基于匹配點傳播的三維重建及深度估計算法
2017-06-05 12:07:08時連標
電子技術與軟件工程 2017年7期

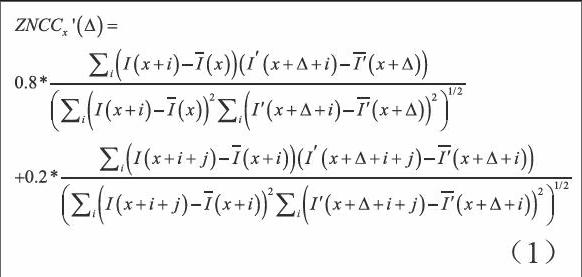
摘 要 在計算機視覺中,從兩幅或多幅圖像中重建出稠密的深度圖是一個相當重要且具有挑戰性的問題,深度信息通常作為一個有價值的信息來源,促進諸多應用領域的發展。重建稠密深度信息的關鍵之處在于找到兩幅圖像中的對應點匹配,即多視角立體匹配。本文提出的方法中,我們預先提取圖像中最初稀疏匹配點對,然后在此基礎上進行全局傳播。我們假設在圖像局部區域中,深度信息的變化是有規律的。本文中,我們運用SLIC對圖像進行分割,得到超像素塊,然后在超像素塊內對粗糙的深度圖進行細化,修復。我們的算法,在精度上要優于傳統的立體匹配算法,且適應性較強,可以應用于現實生活中拍攝得到的一組序列圖像。
【關鍵詞】立體視覺 深度匹配點傳播超像素
1 引言
在計算機視覺領域中,圖像的深度信息通常可作為一個有價值的信息,促進諸多應用領域的發展,如目標檢測、目標識別、路徑規劃以及場景復原等。而從兩幅或多幅圖像中重建稠密的深度圖是一個相當重要且具有挑戰性的問題。
重建稠密的深度圖的關鍵技術,在于如何判斷出兩幅圖像中點與點的密集對應關系,即多視角立體匹配。近幾十年來,該領域也一直被廣大學者所研究。立體匹配,在計算機視覺領域中是一個重要的問題之一。研究表明,諸多問題導致多視角立體匹配問題是一個不易解決的問題,一個問題就是場景本身的屬性導致的,例如無紋理區域、非朗博表面、反射和半透明,以及遮擋等不可避免的問題。還有其他與相機相關的問題:例如圖像噪聲、不準確的校準所產生的一系列錯誤。
近幾十年來,許多優秀的算法致力于更好地解決多視角立體匹配問題。
Scharstein和Szeliski等[1]提出了立體算法的分類和分類方案,他們將不同的立體算法分為兩大類:局部和全局算法。 在局部算法中,一個給定的圖像像素的視差計算僅取決于在一個窗口中的圖像的強度/顏色值。所有的局部算法都需要成本聚合(步驟2),通常利用成本聚合來達到隱含的平滑性假設。另一方面,全局算法提出明確的平滑性假設,然后解決一個優化問題。這樣的算法通常省略了成本聚合步驟,而是尋求一個視差解決方案(步驟3),最大限度地減少全局成本函數。流行的全局方法有動態規劃[2],置信傳播[3,4,5,6]以及圖分割[7]。與局部算法不同的是,全局算法通過估計在其他像素的視差來估計某一個像素的視差。
大多數的成本聚合方法可以被看作是成本量的聯合過濾。實際上,即使是簡單的線性圖像過濾器,如方波或高斯濾波器也可以用于成本聚合,但作為各向同性的擴散濾波器,它們往往會導致在深度邊界處出現模糊。因此一些邊界保持的濾波器,如雙邊濾波器[8]和圖像引導濾波器[9]被引入到成本聚合中。Yoon和Kweon[10]將雙邊濾波器運用到成本聚合中,在Middlebury數據集[1]上產生了奪目的視差圖,但是,他們的計算成本很高。為了解決計算問題,Rhemann等[11]提出引導濾波的使用,其計算復雜性取決于核大小。最近,Yang等[12]提出非局部成本聚合的方法,期望于核大小為整幅圖像,通過在圖上計算最小生成樹,非局部成本聚合有著非常快的表現。Mei等[13]緊跟著非局部成本聚合的思想,使用分割樹來強制視差一致性,可以得到更好的視差圖。
前人的工作大多在于預先設定可能的視差范圍,設計成本計算函數,然后對所有可能的視差計算成本函數,最后利用優化求解技術最小化匹配成本來計算最佳匹配,是一個優化類問題。
相反的,我們的工作在于依照簡單的匹配,擴展和濾波:
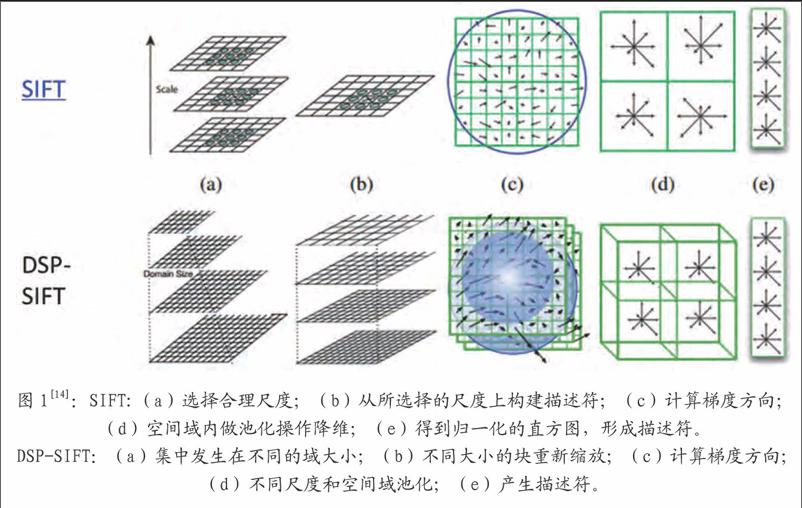
(1)匹配:通過DSP-SIFT[14]來尋找特征并在多幅圖像上匹配,在圖像顯著區域產生稀疏的匹配點對。
得到初始的匹配點對后,依照下面兩步進行:
(2)擴展:利用圖像局部關系,擴展初始匹配的點到周圍的像素來獲得一個稠密的點集。對稀疏點對進行準稠密化[15]。
(3)過濾:利用視覺一致性來去除一些錯誤的匹配點對。最后,利用立體視覺交叉投影技術有效地求解出初始深度圖,由此,得到的深度是絕對深度信息。我們在此粗糙深度圖的基礎上,在超像素塊上進行深度圖的傳播,最終獲得一個細化的深度圖。
2 準稠密化
2.1 種子點的選取和初始匹配
如圖1所示,從兩幅圖像中提取特征點,采用類似傳統的稀疏匹配算法進行匹配,得到初始的對應點對。本文中,我們采取SIFT的變形DSP-SIFT[14]來求解初始的匹配點對。SIFT特征,被設計出來為了減少由于光照和制高點引起的不同,同時保留辨別能力。有助于尋找相同的底層場景的不同視圖之間的關系。DSP-SIFT點特征,除了空間位置上,還在不同的尺度上對梯度進行池化操作,將會得到自然可靠的二維點特征。因此,它可以解決大的視差問題,且我們認為該匹配得到的點對,是相對可靠的。
2.2 傳播
我們假設,在初始匹配點對的附近區域,很大程度上會存在著新的潛在的可能的匹配點對。因此,我們認為初始匹配點對周圍的統計信息對于點的傳播將會有很大的幫助,我們考慮使用某一點的鄰域5*5窗口內的統計信息,以及使用鄰域5*5窗口內各個點為中心的鄰域統計特征。簡單地來說,我們采用的統計信息是基于某點的鄰域,以及該鄰域的鄰域進行的。當我們計算兩者的綜合信息并排序,我們有理由認為鄰域內統計得分最高的點對,是下一組可能的匹配點對。具體的標準,我們采用零均值歸一化互相關(ZNCC)的變形ZNCC來用于兩幅圖像的匹配點的傳播。它具有局部線性不變性。
其中,和是在給定的以x為中心的窗口內像素亮度的均值,同理和是在給定的以x+i以及x+△+i為中心的窗口內像素亮度的均值。之后,用交叉一致性來保證兩個圖像之間的匹配是一一對應的。交叉一致性由像素從第一幅圖像到第二幅圖像的相關性以及第二幅圖像到第一幅圖像的相關性共同構成,只有在兩個方向上都保持好的匹配,才會被保留下來。這里,因為鄰域的鄰域信息會產生的影響要弱于鄰域統計信息,因此,我們設定相應的比例以期望于更好的效果。
所有初始經過交叉檢查過的稀疏匹配點對,按相關性分數遞減排序,用作接下來傳播的種子點。每一步中,由兩個相對應像素x和x組成的匹配點對(x,x'),其中ZNCC得分最高的匹配從當前種子集合中挑選出來,然后我們在當前空間鄰域N(x,x')內搜索新的可能的匹配。本文中,我們同時使用一個平滑約束,稱為二維視差梯度約束。
2.2.1 二維視差梯度約束
通常,沿極線的一維的視差梯度約束已被廣泛用在立體匹配的修正中來消除一些歧義。但是在實際生活中,所得到的圖像對,并不是簡單的一維上的偏差,我們可以認為,兩幅圖像在水平和垂直方向上均有偏差,所以,本文中,采用了在二維空間上加以擴展的二維梯度約束,用來處理未校準的圖像對:比如有著不正確極線約束的嚴格場景或者本身就是一些不嚴格的場景下所得到的圖像對。
2.2.2 置信測度
置信測度的引入,是因為我們的傳播方法需要計算匹配點對周圍的統計信息,所以,我們期望于點對的周圍是有梯度信息存在,這樣才能使得我們的傳播有可信度,我們的算法在完全沒有紋理的區域是不能起作用的。我們這里使用一個簡單的基于差分的置信測度:
為了確保我們算法的有效性,我們約束著傳播沿著有梯度的區域進行,我們禁止在太過均勻的區域內(假設0≤I(u) ≤1,s(u) ≤t,t=0.01)中傳播。
2.2.3 匹配的傳播特性
研究發現,該匹配傳播算法有很多很好的性能如下:
(1)關于錯誤種子匹配點具有魯棒性。
稀疏匹配的全局最優策略大大提高了該算法的魯棒性和穩定性。盡管種子點選擇步驟與現在現存的一些方法相似,利用特征點的相關性做匹配。關鍵的區別在于,匹配傳播依靠極少數可靠的特征點就可以進行,并非需要提取大量的特征點。這就使得算法不容易受到種子點選擇階段時匹配異常值的存在的過多干擾。不良傳播的風險明顯減少了,有以下兩個原因:1)不好的種子匹配點,如果它們在列表中的排名不靠前,則根本就沒有機會被選出。2)盡管壞種子點中偶爾有排名靠前的情況,也會因為傳播過程中缺乏一致性被很快停止。
(2)在低紋理區域具有穩定性。
對于低紋理圖像,如典型的多面體場景。我們可以預料,匹配區域由于不良的紋理會被減少到種子點的小鄰域內,但非常有趣的是,傳播沿著梯度邊緣很好的生長,我們表明,如果透視失真是適度的情況下,那么在兩幅圖像中沿著邊緣的距離是相似的。
3 基于SLIC的整幅圖像深度估計
當我們得到兩幅圖像上對應的匹配點對之后,采用八點法計算得到本質矩陣,并利用本質矩陣和三角化原理,計算得到三維空間中的點,再利用透視投影的比例關系,得到點到圖像的距離,即圖像的深度信息。此時得到的深度信息是有空洞的,粗糙的,因此需要接下來的處理。
3.1 SLIC分割
SLIC[16]:simple linear iterative clustering的簡稱,即簡單的線性迭代聚類算法。它是2010年提出的一種思想簡單、實現也很方便的算法。基本思想:將圖像從RGB顏色空間轉換到CIE-Lab顏色空間。對應每個像素的(L , a , b)顏色值和(x , y)坐標組成一個5維向量V [L , a , b , x , y]。然后對5維特征構造距離度量標準,對圖像像素進行局部聚類的過程。SLIC算法能生成緊湊、近似均勻的超像素,在運算速度,物體輪廓保持、超像素形狀方面都有較好的表現。
具體的實現方法如下:
(1)首先生成K個種子點(K為人為設定的參數,即代表著期望于得到K個超像素),然后在每個種子點的周圍空間里搜索距離該種子點最近的若干像素,將他們歸為該種子點一類,直到所有像素點都歸類完成。
(2)然后計算K個超像素里所有像素點的平均向量值,重新得到K個聚類中心。
(3)然后再以這K個中心去搜索其周圍與其最相似的若干像素。
(4)反復迭代上述過程。
算法接受一個參數K,用于指定生成的超像素數目,設原圖有N個像素,則分割后的每一塊約有N/K個像素,每塊超像素的連長大約為S=[N/K]^1/2。開始時,每隔S個像素取一個聚類中心。然后以這個聚類中心的周圍2S*2S為其搜索空間。對于KITTI數據集中圖的分割效果如圖2。
3.2 整幅圖像深度估計
假設在一個超像素塊內,物體的深度信息是趨于一致的,因此,我們在一個超像素塊內對深度信息進一步的補全工作。
我們假設在一個超像素塊內,圖像的深度信息是趨于一致的:
具體實現:
(1)首先,我們統計每個超像素塊內非空深度的值并求取平均值。
(2)搜索每個超像素塊內的深度值為空的點,然后令其為第一步計算得到的數值。
(3)重復上述兩個步驟,直到結束。
我們利用SLIC超像素分割和深度局部光滑性約束,實現了對整幅圖像的深度估計。實驗結果來看,不僅獲得了所有位置的深度信息,同時也保證的深度信息基本可靠。
4 實驗結束與分析
4.1 算法結果
圖3為本算法處理多對測試圖像得到的SLIC分割圖和稠密視差圖,以及與SGM[17],Yamaguchi[18]等,MeshStereoExt[19]算法的比較。從上到下,分別為Adirondack、Motorcycle、Piano和Recycle,從左到右分別為,原圖、SLIC分割圖、真實值、SGM算法結果、Yamaguchi算法結果、MeshStereoExt算法結果以及本文的結果。
4.2 評價指標
為了定量地說明結果的好壞,本文給出了兩種評價標準的對比結果。
(1)均方根誤差(root-mean-squared,RMS):測量計算得到的深度值dc(x,y)與真實深度值dr(x,y)之間的均方根誤差,具體公式如下:
(2)錯誤匹配像素百分比:測量錯誤匹配點占全部像素的百分比,即匹配誤差超過可容忍的閾值的像素個數占全部像素個數的比重。
其中,δd是視差可以容忍的閾值大小,在實驗中我們令δd=10。
5 總結
我們的深度求解,是基于立體視覺和三維重建等幾何基礎上提出的方法,與傳統的方法相比,我們的深度信息,是更加準確且真實的深度信息。本文的算法,對于兩幅圖像本身的要求也沒有那么嚴格,可以是沒有對準的圖像對;我們假設深度在超像素塊內是保持局部一致性的,并利用超像素塊對深度圖進一步地恢復。通過實驗表明,我們的方法是在精度上優于傳統的立體匹配算法的,且適應性較強。但是,我們的算法在解決毫無紋理的區域塊時,會受到限制,將會產生不好的結果,這也是我們后面將要考慮解決的問題。
參考文獻
[1]Scharstein D,Szeliski R.A taxonomy and evaluation of dense two-frame stereo correspondence algorithms[J]. International journal of computer vision,2002,47(1-3):7-42.
[2]Bobick A F,Intille S S.Large occlusion stereo[J].International Journal of Computer Vision,1999,33(03):181-200.
[3]Freeman W T,Pasztor E C,Carmichael O T.Learning low-level vision[J]. International journal of computer vision,2000,40(01):25-47.
[4]Sun J,Zheng N N,Shum H Y.Stereo matching using belief propagation[J]. Pattern Analysis and Machine Intelligence,IEEE Transactions on,2003,25(07):787-800.
[5]Yang Q,Wang L,Ahuja N.A constant-space belief propagation algorithm for stereo matching[C]//Computer vision and pattern recognition (CVPR),2010 IEEE Conference on. IEEE,2010:1458-1465.
[6]Yang Q,Wang L,Yang R,et al. Stereo matching with color-weighted correlation,hierarchical belief propagation,and occlusion handling[J].Pattern Analysis and Machine Intelligence,IEEE Transactions on,2009,31(03):492-504.
[7]Boykov Y,Veksler O,Zabih R.Fast approximate energy minimization via graph cuts[J].Pattern Analysis and Machine Intelligence,IEEE Transactions on,2001,23(11):1222-1239.
[8]Tomasi C,Manduchi R.Bilateral filtering for gray and color images[C]//Computer Vision,1998. Sixth International Conference on.IEEE,1998:839-846.
[9]He K,Sun J,Tang X.Guided image filtering[M]//Computer Vision–ECCV 2010.Springer Berlin Heidelberg,2010:1-14.
[10]Yoon K J,Kweon I S.Adaptive support-weight approach for correspondence search[J].IEEE Transactions on Pattern Analysis & Machine Intelligence,2006(04):650-656.
[11]Rhemann C,Hosni A,Bleyer M,et al.Fast cost-volume filtering for visual correspondence and beyond[C]//Computer Vision and Pattern Recognition (CVPR),2011 IEEE Conference on.IEEE,2011:3017-3024.
[12]Yang Q.A non-local cost aggregation method for stereo matching[C]//Computer Vision and Pattern Recognition (CVPR),2012 IEEE Conference on.IEEE,2012:1402-1409.
[13]Mei X,Sun X,Dong W,et al.Segment-tree based cost aggregation for stereo matching[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.2013:313-320.
[14]J.Dong and S.Soatto.Domain-Size Pooling in Local Descriptors:DSP-SIFT. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR),2015.
[15]Lhuillier M,Quan L.Match propagation for image-based modeling and rendering[J].Pattern Analysis and Machine Intelligence,IEEE Transactions on,2002,24(08):1140-1146.
[16]Achanta R, Shaji A,Smith K,et al.SLIC superpixels compared to state-of-the-art superpixel methods[J].IEEE transactions on pattern analysis and machine intelligence,2012,34(11):2274-2282.
[17]Hirschmüller H.Stereo processing by semiglobal matching and mutual information[J].Pattern Analysis and Machine Intelligence,IEEE Transactions on,2008,30(02):328-341.
[18]Yamaguchi K,McAllester D,Urtasun R.Efficient joint segmentation, occlusion labeling,stereo and flow estimation[M]//Computer Vision–ECCV 2014.Springer International Publishing,2014:756-771.
[19]Zhang C,Li Z,Cheng Y,et al. Meshstereo:A global stereo model with mesh alignment regularization for view interpolation[C]//Proceedings of the IEEE International Conference on Computer Vision.2015:2057-2065.
作者簡介
時連標(1990-),男,安徽省蚌埠市人。在讀碩士。主要研究方向為計算機視頻三維重建、目標識別。
作者單位
合肥工業大學屯溪路校區 安徽省合肥市 230009
猜你喜歡
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年6期)2019-01-08 02:43:04
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
中華手工(2017年2期)2017-06-06 23:00:31
新聞傳播(2015年10期)2015-07-18 11:05:40
中外會展(2014年4期)2014-11-27 07:46:46
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
