面向微博的PageRank算法的改進與應用
2017-04-14 00:46:57田麗華
計算機應用與軟件 2017年3期
關鍵詞:用戶
原 野 李 晨 田麗華*
1(西安交通大學軟件學院 陜西 西安 710049)2(新浪網(wǎng)技術(中國)有限公司 北京 100000)
面向微博的PageRank算法的改進與應用
原 野1,2李 晨1田麗華1*
1(西安交通大學軟件學院 陜西 西安 710049)2(新浪網(wǎng)技術(中國)有限公司 北京 100000)
從海量數(shù)據(jù)下的社會化網(wǎng)絡中識別出各個領域下產出高質量內容的具有一定影響力的專家,進行具有針對性的廣告推薦與決策支持,已經(jīng)成為微博數(shù)據(jù)挖掘亟待解決的問題之一。從微博的用戶特征和行為特征出發(fā),確定了采集博文的規(guī)則與互動量計算公式,并應用PageRank算法對微博用戶影響力計算時存在的數(shù)據(jù)陳舊性和主題不相關性的問題進行了改進,最后分別基于MapReduce和Spark的并行計算框架對算法進行了實現(xiàn)。實驗結果表明,該挖掘方法具有較好的準確性,在Spark并行計算框架下表現(xiàn)出較高的性能,尤其適合大規(guī)模數(shù)據(jù)集的場景。
微博 用戶影響力 PageRank Spark 大數(shù)據(jù)
0 引 言
微博是一種典型的Web 2.0社交網(wǎng)絡服務SNS(Social Networks Service)應用[1]。它以短文本、圖片、小視頻等方式拓展了用戶的交流途徑,創(chuàng)建了一個類似傳統(tǒng)社區(qū)的網(wǎng)絡虛擬圈。新浪微博由于其對產品的精準定位,在競爭中脫穎而出,領先于國內同類產品,已經(jīng)融入到社會生活的方方面面,成為了獲取實時信息的最佳平臺。其擁有高達1.4億的日活躍用戶數(shù),每天有數(shù)百GB甚至TB級別的結構化數(shù)據(jù)入庫。因此,從海量數(shù)據(jù)下的社會化網(wǎng)絡中識別出各領域下的專家和具有一定影響力的用戶,進而利用這些識別出的專家和用戶進行具有針對性的推薦,已經(jīng)成為亟待解決的問題。
對于高影響力微博用戶的挖掘,不少研究從PageRank算法和評估模型入手,進行了影響力評估[2-5]。這些研究專注于某個模型或者算法的改進,為建立用戶評價模型提出了多種思路,但均沒有考慮挖掘數(shù)據(jù)的規(guī)模、可應用性和可擴展性,無法產生實際的應用價值。其中,文獻[3]結合用戶潛在的影響力和博文傳播影響力,提出了一種基于PageRank的影響力評估指標,具有一定的合理性和有效性。但這些指標缺乏通用性,只能描述特定的少量用戶,因此,其計算的范圍被局限,不能針對海量的用戶進行計算與應用。針對用戶推薦與挖掘,也有一些研究從其他方面入手,利用聚類、鏈接分析、標簽預測等方法提出了一系列描述用戶興趣和影響力的方法及模型[6-8]。這些模型從不同的角度對用戶影響力進行了建模及實驗分析,每種方法都有各自的側重點,但同樣缺乏對海量數(shù)據(jù)集下的實證。如文獻[7]從鏈接分析和用戶行為兩個角度衡量用戶的影響力,提出了微博用戶影響力指數(shù)模型。但該模型以整體用戶為對象,沒有考慮微博用戶的聚類化,即在不同領域下分別進行影響力指數(shù)的計算,使用戶間的對比更有意義。
本文通過分析微博的互動機制,進而將用戶的行為量化,基于PageRank提出了一種微博用戶影響力計算方法。該方法改進了PageRank的主題陳舊性,引入了時間區(qū)間,限定分析的數(shù)據(jù)為最新數(shù)據(jù)。同時,方法還對領域進行了區(qū)分,針對領域內用戶而不是整體微博用戶進行計算,大大改善了算法的主題不相關特點。該算法兼顧了挖掘的覆蓋度和準確性,并針對并行計算框架做了設計與應用,使得用戶影響力計算方法能夠在大數(shù)據(jù)規(guī)模下高效運行,具有很高的可應用性和可擴展性。
1 PageRank算法
PageRank算法,又稱為佩奇排名算法,是谷歌用來衡量網(wǎng)頁重要性、標識網(wǎng)頁等級的一種方法[9]。PageRank算法的基本思想是:確立一個評估網(wǎng)頁的權重值(PR值),該值標志著一個網(wǎng)頁的相關性和質量。在揉合考慮多個特征元素之后,評估指向某個網(wǎng)頁的其他網(wǎng)頁的重要性,再給出這個網(wǎng)頁的重要性。即“被越多優(yōu)秀的網(wǎng)頁所指向的網(wǎng)頁,它是優(yōu)質網(wǎng)頁的概率會更大”。
PageRank算法在入鏈數(shù)的基礎上考慮了網(wǎng)頁質量的因素,提出了兩個基本的假設:
(1) 數(shù)量假設:在網(wǎng)頁圖模型中,如果某個頁面得到的入鏈數(shù)數(shù)目越多,則證明其具有更高的重要性。
(2) 質量假設:在網(wǎng)頁圖模型中,如果指向某個頁面的多個頁面的質量越高(PR值越大),則該頁面的重要性就會越高。
PageRank算法類似于一個投票系統(tǒng),每個人擁有一定的初始權值,PageRank算法是公平的,因此此權重值在開始時是一致的,并不會考慮其他元素的影響。隨后令每個人對其他人進行投票,且可以將自己的票按照一定的比例分別投給多個人。在一輪投票完畢后,每個用戶會得到匯總后的投票數(shù),該投票數(shù)就是其新一輪開始投票時具有的票數(shù)(權值)。如此反復投票N次,直到每個人獲得的投票數(shù)保持穩(wěn)定的時候,結束運算,每個人的最終得票值即為其重要性。
在網(wǎng)頁中,某些網(wǎng)頁是沒有網(wǎng)頁指向的,也有某些網(wǎng)頁是沒有任何鏈接的,這些孤立網(wǎng)頁會在迭代計算的過程中逐漸降低得分直至為0或者在某次排名中丟失,出現(xiàn)“排名泄漏”和“排名下沉”。因此,PagRank中存在一個阻尼系數(shù),來防止這些情況的出現(xiàn),如式(1)所示:
(1)
其中,P1,P2,…,Pn是被研究的頁面,N是所有頁面的數(shù)量,L(Pj)是Pj鏈出頁面的數(shù)量,M(Pi)是Pi鏈入頁面的數(shù)量,q為阻尼系數(shù)。
2 微博互動機制
以新浪微博為例,互動主要由某些特定的用戶發(fā)布博文來引發(fā),整個互動過程是一對多的,以某個用戶的博文或話題為中心,層層傳播,帶動起大量普通用戶的參與。因此要觀察研究微博互動的機制,就需要從用戶特征和行為特征兩個方面出發(fā)。
1) 用戶特征
通過觀察分析新浪微博近3個月的熱門微博榜數(shù)據(jù),可以發(fā)現(xiàn)榜單上的用戶構成主要如圖1所示,其中微博會員是微博的一種收費機制,主要作用在于提升微博用戶發(fā)表博文的傳播力。一般來說,微博會員活躍度高,內容產出質量也較高,其占據(jù)了12.35%的熱門微博數(shù)。橙V與藍V用戶,由于其經(jīng)過官方認證,具有更高的權威性和可靠性,因此其影響力更大,傳播范圍更廣,分別占據(jù)了15.60%與7.23%的熱門微博數(shù)。對于人氣草根來說,一般是因為某些特殊事件或引發(fā)群體關注的博文而被大家關注,這類用戶未來產生高影響力的可能性非常大。由上述微博會員、橙V、藍V、人氣草根構成了一個能力用戶集合,該集合內用戶具備長期穩(wěn)定輸出高質量內容的能力。同時,集合需要排除一部分用戶,即少量轉發(fā)抽獎、營銷等賬號。該類用戶能夠上榜往往是由投入了大量資金而出現(xiàn)短暫性爆發(fā)的關注度,其下的用戶一般不具備長期穩(wěn)定輸出高質量內容的能力。由此,確定了博文采集數(shù)據(jù)源的集合為上面提到的能力用戶集合,而將其他類用戶排除在外。

圖1 熱門微博用戶構成
2) 行為特征
微博用戶間的互動特征在很大程度上是由用戶發(fā)布消息的屬性特征所顯現(xiàn)出來的[10]。互動行為可以細化和歸結為多個種類,但從博文的影響力和擴散性而言,互動行為主要分為轉發(fā)、評論、贊等三種用戶行為,用戶間互動的中心可以是話題、博文或者評論,以原創(chuàng)博文為中心的對話環(huán)狀結構如圖2所示。其中原創(chuàng)博文外第一圈為第一層傳播者,影響力較高,此時也存在贊行為,但更為注重的是其轉發(fā)和評論,虛線表示原創(chuàng)博文用戶有時會回轉第一層傳播者的評論以獲得新一輪的關注。下面是針對三種用戶行為的具體介紹。
① 轉發(fā)。該行為是指某個用戶在閱讀了一篇博文(長博文或短博文)之后產生了強烈的共鳴或反對情緒。其表現(xiàn)出該用戶對該博文產生了較強的關注且急于抒發(fā)自己的直觀感受。轉發(fā)數(shù)的高低反映了消息擴散程度和傳播覆蓋面的廣度。
② 評論。評論是閱讀博文后有所感觸,由此產生的意見和看法。評論數(shù)的高低反映了消息在擴散中引發(fā)的反響程度,也直接的體現(xiàn)了消息的影響力。
③ 贊。此行為只是單純的表達對一條博文是否認同,其用戶主觀性比轉發(fā)和評論都要弱。贊的數(shù)目只能間接的反映一條博文的影響力。

圖2 以原創(chuàng)博文為中心的環(huán)狀傳播
3) 數(shù)據(jù)源過濾規(guī)則與互動行為量化
根據(jù)對用戶特征與行為特征的分析,可以確定微博用戶影響力計算過程中使用的博文數(shù)據(jù)源的過濾規(guī)則,并可以得出用戶互動量的計算公式。
① 過濾規(guī)則。以博文為中心,就要先提取出各個領域下的高質量博文,這里采用用戶特征屬性來過濾這些博文。以新浪微博提供的API為例,博文數(shù)據(jù)源分為5個等級,橙V用戶博文、微博會員博文、高質量可信用戶博文、普通用戶博文以及營銷信息等低質量博文。根據(jù)規(guī)則,確定普通用戶及以上等級的博文為數(shù)據(jù)源,之所以采用普通用戶博文,是由于某些普通用戶可能潛在內容輸出能力,進而成為新的微博人氣草根。確定用戶特征后,根據(jù)博文的原創(chuàng)標識字段,進一步確定博文是原創(chuàng)博文,所有轉發(fā)以及二次原創(chuàng)博文都將被排除在外。確定了過濾規(guī)則后,經(jīng)過過濾篩選的博文成為初始數(shù)據(jù)源。
② 互動行為量化。本文提出了相應的用戶間的互動行為的量化,闡述如下。在T1到T2時間段內,某用戶對另一用戶的所有博文所產生的互動行為的總和,稱為該用戶對單個用戶的互動行為量,如式(2)所示:
(2)
而在T1到T2時間段內,某用戶對另一個用戶的互動行為量占其某時間段內總行為量的占比,稱為用戶對單個用戶的互動行為概率,如式(3)所示:
(3)
其中,確定轉發(fā)、評論、贊行為的影響力因子分別為a、b、c,三個因子之和為1。T1、T2為時間點,所有博文的轉發(fā)、評論、贊的總次數(shù)分別為c_repo、c_cmt、c_like。
3 基于PageRank的微博用戶影響力計算方法
在以博文為中心的環(huán)狀傳播中,若某用戶的博文產生的轉發(fā)、評論、贊的數(shù)目越大,則其更容易出現(xiàn)在微博頭條之上,也代表其重要性和影響力更大。如果在與某條微博發(fā)生互動行為的用戶當中,具有高影響力和權重的高質量用戶數(shù)量更多,則表明該博文的用戶影響力更大。因此,微博的互動機制完全符合PageRank算法的基本條件,可以采用PageRank算法來進行微博用戶影響力的計算。針對PageRank算法應用于微博時存在的問題,本文在其對微博影響力的計算方面進行了相應的改進。
1) 數(shù)據(jù)陳舊性
在PageRank算法的基本原理中,網(wǎng)頁的PR值均勻地分配給鏈出的網(wǎng)頁,這樣會造成存在時間比較久的舊網(wǎng)頁被鏈接次數(shù)明顯高于新網(wǎng)頁,從而使得舊網(wǎng)頁PR值高但內容陳舊,新網(wǎng)頁PR值低但內容重要[11]。本文提出的在微博中應用的PageRank算法通過引入時間區(qū)間的方法,來解決了這個問題。引入算法進行計算的用戶博文數(shù)據(jù),限定在一定時間段內,這樣一來,由用戶產生的互動量就被限制在了最新區(qū)間內,可以實時、動態(tài)反映用戶最新的影響力情況。
2) 主題相關性
PageRank應用在網(wǎng)頁鏈接排名中的另一個缺點是忽略了主題性,導致結果的相關性和主題性降低[12]。而本文以博文為中心的影響力的計算是限定在一定領域內的。多個領域下的數(shù)據(jù)可以混合并同時進行運算,一個領域下的能力不對另一個領域下的能力產生任何影響,由此,在確定了領域的同時又保證了計算的公平性和準確性。
根據(jù)上述結論,本文確定了以博文為中心,以用戶博文的互動量為用戶影響力的評價標準,具體流程如圖3所示。

圖3 微博用戶影響力計算流程圖
1) 初始權值和概率轉移矩陣的建立
在得到了互動量計算公式之后,就可以考慮將其應用到PageRank算法之中了。應用PagekRank算法最重要也是最基本的流程為兩步:第一步建立概率轉移矩陣,上述用戶對單個用戶的行為概率就是概率轉移矩陣中的概率值。第二步初始化權值,對不同領域下的用戶按照一定的規(guī)則賦初值。規(guī)則如下:
① 用戶數(shù)在1千萬以下的領域:用戶初始權值為1/E。這里E為該領域下的總數(shù)。
② 用戶數(shù)在1千萬以上的領域:用戶初始權值為1/E。這里一般取E>107,才能保證算法收斂時,所得權值不至過大而給后續(xù)計算帶來問題。
2) 迭代計算過程
將初始權值與概率矩陣相乘,相乘得到的結果為新一輪的權值,之后將新權值繼續(xù)與概率矩陣相乘,重復迭代計算至兩次結果差值小于ε,得到最終計算結果。
此處偽代碼如下,其中X為權值(x1,x2,…,xn),A為概率轉移矩陣:
R=AX;
while(true ) {
if(|X-R|<ε) {
//如果最后兩次的結果近似或者相同,返回
return R;
} else{
X=R;
R=AX;
}
}
4 算法并行化實現(xiàn)及結果分析
根據(jù)算法的設定,取某一時間段的博文進行處理分析與計算,一般來說,離線分析取時間跨度在2個月以上的博文數(shù)據(jù)較為合適,而每天在微博全領域下產生的博文經(jīng)過過濾后數(shù)據(jù)量仍在千萬級別,即需要處理2個月近億條(TB級別)的數(shù)據(jù),而這只是博文數(shù)據(jù)。在計算互動量時,針對每一條博文都有數(shù)十萬的轉發(fā)、評論、贊,數(shù)據(jù)量的規(guī)模已經(jīng)遠遠超過了單機所能處理的范圍。因此,必須采用分布式系統(tǒng)下的分布式計算框架,才能夠滿足算法運行的需求。本文從兩種最流行的分布式計算框架出發(fā),對算法進行了并行化設計,并在之后對其進行性能分析比較,最終確定出適合的運算框架。
4.1 MapReduce與Spark計算框架下的迭代計算設計
1) 數(shù)據(jù)采集與格式
本文通過使用新浪微博內部API以及數(shù)據(jù)倉庫來獲取新浪微博的用戶數(shù)據(jù),所有數(shù)據(jù)均為線上真實數(shù)據(jù)。數(shù)據(jù)的格式、初始權值及概率轉移矩陣的全部數(shù)據(jù)以行文本格式出現(xiàn)。通過多級hive操作及MapReduce程序的清理轉化,得到了參與計算的初始數(shù)據(jù)集合。其中,某領域下初始權值的文本存儲格式如表1所示,鄰接矩陣的文本存儲格式如表2所示。借助加入標簽與用戶uid組合,可以將用戶加入到不同領域的計算中去,如果某用戶在多個領域下均存在內容輸出能力,在這種方式下由于標簽的存在,用戶在各領域下的計算就不會產生相互影響。
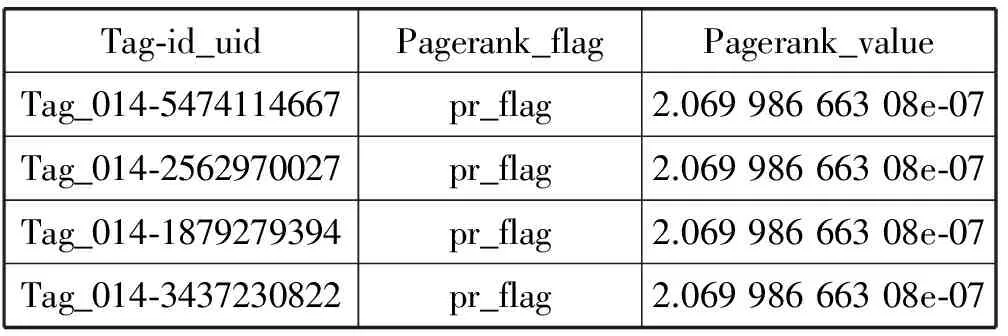
表1 初始權值文本存儲格式示例
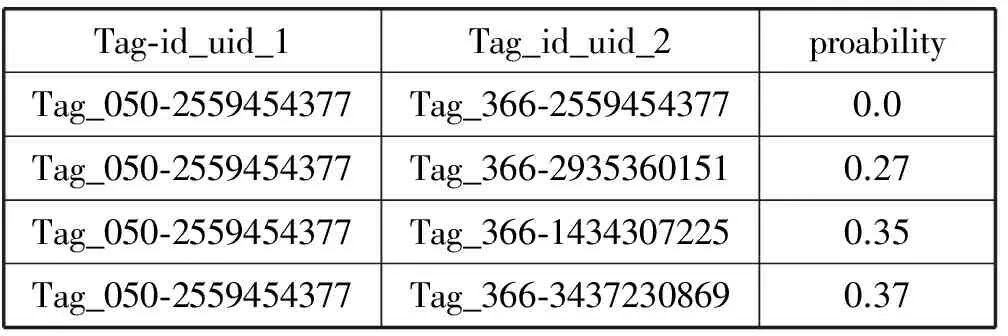
表2 初始鄰接矩陣文本存儲格式示例
2) MapReduce下的迭代計算設計
在使用python編寫的MapReduce代碼中,不能將全部的初始權值、矩陣載入內存后做矩陣乘法。因為數(shù)據(jù)量的規(guī)模巨大,集群中在高負荷運算下沒有一個單點的內存可以載入全部的用戶權值集合。因此,將每一個用戶的權值分別乘以矩陣中的它對應的那一行的概率值(即某個點的全部出度的值),對整個矩陣做了這樣的操作后,得到一個臨時矩陣TMP_MATRIX。該矩陣為概率值乘以權值得到的矩陣,其每一列(即某個點的全部入度對應的值)相加后的值的和,就是要得到的這一輪迭代的某個用戶下的新權值,再將新權值作為輸入返回迭代計算(見圖4中“迭代計算”部分所示)。這樣一來,就將龐大的矩陣計算拆分成了多個可以并行計算的任務,而這些任務之間又相互沒有任何依賴關系,可以很輕松地將其轉化為MapReduce程序進行計算。在編寫MapReduce程序時,需要巧妙地利用HadoopStreamming將第一列認定為進入shuffle階段的鍵值的特性,通過拆分、合并、轉化標簽類別TagCategory和uid來實現(xiàn)迭代的兩個步驟。
MapReduce下的計算過程如圖4所示。
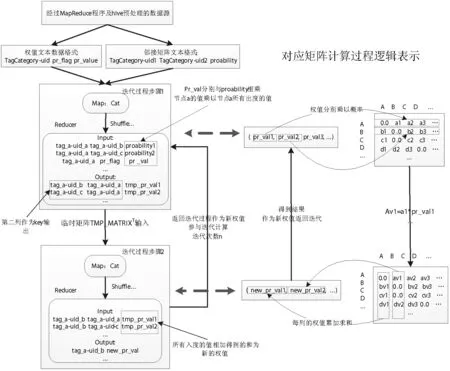
圖4 MapReduce框架下微博用戶影響力計算過程
3) Spark計算框架下的迭代計算設計
Spark框架計算過程使用與MapReduc計算相同的數(shù)據(jù)作為輸入源。根據(jù)使用的初始權值數(shù)據(jù)和概率轉移矩陣數(shù)據(jù),Spark從HDFS上讀取文件進入內存并創(chuàng)建了兩個不同的彈性數(shù)據(jù)集rdd_pr_value和rdd_pr_relation,得到初始rdd后,經(jīng)過對兩份數(shù)據(jù)的join、mapToPair、flatMapToPair、reduceByKey、mapValues等數(shù)據(jù)集的轉化操作后,最終以saveAsHadoopFile激活操作將得到的結果數(shù)據(jù)集存入到HDFS中去。其整個過程都以內存計算為主,除了開始讀入數(shù)據(jù)與最終寫出數(shù)據(jù),整個計算過程基本不會與磁盤發(fā)生I/O行為,計算效率非常高。
在創(chuàng)建RDD(彈性數(shù)據(jù)集)之后,Spark會盡可能地將任務并行化、管道化,按照組織的數(shù)據(jù)來劃分階段(Stage)。PageRank算法的過程有固定Stage和變化Stage,其中準備鄰接矩陣、準備初始權值以及最終存入HDFS三個邏輯任務為固定不變的Stage,隨著數(shù)據(jù)量的擴大其處理的并行任務會增加但Stage并不增加。而只有迭代次數(shù)的不斷增加,才會帶來Stage數(shù)目的不斷增加,增加的次數(shù)要根據(jù)迭代部分的復雜程度來確定。在程序劃分好階段后,會產生DAG(有向無環(huán)圖)作為邏輯執(zhí)行計劃。在執(zhí)行的過程中,每個階段又可能被分為多個任務接受調度。詳細的RDD轉化過程如圖5所示。
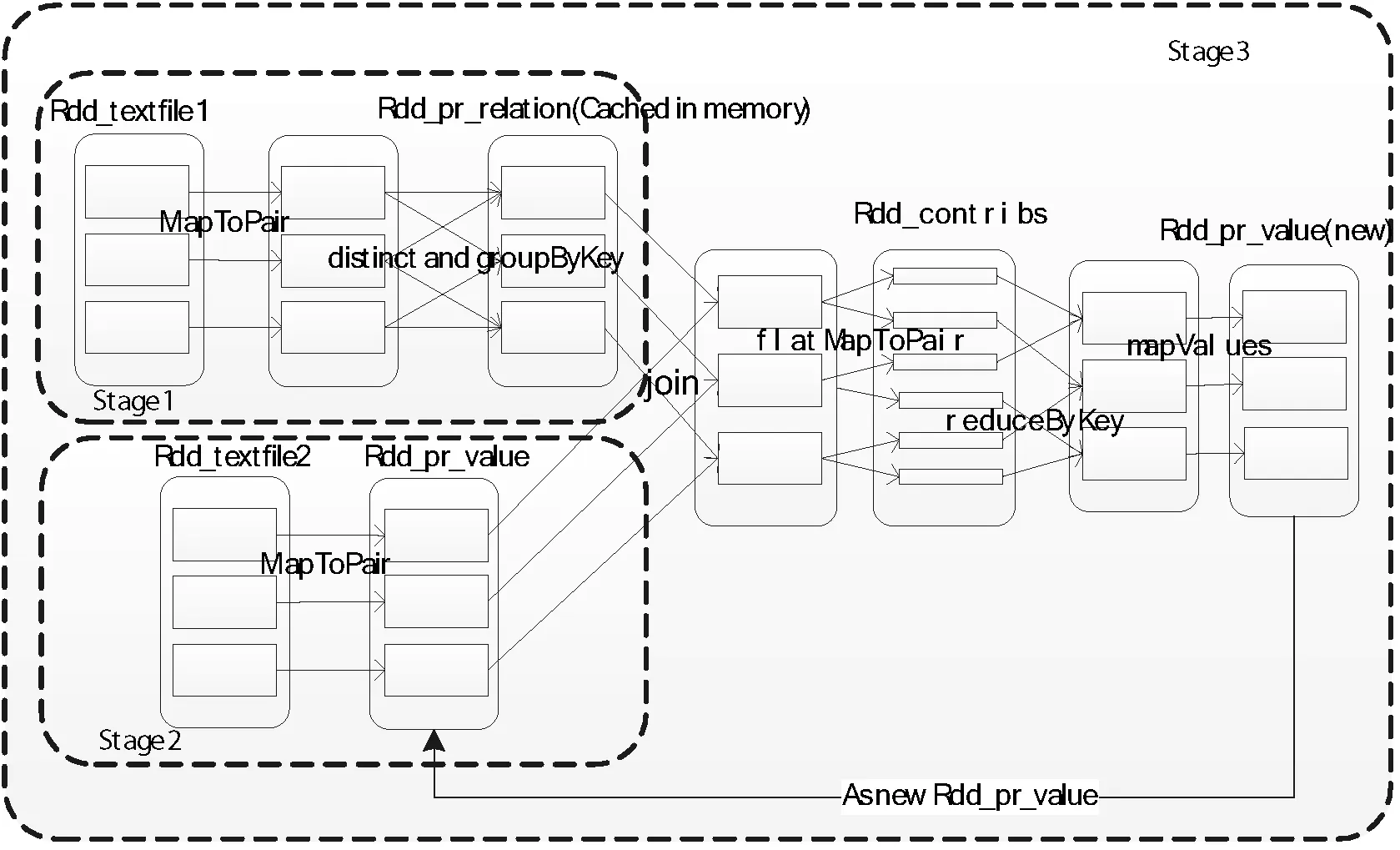
圖5 Spark框架下的PageRank計算RDD轉化過程
4) 動態(tài)選擇并行計算框架
在性能對比上,Spark的性能遠遠好于MapReduce,但這是以消耗巨大內存為前提的。彈性數(shù)據(jù)集意味著如果內存不足,那么有部分數(shù)據(jù)會被刷寫到磁盤之上,在這種情況下,Spark的速度與穩(wěn)定性均會降低,尤其是速度上并不比MapReduce快很多。因此,將挖掘中的全部任務都由MapReduce替換為Spark是不明智的,它會消耗大量資源,并引起資源調度的不穩(wěn)定。只有針對核心的、耗時較大的迭代任務,采用Spark才是高效的。結合集群使用情況來看,當Spark迭代任務與HadoopMapReduce任務同時運行在集群之中時,集群的負荷增大。通過監(jiān)控WebUI可以得知,非高峰期整體內存使用率在92%至96%之間,處于正常運行狀態(tài),但高峰期時,使用Spark進行迭代計算將因為集群內存不足節(jié)點數(shù)增加而導致部分任務被掛起等待,集群利用率下降。
由此,確定了只有迭代計算部分的任務采用Spark進行計算。且計算時采用動態(tài)選擇機制:設置Spark作為默認迭代計算框架,當啟動Spark迭代任務時,若集群整體內存充足,任務順利啟動進行計算;若內存空閑量足夠啟動的節(jié)點數(shù)不足,導致Spark任務無法啟動,返回錯誤代碼,腳本切換至HadoopMapReduce框架進行計算,整體切換流程如圖6所示。

圖6 動態(tài)切換計算框架流程圖
本文算法的執(zhí)行涉及到超大規(guī)模數(shù)據(jù)集(8 100萬條接近4 TB的初始數(shù)據(jù)),因此,在分析采用何種大規(guī)模分布式計算框架時,就會涉及到性能、數(shù)據(jù)量和穩(wěn)定性上的考慮。Spark將常用數(shù)據(jù)貯存于內存之中的機制,大大改善了MapReduce框架的運算性能,減少了大量的I/O開銷,但同時,這種內存計算框架也存在著大量消耗內存、調度不穩(wěn)定易崩潰的缺點。本文將兩種框架結合、根據(jù)集群當前使用情況進行動態(tài)選擇,以內存節(jié)點是否充足、Spark任務是否能正常啟動作為切換的條件。當內存充足,集群壓力正常的情況下,選擇Spark可以大大提升運行的效率;而在內存不足,集群壓力較大的情況下,選擇MapRedcue則更為穩(wěn)定,其穩(wěn)定性上的優(yōu)勢完全彌補了速度上的不足,在多人共用的集群環(huán)境下尤為明顯。
4.2 微博用戶影響力計算實驗結果及分析
實驗運行與測試均在相同的集群環(huán)境之下完成,具體情況如下:
(1) 集群節(jié)點全部部署Hadoop CDH4(Cloudera版本,對應Hadoop2.0),并以Spark on Hadoop方式部署Spark-0.9.4版本。
(2) 集群規(guī)模:600臺節(jié)點,共計28 TB總內存,CPU總核心數(shù)約1.5萬個,磁盤約1 800 TB。
挖掘任務在集群各節(jié)點上運行情況如圖7所示。
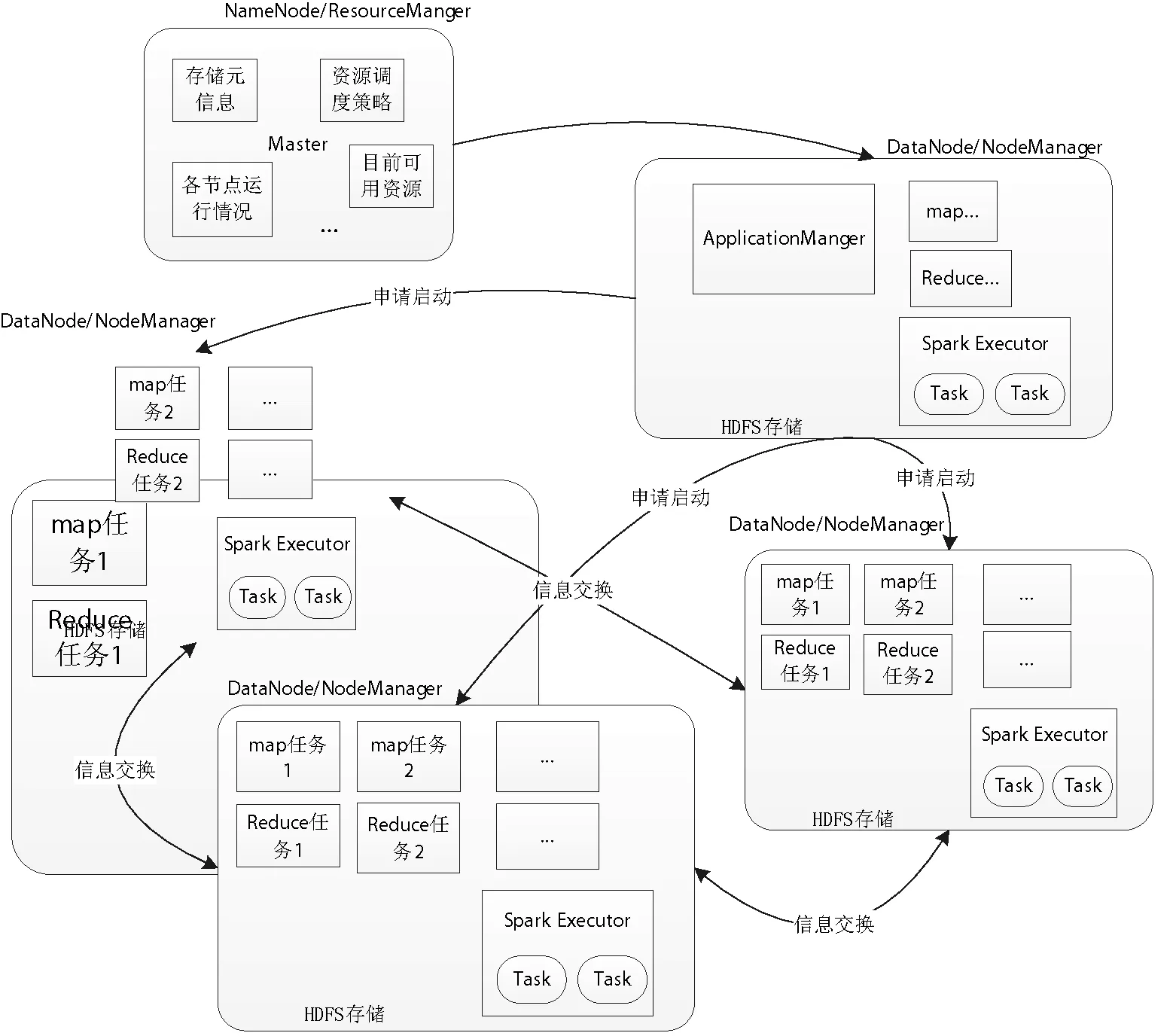
圖7 平臺基本運行情況示意
根據(jù)上一節(jié)中不同并行計算框架下的設計,編寫了MapRedce程序和Spark程序并運行在集群上,典型的用戶得分權重收斂情況如圖8所示,大部分用戶在迭代20次時歸于收斂,而迭代達到40次時,全部數(shù)據(jù)歸于收斂。
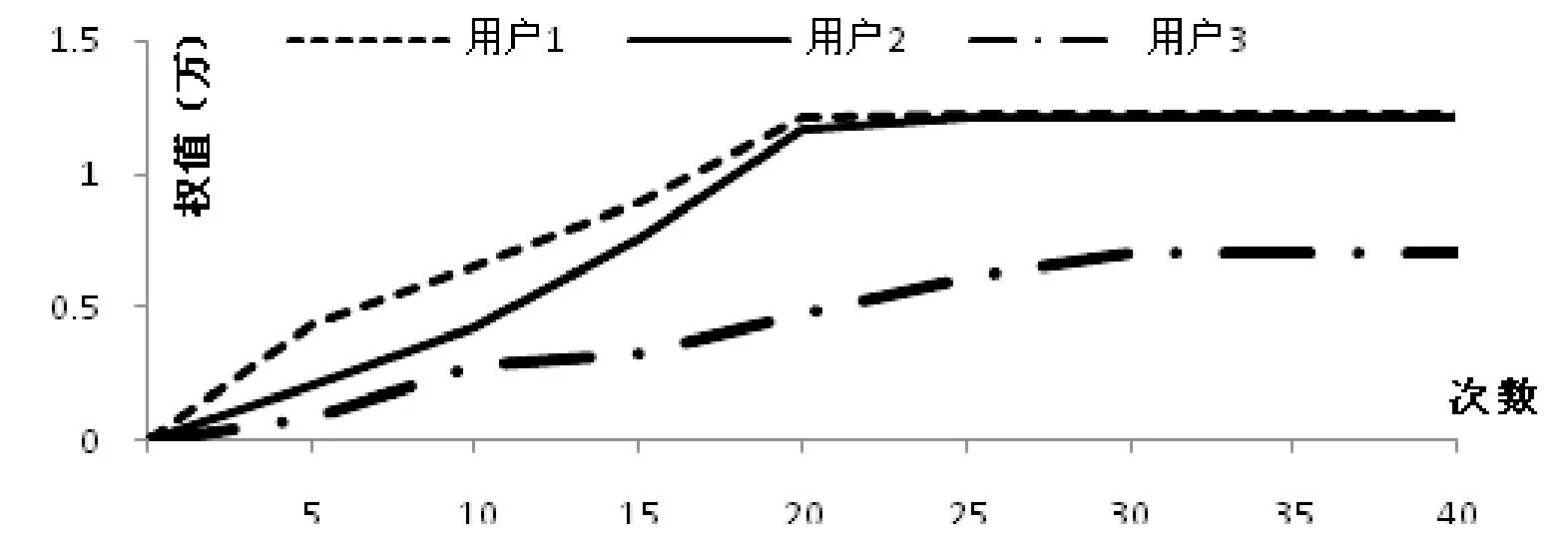
圖8 隨迭代次數(shù)增加用戶權值收斂情況
上述集群環(huán)境下,進行了多次用戶影響力計算實驗,總體計算時間保持在1個小時20分鐘之內,整體運行時長如表3所示。

表3 挖掘運行性能統(tǒng)計 min
經(jīng)過對數(shù)據(jù)的采集和預處理,并利用動態(tài)選擇的分布式框架對近3個月的來自于新浪微博的真實線上用戶數(shù)據(jù)進行微博用戶影響力計算,得出了最終的用戶影響力。在計算結果覆蓋的若干領域中,以熱門領域“健康醫(yī)療”為例分析與說明挖掘對象的能力輸出。表4為采用本算法和計算框架后得出的“健康醫(yī)療”領域下前8名用戶的得分及排名情況,通過將此結果與微博影響力排行榜對應醫(yī)療領域下的榜單進行對比發(fā)現(xiàn),其中8人中有6人上榜,且排名順序一致。這里,微博影響力排行榜來源于微風云網(wǎng)站,這個第三方公司服務與新浪微博、百度、Discovery等多家公司,其數(shù)據(jù)具有一定的權威性[13]。

表4 健康醫(yī)療標簽下排名前8的用戶情況統(tǒng)計
經(jīng)過對實驗結果的分析,可以得出,若某一時間段內,用戶的互動量上升,則該用戶的權重值會由于PageRank權重的上升而增加。這一改進的計算策略有效地改善了傳統(tǒng)PageRank算法挖掘能力用戶的陳舊性缺點,而引入時間區(qū)間與領域區(qū)分后,挖掘排名的動態(tài)性和準確度均得到了提高。
根據(jù)挖掘的結果,本文經(jīng)過展示系統(tǒng)將各領域下的高影響力用戶(高權重值)進行了分類與整理,并設定了條件進行篩選,如圖9所示。本文的用戶挖掘覆蓋了大多數(shù)社會生活領域,挖掘的結果具有較高的準確性和可用性,可以支持廣告推薦與群組推薦。
為了進一步驗證算法的性能,我們比較了本文的改進算法與文獻[3]及文獻[5]中改進的PageRank算法對于相應領域下的新浪微博用戶的挖掘結果,如表5所示。通過結果可以看出本文挖掘的健康醫(yī)療領域下的用戶與文獻[3]、文獻[5]相比,排名趨勢基本一致,但從數(shù)據(jù)規(guī)模上說,文獻[3]與文獻[5]通過用戶活躍度和關注度對數(shù)據(jù)集進行了篩選,限制了最終參與挖掘的數(shù)據(jù)的廣度,那么一次可挖掘的主題較為有限,而本文算法直接對于所有用戶的數(shù)據(jù)進行挖掘,規(guī)模更大,挖掘出的主題覆蓋度更高。這是由于本文算法的研究重點在于覆蓋各個領域下的用戶,并采用并行架構提升結果的實時性和動態(tài)性。而文獻[3]的重點在于從話題和博文的影響力進行PageRank計算,文獻[5]則是從活躍度和關注度進行計算,它們挖掘的結果是全局性的影響力排名及分析,沒有討論數(shù)據(jù)規(guī)模和覆蓋度相關的問題。本文挖掘使用的數(shù)據(jù)規(guī)模在TB級別,討論的是大規(guī)模集群挖掘下的相關問題,因此挖掘的方法具有更高的應用性。
5 結 語
根據(jù)對用戶特征和行為特征的分析,本文針對PageRank算法在微博用戶影響力的計算上做了改進,引入了時間區(qū)間和領域區(qū)間,給出了用戶影響力的量化計算公式。基于PageRank改進的用戶影響力算法,分別在MapReduce和Spark計算框架下進行了微博用戶影響力迭代計算。實驗結果表明,基于PageRank改進的用戶影響力計算方法具有較好的準確性,在采用Spark并行化計算框架進行迭代計算時性能較高,比較適合大規(guī)模數(shù)據(jù)集合的挖掘場景。
[1] 吳根平.我國政府微博發(fā)展現(xiàn)狀及對策[J].信息化建設,2011(10):23-27.
[2] Weng J,Lim E,Jiang J,et al.Twitterrank:finding topic-sensitive influential twitters[C]//WSDM,2010.
[3] 吳少華,馬曉娟,胡勇.基于改進PageRank算法的微博用戶影響力評估[J].四川大學學報(自然科學版),2015(5):1040-1044.
[4] 陳少欽.基于PageRank的社交網(wǎng)絡用戶實時影響力研究[D].上海交通大學,2013.
[5] 歐衛(wèi),歐繽憶,謝贊福,等.一種基于PageRank的微博用戶影響度評估算法[J].計算機與現(xiàn)代化,2013(12):34-37,40.
[6] 楊尊琦,張倩楠.基于k-means算法的微博用戶推薦功能研究[J].情報雜志,2013(8):142-144,131.
[7] 原福永,馮靜,符茜茜.微博用戶的影響力指數(shù)模型[J].現(xiàn)代圖書情報技術,2012(6):60-64.
[8] 邢千里,劉列,劉奕群,等.微博中用戶標簽的研究[J].軟件學報,2015(7):1626-1637.
[9] Page L.The PageRank Citation Ranking:Bringing Order to the Web[C]//Stanford InfoLab,1999:1-14.
[10] 夏雨禾.微博互動的結構與機制—基于對新浪微博的實證研究[J].新聞與傳播研究,2010(4):60-69.
[11] 周奇峰.基于用戶興趣的PageRank算法改進策略[J].網(wǎng)絡安全技術與應用,2014(6):52-53.
[12] Pedroche F,Moreno F,González A,et al.Leadership groups on Social Network Sites based on Personalized PageRank[J].Mathematical & Computer Modelling,2013,57(s7/8):1891-1896.
[13] 微博影響力評估平臺.微博影響力排行榜[EB/OL].2015.http://www.tfengyun.com/rankings.php.
IMPROVEMENT AND APPLICATION OF PAGERANK ALGORITHM FOR MICRO-BLOG
Yuan Ye1,2Li chen1Tian Lihua1*
1(SoftwareEngineeringSchool,Xi’anJiaotongUniversity,Xi’an710049,Shaanxi,China)2(SinaCorporation,Beijing100000,China)
It has been one of the urgent problems of micro-blog mining to identify experts with ability to produce high-quality content and high influence under various fields in social network with massive data, and make targeted advertising recommendation and decision support. In this paper, on the basis of user features and behavior features, the rules of selecting article in micro-blog and interaction calculation formula are determined, and the obsolescence of data and irrelevance of theme have been improved by PageRank algorithm. Finally, the algorithm is implemented respectively in the parallel computing framework of MapReduce and Spark. Experimental results show that the proposed method has high accuracy and great performance under Spark, especially under large-scale dataset scene.
Micro-blog User Influence PageRank Spark Big data
2016-01-25。國家自然科學
61403302)。原野,碩士生,主研領域:數(shù)據(jù)挖掘。李晨,講師。田麗華,高級工程師。
TP301.6
A
10.3969/j.issn.1000-386x.2017.03.006
猜你喜歡
車主之友(2022年4期)2022-08-27 00:58:26
知音·下半月(2022年5期)2022-05-23 23:17:04
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年5期)2016-11-28 09:55:15
非公有制企業(yè)黨建(2016年1期)2016-07-19 13:02:51
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
衛(wèi)星與網(wǎng)絡(2016年12期)2016-02-05 09:23:23
創(chuàng)業(yè)家(2015年10期)2015-02-27 07:55:08
創(chuàng)業(yè)家(2015年10期)2015-02-27 07:54:39
