基于ISODATA聚類算法的語音轉換研究
2017-06-27 08:14:13崔立梅李燕萍呂中良
計算機技術與發展 2017年6期
關鍵詞:模型
崔立梅,李燕萍,呂中良
(南京郵電大學 通信與信息工程學院,江蘇 南京 210003)
基于ISODATA聚類算法的語音轉換研究
崔立梅,李燕萍,呂中良
(南京郵電大學 通信與信息工程學院,江蘇 南京 210003)
提出了一種基于迭代自組織聚類算法(ISODATA)的雙線性頻率彎折語音轉換模型。根據語音特征參數分類不充分產生殘差成分的問題,在基于高斯混合模型的聚類過程中引入了迭代自組織聚類算法。該算法將聚類得到的類內均值作為訓練模型初始均值,改善了EM算法初始值選取不當導致算法不能收斂的問題,從而對特征參數的擬合更加準確,結合后續的雙線性頻率彎折(BLFW)模型實現語音轉換。實驗測試結果表明:提出的算法具有較好的自適應聚類特性,能夠使特征參數分類更合理,進而得到更準確的轉換函數,使得轉換的語音更接近目標語音。選擇合適的初始值參數,對提出的算法與高斯混合模型及雙線性頻率彎折模型進行比較,平均MCD值相差很小,平均MOS值有所提高。這說明合理精確的聚類有利于提高語音轉換系統的性能。
迭代自組織聚類算法;雙線性頻率彎折語音轉換模型;殘差成分;聚類特性
0 引 言
語音包含很多信息,其中最主要的就是語義信息,其次是個性化信息。語音轉換(Voice Conversion)就是要改變一個說話人(源說話人,source speaker)的語音個性特征信息,使之具有另外一個人(目標說話人,target speaker)的個性特征信息[1]。語音轉換是一種改變源說話人的聲音,使其聽起來具有目標說話人特性的技術。它在改變說話人個性特征的同時,保持語音的語義信息不變。
語音轉換的本質是對語音特征參數的轉換,因此首先是選取分析和合成語音的系統模型,提取好的語音特征參數。然后訓練并得到合適的轉換函數,最后進行轉換以及語音合成處理。
現在常用的語音特征參數包括LPC系數和MFCC參數,以及由LPC系數推演得到的包括LSP參數在內的一系列推演參數等。文中采用MFCC參數。語音轉換研究的核心問題是尋找能夠精確反映源說話人特征參數和目標說話人特征參數之間的映射關系,即轉換函數。目前較流行的語音轉換函數是基于高斯混合模型(Gaussian Mixture Model,GMM)。基于GMM模型的轉換方法具有較好的轉換效果,但存在轉換頻譜過平滑的問題,導致轉換后的語音自然度下降,嚴重影響了該方法的實用性。為了提高語音質量,A.Pribilova等提出了一種基于頻率彎折的轉換算法(DFW)[2],但轉換效果不佳。D.Erro綜合了基于GMM模型的轉換算法和頻率彎折算法的優勢,提出了一種在GMM模型的基礎上進行加權的頻率彎折算法(Weighted Frequency Warping,WFW),較好地平衡了語音質量和轉換性能之間的矛盾[3]。但是由于在轉換過程中未對幅度進行轉換,轉換的相似性一般。于是D.Erro提出了高斯混合模型+頻率彎折+幅度壓擴模型(GMM+FW+AS)。
為了進一步提高語音轉換的質量,D.Erro提出了殘差(residual)成分的概念,此處的殘差是指沒有被特征參數捕獲的語音信號譜成分[4]。其中一些語音信號譜成分未被捕獲是由于分類不合理造成的,于是文中提出了迭代自組織聚類算法+高斯混合模型+雙線性頻率彎折加幅度壓擴語音轉換模型(ISODATA+GMM+BLFWA),采用ISODATA聚類方法[5]替代GMM混合模型傳統的K均值法進行自適應無監督分類,獲得更為合理的聚類,能更好地捕獲特征參數的信息;在頻率彎折部分采用BLFW(雙線性頻率卷繞)+AS,比FW+AS更容易實現[6]。
文中研究在于,一方面利用ISODATA聚類方法實現語音特征參數的分類,結合后續的EM計算和BLFWA訓練及轉換得到ISODATA+GMM+BLFWA語音轉換模型,在此基礎上,調整ISODATA的初始參數得到最優分類數;另一方面在最優分類數的基礎上,比較ISODATA+GMM+BLFWA模型與GMM模型、FW模型、GMM+BLFW模型、GMM+BLFWA模型的轉換效果。
1 傳統的GMM+BLFWA轉換算法
在平行語料下,對目標語音和源語音分別提取特征參數MFCC,然后利用動態時間規整(Dynamic Time Warping,DTW)[7]算法進行時間對齊。將對齊的MFCC特征參數進行GMM模型訓練。
(1)

N(X;μi;Σi)=
(2)
其中,μi為均值矢量;Σi為協方差矩陣。
完整的混合高斯模型由協方差、參數均值向量和混合權重組合而成,表示為λ={wi,μi,Σi}[8]。對GMM模型參數λ的估計常常采用EM(Expectation Maximumzation)算法[9-10]。在采用EM算法估計GMM模型參數時,必須要先確定GMM模型的高斯分量個數M和模型的初始參數λ。傳統的GMM模型的高斯分量個數M一般為8,16,32,64等;初始參數λ采用K均值算法將特征參數歸為與高斯分量個數相等的各個類中,然后分別計算各個類的均值、方差,作為初始均值和方差;權值是各個類中所包含的特征矢量個數占總特征矢量個數的比率。確定初始參數λ后,采用EM算法估算出一個新的模型參數,使得新的模型參數下的似然度大于初始參數下的似然度。經過多次迭代得到最終λ。
經過GMM模型訓練后進行雙線性頻率彎折訓練,其中雙線性函數的特征為只需要一個參數α確定。
(3)
若給定一個因果且時間離散序列x[n]及其Z變換X[z],可根據Y[z]=X[zα]計算得到一個新序列y[n],即y[n]為X[zα]的逆Z變換[11-13]。
(4)
實際上,上述理論也適用于倒譜序列,其中Z〗變換對應于log幅度譜。給定一個p維倒譜矢量X,倒譜矢量y對應于頻率彎折函數[11-13]:
(5)
GMM+BLFWA模型中用到的雙線性頻率彎折函數為:
y=Wα(X,θ)X+s(X,θ)
(6)
其中,W由式(5)確定;α(X,θ)和s(X,θ)分別為頻率彎折因子和幅度壓擴因子,由式(7)確定:
(7)
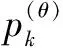
(8)
由式(7)可知,頻率彎折因子和幅度壓擴因子是根據GMM模型訓練得到的,此時GMM模型訓練及BLFWA模型訓練結束。頻率彎折因子和幅度壓擴因子確定后,即可得到轉換函數,通過轉換函數對新語音進行轉換。
2 改進的GMM+BLFWA轉換算法及系統框架
2.1 ISODATA+GMM+BLFWA算法
從上節可以看出,傳統的GMM+BLFWA轉換算法中每個說話人賦予的模型結構完全相同,人為確定聚類數然后采用K均值法對特征參數進行分類。但是每個說話人語音信號短時頻譜的概率分布并不完全相同,這樣就會導致語音特征參數分布聚類擬合不精確,帶來較大誤差并影響頻率彎折中參數的估計。因此,文中提出了ISODATA+GMM+BLFWA模型,根據每個說話人具體語音特征分布選擇高斯混合數,建立與之相應的模型結構,使每個模型結構更好地擬合每個說話人的具體特征分布,從而提高語音轉換準確率。該模型利用ISODATA對特征參數矢量序列進行無監督分類,在樣本均值迭代中根據預先設定的閾值進行反復修改,以達到合理分類數。
2.2 整個轉換系統框圖
系統轉換框圖見圖1。
從圖中可以看出,語音轉換可以分為兩個階段,即訓練階段和轉換階段。在訓練階段,語音信號首先利用AhoTransf[14]語音信號建立模型。該模型可作為語音信號分析/合成模型。提取出參數MFCC和logf0,其中MFCC用于訓練頻率彎折轉換函數。得到MFCC參數后進行時間對齊DTW,形成兩個一一對應的時間序列,再利用ISODATA算法進行聚類,得到合理分類的梅爾特征參數。進而將梅爾特征參數進行GMM訓練,獲得概率函數P及均值、方差等一系列參數。利用GMM訓練得到的概率函數P及對齊的MFCC特征源序列和目標序列進行BLFWA訓練,得到頻率彎折因子和幅度壓擴因子,根據式(6)得到頻率彎折曲線函數,即轉換函數。
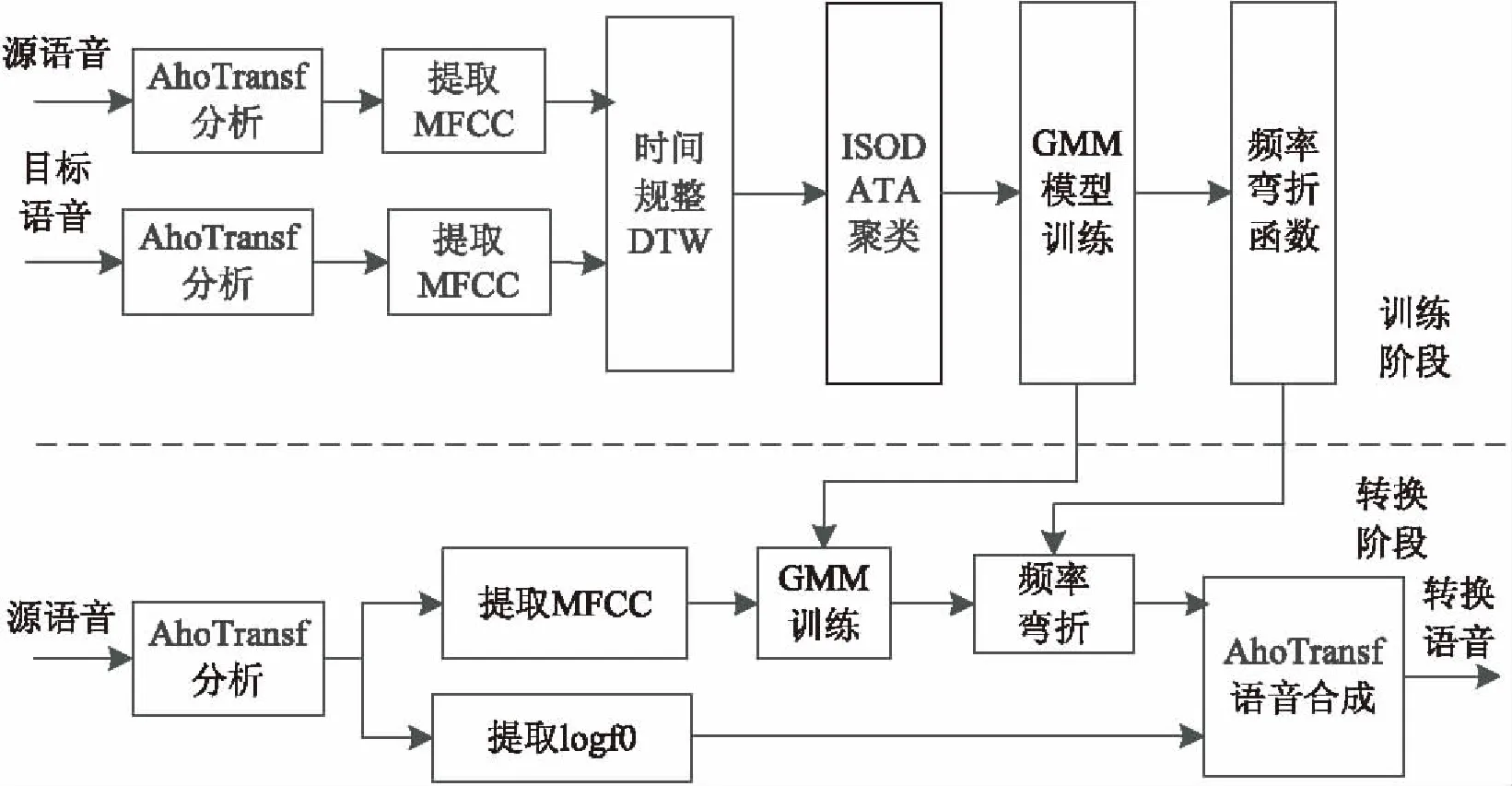
圖1 系統轉換框圖
在轉換階段,源語音信號經過AhoTransf得到MFCC和log基音頻率,其中對MFCC進行GMM訓練,利用訓練階段獲得的GMM模型均值、方差等參數訓練得到概率P。獲得概率P后加上訓練階段得到的頻率彎折因子和幅度壓擴因子(即轉換函數)對輸入的待轉換源語音進行BLFWA轉換,轉換后的頻譜加上log基音頻率通過AhoTransf模型合成出轉換后的語音信號。
3 實驗結果分析
3.1 語音庫
實驗采用的語音庫CMU ARCTIC是由卡內基梅隆大學的語言技術研究所創建的美式英語單說話人平行語音庫,包括5男2女。該實驗采用的特征參數為MFCC矢量,信號的采樣率為16 kHz。抽取其中4個人的語音,即2個男聲和2個女聲,分別命名為M1、M2和F1、F2。每個人都取60個語句,每個語句大概為3~4 s時長的短語,其中50個用于訓練,10用于測試。而且每個人的發音內容相同,為對稱的語音庫。
經過大量實驗發現,在ISODATA聚類過程中,θc=0.2(合并依據的聚類中心距離閾值),θs=0.01(類內標準差閾值),C>35(預期的類數)時,獲得最大分類數31,且實驗所獲得轉換語音最佳。于是不同模型分類數均設置為31并進行比較。
3.2 客觀評價
整個實驗根據轉換方向的不同分為4部分,分別是女聲轉換為男聲(F1-M1)、女聲轉換為女聲(F1-F2)、女聲轉換為男聲(F2-M2)和男聲轉換為男聲(M2-M1)。采用梅爾倒譜失真(Mel-Cepstral Distortion,MCD)[15]作為反映語音轉換性能的客觀準則。
MCD(Vtarg,Vref)=
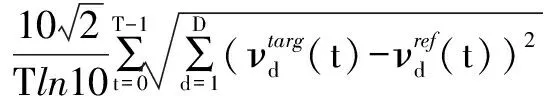
(9)
其中,MFCC參數為20-D梅爾倒譜參數,使用νd(t)表示,0≤d≤19,在計算MCD時,去掉第一維參數;T為MFCC經過DTW對齊后的總幀數。
不同轉換模型下的MCD值見圖2。

圖2 不同轉換模型下的MCD值
從圖2可以看出,BLFW、GMM+BLFW、GMM+BLFWA和ISODATA+GMM+BLFWA的MCD值是依次遞減的,這說明ISODATA+GMM+BLFWA的轉換效果比上述幾種模型要好。經過計算,ISODATA+GMM+BLFWA的平均MCD值為5.496,GMM模型的平均MCD值為5.0431,說明ISODATA+GMM+BLFWA模型和GMM模型的轉換相似性基本相當。
3.3 主觀評價
實驗的主觀評價采用平均主觀意見分(MOS)。讓聽音人聽完轉換語音后,給出意見分(5:優秀,4:良好,3:一般,2:較差,1:很差)[16]。測試結束后,統計出平均意見得分。MOS越高,說明轉換語音的清晰度和可懂度越好。結果如圖3所示。
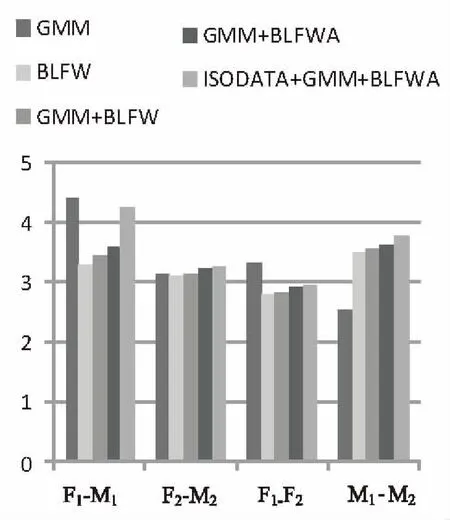
圖3 不同轉換模型下的MOS值
從圖3可以看出,采用文中方法訓練的主觀意見得分明顯高于BLFW、GMM+BLFW和GMM+BLFWA的MOS分,表明改進的ISODATA+GMM+BLFWA模型轉換的語音目標傾向性和質量有明顯改善,降低了殘差分量造成的影響;經過計算,ISODATA+GMM+BLFWA的平均MOS值為3.568,GMM模型的平均MOS值為3.342,說明ISODATA+GMM+BLFWA模型轉換音質比GMM模型好。
4 結束語
ISODATA+GMM+BLFWA模型通過ISODATA聚類算法對語音特征參數進行處理和分析,得到更為精確的分類。從MOS及MCD測試結果表明,改進的ISODATA+GMM+BLFWA模型有效地降低了殘差分量造成的影響,在保證變換語音目標傾向性的同時,提高了轉換語音的音質。
[1] 趙 力.語音信號處理[M].北京:機械工業出版社,2003.
[2] 李 波,王成友,蔡宣平,等.語音轉換及相關技術綜述[J].通信學報,2004,25(5):109-118.
[3] Erro D, Moreno A, Bonafonte A.Voice conversion based on weighted frequency warping[J].IEEE Transactions on Audio,Speech and Language Processing,2010,18(5):922-931.
[4] Erro D,Polyakova T,Moreno A.On combining statistical me-thods and frequency warping for high-quality voice conversion[C]//International conference on acoustics,speech and signal processing.[s.l.]:IEEE,2008:4665-4668.
[5] 孫即詳.現代模式識別[M].長沙:國防科技大學出版社,2002.
[6] Erro D,Navas E,Hernaez I.Parametric voice conversion ba-sed on bilinear frequency warping plus amplitude scaling[J].IEEE Transactions on Audio,Speech,and Language Processing,2013,21(3):556-566.
[7] 徐小峰.基于GMM的獨立建模語音轉換系統研究[D].蘇州:蘇州大學,2010.
[8] 王韻琪,俞一彪.自適應高斯混合模型及說話人識別應用[J].通信技術,2014,47(7):738-743.
[9] Demrsrsa A P, Lamb N M,Rubin D B.Maximum likelihood from incomplete data via the EM algorithm[J].Journal of the Royal Statistical Society:Series B,1977,39(1):1-38.
[10] Xu L,Jordan M I.On convergence properties of the EM algorithm for Gaussian mixtures[J].Neural Computation,1996,8(1):129-151.
[11] McDonough J, Byrne W. Speaker adaptation with all-pass transforms[C]//International conference on acoustics,speech,and signal processing.[s.l.]:IEEE,1999:757-760.
[12] Pitz M,Ney H.Vocal tract normalization equals linear transformation in cepstral space[J].IEEE Transactions on Speech and Audio Processing,2005,13(5):930-944.
[13] Emori T,Shinoda K.Rapid vocal tract length normalization using maximum likelihood estimation[C]//Proceedings of Eurospeech.[s.l.]:[s.n.],2001:1649-1652.
[14] Saratxaga I,Hernáez I,Navas E,et al.AhoTransf:a tool for multiband excitation based speech analysis and modification[C]//Proceedings of LREC.[s.l.]:[s.n.],2010:3733-3737.[15] Shuang Z,Meng F,Qin Y.Voice conversion by combining frequency warping with unit selection[C]//International conference on acoustics,speech and signal processing.[s.l.]:IEEE,2008:4661-4664.
[16] 張雄偉,陳 亮,楊吉斌.現代語音處理技術及應用[M].北京:機械工業出版社,2003.
Research on Voice Conversion Based on Self Organizing Clustering and Frequency Warping
CUI Li-mei,LI Yan-ping,LYU Zhong-liang
(College of Communication & Information Engineering,Nanjing University of Posts and Telecommunications,Nanjing 210003,China)
A voice conversion model of bilinear frequency warping based on Iterative Self-Organizing clustering Data Analysis Techniques Algorithm (ISODATA) is put forward.According to the residual components generated by insufficient classification of speech feature parameters,in the clustering process based on Gaussian mixture model,the iterative self-organizing clustering algorithm is introduced.It takes average value within class obtained by clustering as the initial mean for training model,which improves the problem that the algorithm cannot converge due to inappropriated initial value selection of EM algorithm,thus making the characteristic parameters fitting more accurate,realization of voice conversion with subsequent bilinear frequency warping (BLFW) model.The experimental results show that the proposed algorithm has better adaptive clustering characteristics,which can make the characteristic parameters classification more reasonable,and get more accurate conversion function,making the speech more close to the target speech.Choosing appropriate initial value parameters,the algorithm proposed is compared with the Gauss mixture model and the bilinear frequency warping model.The average MCD value is very small,and the average MOS value is high.This shows that reasonable and accurate clustering is beneficial to improve the performance of speech conversion system.
iterative self-organizing clustering algorithm;bilinear frequency warping voice conversion model;residual components;clustering characteristics
2016-06-08
2016-10-11 網絡出版時間:2017-04-28
國家自然科學基金資助項目(61401227);江蘇省博士后基金(1402067B)
崔立梅(1988-),女,碩士研究生,研究方向為語音轉換;李燕萍,博士,副教授,研究生導師,通訊作者,研究方向為語音轉換和說話人識別。
http://kns.cnki.net/kcms/detail/61.1450.TP.20170428.1702.024.html
TP301.6
A
1673-629X(2017)06-0106-04
10.3969/j.issn.1673-629X.2017.06.022
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
