基于迭代填充的內存計算框架分區映射算法
2017-05-24 14:45:22修位蓉英昌甜錢育蓉
計算機應用 2017年3期
卞 琛,于 炯,修位蓉,英昌甜,錢育蓉
(新疆大學 信息科學與工程學院,烏魯木齊 830046) (*通信作者電子郵箱bianchen0720@126.com)
基于迭代填充的內存計算框架分區映射算法
卞 琛*,于 炯,修位蓉,英昌甜,錢育蓉
(新疆大學 信息科學與工程學院,烏魯木齊 830046) (*通信作者電子郵箱bianchen0720@126.com)
針對內存計算框架Spark在作業Shuffle階段一次分區產生的數據傾斜問題,提出一種內存計算框架的迭代填充分區映射算法(IFPM)。首先,分析Spark作業的執行機制,建立作業效率模型和分區映射模型,給出作業執行時間和分配傾斜度的定義,證明這些定義與作業執行效率的因果邏輯關系;然后,根據模型和定義求解,設計擴展式數據分區算法(EPA)和迭代式分區映射算法(IMA),在Map端建立一對多分區函數,并通過分區函數將部分數據填入擴展區內,在數據分布局部感知后再執行擴展區迭代式的多輪數據分配,根據Reduce端已分配數據量建立適應性的擴展區映射規則,對原生區的數據傾斜進行逐步修正,以此保障數據分配的均衡性。實驗結果表明,在不同源數據分布條件下,算法均提高了作業Shuffle過程分區映射合理性,縮減了寬依賴Stage的同步時間,提高了作業執行效率。
內存計算;數據均衡;擴展式分區;迭代式映射
0 引言
近年來,利用內存的低延遲特性改進并行計算框架性能成為新的研究方向。內存計算框架避免了頻繁訪問磁盤的I/O性能瓶頸,解放了大內存+多核處理器硬件架構的潛在高性能,成為學術界一致認可的高性能并行計算系統[1-2]。雖然內存計算框架的性能表現優異,但與大數據時代的即時應用需求相比,還存在不小的差距,因此,從計算模型的角度研究內存計算框架的性能優化方法具有一定的現實意義。本文選取開源內存計算框架Spark[3-4]為研究對象,Spark以HDFS(Hadoop Distributed File System)為底層文件系統,采用彈性分布式數據集(Resilient Distributed Datasets, RDD)[5]作為數據結構,通過數據集血統(lineage)[5-6]和檢查點機制(checkpoint)[7-8]實現系統容錯,編程模式則借鑒了函數式編程語言的設計思想,簡化了多階段作業的流程跟蹤、任務重新執行和周期性檢查點機制的實現。
在Spark作業的寬依賴Stage執行過程中,Mapper將數據按key劃分并填入不同的Bucket,Bucket與Reducer為一一對應關系。由于原始數據分布的傾斜性,這樣的單一輪次分區映射過程使各Reducer計算數據量有較大差異,任務執行時間長短不一,從而增加了寬依賴Stage的計算延時,降低了作業執行效率。雖然系統支持用戶設定自定義分區函數,但由于真實的數據分布難以預知,無法確保自定義分區函數的合理性和準確性,因此數據分配的傾斜問題不可規避。為解決這一問題,本文主要做了以下工作:
1)首先對內存計算框架的作業執行機制進行分析,建立作業效率模型,給出了RDD計算代價和作業執行時間的定義。
2)通過分析寬依賴RDD的計算過程,建立了分區映射模型,給出了源數據分布、分區映射、分配傾斜度的定義,并證明這些定義與作業執行效率的因果關系。
3)通過模型的相關定義求解,設計了擴展式數據分區算法和迭代式分區映射算法,并對算法執行的細節問題進行詳細的分析和說明。
1 相關工作
在提出MapReduce的文獻[9]中,Dean等采用Hash函數對數據進行一次簡單的劃分,由于這種方法實現簡單且通用性高,成為開源的Hadoop系統默認的分區方案。Spark作為類MapReduce系統,在實現中也自然承接了MapReduce的分區方法,但實際應用表明,在不了解數據分布的情況下,一次Hash劃分的方法很難實現數據的合理分配。
一些研究成果致力于通過優化原生的分區映射策略解決數據分配的均衡性問題,文獻[10]研究Map和Reduce兩個階段的任務執行過程,通過分析數據不均衡分配的原因,歸納出數據傾斜的5個類別。文獻[11]提出SkewReduce策略,該策略建立用戶定義的代價模型,在作業執行過程逐步收集元數據,鄰近代價閾值時啟動分區映射過程,以實現計算數據量的均勻分配。文獻[12]提出MapReduce的增量式分區策略,將原始數據劃分為細粒度的微分區,通過數據分布的逐步感知和已分配數據量的統計,采用Max-Min算法進行數據增量分配,達到數據分配逐漸均衡的目標。文獻[13]提出SkewTune,與上述的研究成果不同,SkewTune建立Reducer的任務剩余代價評估模型,通過對Reducer執行進度進行統計,決定是否將數據向其他Reducer遷移。由于數據的二次遷移將延遲Reducer計算任務,因此相比設計分區策略保證數據均衡分配的方法,SkewTune具有較大的額外開銷。文獻[14]為實現分區數據的實時統計,在系統中增加額外的數據構Sketch-based,通過設計的分包算法進行Reducer計算數據量的動態調配,達到數據均衡分配的目標。
另外一些研究成果期望通過數據分布的逐步感知建立合理的分區映射方案。文獻[15]通過在Mapper增加采樣進程感知原始數據分布,已生成的分區容量達到閾值后進行重組或拆分,保障分配數據的均衡性。文獻[16-17]提出精細分區和動態拆分兩種算法,精細分區算法采樣獲得近似數據分布,動態拆分函數在Map任務完成一定比例后觸發,進行分區容量的二次調整,達到數據合理分配的目標。文獻[18-19]提出基于〈block,entity〉數據塊的分區方法,通過評估函數對超出閾值的數據塊進行調整,但沒有精確定義分區調整的時機問題。文獻[20]提出提前采樣的策略,在Map任務執行前先對輸入數據進行25%的隨機采樣,通過采樣結果獲得數據分布并制定分區函數。文獻[21]提出LEEN策略,通過對輸入數據的預掃描獲取數據分布,在Map任務執行過程中逐步統計key的頻率,然后綜合數據分布和key頻率設定合理的分區函數。
本文與上述研究成果的不同之處在于從寬依賴Stage數據分配的基本原理入手,以提高作業的整體執行效率為目的,設計了迭代填充分區映射算法,解決同構集群環境下數據分配的均衡性問題。通過分析作業的執行過程,建立了作業效率模型,提出了RDD計算代價和作業執行時間的定義。建立分區映射模型,提出了源數據分布、分配傾斜度的定義,并證明了兩個定義與作業執行時間的因果關系。根據模型和定義求解,設計了擴展式數據分區算法和迭代式分區映射算法。通過擴展式分區預留部分原始數據,并設計擴展區的延遲映射機制,為迭代式分區映射奠定基礎。通過擴展區迭代式的多輪數據分配,對原生區的數據傾斜進行逐步修正,減少各Reducer分配數據量差異,從而從整體上提高寬依賴Stage的計算速度,提高作業執行效率。相比已有的研究工作,迭代填充分區映射算法更適宜于內存計算框架的性能優化,并具有較高的普適性和易用性。
2 問題的建模與分析
本章首先分析Spark作業的執行機制,建立作業效率模型和分區映射模型,然后提出迭代填充分區映射的優化目標,為第3章的算法設計提供理論基礎。
2.1 作業執行機制
Spark將操作分為Transformation和Action兩類,調度策略采用延時調度機制,即當Action操作執行時,作業才會分發到集群執行。基于延時調度的原理,Spark會首先根據RDD的血統生成作業的有向無環圖(Directed Acyclic Graph,DAG),如圖1所示。其中虛線框代表Stage,圓角矩形代表RDD,填充方框表示RDD分區。Stage的劃分以寬依賴為邊界,各Stage順序執行,直至計算出最終結果。集群任務分配則以數據本地性作為依據,即任務總是調度給具有最佳數據本地性的工作節點,以減少網絡通信延時,提高作業執行效率。
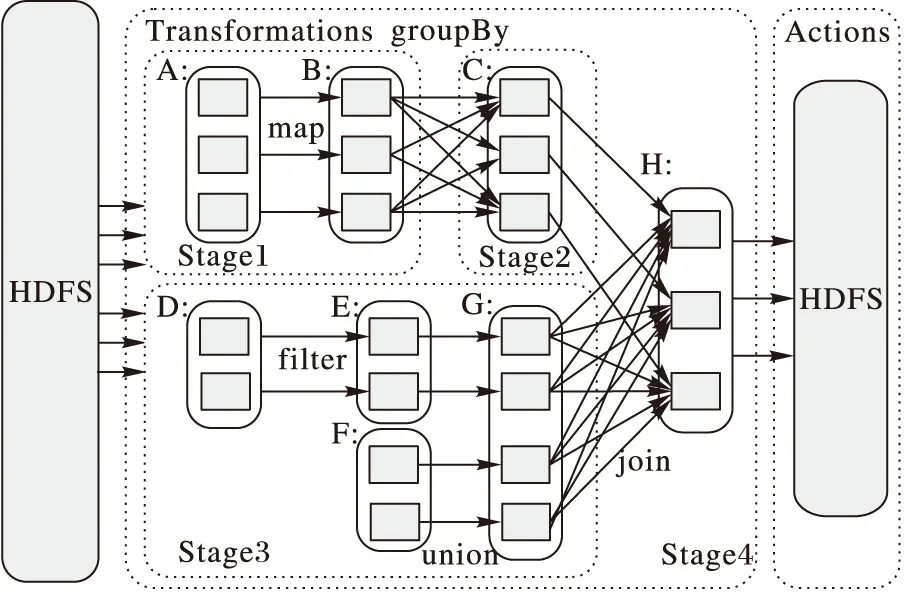
圖1 Spark作業的有向無環圖
2.2 作業效率模型
根據2.1節的描述,Spark作業在執行時劃分為多個Stage同步執行,每個Stage由一個或多個RDD構成,每個RDD由多個分區并行計算生成,因此,記一個作業的Stage集合為stages={stg1,stg2,…,stgi},每個Stage包含的RDD表示為集合stgi={RDDi1,RDDi2,…,RDDij}, 其中RDDij表示第i個Stage中第j個RDD,對于每個RDD,其分區集合記為RDDij={Pij1,Pij2,…,Pijk},這里Pijk表示RDDij中的第k個分區。
定義1 RDD計算代價。Spark任務中,分區是最基本的計算單位,分區計算首先要讀取輸入,再根據閉包運算符和操作符進行運算。設Parentsijk為分區Pijk的父分區集合,用于表示分區計算的輸入數據,那么分區Pijk的計算代價為數據讀取代價與數據處理代價之和,本文以分區計算時間作為衡量計算代價的唯一指標,即:
TPijk=read(Parentsijk)+proc(Parentsijk)
(1)
每個RDD的分區分配到不同的工作節點并行計算生成,因此RDD計算代價為所有分區計算代價的最大值,即:
TRDDij=max(TPij1,TPij2,…,TPijk)
(2)
定義2 作業執行時間。如圖1所示,Spark將Stage分為窄依賴和寬依賴兩類。對于窄依賴Stage,每個Stage包括多條流水線(每條流水線包括多個RDD的不同分區)。設窄依賴stagei共有h個RDD,所有RDD劃分為x條流水線,單條流水線的分區集合為pipeix={Pi1x,Pi2x,…,Pijx},那么單條流水線的執行時間可表示為:
(3)
對于stagei,記其流水線集合為Pipesi={pipei1,pipei2,…,pipeix},那么stagei的執行時間應為各流水線執行時間最大值,即:
Tstagei=max(Tpipei1,Tpipei2,…,Tpipeix)
(4)
設stagei+1為寬依賴,則其中僅包含一個RDD的計算任務,記為RDD(i+1)j,那么stagei的執行時間與RDD(i+1)j的計算代價相同,即:
Tstagei+1=TRDD(i+1)j
(5)
若Spark作業共有n個Stage(其中包括若干個窄依賴和寬依賴Stage),則各Stage順序執行,因此作業執行總時長為:
(6)
2.3 分區映射模型
作業的寬依賴Stage分Map和Reduce兩個階段執行,其中Map階段將前一Stage的生成結果轉化為〈key,value〉元組,放入不同的Bucket中,每個Bucket對應一個Reduce任務,所有Map任務執行結束后,由Reducer到各個工作節點拉取對應Bucket的數據,完成后續計算。由于工作節點內存空間有限,為防止頻繁內存回收,Spark將Bucket數據寫入磁盤,以保證Reducer輸入數據的可用性。
定義3 源數據分布。用于描述輸入數據在Mapper端的分布情況。記源數據的key集合為keys={key1,key2,…,keyl},即源數據有l個不同的key,記作業的Mapper集合為mps={1, 2,…,m},那么對于編號為m的任意Mapper,其數據分布可表示為:
Am=(Am1,Am2,…,Aml)T
(7)
其中Aml表示第l個key在第m個Mapper上的數據量。將所有Mapper的數據分布向量進行歸并,那么源數據的整體分布可表示為m×l矩陣:
(8)
矩陣中同行元素表示相同key在不同Mapper上的數據分布,映射過程同行元素也由相同的Reducer完成計算,因此將數據按key進行數據量統計,任意key的數據總量可表示為:
(9)
那么將源數據按key進行劃分,可表示為如下集合:
S={c1,c2,…,cl};l∈keys
(10)
定義4 分區映射。用于描述Mapper數據分布中key與Reducer之間的映射關系,分區映射也表示與Reducer對應Bucket的填充規則。Spark系統延用MapReduce的一次分區機制,默認對key進行哈希值轉換,再與Reducer的數量取模,以此決定數據所對應的Bucket,因此原生的分區函數可表示為:
f(Bucket)=hash(key)mod(n)
(11)
通過上述的分區函數可以看出,分區函數保證相同key值數據存放在同一個Bucket。由于所有Mapper采用同一分區函數劃分數據,因此源數據中所有相同key數據都映射到同一Reducer。
記作業的Reducer集合為rds={rd1,rd2,…,rdn},那么任意Reducer的分區映射關系可表示為:
inputrdi|→ {ci,cn+i,…,cj×n+i};j∈[0,l/n]
(12)
定義5 分配傾斜度。用于描述Reducer分配數據與均值的差異程度。由定義3可知,Reducer集合要處理的數據總量為S,那么在同構集群環境下,各Reducer分配數據量的均值應表示為:
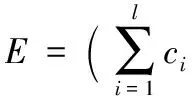
(13)
根據定義4的描述,Spark依舊延用MapReduce的一次分區技術,將key的哈希值與Reducer數量取模,以判定該key數據與Reducer的對應關系,但由于key的哈希值與其在數據分布的出現頻率無關,即與相同key的元組數無關,因此在多數情況下,各Reducer的數據分配量與均值不匹配,根據式(11)、(12),將任意Reducer的分配傾斜度定義為:
Qi=inputrdi/E
(14)
定理1 在同構集群環境下,對于所有執行寬依賴Stage的Reducer,其分配傾斜度越小,作業的執行效率越高。
證明 設作業當前執行寬依賴Stagei,基于定義3,寬依賴Stage僅包含一個RDD的計算工作,因此Stagei的執行時間等于RDDij的計算代價。記任意的Reducer計算時間為Tfinishn,由于在任務分配中,每個Reducer負責計算RDDij的一個分區,因此Stagei的執行時間也可表示為:
Tstagei=TRDDij=max(Tfinish1,Tfinish2,…Tfinishn)
(15)
同構集群環境下,各Reducer的計算能力基本一致,因此輸入數據量成為決定計算時長的唯一因素。根據定義5的描述,分配傾斜度表示Reducer數據分配與均值的差異,均值代表完全均勻的數據分配,因此對于所有執行寬依賴Stage的Reducer,其分配傾斜度越小,作業的執行效率越高。
3 迭代填充分區映射算法
本章基于模型相關的定義和證明,提出擴展式數據分區算法和迭代式分區映射算法,并對算法的執行細節進行分析和說明。
3.1 算法的總體描述
根據2.3節定義4,傳統Spark的分區方法延用MapReduce的一次劃分方法,數據分配與key的個數有關而與分配數據量無關,導致數據發生傾斜影響作業執行效率,因此,迭代填充分區映射算法的目標是提高數據分配策略與數據量的關聯度,以此增加分配策略的合理性,但由于在所有Map任務完成之前難以預知真實的數據分布,因此考慮改進既有的一次分區策略,通過多輪的分區映射過程達到數據適應性分配的目標。
迭代填充分區映射算法的主要思想是:1)將Mapper與Reducer之間的數據緩沖區劃分為原生區和擴展區兩部分,每個區域包含的Bucket數量與Reducer的個數相同。2)在原生分區策略的基礎上加以改進,保證大部分數據寫入原生區,而小部分key的數據寫入擴展區,并能夠對應到擴展區中不同的Bucket編號。3)原生區中的Bucket與Reducer之間為固定對應關系,當某個Mapper計算完畢后,所有Reducer即可開始進行原生區的數據拉取。4)初始狀態下,擴展區中的Bucket與Reducer無對應關系,達到特定時機則啟動后續輪次分配,將擴展區的數據逐步映射到Reducer。
3.2 擴展式數據分區算法
擴展式數據分區算法的主要步驟如下:
1)確定擴展參數x,原生區和擴展區生成Bucket,原生區的Bucket數量與Reducer的個數n相同,擴展區的Bucket數量為n×x。
2)Mapper計算hash(key)mod(n+x)獲得寫入數據的Bucket編號,若編號小于n,則寫入數據,本次過程結束;若編號大于等于n,則表示數據應放入擴展區,繼續執行步驟3)。
3)對于hash(key)mod(n+x)≥n的情況,繼續計算(hash(key)/(n+x))mod(n×x),確定該數據在擴展區中的Bucket編號并寫入數據,本次過程結束。
擴展式數據分區算法的偽代碼如下:
算法1 擴展式數據分區算法。
輸入:原生區native;擴展區extension;Reducer個數n;源數據鍵值key;擴展參數x。
初始化:bukNo←-1;
1)
native.creatBucket(n);
2)
extension.creatBucket(n*x);
3)
bukNo=hash(key) mod (n+x);
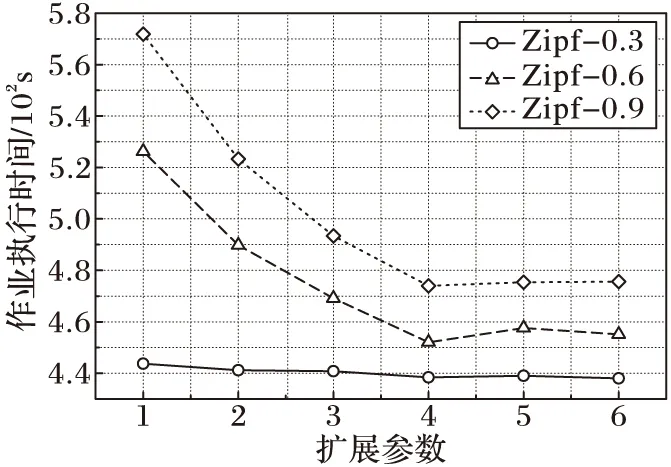
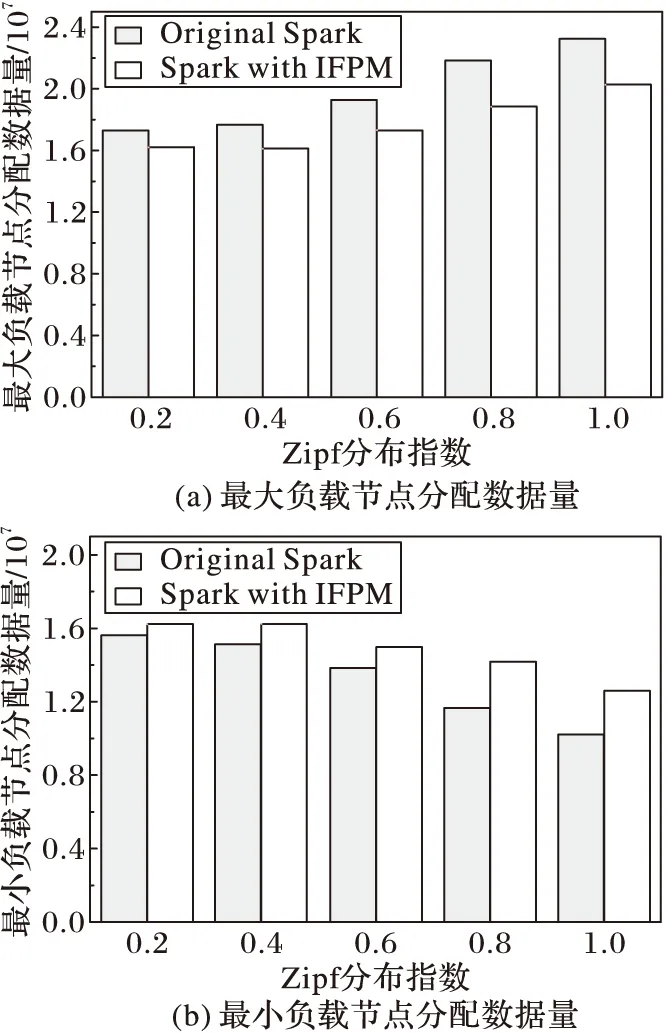
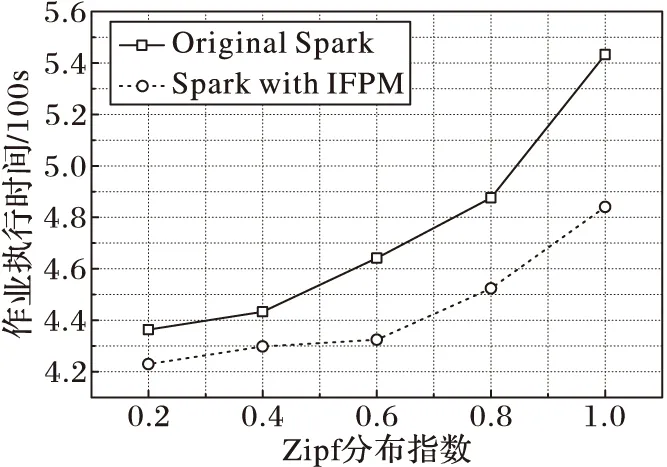
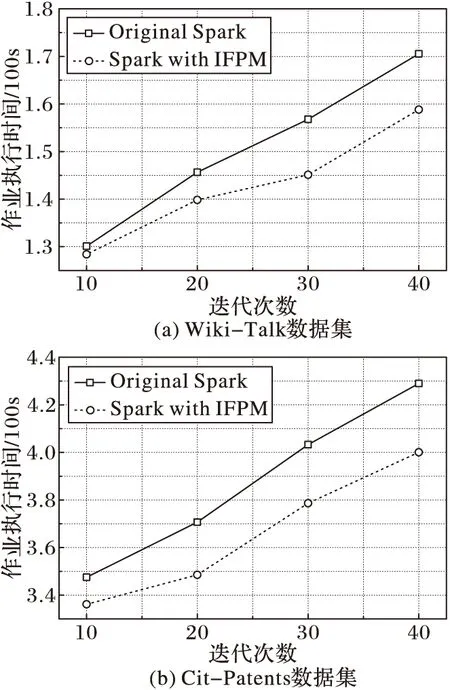
4)
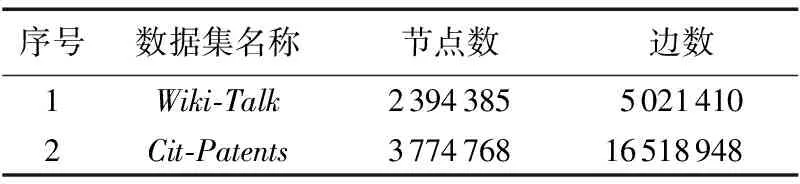
if(bukNo 5) write(key,native[bukNo]); 6) else 7) bukNo= (hash(key) /(n+x)) mod (n*x); 8) write(key,extension[bukNo]); 9) end if 由算法描述可以看出,擴展參數決定了原生區與擴展區的劃分比例,而擴展區則為后續的分區映射算法服務,通過多輪分配漸進填充,提高數據分配的合理性。 3.3 迭代式分區映射算法 根據3.1節的描述,原生區的Bucket數量與Reducer個數相同,兩者之間為一一對應關系,由于原生區的生成方式與MapReduce的一次分區策略相同,難以保證數據的均勻分配,因而擴展區的后續輪次分配的合理性成為算法目標實現的關鍵問題。為達到精準分配,本文方法在原生Spark系統中增加了1個計數器counter和1個數據構RelationSchema,counter用于統計擴展區內各Bucket的數據量,RelationSchema用于表示Bucket與Reducer的映射關系。原生區映射過程與傳統Spark相同,不再贅述,下面重點討論擴展區的映射過程,其主要步驟如下: 1)將擴展區中的Bucket倒序排列,并選取前n個Bucket生成待分配列表。 2)對所有Reducer的RelationSchema進行映射數據量統計,挑選出映射數據量最小的Reducer。 3)將分配列表容量最大的Bucket與映射數據量最小的Reducer建立一一對應的映射關系,更新RelationSchema。 4)重復步驟2),直到n個Bucket都映射完畢。 5)啟動數據拉取進程,等待下一輪映射過程。 算法2 迭代式分區映射算法。 輸入:擴展區extension;Reducer集合rds; 初始化:candis←newList〈Bucket〉; //待分配列表 1) extension.orderDesc(); 2) candis=extension.getTop(n); 3) fori=0 ton-1 do 4) rds.RelationSchema.statistics(); 5) minload=min(rds); //負載最小Reducer 6) minload.mapping(candis[i]); //建立映射 7) minload.RelationSchema.update(); 8) end for 9) start pull; //啟動數據拉取進程 10) waitfor nextround; //等待下一輪分配 接下來討論分區映射算法執行的時機問題,原生區的映射過程依舊采用傳統Spark的處理方式,即當第1個Mapper計算完成后,所有Reducer即可從該Mapper拉取數據。而對于擴展區的映射過程,由于僅當所有Mapper都計算完成才能獲得精確的擴展區數據分布,因此若算法過早執行,計數器counter的統計結果不夠精確,影響分區映射的合理性,而過晚執行則會使Reducer處于饑餓狀態,影響了作業的執行效率,因此分區映射算法的執行時機應設定為不影響作業執行效率的最晚時間,即當任意1個Reducer完成原生區的拉取工作,即啟動第1次分區映射算法,而后續輪次分配的執行時機均為上一輪拉取工作結束時間,以此類推,完成整個擴展區的映射過程。因此,每一輪分區映射過程都是對上一輪因統計結果不精確而產生的分配誤差進行修正,從而經過多輪迭代求得數據分配的近似最優解。 本章通過實驗比較和評價,驗證迭代填充分區映射算法的有效性。 4.1 實驗環境 實驗環境搭建采用1臺服務器和8個工作節點組成的集群,其中服務器作為Hadoop的NameNode和Spark的Master,主要配置為16顆4核心處理器陣列、256GB內存和4個千兆網卡。8個工作節點作為DataNode和Slave,配置如表1所示。參數配置方面,HDFS的默認備份數為3,Block大小為64MB,Spark的并行參數值(spark.default.parallelism)設置為16。作業執行時間的監測通過Spark控制臺,各種資源的使用狀況數據來源于nmon。 實驗數據選取Zipf數據集和有向圖兩種類型,其中Zipf數據集主要包括9個子數據集,總量為7.3GB,用于執行WordCount作業。每個子數據集滿足指數為γ的標準Zipf分布,γ取值范圍為0.2~1.0的小數,增量為0.1,γ的取值越大,表示數據分布越傾斜。有向圖主要包括SNAP(StanfordNetworkAnalysisProject)[22]提供的標準數據集,用于執行PageRank作業,如表2所示。 表1 工作節點配置參數 表2 測試數據集列表 4.2 擴展參數評估實驗 迭代填充分區映射算法通過引入擴展參數,確定原生區與擴展區的劃分比例,同時擴展參數也決定了數據分配的輪數,因此實驗首先驗證擴展參數對作業執行效率的影響。實驗選取Zipf數據集中γ取值為0.3、0.6和0.9的3個子數據集執行WordCount作業,實驗結果如圖2所示。 圖2 擴展參數影響實驗 由圖2可以看出,對于Zipf-0.3數據集,由于數據分布的傾斜度較低,其作業執行效率隨擴展參數值的增大,優化效果并不明顯。而對于Zipf-0.6和Zipf-0.9,在前4個監測點,隨著擴展參數值的增大,作業執行時間急劇下降,這是因為在數據分布傾斜度較大的情況下,原生區中各Bucket數據量差異較大,通過擴展參數的介入,能夠附加額外的數據分配,修正原生區數據分配產生的誤差,因此擴展參數值越大,修正效果越明顯。當擴展參數值為4時,作業執行效率的優化效果趨于穩定,在后2個監測點,作業執行時間又出現小幅提高,這是由于擴展系數具有最優上限,在此基礎上繼續增加分配輪數也無法提高作業執行效率;達到最優上限后,算法的額外開銷開始顯現,額外開銷導致了作業執行效率的輕微下降。 4.3WordCount對比實驗 實驗選取5個不同分布的Zipf數據集執行WordCount作業,對比迭代填充分區映射算法與傳統Spark的性能差異。其中擴展參數值統一設置為4,Spark啟動的Reducer數量為16。實驗首先監測最大負載節點和最小負載節點的分配數據量變化,實驗結果如圖3所示。 由圖3可以看出,與傳統Spark環境相對比,迭代填充分區映射算法降低了最大負載工作節點的計算數據量,提高了最小負載節點的數據量。這是因為傳統Spark一次分區策略對原始數據的分布不敏感,也缺乏有效的應對策略,因此數據分布的傾斜性導致了最大、最小負載節點之間的數據分配差。而對于迭代填充分區算法,擴展區的分配是對原生區數據傾斜分配有效彌補,從而產生相對均衡的數據分配。綜合來看,隨著Zipf分布指數的增大,傳統Spark的數據分配量差異越來越明顯,而迭代填充分區映射算法始終保持較為穩定的均勻狀態。這是由于在傳統Spark環境下,數據傾斜度越大,工作節點數據量差異也越大,分配效果也越差。而迭代填充分區映射算法的映射過程是通過多輪次分配完成,每一輪分配都是對上一輪分配誤差的修正,有效降低了數據分布對分配效果的影響,因此,從數據分配合理性的角度來看,迭代填充分區映射算法具有良好的優化效果。 圖3 分配數據量對比 圖4顯示了不同分布數據集作業執行時間的對比,從實驗結果來看,對于不同分布的Zipf數據集,迭代填充分區映射算法的作業執行時間均小于傳統Spark的執行時間。根據最大、最小節點的數據分配量可知,迭代填充分區映射算法保障了同構集群環境上數據分配的均衡性,具有相同計算能力的Reducer分配計算量差異較小,各任務完成時間也較為接近,因此寬依賴Stage的執行時間較短,作業的執行效率更高。而對于傳統Spark,由于其對數據傾斜分布無任何有效應對策略,往往導致相同計算能力Reducer所分配的計算數據量有較大差異,各任務完成時間長短不一,因此寬依賴Stage的執行時間較長,降低了作業的整體執行效率。從優化效果來看,數據分布傾斜度越大,迭代填充分區映射算法的優化效果越明顯,但優化效果并未隨分布指數據的增大呈線性增加趨勢,這是因為無法預知精確的數據分布,迭代填充分區映射算法僅是在現有條件下提供較為均衡的數據分配方案,而且擴展區的預留也采用固定的公式計算,不能根據不同數據分布進行靈活的適應性調整,因此對于不同的數據集其優化效果無明顯規律。 圖4 WordCount作業執行時間對比 4.4PageRank對比實驗 上一節通過WordCount作業驗證了算法的有效性,但由于WordCount僅包含一個依賴操作,Reducer也僅是作簡單的加法運算,不能完全體現迭代填充分區映射算法的優化效果,因此本節選擇寬依賴個數更多、操作復雜度更高的PageRank作業對算法作進一步評估。實驗選擇了2個不同大小的數據集進行,擴展參數值為4,Reducer個數為16,實驗結果如圖5所示。 圖5 PageRank作業執行時間對比 由圖5可以看出,對于每一個數據集,傳統Spark和迭代填充分區映射算法的作業執行時間都隨迭代次數的增加而上升;在每一個監測點,傳統Spark的作業執行時間均大于迭代填充分區映射算法,從而證明了本文算法對Spark框架的性能優化具有良好的效果,也驗證了理論模型及算法設計的正確性。從不同迭代次數的效率差異來看,作業的迭代次數越多,執行時間的優化度越高,作業執行時間的縮減比基本隨迭代次數據增加呈線性增長趨勢,這是由于在PageRank作業中,每輪迭代的數據分布都相同,因此迭代填充分區映射算法每輪迭代的優化效果也基本相同。從作業執行的整體趨勢來看,隨著迭代次數的增加,傳統Spark的作業執行時間上升幅度較大,而迭代填充分區映射算法由于其多輪分配均衡了不同Reducer間的計算數據量,加速了寬依賴Stage的執行,因此作業執行時間上升趨勢較為緩和。由此可以看出,傳統Spark的作業執行效率受寬依賴的影響較大,而迭代填充分區映射算法對寬依賴的敏感度較低,寬依賴Stage越多,越能夠體現算法的優化效果,作業執行的加速效應也越明顯。 本文針對Spark寬依賴Stage數據分區的傾斜問題,首先分析Spark作業執行機制,建立了作業效率模型,給出了RDD計算代價和作業執行時間的定義。通過對Spark框架原始的分區策略進行研究和分析,建立了分區映射模型,給出了源數據分布、分區映射和分配傾斜度的定義,并證明了這些定義對作業執行效率影響,為算法設計提供依據。其次,在相關定義和證明的基礎上,提出擴展式數據分區算法和迭代式分區映射算法,并對算法的執行細節進行分析和說明。最后,通過不同的實驗驗證算法的有效性,實驗結果表明,迭代填充分區映射算法提高了數據分配的合理性,優化了寬依賴Stage的作業執行效率。下一步的研究方向是探索異構集群下適應工作節點計算能力的分區映射策略。 ) [1]STRANDESM,CICOTTIP,SINKOVITSRS,etal.Gordon:design,performance,andexperiencesdeployingandsupportingadataintensivesupercomputer[C]//Proceedingsofthe1stConferenceoftheExtremeScienceandEngineeringDiscoveryEnvironment:BridgingfromtheExtremetotheCampusandBeyond.NewYork:ACM, 2012:ArticleNo. 3. [2]BRONEVETSKYG,MOODYA.ScalableI/Osystemsvianode-localstorage:approaching1TB/secfileI/O,LLNL-TR-415791 [R].Livermore,CA:LawrenceLivermoreNationalLaboratory, 2009: 1-6. [3]ZAHARIAM,CHOWDHURYM,DAST,etal.FastandinteractiveanalyticsoverHadoopdatawithSpark[J].Login, 2012, 37(4): 45-51. [4]ApacheSpark.Sparkoverview[EB/OL]. [2015- 03- 18].http://spark.apache.org. [5]ZAHARIAM,CHOWDHURYM,DAST,etal.Resilientdistributeddatasets:afault-tolerantabstractionforin-memoryclustercomputing[C]//Proceedingsofthe9thUSENIXConferenceonNetworkedSystemsDesignandImplementation.Berkeley,CA:USENIXAssociation, 2012: 2. [6]LINX,WANGP,WUB.LoganalysisincloudcomputingenvironmentwithHadoopandSpark[C]//Proceedingsofthe5thIEEEInternationalConferenceonBroadbandNetworkandMultimediaTechnology.Piscataway,NJ:IEEE, 2013: 273-276. [7]DONGX,XIEY,MURALIMANOHARN,etal.Hybridcheckpointingusingemergingnonvolatilememoriesforfutureexascalesystems[J].ACMTransactionsonArchitectureandCodeOptimization, 2011, 8(2): 510-521. [8] 慈軼為,張展,左德承,等.可擴展的多周期檢查點設置[J].軟件學報,2010,21(2):218-230.(CIYW,ZHANGZ,ZUODC,etal.Scalabletime-basedmulti-cyclecheckpointing[J].JournalofSoftware, 2010, 21(2): 218-230.) [9]DEANJ,GHEMAWATS.MapReduce:simplifieddataprocessingonlargeclusters[C]//Proceedingsofthe6thConferenceonSymposiumonOpeartingSystemsDesignandImplementation.Berkeley,CA:USENIXAssociation, 2004,6: 10. [10]KWONY,BALAZINSKAM,HOWEB,etal.AstudyofskewinMapReduceapplication[EB/OL]. [2016- 03- 18].https://www.researchgate.net/publication/228941278_A_Study_of_Skew_in_MapReduce_Applications. [11]KWONY,BALAZINSKAM,HOWEB,etal.Skew-resistantparallelprocessingoffeature-extractingscientificuser-definedfunctions[C]//Proceedingsofthe1stACMSymposiumonCloudComputing.NewYork:ACM, 2010: 75-86. [12] 王卓,陳群,李戰懷,等.基于增量式分區策略的MapReduce數據均衡方法[J].計算機學報,2016,39(1):19-35.(WANGZ,CHENQ,LIZH,etal.AnincrementalpartitioningstrategyfordatabalanceonMapReduce[J].ChineseJournalofComputers, 2016, 39(1): 19-35.) [13]KWONY,BALAZINSKAM,HOWEB,etal.SkewTune:mitigatingskewinMapReduceapplications[C]//Proceedingsofthe2012ACMSIGMODInternationalConferenceonManagementofData.NewYork:ACM, 2012: 25-36. [14]YANW,XUEY,MALINB.ScalableandrobustkeygroupsizeestimationforreducerloadbalancinginMapReduce[C]//Proceedingsofthe2013IEEEInternationalConferenceonBigData.Piscataway,NJ:IEEE, 2013: 156-162. [15]RAMAKRISHNANSR,SWARTG,URMANOVA,etal.BalancingreducerskewinMapReduceworkloadsusingprogressivesampling[C]//Proceedingsofthe3rdACMSymposiumonCloudComputing.NewYork:ACM, 2012:ArticleNo. 16. [16]GUFLERB,AUGSTENN,REISERA,etal.HandingdataskewinMapReduce[C]//Proceedingsofthe1stInternationalConferenceonCloudComputingandServicesScience.Berlin:Springer, 2011: 574-583. [17]GUFLERB,AUGSTENN,REISERA,etal.LoadbalancinginMapReducebasedonscalablecardinalityestimates[C]//Proceedingsofthe2012IEEE28thInternationalConferenceonDataEngineering.Washington,DC:IEEEComputerSociety, 2012: 522-533. [18]KOLBL,THORA,RAHME.LoadbalancingforMapReduce-basedentityresolution[C]//Proceedingsofthe2012IEEE28thInternationalConferenceonDataEngineering.Washington,DC:IEEEComputerSociety, 2012: 618-629. [19]KOLBL,THORA,RAHME,etal.Block-basedloadbalancingforentityresolutionwithMapReduce[C]//Proceedingsofthe20thACMInternationalConferenceonInformationandKnowledgeManagement.NewYork:ACM, 2011: 2397-2400. [20]RACHASC.LoadbalancingMap-Reducecommunicationsforefficientexecutionsofapplicationsinacloud[D].Bangalore,India:IndianInstituteofScience, 2012: 12-16. [21]IBRAHIMS,JINH,LUL,etal.HandlingpartitioningskewinMapReduceusingLEEN[J].Peer-to-PeerNetworkingandApplications, 2013, 6(4): 409-424. [22]JUREL.Stanfordnetworkanalysisproject[EB/OL]. [2015- 03- 18].http://snap.stanford.edu. ThisworkispartiallysupportedbytheNationalNaturalScienceFoundationofChina(61262088, 61462079, 61363083, 61562086),theEducationalResearchProgramofXinjiangUygurAutonomousRegion(XJEDU2016S106). BIAN Chen, born in 1981, Ph. D. candidate, associate professor. His research interests include parallel computing, distributed system. YU Jiong, born in 1964, Ph. D., professor. His research interests include grid computing, high performance computing. XIU Weirong, born in 1979, M. S., lecturer. Her research interests include data mining, distributed applications. YING Changtian, born in 1989. Ph. D. candidate. Her research interests include big data storage, in-memory computing. Qian Yurong, born in 1980. Ph. D., associate professor. Her research interests include cloud computing, graphics and image processing. Partitioning and mapping algorithm for in-memory computing framework based on iterative filling BIAN Chen*, YU Jiong, XIU Weirong, YING Changtian, QIAN Yurong (SchoolofInformationScienceandEngineering,XinjiangUniversity,UrumqiXinjiang830046,China) Focusing on the issue that the only one Hash/Range partitioning strategy in Spark usually results in unbalanced data load at Reduce phase and increases job duration sharply, an Iterative Filling data Partitioning and Mapping algorithm (IFPM) which include several innovative approaches was proposed. First of all, according to the analysis of job execute scheme of Spark, the job efficiency model and partition mapping model were established, the definitions of job execute timespan and allocation incline degree were given. Moreover, the Extendible Partitioning Algorithm (EPA) and Iterative Mapping Algorithm (IMA) were proposed, which reserved partial data into extend region by one-to-many partition function at Map phase. Data in extended region would be mapped by extra iterative allocation until the approximate data distribution was obtained, and the adaptive mapping function was executed by awareness of calculated data size at Reduce phase to revise the unbalanced data load in original region allocation. Experimental results demonstrate that for any distribution of the data, IFPM promotes the rationality of data load allocation from Map phase to Reduce phase and optimize the job efficiency of in-memory computing framework. in-memory computing; load balance; extendible partitioning; iterative mapping 2016- 09- 26; 2016- 10- 17。 國家自然科學基金資助項目(61262088, 61462079, 61363083, 61562086);新疆維吾爾自治區高校科研計劃項目(XJEDU2016S106)。 卞琛(1981—),男,江蘇南京人,副教授,博士研究生,CCF會員,主要研究方向:網絡計算、分布式系統; 于炯(1964—),男,北京人,教授,博士,CCF高級會員,主要研究方向:網格計算、高性能計算; 修位蓉(1979—),女,重慶人,講師,碩士,主要研究方向:數據挖掘、分布式應用; 英昌甜(1989—),女,新疆烏魯木齊人,博士研究生,主要研究方向:大數據存儲、內存計算; 錢育蓉(1979—),女,新疆烏魯木齊人,副教授,博士,CCF會員,主要研究方向:云計算、圖形圖像處理。 1001- 9081(2017)03- 0647- 07 10.11772/j.issn.1001- 9081.2017.03.647 TP A4 實驗與評價
5 結語
猜你喜歡
甘肅教育(2020年14期)2020-09-11 07:57:42
鐵道通信信號(2020年9期)2020-02-06 09:15:22
數學大王·趣味邏輯(2019年5期)2019-06-13 20:27:43
小學科學(學生版)(2019年5期)2019-05-21 01:00:18
經濟技術協作信息(2018年30期)2018-11-22 06:20:24
山東青年(2016年1期)2016-02-28 14:25:25
時代英語·高二(2015年1期)2015-03-16 00:08:11
中國衛生(2014年11期)2014-11-12 13:11:32
當代修辭學(2014年3期)2014-01-21 02:30:44
公務員文萃(2013年5期)2013-03-11 16:08:37
