基于大數據技術的告警日志數據分析
2017-03-07 16:39:04應俊
移動通信 2016年23期
應俊
摘要:為了更好地滿足運營商對海量非結構化數據的處理需求,主要以網絡告警日志數據為例,詳細闡述如何利用Hadoop+Spark大數據技術挖掘和分析海量的數據,進而提高網絡監控效率。
關鍵詞:告警數據 Hadoop Spark
1 引言
隨著電信網絡的不斷演進,全省數據網、交換網、接入網設備單月產生告警原始日志近億條。以上告警通過網元網管、專業綜合網管、智能網管系統[1]三層收斂,監控人員每月需處理影響業務或網絡質量的告警事件為20萬條,但一些對網絡可能造成隱患的告警信息被過濾掉。如何從海量告警數據中獲取與網絡性能指標、運維效率相關的有價值的數據,對于傳統的關系型數據庫架構而言,似乎是一個不可能完成的任務。
在一般告警量情況下,ORACLE數據處理能力基本可以滿足分析需求,但當告警分析量上升到億級,如果采用傳統的數據存儲和計算方式,一方面數據量過大,表的管理、維護開銷過大,要做到每個字段建索引,存儲浪費巨大;另一方面計算分析過程耗時過長,無法滿足實時和準實時分析需求。因此必須采用新的技術架構來分析處理海量告警信息,支撐主動維護工作顯得尤為必要,為此我們引入了大數據技術。
2 分析目標
(1)數據源:電信運營商網絡設備告警日志數據,每天50 G。
(2)數據分析目標:完成高頻翻轉類(瞬斷)告警分析;完成自定義網元、自定義告警等可定制告警分析;完成被過濾掉的告警分析、TOPN告警分析;核心設備和重要業務監控。
(3)分析平臺硬件配置:云計算平臺分配8臺虛擬機,每臺虛機配置CPU16核;內存32 G;硬盤2 T。
3 制定方案
進入大數據時代,行業內涌現了大量的數據挖掘技術,數據處理和分析更高效、更有價值。Google、Facebook等公司提供可行的思路是通過類似Hadoop[2]的分布式計算、MapReduce[3]、Spark[4]算法等構造而成的新型架構,挖掘有價值信息。
Hadoop是Apache基金會用JAVA語言開發的分布式框架,通過利用計算機集群對大規模數據進行分布式計算分析。Hadoop框架最重要的兩個核心是HDFS和MapReduce,HDFS用于分布式存儲,MapReduce則實現分布式任務計算。
一個HDFS集群包含元數據節點(NameNode)、若干數據節點(DataNode)和客戶端(Client)。NameNode管理HDFS的文件系統,DataNode存儲數據塊文件。HDFS將一個文件劃分成若干個數據塊,這些數據塊存儲DataNode節點上。
MapReduce是Google公司提出的針對大數據的編程模型。核心思想是將計算過程分解成Map(映射)和Reduce(歸約)兩個過程,也就是將一個大的計算任務拆分為多個小任務,MapReduce框架化繁為簡,輕松地解決了數據分布式存儲的計算問題,讓不熟悉并行編程的程序員也能輕松寫出分布式計算程序。MapReduce最大的不足則在于Map和Reduce都是以進程為單位調度、運行、結束的,磁盤I/O開銷大、效率低,無法滿足實時計算需求。
Spark是由加州伯克利大學AMP實驗室開發的類Hadoop MapReduce的分布式并行計算框架,主要特點是彈性分布式數據集RDD[5],中間輸出結果可以保存在內存中,節省了大量的磁盤I/O操作。Spark除擁有Hadoop MapReduce所具有的優點外,還支持多次迭代計算,特別適合流計算和圖計算。
基于成本、效率、復雜性等因素,我們選擇了HDFS+Spark實現對告警數據的挖掘分析。
4 分析平臺設計
4.1 Hadoop集群搭建
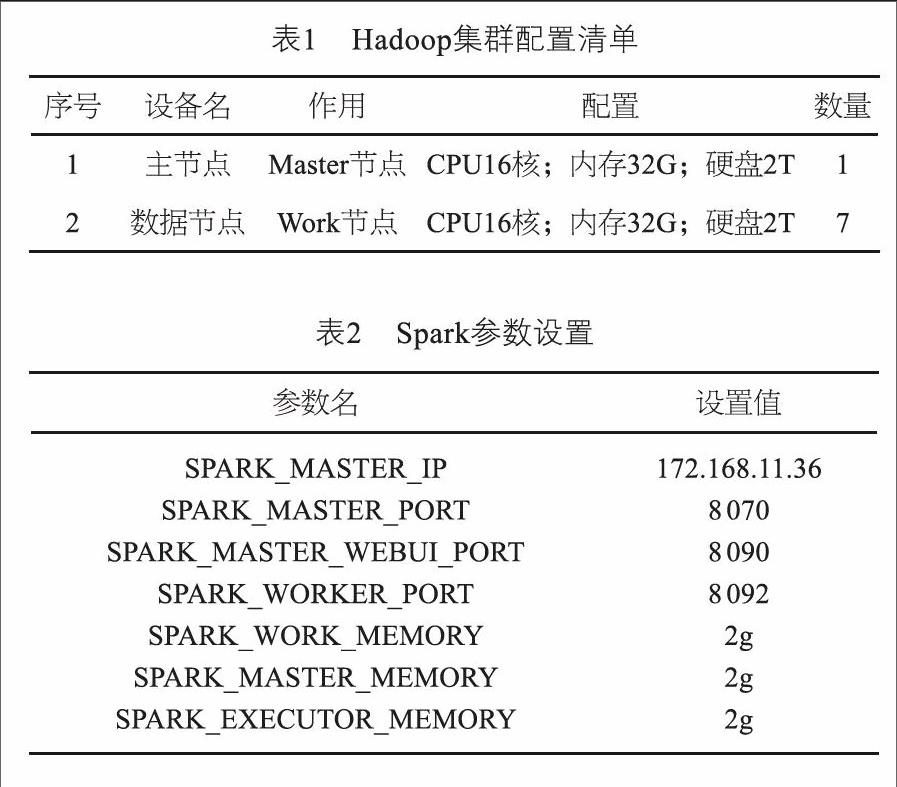
基于CentOS-6.5系統環境搭建Hadoop集群,配置如表1所示。
4.2 Spark參數設置[6]
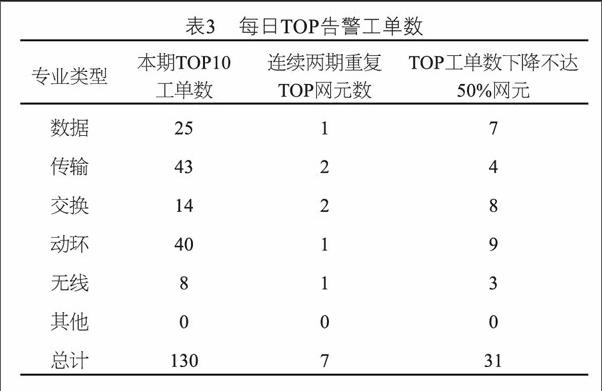
Spark參數設置如表2所示。
4.3 數據采集層
數據采集:由于需采集的告警設備種類繁多,故采取分布式的告警采集,數據網設備、交換網設備、接入網設備分別通過IP綜合網管、天元綜合網管、PON綜合網管進行采集,采集周期5分鐘一次。采集機先將采集到的告警日志文件,通過FTP接口上傳到智能網管系統文件服務器上,再對文件進行校驗,通過Sqoop推送到Hadoop集群上。
4.4 邏輯處理層
(1)建立高頻翻轉告警監控工作流程
先將海量告警進行初步刪選,通過數量、位置和時間三個維度的分析,得出高頻翻轉類告警清單列表,最后由專業工程師甄別確認,對某類告警進行重點關注和監控。
(2)差異化定制方案
按組網架構細分,針對核心重要節點的所有告警均納入實時監控方案;
按業務網絡細分,針對不同業務網絡設計個性化的監控方案;
按客戶業務細分,針對客戶數字出租電路設計個性化的監控方案。
4.5 數據分析層
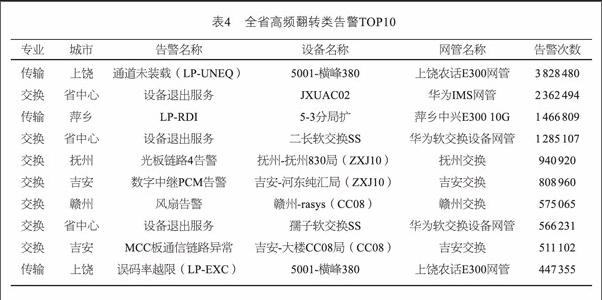
Spark讀取Hive[7]表的告警數據,然后在Spark引擎中進行SQL統計分析。Spark SQL模塊在進行分析時,將外部告警數據源轉化為DataFrame[8],并像操作RDD或者將其注冊為臨時表的方式處理和分析這些數據。一旦將DataFrame注冊成臨時表,就可以使用類SQL的方式操作查詢分析告警數據。表3是利用Spark SQL對告警工單做的一個簡單分析:
5 平臺實踐應用
探索運維數據分析的新方法,利用大數據分析技術,分析可能影響業務/設備整體性能的設備告警,結合網絡性能數據,找到網絡隱患,實現主動維護的工作目標。
5.1 高頻翻轉類告警監控
首先制定了高頻翻轉類告警分析規則,將連續7天每天原始告警發生24次以上定義為高頻翻轉類告警,并基于大數據平臺開發了相應的分析腳本,目前已實現全專業所有告警類型的分析。表4是全省高頻翻轉類TOP10排名。
5.2 核心設備和重要業務監控
目前以設備廠商或專家經驗評定告警監控級別往往會與實際形成偏差,主要表現在以下幾個方面:監控級別的差異化設定基于已知的告警類型,一旦網絡重大故障上報未知的告警類型就無法在第一時間有效監控到;同一類型的故障告警出現在不同網絡層面可能影響業務的程度是完全不同的;不同保障級別的客戶對故障告警監控的實時性要求也是不同的。
通過大數據分析平臺對差異化監控提供了靈活的定制手段,可根據告警關鍵字,分專業、地市、網管、機房、告警頻次等維度自主定制需要的告警數據,實現日、周、月、某個時間區等統計分析。
應用案例:省NOC通過大數據分析出一條編號為CTVPN80113的中國平安大客戶電路在一段時間內頻繁產生線路劣化告警,但用戶未申告,省NOC隨即預警給政企支撐工程師,政支工程師與用戶溝通后,派維護人員至現場處理,發現線路接頭松動,緊急處理后告警消除、業務恢復。
5.3 被過濾告警分析
全省每天網絡告警數據300萬條~500萬條,其中99%都會根據告警過濾規則進行過濾篩選,把過濾后的告警呈現給網絡監控人員。過濾規則的準確性直接影響告警數據的質量。一般來說告警過濾規則可以從具有豐富運維經驗的網絡維護人員獲得,但是這個過程非常繁瑣,而且通過人工途徑獲得的告警過濾規則在不同的應用環境可能存在差異,無法滿足網絡維護的整體需要。采用大數據技術對被過濾的告警進行分析可以很好地完善過濾規則,讓真正急迫需要處理的告警優先呈現給維護人員及時處理,真正做到先于客戶發現故障。表5是動環專業被過濾的告警情況分布。
5.4 動環深放電分析
動環網管通過C接口采集蓄電池電壓數據,在停電告警產生之后,電壓數據首次下降到45 V,表示該局站電池出現深放電現象,通過計算這一放電過程的持續時間,記為深放電時長,該時長可以初步反映電池的放電性能。一個局站每天產生幾十萬條電壓等動環實時數據。
在告警數據分析的基礎上,實現對蓄電池電壓變化數據的分析,提醒分公司關注那些深放電次數過多和放電時長過短的局站,核查蓄電池、油機配置、發電安排等,并進行整治。利用Spark SQL統計了一個月內撫州、贛州、吉安三分公司幾十億條動環數據,分析了其中深放電的情況如表6所示。
6 結論
本文利用HDFS+Spark技術,實驗性地解決告警數據存儲和分析等相關問題:一是通過數據分析,從海量告警數據中發現潛在的網絡隱患;二是結合資源信息和不同專業的告警,最終為用戶提供綜合預警;三是轉變網絡監控思路和方式,通過數據匯聚、數據相關性分析、數據可視化展示,提高了網絡監控效率;最后還擴展到對動環實時數據、信令數據進行分析。
從實際運行效果來看,HDFS和Spark完全可以取代傳統的數據存儲和計算方式,滿足電信運營商主動運維的需求。
參考文獻:
[1] 中國電信股份有限公司. 中國電信智能網管技術規范-總體分冊[Z]. 2015.
[2] Tom white. Hadoop權威指南[M]. 4版. 南京: 東南大學出版社, 2015.
[3] RP Raji. MapReduce: Simplified Data Processing on Large Clusters[Z]. 2004.
[4] Spark. Apache Spark?[EB/OL]. [2016-11-27]. http://spark.apache.org/.
[5] Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, et al. Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing[J]. Usenix Conference on Networked Systems Design & Implementation, 2012,70(2): 141-146.
[6] 許鵬. Apache Spark源碼剖析[M]. 北京: 電子工業出版社, 2015.
[7] Hive. Apache HiveTM[EB/OL]. [2016-11-27]. http://hive.apache.org/.
[8] Holden Karau, Andy Konwinski, Patrick Wendell, et al. Learning Spark: Lightning-Fast Big Data Analysis[M]. Oreilly & Associates Inc, 2015.
[9] 員建廈. 基于動態存儲策略的數據管理系統[J]. 無線電工程, 2014,44(11): 52-54.
[10] 楊毅. 一種基于網格優化的空間數據訪問與存儲
研究[J]. 無線電通信技術, 2014,40(6):43-46. ★
