基于離散序列報文的協議格式特征自動提取算法
2017-06-27 08:10:42李陽,李青,張霞
計算機應用 2017年4期
關鍵詞:特征
李 陽,李 青,張 霞
信息工程大學 信息系統工程學院,鄭州 450002)(*通信作者電子郵箱liqing0206@163.com)
基于離散序列報文的協議格式特征自動提取算法
李 陽,李 青*,張 霞
信息工程大學 信息系統工程學院,鄭州 450002)(*通信作者電子郵箱liqing0206@163.com)
針對缺少會話信息的離散序列報文,提出一種基于離散序列報文的協議格式(SPMbFSC)特征自動提取算法。SPMbFSC在對離散序列報文進行聚類的基礎上,通過改進的頻繁模式挖掘算法提取出協議關鍵字,進一步對協議關鍵字進行選擇,篩選出協議格式特征。仿真結果表明,SPMbFSC在以單個報文為顆粒度的識別中對FTP、HTTP等六種協議的識別率均能達到95%以上,在以會話為顆粒度的識別中識別率可達90%。同等實驗條件下性能優于自適應特征(AdapSig)提取方法。實驗結果表明SPMbFSC不依賴會話數據的完整性,更符合實際應用中由于接收條件限制導致會話信息不完整的情形。
離散序列報文;協議關鍵字提取;自適應特征挖掘;格式特征;協議識別
0 引言
網絡流量的準確識別和分類是提供差異性服務質量保障、入侵檢測、流量監控及計費管理等的基礎。隨著網絡應用的快速發展,傳統的基于端口號[1]的網絡流量識別方法逐漸失效;基于流(Flow)統計特性[2]的方法則無法對應用協議進行精確識別;而基于深度包檢測[3-4]的方法應為應用簡單、準確率高,已經成為目前在實際中廣泛應用的方法。
目前已有的研究成果主要是基于完整的會話流來進行應用協議的格式特征提取。Wang等[5-6]分別提出以會話流為單位,采用X-means聚類算法及粗糙集算法實現混合協議的盲聚類識別,但由于兩人均不采用任何先驗信息,故無法保證識別結果的準確性;劉興彬等[7]提出基于Apriori算法[8]的報文載荷協議關鍵字提取算法,準確率較高,但其算法依舊依賴完整會話流且效率較低;王變琴等[9-10]針對其效率低下的問題分別提出基于FP-growth[11]的改進算法AdapSig[9]和SPFPA算法來進行改進,算法效率有了很大提高,但協議關鍵字提取仍然在完整會話流中進行。在實際應用環境中,由于接收條件的限制,使得具有完整會話流的應用協議數據接收較為困難,接收到的數據多為離散序列報文而非完整會話流,在這種較為苛刻的條件下,如何自動提取協議的格式特征是該領域還沒有解決的問題。
為解決上述問題,本文提出一種基于離散序列報文的協議格式(Separate Protocol Message based Format Signature Construction, SPMbFSC)特征自動提取算法,該算法在挖掘應用協議關鍵字的基礎上,進一步篩選由其組成的格式特征。
本文主要工作有:1)提出SPMbFSC算法,不依賴會話流,更符合實際應用情形,適用條件更廣;2)提出一種改進的DBSCAN(Density-Based Spatial Clustering of Applications with Noise)[12]聚類算法,能有效地在報文層面對應用協議報文進行相似性聚類;3)提出一種基于PrefixSpan[13]的協議關鍵字提取算法PositionSpan,能高效地進行協議關鍵字提取,同時可以進一步挖掘由協議關鍵字構成的格式特征。
1 問題描述與分析
定義1 離散序列報文(Discrete Series Protocol Message)是指會話中由于次序錯亂或部分缺失而形成的報文集合,記為MS={m1,m2,…,mJ},其中:mj(1≤j≤J)為報文。而會話(Session)是指一次通信建立和結束之間的所有報文構成的序列,記為s=m1m2…mN,其中mi(1≤i≤N)為按照特定次序排列的報文。在本文中,約定報文內可打印的字節或字符串用ASCII碼格式表示,不可打印的字節或字符串用形為“xff”的十六進制格式表示,其中ff表示兩位十六進制數字。
實際環境中接收到的數據多為離散序列報文,其與傳統的完整會話相比具有兩方面的特點及困難:1)無序性;2)混疊性。無序性是指接收到的報文只有其到達接收端的時間先后順序,由于會話信息的缺失使得無法在接收端按照報文原有次序進行會話重組;混疊性是指報文在傳輸過程中由于路由選擇、鏈路質量等問題造成的損失不可估計,使得接收端接收到的報文是經過重傳、丟失等問題后的混合報文集合,且無法借助其自身或會話信息進行去冗余處理。由于以上困難的存在,使得目前基于完整會話的協議格式特征提取算法難以適用。
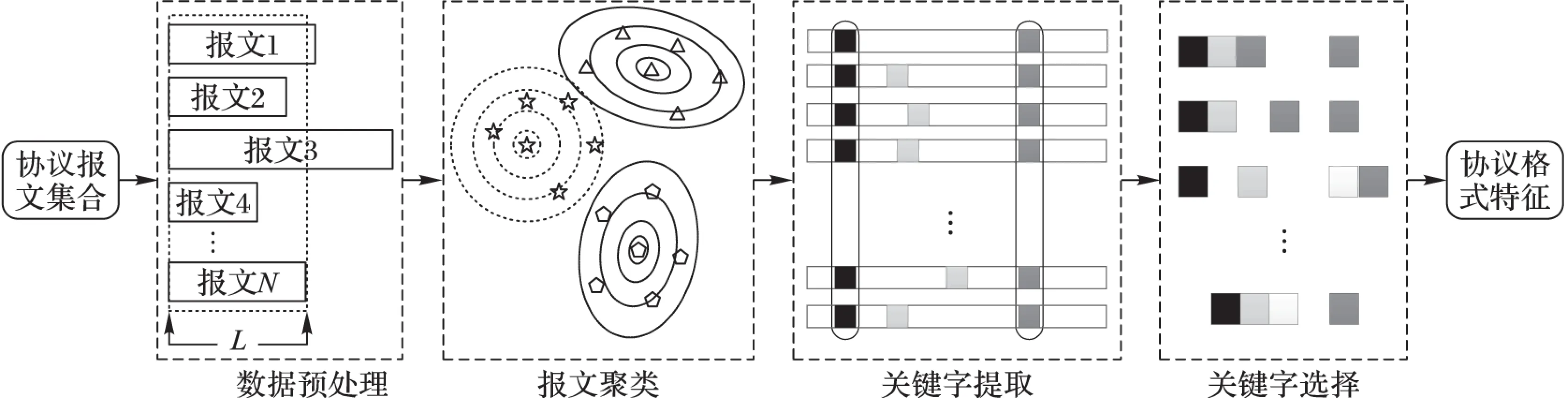
圖1 系統結構
定義2 協議關鍵字(Keyword)是指位置和頻度滿足一定要求的字符串。同種應用協議的關鍵字組成關鍵字集合,記為K={k1,k2,…,kp-1,kp},其中,kp(1≤p≤P)為關鍵字,可以是協議的命令碼、版本號、狀態碼等。
協議關鍵字按其在報文中出現的位置可分為兩類:固定位置協議關鍵字和非固定位置協議關鍵字。其中固定位置協議關鍵字是指其在報文中出現的偏移位置固定,多數是應用層協議報文頭部中的特征字符串,包括協議名稱、版本號等,也可以是應用層協議控制信息中的特征字符串,包括命令碼、狀態碼、定界符等,一般出現在一個報文開頭或最后的若干個字節處;而非固定位置協議關鍵字為出現位置偏移不固定的特征字符串。
定義3 協議格式特征是指能夠識別應用協議類型的協議關鍵字或協議關鍵字組合。
通常用固定位置的協議關鍵字或其組合就可以對應用協議進行精確識別。本文從樣本報文集中自動提取固定位置的協議關鍵字,進而篩選構造只含有固定位置協議關鍵字的協議格式特征。
2 協議格式特征提取算法
針對第1章介紹的離散序列報文協議格式特征提取困難問題,本文提出SPMbFSC算法,重點解決兩大問題:1)離散序列報文的相似聚類;2)協議關鍵字提取及選擇。離散序列報文由于其無序性及混疊性的特點,使其中攜帶控制類信息及業務類信息的報文混合交疊無法區分,導致協議格式特征的提取困難,從而如何將兩類報文彼此區分,即報文的相似聚類就成了必須解決的問題;而針對以協議報文為顆粒度的協議格式特征提取算法,如何正確、高效地進行協議關鍵字提取同時進一步篩選由其構成的具有有效識別能力的協議格式特征,即協議關鍵字提取及選擇也是必須要解決的問題。
SPMbFSC算法系統如圖1所示,對要解決的兩大問題,采用四個主要步驟:1)首先對收集到的報文進行預處理,初步去除掉只攜帶業務類信息的報文,生成樣本報文集;2)利用改進的DBSCAN聚類算法對報文集進行聚類,使具有相似控制類信息或業務類信息的報文聚類成簇;3)在每一個報文簇集合中進行協議關鍵字提取,挖掘其協議關鍵字集合;4)進行協議關鍵字選擇,篩選出具有有效識別能力的協議格式特征用于分類識別。
2.1 數據預處理
大多數應用協議都具有控制類信息和業務類信息兩種協議內容,且其在報文中的分布有如下特點:攜帶控制類信息的報文長度相對較短,內容種類相對固定;攜帶業務類信息的報文長度相對較長,內容分布隨機性強,存在分片傳輸的可能,且通常出現在攜帶控制類信息的報文之后。
基于上述報文分布的特點,在離散序列報文的條件下提出一種基于報文長度截取的數據預處理算法,初步剔除只含有業務類信息的報文。具體做法為首先將報文按照方向分成兩類,對同一方向上的報文按照長度進行排列,之后依據長度閾值L的設定,假定長度小于L的報文攜帶控制類信息而予以保留進行下一步驟的協議關鍵字提取,而假定長度大于L的報文不攜帶控制類信息而只攜帶業務類信息予以舍棄。對于保留的報文,采用目前常用的方法對每個報文提取前后各k個字節[9,14]的數據來代替原有報文,用以提高協議關鍵字提取的準確性和效率。
2.2 改進的DBSCAN聚類算法
針對離散序列報文的特點,本文對經過數據預處理的報文提出一種改進的搜索半徑自適應的DBSCAN算法來進行聚類,使得攜帶有相似信息的報文聚類成簇。算法步驟為:1)設定輸入報文距離中位數的1/8為初始搜索半徑rs;2)每次迭代時增加一倍的rs為新的搜索半徑rs′。重復步驟2)直至滿足終止條件。報文之間的距離采用歐幾里得距離來衡量:
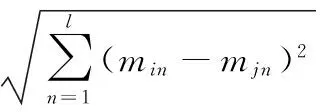
(1)
其中:l為報文長度。為最大限度地利用每一個報文,同時減少聚類過程中過擬合現象的影響,本文聚類算法的終止條件設定如下:1)設定聚類過程中不屬于任何一簇的噪點報文數不得超過總報文數的5%;2)設定聚類簇數的最大值Nmax,避免過多的過擬合簇產生。
較之傳統的DBSCAN算法,本文的聚類算法只用預先給出代表搜索精細程度的每一簇最小樣本數目n,而搜索半徑及聚類簇數自適應確定,從而減少人工參與,克服了傳統DBSCAN算法參數設定需要人工經驗的弊端。
2.3 協議關鍵字提取
在報文聚類的基礎上,對每一簇報文集中協議關鍵字的提取主要由頻繁模式挖掘算法來完成,主要用到支持度測度。
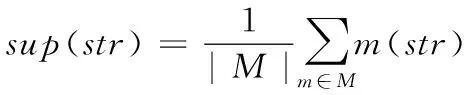
定義5 頻繁字符串。給定報文集M,字符串str及最小支持度minsup∈(0,1),當sup(str)≥minsup時,稱該str為M中的頻繁字符串。M中的所有頻繁字符串組成頻繁字符串集F。
性質1 如果字符串x屬于頻繁字符串集F,即x∈F,則x的所有子集字符串都屬于F;反之若x?F,則x的所有超集字符串都不屬于F。
文獻[15]表明,PrefixSpan算法是比Apriori及FP-growth算法效率更高的頻繁模式挖掘算法,結合本文要挖掘的只含有固定位置協議關鍵字的協議格式特征目標,本文提出一種基于PrefixSpan的PositionSpan算法。其基本思想為:以報文中字節位置為依據,首先按照偏移(字節距離報文首字節的位置,規定首字節的偏移量為零)依次挖掘出報文不同位置上的1-位置頻繁字節項;然后依據PrefixSpan算法的映射思想將1-位置頻繁字節項依據位置的先后次序進行映射拼接得到頻繁字符串集。下面給出1-位置頻繁字節項的定義及PositionSpan算法的詳細步驟。
定義6 1-位置頻繁字節項。依據報文中各字節距離首字節偏移的位置,依次挖掘出不同位置上的頻繁字節,使字節值與字節位置相關聯,其結果稱為1-位置頻繁字節項,表示為:Byte=(Byte.loc,Byte.val),其中Byte.loc為字節所在報文的偏移位置,Byte.val為字節內二進制數的值。所有1-位置頻繁字節項構成1-位置頻繁字節項集B1={Byte1,Byte2,…,Byten-1,Byten},其中Byten(1≤n≤N)為1-位置頻繁字節項。
PositionSpan算法的算法步驟為:1)首先在第一次掃描數據庫時挖掘出所有的1-位置頻繁字節項,并構成1-位置頻繁字節項集B1。2)將B1中的1-位置頻繁字節項按照位置的先后順序進行排序,將位置最前面的兩個不同位置的1-位置頻繁字節項組合構成2-位置頻繁字節項B2。3)計算B2的支持度,若為頻繁,則繼續加入第三個位置的1-位置頻繁字節項構成3-位置頻繁字節項B3;若為不頻繁,由性質1知此B2為一個頻繁字符串同時停止拼接。4)若此頻繁字符串為全新的字符串則加入F否則予以舍棄。迭代步驟2)~4)直至算法結束得到最終的協議頻繁字符串集合F。
2.4 協議關鍵字選擇
協議關鍵字提取得到的關鍵字還包含很多冗余,不能作為最后的分類依據。協議關鍵字只有在滿足一定的約束條件下才能構成協議的格式特征:1)協議格式特征必須是存在于同一個報文中且位置互不重疊的協議關鍵字組合;2)協議格式特征必須具備有效的識別區分能力。針對上述條件1,由本文PositionSpan算法的設計特性予以滿足;而對條件2,本文給出如下規則對協議關鍵字進行初步篩選。
規則1 構成協議格式特征的協議關鍵字組合必須包含三個或三個以上的不同位置1-位置頻繁字節項,且位置最前的1-位置頻繁字節項必須位于報文的前三個字節內。
經過規則1篩選的協議關鍵字只是剔除了大量的無用關鍵字,例如報文中廣泛存在的空格或回車換行符或者單純由這些字符串構成的不具備區分協議能力的協議關鍵字組合,但其作為最后的協議格式特征還主要面臨兩方面問題:1)同一類協議F中的關鍵字選擇;2)不同類協議F間的關鍵字選擇。同一類協議關鍵字選擇主要為剔除關鍵字組合間的包含關系;而不同協議間關鍵字選擇主要為剔除關鍵字組合間的重復關系。為最大限度保留提取出的協議格式特征完整性,本文提出對同一類協議關鍵字選擇采用規則2進行,對不同類協議關鍵字選擇采用規則3進行。
規則2 給定字符串x?y,若sup(x)≤sup(y),則保留y;否則x、y都保留。
規則3 兩類協議的F1及F2,若字符串x?F1且x?F2,則從F1及F2中同時刪除x;否則保留x。
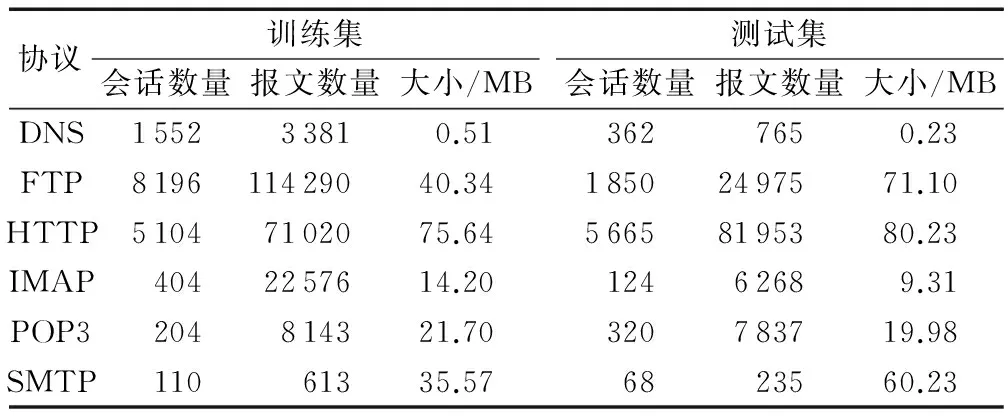
表1 樣本會話集
3 測試分析
實驗環境為一臺PC(CPUi5-4430S,內存2GB),操作系統為Windows7,利用編程軟件Matlab7.14.0進行程序編寫測試。為了驗證算法的性能,利用Wireshark在校園骨干網上采集包含載荷的真實流量,采集時間為2014年12月8日—13日。隨機選取了6個時間段(每個時間段持續5min)的數據,其中3個作為訓練數據集,3個作為測數據集,提取其中域名系統(DomainNameSystem,DNS)、文件傳送協議(FileTransferProtocol,FTP)、超文本傳送協議(HyperTextTransferProtocol,HTTP)、網際報文存取協議(InternetMessageAccessProtocol,IMAP)、郵局協議版本3(PostOfficeProtocol,POP3)、簡單郵件傳送協議(SimpleMailTransferProtocol,SMTP)六種協議進行測試,如表1所示。本文將進行5個實驗來測試SPMbFSC算法的性能,其中:實驗1為算法參數的確定;實驗2為算法格式特征提取功能性驗證;實驗3為算法在報文顆粒度上的性能評估;實驗4為算法與AdapSig算法在會話流顆粒度上的性能比較;實驗5為算法與AdapSig算法時間復雜度的比較。
3.1 參數確定
本文算法參數包括每個報文的字節數k,截斷長度閾值L,聚類算法每一簇最小的樣本數n,聚類最大簇數Nmax以及支持度閾值minsup。目前比較常用的做法是截取報文前后各20字節[9]的數據,所以本文選擇k=20;截斷長度L及聚類最大簇數Nmax的選擇目前沒有確定的標準,所以采用實驗的方法確定;依據本文挖掘精度的需要,設定最小樣本數n=10,以求最大限度地挖掘出所有格式特征;經過多次實驗發現,取minsup=0.7適合每一個聚類簇中報文的頻繁字符串挖掘。
實驗1 截斷長度L及聚類最大簇數Nmax的確定。本文采用自適應的確定方法,具體做法為將每種協議的訓練集報文平均分成兩份:一份作為訓練報文;另一份作為測試報文。對L的確定為將訓練報文按照長度進行排列,按照人為給出的截取總報文數量的百分比來自適應確定每一類協議的最佳截斷長度L;對Nmax的確定為不斷變換人為給出的聚類簇數值來確定最佳的聚類最大簇數Nmax。
本文采用識別率和召回率測度指標[9]來評估提取出的協議格式特征質量。采用本文第2章介紹的SPMbFSC算法,在訓練報文中提取出格式特征,在測試報文中的識別結果分別如圖2~3所示(其中圖2中Nmax設定為20, 圖3中L設定為60%)。
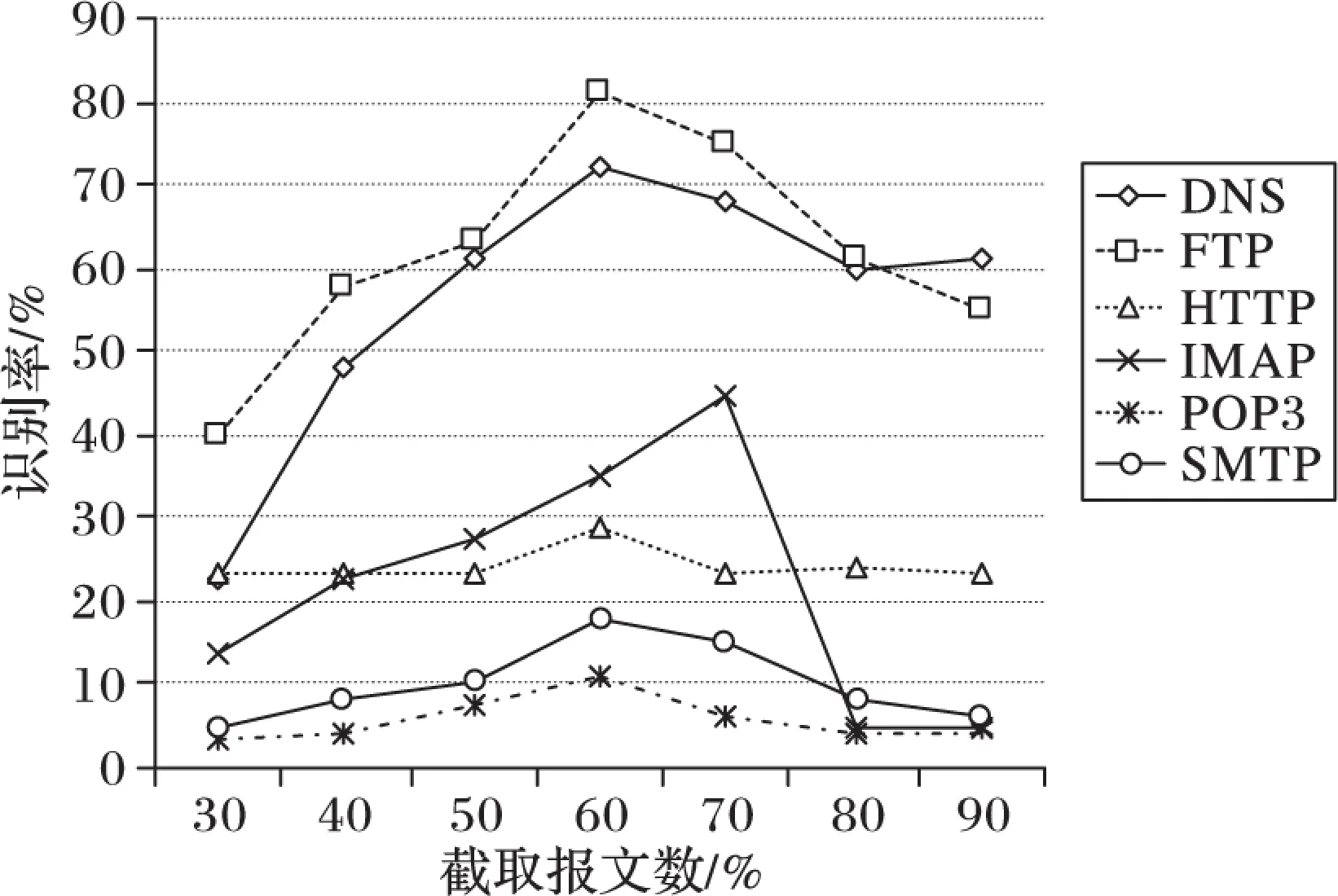
圖2 截斷長度L的確定(Nmax=20)
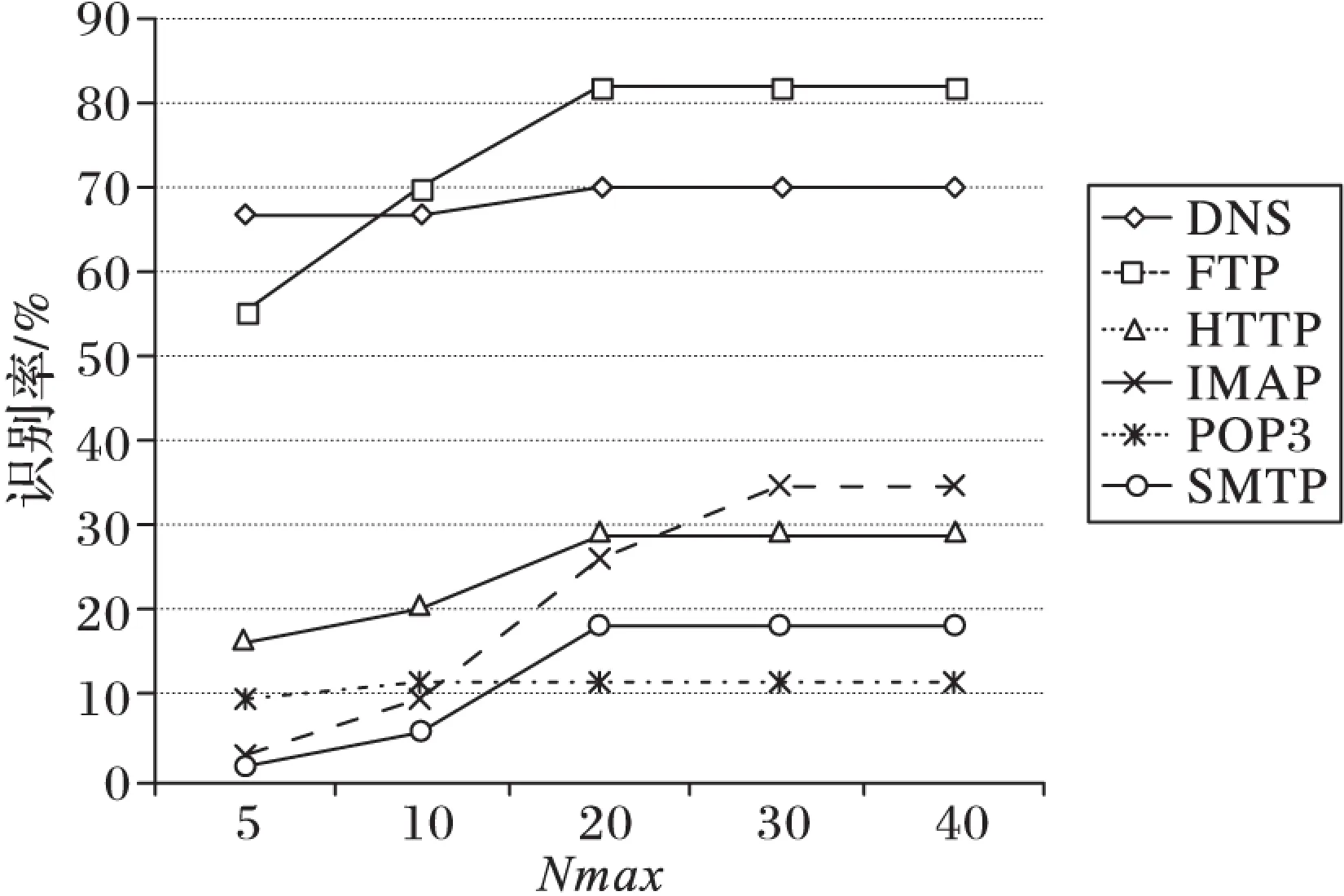
圖3 聚類最大簇數Nmax的確定(L=60%)
由于采用的是報文的識別率,所以提取出的協議格式特征識別率普遍較低。但從圖2可看出,協議格式特征的識別率都具有先上升到峰點然后再下降的特點。其原因在于當截斷長度L較小時,得到的報文數過少,其包含的格式特征少導致識別率低;當L過大時,混入了過多的純業務類信息報文,導致在已有支持度設定的條件下有效特征被淹沒,其識別率降低。
從圖3中則可看出格式特征的識別率都經歷了先上升后穩定的特點。其原因在于當Nmax較小時,聚類簇數少于樣本中真實的類別數,簇內混雜程度高,在高支持度條件下提取出的格式特征較少使得識別率較低;當Nmax較大時,聚類簇數大于樣本中的真實類別數,使得提取出的格式特征完備從而識別率穩定。但同時過大的Nmax設定會使樣本的聚類出現過擬合傾向。
從圖2~3中可看出當截斷長度L為全部報文數量的60%及Nmax為20時,絕大多數協議的識別率都達到最大值,所以設定每一類協議報文數60%所對應的長度為截斷長度L,選取聚類最大簇數Nmax的值為20。
3.2 性能分析
格式特征提取得到的結果如表2所示,為便于比較,表中也列出了AdapSig[9]和L7-Filte[16]獲得的格式特征。其中AdapSig算法為目前已知最先進的協議格式特征自動提取算法,其與本文SPMbFSC算法的區別為AdapSig算法以完整會話為單位進行格式特征提取,從每個會話相同位置偏移的報文中挖掘協議的格式特征;L7-Filter為一款主要依靠人工分析來制定識別特征規則的網絡流量分類識別軟件,其識別單位為完整會話,利用端口號、用戶行為特征等會話流信息及少量的報文載荷中協議關鍵字的匹配實現了非常高的識別率[17],被認為是最精確的。為保證實驗條件的公平性,本文不使用L7-Filter中任何會話流特征來進行輔助識別,僅使用其報文載荷中提取出的協議格式特征進行實驗,其特征用正則表達式(RegularExpression,RegExp)表示。
實驗2 格式特征提取功能性驗證。用本文提出的SPMbFSC算法與AdapSig算法對訓練集協議數據進行特征提取后,結果如表2所示(其中AdapSig算法支持度設置為與文獻[9]中一致的0.02)。
從表2可以看出,本文SPMbFSC算法和AdapSig算法提取出的協議格式特征均達到了對L7-Filter特征的覆蓋,即證明了本文算法功能的正確性,其中表2中三條特征:“220x20,x0dx0a”“USERx20,x0dx0a”和“PASSx20,x0dx0a”由關鍵字選擇規則3不予添加,其原因在于FTP和SMTP協議中均挖掘出了“220x20,x0dx0a”特征而FTP和POP3協議中均挖掘出了后兩條特征。
除IMAP及SMTP協議本文SPMbFSC算法和AdapSig算法提取出的格式特征差別較大,其他四種協議本文提取的協議格式特征實現了對AdapSig算法提取特征的全覆蓋。深入查看數據,發現IMAP及SMTP協議提取的格式特征差別較大的原因在于實驗中收集到的IMAP及SMTP協議報文數量相對較少,但格式種類相對較多,使本文聚類算法在小搜索半徑時的聚類簇數超出了Nmax的上限設置,從而導致搜索半徑過大,同時較高支持度閾值的設置又使得提取出的協議格式特征少,而AdapSig算法則由于非常低的支持度閾值及缺少聚類算法的限制,所以提取出的協議格式特征較多。后期進行了降低支持度閾值及提高Nmax閾值設定的實驗,實現了對AdapSig算法協議格式特征的提取。
實驗3 性能評估。將六種協議的測試數據集合并成為最終的測試數據集,用本文SPMbFSC算法提取的協議格式特征與L7-filter的特征在報文顆粒度上進行性能評估,由于AdapSig算法無法在非完整會話基礎上挖掘協議格式特征所以不參與對比,以識別率與召回率為指標進行評估,其結果分別如圖4~5所示。

表2 訓練報文集格式特征提取結果
注:特征之間用“|”分隔;特征內的元素之間用“,”分隔。

圖4 報文識別率對比
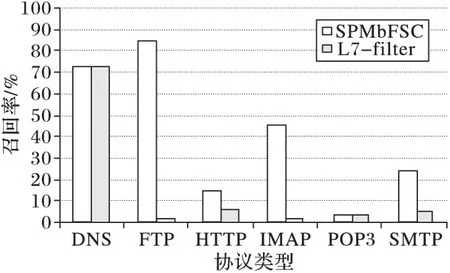
圖5 報文召回率對比
從圖4中看出本文提取的協議格式特征的識別率普遍較高且均不低于L7-filter,即提取的協議格式特征是正確的,其中L7-filter對FTP及SMTP協議識別率較低的原因在于兩協議均含有“220x20,x0dx0a”特征,從而彼此產生誤判。而從圖5中看出本文及L7-filter特征的召回率普遍較低其原因有兩點:1)協議產生的會話中帶有業務類信息的報文數量較多而帶有控制類信息的報文數量較少,在以報文為顆粒度的計算中召回率低下,例如HTTP及POP3協議;2)本文算法提取出的協議格式特征及L7-filter的特征較少,不足以充分覆蓋協議報文,使得召回率較低。
實驗4 與AdapSig算法性能比較。分別利用本文SPMbFSC算法提取出的協議格式特征,AdapSig算法提取出的協議格式特征及L7-filter的特征進行分類識別來進行算法性能的比較,結果以識別率與召回率為指標進行評估。為統一指標的可比性,計算都以會話為單位進行。實驗結果分別如圖6~7所示。
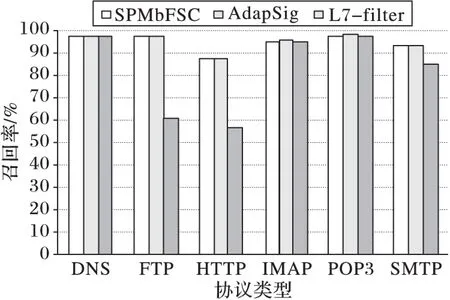
圖7 會話召回率對比
從圖6~7中可看出,從以會話為單位的識別率和召回率來看,本文提出的SPMbFSC算法均為最高,且所有協議的識別率及召回率均達到了90%以上,從而驗證了本文算法在會話為單位的協議識別上的有效性。其中:圖6中FTP協議本文的識別率略高于AdapSig算法,原因在于本文提取的協議格式特征多于AdapSig算法;而L7-filter對FTP及SMTP協議識別率較低的原因為缺少了會話流信息的輔助,同時兩協議均含有“220x20,x0dx0a”特征而引起誤判。圖7中L7-filter對FTP及HTTP協議召回率較低則是由于其特征較少,無法覆蓋協議會話;IMAP及SMTP協議本文與AdapSig算法召回率一致則是由于相同會話中帶有控制字段的報文數較少但類別較多,從而導致AdapSig算法雖然提取出了較多的協議格式特征但兩算法的召回率一致。
實驗5 與AdapSig算法時間復雜度對比。在minsup相同的條件下,通過本文SPMbFSC算法與AdapSig算法挖掘出協議關鍵字所耗費的時間為指標評估本文算法的效率。實驗結果如圖8所示。
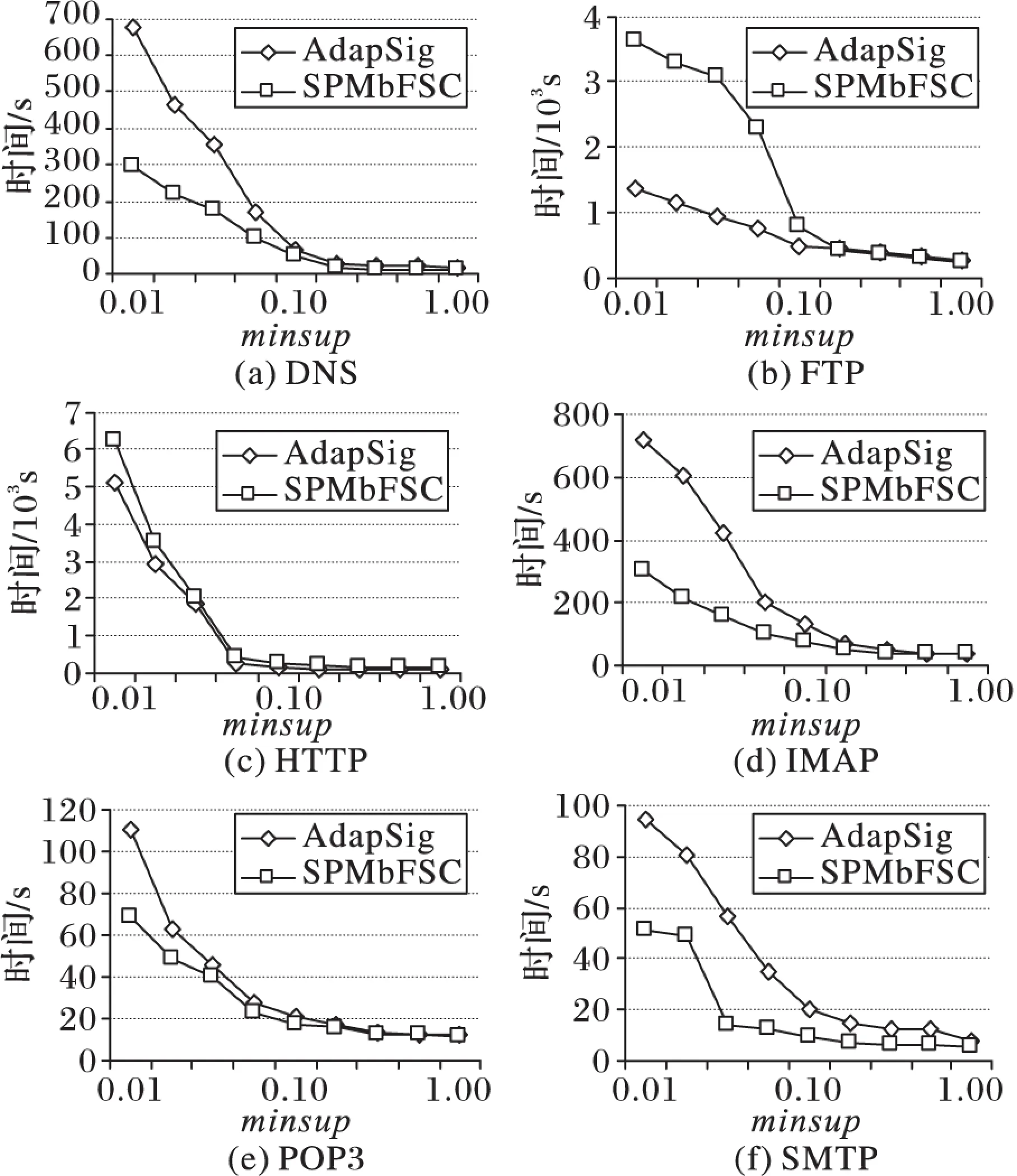
圖8 效率比較
從圖8中看出,除了FTP和HTTP協議外,本文SPMbFSC算法效率均高于AdapSig算法,同時在FTP及HTTP協議中當minsup較高時(大于0.1),本文算法的效率也高于AdapSig算法。其原因在于FTP及HTTP協議的報文不僅數量龐大,同時攜帶的內容種類也多,使SPMbFSC算法運算的報文集規模比AdapSig算法大,同時在minsup較低時,SPMbFSC算法的運算次數十分巨大,導致效率較低,但當minsup增大到一定程度后,其運算次數急劇減小,從而使算法在較高支持度時效率高于AdapSig算法。但在其他條件下本文算法效率均高于AdapSig算法也證明了本文算法的高效性。
4 結語
本文提出的SPMbFSC算法能夠在離散序列報文的條件下自動發現協議關鍵字同時篩選出格式特征,其前提條件更寬泛,更貼近實際的網絡環境,同時減少了人工參與,提高了自動化程度。選擇目前較流行的應用協議流量進行測試取得了不錯的效果。然而本文方法是否適用于其他的協議,尤其是目前增長十分迅速的P2P類應用協議及某些領域內的私有類型協議仍需要廣泛的驗證。同時由于協議關鍵字選擇規則方面研究較少,本文實際操作中也出現了選擇規則過于簡單的現象,如何在已有協議關鍵字提取的基礎上充分利用其識別性能而產生更高效嚴謹的協議關鍵字選擇規則也是下一步的研究目標。
References)
[1] VOLZ B, CAIN E, KOHLER E, et al. Service name and transport protocol port number registry [EB/OL]. [2012- 06- 06]. http://www.iana.org/assignments/port-numbers.
[2] HUANG S, CHEN K, LIU C. A statistical-feature-based approach to Internet traffic classification using machine learning [C]// ICUMT 2009: Proceedings of the 2009 International Conference on Ultra Modern Telecommunications & Workshops. Piscataway, NJ: IEEE, 2009: 1-6.
[3] KARAGIANNIS T, PAPAGIANNAKI K, FALOUTSOS M. BLINC: multilevel traffic classification in the dark [C]// SIGCOMM 2005: Proceedings of the 2005 Conference on Applications, Technologies, Architectures, and Protocols for Computer Communications. New York: ACM, 2005: 229-240.
[4] MOORE A W, PAPAGIANNAKI K. Toward the accurate identification of network applications [C]// PAM 2005: Proceedings of the 6th International Conference on Passive and Active Network Measurement. Berlin: Springer, 2005: 41-54.
[5] WANG Y, XIANG Y, YU S-Z. Automatic application signature construction from unknown traffic [C]// Proceedings of the 2010 24th IEEE International Conference on Advanced Information Networking and Applications. Piscataway, NJ: IEEE, 2010: 1115-1120.
[6] LUO J Z, YU S Z, CAI J. Capturing uncertainty information and categorical characteristics for network payload grouping in protocol reverse engineering [J]. Mathematical Problems in Engineering, 2015, 2015(6): 1-9.
[7] 劉興彬, 楊建華, 謝高崗, 等. 基于 Apriori 算法的流量識別特征自動提取方法[J]. 通信學報, 2008, 29(12): 51-59.(LIU X B, YANG J H, XIE G G, et al. Automated mining of packet signatures for traffic identification at application layer with Apriori algorithm [J]. Journal on Communications, 2008, 29(12): 51-59.)
[8] AGRAWAL R, SRIKANT R. Fast algorithms for mining association rules in large databases [C]// VLDB 1994: Proceedings of the 20th International Conference on Very Large Data Bases. San Francisco: Morgan Kaufmann Publishers, 1994: 487-499.
[9] 王變琴, 余順爭. 自適應網絡應用特征發現方法[J]. 通信學報, 2013, 34(4): 127-137.(WANG B Q, YU S Z. Adaptive extraction method of network application signatures [J]. Journal on Communications, 2013, 34(4): 127-137.)
[10] 朱玉娜, 韓繼紅, 袁霖, 等. SPFPA: 一種面向未知安全協議的格式解析方法[J]. 計算機研究與發展, 2015, 52(10): 2200-2211.(ZHU Y N, HAN J H, YUAN L, et al. SPFPA: a format parsing approach for unknown security protocols [J]. Journal of Computer Research and Development, 2015, 52(10): 2200-2211.)[11] HAN J, PEI J, YIN Y, et al. Mining frequent patterns without candidate generation: a frequent-pattern tree approach [J]. Data Mining & Knowledge Discovery, 2004, 8(1): 53-87.
[12] ESTER M, KRIEGEL H P, SANDER J, et al. A density-based algorithm for discovering clusters in large spatial databases with noise [C]// Proceedings of the Second International Conference on Knowledge Discovery and Data Mining. Menlo Park, CA: AAAI Press, 1996: 226-231.
[13] PEI J, HAN J, MORTAZAVI-ASL B, et al. Mining sequential patterns by pattern-growth: the PrefixSpan approach [J]. IEEE Transactions on Knowledge and Data Engineering, 2004, 16(11): 1424-1440.
[14] HAFFNER P, SEN S, SPATSCHECK O, et al. ACAS: automated construction of application signatures [C]// MineNet 2005: Proceedings of the 2005 ACM SIGCOMM Workshop on Mining Network Data. New York: ACM, 2005: 197-202.
[15] ERMAN J, ARLITT M, MAHANTI A. Traffic classification using clustering algorithms [C]// MineNet 2006: Proceedings of the 2006 SIGCOMM Workshop on Mining Network Data. New York: ACM, 2006: 281-286.
[16] Application layer packet classifier for Linux[EB/OL]. [2012- 06- 02]. http://l7-filter.sourceforge.net/.
[17] Application layer packet classifier for Linux-HOWTO[EB/OL]. [2012- 06- 03]. http://17-filter.sourceforge.net/documents.
LI Yang, born in 1991, M. S. candidate. His research interests include data mining, traffic classification.
LI Qing, born in 1976, Ph. D., associate professor. Her research interests include network data reverse processing, visible-light communication, wireless self-organizing network, sensor network.
ZHANG Xia, born in 1979, Ph. D., lecturer. Her research interests include machine learning, network protocol analysis.
Automatic protocol format signature construction algorithm based on discrete series protocol message
LI Yang, LI Qing*, ZHANG Xia
(College of Information System Engineering, Information Engineering University, Zhengzhou Henan 45002, China)
To deal with the discrete series protocol message without session information, a new Separate Protocol Message based Format Signature Construction (SPMbFSC) algorithm was proposed. First, separate protocol message was clustered, then the keywords of the protocol were extracted by improved frequent pattern mining algorithm. At last, the format signature was acquired by filtering and choosing the keywords. Simulation results show that SPMbFSC is quite accurate and reliable, the recognition rate of SPMbFSC for six protocols (DNS, FTP, HTTP, IMAP, POP3 and IMAP) achieves above 95% when using single message as identification unit, and the recognition rate achieves above 90% when using session as identification unit. SPMbFSC has better performance than Adaptive Application Signature (AdapSig) extraction algorithm under the same experimental conditions. Experimental results indicate that the proposed SPMbFSC does not depend on the integrity of session data, and it is more suitable for processing incomplete discrete seriesprotocol message due to the reception limitation.
discrete series protocol message; protocol keyword extraction; dadptive format signature mining; format signature; protocol identification
2016- 09- 28;
2016- 10- 09。
李陽(1991—),男,河南柘城人,碩士研究生,主要研究方向:數據挖掘、流量分類; 李青(1976—),女,河北正定人,副教授,博士,主要研究方向:網絡數據逆向處理、可見光通信、無線自組織網、傳感網; 張霞(1979—),女,山東濟南人,講師,博士,主要研究方向:機器學習、網絡協議分析。
1001- 9081(2017)04- 0954- 06
10.11772/j.issn.1001- 9081.2017.04.0954
TP393.8
A
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化(高中版.高考數學)(2022年3期)2022-04-26 14:04:16
數學年刊A輯(中文版)(2020年1期)2020-05-19 00:30:36
空間科學學報(2020年2期)2020-04-01 03:50:40
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中等數學(2019年8期)2019-11-25 01:38:14
當代陜西(2019年10期)2019-06-03 10:12:04
新聞傳播(2018年11期)2018-08-29 08:15:24
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
廣西科技大學學報(2016年1期)2016-06-22 13:10:38
