語譜圖二次傅里葉變換特定人二字漢語詞匯識別
2017-06-13 10:43:55梁士利李廣巖許廷發王雙維
東北師大學報(自然科學版) 2017年2期
關鍵詞:詞匯
潘 迪,梁士利,魏 瑩,李廣巖,許廷發,王雙維
(1.東北師范大學物理學院,吉林 長春 130024;2.北京理工大學光電成像與信息工程研究所,北京 100081)
語譜圖二次傅里葉變換特定人二字漢語詞匯識別
潘 迪1,梁士利1,魏 瑩1,李廣巖1,許廷發2,王雙維1
(1.東北師范大學物理學院,吉林 長春 130024;2.北京理工大學光電成像與信息工程研究所,北京 100081)
以語音信號的語譜圖作為處理對象,提出了基于語譜圖二次傅里葉變換對特定人二字詞匯識別的方法.首先對語譜圖二次傅里葉變換頻域圖的圖像意義以及相應的語音特性表征進行了詳細剖析;然后對語譜圖頻域圖像進行二進寬度行投影,將投影值作為語音識別特征值,以支持向量機為分類器,進行特定人二字詞匯語音整體識別.采用1 000個語音樣本進行了仿真實驗.結果表明,該方法正確識別率可達到92.4%,為漢語詞匯整體識別提供了新的思路.
語譜圖;二次傅里葉變換;支持向量機;二進寬度行投影
0 引言
無論語音識別還是語音增強,常規語音處理技術通常基于語音信號屬于非平穩隨機過程這一特性,以10~30 ms的短時語音幀為基本單位進行處理.但這種分割方法破壞了音節承載信息的整體性,在一定程度上影響了語音處理的效果.
相比英語等其他語言,漢語音節信息最強的部分在前面和中間,結尾部分往往只是信息很弱且時間較長的拖尾音.漢語的信息為聲母、韻母及聲調的整體表現,對漢語進行處理時極易使語音信息丟失.因此,對于漢語語音處理而言,尋找能夠體現漢語語音整體化特征的處理方法顯得尤為重要.
語譜圖作為語音分析和語音學的有利工具,它將密切相關的時域與頻域特征及其相互關系同時展現出來.所以,語譜圖更加有利于表征語音信號的整體性.隨著圖像處理技術的發展,人們已將語譜圖本身作為研究對象,利用圖像處理技術提取語音識別的參數實現語音識別,并取得了一定效果.
20世紀70年代,文獻[1]做了若干關于語譜圖閱讀的實驗來嘗試用語譜圖進行語音識別;文獻[2]嘗試通過可視語譜圖檢驗和機器幫助下的詞匯搜索對一組未知句子進行識別,都取得了一定的成果;80年代末和90年代初,人們開始不直接使用語譜圖,而是從語譜圖中提取特征或使用處理過的語譜圖;[3-7]新世紀以來,文獻[8]提出一種新穎的基于譜模型適應算法的語譜圖,并用于說話人識別.
1995年,潘凌云等人[9]將語譜圖應用到語音識別中的語音音素分割中;2005年,馬義德等人[10]把PCNN引入到說話人識別中;2006年,陳向民等人[11]將語譜圖應用到語音端點檢測算法中;2011年,姜洪臣等人[12]提出了一種基于音頻語譜圖像識別的廣告檢索方法;2014年,吳迪等人[13]對增強后語音的時頻語譜進行二維增強,提出PSSB參數,并用于端點檢測;我們依據語譜圖紋理方位的數學形態學特征進行了漢語韻母聲調識別研究[14].
以往基于語譜圖的語音識別僅在語譜圖本身的空域結構中直接尋找特征,并沒有充分利用語譜圖作為可視化圖像的性質.考慮到語譜圖表征語音特性體現在紋絡結構上,而圖像紋絡結構更容易由圖像的頻域描述.因此,本文對語譜圖進行二次傅里葉變換,將其圖像空域轉換至圖像頻域,并對語譜圖圖像頻域進行二進寬度分帶投影,借助于支持向量機實現特定人二字詞匯的識別.仿真實驗表明,選取對語譜圖進行圖像二次傅里葉變換之后的二進寬度分帶投影值作為語音識別特征量,對特定人二字詞匯語音的識別率可達到92.4%,為解決漢語詞匯整體語音識別提供了一種新的思路.
1 語譜圖二次傅里葉變換的意義
語譜圖(Spectrogram)[15]是表示語音頻譜隨時間變化的圖形,它采用二維平面來表達三維信息,任一給定頻率成分在給定時刻的強弱用相應點的灰度或色調的濃淡來表示.語譜圖中顯示了大量的與語音的特性有關的信息,它綜合了頻譜圖和時域波形的特性,顯示出語音頻譜隨時間的變化情況.所以,語譜圖所承載的信息量遠遠大于單純時域和單純頻域承載信息量的總和.
眾所周知,窄帶語譜圖有較高的頻率分辨率,在譜圖上能顯示出2個純音,但其時間分辨率較差,看不出2個純音所產生的拍音.[16]因此,作為詞匯的窄帶語譜圖,可以反映詞匯整體的基頻及各次諧波的時間變化.窄帶語譜圖中基頻及各次諧波體現為等間隔的橫杠,從圖像角度看,這些等間隔的橫杠反映了圖像豎直方向上的周期特征.如果將語譜圖進行傅里葉變換,即由語譜圖的空域轉換到語譜圖的頻域,則上述橫杠的周期性表現為語譜圖頻域豎直方向上的基頻.
為了彰顯上述特性,我們給出漢語單韻母“a”的語譜圖(帶寬43 Hz)見圖1.為了突出重點,圖1只顯示4 kHz以下部分.由圖1可以看出,當持續發“a”時,基頻與各次諧波對應的橫杠基本保持不變,而波動性反映發音時的聲音脈動.圖1的傅里葉變換圖(全頻域變換)見圖2,亦即語譜圖的頻域圖,圖2中心代表0頻率,向左右和上下指向高頻.語譜圖是非負的實數矩陣,所以,其傅里葉變換滿足共軛對稱性,我們只針對上半幅頻域圖進行解讀.由于是單韻母“a”的持續發音,其基頻與各次諧波的相對關系保持不變,體現在頻域圖上,即是圖像的各頻率成分集中在坐標軸上.
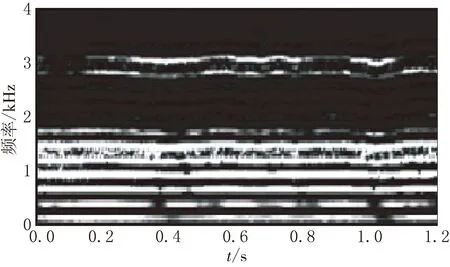
圖1 漢語單韻母“a”的窄帶語譜
語譜圖頻域圖像中心亮斑(可稱為0號亮斑)是語譜圖水平和豎直方向的0頻率分量,這是圖像傅里葉變換的特有標志,因為圖像矩陣為非負實陣,數據沒有過零點,因此任何圖像都包含“直流”成分,也正因為如此,圖像頻域的“直流”成分即中心亮斑不包含有用信息.
語譜圖頻域圖豎直方向1號亮斑的位置,反映了語音基頻及各次諧波間隔的大小,位置越高,說明基頻及各次諧波頻率間隔越小.2號及其以后的高頻亮斑反映語譜圖橫杠斷面邊緣特征,即邊緣梯度特征,高頻亮斑越少,邊緣下降越緩慢,反之亦然.從語音角度,高頻亮斑對應著語音頻譜的精細結構,這一精細結構除含有語音信息外,是否含有說話人的聲紋信息,值得進一步研究.
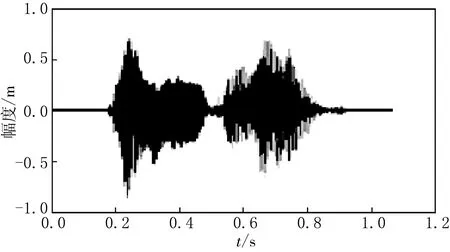
圖3 詞匯“中國”的時域波形
與豎直方向類似,水平方向1號亮斑反映語音脈動的基本周期,高頻亮斑反映語音脈動過程的速率.由于圖1是窄帶語譜圖,時間分辨率不高,因此不能顯示語音“a”發音脈動的細節過程.
某發音人詞匯內容為“中國”的時域波形圖見圖3.相應的窄帶語譜圖(帶寬43 Hz)見圖4,為了突出重點,圖4只顯示4 kHz以下部分.語譜圖傅里葉變換的頻域圖像(全頻域變換)見圖5.

圖4 詞匯“中國”的窄帶語譜

圖5 詞匯“中國”語譜圖二次傅里葉變換后的頻域
由圖5看出,“中國”語譜圖二次傅里葉變換所形成的頻域圖像,其成分不再局限于坐標軸上,這是因為詞匯發音屬于非平穩過程,語音基頻及其諧波的時域變化導致語譜圖紋理周期性在任意方向都有體現.同時也說明,語譜圖有信息價值的部分是較粗的紋理成分.
2 語譜圖頻域圖像矩陣的特征提取
2.1 語譜圖樣本構成
用Cool Edit Pro 2.0軟件進行語音錄制,采樣頻率為44.1 kHz,使得語譜圖頻域表達范圍為0~22 kHz,單聲道,16 B進行量化.采集10人(男、女各5人)的10個詞匯的讀音樣本,10個詞匯均為二字詞匯,重復10遍,即每個詞匯有10個樣本.一個詞匯的語音時長約為1.2 s,10人的10個詞匯共1 000個語音樣本文件.所有語音樣本文件轉化為Matlab數據文件,即語音樣本序列.
對每個樣本序列進行分幀,幀長為1 024點,為保持其連續性,采用重疊率為25%的幀移量,窗函數采用漢明窗(Hamming),漢明窗公式為[17]
每個樣本分為54幀,構造出1 024行54列時域分幀矩陣.對時域分幀矩陣做FFT,生成1 024行54列時頻分析矩陣,頻域分辨率為43Hz.時頻分析矩陣的模矩陣即為樣本所對應的語譜圖矩陣.由于傅里葉變換具有對稱性,取該矩陣的上半部或下半部作為語譜圖即可,因此,每一幅語譜圖的矩陣為512行54列,共1 000幅灰度圖像.以上過程本文形成了參數可調的Matlab語譜圖生成程序,以備隨時調用.
為了消除由于音量不同造成的各個樣本幅度差異,對每個圖像矩陣均進行歸一化處理.
2.2 語譜圖特征提取
2.2.1 語譜圖二進寬度分帶行投影
語譜圖矩陣的每一行代表著某一頻率通道幅度特性隨時間的變化,行投影則反映了某頻率通道在整個語音時長過程中的總體特征.如果簡單的對語譜圖矩陣進行行投影,這種頻域上過于細化的投影方式,不僅對語音識別沒有益處,反而會降低識別系統的容錯能力.而且從語譜圖灰度圖像中也發現大量信息集中分布在圖像的中下部分,這一點符合人類語言信息主要分布在低頻段的特征.為了便于特定人的二字詞匯的語音識別更加準確,同時又能將灰度圖像的中下部分的信息更清楚地顯示出來,我們采取了二進寬度分帶方法,從第1行開始二進分,即將每個語譜圖矩陣的1~256行(帶寬256行)、257~384行(帶寬128行)、385~448行(帶寬64行)、449~480行(帶寬32行)、481~496行(帶寬16行)、497~504行(帶寬8行)、505~512行(帶寬8行)分為7個帶,最后8行不再分帶,因為最后一個帶的頻率范圍在0~200Hz之間,而人類所能聽到的頻率在100Hz以上,所以最后8行相當于只有4行是有效的,因此不用將8行再分.將這7個帶進行行投影,構造每個詞匯的7行10列二進寬度分帶投影矩陣.通過對10個詞匯之間對應帶投影矩陣值的各個行求平均值和方差,并對不同詞匯語譜圖矩陣對應帶投影值進行U檢驗,發現第3行到第7行5個帶投影值有顯著性差異,可以作為特征數據集合.
2.2.2 語譜圖二次傅里葉變換后的二進寬度分帶行投影
語譜圖圖像中像素的灰度值代表了信號在相應頻率、相應時刻的幅度比重.基于圖像處理思路,對其進行頻譜分析,將語譜圖圖像進行再次傅里葉變換,形成512行54列語譜圖圖像頻域特性矩陣,并將頻譜低頻部分移到中心處.我們采用了二進寬度分帶投影方法,考慮到語譜圖中顯示語音特性的條紋主體,從圖像角度看屬于低頻成分,而較低的頻率被移到中心位置處,所以采用從中心向上由細到寬進行二進倍增寬度分帶投影的方法.又因為圖像矩陣為實的非負矩陣,所以二次傅里葉變換的頻域矩陣滿足共軛對稱性,分析其幅頻特性,發現圖像的頻域矩陣既不滿足左右對稱,也不滿足上下對稱.因此,應用圖像二次傅里葉變換所對應的頻域矩陣進行數據處理或分析時,不能只使用1個象限,要同時使用相鄰的2個象限.但也發現圖像的頻域矩陣是轉置對稱矩陣,可完全描述圖像幅頻特征的獨立子陣是上半子陣,或下半子陣,或左半子陣,或右半子陣.選擇上半子陣進行二進寬度分帶行投影,這種投影反映了詞匯發音全過程中語音基頻及其諧波關系的總體特性,同時還反映了語譜圖條紋邊緣梯度的整體特性.實驗表明,不同詞匯其相應的上述總體特性具有顯著性差異.
因為上半子陣的左半部分和右半部分并不對稱,所以分別對上半子陣的左半部分和右半部分進行分帶投影.首先將圖像的中心設置為坐標(0,0),然后對上半子陣的左半部分和右半部分分別二進倍增分帶投影,行數分別設置為128~255行(帶寬128行)、64~127行(帶寬64行)、32~63行(帶寬32行)、16~31行(帶寬16行)、8~15行(帶寬8行)、4~7行(帶寬4行)、0~3行(帶寬4行),分為7對計14個帶的投影值,形成14行列向量,作為語音識別的特征向量.又由于每個詞匯重復10遍,因此可以構造每個詞匯14行10列二進寬度分帶投影矩陣.最后,通過對10個詞匯之間對應帶投影值U檢驗,發現采用上半子陣的左右部分二進寬度分帶投影作為特征量對特定人二字詞匯的識別有顯著性差異,可以作為特征數據集合.由于每個人詞匯重復10遍,每遍有14個特征值構成的向量,共得到140個U檢驗結果,給出樣本右側第一帶投影值間的U檢驗結果,如表1所示.
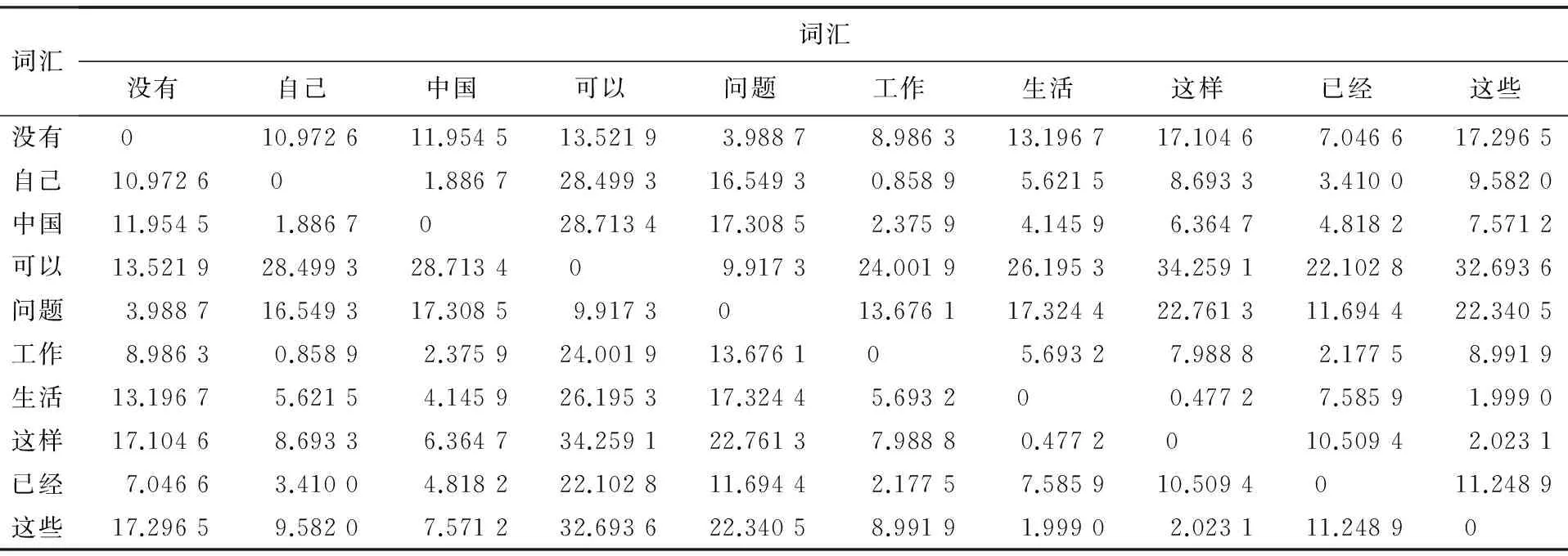
表1 樣本右側第一帶投影值間的U值檢驗結果
為了清楚地觀察到數據之間的識別差異,故在此規定當U≥1.96時,設定值為1,說明可以作為識別詞匯的特征量,當U<1.96時,設定值為0,說明不能作為識別詞匯的特征量,如表2所示.
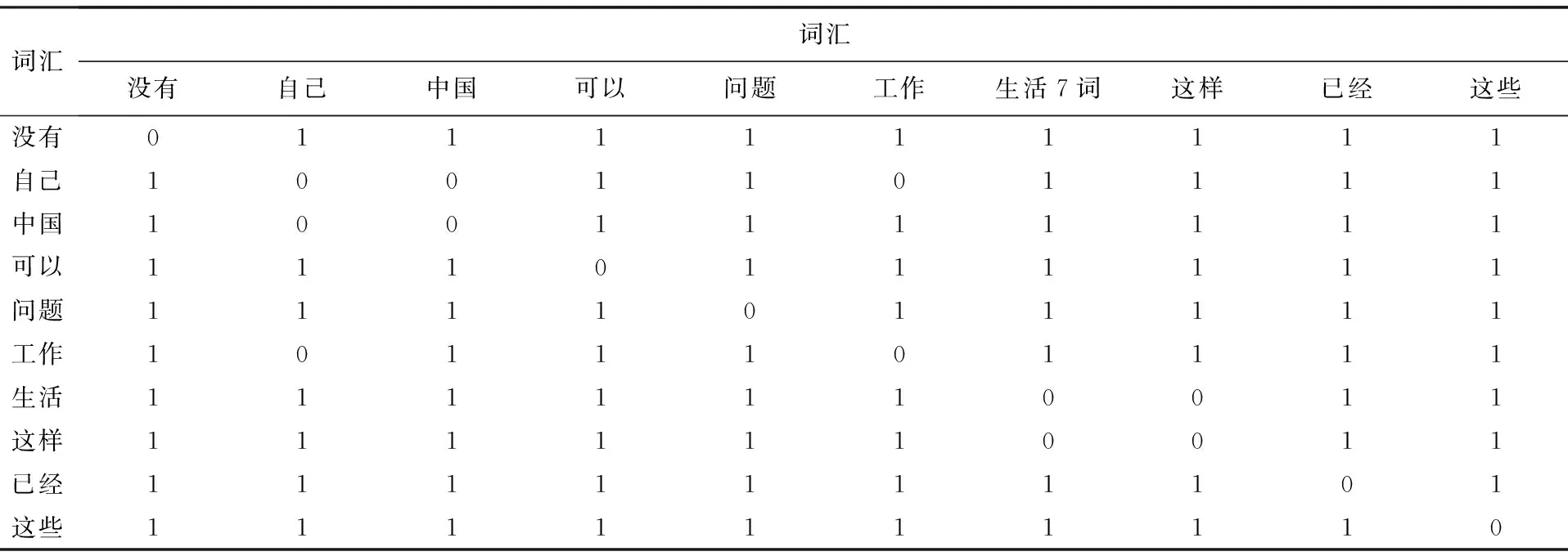
表2 可作為識別詞匯特征量的結果
表2中數據表明,樣本右側第一帶投影值能夠作為識別詞匯特征量的比例為93.33%.由于篇幅所限,其他結果不再詳述.
3 實驗仿真與結果分析
3.1 系統設置
本次語音樣本采用10人對10個二字詞匯進行錄制而成,采樣頻率為44.1 kHz,單聲道,16 B進行量化,其中每個詞匯10段重復錄音,一共是1 000個語音數據樣本,為了采樣數據更加準確,將每人的10個二字詞匯的每前5遍作為訓練集,后5遍作為測試集,即前500個語音數據作為訓練集,后500個語音數據作為測試集.在訓練階段,為了后面的數據處理的方便和保證程序運行時收斂加快,防止出現奇異樣本數據(指的是相對于其他輸入樣本特別大或特別小的樣本矢量)而進行了歸一化處理.首先對特定人的各個特征量的語音樣本進行歸一化的預處理,使所有數據得到相應統一,然后將前500個語音訓練樣本特征數據存入數據庫,作為支持向量機的訓練模板,對其進行訓練.在檢測階段,將后500個語音樣本中提取出的特征數據放入到訓練好的網絡中,對相應的特定人的二字詞匯進行語音檢測.
3.2 仿真結果
對語譜圖矩陣進行二進寬度行投影之后,構造每個詞匯5行10列矩陣.同時對語譜圖矩陣進行二次傅里葉變換之后,分別構造每個詞匯的上半子陣的左半部分和右半部分各7行10列二進寬度分帶投影矩陣.將上半子陣的左半部分小矩陣和上半子陣的右半部分小矩陣合在一起形成一個14行10列的大矩陣.1人的10個詞匯10遍得到10組數據,10人即可得到100組數據,分別相應地將每人的10個詞匯前5遍作為訓練樣本數據,后5遍作為檢測樣本數據.
支持向量機的參數:采用LIBSVM支持向量機的一個軟件包實現10人的10個詞匯的語音識別,由于基于語譜圖特定人二字詞匯漢語識別特征向量的維數是5維,因此輸入維度是5維,中間層內積核函數維度是5維,同時由于基于語譜圖二次傅里葉變換特定人二字詞匯漢語識別特征向量的維數是14維,因此輸入維度是14維,中間層內積核函數維度是14維.本文是對10人的10個詞匯的語音進行識別,采用基數詞第1到第10的編碼方式,即1維10進制輸出.
將基于語譜圖與基于語譜圖二次傅里葉變換得到的特征量用于特定人二字漢語識別的結果進行對比,如表3所示.通過前50組數據對支持向量機進行反復訓練,得到最佳適用模板,將后50組數據放入訓練好的模板中,使用基于語譜圖對特定人的二字漢語詞匯的語音識別正確率達到85.2%.,而基于語譜圖二次傅里葉變換對特定人的二字漢語的語音識別正確率達到92.4%.

表3 用于特定人二字漢語詞匯識別的特征量仿真結果對比 %
4 結論
本文提出了基于語譜圖二次傅里葉變換對特定人二字詞匯識別的方法.對語譜圖頻域圖像進行行二進寬度分帶投影,將投影值作為語音識別特征值,以支持向量機為分類器,進行特定人二字詞匯語音識別.實驗結果表明,該方法正確識別率可達92.4%.這是因為語譜圖頻域圖像的各行反映的恰是語音整體基頻與各次諧波的關系,同時高頻成分還反映了語譜圖橫向條紋邊緣梯度性質,這一性質是語音頻率特征的精細結構,也許正是這些精細結構,可以更加精確識別特定人不同的語音.當然,這一結論有待于進一步研究確認.總之,本文方法為漢語詞匯整體識別提供了新的思路.
由于本文僅以窄帶語譜圖作為研究對象,語音的時間特征沒有得到深入體現,所以,后續工作將考慮引入寬帶語譜圖,并細化研究語譜圖構造時參數選擇以及語譜圖頻域圖像特征量提取方式等因素對語音識別的影響,以便尋求最優方案,進一步提高語音識別效果.
[1] ZUE VICTOR W,LAMEL LORI F.Expert spectrogram a knowledge-based approach to speech recognition[C]//IEEE-IECEJ-ASJ International Conference on Acoustics,Speech,and Signal Processing,Jpn:IEEE,1986:1197-1200.
[2] KLATT D H,STEVENS K N.On the automatic recognition of continuous speech implications from a spectrogram-reading experiment[J].IEEE Transactions on Audio and Electroacoustics,1973,21(3):210-217.
[3] PALAKAL,MATHEW J,ZORAN,et al.Feature extraction from speech spectrograms using multi-layered network models[C]//IEEE International Workshop on Tools for Artificial Intelligence:Architectures,Languages and Algorithms,USA:IEEE Piscataway NJ,1989:1197-1200.
[4] BEN PINKOWSKI.Principal component analysis of speech spectrogram images[J].Pattern Recognition,1997,30(5):777-787.
[5] BRIAN E D KINGSBURY,NELSON MORGAN,STEVEN GREENBERG.Robust speech recognition using the modulation spectrogram[J].Speech Communication,1998,25(1/2/3):117-132.
[6] PAWAN K AJMERA,DATTATRAY V JADHAV,RAGHUNATH S HOLAMBE.Text-independent speaker identification using Radon and discrete cosine transforms based features from speech spectrogram[J].Pattern Recognition,2011,44(10/11):2749-2759.
[7] TAI-SHIH CHI,CHUNG CHIEN HAU.Multiband analysis and synthesis of spectro-temporal modulations of fourier spectrogram[J].The Journal of the Acoustical Society of America,2011,129(5):190-196.
[8] GURBUZ SABRI,GOWDYJOHN N,TUFEKCI ZEKERIYA.Speech spectrogram based model adaptation for speaker identification[C]//IEEE Southeastcon,United:IEEE Piscataway NJ,2000:110-115.
[9] 潘凌云,孫達傳,吳美朝.語音識別中基于語譜圖的語音音素分割方法[J].杭州大學學報(自然科學版),1995,22(1):42-46.
[10] 馬義德,袁敏,齊春亮,等.基于PCNN的語譜圖特征提取在說話人識別中的應用[J].計算機工程與應用,2005(20):81-84.
[11] 陳向民,張軍,韋崗.基于語譜圖的語音端點檢測算法[J].電聲技術,2006(4):46-49.
[12] 姜洪臣,任曉磊,趙耀宏,等.基于音頻語譜圖像識別的廣告檢索[J].清華大學學報(自然科學版),2011,51(9):1249-1252.
[13] 吳迪,趙鶴鳴,陶智,等.低信噪比下采用感知語譜結構邊界參數的語音端點檢測算法[J].聲學學報,2014,39(3):392-399.
[14] XU SHEN,LIANG SHI LI,WANG SHUANG WEI,et al.A mathematical morophological processing of spectrograms for the tone of chinese vowels recognition[C]//Applied Mechanics and Materials,Shanghai:Trans Tech,2014:665-671.
[15] 趙力.語音信號處理 [M].北京:機械工業出版社,2009:128-129.
[16] 張家騄.漢語人機語音通信基礎[M].上海:上海科技出版社,2010:328-331.
[17] 蔡蓮紅,黃德智,蔡銳.現代語音技術基礎與應用[M].北京:清華大學出版社,2003:24-25.
(責任編輯:石紹慶)
Recognition of specific two-word Chinese vocabulary by applying Fourier transform twice to the spectrogram
PAN Di1,LIANG Shi-li1,WEI Ying1,LI Guang-yan,XU Ting-fa2,WANG Shuang-wei1
(1.School of Physics,Northeast Normal University,Changchun 130024,China;2.Institute of Photoelectric Imaging and Information Engineering,Beijing Institute of Technology,Beijing 100081,China)
This paper illustrates a method to recognize specific two-word Chinese vocabulary by analyzing speech signals using a spectrogram after Fourier transform is applied to it twice.First,we analyze the spectrogram in the frequency domain and its corresponding voice characteristics in detail after applying Fourier transform twice.Then,binary width zoning projection is carried out in the frequency domain.The projection value is treated as the characteristic value of semantic recognition feature and the support vector machine(SVM)is considered as the classifier for recognizing the semantics of specific two-word Chinese vocabulary.A total of 1000 voice samples were used in the simulation.The results using this method show a remarkable recognition rate of 92.4%.The proposed method provides a new way for vocabulary recognition.
spectrogram;fourier transform twice;support vector machine(SVM);binary width zoning projection
1000-1832(2017)02-0095-06
10.16163/j.cnki.22-1123/n.2017.02.018
2016-06-14
國家自然科學基金資助項目(61471111).
潘迪(1991—),女,碩士研究生;通訊作者:王雙維(1957—),男,教授,主要從事噪聲、聲音與振動信號處理研究.
TN 7 [學科代碼] 510·40
A
猜你喜歡
國際醫藥衛生導報(2021年12期)2021-07-06 12:35:40
國際醫藥衛生導報(2021年12期)2021-07-06 12:35:36
中華胰腺病雜志(2021年1期)2021-02-26 11:28:36
山東醫藥(2020年34期)2020-12-09 01:22:24
中華胰腺病雜志(2019年4期)2019-08-29 08:52:20
山東醫藥(2017年35期)2017-10-10 02:45:28
山東醫藥(2017年33期)2017-10-09 12:31:41
文理導航·趣味課堂(2016年3期)2016-04-26 15:42:10
山東醫藥(2014年48期)2014-12-02 04:34:34
山東醫藥(2014年34期)2014-12-02 04:33:52
