
幾種排序算法對比分析
2017-03-08 04:02:39穆哈麥德
中國新通信 2017年1期
穆哈麥德
【摘要】 互聯網+已經是當前國內行業經濟發展的重要基礎和技術支撐,搜索引擎技術的目標任務就是將用戶查詢返回的結果進行排序,這個排序的標準就是按照與用戶查詢的相關程度進行排序,而如何獲得這個最準確的返回列表也正是排序學習所要研究的重點。本文對比了幾種常見排序算法,同時對于重點提出的基于蟻群算法的排序算法與經典的直接優化算法進行了比較分析。
【關鍵字】 排序 排序算法 對比
排序學習主要是根據給定的對象集合,學習一種完整的排序模型,以此來計算各個對象的分值,然后利用這些分值對這些對象進行排序。己有的排序學習算法在處理小規模數據集時可以表現出良好的算法性能,然而在大數據的背景下現有的算法在處理大規模數據時面臨訓練模型時間緩慢,內存消耗大等問題,尤其是在一些需要實時處理數據的領域,這些問題的解決顯得尤為迫切,成為一個值得研究的具有理論和應用價值的問題。
一、排序學習算法的比較
排序學習對搜索引擎的研究產生了很大的影響,一般在針對某個社會、管理或者其他領域的復雜問題進行系統分析時,所面臨的問題經常是一個由多個因素影響,且各個因素之間相互制約的復雜排序問題。要解決這類問題,必須尋求到一個簡潔、有效、實用的排序方法,并行排序方法為這類問題找到了解決方案。比較好的排序方法的特征是能夠合理的考慮定性與定量因素,將復雜的決策過程按照思維、邏輯規律進行層次化與量化。這是經濟系統決策科學中的一種常用方法、一種有效的決策工具。層次分析法所依據的原則就是主要靠決策者以及用戶的既有經驗,既通過定性方法,也通過定量方法,然后綜合判斷每個目標的實現的可能性以及互相影響的關系,同時界定重要程序,從而結合這三個方案來賦予一定的權重,通過權值之間的組合給方案進行優劣排序,相比于只使用定量方法來解決問題,效率更高,針對性更強。主要包括以下幾個方式:單文檔方式是指將單個文檔作為訓練樣本,使得根據從訓練樣本學習到的分類或者回歸函數對文檔評分,從而根據這個評分結果決定它的排序。2007年,美國一些人員通過研究將將多類別分類引入到排序問題中從而提出了McRank算法。2012年,程凡提出了基于Point-wise的直接優化的排序算法。
文檔列表方式是將查詢結果的列表作為模型訓練用的實例,其最終目的在于最小化文檔列表的損失函數來達到優化排序結果的效果,文檔列表方式是最具現實意義的方法因為它將排序問題看待為更實際的模型。2007年Z.Cao等人提出的ListNet算法根據定義的排列概率與實際排序的序列的KL距離作為損失函數進行學習。2014年,繆志高將半監督引入了List-wise排序學習框架,基于這種半監督的排序學習算法可以更加有效地提升算法性能。
二、基于蟻群算法的并行排序算法
蟻群算法是一種仿生算法,具有路徑概率選擇機制,信息的正負反饋機制,幾乎所有的螞蟻都沿著一條路徑行走,該條路徑就是一條最優路徑,在很多領域得到成功的應用,也可以應用到排序算法中。
設有一組用戶瀏覽的記錄為:S={(n1,n4,n8),(n1,n4),(n1,n4,n7),(n1,n3,n7),(n1,n3,n6),(n1,n3,n7),(n1,n3,n6),(n1,n2,n5,n3,n7),(n1,n2,n5),(n6,n7))
蟻群算法的Web站點排序模型如圖1所示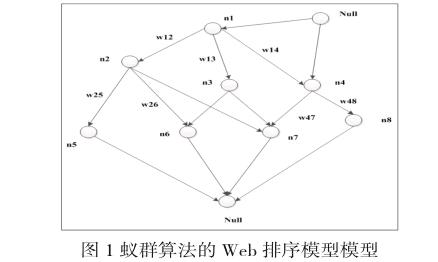
基于蟻群算法的排序模型包括以下策略:(1)首先建立一個比較簡單的文檔列表;(2)然后通過利用文檔列表建立一種群體用戶模型;(3)采用蟻群算法對最優排序進行求解。
三、比較分析
為驗證第2節中的基于蟻群的排序算法效率,接下來對比了本文算法與的直接優化排序算法,對于不同的事務長度,排序的效率如表1所示: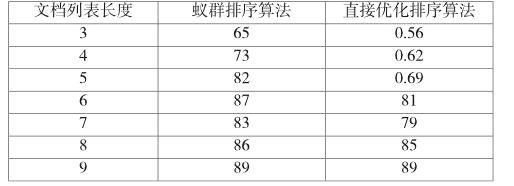
因此,相對于直接優化排序算法,蟻群排序算法的排序效率和準確度更高,主要由于蟻群算法采用信息素機制實現正負反饋機制。
四、結論
現在是海量數據以及物流極度發達的一個時代,為了更好的配置資源,降低實體化的路途成本,充分利用當前數據庫以及分布式技術的優勢,實現多方合理資源共享以及降低成本,提高企業工作效率與利潤。而如何進一步挖掘互聯網下所產生的海量數據信息,進行快速排序,是一個具有高度價值與前景的課題。集成了數據倉庫、數據挖掘技術一體的商業智能,則為顯性知識中的并行排序提供了良好的方式,為企業提供有價值的信息以支持決策。
本文將蟻群算法引入到排序建模中,通過蟻群算法的正負反饋機制和路徑概率選擇機制快速排序,取得很好的效果。
參 考 文 獻
[1] R.Cooley.Web Usage Mining: Discovery and Application of Interesting Patterns from Web data. PhD thesis, Dept. of Computer Science, University of Minnesota, May 2000.
[2] 鄭先榮,湯澤瀅,曹先彬.適應用戶興趣變化的非線性逐步遺:怎協同過濾算法[J].計算機輔助工程,2010,16(2):69-73.
[3] 涂承勝,魯明羽,陸玉昌.Web挖掘研究綜述[J].計算機工程與應用,2003,10:90-93.
猜你喜歡
中學生數理化·七年級數學人教版(2022年11期)2022-02-14 07:14:12
科普童話·學霸日記(2020年1期)2020-05-08 16:45:11
小天使·一年級語數英綜合(2019年2期)2019-01-10 11:57:30
兒童繪本(2018年5期)2018-04-12 16:45:32
商用汽車(2016年11期)2016-12-19 01:20:16
意林原創版(2016年10期)2016-11-25 10:28:30
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
