一種基于Hadoop平臺的分布式數據檢索系統
2017-06-20 00:21:41曹恒瑞曹展碩
軟件導刊 2017年4期
曹恒瑞 +曹展碩

摘要:企業級檢索不同于普通的數據檢索和網站檢索,它包括復雜結構的數據檢索、安全檢索、高可靠的查全和查準、智能化的數據檢索服務和實時的數據更新服務等。雖然可以利用已有數據檢索系統提供的站內數據檢索功能來構建企業級數據檢索系統,但這種站內檢索功能難以滿足絕大多數企業自身檢索需求。隨著大數據時代來臨,為處理海量數據,建立大數據平臺成為趨勢,使用分布式文件存儲系統,通過云計算技術來分析海量數據,開發企業級智能云檢索系統是提高企業綜合效益的關鍵。基于自然語言的智能云檢索,研究開發了基于Hadoop平臺的分布式數據檢索系統,實現了分布式文件系統和傳統關系數據庫協同運行的高效數據檢索系統。
關鍵詞:智能云檢索;Hadoop平臺;數據檢索;企業級檢索
中圖分類號:TP319
文獻標識碼:A
文章編號:16727800(2017)004011803
0引言
現代信息技術迅猛發展,企業面對海量數據存儲的壓力越來越大,導致用戶很難找到所需要的信息[12],已有的傳統數據庫管理系統無法滿足企業檢索需求。 〖HJ*3/8〗Hadoop可建立分布式集群,企業能夠建立屬于自己的大數據平臺并通過大數據平臺處理超大數據集及存儲海量數據。為此,本文設計了基于Hadoop平臺的分布式數據檢索系統。系統包括4個模塊[3]:語言處理模塊、中間語言處理模塊、生成查詢SQL模塊和權限控制模塊。語言處理模塊主要負責語言本身的處理,包括切詞、詞性識別、同義詞識別等。此模塊提供智慧化的接口,用戶可使用自然語言查詢需要的信息,通過分詞、詞性識別等操作,輸出結果,〖HJ〗提供給中間語言處理模塊處理。中間語言處理模塊主要負責將接收到的信息組合成偽SQL,然后通過SQL模塊,生成能被數據庫執行的SQL語句,得到查詢記錄集,最后格式化記錄集返回給前臺查詢頁面,完成自然語言查詢過程。
1系統關鍵技術
1.1Hadoop技術
Hadoop是分布式處理PB級數據的開源框架,具有可靠性、高效性和可伸縮性,能維護多個工作數據副本,并針對失敗節點重新分布處理,以并行工作方式來加速處理數據[4]。Hadoop的可伸縮性使其處理PB級數據得心應手,開源設計和廉價服務器配置使其得到廣泛應用。HDFS內部的所有通信都基于標準的TCP/IP協議,HDFS內部機制如圖1所示[5]。
1.2Lucene框架
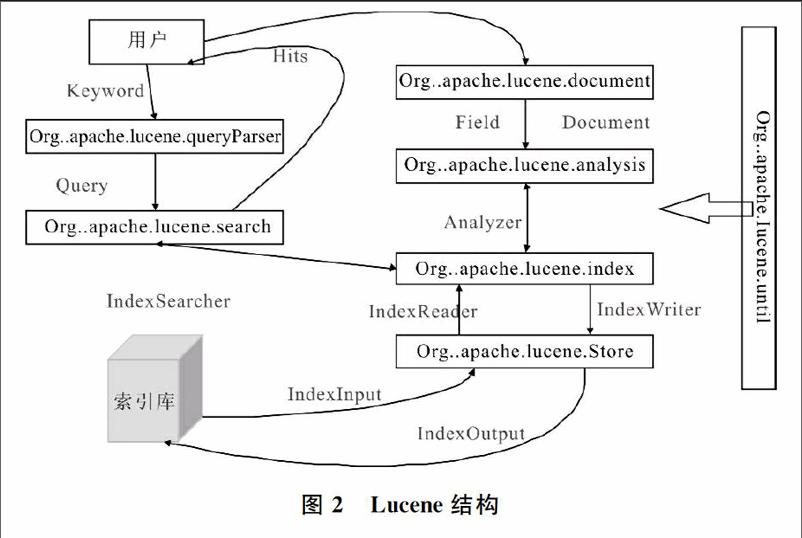
Lucene是非常優秀、成熟且開源的純Java語言全文索引檢查工具包,Lucene擁有高性能、可伸縮的信息檢索庫IRL(Information Retrieval Library,IRL),可為應用程序添加索引和檢索功能。Lucene不是純粹的引擎,只是引擎框架,實現索引、查詢和部分文本解析功能[6],如圖2所示。
1.3Solr檢索
Solr是基于Lucene Java的企業級檢索服務器,易于加入到Web應用程序中。Solr提供層次化檢索和高亮顯示并支持多種輸出文件格式,還有基于Http的管理頁面。相對于Lucene的底層檢索,Solr更專注于企業應用。 Solr對外提供標準的Http接口實現對數據索引的各項操作,用戶可通過Solr部署在Servlet容器中的Web應用來發送命令,Slor接到命令后會以同樣的方法回應,Solr特性如下:①高級全文檢索功能;②可擴展的插件體系;③綜合的HTML管理頁面;④專對高通量網絡進行優化;⑤使用XML配置達到靈活性和適配性;⑥基于開放接口(XML和HTTP)標準;⑦可伸縮性:能夠有效復制到另一個Solr服務器[7]。
1.4Spark Streaming技術
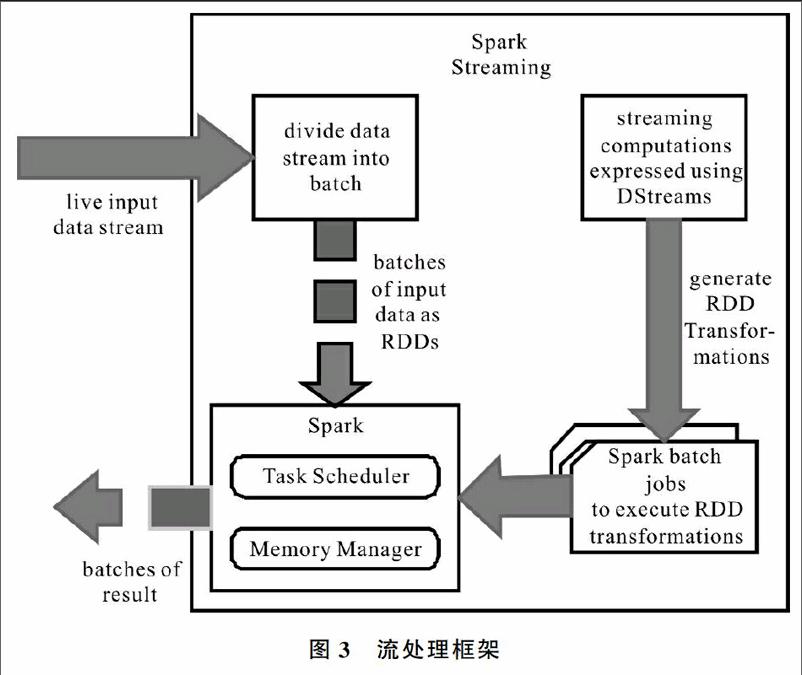
Spark Streaming是基于Spark處理數據的框架。在MapReduce中,由于其分布式特性——所有數據需要讀寫磁盤,啟動Job耗時較大,難以滿足時效性要求。Streaming能夠在Spark上發展的原因是因為其內存特性、低延時的執行引擎和高速的執行效率。Streaming原理:將Stream數據分成小的時間間隔(比如幾秒),即將其離散化(Discretized)并轉換成數據集(RDD),然后分批處理RDD。所以Streaming很容易與mlib、Spark SQL等結合,做到實時數據分析處理。此外,Streaming繼承RDD的容錯特性。如果RDD的某些Partition丟失,可通過Lineage信息重新計算恢復,如圖3所示。Streaming的數據源分兩種類型: (1)外部文件系統,如HDFS、Streaming可以監控一個目錄中新產生的數據并及時處理。如果出現fail,可以通過重新讀取數據來恢復,絕不會有數據丟失。 (2)〖JP3〗網絡系統:如MQ系統(Kafka、ZeroMQ、Flume等)。Streaming會默認在兩個不同節點加載數據到內存,一個節點fail了,系統可通過另一個節點數據重算。正在運行InputReceiver的節點出現fail,可能會丟失一部分數據[8]。
2系統設計
本系統模型及框架由頁面展示組建、權限控制組件、自然語言處理組件、企業級數據檢索、數據集接口組件組成。頁面展示組件就是用戶界面,用于用戶數據以及反饋結果頁面給用戶;權限控制組件用于在反饋結果頁面添加權限控制,以確保用戶數據安全;自然語言處理組件對自然語言進行分詞處理,并標注詞性,用于后續對應索引庫獲取參數字段;企業級數據檢索,用于對用戶輸入進行分詞處理,并建立索引庫;提供接口組件連接文檔庫、HBase數據庫、Web頁面等。
系統整合Hadoop分布式數據庫和DB2關系數據庫實現分布式協同計算框架,通過Spark Streaming流處理技術實現實時索引提高檢索效率,通過Lucene和Solr搭建分詞服務器并實現詞庫的自我完善與更新,通過Apache和Tomcat搭建Web服務器。智能云檢索系統架構如圖4所示。
企業級數據檢索引擎是基于全文檢索技術實現的,就是系統索引程序基于詞庫解析文本數據,每一個分詞后得到的詞語均建立索引,用戶可根據索引進行查詢并將查詢結果呈現。企業數據檢索引擎由索引引擎和檢索引擎構成,數據檢索引擎基于分詞工具實現分詞并根據分詞結果產生多個請求,如圖5所示。
3系統實現
數據檢索要求實現高性能、高穩定性、高可擴展性,針對數據檢索的核心設計包括Web存儲集群、索引計算集群、索引服務集群。 Web存儲集群(Web Storage Cluster)[9]:主要存放資源文件如網頁等,根據系統查詢的文件類型如Word、PDF、圖片等,都可以存放在Web存儲集群中;索引計算集群(Indexing Cluster)[10]:主要用于計算Web存儲的文件,生成索引數據和文件,為后續工作做準備;索引服務集群(Index Service Cluster):主要用于存放索引文件并進行查詢工作,如圖6所示。
數據檢索的前端頁面并不需要華麗的外表和復雜的界面設計,簡潔的頁面反而更受用戶青睞。對系統前端頁面設計沿用常規設計風格,有一個主頁標簽、檢索輸入框、檢索功能按鈕,根據業務需求提供指標、標簽、知識、頁面、表、翻譯等功能候選項。 良好的查詢界面對檢索系統也是非常重要的,整個查詢過程都需要保證頁面的整潔有序。如用戶查詢全省費用戶數分布,以及選擇TD客戶分布情況,查詢結果頁面效果如圖7所示。
4結語
本文對基于大數據平臺的智能云檢索系統關鍵技術作了詳細介紹。目前大數據技術基本成熟,分布式文件系統對海量數據的存儲和處理能力很強,各種大數據開源框架的出現讓大數據處理技術變得不再遙不可及,企業可以在低投入的情況下建立自己的大數據平臺,根據自身特點研究大數據處理技術,建立企業級數據檢索系統,充分利用數據資源為企業創造效益。
參考文獻:[1]孟小峰,慈祥.大數據管理:概念、技術與挑戰[J].計算機研究與發展,2013,34(1):146169.
[2]高明.大數據企業應用探索[J].合作經濟與科技,2014,21(3):106107.
[3]艷琳.大數據應用之道[J].科學大觀園,2013,12(2):7576.
[4]WU D P ,HOU Y T ,ZHU W W,et al.Streaming video over the internet:approaches and directions[J].IEEE Transactions on Circuits and Systems for Video Technology,2011,21(3):282300.
[5]TRAN D A ,HUA K A ,DO T T.A peertopeer architecture for media streaming[J].IEEE Journal on Selected Areas in Communications,2014,22(2):114.
[6]許波,陳曉龍.UML結合軟件工程教學改革探討[J].計算機教育,2013,25(2):239244.
[7]肖漢,車葵,石艷芳.軟件工程[M].北京:國防工業出版社,2013:1020.
[8]馮慧林,朱樹人.基于開源技術的Web應用架構研究[J].計算機技術與發展,2015,38(5):2729.
[9]史長民.軟件工程:原理、方法與應用[M].北京:高等教育出版社,2014,3660.
[10]Microsoft Media Server.Protocol specification[M].Microsoft Corp,USA,2013:110.
[11]向世靜.大數據關鍵技術及發展[J].軟件導刊,2016,15(10):2325.
[12]劉卓,崔忠偉.大數據技術在高校智慧校園中的應用[J].軟件導刊,2015,14(8):224225.
(責任編輯:杜能鋼)
