級聯式低消耗大規模網頁分類在線獲取方法
2017-06-27 08:10:42王亞強舒紅平
計算機應用 2017年4期
王亞強,湯 銘,曾 沁,唐 聃,舒紅平
1.成都信息工程大學 軟件工程學院, 成都 610225; 2.廣東省氣象臺,廣州 510080)(*通信作者電子郵箱yaqwang@cuit.edu.cn)
級聯式低消耗大規模網頁分類在線獲取方法
王亞強1*,湯 銘1,曾 沁2,唐 聃1,舒紅平1
1.成都信息工程大學 軟件工程學院, 成都 610225; 2.廣東省氣象臺,廣州 510080)(*通信作者電子郵箱yaqwang@cuit.edu.cn)
針對海量網頁在線自動高效獲取網頁分類系統設計中如何更有效地平衡準確度與資源開銷之間的矛盾問題,提出一種基于級聯式分類器的網頁分類方法。該方法利用級聯策略,將在線與離線網頁分類方法結合,各取所長。級聯分類系統的一級分類采用在線分類方法,僅利用錨文本中網頁標題包含的特征預測其分類,同時計算分類結果的置信度,分類結果的置信度由分類后驗概率分布的信息熵度量。若置信度高于閾值(該閾值采用多目標粒子群優化算法預先計算取得),則觸發二級分類器。二級分類器從下載的網頁正文中提取特征,利用預先基于網頁正文特征訓練的分類器進行離線分類。結果表明,相對于單獨的在線法和離線法,級聯分類系統的F1值分別提升了10.85%和4.57%,并且級聯分類系統的效率比在線法未降低很多(30%左右),而比離線法的效率提升了約70%。級聯式分類系統不僅具有更高的分類能力,而且顯著地減少了分類的計算開銷與帶寬消耗。
大規模網頁數據獲取;網頁分類;級聯分類器;置信度函數;多目標粒子群優化
0 引言
隨著網絡的飛速發展和普及,互聯網已成為人類獲取日常生活、工作和社會熱點信息的重要信息來源。為滿足不同人群對信息內容的差異性需求,各類信息通過不同的網絡途徑進行著傳播,并且數據量已成規模。如何在互聯網中根據網頁主題內容的不同,實現對大規模網頁資源的自動整理和分類,是大數據研究的重點內容之一,對幫助人類高效地獲取信息、提高工作效率和生活質量具有重要的意義。
目前,實現大規模網頁資源的自動分類的方法主要分為兩種:離線法和在線法[1]。離線法是一種傳統、樸素的網頁資源分類方法,該方法利用網絡爬蟲,無約束地在互聯網中抓取網頁,然后基于樸素貝葉斯(Na?ve Bayes,NB)[2-3]、支持向量機(Support Vector Machine,SVM)[4-5]等分類方法,離線完成對網頁內容的分類。該類方法充分利用網頁中包含的特征信息訓練分類器,可獲得良好的網頁分類性能。然而離線法的良好分類性能建立在大量網絡資源被浪費的條件下,文獻[6]中報道的結果顯示,在給定資源條件下,離線的網頁正文提取速度是每一萬篇網頁平均消耗140 min,遠大于網頁抓取速度,這類資源消耗在大數據時代將是驚人的。
在線法是近年提出的一種較新穎的方法[7],該類方法利用網絡爬蟲在爬取網頁的過程中獲取到的與網頁內容相關的特征信息(錨文本、網頁URL及上下文信息)訓練分類器,然后將該分類器集成到網絡爬蟲中,實現網絡爬蟲在線對目標網頁內容類別進行判定,如果與目標類別相關,才將該網頁下載并存儲管理。該類方法能有效地降低網絡資源的消耗,降低離線網頁數據管理的復雜性,而且在相同帶寬的條件下,具有更快的網頁分類速度和更少的網絡資源消耗[8]。然而,由于分類器所利用特征信息有限,網頁分類性能在較嚴格的約束條件下相對較低。
針對兩類方法在網頁分類質量和資源收集效率方面的各自優勢,本文采用級聯策略,按分類器復雜度遞增的順序,構建多級網頁內容決策序列,并通過在各級增加置信度閾值的方式,協調系統整體的分類質量和效率開銷;同時,提出基于熵的多目標粒子群優化方法實現置信度閾值的自動選取。分類器級聯思想在機器學習領域已有一定的理論研究[9-10],本文將其引入高效的大規模網頁分類資源獲取應用中,以實現低消耗、高質量的網頁分類在線獲取。
1 級聯式網頁分類系統
在線法具有低網絡資源消耗的特點,而離線法具有高準確度的優勢,為綜合兩種方法的各自優點,級聯式網頁分類系統應兼顧彼此,在盡量保證準確度的情況下,實現網絡資源的低消耗。
1.1 基本框架
目前,網頁分類常采用基于統計的分類模型,如樸素貝葉斯[2-3]、支持向量機[4-5]。該類方法一般為待分類網頁產生屬于某類別的概率值,然后將這個預測值與預先設定的分類閾值進行比較,若大于該閾值,則將其劃分到該類別下。以該思想為基礎,在進行級聯分類系統的設計時,可通過預先設定較高的置信度閾值,將在線法能夠以較高置信度確認分類的網頁直接丟棄或分類并下載保存,而將判別結果模糊的網頁交給分類準確度較高的離線法進一步分析確認,以此實現兩種方法的優勢綜合,其基本框架如圖1所示。
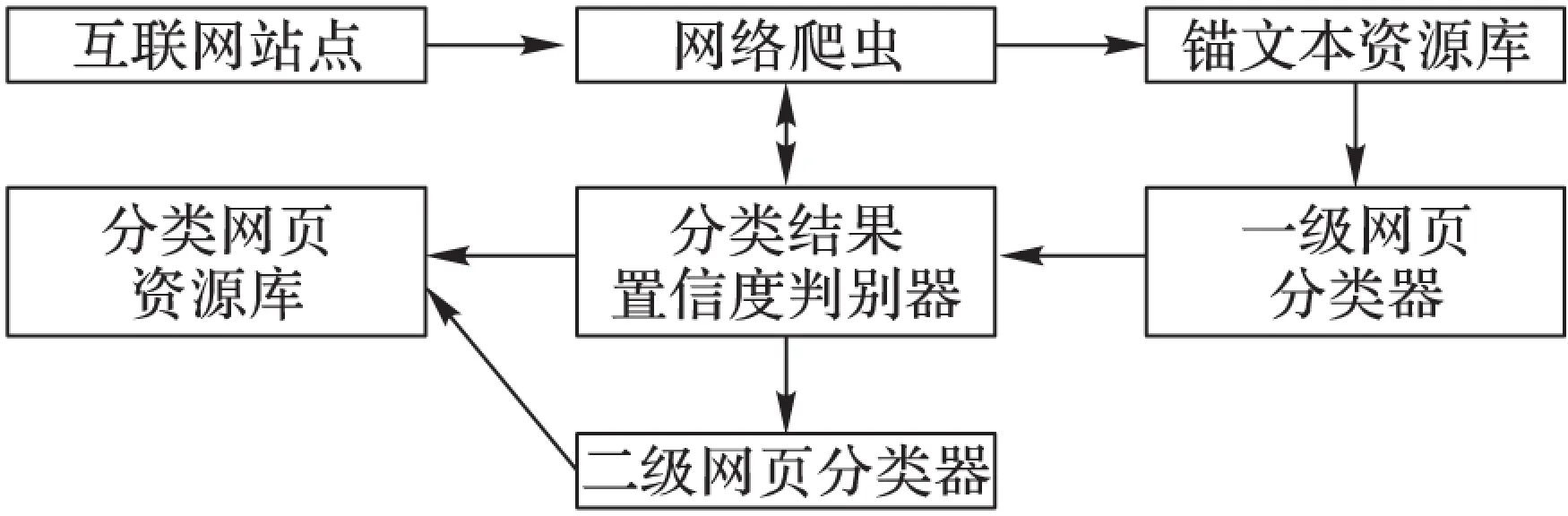
圖1 級聯式分類系統的基本框架
該框架的設計目標是滿足大規模網頁資源的收集和分類的實時系統,其輸入是從網頁中獲取的錨文本及URL,輸出是對該網頁分類的結果。其運行過程如下:
步驟1 網絡爬蟲解析網頁并獲取其中包含的錨文本資源信息。
步驟2 將錨文本進行分詞(本文的分詞均采用開源的NLPIR工具完成,http://ictclas.nlpir.org/),并將其作為分類特征輸入一級分類器。
步驟3 根據一級分類器輸出的網頁分類的后驗概率預測值,使用置信度函數(判別器)量化該判別結果的置信度。
步驟4 若預測值高于預先給定的置信度閾值,那么認為本次判斷置信度足夠高,并將判斷結果作為該網頁的最終分類結果,保存至分類網頁資源庫;若預測值低于預先給定的置信度閾值,那么拒絕一級分類器的判別結果,此時,網絡爬蟲將下載該錨文本的URL所對應的網頁,抽取網頁正文并分詞提取特征,將網頁正文特征交由二級分類器進行處理。
步驟5 根據網頁正文包含的豐富的分類特征信息,二級分類器進行更準確的網頁分類,并將該分類結果作為該網頁最終的分類結果保存至分類網頁資源庫。
1.2 置信度函數的確定方法
在1.1節所述的框架中,其核心在于如何有效地確定其中包含的置信度閾值,該閾值由置信度函數衡量,合理的定義置信度函數將直接影響系統整體的性能。
本文的置信度函數,用于確定在給定錨文本特征x的條件下,網頁被判定為類別cj的后驗概率P(cj|x),是否具有較高的置信度將該網頁劃分至類別cj。條件概率分布P(cj|x)的確定與不確定性判斷結果如圖2所示。從圖2可看出:在P(cj|x)分布較均勻的情況下,分類結果的可判別性較低;而分布越不均勻,則其分類結果的可判別性較高。根據此特性,在本文提出的框架中,一級分類器輸出結果是否會交由二級分類器進行進一步的判別,可由該特性對應的判別函數進行度量。
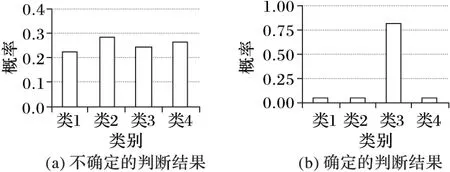
圖2 條件概率分布的確定與不確定判斷結果情況
信息熵是用于度量變量不確定性的重要函數。熵值越大,則說明變量的不確定性越大;熵值越小,則變量的不確定性越小。根據這一思路,本文采用網頁分類條件概率分布P(cj|x)的信息熵作為置信度度量函數,其度量方法如式(1)所示:
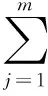
(1)
其中:C為預先確定的網頁類別劃分的集合;m為集合C的大小。H(C)值越大,網頁分類條件概率分布越均勻,則網頁類別劃分越不確定;置信度度量函數結果值越小,說明網頁分類條件概率分布越不均勻,決策結果的置信度越高,越容易根據分類器得到的網頁分類概率分布確定當前網頁類別的具體劃分。如圖2(a),該網頁分類條件概率分布的信息熵值約為0.600 3,當前待分類網頁屬于各類別的概率相當,類別劃分的不確定性較高;而圖2(b)中的網頁分類條件概率分布的信息熵值約為0.290 6,且更容易判別當前待分類網頁的所屬類別劃分。
1.3 置信度閾值的選取方法
置信度閾值選取的本質是參數優化問題,首先需要確定優化的目標。網頁分類屬于文本分類任務,其優化目標一般包括準確度、宏F1值和時間開銷。本文將置信度閾值的選取定為多目標優化問題[11]:在給定準確度、宏F1值和時間開銷的條件下,尋找能夠獲得最優分類結果的閾值。
為選取優化置信度閾值,本文采用多目標粒子群優化(Multi-ObjectiveParticleSwarmOptimization,MOPSO)算法尋找最優閾值,優化的目標為分類的準確度、宏F1值和被一級分類器拒絕的樣本數量。其中,“被一級分類器拒絕的樣本數量”是對級聯分類器的“時間開銷”的近似估計,而“被一級分類器拒絕的樣本”是指那些無法被一級分類器以較高的置信度(詳見1.2節)來判斷分類的網頁。
為確保解的多樣性和非支配解分布的均勻性,本文采用文獻[12]提出的最大擁擠距離的粒子更新策略:當所有粒子都能找到第一前沿時,迭代結束。由于分類準確度和時間開銷之間存在矛盾,同時找到兩者的最優值是不可能的,只能通過MOPSO找出多個非支配解,這些解一并構成Pareto前沿[13],再根據實際需求(即系統的實現需求是更重視高準確度,還是更重視降低資源開銷,又或者要求兩者均衡),動態地選擇最佳閾值。
1.4 級聯分類系統的時間開銷估算
系統的真實總體時間開銷難以直接求得,考察級聯分類系統框架發現,系統的分類時間其實與一級分類器拒絕的樣本數有關,即一級分類器拒絕的樣本數越多,那么二級分類器需要進行判別的樣本就越多,時間開銷就越大。
表1為一級分類器的分類情況。
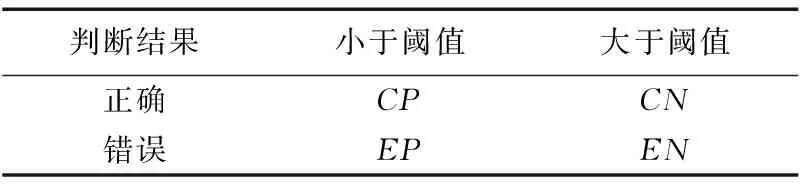
表1 一級分類器的分類情況
表1中:CP為該分類器正確分類且被保留未傳遞給二級分類器的網頁總數;CN為該分類器正確判別,但由于其分類結果的條件概率分布的熵值高于預先設定的閾值,因此被誤傳遞給二級分類器進行進一步判別的網頁總數;EP為該分類器判斷錯誤但因該判別得到的條件概率分布的熵值高于預先設定的閾值而被誤保留的網頁總數;EN為一級分類器無法準確判斷且通過置信度正確被過濾傳遞給二級分類器進行進一步判別的網頁總數。
級聯分類系統的理論開銷時間Tc可通過式(2)得出。
Tc=T1+T2=N·v1+(CN+EN)·v2
(2)
其中:T1和T2分別是一級分類器和二級分類器的時間開銷;v1和v2分別表示一級分類器和二級分類器處理網頁相關特征的平均速度;N為分類網頁樣本總量。由此分析可知,級聯分類系統的分類時間與拒絕樣本總數(CN+EN)正相關,而與預先設定的置信度閾值負相關。因此,本文使用一級分類器的拒絕樣本數衡量系統的時間開銷。
2 實驗結果及分析
2.1 分類器參數的設定
本文使用的實驗數據來源于新浪、網易和鳳凰網上六類欄目的新聞網頁,分別是娛樂、財經、游戲、軍事、體育、科技,網頁總數為90 206。文獻[7]驗證了樸素貝葉斯(NB)分類器用于在線分類具有良好的性能,文獻[5,14-15]證明了SVM一般是最優的網頁離線分類器,因此,本文以NB作為在線一級分類器,SVM作為離線二級分類器(用“NB+SVM”表示)。驗證本文提出的級聯式網頁分類獲取策略的有效性,采用10折交叉驗證方法,以各分類器在每個類別下的F1值作為分類性能的整體評價結果。
在本文實驗中,使用徑向基函數作為SVM的核函數,其包含的參數c和γ分別定為851和1.5,為SVM在本文數據集上取得最優分類結果時的參數,限于篇幅未在本文贅述SVM的參數調優結果。
2.2NB與SVM的性能分析
在線法的分類(即利用NB進行網頁分類)依據是錨文本特征,而離線分類則利用的是目標網頁中包含的正文內容,后者需要從包含大量噪聲的網頁中選取特征,本文主要研究級聯分類策略,因此,網頁正文的抽取采用基于規則的方法完成。圖3給出了在線法和離線法在六個類別下的F1值分類結果,該結果與2.1節描述的前人的研究結果保持一致。
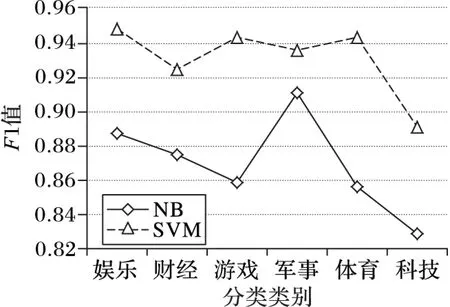
圖3 在線與離線方法在預定類別下的F1值
2.3 置信度閾值與樣本數的相關性分析
為了分析置信度閾值與拒絕樣本數的關系,首先在熵值的值域內等間距取格點,在NB+SVM級聯分類系統上進行分類實驗,得到如圖4所示結果。從圖4可看出,樣本總數(即一級分類器要作判別的網頁總數)始終保持不變,即所有網頁均要經過一級分類器進行判別,這與事實相符。而拒絕樣本總數(即利用置信度閾值過濾的無法判別網頁樣本總數)隨閾值的增大而減少,驗證了1.4節提出的利用拒絕樣本數衡量系統時間開銷的合理性。
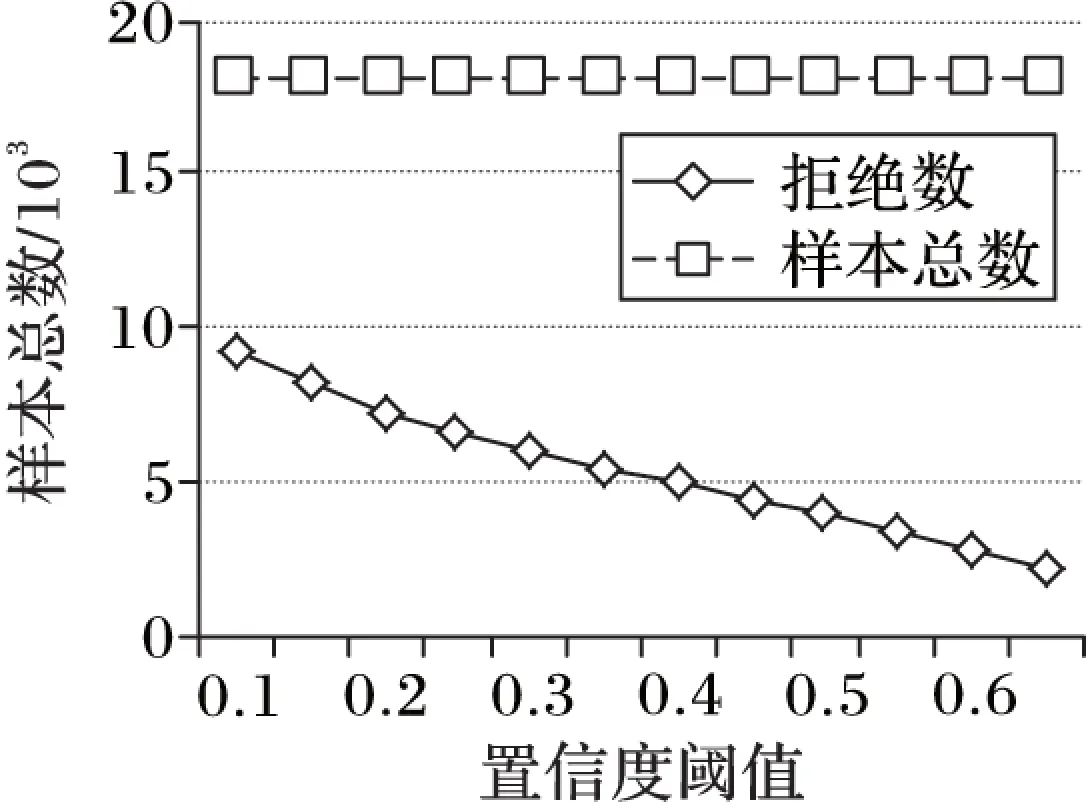
圖4 置信度閾值與樣本數的相關性
2.4 置信度閾值的選取
置信度閾值的大小同時影響級聯分類系統的優化目標、分類準確度和分類時間,使用信息熵作為置信度函數時,熵值取得越小,對置信度的要求就越高,拒絕樣本數就越多,分類時間越長。相比拒絕樣本數,分類系統的準確度和熵值之間并沒有明確關系,因此本文通過MOPSO尋找一組閾值的最優解集。圖5給出了該系統在“拒絕樣本比例”和“宏F1值”下32個粒子迭代60次的Pareto曲線。從圖5中看出,兩個優化目標之間存在明顯的制約關系,對于其中一個目標的優化必須以犧牲另一個目標的性能作為代價。由于Pareto曲線上的點均為模型的可行解,因此認為最優閾值應根據實際工程需求,在Pareto曲線上動態地選取(正如1.3節所述)。此外曲線在“拒絕樣本比例”上分布更廣,說明閾值對整個系統的時間性能影響較大,本文以給定宏F1值為0.956 7時最小化時間開銷為后續級聯分類系統的測試方案,即從曲線的左側取值,將0.273 9作為該系統的置信度閾值以分析系統的分類能力。
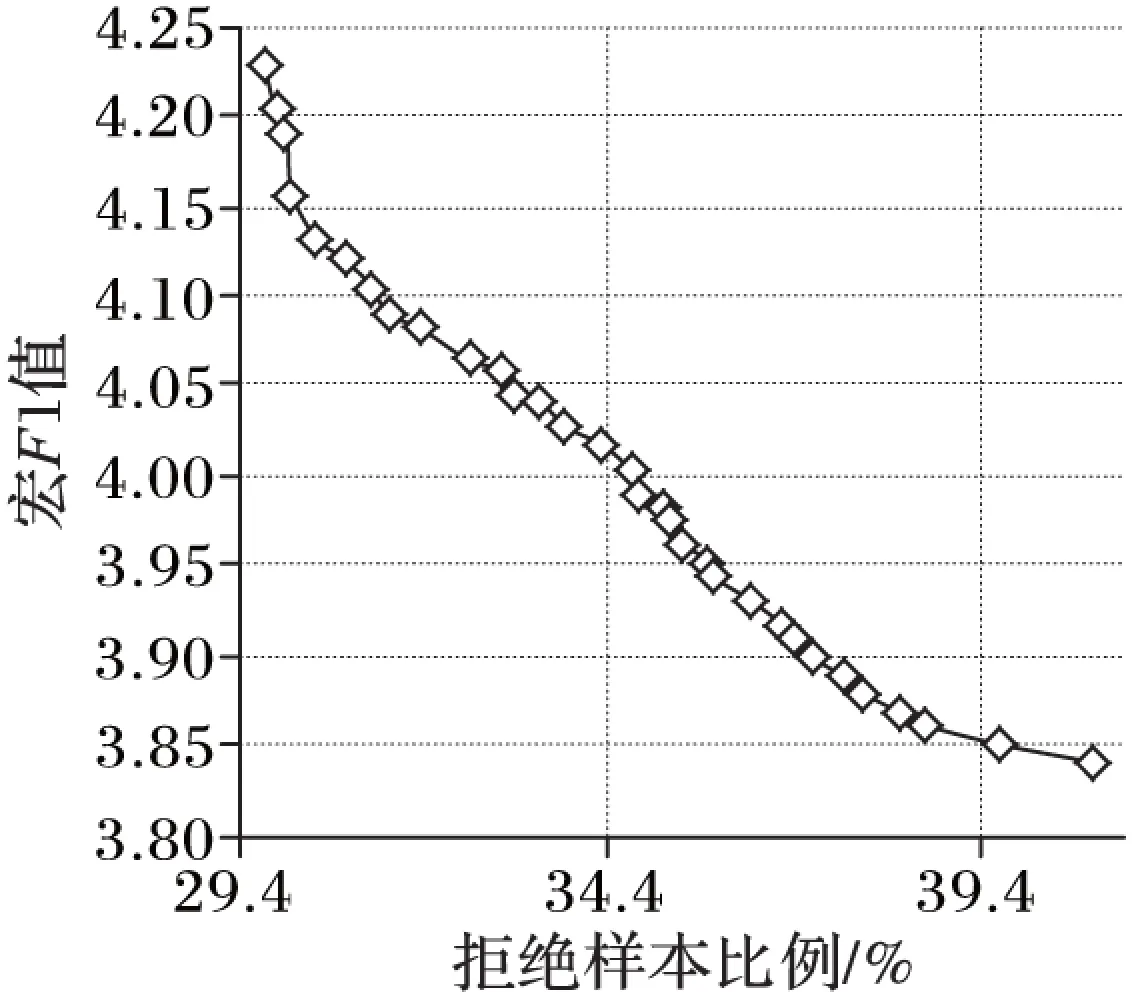
圖5 NB+SVM級聯分類系統的置信度閾值Pareto曲線
2.5 級聯分類系統的分類能力分析
圖6對比了NB+SVM級聯分類系統與單獨使用NB作在線分類和單獨使用SVM作離線分類在各類別下的F1值結果。從圖6中可以看到,級聯分類系統具有更準確和更穩定的分類性能,在各類別上的分類性能均有提升。特別是對科技類網頁的識別,性能提升明顯,其平均F1值達到0.959 6。并且,相對于單獨使用NB作在線分類和單獨使用SVM作離線分類,其F1值分別提升了10.85%和4.57%。
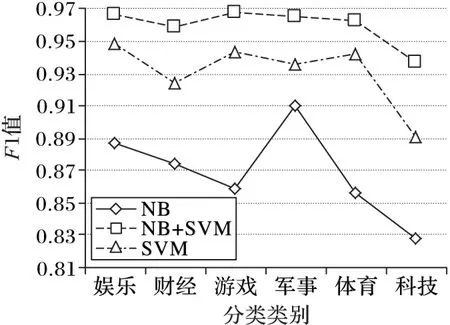
圖6 在線、離線和級聯分類系統在預定類別下的F1值
此外,從圖6可以看到,級聯分類系統(NB+SVM)的分類性能更加穩定,在各類別下的分類水平比單獨的離線法(SVM)和在線法(NB)均得到改善,且類別之間的分類性能差異得到改善,實現了各類別的分類性能的兼顧,達到了級聯分類系統“優勢能力互補”的目標。
為進一步驗證級聯分類系統的分類性能,本文還實現了使用NB做在線分類、K近鄰(K-Nearnest Neighbors, KNN)作離線分類的對比實驗,圖7給出了該組實驗結果。從圖7中可以明顯看到,級聯分類系統的性能始終優于單獨采用在線法和離線法,并且同樣實現了各類別分類性能的兼顧,達到了級聯分類系統“能力互補”的目標。
此外,從時間開銷成本上看,級聯分類系統在一級分類階段平均約有31.38%(NB+SVM約有30.14%,NB+KNN約有32.61%)的實例交由二級分類器進行處理。這意味著級聯分類系統不僅可有效地提升了網頁分類的總體能力,同時,取得該明顯的分類能力提升,只需要消耗比在線法多出30%左右的時間消耗。而對比于離線法,級聯分類系統可以大大降低其時間消耗(約70%)。
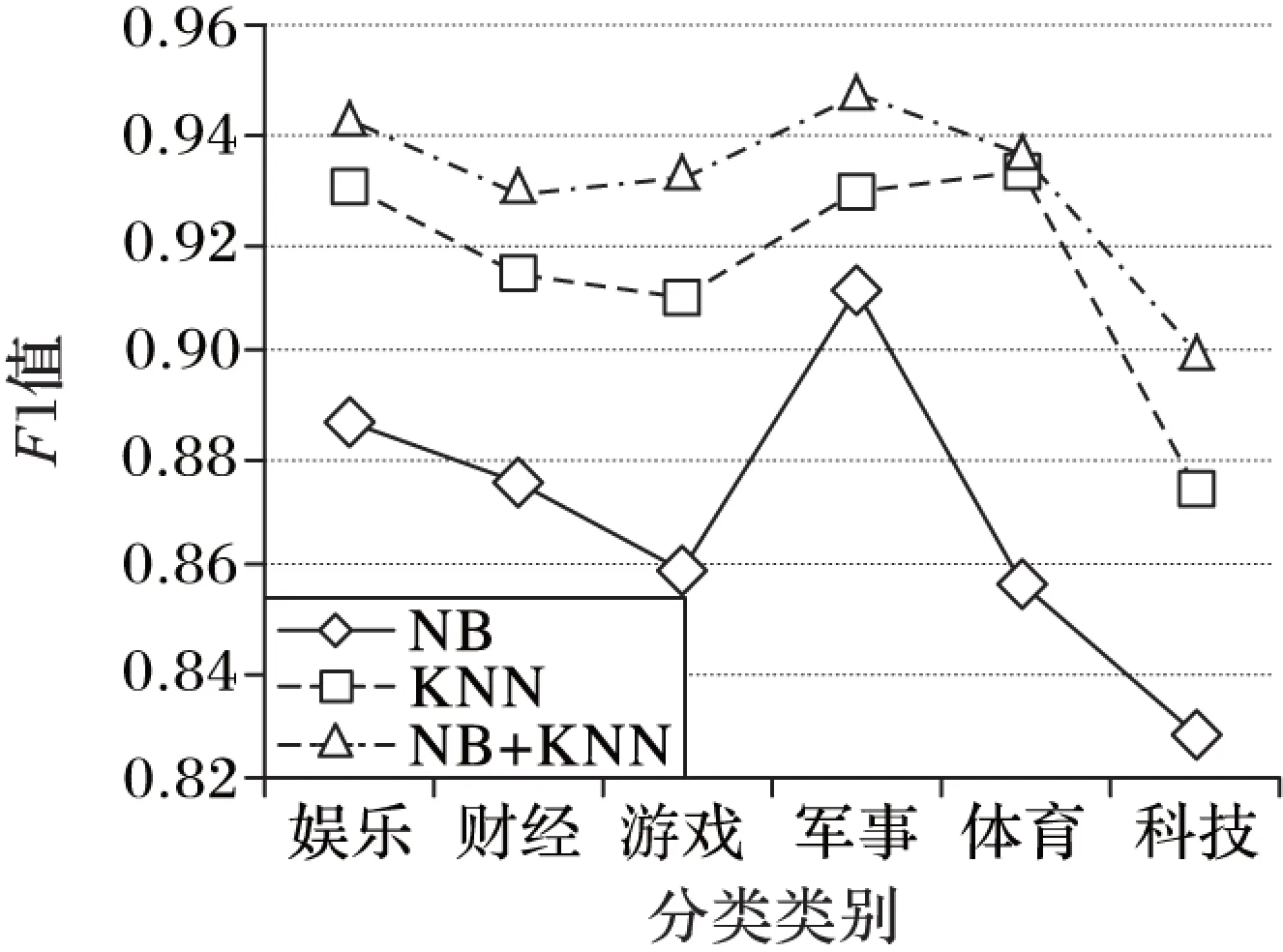
圖7 在線、離線、級聯分類系統在預定類別下的F1值
3 結語
本文對在線和離線網頁分類的級聯方法進行了研究,提出了采用級聯策略實現在線法和離線法的優勢能力互補,基于多目標粒子群優化算法實現參數的調優。本文通過實驗結果表明了該方法的可行性,相對于單獨的在線法和離線法,級聯分類系統的總體分類性能分別提升了10.85%和4.57%;并且級聯分類系統的效率比在線法未降低很多(30%左右),但比離線法的效率提升了70%左右。結果表明,本文提出的級聯分類系統在分類能力和時間、帶寬等資源開銷上均有較大優勢,能夠在保證效率的條件下,有效地提升分類總體的性能。在當前大數據環境下,該方法是一種有效的低消耗大規模網頁分類資源的獲取方法。
References)
[1] PANT G, SRINIVASAN P. Link contexts in classifier-guided topical crawlers[J]. IEEE Transactions on Knowledge and Data Engineering, 2006, 18(1): 107-122.
[2] FENG G, GUO J, JING B-Y, et al. Feature subset selection using Na?ve Bayes for text classification[J]. Pattern Recognition Letters, 2015, 65:109-115.
[3] LIU B, BLASCH E, CHEN Y, et al. Scalable sentiment classification for big data analysis using Na?ve Bayes classifier[C]// Proceedings of 2013 IEEE International Conference on Big Data. Piscataway, NJ: IEEE, 2013:99-104.
[4] CHANG C C, LIN C J. LIBSVM: a library for support vector machines[J]. ACM Transactions on Intelligent Systems and Technology, 2011, 2(3): Article No. 27.
[5] HWANG Y S, KWON J B, MOON J C, et al. Classifying malicious Web pages by using an adaptive support vector machine[J]. Journal of Information Processing Systems, 2013, 9(3):395-404.
[6] WU G, LI L, HU X, et al. Web news extraction via path ratios[C]// CIKM 2013: Proceedings of the 22nd ACM International Conference on Information & Knowledge Management. New York: ACM, 2013:2059-2068.
[7] 韓國輝, 陳黎, 梁時木, 等. Na?ve Bayes分類器制導的專業網頁爬取算法[J]. 中文信息學報, 2010, 24(4):32-38.(HAN G H, CHEN L, LIANG S M, et al. Na?ve Bayesian classifier guided domain specific webpage crawling algorithm[J]. Journal of Chinese Information Processing, 2010, 24(4):32-38.)
[8] RAJALAKSHMI R, ARAVINDAN C. Web page classification using n-gram based URL features[C]// Proceedings of the 2013 Fifth International Conference on Advanced Computing. Piscataway, NJ: IEEE, 2013:15-21.
[9] TRAPEZNIKOV K, SALIGRAMA V, CASTANON D. Multi-stage classifier design[J]. Machine Learning, 2013, 92(2): 479-502.
[10] KAYNAK C, ALPAYDIN E. Multistage cascading of multiple classifiers: one man’s noise is another man’s data[C]// ICML 2000: Proceedings of the Seventeenth International Conference on Machine Learning. San Francisco: Morgan Kaufmann Publishers, 2000: 455-462.
[11] FUMERA G, ROLI F, GIACINTO G. Reject option with multiple thresholds[J]. Pattern Recognition, 2000, 33(12): 2099-2101.
[12] 裴勝玉, 周永權. 基于Pareto最優解集的多目標粒子群優化算法[J]. 計算機工程與科學, 2010, 32(11):85-88.(PEI S Y, ZHOU Y Q. A multi-objective particle swarm algorithm based on the Pareto optimization solution set[J]. Computer Engineering and Science, 2010, 32(11):85-88.)
[13] TEA T, BOGDAN F. Visualization of Pareto front approximations in evolutionary multiobjective optimization: a critical review and the prosection method [J]. IEEE Transactions on Evolutionary Computation, 2015, 19(2):225-245.
[14] CHEN R-C, HSIEH C-H. Web page classification based on a support vector machine using a weighted vote schema[J]. Expert Systems with Applications, 2006, 31(2):427-435.
[15] SEBASTIANI F. Machine learning in automated text categorization[J]. ACM Computing Surveys, 2002, 34(1): 1-47.
This work is partially supported by the National Natural Science Foundation of China (61501063, 61501064), the Scientific Research Foundation of Science and Technology Department of Sichuan Province (2016JY0240), the Scientific Research Foundation of Sichuan Education Department (15ZB0177).
WANG Yaqiang, born in 1984, Ph. D., lecturer. His research interests include big data, cloud computing, natural language processing, machine learning.
ZENG Qin, born in 1975, M. S., senior engineer. His research interests include big data, cloud computing, precise forecast, meteorological big data analysis.
TANG Dan, born in 1982, Ph. D., associate professor. His research interests include big data, cloud computing, coding theory.
SHU Hongping, born in 1974, Ph. D., professor. His research interests include big data, cloud computing.
Cascaded and low-consuming online method for large-scale Web page category acquisition
WANG Yaqiang1*, TANG Ming1, ZENG Qin2, TANG Dan1, SHU Hongping1
(1. College of Software Engineering, Chengdu University of Information Technology, Chengdu Sichuan 610225, China;2. Guangdong Meteorological Observatory, Guangzhou Guangdong 510080, China)
To balance the contradiction between accuracy and resource cost during constructing an automatic system for collecting massive well-classified Web pages, a cascaded and low-consuming online method for large-scale Web page category acquisition was proposed, which utilizes a cascaded strategy to integrate online and offline Web page classifiers so as to take full of use of their advantages. An online Web page classifier trained by features in the anchor text was used as the first-level classifier, and then the confidence of the classification results was computed by the information entropy of the posterior probability. The second-level classifier was triggered when the confidence is larger than the predefined threshold obtained by Multi-Objective Particle Swarm Optimization (MOPSO). The features were extracted from the downloaded Web pages by the secondary classifier, then they were classified by an offline classifier pre-trained by Web pages. In the comparison experiments with single online classification and single offline classification, the proposed method dramatically increased theF1 measure of classification by 10.85% and 4.57% respectively. Moreover, compared with the single online classification, the efficiency of the proposed method did not decrease a lot (less than 30%), while the efficiency was improved about 70% compared with single offline classification. The results demonstrate that the proposed method not only has a more powerful classification ability, but also significantly reduces the computing overhead and bandwidth consumption.
large scale Web page acquisition; Web page classification; cascaded classifier; confidence function; Multi-Objective Particle Swarm Optimization (MOPSO)
2016- 10- 08;
2016- 11- 27。 基金項目:國家自然科學基金資助項目(61501063,61501064);四川省科技計劃項目(2016JY0240);四川省教育廳科研基金資助項目(15ZB0177)。
王亞強(1984—),男,吉林龍井人,講師,博士,CCF會員,主要研究方向:大數據、云計算、自然語言處理、機器學習; 曾沁(1975—),男,廣東梅州人,高級工程師,碩士,主要研究方向:大數據、云計算、精細化預報、氣象大數據分析; 唐聃(1982—),男,四川成都人,副教授,博士,CCF會員,主要研究方向:大數據、云計算、編碼理論; 舒紅平(1974—),男,重慶人,教授,博士,主要研究方向:大數據、云計算。
1001- 9081(2017)04- 0924- 04
10.11772/j.issn.1001- 9081.2017.04.0924
TP391.1
A
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
家庭影院技術(2017年9期)2017-09-26 03:41:45
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
