基于詞典與規則的新聞文本情感傾向性分析
2017-03-09 02:07:02李晨朱世偉魏墨濟于俊鳳李新天
山東科學 2017年1期
李晨 ,朱世偉 ,魏墨濟 ,于俊鳳,李新天
(1.山東省科學院情報研究所,山東 濟南 250014;2.山東省科學院生物研究所,山東 濟南 250014)
基于詞典與規則的新聞文本情感傾向性分析
李晨1,朱世偉1,魏墨濟1,于俊鳳1,李新天2
(1.山東省科學院情報研究所,山東 濟南 250014;2.山東省科學院生物研究所,山東 濟南 250014)
通過對新聞類文體的結構分析,將新聞文體按段落劃分,采用一種基于情感詞典和語義規則相結合的情感關鍵句抽取方法,對段落內的句子進行情感分析。綜合考慮情感、轉折、否定、程度和歸總等詞語信息構建情感詞典,根據規則切割新聞文本,將新聞劃分為意群、句子、段落以及篇章,通過制定的規則計算情感關鍵句傾向值,最終獲得段落以及整個篇章的情感傾向值,從而得出新聞的情感傾向。與情感詞典和SVM情感分類方法的實驗結果對比表明,本文方法在對新聞文本進行傾向判別時效果較好,方法具可行性。
情感分析;規則;情感詞典;網絡新聞
文本情感傾向性分析又稱情感分析、意見挖掘,是對帶有情感色彩的主觀性文本進行分析、處理、歸納和推理的過程,旨在研究人們對人物、事件及其屬性的主觀意見和評價[1-3]。文本情感分析已經成為自然語言處理領域的熱點研究話題,涉及自然語言處理、信息檢索、數據挖掘等研究領域。
目前,國內外使用最多的文本情感分析方式有兩種,一是基于機器學習的情感分析[4-5];二是基于語義的情感分析[6-7]。基于機器學習的情感分析多采用傳統的文本分類技術,該方式將情感詞匯作為分類的特征關鍵詞,然后再聯合其他特征訓練分類器來完成文本情感分類,常用的方法有樸素貝葉斯、最大信息熵和支持向量機。Pang等[8]分別使用上述方法進行情感傾向性分析研究,對英文電影評論進行分類,并研究不同特征選擇方式對分類效果的影響。Tan等[9]分別使用NB(NaiveBayesian)、KNN(K-NearestNeighbor)、SVM(SupportVectorMachine)、CentroidClassifier和WindowClassifier5種分類方法并結合多種特征選擇方法對文章情感傾向性進行分類。樊小超[10]通過對評論性文本的分析,結合詞典和規則將文本劃分成情感句集合、細節句集合和關鍵句集合,再對全部文本情感句集合和關鍵句集合進行訓練得到不同的分類器,最后使用投票策略將分類器進行融合,得到最終情感分類結果。采用機器學習的方法進行文本傾向性分類需要大規模標注的訓練集,想要獲得較高的分類結果時,對訓練集的質量要求很高,而且在進行文本向量化的時候往往會忽略情感詞匯的上下文信息。基于語義規則的文本傾向性研究中,研究者一般考慮詞語、句子、段落和篇章等多個角度自底向上進行層次分析。首先,抽取文中具有明顯主觀色彩的情感詞匯;然后,找出對該詞匯進行修飾的否定和程度詞匯等,通過規則計算情感詞匯情感值;最后,根據情感詞匯的情感值,計算得到句子、段落以及篇章的整體情感值,從而獲得最終的情感傾向信息。朱嫣嵐等[11]利用HowNet提供的語義相似度和語義相關場的定義,通過計算待評估詞與褒貶基準詞的相似性和相關性,從而得到待評估詞的傾向度。Turney等[12]使用點互信息PMI(PointwiseMutualInformation)對基準情感詞表進行擴充,并且采用了基于HNC(HierarchicalNetworkofConcepts)的語義相關度方法計算詞語的原始極性。馮亮祖[13]利用語句情感傾向性、文本關鍵詞、語句位置以及語句與標題的相似度4種特征抽取情感關鍵句,通過對情感關鍵句進行計算得出新聞文本的情感傾向。張成功等[14]構建了一個包括基礎詞典、領域詞典、網絡詞典以及修飾詞典的高效極性詞典,將極性詞和修飾詞組合形成極性短語作為情感分析的基礎單元。
綜合分析現有的研究成果,在中文網絡新聞情感分析領域,對篇章級情感分析的研究方法中仍然存在沒有充分考慮文體特征和情感分布,以及對復雜句式缺乏有效的分析方法等問題。本文在上述研究基礎之上,綜合分析網絡新聞的結構特點,對篇章級的新聞情感分析進行細化,把新聞自頂向下分割成篇章、句子以及意群,以HowNet情感詞典為基礎,利用哈工大同義詞詞林和臺灣大學的中文情感極性詞典進行擴展獲得基準情感詞典,再結合各類語義規則獲得網絡新聞的情感傾向。
1 情感傾向性計算方法
1.1 網絡新聞文體研究
新聞的主觀性是指在現實生活中真實發生的事件過程中,敘述者在新聞事件中表現出來的立場、態度和情感[15]。新聞文體一般主題描述簡單突出,情感表達方式簡單明了,所以可以較好地提取新聞的情感信息。通過對新聞文體的分析研究發現,對新聞情感分析起到關鍵作用的文本位置為:
(1)標題:標題是新聞作者主觀意志的直接表達,是文章主旨的高度濃縮,能夠直接陳述新聞的概要。當標題含有明顯的情感傾向時,它應該被賦予較高的權重,同時可以將其他語句與標題進行相似度計算,進而得到句子與新聞主旨的的相似性。與主旨越相似則就越接近文章作者的情感。
(2)段首與段尾:段首與段尾是新聞作者的開篇與總結。通過觀察研究,段首與段尾是表達作者情感的主觀句最常出現的位置,而且新聞文本的結構是一種“倒金字塔”式[16]的結構。
(3)其他位置:對于其他位置的句子,如果與標題不相關,則按照普通方式進行情感傾向計算,不再附加額外權重。
對于篇章級的文本情感分析來說,通常都是對文本進行降維,壓縮文本特征空間來優化情感分類問題。Yessenalina等[17]使用SVM模型在進行篇章級情感分類的同時抽取部分語句作為分類的特征空間,取得了較好的效果。李本陽等[18]使用ME模型處理小句級情感分類,以小句級的情感輸出作為篇章級的輸入,并結合句型特征和句子位置等信息作為特征,采用SVM模型對文本進行篇章級情感分類。本文在對網絡新聞文本進行情感分析時,首先切割新聞文本,找出情感句,以情感句作為分析基礎,最終通過融合各類規則計算出文本的情感傾向。
1.2 情感詞典構建
新聞由句子組成,句子由詞匯組成,因此詞匯是進行情感傾向性分析的基礎。通過構建情感詞典可以將句子中具有情感的詞匯識別出來,從而進行分析。情感詞典在情感分析中起到了重要作用,一些研究者對情感詞典的構建工作展開了深入的研究[19]。自然語言當中一般會把詞匯分為褒義詞、貶義詞和中性詞3類,其中褒貶義詞明確地表達了作者對某一主題的情感傾向。
本文以HowNet為主體,合并中文負面情感詞語和中文負面評價詞語去重后構建負面基礎情感詞典,合并中文正面情感詞語和中文正面評價詞語去重后構建正面基礎情感詞典,以中文程度級別詞語作為描述情感詞的程度詞語詞典,考慮否定詞、轉折詞和新聞中的各類歸總詞語,分別構建否定詞典、轉折歸總詞典。HowNet所包含的情感詞匯有限,本文采用哈工大同義詞詞林和臺灣大學NTUSD簡體中文版本進行去重、剔除歧義詞匯之后,分別加入正/負面基礎情感詞典。文中采用四元組對情感詞典進行描述,定義如下:
sentimentword(name,polarity,pos,weight) ,
(1)
其中,name表示該詞匯的名稱,polarity表示極性,pos表示詞性,weight代表該詞的權重。name和pos通過文本分詞工具FudanNLP獲取,polarity和weight則通過定義好的情感詞典獲取。
1.2.1 程度詞典構建
在各類語言描述當中,修飾詞對情感詞匯的情感表達有著非常重要的作用,不同級別的詞語會產生不同級別的情感傾向。例如:這個人極其討厭和這個人很討厭,同樣是對“討厭”進行修飾,但是“極其”所表達的情感傾向比“很”更加強烈。針對這些能夠對情感傾向產生巨大作用的詞匯,本文借助HowNet提供的中文程度級別詞語,構建了程度詞語詞典。HowNet對程度詞語進行了級別分類,具體分為6個等級:最(most)、很(very)、較(more)、稍(-ish)、欠(insufficiently)和超(over)。本文按照修飾程度的不同為這6個級別的程度詞分別賦予不同的權重值,程度詞典表如表1所示。

表1 程度詞典表
1.2.2 否定詞典與轉折歸總詞典構建
否定詞在文本分析中起到置反情感傾向的作用,所以在分析文本情感傾向時也應該將否定詞作為重要的分析對象,因此本文構造了一部否定詞詞典。根據張誼生[20]的文獻,本文使用了28個否定副詞,這些詞包括:不、沒、無、非、莫、弗、勿、毋、未、否、別、無、休、不要、沒有、未必、難以、未曾、不能等。由于否定詞在進行情感判斷時具有置反作用,所以將其權值設置為-1。
文本中會存在很多轉折句型,在轉折句型中往往會發生情感反轉,將前一部分表達的情感弱化,從而突出轉折之后的情感。同樣,文本中可能也會包含對作者觀點進行總結的歸總類詞匯,包含這類詞匯的分句更能夠表達作者的情感傾向,所以需要賦予更高的權重比例。通過查閱金允經等[21]的文獻,本文選擇但、但是、卻、然而、不過、只是、就是、總之、總而言之、總體來看、認為、覺得、總結、綜上所述等作為轉折歸總詞匯。
本文情感詞典的構建過程如圖1所示:
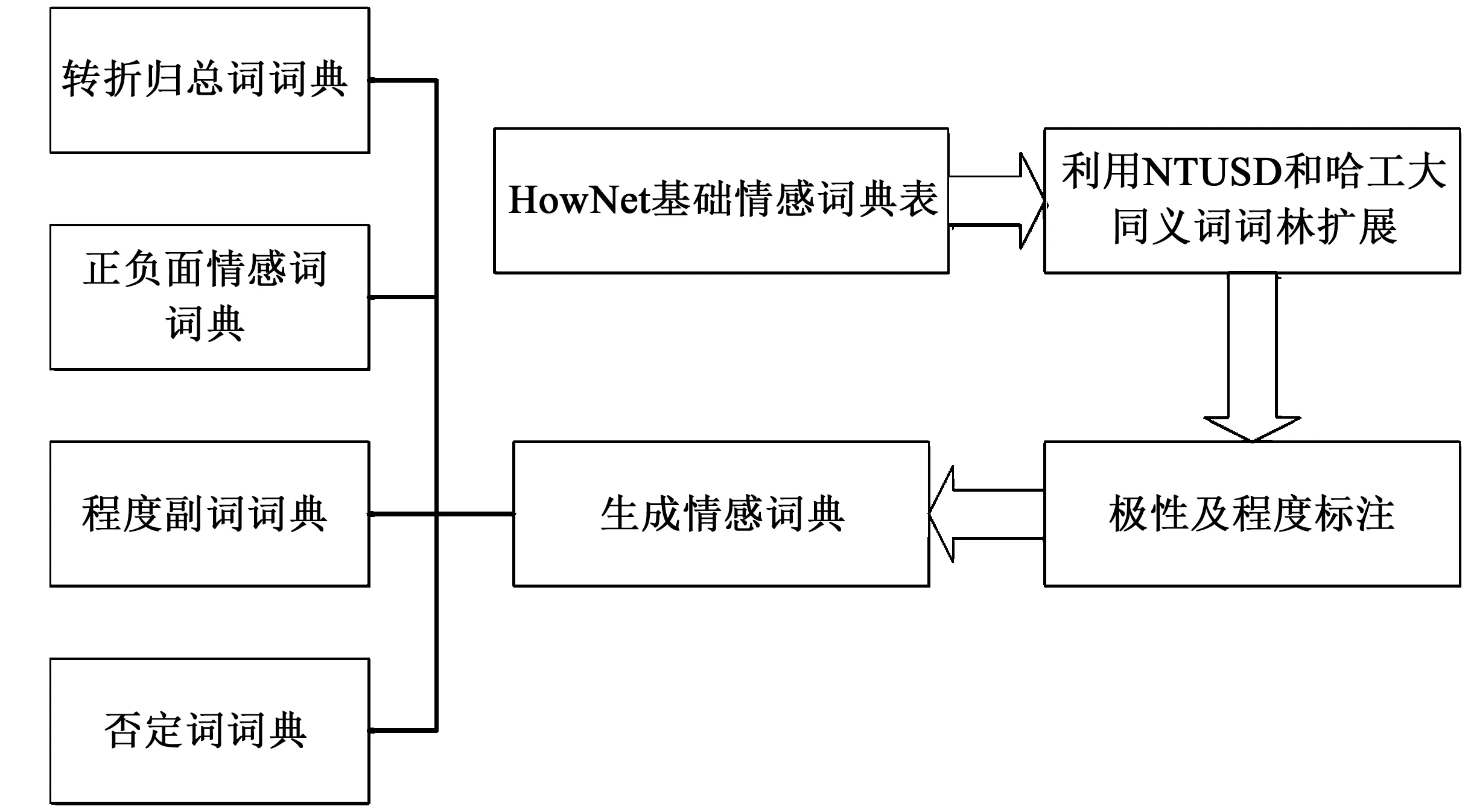
圖1 情感詞典構建流程Fig.1 Construction process of sentiment lexicons
1.3 規則定義
情感詞典的構建可以把情感詞語從句子中孤立出來,但是如果孤立地看待這些詞語,并不能正確地反映新聞的情感傾向。為了提高分析的準確度,必須將上下文的聯系考慮進來。因此,在詞語情感計算的基礎上,應該考慮上下文中能夠改變詞語情感傾向或者情感強度的語義規則信息。
本文結合新聞文體的特點,綜合情感詞典、情感句位置、標題等元素定義了多種語義規則用于情感句的傾向性計算。
1.3.1 情感表達組合
對新聞進行切割,分為段落、句子以及意群,以意群為最小情感單元進行分詞獲取情感詞匯。以情感詞匯為中心,與情感表達有關的規則有如下幾種:
規則1:只包含情感詞匯而不包含其他修飾詞匯的意群,例如:今天心情不錯。例子當中只包含“不錯”一個情感詞,該類別的意群權值計算如公式2所示,其中w為該意群的情感值,p為該情感詞匯的情感值,N為情感詞匯數量。

(2)
規則2:包含否定修飾詞意群,例如:今天我不高興!例子中存在否定詞“不”來修飾情感詞“高興”,那么句子的傾向性發生了反轉,由正面變成了負面。該類別的意群情感值計算如公式3所示,其中m為修飾該情感詞的否定詞的個數,m的選取采用了滑動窗口方式。通過對情感語料的分析,本文將m設置為5,即選擇情感詞匯之前5個詞匯中的否定詞個數。
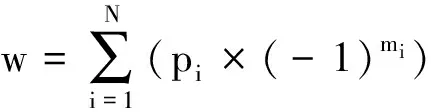
(3)
規則3:包含程度修飾詞的意群,例如:今天我很高興!例子中存在“很”這樣一個程度詞來修飾“高興”,那么本來的意群情感傾向在經過修飾后得到了明顯的加強。該類別的意群情感值計算如公式4所示,其中d表示修飾該情感詞匯的程度詞的情感權重,程度修飾詞的選擇依然采用滑動窗口的方式,根據對情感語料的分析,本文設置窗口大小為情感詞匯前后各3個。
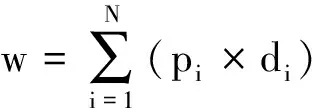
(4)
規則4:包含否定詞、程度詞和情感詞匯的意群,其中否定詞位于程度詞之前,例如:今天我不是很高興。這種句型當中,否定詞將程度詞的情感程度有所弱化,意群情感計算方式如公式5所示,其中α為否定詞和程度詞的位置信息權重,這里取0.8。
(5)
規則5:包含程度詞、否定詞和情感詞匯的意群,其中否定詞位于程度詞之后,例如:今天我很不高興。這種句型當中,否定詞將程度詞的情感傾向明顯加強,意群情感計算方式如公式5所示,其中w的取值為1.2。
規則6:當上述規則中含有轉折、歸總詞匯或者位于段首與段尾時,其情感值計算的權重要增強。計算方式如公式6所示,其中wori為未引入規則6時計算出的情感值:
w=1.2×wori。
(6)
根據上述規則可以計算出每個句子的意群情感傾向值,由此可以計算句子、段落以及篇章的最終情感值,從而得到新聞的情感傾向。其中,s為該句子的情感值;P為段落的情感值;K為該句意群總數;M為該段落句子總數;n為最終情感值;Q為該篇章段落總數。
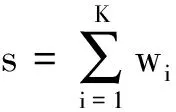
(7)
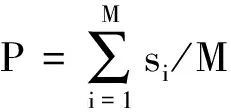
(8)

(9)
1.3.2 分析流程
本文使用的基于規則的網絡新聞文本情感分析具體流程如下:
(1)文本切割。將文本Doc按照換行符“/r”或者“/n”切割成段落Para,再按照[“。”,“?”,“!”]將Para分為Sen,最后按照[“,”]將Sen切割為多個意群SenGroup。
(2)文本預處理與情感定位。對每個意群使用FudanNLP進行分詞,結合情感詞典獲取情感關鍵詞并按照sentimentword四元組進行標注。
(3)融合規則計算意群情感值。通過文中定義的6個規則,對得到的意群進行情感值計算。
(4)計算句子情感傾向值。通過規則對意群加權得到句子的情感值之后需要再次計算該句子與標題的文本相似度。文本采用SimHash算法進行相似度計算,生成標題和要對比句子的Hash值,再通過計算兩個Hash值的海明距離判斷相似度。此時句子的情感傾向值計算方式如公式10所示,其中α的值根據相似度進行調整,相似度越高α越大。sori為未進行相似度計算時的句子情感值:
s=α×sori。
(10)
(5)計算段落以及篇章的情感傾向值,最終得到文本的情感傾向。算法流程如圖2所示。

圖2 算法流程分析Fig.2 Algorithm flow analysis
2 實驗結果與分析
2.1 數據來源及任務指標
數據集1來源于網易和新浪新聞板塊,通過網絡爬蟲共采集1 000篇新聞語料,采用人工標注的方式進行情感標注,其中正面新聞320篇,負面新聞219篇,其余為中性新聞。數據集2采用網絡爬蟲爬取的新聞、博客、論壇各300篇作為測試數據集。文本采用準確率(precision)、召回率(recall)和F1值對實驗結果進行評估。計算方式如下,其中a為判斷正確的文本數目;b為實際正確的文本數目,c為所有的文本數目,Pre為準確率;Rec為召回率:
Pre=(a/b)×100% ,
(11)
Rec=(a/c)×100% ,
(12)

(13)
2.2 結果與分析
本文實驗1以只考慮情感詞典而未加入任何規則條件的測試結果作為baseline,將融入規則的測試與之進行對比。結果如表2所示,其中RPos為正面新聞召回率、PPos為正面新聞準確率、F1Pos為正面新聞F1值;RNeg、PNeg和F1Neg分別代表負面新聞召回率、準確率和F1值。通過結果可知,只采用情感詞匯權重加權方式的情感傾向性計算方式比本文采用的基于情感詞典和規則的計算方式各項指標明顯偏低,在復雜的語言環境下,相同的詞匯在不同的上下文中所代表的語義有所不同,單純只考慮詞匯本身的含義不能準確表達情感信息。隨著各類規則的加入,綜合考慮上下文語義關系,本文得到的實驗結果準確率和召回率都在0.75以上,從而驗證了本文方法是有效可行的。

表2 實驗1結果
實驗2對數據集2中的數據進行分析,與目前比較主流的分析方法SVM進行對比。SVM采用的是臺灣大學林智仁教授開發的LibSVM。實驗結果如表3所示。其中Rec為召回率、Pre為準確率。從實驗結果來看,通過對各類規則的總結,本文提供的方法要優于SVM算法,說明本文提供的方法是有效的。

表3 實驗2結果
3 結語
本文在對網絡新聞文體結構分析的基礎上,先后構建了正負面情感詞典、否定詞詞典、程度副詞詞典、轉折歸總詞典,結合多種規則,提出了一種基于詞典和規則的網絡新聞文本情感分析方法,并通過實驗對本方法的有效性和可行性進行了驗證。雖然此次研究取得了一定的成果,但是尚有許多工作需要完成,如含有歧義的詞語的處理;篇章級的情感值是通過段落加權平均得到,而段落的情感值又是通過句子的加權平均獲得,這種方式雖然能取得不錯的效果,但是仍然比較簡單。因此,如何消除詞語歧義和更好地獲取篇章級情感值是下一步的研究重點。
[1]趙妍妍,秦兵,劉挺.文本情感分析[J].軟件學報,2010,21(8):1834-1848.
[2]LIUB,HUMQ,CHENGJS.Opinionobserver:AnalyzingandcomparingopiniosontheWeb[C]//Proceedingsofthe14thinternationalconferenceonWorldWideWeb.NewYork,NY,USA:ACM,2005:342-351.
[3]PANGB,LEEL.Opinionminingandsentimentanalysis[J].Foundationsandtrendsininformationretrieval,2008,2(1/2):1-135.
[4]王成. 基于半監督機器學習的文本情感分析技術[D]. 南京;南京理工大學,2015.
[5]孫建旺,呂學強,張雷瀚. 基于詞典與機器學習的中文微博情感分析研究[J]. 計算機應用與軟件,2014, 31(7):177-181.
[6]楊佳能,陽愛民,周詠梅. 基于語義分析的中文微博情感分類方法[J]. 山東大學學報(理學版),2014,49(11):14-21.
[7]張志飛,苗奪謙,岳曉冬,等. 強語義模糊性詞語的情感分析[J]. 中文信息學報,2015,29(2):68-78.
[8]PANGB,LEEL,VAITHYANATHANS.Thumbsup?Sentimentclassificationusingmachinelearningtechniques[EB/OL]. [2016-03-04].http://delivery.acm.org/10.1145/1120000/1118704/p79-pang.pdf?ip=222.173.55.212&id=1118704&acc=OPEN&key=4D4702B0C3E38B35%2E4D4702B0C3E38B35%2E4D4702B0C3E38B35%2E6D218144511F3437&CFID=849300259&CFTOKEN=78353276&__acm__=1475909422_f62191db62812a3a07db2d210c7dc31b.
[9]TANSB,ZHANGJ.AnempiricalstudyofsentimentanalysisforChinesedocuments[J].ExpertSystemswithApplications, 2008, 34(4):2622-2629.
[10]樊小超. 基于機器學習的中文文本主題分類及情感分類研究[D]. 南京:南京理工大學, 2014.
[11]朱嫣嵐, 閔錦, 周雅倩,等. 基于HowNet的詞匯語義傾向計算[J]. 中文信息學報, 2006, 20(1):14-20.
[12]TURNEYPD,LITTMANML.Measuringpraiseandcriticism:Inferenceofsemanticorientationfromassociation[J].AcmTransactionsonInformationSystems, 2003, 21(4):315-346.
[13]馮亮祖. 基于情感關鍵句的新聞文本情感分類研究[D]. 北京:北京郵電大學, 2015.
[14]張成功, 劉培玉, 朱振方,等. 一種基于極性詞典的情感分析方法[J]. 山東大學學報(理學版), 2012, 47(3):47-50.
[15]李凌燕. 新聞敘事的主觀性研究[M]. 上海:東方出版中心, 2013.
[16]謝暉. 新聞文本學[M]. 北京:中國傳媒大學出版社, 2007.
[17]YESSENALINAA,YUEY,CARDIEC.Multi-levelstructuredmodelsfordocument-levelsentimentclassification[C]//ConferenceonEmpiricalmethodsinnaturallanguageprocessing.Massachusetts,USA:AssociationforComputationallinguistics,2010:1046-1105.
[18]李本陽. 句子和篇章文本傾向分析[D]. 哈爾濱: 哈爾濱工業大學, 2010.
[19]杜偉夫. 文本傾向性分析中的情感詞典構建技術研究[D]. 哈爾濱:哈爾濱工業大學, 2010.
[20]張誼生.現代漢語副詞研究[M].上海:學林出版社,2000.
[21]金允經,金昌吉. 現代漢語轉折連詞組的同異研究[J]. 漢語學習,2001(2):34-40.
DOI:10.3976/j.issn.1002-4026.2017.01.020
Lexiconandrulesbasednewstextsentimentanalysis
LIChen1,ZHUShi-wei1,WEIMo-ji1,YUJun-feng1,LIXin-tian2
(1.InformationInstitute,ShandongAcademyofSciences,Jinan250014,China;2.BiologyInstitute,ShandongAcademyofSciences,Jinan250014,China)
∶Accordingtothestructure,thenewsstylewasdividedintoseveralparagraphs.Basedonsentimentlexiconandsemanticrules,amethodofextractingsentimentalkeysentenceswasusedtoanalyzethesentimentofsentenceswithineachparagraph.Firstly,sentimentlexiconwasbuiltbyconsideringtheemotion,twist,negation,degreeandsumsupvocabularies;Secondly,accordingtorules,newstextwasdividedintosensegroups,sentences,paragraphsandchapters;Furthermore,orientationvalueofsentimentalkeysentenceswascomputedbytherulesestablished,andthenthesentimentalorientationvalueoftheparagraphsandthewholechapterswasobtainedbyweightedaverageofsentences,thusthesentimentalorientationofnewswasrevealed.ComparedwithlexiconbasedmethodandSVMsentimentclassification,experimentalresultsshowthatthemethodproposedhasgoodeffectsontheorientationidentificationofnewstext,showinggoodfeasibilityaswell.
∶sentimentanalysis;rules;sentimentlexicon;onlinenews
10.3976/j.issn.1002-4026.2017.01.019
2016-07-13
山東省科技發展計劃(2014GGX101013);山東省重點研發計劃(2015GGX101032,2015GGX101037,2016GGX101018)
李晨(1988—),男,碩士,研究方向為大數據和數據挖掘。
TP
A
1002-4026(2017)02-0115-07
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
中華胰腺病雜志(2021年1期)2021-02-26 11:28:36
山東醫藥(2020年34期)2020-12-09 01:22:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
中華胰腺病雜志(2019年4期)2019-08-29 08:52:20
電子制作(2018年18期)2018-11-14 01:48:06
Coco薇(2017年11期)2018-01-03 20:59:57
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
小學教學參考(2015年20期)2016-01-15 08:44:38
