基于Map Reduce的云數據挖掘模型的設計與實現
2017-06-15 14:15:08◆謝光
網絡安全技術與應用 2017年6期
◆謝 光
?
基于Map Reduce的云數據挖掘模型的設計與實現
◆謝 光
(三亞學院 海南 572000)
當今社會隨著計算機技術的高速的發(fā)展,涌現出大量的數據,促使了云數據逐漸成為時代潮流。數據挖掘技術則正是從這些大量的數據中提取對我們有價值的的數據。數據挖掘又叫做數據采礦、數據資料探勘等,是當今數據快速發(fā)展的產物。大數據的出現對傳統(tǒng)的簡單的數據挖掘算法提出挑戰(zhàn),新型的基于Map Reduce的云數據挖掘正在茁壯地發(fā)展。Map Reduce是當前最流行的分布式計算模型,在云數據數據挖掘當中作為一個佼佼者迅速發(fā)展。本文主要研究傳統(tǒng)的數據挖掘算法如何與Map Reduce計算模型有效地在云數據中結合起來。給當今云數據挖掘模型做出了較好的闡述。
云數據;數據挖掘;分布儲存系統(tǒng);Map Reduce
0 引言
Map Reduce計算模型[1]是目前數據挖掘處理中最流行的一種云計算環(huán)境下的分布式計算模型[2-3],它可以將所有的數據處理均勻地分布在不同的計算機上,并且可以同時屏蔽復雜的并行編程,將所有處理的編程處理歸結到兩個簡單的函數,這兩個函數就是map函數和reduce函數[4],這兩個函數有著可用性、高可擴展性、高容錯性及簡單性使得其數據挖掘工作變得更加容易、更加簡便。為了使得Map Reduce模型適用于數據量更大的數據挖掘,本文對數據挖掘原有的算法進行了改進,提出了基于Map Reduce的K-means算法模型,對K-means算法模型進行Map Reduce化。
1 數據挖掘
數據挖掘(Data Mining),是處理大量數據庫的一種軟件。主要職責就是從大量數據中獲取有效的、新穎的、潛在有用的、最終可理解的模式的非平凡數據發(fā)現過程。簡單的說,數據挖掘就是從大量數據中提取或“挖掘”數據中有用的信息[5]。
Map Reduce最先是由Google公司設計出來的,并且一貫成為Google公司的核心計算模型,它也是一種程序模型,將復雜的運行于大規(guī)模集群上的并行計算過程高度的抽象到了map函數和reduce函數這兩個函數[6],主要用于數據集大于1TB的并行運算,現如今也大量的應用在云數據的數據處理上。Map函數接受一組數據并將其轉換為一個鍵/值對列表,輸入域中的每個元素對應一個鍵/值對。Reduce函數接受Map函數生成的列表,然后根據它們的鍵(為每個鍵生成一個鍵/值對)縮小鍵/值對列表[7]。根據這一性質可以得到Map Reduce的流程概念圖如圖1所示。
根據MapReduce的核心思想得出MapReduce模型[8]的主要流程圖如圖1所示,對流程圖進行分析并且進一步總結可以得出Map Reduce還有幾個比較重要的特點,主要在數據分布儲存、分布式并行計算、本地計算三個方面有著突出的表現:
(1)數據分布存儲:Map Reduce模型由Google公司采用GFS的底層文件系統(tǒng)支撐。GFS主要是從不同的計算機當中獲取的數據集群。然后很自然的將數據分布存儲在GFS上,其實是存儲在GFS的集群中各自的機器的本地磁盤中。
(2)分布式并行計算:Map Reduce其實質上是一種分布式的并行計算,但是其實際操作的是一個map和reduce函數,這兩個函數對于各個數據分片,都會有一個Map任務(運行Mapper類的進程)對該分片進行處理,這種處理傳承了良好的并行的方式。但是對同一個分片,Map Reduce的Map任務對該分片的
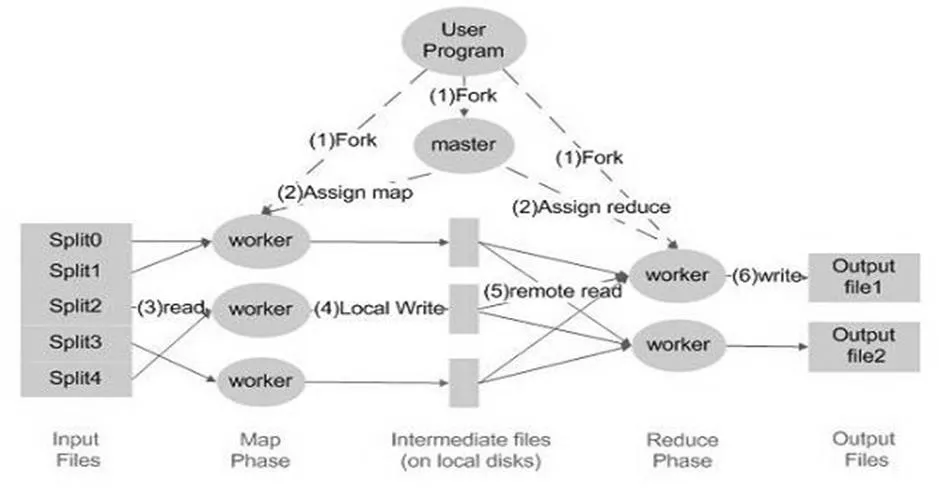
圖1 Map Reduce模型主要流程
(3)本地計算:由于分布式系統(tǒng)中網絡I/O的性能通常要比本地I/O的性能差,所以Map Reduce認為“移動計算比移動數據更經濟”,即通過將計算任務派送到數據所在節(jié)點來實現本地計算。
2 基于Map Reduce云數據數據挖掘系統(tǒng)的設計與實現
2.1Map Reduce架構
在云數據數據挖掘中,Map Reduce 同樣可以采用 Master/Slave 主從結構,根據Map Reduce的核心思想可以設計得到Map Reduce 架構主要包括Client、Job Tracker、Task Tracker 和 Task這四個組件。
2.2基于Map Reduce的數據挖掘
Map Reduce 是一種非常適合處理數據量很大,并且計算過程簡單的并行計算框架,將Map Reduce 應用于數據挖掘領域是應對大數據挖掘難題的一種需求,是當今社會云數據出現后解決數據問題最簡單的一個方式。2006年,在 NIPS 國際會議上提出一種稱為“求和范式”條件,這種條件很明確的指出:一個數據挖掘算法能用 Map Reduce的基本要求。[9]

圖2基于Map Reduce的云數據數據挖掘模型
3 K-means算法
K-Means算法是以K為參數,把數據集內的N個數據元組分為K個子集,以使得子集內的所有數據元組具有較高的相似度,且子集之問的數據元組的相似度較低。而相似度則是根據子集內對象的平均值來進行計算的[9]。K-Means算法的基本過程為:首先在全體數據集內任意選取K個數據元組作為初始的聚類中心,數據集內剩下的其他數據元組,則計算其與聚類中心的相似度(根據需要事先確定的某種歐氏兒何距離),依次將它們分別劃歸到與之最為相似(聚類中心的代表元組)的一個聚類中,再重新計算每個歸并之后獲得了新數據元組的新的聚類中心(新聚類所有數據元組的均值);并重復上述過程直到預先指派的某個測度函數(一般是均方差函數)收斂到某個闌值為止[10]。
3.1K-means算法聚類分析距離D的計算方法[11]
K-means算法的優(yōu)點是原理簡單,算法過程中的大部分計算來自于數據與聚類中心的距離計算與新的聚類中心的迭代過程。通常算法中的距離計算都是基于向量的。根據所選K-means算法的核心意義不同可以有以下四種不同的計算方法:
(1)余弦距離
兩個向量之間的夾角的余弦值即為余弦距離,余弦距離與兩個向量之間的夾角成反比關系。兩個n維向量的余弦距離如下公式1所示。

(2)歐幾里得距離
歐式距離是測量的是n維空間中每個點之間的絕對距離。歐幾里得距離計算公式2如下所示。

(3)曼哈頓距離
曼哈頓距離主要是兩個點在標準坐標軸上的絕對軸距總和,曼哈頓名字主要是從網格狀的城市區(qū)建筑塊得來,在知道每個維度距離的同時,我們可以使用曼哈頓距離計算得到。兩個n維向量的曼哈頓距離如下公式3所示。

(4)Tanimoto距離
余弦距離沒有計算到向量的權值,需要反映向量之間的角度就要使用Tanimoto距離。Tanimoto距離同時又叫Jaccard距離,角度和點之間的相對距離是我們通過Tanimoto距離所要得到多少數據。兩個n維向量的Tanimoto距離如下所示。
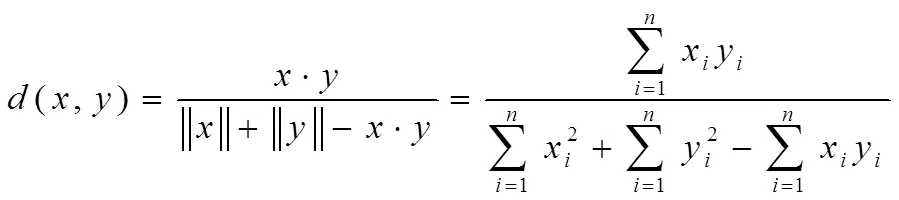
3.2 K-Means算法的Map/Reduce化
基于經典K-Means算法,探討其云計算化中Map/Reduce化后K-Means算法的方案并進一步研究云計算化后的算法性能是本次研究的關鍵[12-13]。 Map/Reduce化后K-Means算法的執(zhí)行步驟如下:
(1)隨機選擇k個初始聚類中心,如cp[0]=D[0],cp[k-1]=D[k-1],然后將這些聚類中心中的初始聚類數據復制到OriginalCluster[]中,并將OriginalCluster[]進行分塊處理,根據計算節(jié)點集群的情況,將OriginalCluster[]塊分配給各個計算節(jié)點;
(2)Map:對于D[0]…D[n]這些數據中,需要分別計算出cp[0]…cp[n-1]之間的距離,距離最近者記為c[i], c[i]的總個數可以用Ci表示,同時在Map/Reduce框架下,把鍵值分別對應到i、D[k]上;
(3)Reduce:由于i是Map/Reduce框架中鍵值對的Key,這保證了同一個Key的所有D [k]會分配到同一個Reduce進程,則在此Reduce進程可以計算新的聚類中心cp[i]=(Ec[i]對應的D[J])/Ci,并將此新的聚類中心存入DestinationCluster[];
(4)比較DestinationCluster[]與OriginalCluster[]這兩個處理方式之間的變化,如果兩者的變化小于預先給定值,則聚類完成,否則將DestinationCluster[]復制到OriginalCluster[]后繼續(xù)重復上訴過程執(zhí)行。
可以看出,K-Means算法的Map/Reduce化算法的改進之處,這是因為Map/Reduce框架是一致不變的,開發(fā)人員所要做的工作只是將算法可供Map和Reduce的部分剝離出來,構造鍵值對,其他調度、監(jiān)控、通訊等任務就全部交由Map/Reduce框架去完成了。
4 實驗仿真與分析
論文研究的是K-Means數據挖掘算法MapReduce化的可行性及過程,通過對實驗形式論證其可行性。云計算是為海量數據的分析及處理而準備的,因此實驗數據應具備如下特點:(1)海量的數據。只有數據規(guī)模達到一定的量才能達到本次實驗的目的;(2)所選的數據集中所有的數據其屬性、狀態(tài)符、都應該符合K-means數據挖掘算法的Map Reduce化的要求。依次測試Map/Reduce化后挖掘算法的實際工作能力。
本文選取QQ音樂上某電臺的一個媒體庫作為實驗數據集,數據集內包含音樂、歌曲、片頭、片花、廣告、音效、混合媒體包等媒體文件共110萬條數據記錄,同時包含電臺聽眾點播記錄600萬條,網絡互動消息記錄2000萬條[14-15]。
4.1實驗結果分析
第一組實驗使用的是數據集中網絡互動消息記錄中提取出來的1000萬條數據,配置DataNode上的Reduce節(jié)點數為1, Map節(jié)點數分別為:1, 2, 5, 10, 100。K-Means算法的耗時分別為:612s, 466s, 307s, 163s, 199s。根據數據可以很直觀的表示Map節(jié)點和耗時關系圖如下圖3所示:

圖3 Map節(jié)點和耗時關系圖
根據圖像很容易看出Map節(jié)點和耗時情況的關系,在Reduce節(jié)點為1的基礎上,從數據中可以得出map節(jié)點在10的時候其運行效率最高。
第二組實驗使用所有的數據集,配置DataNode上的Reduce節(jié)點數為1, Map節(jié)點數始終為10,而分別使用100萬、500萬、1000萬、1500萬、1800萬、2000萬條數據進行運算。K-Means算法的耗時分別為:66s,169s, 288s, 352s, 429s, 475s。根據數據得出不同數據量運算和時間關系圖如圖4所示:
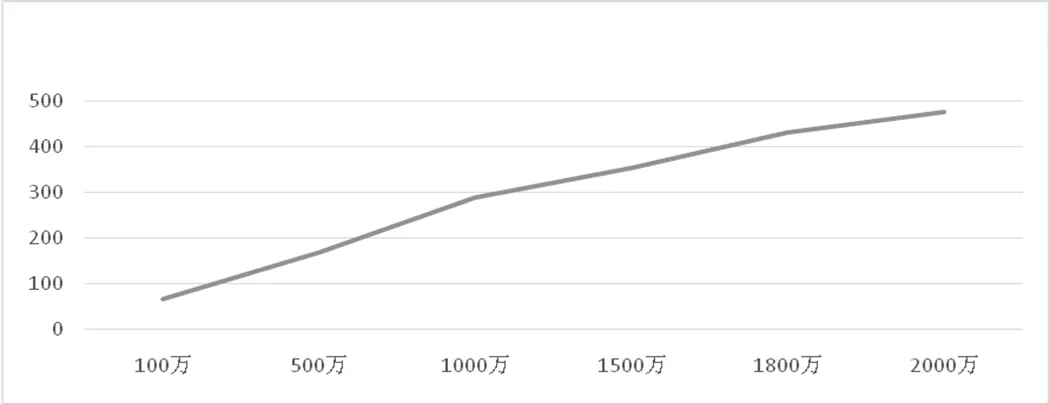
圖4數據量和時間關系圖
從圖4圖表信息中我們可以得出,Map節(jié)點數不變的時候,隨著數據量的增加耗時也會逐漸增加。兩者之間成正比關系。
4.2 Map reduce的云數據挖掘速度優(yōu)化
加速比是在數據處理中運行消耗的時間的比率,K-means算法就是一種數據挖掘算法,加速比可以用來衡量次算法對于云數據挖掘速度優(yōu)化條件。我們定義加速比,其中,sp為加速比,t1為單處理器下的運行時間,tp為p個處理器下并行計算的運行時間[16]。
分別測試數據集在1個節(jié)點和3, 5, 7, 9個節(jié)點的集群中k-means并行計算時間及其比率,得出加速比S1,S3,S5, S7,S9,結果如圖5所示。隨著云數據數據量的增加,其中的節(jié)點數也會隨之增加,圖5表明,同一數據集處理的加速比是逐漸增大的,也說明k-means算法在云數據挖掘中有更大的計算能力。
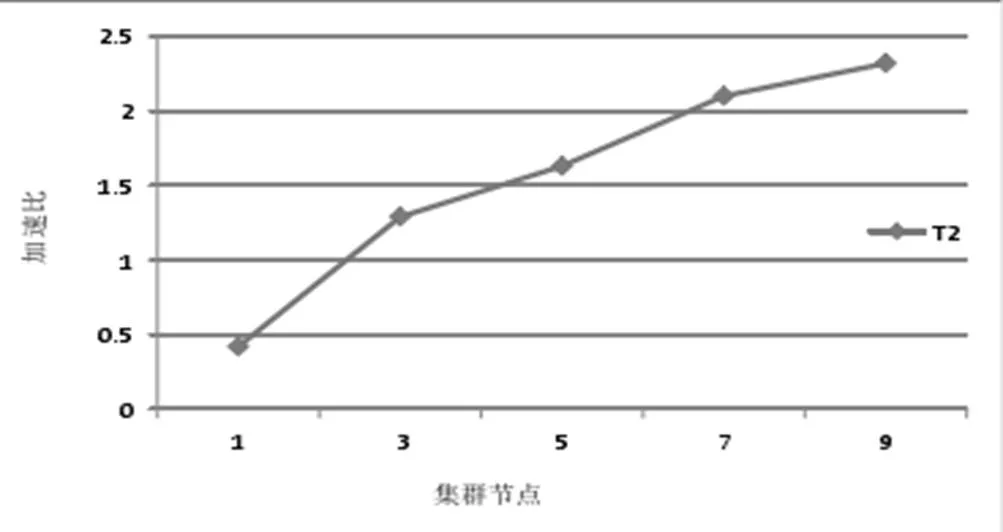
圖5 K-means算法集群優(yōu)化數據圖
5 結束語
首先深入研究了K-means的關鍵算法在 Map Reduce 的核心設計思想和實現,并且根據Map Reduce中的聚類K-means算法對給定數據集進行試驗。在掌握了 Map Reduce 并行計算框架這一基礎之上,通過對多種數據挖掘算法進行分析,提出并構建一種基于Map Reduce 的數據挖掘算法并行化實現模型。根據此模型和次模型給定的數據結果,總結了K-means算法在Map Reduce中處理大規(guī)模數據時的性能瓶頸,并且做了性能試驗分析。
當今時代網絡的普及帶來了海量數據難以處理的難題。研究的云數據中數據挖掘算法,是當今云數據迅速發(fā)展中一項較為復雜的技術,通過對K-means算法進行Map reduce化進行改進,從而能夠更好地縮短云數據數據挖掘的時間,提高效率,最大限度發(fā)揮了的可用性、協(xié)同性、擴展性等特點。
[1]李國杰,程學旗.大數據研究:未來科技及經濟社會發(fā)展的重大戰(zhàn)略領域一一大數據的研究現狀與科學思考[J].中國科學院院刊,2012.
[2]王佳雋,呂智慧,吳杰等.云計算技術發(fā)展分析及其應用探討田.計算機工程與設計,2012.
[3]Apache Hadoop.[EB/OL]. http://hadoop.apache.org. (2013-12-01).
[4]李雪梅,張素琴.數據挖掘中聚類分析技術的應用[J].武漢大學學報(工學版),2009.
[5]田力.山東移動通信公司泰安分公司BI系統(tǒng)設計[D]. 山東大學,2009.
[6]張釗寧.數據密集型計算中任務調度模型的研究[D].國防科學技術大學,2011.
[7]從玉相.基于MapReduce的社區(qū)挖掘算法[D].上海交通大學,2013.
[8]Rakesh Agrawal,Ramakrishnan Srikant. Fast Algorithms for mining association rules in large databases. Very Large Data Bases,International Conference Proceedings,P487-499,1994.
[9]Shcn M, Tzcng U H,Liu D R. Multi-criteria task as-signment in workflow management term Sciences,2003. Proceedings of the 36th Annual Hawaii International Conference on.IEEE,2003.
[10]曹聰.云計算支持下的數據挖掘算法及其應用[D]. 廣州大學, 2013.
[11]Yaakob SB, Kawata S. Workers placement in an in-dustrialenvironment[J].Fuzzy Setand Systems,1999.
[12]劉怡,張裁.基于負載平衡和經驗值的工作流任務分配策略[J].計算機工程,2009.
[13]郭希娟,李墨華.基于多準則的動態(tài)任務分配算法[J]一計算機應用,2008.
[14]江小平,李成華,向文,張新訪,顏海濤.k-means聚類算法的MapReduce并行化實現[[J].華中科技大學學報,2011.
[15]李賢虹.基于數據挖掘的讀者個性化信息服務系統(tǒng)的研究與設計[D].南昌:南昌大學,2009.
[16]張立.多體系統(tǒng)傳遞矩陣法分布式并行計算研究[J]. 中國廠礦醫(yī)學, 2009.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
大眾投資指南(2021年35期)2021-02-16 01:06:26
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
電力與能源(2017年6期)2017-05-14 06:19:37
中國中醫(yī)藥信息雜志(2016年7期)2016-12-01 06:07:55
光學精密工程(2016年6期)2016-11-07 09:07:19
信息通信技術(2015年6期)2015-12-26 01:16:46
核科學與工程(2015年4期)2015-09-26 11:59:03
河南科技(2014年23期)2014-02-27 14:18:43
