基于HSMM和K-means的納米孔多級事件檢測
2017-04-27 03:39:31賴永杭顏秉勇王慧鋒華東理工大學信息科學與工程學院上海200237
華東理工大學學報(自然科學版) 2017年2期
賴永杭, 顏秉勇, 王慧鋒(華東理工大學信息科學與工程學院,上海 200237)
基于HSMM和K-means的納米孔多級事件檢測
賴永杭, 顏秉勇, 王慧鋒
(華東理工大學信息科學與工程學院,上海 200237)
提出了一種基于隱半馬爾科夫模型(HSMM)和K-means的混合算法,用于對納米孔數據中出現的多級事件進行分析。通過K-means對檢測到的阻斷事件進行分析,確定納米孔信號中的電流幅值水平個數,將其作為HSMM模型的隱狀態輸入;然后采用HSMM識別多級事件內部的不同水平,確定各水平的幅值和持續時間。最后將算法與Opennanopore軟件進行比較,對三級、四級事件進行處理。仿真結果發現:HSMM比Opennanopore軟件的準確率高,能夠準確對事件進行分級。
納米孔; HSMM; K-means; 多級事件
作為最具前景的第3代DNA測序技術,納米通道檢測技術在過去十年獲得了巨大發展,被廣泛用于生物化學研究,并已成為單分子檢測必不可少的工具。在納米通道檢測技術中,由于納米孔兩側電極施加電壓的作用,待測分子在電場力作用下穿越納米孔時,離子電流會被短暫阻斷,這就達到通過外部設備檢測電流變化來進行單分子檢測的目的。阻斷事件的持續時間、幅值和頻率是納米孔研究中的重要信息,這些參數已經被用來探究DNA、RNA和蛋白質等物質的生物物理學信息、物理化學信息和化學性質[1]。在DNA實驗中,不同的堿基(A,G,C,T)通過納米孔時的阻斷事件幅值高度和持續時間是不同的[2],幅值變化范圍為5~10 pA,持續時間范圍為2~12 ms。
目前,納米孔檢測技術的研究熱點主要集中在檢測設備上,并已取得顯著進展[3]。然而,對于納米孔數據處理的研究卻不夠深入,大量的數據、復雜的信號使得納米孔數據分析成為一個耗時和缺乏標準的過程[4]。Balijepalli等[5]開發的MOSAIC軟件采用等效電路法對阻斷事件進行建模分析。Arjmandi[3]研究了小波在低通濾波的優勢,特別是在準確恢復阻斷事件的持續時間和幅值當中的應用。Pedone等[6]對小分子(蛋白質、短DNA、RNA片段)實驗中出現的持續時間小于100 μs的短事件進行了研究。
根據電流幅值水平個數,納米孔阻斷事件可分為2類:單級事件和多級事件。通常采用閾值法來檢測阻斷事件,然而閾值法只能確定事件的起始點和終止點,無法得到事件內部的子事件(即多級事件)的信息。Raillon等[7]開發的Opennanopore軟件采用CUSUM算法來檢測納米孔多級事件,然而該方法對于參數選擇敏感且準確度不高。只有精確檢測出各種納米孔電流信號,才能通過數據分析得到分子的動態和結構信息。
本文提出了一種基于隱半馬爾科夫模型(Hidden Semi-Markov Model,HSMM)和K-means的納米孔多級事件檢測方法,用于對納米孔信號的參數進行估計和信號的統計重構。該方法利用K-means確定納米孔信號的最佳分類個數,將其作為HSMM隱狀態的個數;采用HSMM模型對信號進行統計分析;在此基礎上,對信號進行重構,得到理想的納米孔多級事件。
1 納米通道HMM分析
1.1 HMM模型
HMM (Hidden Markov Model)是一個雙重隨機過程,其中之一是Marcov鏈,它是基本隨機過程,描述的是狀態間的轉移;另一重隨機過程描述了狀態和觀測值之間的統計對應關系。
一個HMM過程可以由以下參數描述:
(1)N:模型中Markov鏈狀態數目,記N個狀態為θ1,…,θN,t時刻的Markov狀態為qt,并且qt∈(θ1,…,θN)。本文中,N表示納米孔多級事件的數目,N=2為單級事件,N>2為多級事件。
(2)M:每個狀態對應的可能觀測值數目,記M個觀測值為V1,…,VM,t時刻的觀測值為Ot,其中Ot∈(V1,…,VM)。
(3)π:初始狀態概率矢量,π=(π1,…,πN),用于描述觀測序列O在t=1時刻所處狀態θi的概率。在納米孔事件檢測中,π是確定的,即沒有分子通過納米孔時的電流狀態,其中
(1)
(4)A:狀態轉移矩陣,A=(aij)N×N,描述從狀態i轉移到狀態j的概率,其中
(2)
(5)B:觀測值概率矩陣,B=bj(yt),描述t時刻狀態為θj條件下,觀測值為yt的概率,其中
(3)
記一個HMM為λ=(N,M,π,A,B),或者簡寫為λ=(π,A,B)。
1.2 納米通道HMM描述
納米孔理想事件波形為幅值、持續時間均隨機變化的矩形波,單級事件為僅有一個幅值水平的矩形波(除基線外),而多級事件則擁有多個幅值水平,類似“階梯”狀的矩形波。事件的每個幅值水平稱為一個狀態,1個事件至少擁有2個狀態(基線值和事件值),各個狀態之間的轉移服從時間連續、狀態有限的一階Markov過程。結合納米孔數據的特點,本文采用的Markov鏈如圖1所示。
圖1 納米孔多級事件Markov鏈
由于檢測池和信號傳輸過程中的噪聲影響,狀態間相互轉移的Markov性不能直接顯現出來,因此可以用HMM模型描述納米孔檢測信號。
(4)
式(4)中:i(t)為檢測到的電流,即觀測值;ibaseline(t)為帶漂移的基線值;inoise(t)為信號噪聲;ievent(t)為事件幅值,即隱狀態,通過HMM模型判斷t時刻的觀測值Ot的隱狀態,即可實現對納米孔多級事件的識別。
通過分析發現,模型在狀態θi(1≤i≤N)持續d個觀測時間的概率為pi(d)=(aii)d-1(1-aii),結果為一個典型的指數分布且最大概率出現在d=0處。根據納米孔阻斷事件的信號特性,概率分布為指數分布是不合理的。
1.3 HSMM模型
為了克服常規HMM的缺點,HSMM在Markov鏈中加入狀態駐留時間的非指數分布pi(d)。這時,隱狀態的轉移過程就成了半馬爾科夫鏈,每個狀態都有一個可變的持續時間分布[8],如圖2所示。在這種情況下,狀態之間的轉移只有在通過pi(d)持續時間密度函數確定一個狀態所發射的觀測值數目后才會發生。

圖2 半馬爾科夫模型
HSMM與HMM相比,克服了因馬爾科夫鏈假設造成HMM建模所具有的局限性,在解決現實問題中,HSMM提供了更好的建模能力和分析能力。實現HSMM模型主要有2種方法:
(1) 非參數方法,也是最直接的方法。在Markov鏈中,增加狀態持續時間概率分布pi(d),d=1,…,D,其中D為所有狀態可能停留的最長時間。
(2) 參數法,不去估計pi(d)的具體數值,而是假定pi(d)服從某種分布(如高斯分布、泊松分布等),通過估計描述這種分布的參數實現估計pi(d)的目的。
參數法計算量比非參數法大,而且假定pi(d)服從某種分布,并不適用于所有狀態。因此,本文采用非參數法實現HSMM模型。
2 納米孔多級事件檢測
2.1 概述
利用HSMM對納米孔信號進行統計分析,檢測多級事件,即根據觀測值序列OT=(o1,o2,…,oT)確定納米孔的隱狀態序列QT=(q1,q2,…,qT),然后根據隱狀態序列確定各個事件的持續時間與幅值。其中,隱狀態序列的確定是多級事件正確分級的關鍵。
分析過程主要涉及HSMM中的2個問題:學習問題,即HSMM的訓練;解碼問題,即通過HSMM模型和觀察序列,確定隱狀態序列。
2.2 HSMM模型訓練
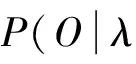
初始化:
(5)
遞歸:
(6)
初始化:
(7)
遞歸:
(8)
(3) 定義在給定觀測序列O=(o1,o2,…,oT),t時刻,狀態θm轉移到狀態θn的概率為
(9)
定義在t時刻,狀態為θm且持續d個時間單位的概率為
(10)
定義在t時刻狀態為θm的概率:
(11)
初始狀態:
(12)
遞歸:
(13)
(4) 重估模型參數:
(14)
(15)
(16)
(17)
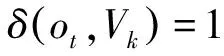
2.3 隱狀態序列估計及事件信息確定
2.2節中,γt(m)為t時刻狀態為θm的概率,欲獲得最佳隱狀態序列,即想獲得t時刻可能性最大的狀態,可對γt(m)取最大值,如式(18)所示:
(18)
隱狀態序列確定后,可直接獲得多級事件內部各子事件的持續時間,然而,子事件的幅值信息無法直接獲得。在單級事件情況下,確定了事件的起始點和終止點后,幅值的選取主要有兩種:對同一狀態的所有觀測值取平均值作為事件幅值;或取同一狀態的最小觀測值作為事件幅值。本文采用對事件內同一水平的數據點取平均值,作為子事件的幅值。
3 K-means算法確定隱狀態個數
運用HSMM對阻斷事件進行分析時,必須事先給定隱狀態的個數N,即納米孔事件幅值水平數目。若隱狀態的個數判斷錯誤,所得到的結果也是錯誤的。為了實現納米孔事件的多級事件的自動檢測,本文采用K-means聚類算法對數據進行分析,獲得最佳分類個數k,將k值作為HSMM的隱狀態個數。
K-means算法是一種聚類算法,常用于數據挖掘和模式識別中,是一種無監督學習式的算法。聚類分析的目的在于把數據集中的數據劃分為一系列有意義的子集(或稱類),使得每個子集中的數據盡量“相似”或“接近”,而子集與子集之間的數據盡可能有“較大差異”[10]。
假設有L個數據點{x1,x2,…,xL},需要分成K個類簇{μ1,μ2,…,μK},采用誤差平方和準則函數作為K-means的目標函數:
(19)
其中:在數據點l被歸類到類簇k時rlk為1,否則為0;xl為第l個數據點;uk為第k個類簇的中心點。直接通過尋找rlk和uk的方法來最小化J的值并不容易,通常采取迭代的方法。
(1) 先固定uk,選擇最優的rlk,即將數據點歸類到離它最近的中心就能使J取到最小值。
(20)
(2) 固定rlk,再求最優的uk。將J對uk求導且導數為0,可得到J最小時uk應滿足:
(21)
即uk為類簇k中數據點的平均值。直到迭代前后J值相差小于一個閾值時,算法停止。
K-means由于其簡單、快速的特點得到廣泛應用。然而,K-means也有其自身的局限性,它需要使用者事先確定類簇的數目k[11]。k值的選取通常需要基于先驗知識、假設和實際經驗。但是,如果在不同的k下對聚類結果的質量進行評價,往往就可得到正確的k值。給定一個合適的簇指標,如平均半徑和直徑,當簇的數目等于或高于真實的簇的數目,該指標上升趨勢會很緩慢,但是,一旦少于真實的簇數目時,該指標會急劇上升[12]。
本文選用數據點與所在類簇中心點的距離之和的平均值作為指標,用符號E表示,如式(22)所示。經仿真實驗和實際信號檢驗,可以準確確定納米孔事件的級數。
(22)
其中,Q為最大類簇個數。
4 基于K-means和HSMM的納米孔事件檢測
基于HSMM和K-means的納米孔事件檢測算法主要包括3個部分:事件檢測、事件級數判斷、事件分析。
(1) 事件檢測。納米孔數據的分析從在含有噪聲的基線電流中判斷阻斷事件開始,目前,普遍采用閾值法來分離事件,在該方法中,如果電流超過所設閾值則為事件。閾值定義為峰值檢測因子與噪聲均方根σ的乘積。峰值檢測因子的選擇要盡量滿足兩個條件:一是數值盡可能大,以減少將噪聲誤判為事件的數量;二是數值盡可能小,以盡可能多地檢測到阻斷事件。通常閾值為偏離基線電流的5倍的噪聲均方根[13]。
檢測到事件發生時,分別將下降沿和上升沿中第1個穿越基線電流的點作為起始點和終止點。為了便于觀察和分析,本文在事件前后各增加50個采樣點。
(2) 事件級數判斷。通過K-means算法判斷事件最佳分類數目N,即納米孔電流幅值水平個數。
(3) 事件分析。對于單級事件,即N=2時,可以通過傳統方法確定事件的起始點和終止點,進而得到事件的持續時間和幅值,而不必通過HSMM算法處理,提高算法處理速度。當N>2,即事件為多級事件時,傳統方法失效,引入HSMM模型對事件進行分析。該步驟的主要目的是確認事件的持續時間、幅值。系統結構框圖如圖3所示。
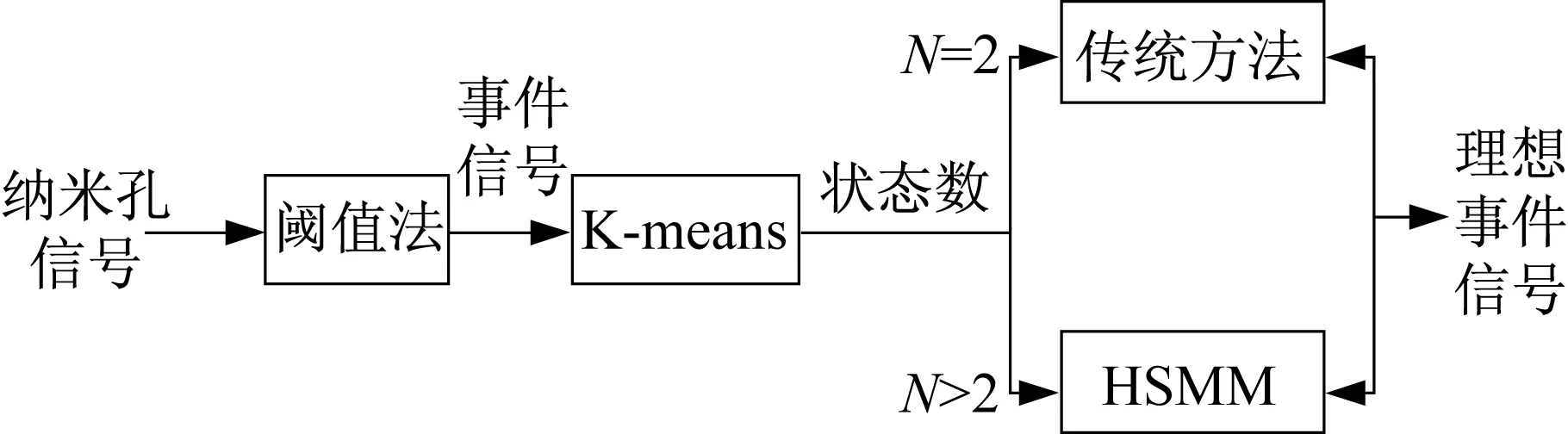
圖3 系統框圖
5 仿真實驗與結果
5.1 實驗平臺與仿真數據生成
實驗采用α-Hemolysin生物納米孔,緩沖液由10 mmol/L Tri-HCL (pH=7.8)配置。在檢測池兩端置入Ag/AgCl電極,實驗過程中施加100 mV電壓。信號采用ChemClamp(Dagan Corporation公司)電流放大器對納米孔的離子電流進行檢測和放大,放大后的信號經過3 kHz的濾波后,選用DigitalData 440A數模轉換器(Axon Instruments公司)進行采樣,采樣頻率為250 kHz。
利用納米孔在檢測池中無待測分子時采集7 000個數據點,采樣頻率為250 kHz,將該信號作為背景噪聲,其均值為100.115 6 pA,方差為1.649 6,由式(4)可知,此時的數據為基線電流與噪聲之和,如圖4(a)所示。在納米孔實驗中,多級事件主要為三級和四級事件,因此本文采用這2種事件來檢測算法的有效性。根據實際納米孔實驗信號幅值高度和持續時間特征,取其中較為典型的多級事件信號,產生一個采樣點為7 000的模擬納米孔理想信號,信號中包括單級事件和多級事件,如圖4(b)所示。將兩個信號疊加,得到模擬實驗仿真信號,如圖4(c)所示。
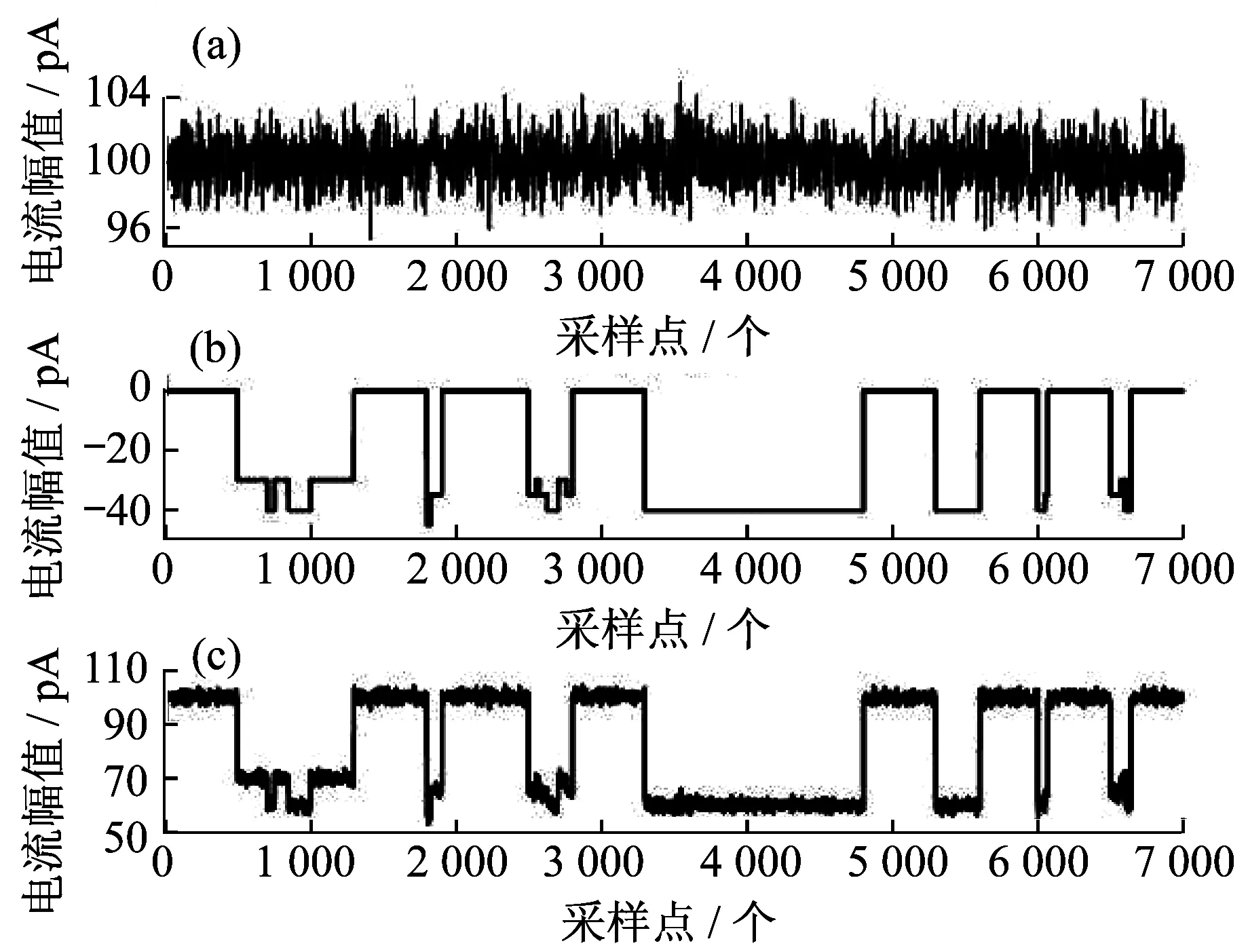
圖4 模擬納米孔實驗信號
5.2 仿真結果與對比
首先通過閾值法,檢測是否有阻斷事件發生,本文中,閾值設置為偏離基線值10 pA。檢測到事件發生后,確定事件的起始點和終止點。下一步通過K-means算法判斷事件的級數,結果如圖5所示。
圖5中,二級事件(包括基線)即為單級事件,曲線變化不大,幾乎成一條直線;三級事件在類簇個數為3時指標驟降,而后趨于平穩;四級事件也在類簇個數為4時指標驟降。可見,K-means可以準確判斷事件級數,可以用于納米孔多級事件的自動判定,無須先驗知識。
K-means正確判斷事件級數后,當最佳類簇個數為2時,即為單級事件,則由傳統算法處理。若最佳類簇個數大于2,即為多級事件,則由HSMM算法處理。
在納米孔數據分析中,采用直方圖來分析事件峰值,對直方圖進行高斯擬合后可以得到事件各級的幅值。由圖6(a)所示,事件有3個幅值水平,幅值分別為:99.69,70.12,59.97 pA。通過圖6(b)示出的處理效果對比圖可看出,HSMM方法處理后的事件曲線幾乎和理想曲線重合,數據點誤判概率接近0,幅值高度誤差為0.14~0.32 pA。而CUSUM(Cumulative Sum)算法的處理效果顯示,算法對事件錯誤分級,且出現了不少“毛刺”,數據點錯判概率為9.8%。

圖5 事件級數判斷
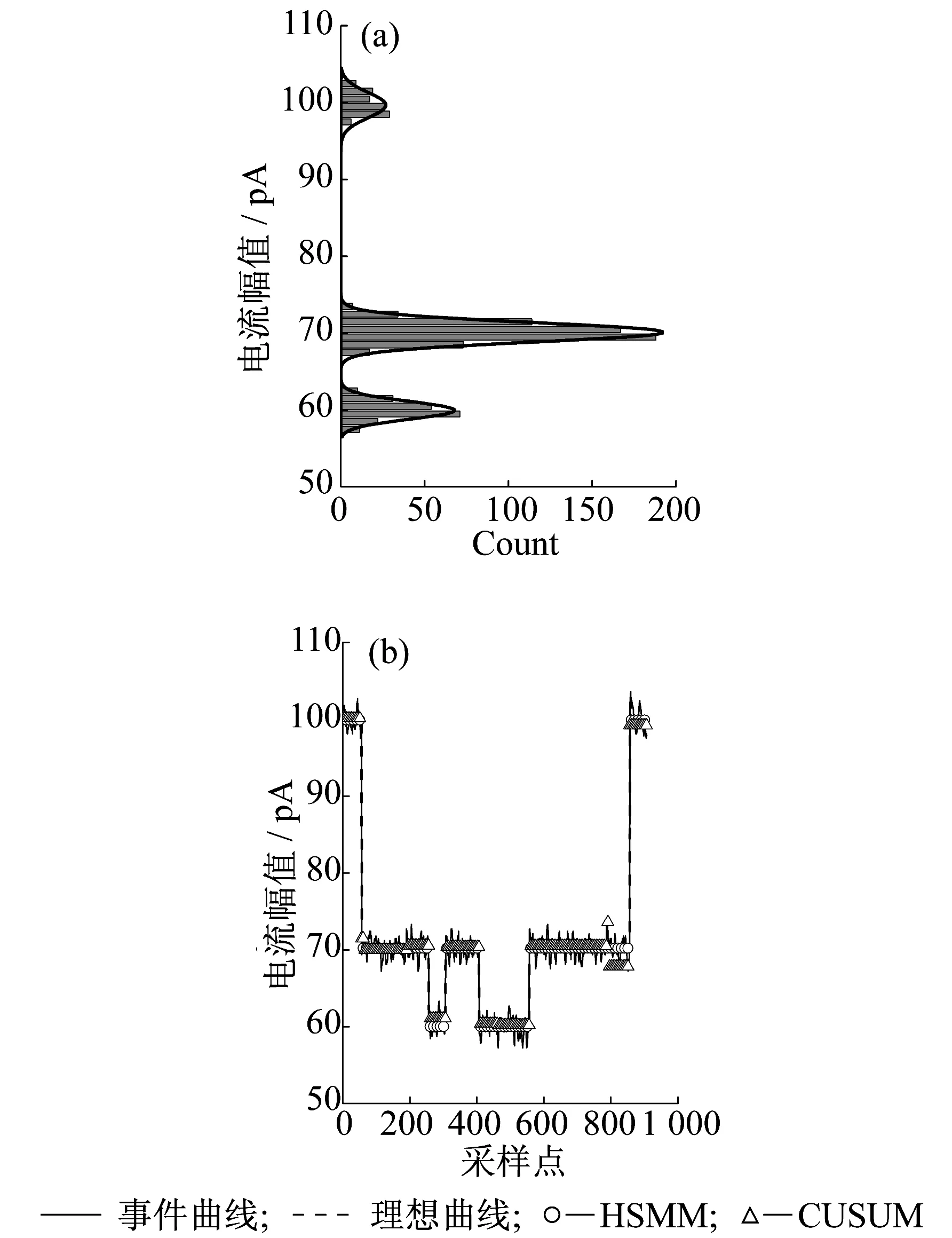
圖6 三級事件
四級事件的處理效果對比如圖7所示。圖7示出了直方圖高斯擬合后有4個峰值:100.04,70.07,65.27,60.49 pA。由圖7(b)示出的處理效果比較可見,HSMM處理的曲線與理想曲線幾乎重合,數據點錯判概率接近0,幅值高度誤差為0.01~0.19 pA。CUSUM算法的數據點錯判概率為11.9%,幅值高度誤差為0.17~1 pA。
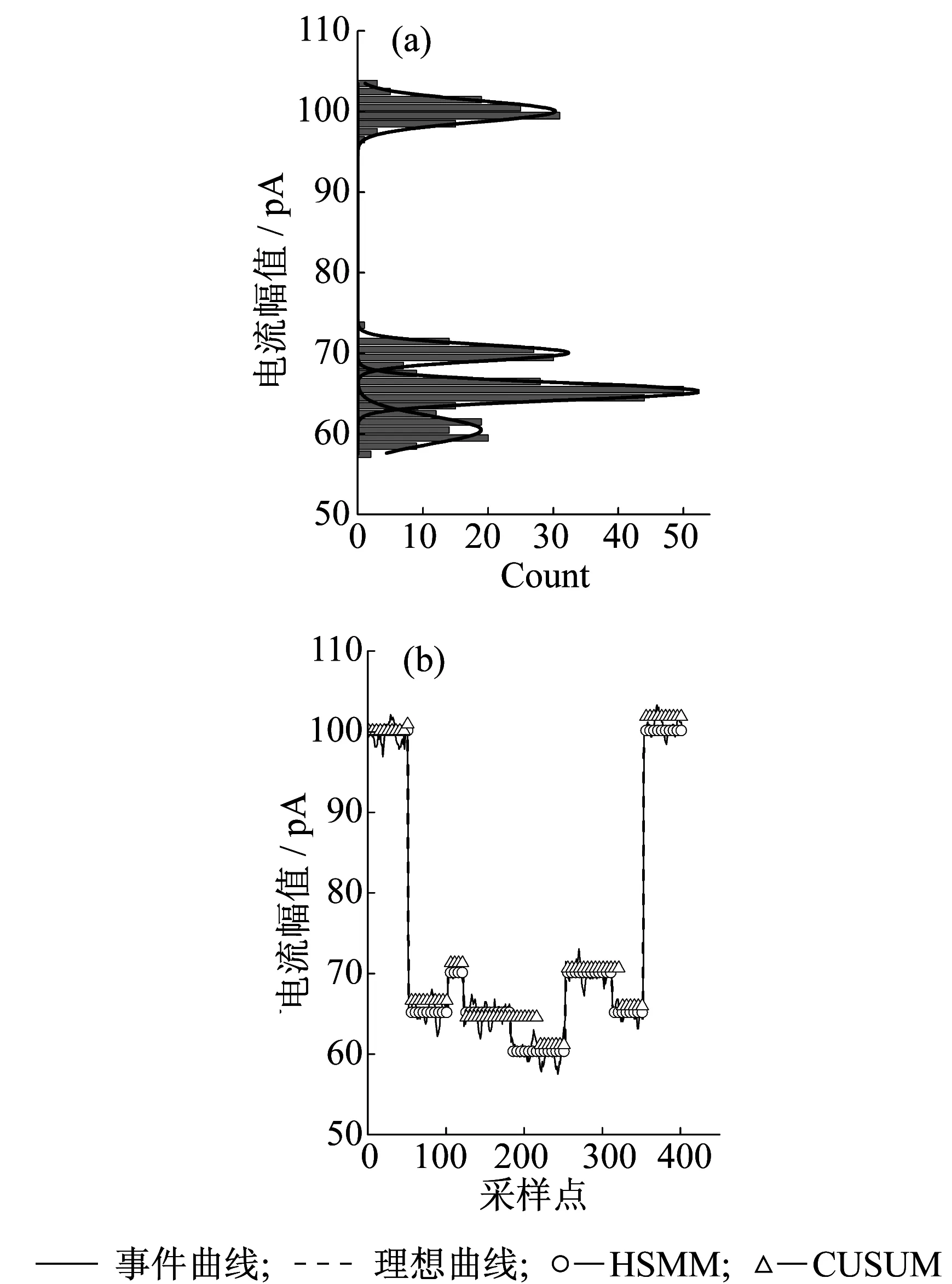
圖7 四級事件
6 結束語
采用HSMM和K-means聚類算法,有效地解決了納米孔實驗中出現的多級事件識別問題,實現了多級事件的自動檢測分析。由仿真信號實驗結果可得,該算法與Opennanopore軟件的CUSUM算法相比,算法精度高,能夠實現納米孔事件的正確自動分級,因此可以用于納米孔多級事件分析。
[1]GU Z,YING Y L,CAO C,etal.Accurate data process for nanopore analysis[J].Analytical Chemistry,2015,87(2):907-913.
[2]CLARKE J,WU H C,JAYASINGHE L,etal.Continuous base identification for single-molecule nanopore DNA sequencing[J].Nature Nanotechnology,2009,4(4):265-270.
[3]ARJMANDI N,ROY W V,LAGAE L,etal.Improved algorithms for nanopore signal processing[C]∥Nanopores for Bioanalytical Applications Proceedings of the International Conference.[s.l.]:[s.n.],2012:11-17.
[4]ZHANG N,HU Y X,GU Z,etal.An integrated software system for analyzing nanopore data[J].Science Bulletin,2014,59(35):4942-4945.
[5]BALIJEPALLI A,ETTEDGUI J,CORNIO A T,etal.Quantifying short-lived events in multistate ionic current measurements[J].Biophysical Journal,2011,106(2):637-643.
[6]PEDONE D,FIRNKES M,RANT U.Data analysis of translocation events in nanopore experiments[J].Analytical Chemistry,2009,81(23):9689-9694.
[7]RAILLON C,GRANJON P,GRAF M,etal.Fast and automatic processing of multi-level events in nanopore translocation experiments[J].Nanoscale,2012,4(16):4916-4924.
[8]YU S Z.Hidden semi-markov models[J].Artificial Intelligence,2010,174(2):215-243.
[9]YU S Z,KOBAYASHI H.An efficient forward-backward algorithm for an explicit-duration hidden Markov model[J].IEEE Signal Processing Letters,2003,10(1):11-14.
[10]李雙虎,王鐵洪.K-means聚類分析算法中一個新的確定聚類個數有效性的指標[J].河北省科學院學報,2003,20(4):199-202.
[11]NALDI M C,CAMPELLO R J G B,HRUSCHKA E R,etal.Efficiency issues of evolutionary K-means[J].Applied Soft Computing,2011,11(2):1938-1952.
[12]RAJARAMAN A,ULLMAN J D.大數據-互聯網大規模數據挖掘與分布式處理[M].北京:人民郵電出版社,2012:188-189.
[13]PLESA C,DEKKER C.Data analysis methods for solid-state nanopores[J].Nanotechnology,2015,26(8):2890-2898.
Detecting of Multi-level Events in Nanopore Experiments Based on HSMM and K-means
LAI Yong-hang, YAN Bing-yong, WANG Hui-feng
(School of Information Science and Engineering,East China University of Science and Technology,Shanghai 200237,China)
This paper proposes a HSMM and K-means based hybrid algorithm for identifying the multi-level events in nanopore data.By means of K-means to analyze the detected blockade events,the number of current amplitude level of nanopore data can be identified,which will be taken as the input of the HSMM’s number of hidden states.And then,HSMM is used to identify different level inside multi-level event and deceide the dwell times and amplitude of different levels.In the situation of third-level and fourth-level event,the simulation results show that HSMM is more accurate than Opennanopore software,and can classify the events accurately.
nanopore; HSMM; K-means; multi-level events
1006-3080(2017)02-0220-07
10.14135/j.cnki.1006-3080.2017.02.011
2016-07-11
國家重大儀器專項(21327807)
賴永杭(1991-),男,碩士生,主要研究方向為檢測技術與自動化裝置。
王慧鋒,E-mail:whuifeng@ecust.edu.cn
TH776
A
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
鴨綠江(2021年35期)2021-04-19 12:24:18
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
數學物理學報(2020年2期)2020-06-02 11:29:24
電子制作(2018年11期)2018-08-04 03:25:42
光學精密工程(2016年6期)2016-11-07 09:07:19
