基于雙權(quán)重約束的判別字典學(xué)習(xí)算法?
2017-06-05 15:03:56
計(jì)算機(jī)與數(shù)字工程 2017年5期
基于雙權(quán)重約束的判別字典學(xué)習(xí)算法?
李爭(zhēng)名1,2楊南粵1
(1.廣東技術(shù)師范學(xué)院工業(yè)中心廣州510665)(2.哈爾濱工業(yè)大學(xué)深圳研究生院生物計(jì)算研究中心深圳518055)
為了提高字典學(xué)習(xí)算法的分類性能,提出基于編碼系數(shù)和原子的雙權(quán)重約束判別字典學(xué)習(xí)算法(DWCDL)。利用編碼系數(shù)矩陣的行向量(Profiles)構(gòu)造原子權(quán)重約束項(xiàng),促使相似的原子重構(gòu)同類訓(xùn)練樣本,并減少原子間的自相關(guān)性。利用訓(xùn)練樣本的類標(biāo)設(shè)計(jì)編碼系數(shù)的權(quán)重,促使同類的訓(xùn)練樣本有相似的編碼系數(shù)。實(shí)驗(yàn)結(jié)果表明DWCDL算法比七個(gè)稀疏編碼和字典學(xué)習(xí)算法取得更高的分類性能。
字典學(xué)習(xí);權(quán)重約束;圖像分類
Class NumberTP391
1 引言
基于稀疏表示的分類算法(Sparse Representa?tion based Classification,SRC)[1]和基于協(xié)同表示的分類算法(Collaborative Representation based Classi?fication,CRC)[2]在人臉識(shí)別等領(lǐng)域中取得較好的分類性能。然而,研究結(jié)果表明利用從訓(xùn)練樣本中學(xué)習(xí)的字典比直接利用訓(xùn)練樣本能夠取得更好的性能[3~5]。因此,作為稀疏理論中的一個(gè)重要研究分支,判別字典學(xué)習(xí)受到越來越多研究者的關(guān)注。判別字典學(xué)習(xí)的主要目的是從訓(xùn)練數(shù)據(jù)中學(xué)習(xí)字典,使其能夠盡可能地保持訓(xùn)練數(shù)據(jù)的特征,同時(shí)又具有一定的判別性。判別字典學(xué)習(xí)算法的核心問題是如何設(shè)計(jì)判別式約束項(xiàng),增強(qiáng)字典的判別性。
由于類標(biāo)特征在模式分類中起到非常重要的作用,研究者利用訓(xùn)練樣本或原子類標(biāo)設(shè)計(jì)了許多判別式約束項(xiàng)。Zhang等[6]利用訓(xùn)練樣本類標(biāo)與編碼系數(shù)構(gòu)造誤差分類項(xiàng)作為判別式約束項(xiàng),在K奇異值分解(K-means-based Singular Value Decompo?sition,K-SVD)[7]字典學(xué)習(xí)算法的基礎(chǔ)上提出判別
綜上所述,為了提高字典學(xué)習(xí)算法的分類性能,提出同時(shí)考慮原子和編碼系數(shù)的權(quán)重約束判別字典學(xué)習(xí)算法。雙重構(gòu)約束判別字典學(xué)習(xí)算法不僅促使同類的訓(xùn)練樣本有相似的編碼系數(shù),也鼓勵(lì)同類的原子盡量重構(gòu)某一類訓(xùn)練樣本,增強(qiáng)字典的判別性能。
2 DWCDL算法
假設(shè)Y=[y1,…,yn]∈?m×n是訓(xùn)練樣本集合,n是訓(xùn)練樣本個(gè)數(shù),m是訓(xùn)練樣本的維數(shù),D=[d1,…,dk]T∈?m×k是字典,k是原子個(gè)數(shù),di是字典D的第i個(gè)原子,X=[x1,…,xn]T∈?k×n是編碼系數(shù)矩陣。
2.1原子的權(quán)重約束模型
根據(jù)文獻(xiàn)[12],理想情況下字典學(xué)習(xí)模型如圖1所示。

圖1 理想情況下的字典學(xué)習(xí)模型
其中,yi=[y1i,…,ymi]T是第i個(gè)訓(xùn)練樣本,xi=[x1i,…,xki]T是訓(xùn)練樣本yi對(duì)應(yīng)的編碼系數(shù),di=[d1i,…,dmi]T是第i個(gè)原子。根據(jù)profiles的定義,原子di對(duì)應(yīng)的profile為pi=[xi1,…,xin]T,圖1中每個(gè)長(zhǎng)方形框表示一個(gè)profile。因此,profiles矩陣可以定義為P=[p1,p2,…,pk]∈?n×k,其是編碼系數(shù)矩陣X的轉(zhuǎn)置矩陣,也即P=XT。從圖1中可以看出同一個(gè)profile中的元素都對(duì)應(yīng)字典中的一個(gè)原子。因此,profiles與字典中的原子是一一對(duì)應(yīng)關(guān)系。
由于profile是一個(gè)矢量,可以有很多種方法衡量它們的相似性。為了更好地反映profiles間的關(guān)系,利用profiles為頂點(diǎn)構(gòu)造圖G。圖G的權(quán)重利用式(1)計(jì)算:

其中,U(i,j)表示profilespi和pj間的相似性。δ是參數(shù),kNN(pi)表示profilepi的K近鄰。
根據(jù)文獻(xiàn)[13],相似的profiles對(duì)應(yīng)的原子也相似。因此,可以利用profiles衡量原子間的相似性,構(gòu)造原子的權(quán)重約束項(xiàng)如式(2):

為了更好地表示字典學(xué)習(xí)中原子間的權(quán)重關(guān)系,式(2)可以轉(zhuǎn)換為式(3)
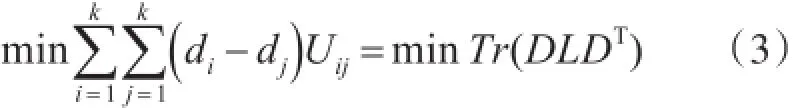

其中,Wij表示編碼系數(shù)xi和xj對(duì)應(yīng)訓(xùn)練樣本yi和yj的特征。
為了選擇合適的方法構(gòu)造自適應(yīng)的權(quán)重系數(shù)Wij,文獻(xiàn)[9]利用訓(xùn)練樣本的類標(biāo)構(gòu)造自適應(yīng)引導(dǎo)支持矢量模型如式(6)。
其中,L為拉普拉斯圖,構(gòu)造方法如式(4):
2.2編碼系數(shù)的權(quán)重約束模型
根據(jù)文獻(xiàn)[15],同類的訓(xùn)練樣本對(duì)應(yīng)的編碼系數(shù)也相似。因此,可以利用訓(xùn)練樣本的特征設(shè)計(jì)編碼系數(shù)的權(quán)重,其公式如下
其中,U=[u1,u2,…,uC]是SVM分類器的基準(zhǔn)超平面b=[b1,b2,…,bC]是對(duì)應(yīng)的誤差。C是訓(xùn)練樣本的類數(shù)。h=[h1,h2,…,hn]是訓(xùn)練樣本的類標(biāo)集合,hj=[,,…,]是第i個(gè)訓(xùn)練樣本的類標(biāo),如果hi=j,則=1,否則=-1。
2.3DWCDL算法的目標(biāo)函數(shù)
根據(jù)上述分析,為了提高字典學(xué)習(xí)算法的分類性能,構(gòu)造雙權(quán)重約束的判別字典學(xué)習(xí)算法的目標(biāo)函數(shù)如式(7):

其中,第一項(xiàng)表示字典的重構(gòu)性能,第二項(xiàng)表示原子的權(quán)重約束項(xiàng),第三項(xiàng)表示編碼系數(shù)的權(quán)重約束項(xiàng),第四項(xiàng)是編碼系數(shù)的正則項(xiàng)。α,β和γ是參數(shù)。
根據(jù)文獻(xiàn)[12~13],如果兩個(gè)profiles相似,它們對(duì)應(yīng)的原子被訓(xùn)練樣本集合使用的情況也是一樣的。因此,它們對(duì)應(yīng)的原子也是相似的。此外,minTr(DLDT)=minTr(DTDL),表明原子的權(quán)重約束項(xiàng)還能減少原子間的自相關(guān)性,進(jìn)一步增強(qiáng)字典的判別性能。根據(jù)文獻(xiàn)[9],利用訓(xùn)練樣本的類標(biāo)構(gòu)造自適應(yīng)的編碼系數(shù)權(quán)重約束項(xiàng),能夠促使同類的訓(xùn)練樣本對(duì)應(yīng)的編碼系數(shù)相似,增強(qiáng)字典學(xué)習(xí)算法的分類性能。同時(shí),為了減少算法的計(jì)算復(fù)雜度,利用l2范數(shù)約束編碼系數(shù)。
3 DWCDL算法的求解及分類方法
根據(jù)文獻(xiàn)[9],DWCDL算法不是一個(gè)全局凸優(yōu)化問題,但是對(duì)于各個(gè)變量則是凸優(yōu)化問題。因此,可以采取交替約束的方法對(duì)DWCDL算法求解。DWCDL算法利用主成元素分析(Principal Component Analysis,PCA)方法為每類樣本初始化一個(gè)特定類字典,并形成初始化的字典D。編碼系數(shù)矩陣X和U初始化為零矩陣,b初始化為零矢量。
3.1基準(zhǔn)超平面U和對(duì)應(yīng)的誤差b的求解
假設(shè)字典D,編碼系數(shù)矩陣X和拉普拉斯圖L是常量,則式(7)可轉(zhuǎn)換為一個(gè)多類線性支持向量機(jī)(Support Vector Machine,SVM)問題。根據(jù)文獻(xiàn)[9],利用式(8)所示的二次鉸鏈損失函數(shù)更新基準(zhǔn)超平面U和對(duì)應(yīng)的誤差b。

3.2編碼系數(shù)矩陣X和拉普拉斯圖L的求解
假設(shè)字典D,基準(zhǔn)超平面U和對(duì)應(yīng)的偏差b及拉普拉斯圖L是常量,編碼系數(shù)矩陣X的求解可以轉(zhuǎn)換為對(duì)每個(gè)編碼系數(shù)逐一求解。根據(jù)文獻(xiàn)[9],第i個(gè)編碼系數(shù)xi的求解如式(9):

如果獲得了編碼系數(shù)矩陣X,則可以利用式(4)更新拉普拉斯圖L。
3.3字典D的求解
假設(shè)編碼系數(shù)X,基準(zhǔn)超平面U和對(duì)應(yīng)的偏差b及拉普拉斯圖L是常量,字典D的求解可以轉(zhuǎn)換為式(10):

根據(jù)文獻(xiàn)[15],其可以利用拉格朗日函數(shù)進(jìn)行求解,于是式(10)轉(zhuǎn)換為式(11):

其中λ=[λ1,…,λi,…,λk](i∈[1,…,k]),λi是第i個(gè)等式約束(‖di‖2=1)的拉格朗日乘子。定義對(duì)角矩陣Λ∈?k×k,其對(duì)角元素Λii=λi。式(11)可以轉(zhuǎn)換為式(12):

為了獲得最優(yōu)的字典D,對(duì)式(12)求一階導(dǎo)數(shù)并令其等于零,可得式(13):
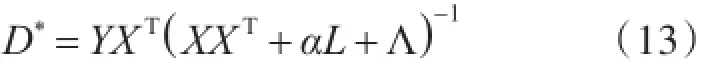
Λ的最優(yōu)求解過程見文獻(xiàn)[15]。為了減少計(jì)算復(fù)雜度,利用ηI代替Λ獲得最優(yōu)的字典D*為式(14):

其中,η是參數(shù),I是單位矩陣。
3.4分類方法
根據(jù)文獻(xiàn)[9],一旦獲得字典D和基準(zhǔn)超平面U和對(duì)應(yīng)的誤差b,利用SVM方法對(duì)測(cè)試樣本進(jìn)行分類的方法。DWCDL算法的分類過程如下:
1)對(duì)于測(cè)試樣本y,利用式(15)獲得其編碼系數(shù)x:


4 實(shí)驗(yàn)及結(jié)果分析
為了驗(yàn)證DWCDL算法的性能,本節(jié)給其與SRC[1],CRC[2],K-SVD[7],D-KSVD[6],LC-KSVD[8],F(xiàn)DDL[10]和SVGDL[9]算法在AR(Aleix Martinez and Robert Benavente)[16]和LFW(Labeled Faces in the Wild)[17]人臉數(shù)據(jù)庫(kù)以及Caltech 101[18]數(shù)據(jù)庫(kù)中的實(shí)驗(yàn)結(jié)果。SRC算法利用l1_ls方法獲得測(cè)試樣本的表示系數(shù)。CRC,K-SVD,D-KSVD,LC-KSVD,F(xiàn)DDL和SVGDL算法的代碼均由作者提供。由于LC-KSVD2比LC-KSVD1取得更好的分類性能,LC-KSVD算法的實(shí)驗(yàn)結(jié)果指的是LC-KSVD2算法。在所有實(shí)驗(yàn)中,DWCDL算法的參數(shù)α=1和η=1。參數(shù)β=0.05,θ=5和γ=0.002與SVGDL算法中的一樣。另外,構(gòu)造拉普拉斯圖L的參數(shù)δ=4和K=1。
4.1AR數(shù)據(jù)庫(kù)中的實(shí)驗(yàn)結(jié)果
AR數(shù)據(jù)庫(kù)中具有不同的表情、亮度和遮擋的采集于兩個(gè)階段的超過4,000幅彩色人臉圖像。根據(jù)文獻(xiàn)[19],選擇120個(gè)人作為子集合,圖像被調(diào)整為40×50像素大小的灰度圖像,圖2顯示AR數(shù)據(jù)庫(kù)中的部分圖像。

圖2 AR數(shù)據(jù)庫(kù)中的部分圖像
在本實(shí)驗(yàn)中,每類第一階段的13幅圖像作為訓(xùn)練樣本,第二階段的13幅圖片作為測(cè)試樣本。字典大小為1560,實(shí)驗(yàn)結(jié)果如表1所示。
4.2LFW人臉數(shù)據(jù)庫(kù)中的實(shí)驗(yàn)結(jié)果
LFW數(shù)據(jù)庫(kù)中的圖像來自于互聯(lián)網(wǎng),共計(jì)有1,680個(gè)人的13,000多幅人臉圖像。根據(jù)文獻(xiàn)[20],本實(shí)驗(yàn)用LFW數(shù)據(jù)的裁剪版本(LFW crop)為實(shí)驗(yàn)所用數(shù)據(jù)。根據(jù)文獻(xiàn)[21],從LFW crop數(shù)據(jù)庫(kù)中選擇每類圖像個(gè)數(shù)為11~20的人臉圖像作為數(shù)據(jù)集合,則一共有86人共計(jì)1,215幅圖像,并把圖像調(diào)整為32×32像素大小。圖3顯示LFW crop數(shù)據(jù)庫(kù)中的部分圖像。
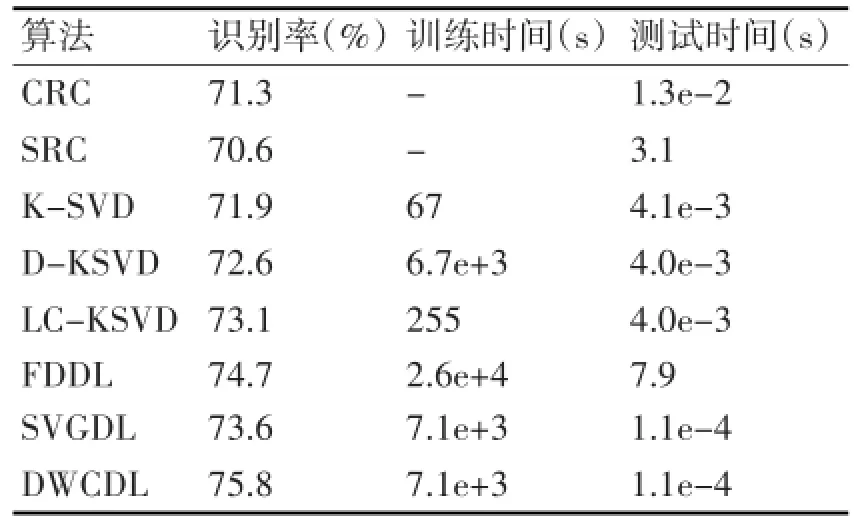
表1 AR數(shù)據(jù)庫(kù)中的識(shí)別率以及訓(xùn)練字典和分類樣本的平均時(shí)間

圖3 LFW crop數(shù)據(jù)庫(kù)中的部分圖像
在實(shí)驗(yàn)中,每個(gè)人隨機(jī)選擇5幅圖像作為訓(xùn)練樣本集合,剩下的作為測(cè)試樣本。字典的大小為430。重復(fù)運(yùn)行WDCDL算法和7個(gè)對(duì)比算法10次,實(shí)驗(yàn)結(jié)果如表2所示。

表2 LFW數(shù)據(jù)庫(kù)中的識(shí)別率以及訓(xùn)練字典和分類樣本的平均時(shí)間
4.3Caltech 101數(shù)據(jù)庫(kù)中的實(shí)驗(yàn)結(jié)果
Caltech 101數(shù)據(jù)集合包括有動(dòng)物、花和汽車等物體,共計(jì)102類圖像,每類圖像的數(shù)目為40~800不等。圖4顯示Caltech 101數(shù)據(jù)集合中的部分圖像。

圖4 Caltech 101數(shù)據(jù)庫(kù)中的部分圖像
根據(jù)文獻(xiàn)[8],利用從Caltech 101數(shù)據(jù)集合中提取的金字塔特征,并利用PCA方法降維到3000作為實(shí)驗(yàn)數(shù)據(jù)。在本實(shí)驗(yàn)中,每類隨機(jī)選擇5個(gè)作為訓(xùn)練樣本,剩余的作為測(cè)試樣本。字典大小設(shè)為510。重復(fù)運(yùn)行DWCDL算法和七個(gè)對(duì)比算法10次,實(shí)驗(yàn)結(jié)果如表3所示。

表3 Caltech101數(shù)據(jù)庫(kù)中的識(shí)別率
4.4實(shí)驗(yàn)結(jié)果分析
1)從表1~3中可以看出DWCDL算法比SVG?DL算法取得更高的識(shí)別率。SVGDL算法利用訓(xùn)練樣本的類標(biāo)設(shè)計(jì)自適應(yīng)的編碼系數(shù)權(quán)重,促使同類訓(xùn)練樣本對(duì)應(yīng)的編碼系數(shù)盡可能地相似。但是忽略了原子的特征,特別是理想情況下某些原子應(yīng)該僅僅重構(gòu)同類訓(xùn)練樣本。DWCDL算法利用Pro?files構(gòu)造自適應(yīng)原子權(quán)重約束,不僅能夠促使相似的原子盡可能地重構(gòu)同類訓(xùn)練樣本,而且能夠減少原子間的自相關(guān)性,增強(qiáng)了字典的判別性能。因此,DWCDL算法比SVGDL算法取得更好的分類性能。
2)表1~3表明DWCDL算法比FDDL算法取得更高的識(shí)別率。雖然兩種算法都同時(shí)考慮了編碼系數(shù)和原子的特征。不同點(diǎn)主要是FDDL算法考慮了不同類原子的重構(gòu)性能,而DWCDL算法不僅考慮了原子間的相似性,促使同類原子盡可能重構(gòu)某一類訓(xùn)練樣本,而且還能夠減少原子間的自相關(guān)性特征。因此,DWCDL算法比FDDL算法取得更好的識(shí)別率。
3)從表1~3中可以看出,DWCDL算法比K-SVD,D-KSVD和LC-KSVD算法取得更高的識(shí)別率。K-SVD,D-KSVD和LC-KSVD算法在字典學(xué)習(xí)中都忽略了自相關(guān)性及權(quán)重等原子特征,降低了字典的判別性能。而DWCDL算法通過構(gòu)造雙權(quán)重約束判別式項(xiàng)能夠克服上述算法存在的問題,提高了字典學(xué)習(xí)算法的分類性能。
4)當(dāng)原子個(gè)數(shù)等于訓(xùn)練樣本個(gè)數(shù)時(shí),表1~3表明DWCDL算法取得比CRC和SRC算法更高的識(shí)別率。主要原因是利用學(xué)習(xí)得到的字典比直接利用原始的訓(xùn)練樣本具有更好的分類性能。
5)表1和2表明,DWCDL算法的訓(xùn)練字典和測(cè)試樣本的時(shí)間與SVGDL算法基本上相等。主要是它們都采取相同的分類方法。DWCDL算法在訓(xùn)練階段增加了原子權(quán)重約束項(xiàng),由于原子權(quán)重約束項(xiàng)可以直接求導(dǎo),因此DWCDL算法的訓(xùn)練時(shí)間和SVGDL算法基本相等。此外,DWCDL訓(xùn)練字典的時(shí)間比K-SVD,D-KSVD,LC-KSVD算法都大,比FDDL算法小。主要原因是DWCDL算法采取逐個(gè)對(duì)編碼系數(shù)進(jìn)行求解,導(dǎo)致時(shí)間增加。由于采取SVM方法對(duì)測(cè)試樣本進(jìn)行分類,DWCDL算法的分類時(shí)間比SRC,CRC,K-SVD,D-KSVD,LC-KSVD和FDDL算法都小。
5 結(jié)語
本文提出一種新的原子權(quán)重約束模型,不僅能夠使得相似的原子盡可能重構(gòu)同類樣本,還能減少原子間的自相關(guān)性。并在SVGDL算法的基礎(chǔ)上,提出雙重構(gòu)約束的判別字典學(xué)習(xí)算法,增強(qiáng)字典學(xué)習(xí)算法的分類性能。實(shí)驗(yàn)結(jié)果表明DWCDL算法比直接利用原始訓(xùn)練樣本的SRC和CRC算法以及LC-KSVD,F(xiàn)DDL和SVGDL等字典學(xué)習(xí)均取得更高的分類性能。
[1]Wright J,Yang A Y,Ganesh A,et al.Robust face recogni?tion via sparse representation[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2009,31(2):210-227.
[2]Zhang L,Yang M,F(xiàn)eng X.Sparse representation or collab?orative representation:which helps face recognition[C]// IEEEInternationalConferenceonComputerVision(CVPR),2011:471-478.
[3]謝勤嵐,丁晶晶.基于改進(jìn)的字典學(xué)習(xí)算法的圖像去噪方[J].計(jì)算機(jī)與數(shù)字工程,2014,42(6):1071-1074.
XIE Qinlan,DING Jingjing.Image denoising method based on modified dictionary learning algorithm[J].Com?puter&Digital Engineering,2014,42(6):1071-1074.
[4]Xu Y,Li Z,Zhang B,et al.Sample diversity,representa?tion effectiveness and robust dictionary learning for face recognition[J].Information Sciences,2017,375:171-182.
[5]Huang K,Dai D,Ren C,et al.Learning kernel extended dictionary for face recognition[J].IEEE Transactions on Neural Networks and Learning Systems,2016,DOI:10.1109/TNNLS.2016.2522431.
[6]Zhang Q,Li B.Discriminative K-SVD for dictionary learn?ing in face recognition[C]//IEEE Conference on Comput?er Vision and Pattern Recognition(CVPR),2010,pp.2691-2698.
[7]Aharon M,Bruckstein M E.K-SVD:an algorithm for de?signing of over-complete dictionaries for sparse represen?tation[J].IEEE Transactions on Signal Processing,2006,54(11):4311-4322.
[8]Jiang Z,Lin Z,Davis Larry S.Label consistent K-SVD:learning a discriminative dictionary for recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intel?ligence,2013,35(11):2651-2664.
[9]Cai S,Zuo W,Zhang L,et al.Support vector guided dic?tionary learning[C]//European Conference on Computer Vision(ECCV),2014:624-639.
[10]Yang M,Zhang L,F(xiàn)eng X,et al.Sparse representation based fisher discrimination dictionary learning for image classification[J].International Journal of Computer Vi?sion,2014,109(3):209-232.
[11]Sadeghi M,Babaie-Zadeh M,Jutten C.Learning over?complete dictionaries based on atom-by-atom updating[J].IEEE Transactions on Signal Processing,2014,62(4):883-891.
[12]Lu C,Shi J,Jia J.Scale adaptive dictionary learning[J]. IEEE Transactions on Image Processing,2014,23(2):837-847.
[13]Li Z,Lai Z,Xu Y,et al.A locality-constrained and label embedding dictionary learning algorithm for image classi?fication[J].IEEE Transactions on Neural Networks and LearningSystems,2015,DOI:10.1109/ TNNLS.2015.2508025.
[14]Zhang Y,Jiang Z,Davis Larry S.Learning structured low-rank representations for image classification[C]// IEEE Conference on Computer Vision and Pattern Recog? nition(CVPR),2013:676-683.
[15]Zheng M,Bu J,Chen C,et al.Graph regularized sparse coding for image representation[J].IEEE Transactions on Image Processing,2011,20(5):1327-1336.
[16]Martineza M,Benavente R.The AR face database[J]. CVC Technical Report,1998,24.
[17]Huang G B,Ramesh M,Berg T,et al.Labeled faces in the wild:a database for studying face recognition in un?constrained environments[J].University of Massachu?setts,Amherst,Technical Report 07-49,Oct.2007.
[18]Li F,F(xiàn)ergus R,Perona P.Learning generative visual models from few training samples:an incremental Bayes?ian approach tested on 101 object categories[C]//Confer?ence on Computer Vision and Pattern Recognition Work?shop(CVPRW),2004,pp.178-178.
[19]Yang J,Zhang D,Yang J,et al.Globally maximizing,lo?cally minimizing:unsupervised discriminant projection with applications to face and palm biometrics[J].IEEE Transactions on Pattern Analysis and Machine Intelli?gence,2007,29(4):650-664.
[20]Sanderson C,Loverll Brain C.Multi-region probabilistic histograms for robust and scalable identity inference[C]// International Conference on Biometrics(ICB),2009:199-208.
[21]Wang S,Yang J,Sun M,et al.Sparse tensor discriminant color space for face verification[J].IEEE Transactions on Neural Networks and Learning Systems,2012,23(6):876-887.
Discriminative Dictionary Learning Based on the Double Weighted Constraints
LI Zhengming1,2YANG Nanyue1
(1.Industrial Training Center,Guangdong Polytechnic Normal University,Guangzhou510665)(2.Bio-Computing Research Center,Shenzhen Graduate School,Harbin Institute of Technology,Shenzhen518005)
In order to improve the classification performance of dictionary learning algorithms,a double weighted constraints discriminative dictionary learning algorithm(DWCDL)is proposed.The weighted constraint of atoms is constructed by using the pro?files,and it not only encourages the similar atoms to reconstruct training samples of the same class,but reduces the coherence of at?oms.The weighted constraint of coding coefficients is constructed by using the label information of training samples,and it can en?courage the training sample of the same class to have similar coding coefficients.Experimental results show that the proposed algo?rithm can achieve better classification performance than seven sparse coding and dictionary learning algorithms.
dictionary learning,weighted constraint,image classification
TP391
10.3969/j.issn.1672-9722.2017.05.004
2016年11月17日,
2016年12月23日
國(guó)家自然科學(xué)基金項(xiàng)目(編號(hào):61370613,61573248);廣東省普通高校青年創(chuàng)新人才項(xiàng)目(編號(hào):2015KQNCX089)資助。
李爭(zhēng)名,男,博士研究生,高級(jí)實(shí)驗(yàn)師,研究方向:字典學(xué)習(xí)。楊南粵,女,碩士,講師,研究方向:圖像處理,虛擬現(xiàn)實(shí)。K-SVD字典學(xué)習(xí)算法(Discriminative K-SVD,D-KSVD)。為了進(jìn)一步增強(qiáng)字典的判別性能,Ji?ang等[8]在D-KSVD算法的基礎(chǔ)上,利用原子的類標(biāo)構(gòu)建判別稀疏編碼錯(cuò)誤項(xiàng)作為判別式約束項(xiàng),提出類標(biāo)一致的判別字典學(xué)習(xí)算法(Label Consistent K-SVD,LC-KSVD)。Cai等[9]利用訓(xùn)練樣本的類標(biāo)特征設(shè)計(jì)編碼系數(shù)的權(quán)重,并在此基礎(chǔ)上構(gòu)造支持矢量引導(dǎo)字典學(xué)習(xí)(Support Vector Guided Diction?ary Learning,SVGDL)算法。Yang等[10]提出Fisher判別字典學(xué)習(xí)算法(Fisher Discrimination Diction?ary Learning,F(xiàn)DDL),同時(shí)利用編碼系數(shù)特征和原子的重構(gòu)性能設(shè)計(jì)判別式約束項(xiàng)。然而上述算法均忽略了原子間的特征,降低了字典的判別性能。最近,Sadeghi等[11]把編碼系數(shù)矩陣中每個(gè)行向量定義為一個(gè)profile,并利用其設(shè)計(jì)原子更新算法。Lu等[12]利用profile衡量原子重構(gòu)訓(xùn)練數(shù)據(jù)的貢獻(xiàn),并提出自適應(yīng)原子個(gè)數(shù)選擇算法。在此基礎(chǔ)上,Li等[13]提出利用原子衡量對(duì)應(yīng)profiles的局部特征約束模型,增強(qiáng)了字典的判別性能。根據(jù)文獻(xiàn)[8,14],理想情況下,同類訓(xùn)練樣本應(yīng)該由某些原子單獨(dú)重構(gòu),而且這些原子應(yīng)該屬于同一類。然而,上述算法均忽略了原子的權(quán)重約束。
猜你喜歡
中等數(shù)學(xué)(2022年2期)2022-06-05 07:10:50
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年11期)2021-12-06 05:38:48
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
小學(xué)生學(xué)習(xí)指導(dǎo)(低年級(jí))(2020年6期)2020-07-25 02:31:36
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
小學(xué)生學(xué)習(xí)指導(dǎo)(低年級(jí))(2018年9期)2018-09-26 05:59:44
瘋狂英語·新讀寫(2018年2期)2018-09-07 09:32:10
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(jí)(2017年9期)2017-10-13 22:27:46
