動推薦相似論文研究具有良好的現實應用價值。基于這一原因,學者們做出了很多努力,也產生了豐富的研究成果。張玉連等[2]提出通過建立隱語義模型,然后利用用戶和論文的特征向量進行論文推薦的算法,其將所推薦論文的引用和引用該論文的情況加入到論文的特征向量中,通過用戶和論文特征向量之間內積的大小確定推薦的論文。通過與基于用戶的協同過濾算法以及基于論文的協同過濾算法進行比較,該論文推薦算法取得了較好的準確率和召回率。賀超波等[3]提出了基于學術社區的學術論文推薦方法。該方法首先抽取用戶基本信息、論文信息、用戶關系網絡以及用戶對論文的評價信息,然后通過社區發現模塊對用戶群體進行社區劃分,計算目標用戶在社區內最相近的K個用戶,然后結合基于網絡社區的協同推薦算法以及用戶論文評價數據進行綜合計算后給出論文推薦列表。該方法通過社區的互動和分享來提高推薦的質量和效率。李建國等[4]提出了基于領域認知度的學術信息服務平臺論文推薦方法。該方法首先對論文所屬的領域進行分類,然后計算作者對研究領域的認知度,領域相近的作者為目標論文預測評分,根據評分實現論文推薦。文獻[2~4]在推薦中使用了用戶顯性信息或者隱性信息,這種方法對于新注冊且信息極少的數據稀疏用戶存在推薦冷啟動問題。文獻[5]提出使用讀者在數字圖書館的共訪問記錄比以及共引記錄進行論文推薦具有更好的覆蓋率,使用共訪問記錄可使沒有獲得足夠引用的研究論文獲得推薦。但是這種方法對于首次使用數字圖書館的科技工作者難于獲得推薦。文獻[6]基于奇異值分解理論通過已出版論文的參考文獻列表預測目標研究者的研究興趣,并根據預測的研究興趣推薦新出版的科技論文給目標用戶。通過在DBLP真實數據集上的實驗表明該方法比基于引用網絡的方法具有更好的推薦效果。但這種方法存在科技工作“新人”難于獲得論文推薦的問題。
3 該推薦方法詳細設計
本文以大型學術社交網絡平臺學者網(www.scholat.com)為依托,以其中文論文數據庫作為研究語料,提出學術社交網絡平臺相似論文推薦方法,如圖1所示。該模型預處理階段對研究語料中的論文進行分詞,分詞結果分別存入文本文件wordList.txt和數據庫HBase中。對存儲在HBase中的論文,根據分詞結果統計詞條的TF-IDF,并將這些詞條作為論文的關鍵詞。論文分詞結果文本文件在Word2Vec程序的訓練下得到相應的向量表示并使用余弦相似度計算其與用戶輸入論文的相似程度,根據相似度從高到低排序生成論文推薦列表。
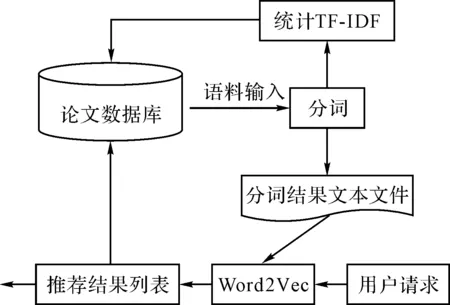
圖1 推薦方法整體架構圖
3.1 數據庫設計
HBase[7]是Apache Hadoop的子項目,是構建在HDFS上的典型的key/value分布式列存儲系統,尤其適合于海量非結構化數據存儲。對于迅速增長的海量論文數據而言,HBase可以依靠橫向擴展,通過在廉價PC Server上搭建大規模結構化存儲集群可以提高系統的計算、存儲能力。因此,本推薦系統采用Apache HBase作為數據庫管理系統存儲和計算海量論文數據并對用戶提供論文推薦服務。另外,Apache HBase表的屬性可以根據需求動態增加。表是由行和列構成的,一個列名由column family前綴和qualifier構成,所有的列都從屬于某個column family[8]。在本推薦方法中共涉及四個Bigtable:詞條文檔數表,論文關鍵詞表,關鍵詞論文集合表和論文推薦結果表。
詞條文檔數表如表1所示,用于統計語料中出現某詞條的文檔數,其中term代表一個詞,qualifier的列數代表出現該詞條的文檔數量。

表1 詞條文檔數表
使用3.2節Ansj分詞工具動態產生詞條,并利用式(1)計算詞條在文檔中的詞頻。通過遍歷表1中的詞條,獲取擁有該詞條的文檔數,使用3.3節的式(2)計算詞條的逆文檔頻率值,據此計算每個詞條對應的TF和IDF之積。TF-IDF值越高的詞條與論文的相關性越高,因而選擇TF-IDF值較高的前15個詞條作為論文的關鍵字,存儲于表2中。為了計算相似度并進行論文推薦,設計表3用于存儲以某個詞條作為關鍵詞的論文的集合。表3中qualifier的值是出現該關鍵詞的論文id,列數則代表以該詞條作為關鍵詞的論文的篇數。
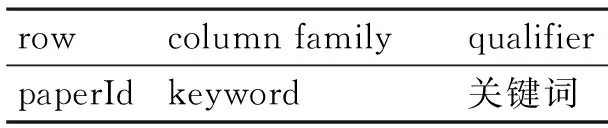
表2 論文關鍵詞表
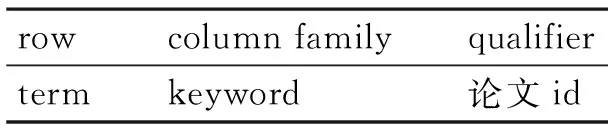
表3 關鍵詞論文集合表
利用表2和表3中存儲的數據信息,結合Word2Vec訓練結果,計算輸入論文與數據庫中論文的相似度,并產生論文推薦結果,并存儲于表4中。
3.1 護理質量管理的信息化 信息技術的使用是當前護理質量管理走向科學化的必由之路。通過充分整合搜索引擎技術、數據庫技術、分布存儲技術等,設計醫院護理質量信息化管理軟件,包括數據錄入、統計分析、實時反饋、重大案例分析、專家在線咨詢、工作提醒、危重癥護理實時監測、標準查詢等護理質量管理資源共享模塊,實現全市護理質量評價數據實時監測、動態評價、專家反饋以及護理質量改進的科學決策,研制開發護理風險危機管理系統,建立全市范圍的護理安全管理共享平臺,從而真正實現護理質量管理的自動化與智能化。

表4 論文推薦結果表
3.2 中文分詞
分詞是對語料進行統計和訓練的前提條件。Ansj是基于Google語義模型和條件隨機模型的中文分詞開源工具,支持用戶自定義詞典。Ansj運行時首先讀取停用詞列表文件,去除語料中可能出現頻率很高但無意義的詞條。然后Ansj根據用戶自定義詞典對語料信息進行分詞,并以詞條作為鍵,paperId作為表1的qualifier。
3.3 計算詞條的TF-IDF值
Salton的詞頻-逆文檔詞頻TF-IDF是一種用于信息檢索和文本挖掘的常用加權技術,用來評估詞組在文檔中的重要程度。詞頻是統計一個詞在文檔中出現的頻率,詞頻越高,通常意味著該詞在文檔中的地位越重要;逆文檔詞頻是一個詞語重要性的衡量,如果包含該詞條的文檔數越少,說明該詞條具有很好的類別區分能力,其值越大。詞頻和逆文檔詞頻的乘積為TF-IDF,其作用通俗來講就是:如果一個詞條在一個文檔中頻繁出現,即其TF值很高;而同時在其他文檔中又很少出現,那么說明該詞條的區分度很高。詞條ti在文檔dj中的詞頻TF計算如式(1)所示。其中,ni,j表示ti在文檔dj中出現的次數,∑knk,j表示所有詞出現的次數之和。
(1)
詞條ti在當前語料庫中的逆文檔頻率IDF的計算如式(2)所示。其中,|D|是語料庫中的文檔總數,|{j:ti∈dj}|是出現詞條ti的文檔數。
(2)
根據語料數據集,通過遍歷詞條文檔數表,對于每一行,統計其qualifier的列數,即可得到包含該詞條的論文數,而論文總數在實驗中是常量。依據式(2)計算詞條的逆文檔詞頻IDF,保存到詞條逆文檔頻率表中。
3.4 相似度推薦
Word2Vec[9]是Google在2013年開源的一款將詞表征為實數向量的高效工具,尤其適合對互聯網大數據進行處理,其在一個優化的單機版本一天可訓練上千億個詞條[10~11]。本文采用Word2Vec的Distributed Representation向量表示法[12]。該向量表示法的維數可自定義為超參數K,通過訓練把對文本內容的處理簡化為K維實數向量。并且使用余弦相似度計算向量之間的距離來判斷文本之間的語義相似度。與潛在語義分析(Latent Semantic Index)[13]、潛在狄立克雷分配(Latent Dirichlet Allocation)[14]等經典的相似度計算模型相比,Word2vec結合深度學習的思想,利用了詞語的上下文關系,語義信息、語義關聯等表達得更加豐富。
4 實驗
開發環境:Apache HBase 1.0、Google Word2Vec、Apache Solr、Ansj2.0.6、Intel(R)Core(TM) i3-3240 CPU @ 3.40GHz,4G內存,300G硬盤。基于提出的論文推薦模型,算法如下所示。
算法1 論文推薦算法
已知:學術社交網絡論文集;當前用戶的行為記錄(輸入關鍵詞等)
求:論文推薦列表recommList
1.收集研究語料(包含標題、關鍵詞、摘要)、用戶行為;
2.信息預處理,去噪、對信息進行分詞、統計詞條TF-IDF;
3.利用Word2Vec訓練,計算用戶行為的余弦相似度;
4.對相似度進行逆序排列,取出TOPn篇論文形成推薦列表(最多推薦5篇);
5.return recommList,量化評價。
4.1 實例應用
考慮到直接采用論文現有的關鍵詞信息不能很好地體現論文的實質內容,實驗挑選學者網數據集SCHOLAT中文部分且論文的元數據信息包含標題、關鍵詞、摘要等三種信息的數據作為研究語料。利用3.2節Ansj分詞模型對研究語料進行分詞并使用式(1)和式(2)計算詞條的TF-IDF值,提取前15個詞條作為論文的關鍵詞,并將結果保存到表2中。將以空格作為分隔符的分詞結果文件wordList.txt導入Word2Vec進行訓練,訓練完成后輸出文件vectors.bin,該文件以二進制形式保存了詞條的向量表示。使用Word2Vec提供的distance程序計算詞條向量表示之間的余弦相似度,distance應用通過讀取模型文件中每一個詞條和其對應的向量,對應輸入查詢的詞組,計算該詞與其他被采樣的詞條的余弦相似度,按照分數從高到低排序后返回結果。然后根據關鍵詞,查詢表3中對應的論文,并將產生的推薦論文列表id信息保存到表4中。
現假設社交網絡平臺用戶輸入論文名稱為“計算機輔助教學的優勢與應注意的問題”為例,根據Word2Vec的訓練結果,與“計算機”相近的詞語有“多媒體”、“微機”等,如圖2所示。在表3中檢索對應的論文后產生推薦結果,如圖3所示。

圖2 詞條“計算機”的訓練結果圖

圖3 論文推薦結果圖
4.2 量化分析
為了對本文提出的論文推薦算法進行量化評價,利用學者網提供的數據接口,采集了計算機相關類別的中文期刊92848篇論文作為測試集。文中用來評價論文推薦效果的指標是準確率、召回率、F1-Measure。如式(3)~(5)所示
(3)
(4)
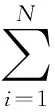
圖4是本文提出的論文推薦算法在不同的推薦數量的情況下的效果比較,由圖中可以看出,隨著推薦數量的增加,尤其是達到200以上的時候,論文推薦算法趨于穩定,總體上具有較好的應用價值。
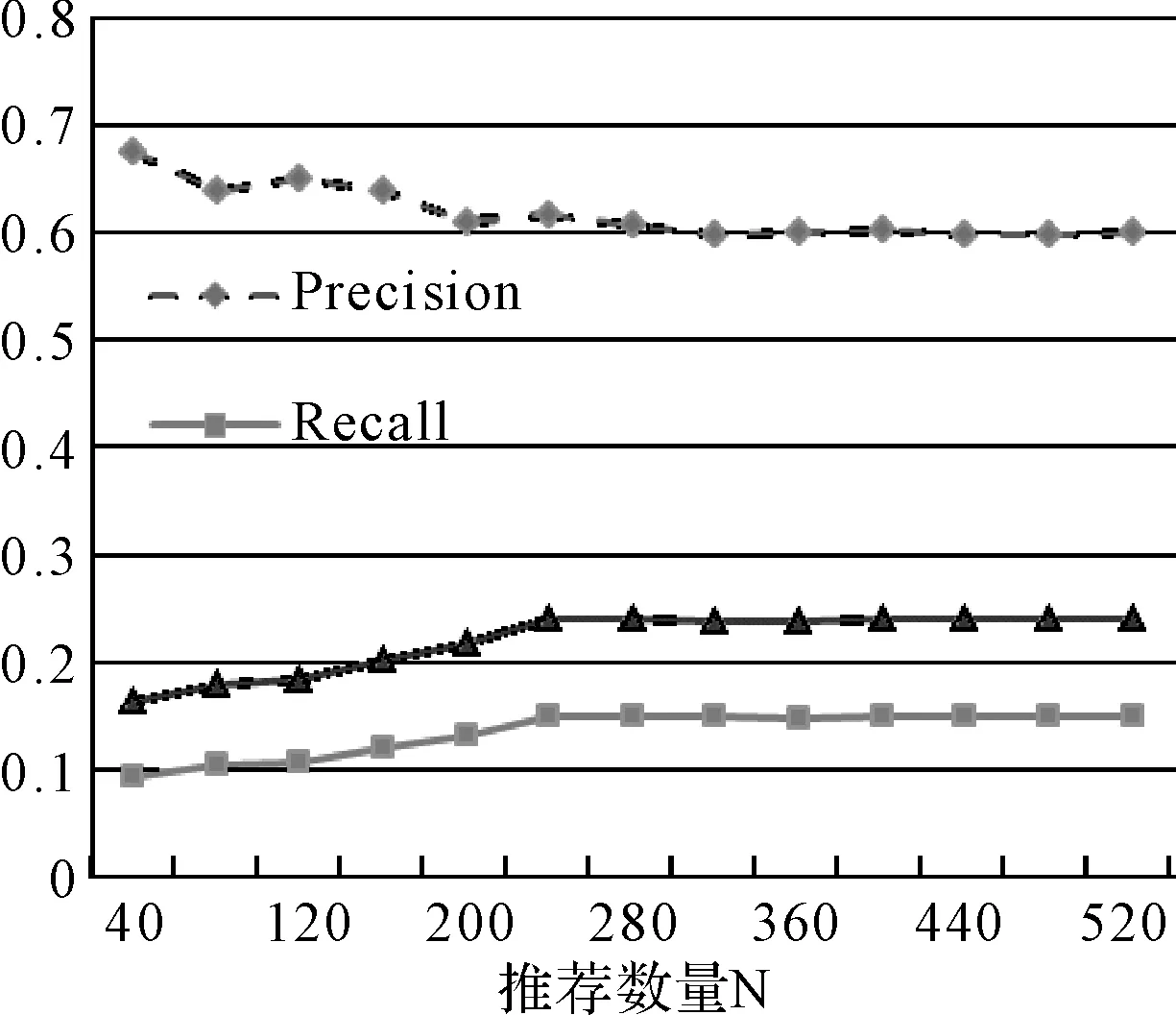
圖4 推薦效果對比圖
5 結語
提出一種學術社交網絡平臺相似論文推薦方法,給出了系統的總體架構及各部分的詳細設計方案。在SCHOLAT(學者網)論文數據集上驗證了模型的有效性。但由于當前推薦系統計算量較大,特別是計算詞頻-逆文檔詞頻和詞條之間的相似度。同時Word2Vec使用的語料數據集越大,效果越理想,但超大的數據集使單機系統的性能受到考驗。因此當前僅抽取SCHOLAT數據集上少部分數據進行實驗驗證。下一步考慮采用Apache Hadoop平臺實現學者網SCHOLAT完整論文數據集的分布式動態計算,提高系統的響應時間和訓練效果,并將該論文推薦系統模型投入到學者網平臺上推廣使用。
[2] 張玉連,袁偉.隱語義模型下的科技論文推薦[J].計算機應用與軟件,2015,32(2):37-40. ZHANG Yulian, YUAN Wei. Scientific Papers Recommendation Using Implicit Semantics Model[J]. Computer Applications and Software,2015,32(2):37-40.
[3] 賀超波,沈玉利,余建輝,等.基于學術社區的科技論文推薦方法[J].華南師范大學學報(自然科學版),2012,44(3):55-58. HE Chaobo, SHEN Yuli, YU Jianhui, et al. Method for Scientific Paper Recommendation Based on Academic Community[J]. Journal of South China Normal University(Natural Science Edition),2012,44(3):55-58.
[4] 李建國,毛承潔,劉曉,等.學術信息服務平臺的研究與設計[J].華南師范大學學報(自然科學版),2012,44(3):51-54. LI Jianguo, MAO Chengjie, LIU Xiao, et al. Research and Design of Academic Information Service Platform[J]. Journal of South China Normal University(Natural Science Edition),2012,44(3):51-54.
[5] Pohl Stefan, RadlinskiFilip, Joachims Thorsten. Recommending Related Papers Based on Digital Library Access Records[C]//Proceedings of the 7thACM/IEEE-CS Joint Conference on Digital Libraries,New York: ACM,2007:417-418.
[6] Ha Jiwoon, Kwon Soon-Hyoung, Kim Sang-Wook. On Recommending Newly Published Academic Papers[C]//Proceeding HT’15 Proceedings of the 26th ACM Conference on Hypertext & Social Media,New York: ACM,2015:329-330.
[7] Apache HBase Team. Apache HBaseTMReference Guide[EB/OL]. http://hbase.apache.org/book.html,2013-01-17.
[8] Dimiduk Nicholas, Khurana Amandeep. HBase in Action[EB/OL]. https://www.manning.com/books/hbase-in-action.
[9] 周練.Word2vec的工作原理及應用探究[J].科技情報開發與經濟,2015(2):145-148. ZHOU Lian. Exploration of the Working Principle and Application of Word2vec[J]. Sci-Tech Information Development & Economy,2015(2):145-148.
[10] 鄭文超,徐鵬.利用word2vec對中文詞進行聚類的研究[J].軟件,2013(12):160-162. ZHENG Wenchao, XU Peng. Research on Chinese Word Clustering with Word2vec[J]. Software,2013(12):160-162.
[11] Mikolov Tomas, Chen Kai, CorradoGreg, et al. Efficient Estimation of Word Representations in Vector Space[J]. eprintarXiv:1301.3781,2013,1:1-12.
[12] 鄧澎軍,陸光明,夏龍.Deep Learning實戰之word2vec[EB/OL].網易有道,2014-02-27. DENG Pengjun, LU Guangming, XIA Long. Deep Learning Practice in Word2vec[EB/OL]. Net Ease You Dao, 2014-02-27.http://techblog.youdao.com/?p=915.
[13] Scott Deerwester, Dumais Susan T, Furnas George W, et al. Indexing by latent semantic analysis[J]. Journal of The American Society for Information Science,1990,41(6):391-407.
[14] Blei David M, Ng Andrew Y, Jordan Michael I. Latent Dirichlet Allocation[J]. Journal of Machine Learning Research,2003,3:993-1022.
Paper Recommendation Method Based on Scholar Social Platform
TANG Zhikang1LI Chunying2,3TANG Yong3HUANG Yonghang3CAI Yibin3
(1. School of Computer Science, GuangDong Polytechnic Normal University, Guangzhou 510665) (2. Computer Network Center, GuangDong Polytechnic Normal University, Guangzhou 510665) (3. School of Computer Science, South China Normal University, Guangzhou 510631)
According to the defects that researchers search academic papers. This paper proposed a similar paper recommendation method in scholar social platform that includes several popular search engine, and explainedthe framework of recommendation method and detailed design of the system. This recommendation method executes word-segmentation with ANSJ, calculate the TF-IDF of lemma and extract paper key words in initialization. Next, read the segmentation result to get the word-vectors by Word2Vec, calculate its similarity with querypaperfrom users according to cosine similarity formula. And further, the paper recommendation list will be generated. In the end, the efficacy will be proof by an application instance and quantitative index analysison SCHOLAT paper dataset.
academic social network, paper seeking, similar paper, recommendation method
2016年8月10日,
2016年9月22日
國家自然科學基金(編號:61272067,61370229);廣東省自然基金團隊研究項目(編號:S2012030006242);廣東省自然科學基金-博士科研啟動項目(編號:2014A030310238);廣東省科技計劃項目(編號:2015B010109003)資助。
湯志康,男,講師,研究方向:社交網絡與大數據應用。李春英,女,博士研究生,副教授,研究方向:社交網絡與大數據應用、服務計算。湯庸,男,教授,博士生導師,研究方向:信息搜索與數據挖掘、協同計算。黃泳航,男,博士研究生,研究方向:社交網絡。蔡奕彬,男,碩士研究生,研究方向:服務計算。
TP311
10.3969/j.issn.1672-9722.2017.02.006
猜你喜歡
中華手工(2017年2期)2017-06-06 23:00:31
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
創業家(2015年5期)2015-02-27 07:53:25
中外會展(2014年4期)2014-11-27 07:46:46
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
