視頻拷貝檢測方法綜述
2017-06-23 12:48:06顧佳偉趙瑞瑋姜育剛
計算機研究與發展 2017年6期
顧佳偉 趙瑞瑋 姜育剛
(復旦大學計算機科學技術學院 上海 201203)
視頻拷貝檢測方法綜述
顧佳偉 趙瑞瑋 姜育剛
(復旦大學計算機科學技術學院 上海 201203)
(gujw15@fudan.edu.cn)
目前網絡上存在著大量的拷貝視頻,研究人員長期以來致力于視頻拷貝檢測技術的研究,特別是近年來隨著深度學習方法的引入,又涌現出了一些新穎的檢測算法.將對現有代表性的視頻拷貝檢測方法進行回顧與總結,涵蓋視頻拷貝檢測系統的基本框架與各個主要步驟的不同實現方法,包含視頻拷貝檢測中的特征提取、建立索引、特征匹配與時間對齊等不同模塊.總結的關鍵技術包括了最新的深度學習方法在其中的應用與取得的突破,主要體現在深度卷積神經網絡和雙胞胎卷積神經網絡方法的應用.此外,還將詳細介紹目前常用的5個用于視頻拷貝檢測評測的數據集及通用的評價標準,并討論分析一些代表性方法的性能表現.最后,對視頻拷貝檢測技術未來發展趨勢進行展望.
視頻拷貝檢測;特征表示;性能評價;數據集;綜述
隨著互聯網的快速發展,承載著人類活動信息的網絡數據正以指數速度增長.據統計,這些海量的網絡數據中80%的內容為圖像視頻等媒體數據[1].例如,全球最大的視頻網站YouTube在2007年初平均每分鐘有6 h時長的視頻被上傳;在2010年11月,該數字增加到了35 h;在2013年5月,平均每分鐘上傳視頻進一步增至100 h;而至2015年7月,這一數字已攀升至400 h[2];與此同時,根據2014年4月的統計結果,人們每個月要花費60億小時的時間在收看YouTube的視頻內容上[3].據IDC在2012年預測,到2020年全世界網絡數據規模將達到40 ZB[4].
互聯網的高速發展是一把雙刃劍,它在帶給人們方便與快捷的同時,也導致了許多問題.例如,一些盜版商利用網絡平臺出售盜版視頻以獲取不正當利益;一些用戶與團體借助網絡平臺惡意傳播非法視頻以擾亂社會秩序等.在這樣的背景下,多種問題視頻在各個視頻網站、交友社區、聊天工具等平臺中不斷傳播,危害社會.由于網絡數據規模十分龐大,依靠人力在海量數據中找出拷貝視頻是不現實的,視頻拷貝檢測技術也因此被提出.該技術的應用場景是,基于已有的源視頻,在海量數據中尋找與之相同或近似的拷貝視頻.視頻拷貝檢測技術除了可以應對上述的版權保護問題[5-7]與非法內容檢測問題[8]之外,還可以處理視頻監控計數問題[9]、視頻推薦問題[10]等.比如,一些用戶希望知道某視頻片段在網絡流媒體上某個時間段內出現的次數,獲取這類信息就需要運用該技術;當前各類視頻網站的個性化推薦服務是促進用戶體驗的重要手段,除了依據文本標簽匹配外,聯合視覺內容進行視頻推送,可以達到更準確的推送效果.隨著人類社會進入移動互聯網時代,多媒體信息傳播更加便捷化,形式更加復雜化,越來越多的地方需要用到這種技術.
早期的視頻拷貝檢測技術主要使用各類傳統特征進行檢測,取得了不錯的結果;近幾年,隨著深度學習方法的引入,涌現了一批新的基于深度網絡模型的視頻拷貝檢測技術,它們相比傳統方法取得了更優秀的識別效果.針對目前發展現狀,本文對現有代表性的視頻拷貝檢測方法進行回顧與總結,借此希望能給當前及未來的相關研究提供一定的參考與幫助.
1 視頻拷貝檢測技術概述
1.1 視頻拷貝檢測技術定義
目前關于視頻拷貝檢測技術的研究已有十多年,視頻拷貝檢測技術主要針對拷貝視頻進行檢測,但在同時期還存在幾種相近的檢測對象[11],如重復視頻、近似重復視頻[5,12]等.重復視頻即為幾乎一模一樣的視頻,范圍較窄;近重復視頻,要求語義一致、畫面近似,視頻來源一般不同;而拷貝視頻,要求語義一致、畫面近似且視頻來源相同.例如,父母用各自的手機分別記錄某時刻孩子的生活,這2個視頻視為近似重復而不是拷貝;如果母親對其中一個視頻進行后期加工,加入一些卡通元素,則新視頻才被視為拷貝視頻.在研究之初,其定義范圍較窄,一些研究者認為拷貝檢測與近似重復檢測有明顯的差異[6].后來,Basharat等人[13]建議放寬定義,以適應更廣泛的應用;為了獲取大眾對近似視頻的理解,Cherubini等人[10]還做了網絡調查.雖然目前還未有統一檢測對象,但它們所使用的檢測方法是共通的[11].
一般地,拷貝視頻主要由源視頻經過光學變換、幾何變換或時間變換等變換方式轉化而得,具體有插入圖標、模擬錄像、尺度改變和畫中畫等方式[8,14],圖1展示了部分拷貝方式.其中,圖1(a)為亮度改變;圖1(b)為左右對稱變換;圖1(c)為插入圖標;圖1(d)為畫中畫.在實際應用中,視頻的拷貝變換具有多樣性與不確定性,研究者希望找到一些通用的方法來適應所有的拷貝變換,目前許多方法對各種變換都有一定的效果,但在不同變換上存在著一定差異,一般插入圖標和改變伽馬值等拷貝變換較易檢測,而模擬錄像、畫中畫和后期加工等拷貝變換的檢測比較困難[8,15-18].從圖1中可以看出,后者在視覺內容上的變化相對較大.

Fig. 1 Examples of copied frames圖1 拷貝幀樣例
另外,視頻拷貝檢測應對不同任務具有不同的檢測級別.一些研究工作僅考慮整個視頻是否拷貝[12,19],即對于一個查詢視頻,在參考集中找出與整個查詢視頻互為拷貝的視頻,這種檢測被視為全局視頻拷貝檢測.相對地,更細粒度的局部視頻拷貝檢測技術主要針對視頻中的任意片段,找出2個視頻中所有的拷貝片段對[7,14,20-21].局部視頻拷貝檢測雖然具有更為全面、精準的效果,但檢索過程相對復雜,導致了檢索效率的降低.
1.2 視頻拷貝檢測技術基本框架
典型的視頻拷貝檢測技術基本框架如圖2所示,它主要包含4個步驟:特征提取(feature extraction)、建立索引(indexing)、特征匹配(feature matching)和時間對齊(temporal alignment).框架中對于數據庫視頻(database videos)的建模為離線步驟(圖2中offline線路);而對于查詢視頻(query video)需要進行更復雜的在線檢測步驟(圖2中online線路),下面介紹其大致流程.

Fig. 2 A general framework of a video copy detection system圖2 視頻拷貝檢測技術基本框架
如圖2所示,無論對于視頻庫中的視頻還是查詢視頻,首先需要進行特征提取步驟,即對視頻關鍵幀提取相應的特征向量,并經過一定處理形成幀特征或視頻特征.具體的特征提取方法將在第2節中詳細介紹.值得一提的是:一個視頻主要由幀序列和音頻信息組成,視頻拷貝檢測技術主要關注其幀序列.音頻信息對于拷貝檢測的幫助不夠穩定,因為相似音頻固然能給予加分,但音頻上差異較大的拷貝視頻反而可能會被誤判為非拷貝視頻.因此音頻信息在視頻拷貝檢測上并不具備普適性[12],故一般不被采用.
在獲得幀特征或視頻特征之后,需要進行建立索引操作.對于海量數據庫視頻中的拷貝檢測問題,使用直接的特征一一匹配方式顯得十分耗時.為了達到更高效的檢索,建立索引是一種必要的手段.理想的索引結構不僅要能提高檢索速度,還應控制因建立索引而產生的量化誤差.
對于數據庫視頻,只需執行以上步驟即可.而對于一個查詢視頻,還需要進行之后的特征匹配操作,也可稱之為索引匹配.不同的索引結構有不同的索引匹配方式.針對不同任務,如果是全局視頻拷貝檢測,通常將大于閾值的匹配結果確認為拷貝視頻;如果是局部視頻拷貝檢測,則將大于閾值的匹配結果確認為拷貝幀.第3節介紹了4種比較有代表性的索引結構與特征匹配方法.
最后,針對局部視頻拷貝檢測,還需要使用時間信息把拷貝幀整合成拷貝片段.具體的時間對齊方法詳見第4節.
1.3 討論與分析
1.2節介紹了視頻拷貝檢測技術的基本框架,特征提取部分對視頻生成具有視覺關鍵信息描述且又易于后續計算的數字序列.建立索引部分主要考慮的是特征匹配的效率問題,是為了實現高效的實時在線檢測系統而采用的一種技術.建立索引的同時往往會損失一定精度,對于不同的應用場景,是否使用索引結構以及使用何種索引結構都需要權衡考慮.時間對齊部分主要用于提取2個視頻的具體拷貝片段,相比全局視頻拷貝檢測,局部視頻拷貝檢測具有更直觀、更精確的效果,但同時帶來低效的檢索效率也是不可避免的.
2 特征提取
對視頻拷貝檢測系統中的特征提取環節,研究者總希望找到一種通用的特征,使之能夠魯棒地應對各種拷貝變換,可以說視覺特征是視頻拷貝檢測的關鍵[20-22].
目前對于視頻的描述特征分為2類:
1) 對于視頻幀級別的特征描述,該類特征大量用于局部視頻拷貝檢測中.在早期的工作中,大量傳統的圖像特征提取方法被用于視頻幀級別的特征提取.近年來,隨著深度學習技術的興起,出現了一些基于深度網絡的視頻幀特征提取方法.
2) 融合視頻內的所有幀信息后的視頻整體描述特征,主要用在全局視頻拷貝檢測問題,它在計算上依賴于前者視頻幀級別的特征描述.
以下先回顧常用的基于傳統方法和基于深度網絡的視頻幀特征的提取算法,再對視頻全局特征提取方法進行簡單介紹.
2.1 基于傳統方法的視頻幀特征
顏色直方圖與尺度不變特征變換(scale-invariant feature transform, SIFT)是視頻拷貝檢測系統中極為常用的2種傳統視頻幀特征提取方法.
在計算顏色直方圖時,需要預設一定的顏色域,對于原始圖像的像素矩陣,統計每一個像素點的顏色值,對其所屬的顏色域進行計數,整個方法描述的是不同色彩在整幅圖像中所占的比例.由于計算量小、檢索高效,該方法及其改進方法被運用于許多相關工作[6,12,23-29].然而顏色直方圖只考慮顏色信息,而忽略了視頻幀的幾何關系、形狀信息和紋理信息等,因此具有一定局限性.
SIFT特征對旋轉、尺度縮放、亮度變化保持不變性,對視角變化、仿射變換、噪聲也保持一定程度的穩定性[30-32].計算SIFT特征時需要對原始圖像中的局部關鍵點進行檢測,這些關鍵點依據各自在原圖像上的相對位置而形成幾何相關的描述子集合.為了提高匹配效率,研究者采用視覺詞袋模型把一個幀內眾多的局部描述子合成一個單一特征來表征視頻幀,這種特征在視頻拷貝檢測上具有良好的擴展性和較好的準確率[33].一些研究者針對詞袋模型產生的量化誤差,使用海明嵌入(Hamming embedding)[34]、基于重疊域的全局上下文描述子(OR-GCD)[35]等方法對其進行了優化.除了詞袋模型,一些工作還采用了其他特征編碼方式,比如Fisher Vector等[36-38].此外,對于視頻拷貝檢測這一特定任務,有學者還專門提出了對于SIFT的改進方法[39-40],例如在文獻[39]中,作者結合奇異值分解運算提出了一種名為SVD-SIFT的算法.相比于原始的SIFT算法,作者指出該改進的特征在保持了尺度、旋轉不變性等良好特性的同時,減少了總計算開銷,提高了拷貝檢測的速度.
2.2 基于深度學習方法的視頻幀特征
2012年Krizhevsky等人提出了著名的深度卷積神經網絡AlexNet,它在ImageNet挑戰賽中的大規模圖像分類任務上取得了突破性的成績[41].此后,大量基于深度學習的方法在計算機視覺領域涌現并取得了巨大成功.在多媒體拷貝檢測方面,一些工作[42-43]展示了其遠高于傳統方法的優異性能.目前深度學習技術在視頻拷貝檢測方面的成功應用主要集中在使用卷積神經網絡和雙胞胎卷積神經網絡進行視頻幀的特征提取.
2.2.1 卷積神經網絡方法
卷積神經網絡(convolutional neural network, CNN)可以直接用于視頻幀特征提取.經典的AlexNet主要包含5個卷積層(convolutional layer)和3個全連接層(fully-connected layer).Jiang等人[42]采用了預訓練的AlexNet模型,取AlexNet的第6層特征(fc6)作為視頻幀特征,如表1所示.表1中的第1列是網絡各層的名稱,第2列是對應的輸出特征尺寸.該方法使得每一個關鍵視頻幀,都被轉化成一個4 096維的特征向量.實驗表明,該方法具有高于傳統方法的優異性能.
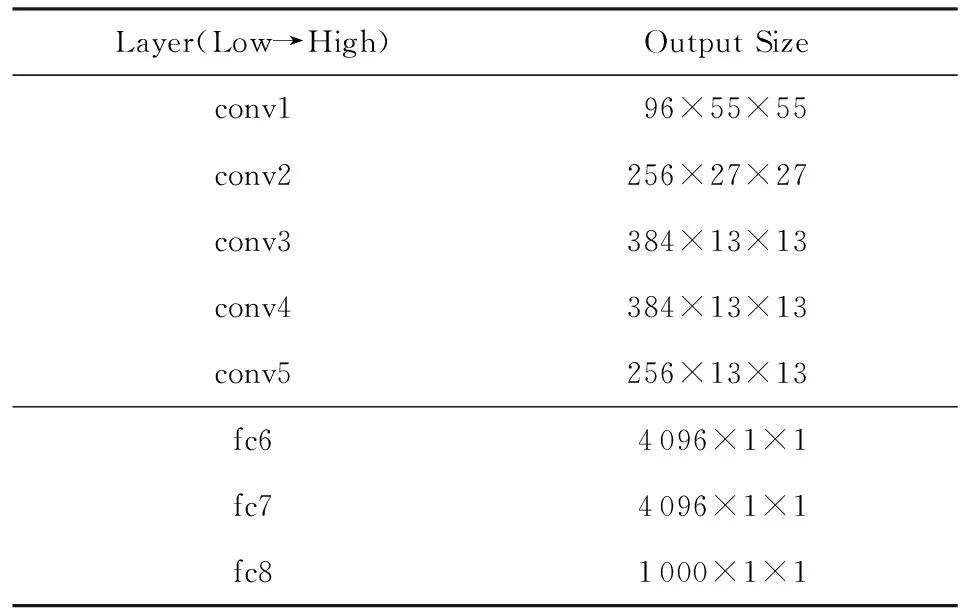
Table 1 A Simplified AlexNet Architecture表1 簡化的AlexNet框架
在AlexNet之后,又有許多深度網絡被提出,較著名的有VGGNet[44],GoogleNet[45]以及ResNet[46]等.VGGNet是一個更深的網絡,它最多有19層組成,具有更高的辨別能力.同時,它使用更小的卷積過濾器,能夠獲取原始圖像中更多的細節.GoogleNet包含22個網絡層,具有多尺度處理能力.一些工作對GoogleNet等深度網絡框架做了相應的研究,比較了各網絡之間的性能差異[47].ResNet是較新的一個CNN框架,它在2015年的ImageNet挑戰賽上獲得了冠軍.ResNet使用深度殘差網絡把CNN擴展到了152層,而在后續應用中,其深度更是超過了1 000層[48].
無論VGGNet,GoogleNet還是最近的ResNet,其網絡框架不斷變深,這些更先進的網絡結構原理上與AlexNet相同,都能用在視頻幀特征提取.例如,文獻[49]的算法基于VGGNet進行了視頻拷貝檢測的相關研究,獲得了比Jiang等人所提算法更好的結果.
2.2.2 雙胞胎卷積神經網絡方法
雙胞胎卷積神經網絡(siamese convolutional neural network, SCNN)[50]由2個結構相同、參數共享的子網絡組成,它以圖像對作為訓練輸入,通過預測的相似度與實際相似度之間的誤差進行前向反饋以調節網絡模型參數,如圖3所示.
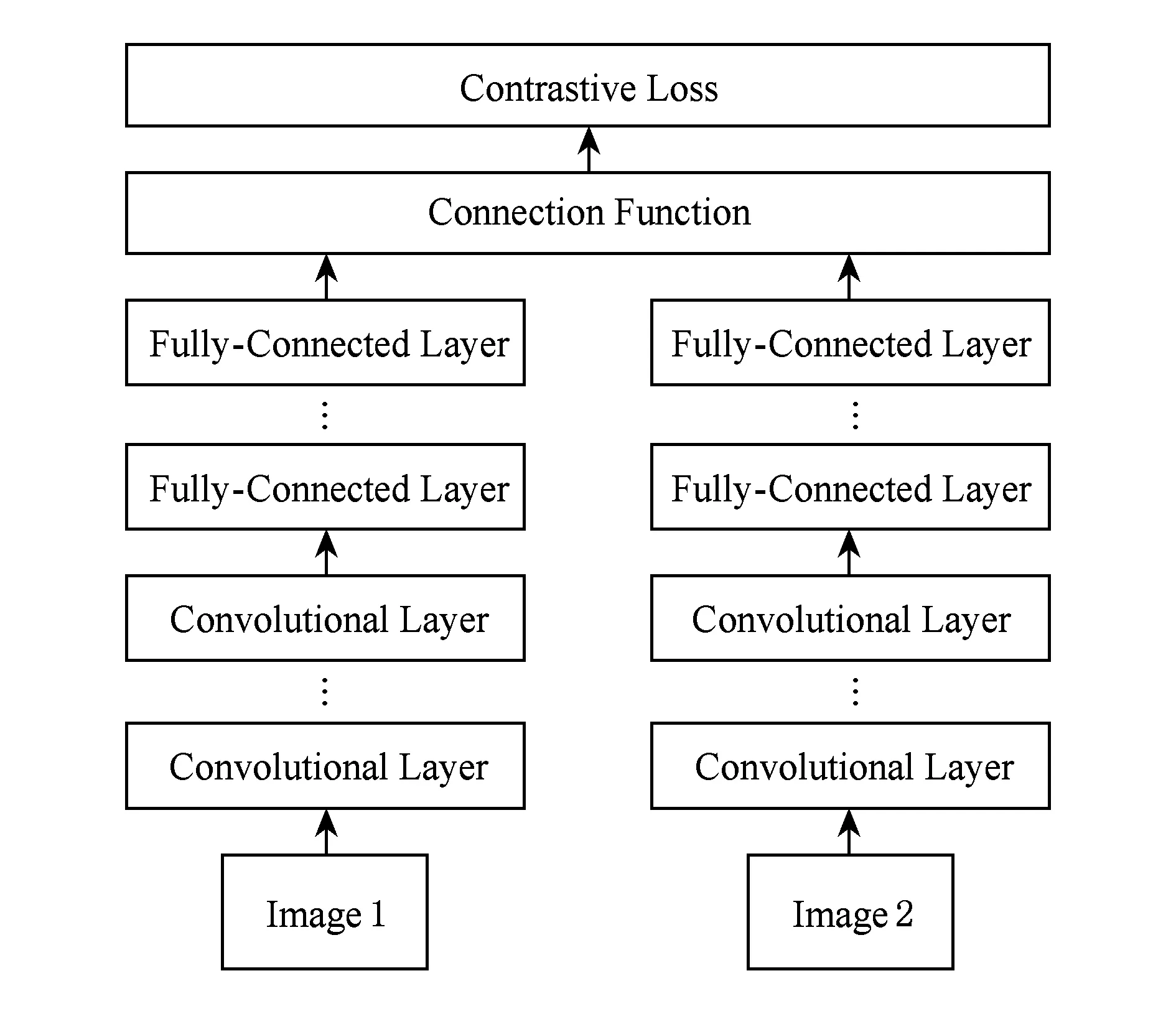
Fig. 3 A basic SCNN architecture圖3 一個基本的SCNN框架
該網絡用于拷貝檢測中的視頻特征提取原理是:當網絡輸入2張視頻幀圖像時,預測的相似度通過歐氏距離計算,模型訓練目標是使得拷貝對距離越小、非拷貝對距離越大.SCNN方法需要準備一定的訓練數據,通過模擬拷貝效果的方式制造拷貝對數據,非拷貝對數據可直接抽樣隨機配對獲得.依據所采用的CNN框架的不同,視頻幀表示方式也有所不同.例如Jiang等人在文獻[42]中使用了較窄的CNN子網絡,對視頻幀提取多個局部特征,后續計算采用了類似處理SIFT特征的方法,即使用詞袋模型形成單一向量作為視頻幀表示.另一種情況,是使用較寬的CNN子網絡,可直接提取視頻幀的全局特征,如在一些圖像拷貝檢測的工作[43]采用了此類方法,這些工作也都得到了優于傳統方法的良好效果.
SCNN方法直接針對相似度信息訓練模型參數,理論上比標準的深度學習方法更適合多媒體拷貝檢測任務.但由于訓練數據的差異以及更難的模型訓練,SCNN方法目前取得的整體效果顯得并不突出.
2.3 視頻全局特征
在視頻拷貝檢測系統中,除了對以上視頻幀描述特征進行比對,還有一類方法將各個視頻所有幀的特征合并為全局描述特征,再進行基于視頻全局特征的比對.此類方法主要用于全局視頻拷貝檢測,它的典型代表包括基于視頻幀特征聚類的方法[51]、基于視頻所有幀特征向量主成分分析得到的邊界坐標系統(bounded coordinate system)描述[5,26]、基于視頻幀特征直方圖統計的累積直方圖(accumulative histogram)方法[12]和參考視頻直方圖(reference video-based histogram)方法[24]等.此類方法的主要優點在于得到的視頻描述特征較為精簡.然而與基于視頻幀特征比較的方法相比,此類方法的最大問題在于它們往往忽略了視頻中的局部信息,例如視頻片段中出現的物體或區域變化[11].由于視頻全局特征的這些不足,近年來提出的一些更有效的拷貝檢測系統主要采用基于視頻幀比較的方法.
2.4 多特征融合
對于視頻拷貝檢測問題,大部分已有的方法都只使用一種特征,然而單一特征往往不足以描述視頻內容,不能應對復雜而多樣的拷貝變換,所以一些方法[19,52]采用了具有不同特性的多重特征作為視頻內容描述,獲得了比單一特征更好的結果.
3 建立索引與特征匹配
為了達到快速檢索的目的,視頻拷貝檢測系統中通常需要運用高效的索引結構.特別是局部視頻拷貝檢測,總體特征量十分龐大,如果采用枚舉的方式進行一一匹配,檢索效率會十分低下,很難應用于在線的視頻拷貝檢測系統.索引結構一般與特征的形式和特征匹配所采用的最近鄰搜索方法相關.本文總結如下4種常見的索引方法,分別是樹形結構、向量近似文件、Hash結構和倒排索引方法.
3.1 樹形結構
目前已有許多樹形索引結構被提出,在視頻方面,一種被稱為“高斯樹”[53]的索引結構既實現了高效率搜索,又保留了較多的視覺信息.高斯樹通過管理高斯分布來實現快速的概率查詢,它能應用于較復雜的對象.但樹形結構對于高維擴展并不友好,當特征維度增加時,會引發“維數災難問題”.
3.2 向量近似文件
向量近似文件(vector approximation file, VA-file)方法[54]的主要思想是將特征空間劃分成2b個單元,每個單元都可以用一個長度為b的二進制比特串表示,查詢樣本在比對時可以排除距離較遠的單元內的數據,從而大大減少了計算開銷.后續工作還對算法中不同掃描邊界的設定進行了比較分析,提出了VA-LOW,VA-BND和VA-LOW-k等不同設定以及改進方法[55].
3.3 Hash結構
Hash是一種常用的加快查找速度的方法.其中,位置敏感Hash(locality-sensitive hashing, LSH)[56]能很好地應對高維特征而被廣泛應用[40,57].該方法采用一組位置敏感Hash函數,在特征空間內做隨機方向的線性映射,使得近似的特征能有很高的概率落入同一個散列桶內.LSH的查詢時間是次線性(sub-linear)的,但同時它的查詢結果質量也是不穩定的[58].在隨后的幾年內,針對其準確率和時空效率,LSH不斷被人改進[59-61].
另外,針對多重特征的情況,多特征Hash(multiple feature hashing, MFH)[19]被使用于視頻拷貝檢測并取得了不錯的效果.該方法采用一組預訓練的Hash函數,每個Hash函數以多重特征為輸入并輸出一個二進制位,最后形成一個二進制向量并通過異或操作進行相似度值的計算.MFH具有較好的擴展性,但其難點在于如何訓練Hash函數以提高精度與效率.
3.4 倒排索引
倒排索引結構首先被應用于文本檢索,后來在圖像視頻領域也被廣泛應用.各類特征通過視覺詞袋模型[33,62-63]形成一個個視覺詞,所有視覺詞形成一個詞典,這與文本數據十分相似,因而能很方便地使用倒排索引結構.一個典型的倒排文件主要記錄每個視覺詞的頻率及其出現位置,并以視覺詞作為屬性、出現位置作為記錄,形成屬性確定記錄的結構.一般地,對于幀級別的特征匹配,以每一幀的局部特征作為屬性,整個圖像作為記錄;對于視頻級別的特征匹配,以每一幀的全局特征作為屬性,整個視頻作為記錄.此外,一些研究者針對倒排索引結構造成的幾何信息的缺失問題,使用弱幾何一致性[34]及其改進方法[9,64]對倒排索引結構進行了優化.
一般地,建立索引會損失一定的量化誤差,故為了追求更高的理論精度,一些工作也會不加索引而采用一一匹配的方式[42].特征匹配一般采用距離度量,較普遍的2種距離為歐氏距離與余弦距離.針對一些特殊類型的特征,也會采用地球移動距離(earth mover’s distance, EMD)[65]、編輯距離(edit distance)[66]等度量方式,其中前者能很好地評估直方圖相似性,后者常被運用于類字符串數據.
4 時間對齊
時間對齊是在進行局部視頻拷貝檢測中為了確定2個視頻的哪些片段對互為拷貝時進行的操作.對于任意2個視頻,有一對一、一對多、多對多以及交叉對應等多種拷貝片段對齊形式.圖4簡單描述了以上4種情況,圖4中上下2條長線分別表示2個完整視頻,其中同灰度短線條表示拷貝片段,由中間的指示線連接表明對應關系.為了解決上述形式多樣的拷貝片段對齊問題,下面介紹并分析3種時間對齊方法,分別是基于滑動窗口的時間對齊算法、基于樹形結構的時間對齊算法和基于圖的時間對齊算法.

Fig. 4 Four examples of copied segments in a pair of video圖4 在一對視頻內的4種拷貝片段對齊情況
4.1 基于滑動窗口的時間對齊算法
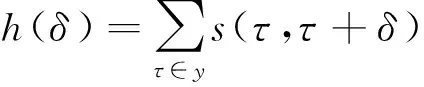
4.2 基于樹形結構的時間對齊算法
文獻[67]提出了一種樹形表示的時間對齊算法.該方法對于每個查詢幀,先找出一個與之相似的參考視頻幀集合作為候選集,然后將所有候選集構成一個樹狀結構.樹的根節點對應查詢視頻的某個幀,以該查詢幀作為起點,樹的第1層由其相似幀集合組成,第2層由其查詢幀的下一幀的相似幀集合組成,并且從第2層起,每次連接子樹要額外考慮時間信息,即要求在時間上父節點先于子節點且父子節點的時間差小于預設閾值.最后,再使用剪枝策略得到最終的匹配結果.另外,如果構建樹的過程中因無法找到可連接的子樹而中斷時,以中斷處的幀為根節點,重新構建樹;被中斷的樹則執行剪枝策略獲得相應的拷貝片段.
4.3 基于圖的時間對齊算法
Tan等人[9,68]提出了一種運用網絡流算法的時間對齊方式,并開發出了相應的算法工具[69].該方法對于一個查詢視頻Q和一個參考視頻R,針對視頻Q中每一幀,從視頻R中找出與之最相似的k幀,用以構建初始的拷貝幀網絡;然后嚴格依據時間順序,用有向邊連接top-k列表中的所有幀,邊的權重即為對應幀之間的相似度值;最后,執行最大流算法,獲得最長的視頻拷貝段.
時間對齊是局部視頻拷貝檢測中的一個重要環節.上述3種方法,第1種方法是先考率時間信息,再考慮幀之間的相似度信息;而后2種方法與之相反.基于滑動窗口的方法受視頻幀率與預設閾值的影響而不夠穩定,基于樹與基于圖的方法都需要額外確定路徑的算法而產生較多的計算量.針對不同的視頻拷貝檢測任務,需要使用與之相適應的時間對齊方法.
5 數據集與已有方法性能
5.1 數據集
在視頻拷貝檢測領域中常見并具有代表性的數據集主要包括TRECVID[70-72],Muscle-VCD[7],CC_Web[12],UQ_Video[19]和VCDB[14],表2中羅列了這些數據集的基本統計信息.

Table 2 Comparison of the Widely Used Copy Detection Datasets[14]
TRECVID是美國國家標準技術局(NIST)支持的一個視頻檢索項目,它在2008年發布了一個專用于視頻拷貝檢測算法評測的公共數據集[72],該數據集包含200 h時長的電視節目視頻,約2 000個查詢片段.其中,查詢片段采樣于原數據庫,并加以隨機的模擬拷貝操作而得,具體操作有插入圖標、模擬錄像、再編碼、后期加工等,一些工作[73-74]涉及了該項目數據集.
Muscle-VCD數據集包含約100 h時長的視頻[7].該數據集中所有視頻采樣于網絡視頻片段、電視檔案和電影等,并以不同的比特率、分辨率以及視頻格式進行存儲.該評測數據集共有2個任務,分別是全局視頻拷貝檢測與局部視頻拷貝檢測.針對不同任務,研究者可以獲取一個原始視頻集和一個相應的用于查詢的模擬拷貝的視頻集,以此評估各個視頻拷貝檢測方法的性能.一些研究工作[9,75]在該數據集上進行了實驗.
CC_Web是一個包含12 790個視頻的拷貝檢測數據集[12].該數據集最大特點是它的所有視頻均來源于網絡,沒有對視頻進行模擬拷貝的轉化操作,所以這個數據集被認為是體現網絡真實拷貝情況的數據集.CC_Web數據集中的樣例視頻如圖5所示.圖5中行a展示的是原始的視頻幀,行b的視頻幀是經過亮度與尺寸變換后的視頻幀,行c是調整視頻幀采樣率后的視頻幀,行d是加入了文字、分框和內容改變后的結果,行e-f是在起始和末尾加入了變化內容的結果,行g是整個視頻加入上下邊框的結果,行h是單純的尺寸變換的結果.該數據集被運用于一系列工作中[9,12,33,76-78].
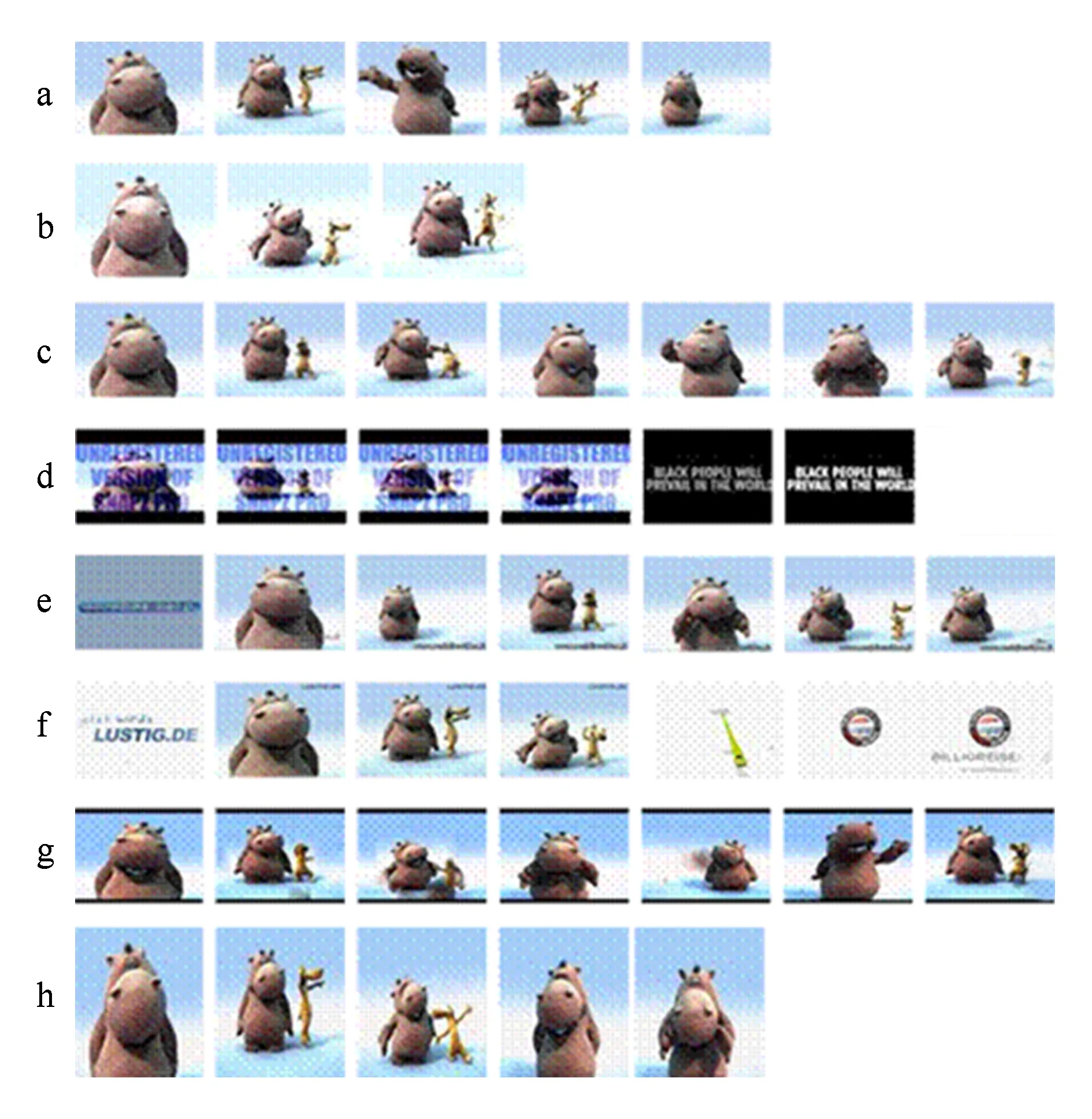
Fig. 5 Examples of video frames in CC_Web dataset[12]圖5 CC_Web數據集中視頻幀示例[12]
UQ_Video是對CC_Web數據集的擴展,主要加入了10多萬個干擾視頻[19].CC_Web和UQ_Video這2個數據集都只能用于全局視頻拷貝檢測.
VCDB是一個較新的視頻拷貝檢測數據集,它共有100 528個視頻[14],其中528個視頻是核心視頻,包含9 236對視頻拷貝片段,其余的10萬個視頻為干擾視頻.該數據集也完全采集于網絡,屬于真實拷貝的數據集.它被用于局部視頻拷貝檢測,并對各拷貝片段的變化方式做了精確統計.VCDB數據集中的部分樣例視頻如圖6所示.圖6中展示了該數據集中不同類別的視頻數據,包括商業、電影、音樂、演講、運動、監控和其他等主題.圖6中每張小圖的左右兩半顯示了原始視頻幀和經過拷貝變換后的視頻幀的樣例.基于深度學習的拷貝檢測方法[42,49]在該數據集上進行了實驗.

Fig. 6 Examples of video frames in VCDB dataset[14]圖6 VCDB數據集中視頻幀示例[14]
5.2 評價標準
在關于視頻拷貝檢測方法的評估中,與信息檢索相關的準確率、召回率、F1均值以及平均精度均值(mean average precision,MAP)都是常用的評測指標.
特別地,在TRECVID的拷貝檢測任務中,還采用了一種稱為最小標準化檢測消耗率(minimal normalized detection cost rate,MinNDCR)的指標,計算公式如下:
NDCR=CMiss×PMiss×Rtarget+CFA×RFA,
(1)
其中,PMiss與RFA分別為漏檢率與誤檢率,CMiss與CFA分別為漏檢率與誤檢率的懲罰系數,Rtarget為先驗達標率.NDCR數值越小,代表檢測算法的性能越好.
在Muscle-VCD-2007的局部視頻拷貝檢測任務中,幀精度(QualityFrame,QF)和片段精度(QualitySegment,QS)指標被用于局部視頻拷貝檢測算法的性能評測,它們的計算公式分別為

(2)
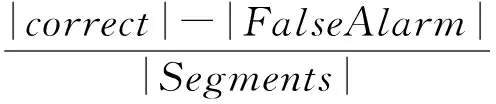
(3)
其中,QF指標計算的是拷貝片段中幀的覆蓋精度,QS指標計算的是拷貝片段的檢測精度.QF與QS的值越大,代表檢測算法的性能越好.
在VCDB數據集中,視頻幀級別的準確率(frame-level precision,FP)和召回率(frame-level recall,FR)、視頻片段級別的準確率(segment-level precision,SP)和召回率(segment-level recall,SR)指標被用于性能評測,它們的計算公式分別為

(4)

(5)

(6)
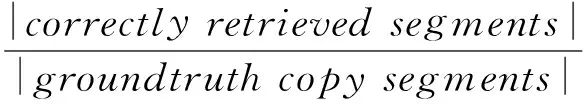
(7)
其中,檢測返回的一對拷貝段若與實際拷貝段皆有重合,則被視為正確的檢索片段(correctlyretrievedsegments).以上指標數值越大,代表檢測算法的性能越好.
另外,針對拷貝檢測的實際應用場景,一些工作還評測了檢測效率[26,33,42,66,79]和可擴展性[9,78,80-81]等指標.
5.3 已有代表性方法性能
目前已有工作的實驗對象主要是以上的5個數據集,應用場景包括檢測拷貝幀、檢測拷貝片段以及視頻級別檢測等.由于各個工作在實驗對象、應用場景上的差異,導致無法進行統一的比較.其中TRECVID中基于內容的拷貝檢測(content based copy detection, CBCD)任務曾提供了一個很好的性能比對平臺[71],但這個任務因在2011年獲得了接近完美的提交結果而被取消了.圖7展示了TRECVID 2011 CBCD中性能最好的前10個結果,其中橫坐標為拷貝變換方式,縱坐標為F1得分,數字1~10表示排名前10的隊伍,Act.與Opt.分別表示為使用隊伍提交閾值與使用最優閾值的情況,Median為所有隊伍結果的中位數.圖7中排名前10的隊伍采用Act.閾值的結果用菱形表示,采用Opt.閾值的結果用短橫線表示,Median結果則用折線圖表示,其中折線圖上點為方形的為Act.Median,點為菱形的為Opt.Median.從圖7中可以看出,在該數據集上大部分方法都已經達到接近完美的結果.
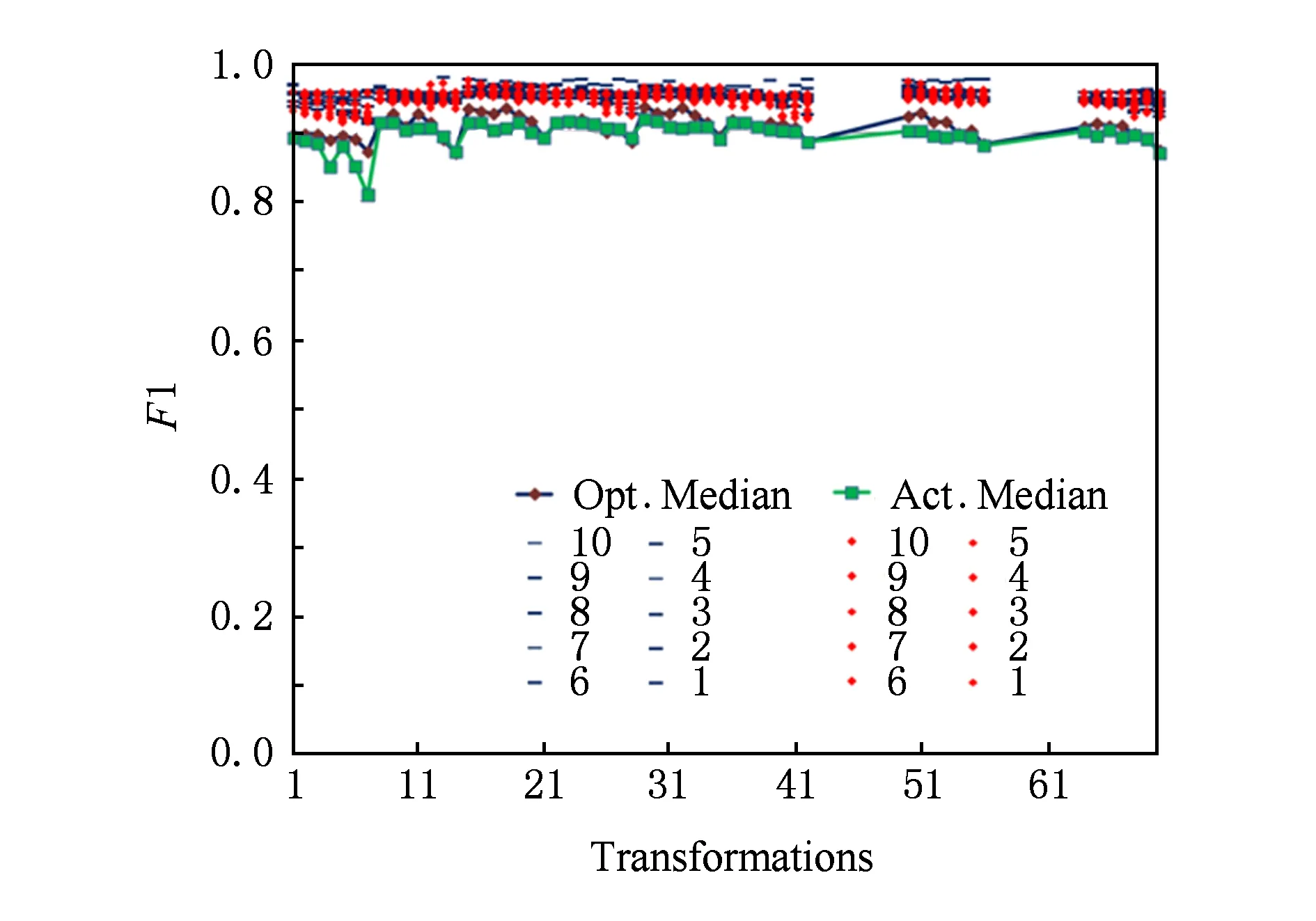
Fig. 7 F1 Scores of top 10 performance in TRECVID 2011 Content Based Copy Detection[8]圖7 TRECVID 2011 CBCD中top10性能的F1得分[8]
在Muscle-VCD數據集上,表3展示了全局視頻拷貝檢測任務中的部分比較有代表性的算法的評測結果.其中,ADV,IBM,CITYU和CAS是當時Muscle-VCD-2007比賽中的拷貝檢測方法.從表3中可以看出TNP方法[9]在精度與效率上都達到了最優,特別是在精度上獲得了100%的準確率.表4展示了局部視頻拷貝檢測任務中的部分比較有代表性的算法的評測結果,TNP方法[9]依舊在精度與效率上展現出最好的性能.
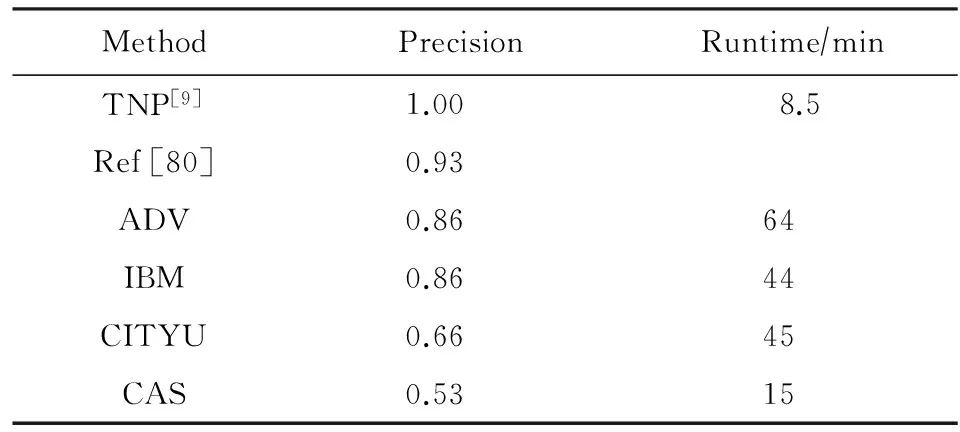
Table 3 The Performance of Several Representative Methods in Entire Video Copy Detection Task of Muscle-VCD-2007
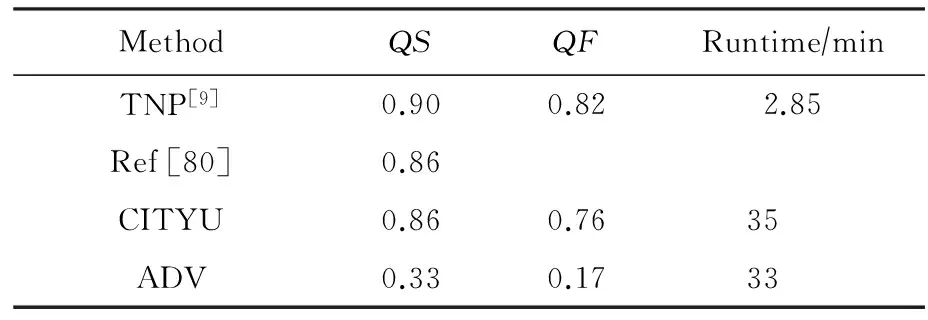
Table 4 The Performance of Several Representative Methods in Partial Video Copy Detection Task of Muscle-VCD-2007
一些工作在CC_Web數據集上進行了評測,如表5所示.其中PPT方法[21]取得了最優的結果,但差距并不明顯,4種方法都達到了較好的結果;而SIG_CH方法[12]由于直接采用顏色直方圖所帶來的局限性而導致性能不佳.
一些方法在UQ_Video數據集上進行了實驗,如表6所示.相比CC_Web數據集,由于UQ_Video數據集增加了10多萬個干擾視頻,各方法性能整體表現不高;其中PPT方法[21]依舊取得了最優的結果,但處理速度上不及MFH方法[19].

Table 5 The Performance of Several Methods in CC_Web Dataset
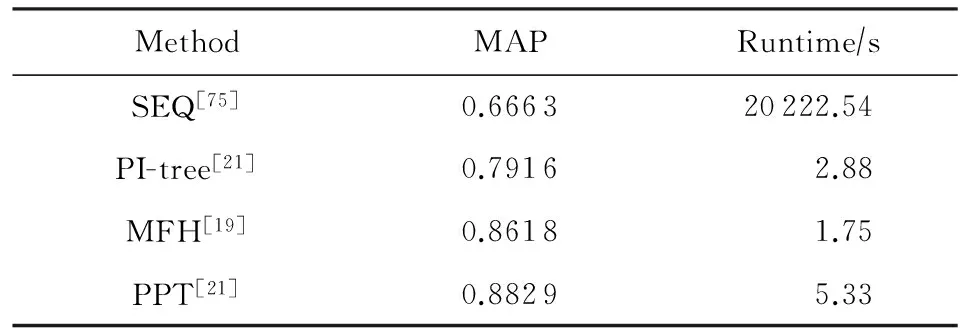
Table 6 The Performance of Several Methods in UQ_Video Dataset[21]
在最新的相關工作中,文獻[42]給出了采用深度學習方法與傳統方法在拷貝檢測任務中的性能比較,如表7所示.實驗中,該文作者使用了VCDB數據集,并采用F1得分作為評價指標.從該文作者給出的結果與分析中可以明顯發現,算法在視頻幀級別與視頻片段級別上得到的評測結果一致,使用深度學習方法得到的視頻特征(CNN與SCNN)取得了比傳統方法(SIFT)更好的檢測性能,驗證了深度學習方法在拷貝檢測問題中的適用性.此外,還可以發現同屬深度學習方法的SCNN網絡得到的檢測性能并不如普通的CNN網絡.文獻[42]中作者給出的解釋是在使用CNN網絡時,人們可以利用大量的已標注圖像數據對網絡進行預訓練,而對于SCNN可用的訓練樣本的數據量非常有限,從而影響了最終訓練完成的SCNN網絡的性能.
Table 7 Frame-Level and Segment-LevelF-Measure on the Core Data Set of VCDB[42]

表7 不同方法在VCDB上的F1得分情況[42]
另外,在局部視頻拷貝檢測中,時間對齊算法也對檢測性能具有一定影響.文獻[14]中將2種時間對齊算法在VCDB數據集上進行了實驗比較,結果表明:在性能上,網絡流時間對齊算法在拷貝幀檢測與拷貝片段檢測上均優于霍夫投票機制時間對齊算法;在效率上,網絡流時間對齊算法要略慢于霍夫投票機制時間對齊算法,但在可接受范圍內.
6 未來發展趨勢
就目前成果而言,拷貝檢測技術雖然在一些相對簡單的數據集上取得了接近完美的結果,但在相對復雜的數據上還遠未達到令人滿意的性能.目前而言,視頻拷貝檢測方法本身的性能還有待提高,同時更多豐富的評測數據也有待建立,為深入地研究提供幫助.
評測數據集的建立,一方面要考慮其真實性,另一方面要考慮其復雜性.在真實性上,CC_Web與VCDB等數據集給出了解決方法,即直接從網絡環境采集數據;在復雜性上,保證一定量級的同時還要保證拷貝方式的多樣化,這個過程中需要一定人為的篩選.另外,視頻標注也是一大挑戰,特別是局部視頻拷貝檢測評測數據集,需要精確拷貝段到秒級;面對如此龐大的標注量,半自動化的標注工具可能是一種解決方法.
在視頻拷貝檢測方法上,特征表示是其關鍵.目前深度學習技術在視頻拷貝檢測上展現出優于傳統方法的性能,這肯定了深度學習的特征表示能力.未來一段時間內,基于深度學習的視頻拷貝檢測方法應是主要研究方向,RNN/LSTM是否可以用來對視頻片段建模有待探索;RCNN這類用于目標檢測的網絡是否可以用在拷貝檢測上也有待研究;更適宜拷貝檢測的深度網絡結構還有待提出.與此同時,為了訓練出與理論框架效果接近的網絡模型,與深度網絡結構相適應的訓練數據也亟需完善.
另外,隨著網絡的發展與科技的進步,視頻拷貝檢測方法所能應對的新的應用場景也將不斷被探索.
7 總 結
本文首先描述了視頻拷貝檢測技術的研究背景;然后介紹了一個實現視頻拷貝檢測的基本框架,對框架內各步驟要點進行了分析,結合最新的深度學習方法,詳細介紹了深度學習在視頻拷貝檢測方法中的應用與進展;最后回顧了目前具有代表性的5個數據集及通用的評價標準,討論并分析了當前研究狀況與未來發展趨勢.隨著視頻拷貝檢測研究的不斷深入,希望本文能給當前及未來的研究提供一定的參考與幫助.
[1]Analytics Magazine. Images & videos: Really big data[EB/OL]. 2012[2016-12-05]. http://analytics-magazine.org/images-a-videos-really-big-data
[2]Tubular Insights. 500 hours of video uploaded to YouTube every minute[Forecast][EB/OL]. 2015[2016-12-05]. http://tubularinsights.com/hours-minute-uploaded-youtube
[3]Smith G. 145 amazing YouTube statistics (October 2016)[EB/OL]. 2016[2016-12-05]. http://expandedramblings.com/index.php/youtube-statistics
[4]Infosecurity Magazine. Digital universe is headed for 40 ZB, but big data lacks protection[EB/OL]. 2012[2016-12-05]. http://www.infosecurity-magazine.com/news/digital-universe-is-headed-for-40-zb-but-big-data
[5]Shen Hengtao, Zhou Xiaofang, Huang Zi, et al. UQLIPS: A real-time near-duplicate video clip detection system[C] //Proc of the 33rd Int Conf on Very Large Data Bases. New York: VLDB Endowment, 2007: 1374-1377
[6]Law-To J, Buisson O, Gouet-Brunet V, et al. Robust voting algorithm based on labels of behavior for video copy detection[C] //Proc of the 14th ACM Int Conf on Multimedia. New York: ACM, 2006: 835-844
[7]Law-To J, Joly A, Boujemaa N. Muscle-VCD-2007: A live benchmark for video copy detection[EB/OL]. 2007[2016-12-05]. http://www-rocq.inria.fr/imedia/civr-bench
[8]Kraaij W, Awad G. TRECVID 2011 content based copy detection: Task overview[EB/OL]. Gaithersburg, MD: NIST, 2011[2016-12-05]. http://www-nlpir.nist.gov/projects/tvpubs/tv11.slides/tv11.ccd.slides.pdf
[9]Tan H K, Ngo C W, Hong R, et al. Scalable detection of partial near-duplicate videos by visual-temporal consistency[C] //Proc of the 17th ACM Int Conf on Multimedia. New York: ACM, 2009: 145-154
[10]Cherubini M, De Oliveira R, Oliver N. Understanding near-duplicate videos: A user-centric approach[C] //Proc of the 17th ACM Int Conf on Multimedia. New York: ACM, 2009: 35-44
[11]Liu Jiajun, Huang Zi, Cai Hongyun, et al. Near-duplicate video retrieval: Current research and future trends[J]. ACM Computing Surveys, 2013, 45(4): No.44
[12]Wu Xiao, Hauptmann A G, Ngo C W. Practical elimination of near-duplicates from Web video search[C] //Proc of the 15th ACM Int Conf on Multimedia. New York: ACM, 2007: 218-227
[13]Basharat A, Zhai Y, Shah M. Content based video matching using spatiotemporal volumes[J]. Computer Vision and Image Understanding, 2008, 110(3): 360-377
[14]Jiang Yugang, Jiang Yudong, Wang Jiajun. VCDB: A large-scale database for partial copy detection in videos[C] //Proc of the European Conf on Computer Vision. Berlin: Springer, 2014: 357-371
[15]Jiang Menglin, Fang Shu, Tian Yonghong, et al. PKU-IDM@ TRECVid 2011 CBCD: Content-based copy detection with cascade of multimodal features and temporal pyramid matching[C] //Proc of the TRECVID Workshop. Gaithersburg, MD: NIST, 2011
[16]Ayari M, Delhumeau J, Douze M, et al. Inria@ trecvid’2011: Copy detection & multimedia event detection[C] //Proc of the TRECVID Workshop. Gaithersburg, MD: NIST, 2011
[17]Uchida Y, Takagi K, Sakazawa S. KDDI Labs at TRECVID 2011: Content-based copy detection[C] //Proc of the TRECVID Workshop. Gaithersburg, MD: NIST, 2011
[18]Gupta V, Varcheie P D Z, Gagnon L, et al. CRIM at TRECVID 2011: Content-based copy detection using nearest-neighbor mapping[C] //Proc of the TRECVID Workshop. Gaithersburg, MD: NIST, 2011
[19]Song Jingkuan, Yang Yi, Huang Zi, et al. Multiple feature hashing for real-time large scale near-duplicate video retrieval[C] //Proc of the 19th ACM Int Conf on Multimedia. New York: ACM, 2011: 423-432
[20]Wu Xiao, Li Jintao, Tang Sheng, et al. Video copy detection based on spatio-temporal trajectory behavior feature[J]. Journal of Computer Research and Development, 2010, 47(11): 1871-1877 (in Chinese)
(吳瀟, 李錦濤, 唐勝, 等. 基于時空軌跡行為特征的視頻拷貝檢測方法[J]. 計算機研究與發展, 2010, 47(11): 1871-1877)
[21]Chou C L, Chen H T, Lee S Y. Pattern-based near-duplicate video retrieval and localization on Web-scale videos[J]. IEEE Trans on Multimedia, 2015, 17(3): 382-95
[22]Shinde S, Chiddarwar G. Recent advances in content based video copy detection[C] //Proc of the Int Conf on Pervasive Computing (ICPC 2015). Piscataway, NJ: IEEE, 2015: 1-6
[23]Zobel J, Hoad T C. Detection of video sequences using compact signatures[J]. ACM Trans on Information Systems, 2006, 24(1): 1-50
[24]Liu Lu, Lai Wei, Hua Xiansheng, et al. Video histogram: A novel video signature for efficient Web video duplicate detection[C] //Proc of the 2007 Int Conf on Multimedia Modeling. Berlin: Springer, 2007: 94-103
[25]Wu Xiao, Ngo C W, Hauptmann A G, et al. Real-time near-duplicate elimination for Web video search with content and context[J]. IEEE Trans on Multimedia, 2009, 11(2): 196-207
[26]Huang Zi, Shen Hengtao, Shao Jie, et al. Bounded coordinate system indexing for real-time video clip search[J]. ACM Trans on Information Systems, 2009, 27(3): No.17
[27]Huang Zi, Hu Bo, Cheng Hong, et al. Mining near-duplicate graph for cluster-based reranking of Web video search results[J]. ACM Trans on Information Systems, 2010, 28(4): No.22
[28]Jun W, Lee Y, Jun B M. Duplicate video detection for large-scale multimedia[J]. Multimedia Tools and Applications, 2016, 75(23): 15665-15678
[29]Zou Fuhao, Li Xiaowei, Xu Zhihua, et al. Image copy detection with rotation and scaling tolerance[J]. Journal of Computer Research and Development, 2009, 46(8): 1349-1356 (in Chinese)
(鄒復好, 李曉威, 許治華, 等. 抗旋轉和等比縮放失真的圖像拷貝檢測技術[J]. 計算機研究與發展, 2009, 46(8): 1349-1356)
[30]Lowe D G. Object recognition from local scale-invariant features[C] //Proc of the 7th IEEE Int Conf on Computer Vision. Piscataway, NJ: IEEE, 1999: 1150-1157
[31]Lowe D G. Distinctive image features from scale-invariant keypoints[J]. International Journal of Computer Vision, 2004, 60(2): 91-110
[32]Ke Y, Sukthankar R. PCA-SIFT: A more distinctive representation for local image descriptors[C] //Proc of the 2004 Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2004: 506-513
[33]Wu Xiao, Zhao Wanlei, Ngo C W. Near-duplicate keyframe retrieval with visual keywords and semantic context[C] //Proc of the 6th ACM Int Conf on Image and Video Retrieval. New York: ACM, 2007: 162-169
[34]Jégou H, Douze M, Schmid C. Hamming embedding and weak geometric consistency for large scale image search[C] //Proc of the 2008 European Conf on Computer Vision. Berlin: Springer, 2008: 304-317
[35]Zhou Zhili, Wang Yunlong, Wu Q J, et al. Effective and efficient global context verification for image copy detection[J]. IEEE Trans on Information Forensics and Security, 2017, 12(1): 48-63
[36]Perronnin F, Dance C. Fisher kernels on visual vocabularies for image categorization[C] //Proc of the 2007 Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2007: 1-8
[37]Jégou H, Douze M, Schmid C, et al. Aggregating local descriptors into a compact image representation[C] //Proc of the 2010 Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2010: 3304-3311
[38]Douze M, Jégou H, Schmid C, et al. Compact video description for copy detection with precise temporal alignment[C] //Proc of the European Conf on Computer Vision. Berlin: Springer, 2010: 522-535
[39]Liu Hong, Lu Hong, Wen Zhaohui, et al. Gradient ordinal signature and fixed-point embedding for efficient near-duplicate video detection[J]. IEEE Trans on Circuits and Systems for Video Technology, 2012, 22(4): 555-66[40]Zhu Yingying, Huang Xiaoyan, Huang Qiang, et al. Large-scale video copy retrieval with temporal-concentration SIFT[J]. Neurocomputing, 2016, 187(C): 83-91
[41]Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks[C] //Proc of the Advances in Neural Information Processing Systems. New York : Curran Associates, 2012: 1097-1105
[42]Jiang Yugang, Wang Jiajun. Partial copy detection in videos: A benchmark and an evaluation of popular methods[J]. IEEE Trans on Big Data, 2016, 2(1): 32-42
[43]Zhang Jing, Zhu Wenting, Li Bing, et al. Image copy detection based on convolutional neural networks[C] //Proc of the Chinese Conf on Pattern Recognition. Berlin: Springer, 2016: 111-121
[44]Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition[J]. arXiv: 1409.1556, 2014
[45]Szegedy C, Liu Wei, Jia Yangqing, et al. Going deeper with convolutions[C] //Proc of the 2015 Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2015: 1-9
[46]He Kaiming, Zhang Xiangyu, Ren Shaoqing, et al. Deep residual learning for image recognition[C] //Proc of the Conf on the 2016 Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2016: 770-778
[47]Perkins L N. Convolutional neural networks as feature generators for near-duplicate video detection[R]. Boston, MA: Boston University, 2015
[48]He Kaiming, Zhang Xiangyu, Ren Shaoqing, et al. Identity mappings in deep residual networks[C] //Proc of the 2016 European Conf on Computer Vision. Berlin: Springer, 2016: 630-645
[49]Wang Ling, Bao Yu, Li Haojie, et al. Compact CNN based video representation for efficient video copy detection[C] //Proc of the 2017 Int Conf on Multimedia Modeling. Berlin: Springer, 2017: 576-587
[50]Zagoruyko S, Komodakis N. Learning to compare image patches via convolutional neural networks[C] //Proc of the 2015 Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2015: 4353-4361
[51]Shen Hengtao, Ooi B C, Zhou Xiaofang. Towards effective indexing for very large video sequence database[C] //Proc of the 2005 ACM SIGMOD Int Conf on Management of Data. New York: ACM, 2005: 730-741
[52]Lin Ying, Yang Yang, Ling Kang, et al. Video copy detection based on multiple visual features synthesizing[J]. Journal of Image and Graphics, 2013, 18(5): 591-599 (in Chinese)
(林瑩, 楊揚, 凌康, 等. 多特征綜合的視頻拷貝檢測[J]. 中國圖像圖形學報, 2013, 18(5): 591-599)
[53]Bohm C, Gruber M, Kunath P, et al. Prover: Probabilistic video retrieval using the Gauss-tree[C] //Proc of the 23rd Int Conf on Data Engineering. Piscataway, NJ: IEEE, 2007: 1521-1522
[54]Weber R, Schek H J, Blott S. A quantitative analysis and performance study for similarity-search methods in high-dimensional spaces[C] //Proc of the 24th Int Conf on Very Large Data Bases. New York: VLDB Endowment, 1998: 194-205
[55]Weber R, B?hm K. Trading quality for time with nearest-neighbor search[C] //Proc of the 2000 Int Conf on Extending Database Technology: Advances in Database Technology. Berlin: Springer, 2000: 21-35
[56]Datar M, Immorlica N, Indyk P, et al. Locality-sensitive hashing scheme based onp-stable distributions[C] //Proc of the 20th Annual Symp on Computational Geometry. New York: ACM, 2004: 253-262
[57]Xu Zhe, Xue Zhifeng, Chen Fucai. Video copy detection based on improved affinity propagation[J]. Computer Engineering and Design, 2014, 35(9): 3185-3189 (in Chinese)
(許喆, 薛智鋒, 陳福才. 基于改進的近鄰傳播學習算法的視頻拷貝檢測[J]. 計算機工程與設計, 2014, 35(9): 3185-3189)
[58]Houle M E, Sakuma J. Fast approximate similarity search in extremely high-dimensional data sets[C] //Proc of the 21st Int Conf on Data Engineering. Piscataway, NJ: IEEE, 2005: 619-630
[59]Tao Y, Yi K, Sheng C, et al. Quality and efficiency in high dimensional nearest neighbor search[C] //Proc of 2009 ACM SIGMOD Int Conf on Management of Data. New York: ACM, 2009: 563-576
[60]Grauman K. Efficiently searching for similar images[J]. Communications of the ACM, 2010, 53(6): 84-94
[61]Liu Dawei, Yu Zhihua. A computationally efficient algorithm for large scale near-duplicate video detection[C] //Proc of the 2015 Int Conf on Multimedia Modeling. Berlin: Springer, 2015: 481-490
[62]Jégou H, Douze M, Schmid C. Improving bag-of-features for large scale image search[J]. Int Journal of Computer Vision, 2010, 87(3): 316-336
[63]Sivic J, Zisserman A. Video Google: A text retrieval approach to object matching in videos[C] //Proc of the 2003 IEEE Int Conf on Computer Vision. Piscataway, NJ: IEEE, 2003: 1470-1477
[64]Zhao Wanlei, Ngo C W. Flip-invariant SIFT for copy and object detection[J]. IEEE Trans on Image Processing, 2013, 22(3): 980-991
[65]Jiang Yugang, Ngo C W. Visual word proximity and linguistics for semantic video indexing and near-duplicate retrieval[J]. Computer Vision and Image Understanding, 2009, 113(3): 405-414
[66]Huang Zi, Shen Hengtao, Shao Jie, et al. Practical online near-duplicate subsequence detection for continuous video streams[J]. IEEE Trans on Multimedia, 2010, 12(5): 386-398
[67]Can T, Duygulu P. Searching for repeated video sequences[C] //Proc of the 2007 Int workshop on Workshop on Multimedia Information Retrieva. New York: ACM, 2007: 207-216
[68]Tan H K, Ngo C W, Chua T S. Efficient mining of multiple partial near-duplicate alignments by temporal network[J]. IEEE Trans on Circuits and Systems for Video Technology, 2010, 20(11): 1486-1498
[69]Pang Lei, Zhang Wei, Tan H K, et al. VIREO-VH: Video hyperlinking[R]. Hong Kong: City University of Hong Kong, 2012
[70]Smeaton A F, Over P, Kraaij W. Evaluation campaigns and TRECVID[C] //Proc of the 8th ACM Int Workshop on Multimedia Information Retrieval. New York: ACM, 2006: 321-330
[71]Over P, Awad G, Michel M, et al. Trecvid 2011—An overview of the goals, tasks, data, evaluation mechanisms and metrics[C] //Proc of the 2011 TRECVID Workshop. Gaithersburg, MD: NIST, 2011
[72]NIST. Guidelines for the TRECVID 2008 evaluation[EB/OL]. 2008[2016-12-12]. http://www-nlpir.nist.gov/projects/tv2008/tv2008.html
[73]Zhou Xiangmin, Zhou Xiaofang, Chen Lei, et al. An efficient near-duplicate video shot detection method using shot-based interest points[J]. IEEE Trans on Multimedia, 2009, 11(5): 879-891
[74]Douze M, Jégou H, Schmid C. An image-based approach to video copy detection with spatio-temporal post-filtering[J]. IEEE Trans on Multimedia, 2010, 12(4): 257-266
[75]Yeh Mei-Chen, Cheng Kwang-Ting. Video copy detection by fast sequence matching[C] //Proc of the ACM Int Conf on Image and Video Retrieval. New York: ACM, 2009: No.45
[76]Wu Xiao, Zhao Wanlei, Ngo C W. Efficient near-duplicate keyframe retrieval with visual language models[C] //Proc of 2007 IEEE Int Conf on Multimedia and Expo. Piscataway, NJ: IEEE, 2007: 500-503
[77]Tan H K, Wu Xiao, Ngo C W, et al. Accelerating near-duplicate video matching by combining visual similarity and alignment distortion[C] //Proc of the 16th ACM Int Conf on Multimedia. New York: ACM, 2008: 861-864
[78]Shang Lifeng, Yang Linjun, Wang Fei, et al. Real-time large scale near-duplicate Web video retrieval[C] //Proc of the 18th ACM Int Conf on Multimedia. New York: ACM, 2010: 531-540
[79]Zhao Wanlei, Ngo C W. Scale-rotation invariant pattern entropy for keypoint-based near-duplicate detection[J]. IEEE Trans on Image Processing, 2009, 18(2): 412-423
[80]Poullot S, Crucianu M, Buisson O. Scalable mining of large video databases using copy detection[C] //Proc of the 16th ACM Int Conf on Multimedia. New York: ACM, 2008: 61-70
[81]Law-To J, Buisson O, Gouet-Brunet V, et al. ViCopT: A robust system for content-based video copy detection in large databases[J]. Multimedia Systems, 2009, 15(6): 337-353

Gu Jiawei, born in 1992. Master candidate of computer science. His main research interests include image and video recognition.

Zhao Ruiwei, born in 1987. PhD candidate of computer science. His main research interests include image and video recognition.
Video Copy Detection Method: A Review
Gu Jiawei, Zhao Ruiwei, and Jiang Yugang
(SchoolofComputerScience,FudanUniversity,Shanghai201203)
Currently, there exist large amount of copy videos on the Internet. To identify these videos, researchers have been working on the study of video copy detection methods for a long time. In recent years, a few new video copy detection algorithms have been proposed with the introduction of deep learning. In this article, we provide a review on the existing representative video copy detection methods. We introduce the general framework of video copy detection system as well as the various implementation choices of its components, including feature extraction, indexing, feature matching and time alignment. The discussed approaches include the latest deep learning based methods, mainly the application of deep convolutional neural networks and siamese convolutional neural networks in video copy detection system. Furthermore, we summarize the evaluation criteria used in video copy detection and discuss the performance of some representative methods on five popular datasets. In the end, we envision future directions on this topic.
video copy detection; feature representation; performance evaluation; dataset; review
ang, born in 1981.
his PhD degree in computer science from City University of Hong Kong in 2009. Full professor at the School of Computer Science, Fudan University. Received the NSFC award for outstanding young researchers in 2016. His main research interests include multimedia content analysis and computer vision.

2017-01-03;
2017-03-07
國家自然科學基金優秀青年科學基金項目(61622204) This work was supported by the National Natural Science Foundation of China for Excellent Young Scientists (61622204).
TP311
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
海峽科技與產業(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
