大數據環境下的分布式數據流處理關鍵技術探析
2017-05-24 14:45:22陳付梅韓德志戴永濤
計算機應用 2017年3期
陳付梅,韓德志,畢 坤,戴永濤
(上海海事大學 信息工程學院,上海 201306) (*通信作者電子郵箱dezhihan88@sina.com)
大數據環境下的分布式數據流處理關鍵技術探析
陳付梅,韓德志*,畢 坤,戴永濤
(上海海事大學 信息工程學院,上海 201306) (*通信作者電子郵箱dezhihan88@sina.com)
大數據環境下的數據流處理實時性要求高,數據計算要求持續性和高可靠性。分布式數據流處理系統(DDSPS)能解決大數據環境下的數據流處理問題,它除具備分布式系統的可擴展性和容錯性優勢外,還具有高的實時處理能力。詳細介紹了組成基于大數據的分布式數據流處理系統的四個子系統及其關鍵技術,討論和比較了各個子系統的不同技術方案;同時介紹一種分布式拒絕服務(DDoS)攻擊檢測數據流處理系統結構案例,其研究內容能為大數據環境下的數據流處理理論研究和應用技術開發提供技術參考。
大數據;流處理;消息隊列;數據處理;數據存儲
0 引言
2016年1月,中國互聯網信息中心(China Internet Network Information Center, CNNIC)發布了《第37次CNNIC報告:中國互聯網絡發展狀況統計》[1],報告統計了目前中國互聯網大環境的發展情況。數據顯示,截至2015年12月,中國的網民規模達6.88億,全年共計新增網民3 951萬人;互聯網普及率為50.3%,較2014年底提升了2.4個百分點,同時根據IDC(International Data Corporation, IDC)發布的數字宇宙報告顯示,至2020年數字宇宙將超出預期,達到40 ZB,相當于地球上人均產生5 247 GB的數據[2]。上述數據意味著大數據時代已經來臨,大量的信息呈現在用戶面前。比如國內最大的電商平臺淘寶網每日訪問用戶達6 000萬,每日在線商品數目已經超過了8億件。面對急速增長的數據規模,用戶正面臨著“信息超載問題”,如果不借助于大數據分析系統和搜索引擎等輔助技術,用戶從海量的互聯網資源中找到自己真正感興趣的信息是一件非常困難的事情,使得信息的有效利用率反而降低了。
在大數據時代,數據的來源已經不再是人們所關心的問題,如何從形態多樣的海量數據中高效、快速、及時地挖掘出有用的信息這才是關鍵,這也大數據分析面臨的難題。單機系統不能滿足海量數據分析處理要求,Hadoop系統的開源解決了此難題;基于Google GFS(Google File System)[3]實現的HDFS(Hadoop Distributed File System)解決了海量數據的存儲問題;MapReduce則實現了海量數據的分布式計算,這大幅度降低了大數據處理的門檻,使得海量數據處理成為一種可能。雖然Hadoop系統具有近乎線性的擴展能力、良好的容錯性、分布式的計算能力等優勢,是很多公司處理海量數據的首選方案,但是,它仍存在一個關鍵的缺陷——缺乏實時性。Hadoop主要用于海量數據的離線計算,因此,從數據的產生到得到最終的數據結果之間存在時間差,不能滿足實時性要求高的應用要求。
實時化、內存計算、泛在化(普適應計算或環境智能化)、智能化是當今大數據技術的四大發展趨勢[4]。實時化作為發展趨勢之一,已經受到越來越多的關注。而數據的實時處理,首先需要在數據產生的時候將其轉為源源不斷的數據流,并將數據流發送給流處理系統,然后由流處理系統對數據流進行在線(實時,real-time)或近線(接近實時,near-real-time)分析。流數據處理系統的核心思想是:從不斷流入的新數據中提取感興趣的、有效的信息,縮減數據從產生到被利用的時間間隔,丟棄部分無效數據或者已經被處理后的原始數據,在獲取有效信息的同時避免存儲海量原始數據,降低數據的存儲成本。
大數據環境下的數據流具有五大特點:實時性、易失性、無序性、突發性、無限性[5-6],因此,在大數據流處理過程中面臨著一些新的挑戰[7]:實時性要求高、流入數據量不可預知、數據和計算的持續性、數據計算要求高的可靠性。分布式流處理系統是解決大數據流最理想系統,它具備了分布式系統的可擴展性和容錯性等優勢,同時又很好地應對了大數據流的各種挑戰。
分布流處理系統是一個很復雜的系統,它由多個子系統組成,并且需要不同的子系統之間相互分工、共同協作[3]。一個完整的流式數據處理系統由4部分組成:1)數據收集系統(Data Collection System),用于收集、匯總原始數據。2)消息隊列系統(Message Management System),對收集到的實時數據進行轉存、維護,并將數據傳送給數據處理和分析系統,是原始數據的中轉站、緩沖區。所謂的消息,是接收到的一條一條的數據。3)數據處理系統(Data Processing System),是整個流式數據處理系統的核心。它主要負責從消息隊列系統或其他數據發送系統中獲取數據,并進行及時的業務邏輯處理和分析,然后將處理后的結果數據保存到數據庫系統中或直接傳送給其他業務處理系統,作進一步的分析和展示。4)數據存儲系統(Data Storage System),是處理后的數據的最終歸屬地,也是連接流式數據處理系統跟其他系統之間的橋梁。本文將對大數據環境下的一個完整分布式流處理系統四個組成部分所采用的技術進行介紹和探析,同時介紹一種分布式拒絕服務(Distributed Denial of Service, DDoS)攻擊檢測數據流處理系統結構,為大數據環境下的數據流處理理論研究和應用技術開發提供參考。
1 數據收集
海量的數據是大數據出現的前提,而數據收集則是大數據的基石。日志數據收集在流數據收集中占有重要比重,許多公司的業務平臺每天都會分散的產生大量日志數據,收集并匯總這些業務日志數據,供離線和在線的分析系統使用。日志收集系統所需考慮的基本特征包括:高可靠性、高可用性和高可擴展性。“分散收集,集中處理”是當前日志處理系統的一個主流思想。日志收集也是流式日志處理系統的前提和基礎,日志只有被實時收集、匯總之后,才能進行后續的相關處理操作。下面針對當前流行的開源日志數據流收集系統,進行介紹和對比。
1.1 Scribe
Scribe[8]是Facebook為了滿足內部大量日志處理而設計的日志收集系統。它能將分散在不同服務器上的不同應用日志匯總到中央存儲系統,通常是將日志存入HDFS中,為日志的集中處理提供了有力的保障。
Scribe數據的傳遞依賴于Thrift[9],Thrift通過一個中間語言(接口定義語言),來定義遠程過程調用(Remote Procedure Call, RPC)的接口和數據類型,然后通過編譯器,生成不同語言的代碼,是跨語言服務的部署框架)。其架構如圖1所示,由以下三部分構成:
1)Scribe Agent。位于日志產生的應用服務器上,實質是一個Thrift客戶端,通過RPC負責將應用系統產生的日志,發送到匯總服務端。
2)Scribe Collector。完成多個Agent發送過來的數據接收,并將數據存入可靠的存儲介質中,如:本地磁盤、HDFS等,此部分并不是Scribe日志收集系統中的必需部分,可以跳過Collector直接將日志從Agent存入到存儲系統中。
3)存儲介質。Scribe已經實現了向不同類型的存儲介質中寫入數據的功能,包括文件系統(如HDFS,位于本地磁盤或共享式的存儲系統中),網絡(直接發送給其他Scribe),緩存(可滿足故障恢復的要求,數據優先寫入主存儲中,若主存儲故障,則存入到備份的存儲中),多存儲介質(同時將數據寫入不同的存儲系統中,達到數據備份的目的)。
從架構上分析,Scribe能在一定程度上保證數據不丟失。Scribe進程能將消息在內存中緩存一段時間,但是當Scribe Agent出現故障時,這些緩存的數據就會丟失,因此,從這方面來講,Scribe不能嚴格保證數據可靠性。
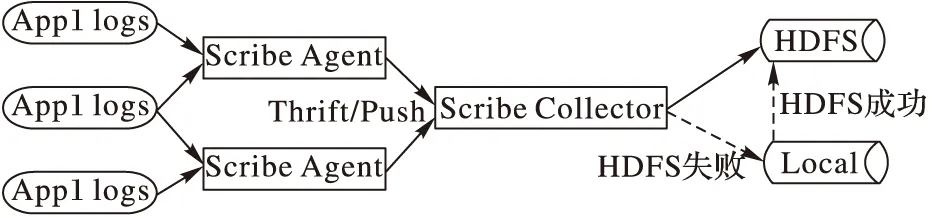
圖1 Scribe 體系架構
1.2 Flume
Flume最初是由Cloudera的工程師設計用于合并日志數據的系統[10],后將其開源出來,并逐漸發展成為一款開源、高可靠、高擴展、易管理、支持客戶擴展的分布式數據流采集系統,主要是用于日志數據的收集和聚合。
在原始的Flume版本中,一個完整的Flume系統由Agent(用于采集數據)、Master(配置及通信管理)、Collector(對數據進行聚合)構成。而重構后的新版Flume也稱為Flume NG(Next Generation),其系統中只有Agent一種角色。圖2為Flume NG的架構,由分布在不同節點的Agent負責收集不同的應用所產生的數據,并發往匯總的Agent節點,最后存入大容量、高可靠的存儲系統,如:HDFS。

圖2 Flume架構
每一個Flume Agent的內部都是由Source、Channel以及Sink組成。Source即為要收集數據的來源,負責產生或接收數據,并發往Channel。Channel則是負責接收來自Source的數據,并傳送到Sink,負責對數據提供可靠性保證。Sink則是從Channel拉取數據,并將數據寫入到后端的存儲系統中,已經實現的Sink包括:HDFS Sink(將數據寫入到HDFS中)、Hive Sink(將數據存入Hive中)、Avro Sink(將數據以Avro的方式進行序列化,并發往后端的Avro接收端,也可以是Flume的Avro Source)等若干常見的數據存儲和接收系統。
1.3 Chukwa
Chukwa是Apache旗下的一款開源數據收集軟件[11],它可以將不同類型的數據匯聚成適合Hadoop處理的文件,并保存在HDFS中,并與Hadoop集成,可以快速方便地進行各種MapReduce操作。Chukwa本身已經實現了很多內置的功能,能夠用于數據的收集和整理。
Chukwa的架構如圖3所示,由Agent、Collector以及HDFS構成。Agent是運行在不同節點上負責收集數據的程序,而Agent又由多個Adapter組成,并由Adapter執行實際的數據收集工作;Collector負責接收不同的Agent發送過來的數據,并負責將數據寫入HDFS;HDFS是Chukwa中數據的最終存儲系統,能夠滿足海量數據的存儲要求,并具有很好的容錯性、可用性、擴展性。Chukwa非常適合于將數據收集后需要進行MapReduce操作的應用場景。

圖3 Chukwa架構
1.4 LogStash
LogStash[12]是著名的開源數據棧ELK (ElasticSearch, Logstash, Kibana)中的那個L,其主要功能就是進行數據的收集,配合ElasticSearch進行數據索引和檢索,Kibana用于數據的展示,即為一個完整實時數據分析平臺。LogStash是一款輕量級的日志收集處理軟件,可以極其方便地把分散的、多樣化的日志收集起來,并能根據業務需求實現自定義的處理,然后傳輸到指定的位置,比如某個服務器或者文件。
圖4為LogStash架構,Input Plugin負責從不同的地方接收或讀取數據,轉化為LogStash所支持的事件格式,其已經實現了幾十種常用的Input Plugin。Filter Plugin則用于根據自定義的規則對事件進行過濾或轉為特定的格式。Output Plugin則將事件發往指定的存儲位置,將數據進行持久化存儲,完成數據的匯總。LogStash已經有非常豐富的Plugin,而且,如果已有的Plugin不能滿足要求,還能通過自己編碼來實現自定義的Plugin,因此,其靈活性非常好。
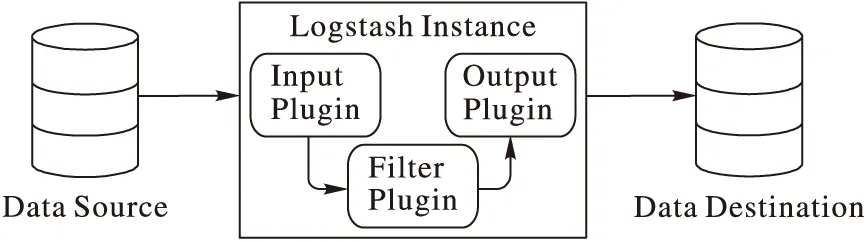
圖4 LogStash架構
1.5 日志收集系統對比
日志數據流收集系統具備三個基本組件,分別是Agent(接收原始數據,并將數據發給Collector)、Collector(接收多個Agent發送過來的數據,匯總后將數據發往Store)、Store(中央存儲系統,將匯總后的數據進行持久化存儲)。表1綜合對比了Scribe、Flume、Chukwa、LogStash四種日志數據流收集系統。

表1 四種日志數據流收集系統對比
所述四種數據流收集系統都具備一定高可用和擴展性,且都是開源的系統,完全可以進行二次開發,完成功能的自定義擴展。由表1綜合考慮,Flume在各個方面都具備一定優勢,是一款通用的數據流收集軟件;若需要對數據流進行檢索,則LogStash是非常不錯的選擇;若要實現對收集的數據流進行MapReduce操作,則可以選擇Chukwa。
2 消息隊列管理技術
在離線數據處理系統中,只需要將數據進行匯總到中央存儲系統,然后對匯總后的數據定期的集中處理即可。在數據流處理系統中,由于數據是源源不斷流入,且需要對新增的數據進行實時處理。相比于離線數據處理系統,數據流處理系統中需要一個消息隊列系統充當數據緩沖區的角色,一方面快速接收數據收集系統發送過來的數據,另一方面,當數據處理系統處理能力未達到滿負載時,盡量快地發送數據給數據流處理系統,當處理系統達到滿負載時,緩存接收到的數據,減緩數據發往數據流處理系統的速度。下面主要介紹當前比較流行的幾款消息隊列系統。
2.1 RabbitMQ
RabbitMQ[13]是一個由Erlang開發的、基于高級消息隊列(Advanced Message Queue, AMQP)協議[14]的開源消息系統。其最初誕生于金融應用系統,用于轉發存儲分布式系統中的消息,在擴展性、易用性、高可用性等方面優勢突出。
如圖5所示,RabbitMQ中包括Producer(消息產生者)、Broker(消息隊列管理者)和Consumer(消息使用者)。
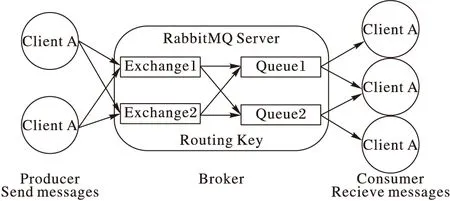
圖5 RabbitMQ架構
Broker中的Exchange(消息交換機)負責接收Producer發送過來的消息,并將消息根據Routing Key(路由關鍵字)綁定到不同的Queue(消息隊列)。每一條消息都會被綁定到至少一個Queue,而每一個Queue則是若干條消息的實體。Consumer再從不同的Queue中讀取數據,進行后續的分析和計算。
2.2 ZeroMQ
ZeroMQ[15]是一個非常輕量級的消息系統,也是一種基于消息隊列的多線程網絡庫。它是網絡通信中新的一層,介于應用層和傳輸層之間,像框架一樣的一個Socket library,大幅度簡化了Socket編程,而且性能更高效。與傳統消息隊列管理系統不同的是,ZeroMQ不再需要一個消息服務器(Broker)來存儲轉發消息,而是直接在發送端緩存。ZeroMQ是一個可嵌入的并發框架,不需要獨立部署任何服務進程,但需要在其提供的API(Application Program Interface)基礎上編程實現消息管理邏輯,從這方面來講,它是一個比較復雜的系統。ZeroMQ設計初衷就是為了盡可能快地發送消息,且其具有良好的跨平臺、跨語言特性,能夠在Windows、Linux、OS X下運行,能支持超過20種編程語言的編程操作。
圖6ZeroMQ架構圖中的I/O(Input/Output)線程所涉及的I/O操作都是異步的。ZeroMQ會在初始化時要求用戶傳入接口參數,并根據這些參數創建對應的I/O線程,每個I/O線程都有與之綁定的Poller(輪詢器),Poller則采用Reactor模型[16]與不同操作系統平臺的I/O模型進行通信。主線程與I/O線程通過消息盒子(Mail Box)進行通信。Server開始監聽或者Client發起連接時,在主線程中創建連接器或監聽器,通過消息盒子以發消息的形式將其綁定到I/O線程,I/O線程會把連接器或監聽器添加到Poller中用以偵聽讀/寫事件。Server與Client在第一次通信時,會發送認證標識符,用以進行認證。認證結束后,雙方會為此次連接創建會話(Session),以后雙方就通過會話進行通信。每個會話都會關聯到相應的讀/寫管道,主線程收發消息只是分別從管道中讀/寫數據。會話并不直接跟Kernel交換I/O數據,而是通過Plugin到會話中的Engine來與kernel交換I/O數據。
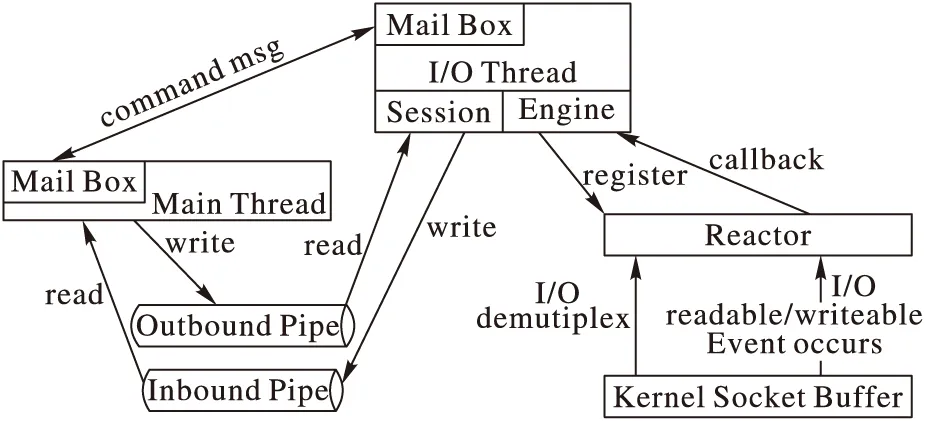
圖6 ZeroMQ整體架構
2.3 Kafka
Kafka[17]是由LinkedIn開發的,作為其運營數據處理管道(Pipeline)和活動流(Activity Stream)的基礎,并于2010年將其開源,成為Apache下一個子項目。經過幾年的發展,現在它已被用作數據管道和消息系統廣泛的使用在不同應用領域。Kafka作為一個高性能的分布式發布/訂閱(Publish/Subscribe)消息隊列系統,其具有以下特性:1)高吞吐量,能在低性能的設備上達到每秒數十萬的消息讀寫速度;2)支持水平擴展,當集群吞吐量不能滿足需求時,只需要增加設備,就能讓其吞吐量近似線性地增長;3)容錯性好,不管消息有沒有被消費掉,都可以將數據存儲在磁盤上,可以對消息進行多次讀取,且可以自動將消息拷貝到不同的機器上,實現數據的冗余;4)保證消息有序,通過將消息分區存儲,能保證每一個分區中的數據都能被有序地消費。
Kafka的整體架構如圖7所示,包括三種角色:生產者(Producer),向Kafka集群發送數據的一端,由不同的數據收集系統和組件構成;代理集群(Broker Cluster),運行Kafka相關進程的一端,負責接收來自Producer的數據,并將數據轉發給Consumer;消費者(Consumer),即數據的使用者,如實時數據應用系統等,完成對數據作業務邏輯相關的處理。
在Kafka中每一條消息至少屬于某一個主題(Topic),一個Topic則是某一類消息的分組,并根據消息的Topic進行分區(Partition)并分散到不同服務器上的日志(log)文件中按順序存儲。每條消息所在的文件中會有一個不斷增長的長整型偏移量(offset),通過offeset能唯一標識一條消息。Kafka中消息存儲和消費有關的狀態信息,如:offeset,都是通過Zookeeper[18]來保存。雖然Kafka將數據存儲到了磁盤中,但是磁盤的順序讀寫速度是非常快,甚至能超過內存的隨機讀寫速度,且Kafka中使用了Zero-Copy[19]技術,因此Kafka能保證消息的快速讀取。
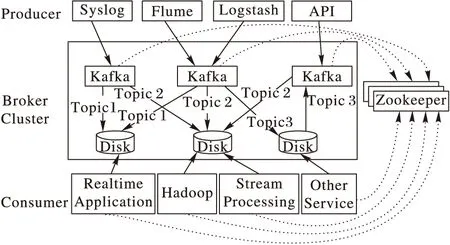
圖7 Kafka整體架構
這三款消息隊列系統都是非常優秀的,有很多共性,也有一些區別(如表2)。

表2 消息隊列系統對比
1)RabbixMQ采用通用高級消息隊列協議(AMQP),得到很多到公司的支持,且其能很好地支持消息的事物機制、數據的持久化,非常適用于金融行業,但是在相同的配置情況下,其吞吐量比另外兩款消息隊列系統要低很多。
2)ZeroMQ實質上是一個基于Socket的可嵌入的并發框架,其并沒有完整的實現消息隊列管理系統,而是需要用戶通過調用相關的API來完成對消息的管理,因此,其使用起來要稍微復雜一些。其底層的相關技術,能夠盡快地發送消息數據,其吞吐量非常大,但是,不提供數據的持久化支持,即消息被消費者接收后,就不能再次讀取,因此在一些需要非常高的吞吐量且不需要多次讀取消息,且也能容忍系統故障時丟失部分數據的場景中比較適合。
3)Kafka則是RabbitMQ和ZeroMQ的折中方案,能支持消息的持久化,在盡可能保證數據不丟失的同時,又使用Zero-Copy技術及順序的存儲和讀取消息機制,使其具有很高的吞吐量。其擴展性也是非常的出色,只需要增加相應的設備,即能使其吞吐量達到幾乎線性地增長。Kafka比較適合互聯網的應用場景,在很多的互聯網公司都被廣泛地使用。
3 分布式流式數據處理技術
數據被實時地收集和匯總形成數據流,為了盡快得到實時應用系統需要的數據結果,需要數據分析系統能盡快完成對原始數據的處理。在大數據環境下,單臺服務器很難滿足短時間內大量的數據計算要求,且考慮到業務和數據的增長,這些都要求數據分析系統具有良好的擴展性。下面介紹目前幾種主流的分布式數據流處理系統。
3.1 Storm
Storm[20]最初是由Twitter開發并開源的、基于分布式的實時數據處理系統,在Twitter、Yahoo、Alibaba等很多知名的大公司都得到廣泛的應用。其具有很好的容錯性、擴展性,且能到次秒級的延時,非常適合于低延時的應用場景。其組成系統組成為:
1)Nimbus,集群的主節點,負責集群資源的管理、任務的調度分配。
2)Supervisor,負責接收Nimbus分配的任務,啟動和停止屬于自己管理的工作進程。
3)Zookeeper,是Storm重點依賴的外部組件,提供Supervisor和Nimbus之間協調的服務,Nimbus和Supervisor心跳和任務運行情況都是保存在Zookeeper上。
Storm實現的數據流模型如圖8所示,包括:Topoloy(拓撲),類似于Hadoop上的MapReduce任務,數據在節點之間流動方向所組成的一個圖,且包含數據的處理邏輯;Tuple(消息元組),最小的消息處理和傳遞單元,每個Tuple都是不可變數組;Spout(噴嘴),從Storm外部接收數據轉為內部的數據來源,并將原始數據轉為處Tuple;Bolt(螺栓),接收來自Spout或上一級的Bolt的Tuple,在其內部作簡單的數據轉換和計算,并產生多個輸出Tuple流,發送給其他的Bolt,協作完成復雜的計算邏輯。
如圖8所示,Storm會通過Spout將外部的流式數據讀入Topology中,將其轉為消息處理單元Tuple,且給每一個Tuple分配一個消息ID(Identity),開始消息的處理流程。再將Tuple輸出到Bolt中,對于復雜的數據處理過程,Storm會將其分解成若干個簡單的處理邏輯,并根據特定的順序在不同的Bolt中進行處理和流通,直到經過最后一個Bolt的計算,此時才會將該消息ID標記為處理完成。
3.2 Samza
Samza[21]是LinkedIn開源的一個分布式流處理系統。Samza具有一些非常優秀的特性:通過簡單的API可以非常方便地處理流式數據;具有很好的容錯性,能在用戶沒有感知到的情況下恢復處理失敗的任務;任務狀態管理,出現故障時,能快速準確地恢復到失敗之前的狀態。
一個完整的Samza系統由三個組件構成:①Kafka為Samza提供實時的消息數據來源,也可以作為Samza數據處理后的數據存儲系統;②Samza進行流式數據處理,用戶可以使用它提供的API簡單方便的處理流式數據,而不用關心處理過程及容錯性等的管理;③Yarn[22]是Samza中的資源分配和任務管理系統,客戶端(Client)提交任務時會向Yarn集群中的RM(資源管理器,Resource Manager)申請資源,RM以容器(Container)的形式將資源封裝起來,并在容器里執行相應的Samza計算任務。
圖9為Samza系統的流式數據處理模型。當用戶提交一個任務時,首先會向Yarn中的Resource Manager申請所需的資源。接著Yarn在Node Manager節點上啟動容器,供Samza運行相應的任務。然后Samza進程從Kafka中不同分區中實時拉取數據,并進行相應的計算。最后將處理后的結果再次存入到Kafka進入到下一輪的計算或者輸出到其他存儲系統。
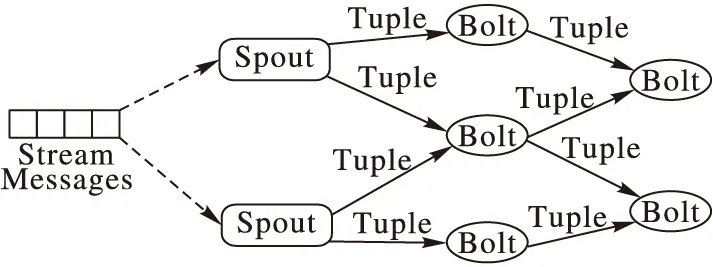
圖8 Storm數據流模型
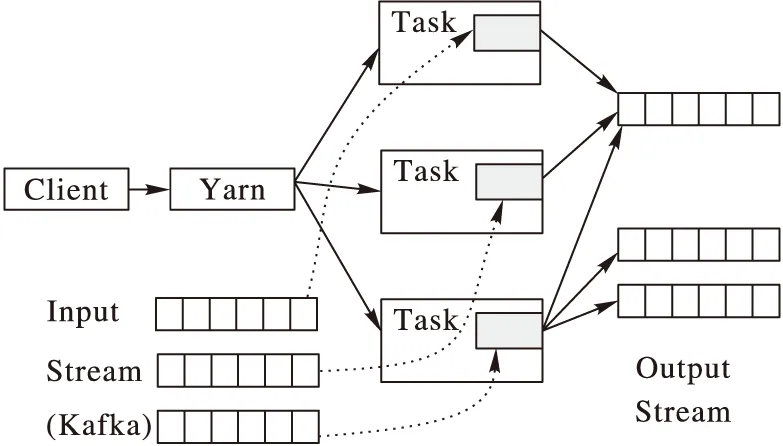
圖9 Samza流處理模型
3.3 Flink
Flink[23]起源于柏林理工大學的一個研究性項目,2014年被Apache孵化器所接受,并迅速地成為了ASF(Apache Software Foundation)的頂級項目之一。Flink是一個能同時適用于流數據和批處理的分布式處理引擎,其體現了一個最新的設計理念:數據處理應該是流式的,批處理只是流處理的一個特例,也就是說所有的任務都可以當成流來處理。這也是Flink跟其他流處理系統的最大區別。
圖10展示了Flink流計算的數據處理模型,在分布式數據處理系統中數據會在多個節點(Node)之間進行傳輸,在不同節點之間的數據傳輸分為兩種情況:
1)流處理。對實時達到的數據流在一個節點上處理之后,會將處理后的結果緩存在當前節點中,并立刻將數據傳輸給后續節點,進行下一步的處理,一直重復這個流程,直到得到最終結果。
2)批處理。當前節點會把需要處理的所有數據逐條處理,序列化并緩存起來,但不會立刻將該處理后的結果發送給下一個節點,當緩存不足時,會將數據持久化到磁盤,只有當所有數據都被處理完成后,才會將處理后的數據通過網絡傳輸到下一個節點。
Flink通過設置緩存數據的超時時間,來同時應對流處理和批處理系統:若超時時間為0,則會執行上述1)中的流程;若超時時間為無窮大,則執行2)的數據處理流程。此外,還可以通過設置超時時間的長短,來達到調節流處理延時的目的。
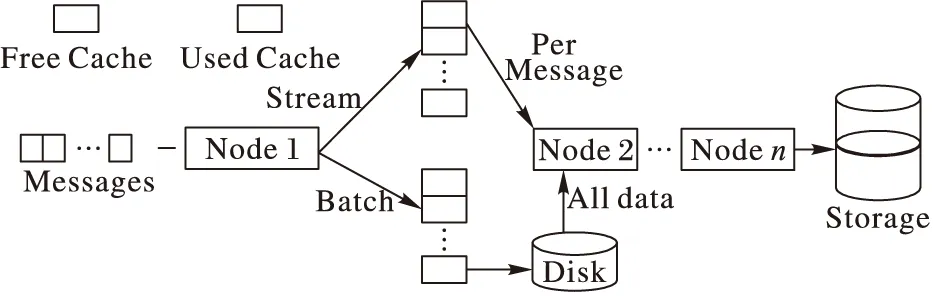
圖10 Flink數據處理模型
3.4 Spark Streaming
Spark Streaming是Spark[24]中用于流處理的一個組件。Spark是一個通用的并行計算框架,由加州伯克利大學(UCBerkeley)的AMP(Algorithms Machines People)實驗室開發,并于2010年開源,2013年成長為Apache旗下為大數據領域最活躍的開源項目之一。Spark也是基于MapReduce模型實現的分布式計算框架,擁有Hadoop MapReduce所具有的優點,并且增加了很多優秀的特性。
Spark同樣適用于批處理和流處理,其數據處理的實現都是基于彈性分布式數據集(Resident Distributed Dataset, RDD)[25]。RDD是其本質是一個基于內存的數據集,記錄了數據塊列表、數據塊上的數據如何轉化的函數、與父RDD之間的依賴關系(Lineage)、以及針對Key-Value類型數據的分區函數、數據的偏好位置(用于數據計算本地化)。Spark Streaming是Spark生態系統中用于處理流式數據的一個模塊,其本質是將用戶設定的固定時間內新接收的數據轉為一個RDD,進而分成很多小段的批處理,此操作稱為離散流(Discretized Stream, DStream)[26]。一個DStream實質是一個時間間隔很短的微批處理(micro-batching),所以,Spark Streaming的本質是將所有的數據處理形式都當作批處理對待。
圖11為Spark Streaming流式數據處理模型,在Spark Streaming中會把每個時間間隔內新接收的數據存入到一個新的RDD中,然后對每一個RDD進行相同的轉化操作(Transformation)和動作(Action),且它能支持窗口(Window)操作,即將不同時刻得到的RDD的數據統一進行操作,使之成為一個新的RDD,這樣就可以將新數據跟歷史數據相結合。
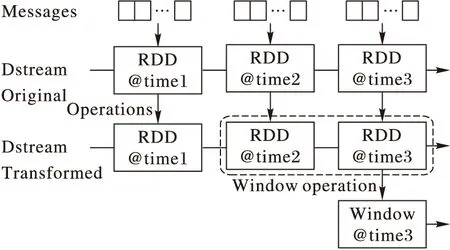
圖11 Spark Streaming數據處理模型
Spark Streaming流處理的理念與其他的流處理系統存在本質區別,但是在很多的應用場景中是可以容忍秒級別的延時,且將流數據進行微批處理在一定程度上能提高系統的吞吐量。此外,它在Spark的全棧式生態系統中,能很好地與批處理、Spark ML(Machine Language)、Spark Graph、Spark SQL(Structured Query Language)等相結合,解決數據的后續處理與分析問題,這是其他系統所不能比擬的。
3.5 分布式流式數據處理系統對比
表3中從不同角度比較Storm、Samza、Flink和Spark Streaming和特性。

表3 流式數據處理系統對比
在實時性方面,Spark Streaming由于采用微批處理的方式,所以延時最大,會存在秒級的延時,而其他三個流處理系統都是次秒級的延時。
分布式系統都會重點考慮容錯性,因此,這些分布式流處理系統都具有很好的容錯性。
而在語言支持上,Storm支持C/C++、Python、基于JVM(Java Virtual Machine)等大多數編程語言,相對而言,其語言支持特性是最好的,而且其他的系統一般只支持Python和基于JVM的編程語言。
在狀態管理上,Storm最初是不支持狀態管理的,后來才提供高層抽象——Trident來支持狀態管理,而其他流處理系統都支持狀態管理。
數據處理語義方面,都能保證數據至少被處理一次,這種方式在特定場景下,會存在部分數據被多次處理的情況,而Storm、Spark Streaming、Flink通過特定的配置,能達到數據剛好被處理一次的要求。
適用場景及生態系統完整性方面,Spark Streaming是最全面的,既支持批處理,又支持流處理,且還支持分布式圖計算、機器學習庫等高級功能;Flink緊跟Spark的步伐,也具備非常完善的生態系統,Storm也有部分其他的功能支持,而Samza則只支持流處理,缺乏其他場景的應用支持。
4 數據存儲技術
一方面,在一些場景中需要將海量的原始數據保存一段很長的時間,供后續的數據分析及防止系統故障導致的數據丟失。另一方面,在流式數據處理系統中,原始數據被處理之后,部分的數據會被立刻交付給應用系統加以應用,但也有部分是需要共享或者長期保存的,這就要求將處理后的結果存儲到可靠介質中。
表4列出了四種常用的數據存儲方式,下面從不同方面進行對比介紹:
HDFS(Hadoop Distributed File System),是谷歌GFS(Google File System)的開源實現,是一個分布式的數據存儲系統,支持大規模的數據存儲,具有很好的容錯性,其存儲能力隨著集群數量的增加呈線性增長,其具備很高的吞吐量,但是不適合低延遲數據訪問,無法高效存儲大量小文件,不支持多用戶寫入及任意修改文件。HDFS作為Hadoop生態系統中的主要存儲系統,在實時性要求不是很高的情況下,已經成為很多公司的首選存儲方案;
HBase[27],作為一個分布式的、面向列存儲的開源NoSQl數據庫,其理論基礎來源于谷歌的BigTable[28],支持上百萬列的大表,其數據最終存儲在HDFS中;但是,它克服了HDFS實時性和隨機讀寫的缺陷,可以支持數據的隨機讀寫、實時訪問,從而彌補了Hadoop生態系統中實時數據讀寫的空白。在CAP定理[29]中,HBase選擇了CP,即:C(Consistency,一致性)和P(Partition tolerance,分區容錯性),因此HBase在可用性上稍有欠缺,需要結合Zookeeper來完善其高可用性;
Cassandra[30],最初由Facebook開發,非常適合于社交網絡的數據存儲,在亞馬遜分布式引擎——Dynamo[31]的基礎上,結合BigTable的列族(Column Family)數據模型,并采用P2P(Peer to Peer)去中心化節點管理方式,側重于CAP理論中的AP:A(Availability,可用性)和P(Partition tolerance,分區容錯性),而采用最終一致性。支持多數據中心的數據復制,并提供類SQL語言——CQL(Cassandra Query Language)的支持。
Redis[32],是一款基于內存的key-value存儲系統。由于基于內存存儲,其具有很高的吞吐量,同時也支持將數據持久化到磁盤,提供強大的數據類型支持,包括lists、sets、ordered sets以及hashes等。此外,Redis中所有操作都是原子性的,Redis 3.0[33]以后提供了Cluster(集群)支持,使得其擴展性大幅度增強,但是其數據存儲容量比其他分布式數據庫系統略小。
表4中的四種常用數據存儲技術分別適用于不同的大數據應用場景,延時大小、擴展性、容錯性、高可用性等方面都是大數據環境下需要考慮的關鍵因素,沒有最好,只有更適合業務場景的解決方案。

表4 四種常用的數據存儲方式對比
5 分布式數據流的DDoS攻擊檢測
為了更好地理解分布式數據流處理系統組成,本章介紹一種大數據環境下的分布式拒絕服務(Distributed Denial of Service, DDoS)攻擊檢測數據流處理系統,其結構如圖12所示。整個系統包括:數據收集、數據分析、數據存儲、模型(或算法)訓練、入侵檢測。
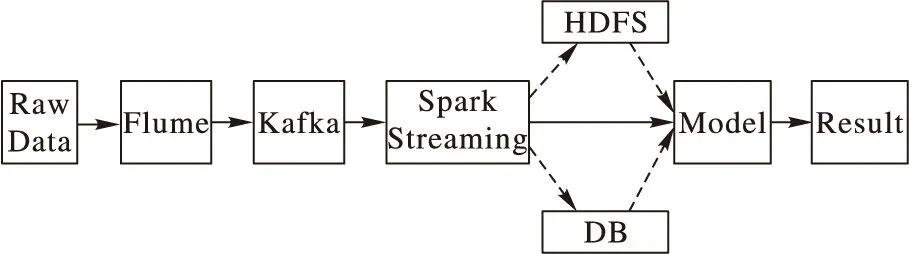
圖12 大數據環境下的DDoS攻擊檢測數據流處理系統
系統的數據流向為:1)數據的來源為不同的服務器,通過各種抓包軟件,如:TcpDump、NetFlow、Sniff等,對特定的網卡或端口進行數據包抓取,并通過Flume將不同服務器上的網絡數據匯總,將數據抓、分析和檢測分離,減輕應用服務器的負擔。2)數據匯聚之后,將所抓取的網絡數據作為Kafka Producer的消息源,并傳送到Kafka Broker,讓Broker對所有網絡數據進行有序的管理。3)Spark Streaming則實時從Kafka Broker中拉取數據,再將數據分散到不同的Spark Executor進行分析和統計。4)Spark將抓取的網絡數據處理后,一方面可以將結果傳給其他的應用,作進一步的分析;另一方面可以將結果持久化,存儲在數據庫(HDFS或其他數據庫)中,供后續分析使用。5)對得到的實時數據,可以使之與之前得到的歷史數據進行合并進行模型(或算法)訓練或者直接通過模型進行DDoS檢測,并得到檢測結果。整個系統數據搜集使用Flume、消息隊列管理使用Kafka、數據實時分析使用Spark Streaming、數據存儲使用HDFS或其他數據庫,具有好的擴展性、容錯性和實時處理能力,能充分滿足大數據環境下的各種DDoS攻擊檢測需求。
6 結語
本文主要研究了組成大數據環境下分布式數據流處理系統的各個子系統,包括數據收集子系統、消息隊列管理子系統、流式數據處理子系統和數據存儲子系統,詳細介紹了四類子系統中涉及的相關技術,并從不同的應用角度進行了比較,本文的研究內容能為大數據環境下的數據流處理的理論研究和應用系統開發提供參考,有一定的理論和應用價值。
References)
[1] 國家圖書館研究院.CNNIC發布第37次《中國互聯網絡發展狀況統計報告》[J].國家圖書館學刊,2016(2):20.(The Research Institute of the National Library.The 37th China Internet network development state statistic report issued by CNNIC [J]. Journal of the National Library of China, 2016(2):20.)
[2] IDC. The digital universe of opportunities: rich data and the increasing value of the Internet of things [EB/OL]. [2014- 04- 15]. http://www.emc.com/leadership/digital-universe/2014iview/executive-summary.htm.
[3] 戴永濤.分布式流處理系統研究與應用[D].上海:上海海事大學,2016:1-40.(DAI Y T. Research and application of distributed streaming system [D]. Shanghai: Shanghai Maritime University, 2016:1-40.)
[4] 趙勇.架構大數據——大數據技術及算法解析[M].北京:電子工業出版社,2015:394-410.(ZHAO Y. Big Data Structure—The Technology and Algorithm Analysis of Big Data [M]. Beijing: Publishing House of Electronics Industry, 2015: 394-410.)
[5] 孟小峰,慈祥.大數據管理:概念、技術與挑戰[J].計算機研究與發展,2013,50(1):146-169.(MENG X F, CI X. Big data management: concepts, technology and challenges [J]. Journal of Computer Research and Development, 2013, 50(1): 146-169.)
[6] 孫大為,張廣艷,鄭緯民.大數據流式計算:關鍵技術及系統實例[J].軟件學報,2014,25(4):839-862.(SUN D W, ZHANG G Y, ZHENG W M. Big data flow calculation: the key technology and system instance[J]. Journal of Software, 2014, 25(4): 839-862.)
[7] MICHAEL K, MILLER K W. Big data: new opportunities and new challenges [J]. Computer, 2013, 46(6): 22-24.
[8] Facebook. Scribe Wiki [EB/OL]. [2015- 02- 03]. https://github.com/facebookarchive/scribe/wiki.
[9] Apache Software Foundation. Apache Thrift [EB/OL].[2016- 05- 01]. http://thrift.apache.org/.
[10] Apache Software Foundation. Apache Flume [EB/OL]. [2016- 04- 09]. http://flume.apache.org/.
[11] Apache Software Foundation. Apache Chukwa [EB/OL]. [2016- 04- 05]. http://chukwa.apache.org/.
[12] Elasticsearch. Elasticsearch Logstash[EB/OL]. [2016- 04- 11]. https://www.elastic.co/products/logstash.
[13] Pivotal Software. RabbitMQ [EB/OL]. [2016- 04- 11]. http://www.rabbitmq.com/.
[14] Erlang. Erlang introduction [EB/OL]. [2016- 04- 11]. http://www.erlang.org/.
[15] HINTJENS P. ZeroMQ : Messaging for Many Applications [M]. Sebastopol: O’Reilly Media, 2013.
[16] SCHMIDT D C. Reactor: an object behavioral pattern for demultiplexing and dispatching handles for synchronous events [J]. Compilers Principles Techniques & Tools, 1999, 261(2): 201-208.
[17] Apache Software Foundation. Kafka [EB/OL]. [2016- 04- 11]. http://kafka.apache.org/.
[18] Apache Software Foundation. Apache Zookeeper [EB/OL]. [2016- 04- 11]. http://zookeeper.apache.org/.
[19] PALANIAPPAN S K, NAGARAJA P B. Efficient data transfer through zero copy [EB/OL]. [2016- 03- 13]. https://www.ibm.com/developerworks/linux/library/j-zerocopy/j-zerocopy-pdf.pdf.
[20] Apache Software Foundation. Apache Storm [EB/OL]. [2016- 04- 07]. http://storm.apache.org/.
[21] Apache Software Foundation. Apache Samza [EB/OL]. [2016- 04- 08]. http://samza.apache.org/.
[22] MURTHY A. Apache Hadoop YARN—background and an overview [EB/OL]. [2016- 04- 08]. http://hortonworks.com/blog/apache-hadoop-yarn-background-and-an-overview/.
[23] Apache Software Foundation. Apache Flink [EB/OL]. [2016- 04- 08]. http://flink.apache.org/.
[24] Apache Software Foundation. Apache Spark [EB/OL]. [2016- 04- 08]. http://spark.apache.org/.
[25] ZAHARIA M, CHOWDHURY M, DAS T, et al. Resilient distributed datasets: a fault-tolerant abstraction for in-memory cluster computing [C]// Proceedings of the 9th Usenix Conference on Networked Systems Design and Implementation. Berkely: USENIX Association, 2012: 2.
[26] ZAHARIA M, DAS T, LI H, et al. Discretized streams: an efficient and fault-tolerant model for stream processing on large clusters [C]// Proceedings of the 4th USENIX Conference on Hot Topics in Cloud Computing. Berkeley, CA: USENIX Association, 2012: 10.
[27] Apache Software Foundation. Apache Hbase [EB/OL]. [2016- 04- 06]. http://hbase.apache.org/.
[28] CHANG F, DEAN J, GHEMAWAT S, et al. Bigtable: a distributed storage system for structured data [C]// Proceedings of the 7th USENIX Symposium on Operating Systems Design and Implementation. Berkeley, CA: USENIX Association, 2006: 15.
[29] 百度百科.CAP原則 [EB/OL]. [2016- 03- 18]. http://baike.baidu.com/link?url=i-7VhglR7AO5k63IHraug1jk0t6LE03jVJsKJQiU L4VU22oNGDa3u2vr_PT8m27-b4ZG_vpxtY7laL8jHNzq9q.(Baidu Encyclopedia. CAP principle [EB/OL]. [2016- 03- 18]. http://baike.baidu.com/link?url=i-7VhglR7AO5k63IHraug1jk0t6LE03jVJsKJQiU L4VU22oNGDa3u2vr_PT8m27-b4ZG_vpxtY7laL8jHNzq9q.)
[30] LAKSHMAN A, MALIK P. Cassandra: a decentralized structured storage system [J]. ACM SIGOPS Operating Systems Review, 2010, 44(2): 35-40.
[31] DECANDIA G, HASTORUN D, JAMPANI M, et al. Dynamo: amazon’s highly available key-value store [J]. ACM SIGOPS Operating Systems Review, 2007, 41(6): 205-220.
[32] Redis Labs. Redis [EB/OL]. [2016- 04- 11]. http://redis.io/.
[33] Redis Labs. Redis cluster tutorial [EB/OL]. [2016- 04- 11]. http://redis.io/topics/cluster-tutorial.
This work is partially supported by the National Natural Science Foundation of China (61672338, 61373028).
CHEN Fumei, born in 1989,M.S. candidate, Her research interests include cloud computing, big data real-time analysis.
HAN Dezhi, born in 1966, Ph.D., professor. His research interests include cloud computing, cloud storage and security technologies, big data application technology.
BI Kun, born in 1981, Ph.D., lecturer, His research interests include cloud computing, cloud storage, big data application technology.
DAI Yongtao, born in 1991, M.S. candidate, His research interests include cloud computing, distributed computing, data mining, network security technology.
Key technologies of distributed data stream processing based on big data
CHEN Fumei, HAN Dezhi*, BI Kun, DAI Yongtao
(CollegeofInformationEngineering,ShanghaiMaritimeUniversity,Shanghai201306,China)
In the big data environment, the real-time processing requirement of data stream is high, and data calculations require persistence and high reliability. Distributed Data Stream Processing System (DDSPS) can solve the problem of data stream processing in big data environment. Besides, it has the advantages of scalability and fault-tolerance of distributed system, and also has high real-time processing capability. Four subsystems and their key technologies of the DDSPS based on big data were introduced in detail. The different technical schemes of each subsystem were discussed and compared. At the same time, an example of data stream processing system structure to detect Distributed Denial of Service (DDoS) attacks was introduced, which can provide the technical reference for data stream processing theory research and application technology development under big data environment.
big data; stream processing; message queue; data processing; data storage
2016- 09- 20;
2016- 10- 18。
國家自然科學基金資助項目(61373028, 61672338)。
陳付梅(1989—),女,山東臨沂人,碩士研究生,主要研究方向:云計算、大數據實時分析; 韓德志(1966—),男,河南信陽人,教授,博士, CCF高級會員,主要研究方向:云計算、云存儲及其安全技術、大數據應用技術; 畢坤(1981—),男,山東青島人,講師,博士,主要研究方向:云計算、云存儲、大數據應用技術; 戴永濤(1991—),男,湖南邵陽人,碩士研究生,主要研究方向:云計算、分布式計算、數據挖掘、網絡安全技術。
1001- 9081(2017)03- 0620- 08
10.11772/j.issn.1001- 9081.2017.03.620
TP391; TP311.13
A
猜你喜歡
電腦知識與技術(2025年18期)2025-07-20 00:00:00
工業設計(2022年8期)2022-09-09 07:43:20
心理學報(2022年4期)2022-04-12 07:38:02
水泵技術(2021年3期)2021-08-14 02:09:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
家庭影院技術(2017年9期)2017-09-26 03:41:45
工業設計(2016年8期)2016-04-16 02:43:26
中國慣性技術學報(2015年1期)2015-12-19 13:12:17
電測與儀表(2015年2期)2015-04-09 11:28:56
