基于特征相似度的可比語料挖掘漢柬命名實(shí)體等價(jià)對(duì)?
2017-06-05 15:03:52
計(jì)算機(jī)與數(shù)字工程 2017年5期
關(guān)鍵詞:特征
基于特征相似度的可比語料挖掘漢柬命名實(shí)體等價(jià)對(duì)?
徐璐1,2嚴(yán)馨1,2夏青1,2周楓1,2莫源源3
(1.昆明理工大學(xué)信息工程與自動(dòng)化學(xué)院昆明650500)(2.昆明理工大學(xué)智能信息處理重點(diǎn)實(shí)驗(yàn)室昆明650500)(3.云南民族大學(xué)東南亞南亞語言文化學(xué)院昆明650500)
命名實(shí)體翻譯等價(jià)對(duì)在跨語言信息處理中具有非常重要的應(yīng)用價(jià)值,然而由于語料資源的有限性,國(guó)內(nèi)外關(guān)于漢柬命名實(shí)體等價(jià)對(duì)的抽取方法還沒有深入研究。論文從可比語料文本出發(fā),根據(jù)不同類型實(shí)體要素的特點(diǎn)以及在可比語料中的特點(diǎn),選取了柬文命名實(shí)體到中文命名實(shí)體的音譯特征、翻譯特征、可比語料中命名實(shí)體的上下文特征及自身的長(zhǎng)度特征,提出了一種基于多特征融合來計(jì)算相似度的方法來挖掘漢柬雙語命名實(shí)體等價(jià)對(duì)。實(shí)驗(yàn)表明該方法取得了比較好的效果,其中挖掘人名實(shí)體對(duì)的準(zhǔn)確率達(dá)到76%,召回率達(dá)到66%,證明了該方法要優(yōu)于只采用單一特征的方法。
命名實(shí)體等價(jià)對(duì);漢柬雙語;多特征融合;可比語料;音譯模型
Class NumberTP391.1
1 引言
命名實(shí)體是語言信息的關(guān)鍵載體,包括人名、地名、組織機(jī)構(gòu)名等具有名稱標(biāo)識(shí)的實(shí)體,而命名實(shí)體翻譯等價(jià)對(duì)是指源語言實(shí)體與目標(biāo)語言實(shí)體可互為翻譯,可比語料則是在兩篇雙語語料文本中,內(nèi)容不完全一致,但是討論的話題或主題是相同的。Cao[1]利用中英文網(wǎng)頁中英實(shí)體共現(xiàn)的特點(diǎn)來進(jìn)行命名實(shí)體等價(jià)對(duì)的挖掘。Lu[2]利用網(wǎng)頁中的錨點(diǎn)文本獲取命名實(shí)體等價(jià)對(duì)。Klementiev[3]提出在英俄可比語料中能夠獲取英俄命名實(shí)體音譯等價(jià)對(duì)的方法。Lam[4]團(tuán)隊(duì)提出了基于語義和語音信息匹配的雙語命名實(shí)體等價(jià)對(duì)的抽取方法。Rapp[5~6]在雙語可比語料中通過計(jì)算上下文的詞向量相似度來判斷候選命名實(shí)體等價(jià)對(duì)的相似度。Lu和Zhao[7]在可比語料中挖掘?qū)嶓w等價(jià)對(duì)時(shí),定義了多個(gè)特征并進(jìn)行特征的線性融合來計(jì)算候選命名實(shí)體等價(jià)對(duì)的相似度。Tao[8]則利用在不同語言環(huán)境下同一主題下的命名實(shí)體具有時(shí)空分布的特性來挖掘命名實(shí)體等價(jià)對(duì)。Wang[9]對(duì)可比語料中使用高關(guān)聯(lián)度詞對(duì)種子詞典沒有覆蓋到的詞進(jìn)行替代來擴(kuò)充種子詞典的覆蓋率,提高了實(shí)體等價(jià)對(duì)挖掘的準(zhǔn)確率。
本文針對(duì)以上研究現(xiàn)狀,充分考慮各種類型命名實(shí)體從源語言轉(zhuǎn)換為目標(biāo)語言的特征、可比語料中命名實(shí)體所在位置的上下文特征以及命名柬文命名實(shí)體和中文命名實(shí)體自身的一些特征,采用特征融合的方法來挖掘漢柬雙語命名實(shí)體等價(jià)對(duì)。
2 挖掘框架
漢柬命名實(shí)體等價(jià)對(duì)的挖掘總體框架如圖1所示。

圖1 可比語料獲取實(shí)體等價(jià)對(duì)框架
具體步驟如下:
1)命名實(shí)體識(shí)別
針對(duì)柬文的命名實(shí)體的識(shí)別使用基于CRF模型的柬埔寨語分詞工具和命名實(shí)體識(shí)別工具[10],而針對(duì)中文的命名實(shí)體的識(shí)別使用中科院的中文命名實(shí)體識(shí)別工具。
2)命名實(shí)體特征選取
計(jì)算源語言實(shí)體和目標(biāo)語言實(shí)體的特征相似度,需要充分利用不同類型實(shí)體的特征[11]。柬文中的人名、地名轉(zhuǎn)換為中文具有音譯特征;而柬文組織機(jī)構(gòu)名到中文組織機(jī)構(gòu)名的轉(zhuǎn)換往往通過意譯結(jié)合音譯,這就需要翻譯特征;此外不同語言實(shí)體本身的長(zhǎng)度也是實(shí)體的特征之一;由于實(shí)體的挖掘是在文本中進(jìn)行的,就要充分考慮實(shí)體上下文的文本特點(diǎn)。綜上所述,我們主要選取的特征為:音譯特征、翻譯特征、長(zhǎng)度特征、上下文向量特征。
3)特征相似度計(jì)算
根據(jù)命名實(shí)體的類型,將不同的特征融合到一個(gè)計(jì)算模型中,為每一個(gè)特征分配不同的權(quán)重,計(jì)算每個(gè)候選等價(jià)對(duì)的相似度,取相似度最大的候選等價(jià)對(duì)作為最終的輸出結(jié)果。
3 特征相似度計(jì)算
3.1音譯特征
音譯是指將目標(biāo)語言具有相似的發(fā)音序列作為源語言的翻譯,在人名和地名的翻譯中經(jīng)常用到的方式就是音譯。其音譯概率的計(jì)算流程如圖2所示。

圖2 音譯概率生成流程圖
音譯概率的生成步驟為
1)將漢柬雙語命名實(shí)體等價(jià)對(duì)的語料進(jìn)行人工標(biāo)注,包括柬文人名實(shí)體的音節(jié)切分標(biāo)注以及柬文人名實(shí)體音節(jié)到中文漢字的翻譯標(biāo)注。
2)定義條件隨機(jī)場(chǎng)模型進(jìn)行數(shù)據(jù)訓(xùn)練所需要的特征模板,使用音譯單元上下文特征、音譯單元序列上下文特征、標(biāo)注之間的轉(zhuǎn)移特征組合形成的特征模板進(jìn)行學(xué)習(xí)。
3)條件隨機(jī)場(chǎng)根據(jù)訓(xùn)練數(shù)據(jù)和定義的特征模板對(duì)特征進(jìn)行學(xué)習(xí),對(duì)模型中的參數(shù)進(jìn)行估計(jì),構(gòu)建出音譯模型。
4)在漢柬人名實(shí)體集合中,由音譯模型計(jì)算給定的柬語人名翻譯為中文人名的概率值。
這里采用基于序列標(biāo)注方法構(gòu)建的柬-漢音譯模型[12]。使用式(1)計(jì)算兩個(gè)集合間的各實(shí)體間的音譯相似度:

其中,km代表柬文人名實(shí)體集合中的一個(gè)柬文人名實(shí)體;cn代表中文人名實(shí)體集合中的一個(gè)中文人名實(shí)體;λ是音譯模型中的參數(shù);Z(x)表示歸一化因子。
3.2翻譯特征
命名實(shí)體中的組織機(jī)構(gòu)名是一種特殊的實(shí)體要素,為了計(jì)算兩個(gè)組織機(jī)構(gòu)名的翻譯模型概率,使用IBM統(tǒng)計(jì)翻譯模型中的翻譯模型概率。
翻譯概率模型的生成流程圖如圖3所示。

圖3 翻譯概率模型生成過程
翻譯概率模型的構(gòu)建步驟為:
1)漢柬平行句對(duì)齊文本的預(yù)處理,去掉噪聲和干擾。
2)GIZA++詞對(duì)齊。此處考慮到翻譯是正序的,故對(duì)應(yīng)的GIZA++調(diào)序配置項(xiàng)設(shè)置為否。
3)計(jì)算翻譯概率。
用生成的翻譯概率模型計(jì)算組織機(jī)構(gòu)名的翻譯特征相似度,如式(2)所示:
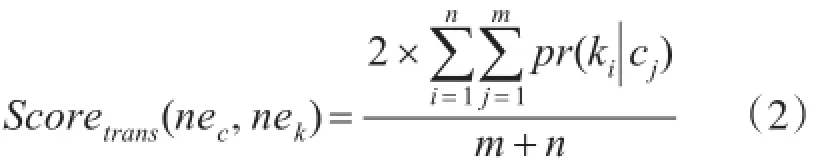
其中nec表示中文命名實(shí)體,n表示中文命名實(shí)體nec中詞的個(gè)數(shù),nek表示柬文命名實(shí)體,m表示柬文命名實(shí)體nek中詞的個(gè)數(shù),ki表示nek中的第i個(gè)詞,cj表示nec中的第j個(gè)詞。
3.3上下文詞向量特征
在柬文和中文兩種不同語言表述的可比語料中,如果文中某一個(gè)命名實(shí)體的上下文信息相通,則這兩個(gè)命名實(shí)體就有可能是互為翻譯的。上下文詞向量特征相似度計(jì)算流程如下:
1)候選命名實(shí)體的識(shí)別
該部分在柬-漢音譯特征研究中已經(jīng)介紹,這里不再贅述。
2)上下文信息的選取
首先在柬文語料中標(biāo)記全部的該柬文實(shí)體,然后將語料中該實(shí)體每個(gè)位置所在句子的前4個(gè)詞及后4個(gè)詞收集起來作為該柬文實(shí)體的上下文信息,形成集合個(gè)數(shù)為8的柬文實(shí)體上下文詞集合。用同樣的方法可以得到中文實(shí)體上下文詞集合。
3)上下文詞信息翻譯集合構(gòu)建
使用漢柬雙語詞典作為柬文實(shí)體上下文詞的翻譯工具,形成對(duì)應(yīng)的中文翻譯集合。
4)將中文翻譯集合與中文上下文詞集合進(jìn)行比較
如翻譯集合中的一個(gè)翻譯詞存在于中文上下文集合中,將該詞放入中文實(shí)體上下文向量集合中,同時(shí)該柬文詞放入柬文實(shí)體上下文向量集合中。重復(fù)此過程,直到源語言和目標(biāo)語言上下文詞集合中不存在翻譯詞。
5)向量相似度計(jì)算
獲取Km所在句子中Km的前4個(gè)名詞與后4個(gè)名詞,組成柬文實(shí)體上下文詞集合INFOkm={kq1,kq2,kq3,kq4,kh1,kh2,kh3,kh4},同理得到中文實(shí)體上下文詞集合INFOch={cq1,cq2,cq3,cq4,ch1,ch2,ch3,ch4}。使用漢柬雙語詞典比較IN?FOkm和INFOch,假定INFOkm中的一個(gè)柬文詞ki具有的翻譯集合為T={t1,t2,…,tw},比較翻譯集合T與中文實(shí)體上下文詞集合INFOch,若翻譯集合T中的一個(gè)翻譯ti存在于INFOch中,我們就把這個(gè)翻譯ti作為中文命名實(shí)體Ch的上下文詞向量VECch=[vc1,vc2,…,vcn]中的一維元素,將柬文詞ki作為柬文實(shí)體上下文詞向量VECkm=[vk1,vk2,…,vkm]中的一維元素。最后分別從柬文實(shí)體上下文詞集合INFOkm和中文實(shí)體上下文詞集合INFOch中刪除ki和ti。對(duì)這個(gè)過程進(jìn)行不斷的迭代,直到上下文INFOkm和INFOch中不再有等價(jià)的翻譯詞。
使用式(3)計(jì)算VECkm和VECch中每個(gè)詞的權(quán)重,這樣使得柬文命名實(shí)體上下文詞向量和中文命名實(shí)體上下文詞向量中的每個(gè)詞都有一個(gè)權(quán)重值。

式中tfi表示ti在Km的上下文中出現(xiàn)的次數(shù)。Km上下文中所有詞出現(xiàn)的次數(shù)總和用∑tfi表示。
VECkm和VECch中每個(gè)詞向量權(quán)重計(jì)算完成后,將上下文詞向量轉(zhuǎn)換為對(duì)應(yīng)的權(quán)重向量valuekm和valuech。最后,候選漢柬命名實(shí)體等價(jià)對(duì)的上下文詞向量特征相似度如下:
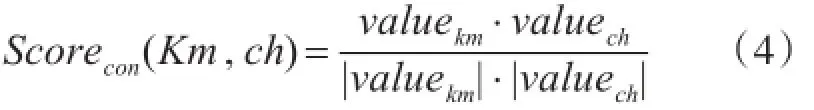
其中valuekm為柬文命名實(shí)體對(duì)應(yīng)的權(quán)重向量,valuech為中文命名實(shí)體對(duì)應(yīng)的權(quán)重向量。
3.4長(zhǎng)度特征
我們統(tǒng)計(jì)了8392對(duì)漢柬命名實(shí)體等價(jià)對(duì),發(fā)現(xiàn)中文實(shí)體漢字的長(zhǎng)度和對(duì)應(yīng)柬文實(shí)體kcc字符的長(zhǎng)度的比值在1~2之間,因此使用柬文kcc的長(zhǎng)度與漢字長(zhǎng)度的比值作為一維特征相似度來約束柬文實(shí)體與中文實(shí)體的長(zhǎng)度匹配,長(zhǎng)度相似度的計(jì)算如式(5):

其中,Ch表示中文命名實(shí)體,Km表示柬文命名實(shí)體,Lkcc表示柬文命名實(shí)體kcc字符的長(zhǎng)度,Lcha表示中文命名實(shí)體漢字的長(zhǎng)度。
4 漢柬雙語實(shí)體等價(jià)對(duì)相似度計(jì)算
分別為選取的四種特征進(jìn)行權(quán)重分配,將各特征值進(jìn)行歸一化處理后得到最終的漢柬雙語實(shí)體等價(jià)對(duì)相似度。表1為命名實(shí)體各特征組合的權(quán)重設(shè)置統(tǒng)計(jì)表。

表1 實(shí)體特征組合權(quán)重分配表
每種特征值都表示候選漢柬命名實(shí)體等價(jià)對(duì)在該特征方面的相似度,我們將四種特征融合到一個(gè)計(jì)算模型中來評(píng)價(jià)候選漢柬命名實(shí)體等價(jià)對(duì)的相似度,計(jì)算模型如式(6)所示。
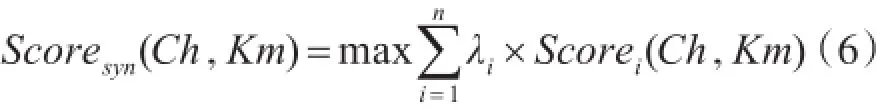
其中,Km表示候選漢柬命名實(shí)體等價(jià)對(duì)中的柬文命名實(shí)體,Ch表示候選漢柬命名實(shí)體等價(jià)對(duì)中的中文命名實(shí)體。Scorei(Ch,Km)是當(dāng)使用第i個(gè)特征計(jì)算中文命名實(shí)體Ch與柬文命名實(shí)體Km在該特征上的相似度,λi表示特征i在計(jì)算中的權(quán)重,將所有的特征進(jìn)行加權(quán)求和,取結(jié)果最大值的候選命名實(shí)體等價(jià)對(duì)作為最終的挖掘結(jié)果輸出。
5 實(shí)驗(yàn)及結(jié)果分析
5.1評(píng)價(jià)方法
評(píng)價(jià)方法包括準(zhǔn)確率(P),召回率(R),F(xiàn)值(F),計(jì)算公式如下:
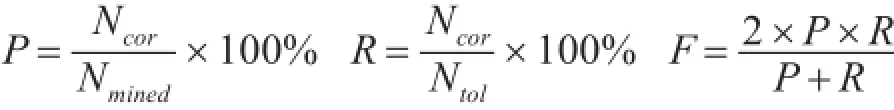
其中Ncor是挖掘到的正確的命名實(shí)體等價(jià)對(duì),Nmined是挖掘到的命名實(shí)體等價(jià)對(duì),Ntol是可比較語料中存在的命名實(shí)體等價(jià)對(duì)。
5.2實(shí)驗(yàn)語料
實(shí)驗(yàn)用到的漢柬可比語料庫的統(tǒng)計(jì)如表2,該可比語料庫人工標(biāo)注了語料中的命名實(shí)體等價(jià)對(duì)以及實(shí)體的類型用作標(biāo)準(zhǔn)結(jié)果來對(duì)比挖掘的漢柬命名實(shí)體等價(jià)對(duì)。

表2 可比語料數(shù)量及語料中各類型實(shí)體數(shù)量統(tǒng)計(jì)
5.3實(shí)驗(yàn)結(jié)果分析
命名實(shí)體對(duì)挖掘?qū)嶒?yàn)結(jié)果如表3所示,表中特征組合按照第4節(jié)中的權(quán)重分配表設(shè)置。
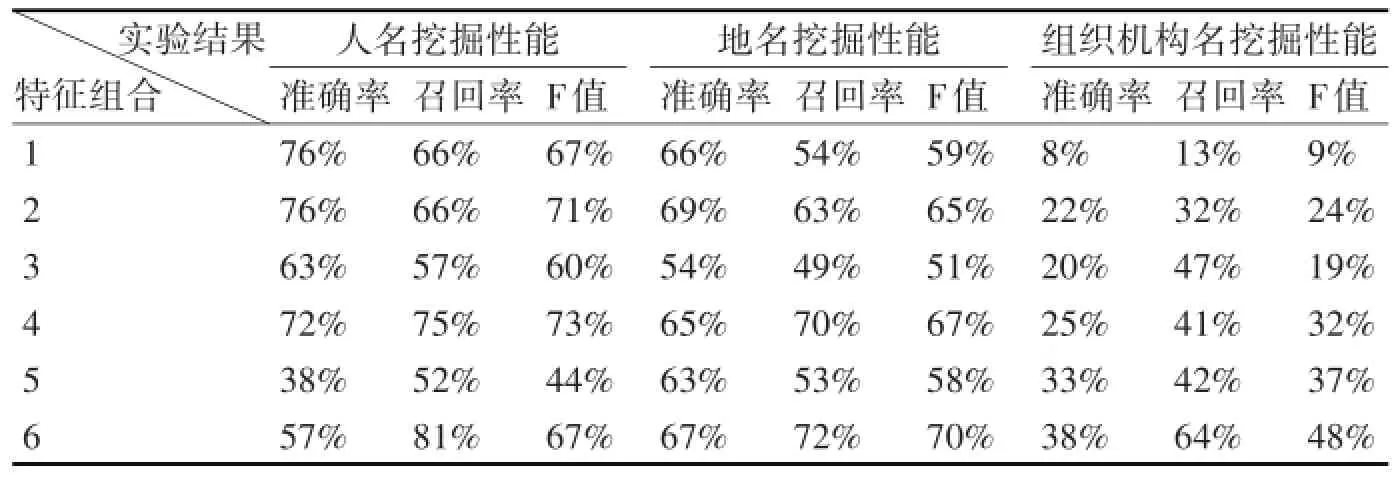
表3 使用不同特征組合挖掘人名、地名、組織機(jī)構(gòu)名命名實(shí)體挖掘性能
從表3實(shí)驗(yàn)結(jié)果可以看出,人名和地名命名實(shí)體挖掘的主要特征是音譯特征,在加入上下文詞向量特征后,挖掘性能達(dá)到最高,說明上下文詞向量特征對(duì)人名和地名的挖掘有一定的幫助,而長(zhǎng)度特征和翻譯特征對(duì)挖掘性能的提升并不大。而組織機(jī)構(gòu)名的挖掘主要是音譯特征與翻譯特征的結(jié)合,當(dāng)加入上下文詞向量特征和長(zhǎng)度特征會(huì)對(duì)挖掘性能有一定的提升。
6 結(jié)語
本文通過分析漢柬命名實(shí)體等價(jià)對(duì)的特點(diǎn),提出了音譯特征、翻譯特征、上下文詞向量特征以及實(shí)體的長(zhǎng)度特征,并將這些特征進(jìn)行了線性組合,并根據(jù)要挖掘?qū)嶓w的類型進(jìn)行了相應(yīng)權(quán)重的設(shè)置,從而在漢柬可比語料中挖掘漢柬命名實(shí)體等價(jià)對(duì)。最后設(shè)置相關(guān)的實(shí)驗(yàn)進(jìn)行了驗(yàn)證,實(shí)驗(yàn)表明提出的各項(xiàng)特征都起到了較好的效果。在下一步研究中,我們將通過實(shí)驗(yàn)探索從而確定最佳的權(quán)值與特征線性組合,得到準(zhǔn)確率和召回率更高的命名實(shí)體等價(jià)對(duì)。
[1]Cao G H,Gao J F,Nie J Y.A System to Mine Large-Scale Bilingual Dictionaries from Monolingual Web Pages[C]// Proceedings of MT Summit Xl.Copenhagen,Denmark:Dtw Deutsche Tierrztliche Wochenschrift,2007.
[2]Lu W,Lee H,et al.Anchor Text Mining for Translation of web Queries:A Transitive Translation Approach[J].ACM Transactions on Information Systems,2004,22(2):242-269.
[3]Klementiev A,Roth D,et al.Named Entity Transliteration and Discovery from Multilingual Comparable Corpora[C]// In Proceedings of the Human Language Technology Con?ference of North American Chapter of the ACL,New York,America:Association for Computational Linguis? tics,2006.
[4]Lam W,et al.Named Entity Translation Matching and Learning:With Application for Mining Unseen Transla?tions[J].ACM Transactions on Information Systems,2007,25(1):1-32.
[5]Reinhard Rapp.Identifying Word Translation in Non Par?allel Texts[C]//33rd Annual Meeting of the ACL,Massa?chusetts,USA:DBLP,1995.
[6]Reinhard Rapp.Automatic Identification of Word Transla?tions from Unrelated English and German Corpora[C]//37th annualmeetingoftheACL,GoldCoast,Australia,1999.
[7]Lu M,Zhao J.Multi-feature Based Chinese-English Named Entity Extraction from Comparable Corpora[C]// The 20th Pacific Asia Conference on Language Informa?tion and Computation,Wuhan,China:Association for Computational Linguistics,2006.
[8]Tao T,et al.Unsupervised Named Entity Transliteration Using Temporal and Phoetic Correlation[C]//Proceedings of the 2006 Conference on Empirical Methods in Natural Language Processing:Conference on Emnlp,2006.
[9]Lishuang Li,Peng Wang,Degen Huang,Lian Zhao:Min?ing English-Chinese Named Entity Pairs from Comparable Corpora[J].ACM Trans.Asian Lang.Inf.Process.(TALIP),2011,10(4):1-19.
[10]潘華山.基于條件隨機(jī)場(chǎng)的柬埔寨語詞法分析方法研究[D].昆明:昆明理工大學(xué),2014.
PAN Huashan.Cambodian lexical analysis based on con?ditional random method[D].Kunming:Kunming Univer?sity of Science and Technology,2014.
[11]王鵬.從可比語料中抽取中英命名實(shí)體等價(jià)對(duì)[D].大連:大連理工大學(xué),2011.
WANG Feng.The equivalence of named entities in Chi?nese and English from comparable corpora[D].Dalian:Dalian University of Science and Technology,2011.
[12]Qing Xia,Xin Yan,Zhengtao Yu,Shengxiang Gao.Re?searchontheextractionofWikipedia-basedChi?nese-Khmer named entity equivalents[C]//The 4th CCF Conference on Natural Language Processing and Chinese Computing,Nanchang,China:Springer International Publishing,2015.
Chinese-Khmer Named Entity Equivalents Excavation Based on Feature Similarity in Comparable Corpus
XU Lu1,2YAN Xin1,2XIA Qing1,2ZHOU Feng1,2MO Yuanyuan3
(1.School of Information Engineering and Automation,Kunming University of Science and Technology,Kunming650500)(2.The Intelligent Information Processing Key Laboratory,Kunming University of Science and Technology,Kunming650500)(3.School of Southeast Asia&South Asia Languages and Cultures,Yunnan Minzu University,Kunming650500)
Named entity translation equivalent has been playing a significant role in the processing of cross-language informa?tion.However limited by the corpora resource,few in-depth studies have been made on the extraction of the bilingual Chi?nese-Khmer named entity equivalents.Starting from the comparable corpus text,according to the type of entity characteristics and comparable corpus characteristics,the paper selects transliteration feature,translation feature,context feature of the bilingual Chi?nese-Khmer named entity equivalents and length feature.So a method based on multi-feature fusion is proposed to calculate the sim?ilarity to excavate the bilingual Chinese-Khmer named entity equivalents.The experiment shows this method has a good perfor?mance when the bilingual Chinese-Khmer named entity equivalents are acquired through the computation of feature similarity,turn?ing out that the method proposed in this paper is able to give better effect compared with the method using only a single feature.
named entity equivalents,Chinese-Khmer bilingual,multi-feature fusion,comparable corpus,transliteration model
TP391.1
10.3969/j.issn.1672-9722.2017.05.020
2016年11月10日,
2016年12月20日
國(guó)家自然科學(xué)基金“柬埔寨語命名實(shí)體識(shí)別及漢柬雙語語料庫構(gòu)建方法研究”(編號(hào):61462055);國(guó)家自然科學(xué)基金“基于篇章特征的越南語新聞事件元素抽取關(guān)鍵技術(shù)研究”(編號(hào):61562049)資助。
徐璐,男,碩士研究生,研究方向:自然語言處理。嚴(yán)馨,女,副教授,碩士生導(dǎo)師,研究方向:自然語言處理。夏青,男,碩士研究生,研究方向:自然語言處理。周楓,男,副教授,碩士生導(dǎo)師,研究方向:自然語言處理。莫源源,男,博士,講師,研究方向:自然語言處理。
猜你喜歡
數(shù)學(xué)小靈通·3-4年級(jí)(2024年2期)2024-05-15 02:02:28
中學(xué)生數(shù)理化(高中版.高考數(shù)學(xué))(2022年3期)2022-04-26 14:04:16
數(shù)學(xué)年刊A輯(中文版)(2020年1期)2020-05-19 00:30:36
空間科學(xué)學(xué)報(bào)(2020年2期)2020-04-01 03:50:40
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中等數(shù)學(xué)(2019年8期)2019-11-25 01:38:14
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
新聞傳播(2018年11期)2018-08-29 08:15:24
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
廣西科技大學(xué)學(xué)報(bào)(2016年1期)2016-06-22 13:10:38
