類屬數據的貝葉斯聚類算法
2017-06-27 08:10:42陳黎飛
計算機應用 2017年4期
關鍵詞:符號
朱 杰,陳黎飛
1.中國西南電子技術研究所,成都 610036; 2.福建師范大學 數學與計算機科學學院,福州 350117)(*通信作者電子郵箱clfei@fjnu.edu.cn)
類屬數據的貝葉斯聚類算法
朱 杰1,陳黎飛2*
1.中國西南電子技術研究所,成都 610036; 2.福建師范大學 數學與計算機科學學院,福州 350117)(*通信作者電子郵箱clfei@fjnu.edu.cn)
針對類屬型數據聚類中對象間距離函數定義的困難問題,提出一種基于貝葉斯概率估計的類屬數據聚類算法。首先,提出一種屬性加權的概率模型,在這個模型中每個類屬屬性被賦予一個反映其重要性的權重;其次,經過貝葉斯公式的變換,定義了基于最大似然估計的聚類優化目標函數,并提出了一種基于劃分的聚類算法,該算法不再依賴于對象間的距離,而是根據對象與數據集劃分間的加權似然進行聚類;第三,推導了計算屬性權重的表達式,得出了類屬型屬性權重與其符號分布的信息熵成反比的結論。在實際數據和合成數據集上進行了實驗,結果表明,與基于距離的現有聚類算法相比,所提算法提高了聚類精度,特別是在生物信息學數據上取得了5%~48%的提升幅度,并可以獲得有實際意義的屬性加權結果。
數據聚類;類屬型屬性;屬性加權;貝葉斯聚類;概率模型
0 引言
在模式識別和數據挖掘領域,類屬數據聚類(categorical data clustering)是一項重要但較為困難的任務:一方面,這是由于許多實際應用中的待聚類對象通常由該型數據或混合了數值型(numerical)及類屬型的數據描述。例如,生物數據聚類任務中的DNA序列就是由A、T、G和C等代表不同氨基酸的符號構成的;在描述患者體征時,又可能使用諸如“心跳數”這樣的數值型生理指標,而實際應用中人們通常將這些數值型數據轉換為類屬型數據加以處理[1]。另一方面,由于類屬數據的屬性值取自有限的符號集合,是離散的,定義有效的對象間距離度量較數值型數據顯得困難[2],這使得類屬數據聚類成為一項富有挑戰性的任務。
根據所生成聚類結構的差異,現有類屬數據聚類算法大致分為兩類[3]:層次聚類和基于劃分的聚類。前者的目的是構造層次聚類樹,代表性算法包括凝聚型算法[4]和分裂型算法[5]等。本文著重于基于劃分的聚類,主要原因是該型方法(與層次聚類算法相比)通常具有較低的時間復雜度且易于實現。實際上,以著名的K-means[6]為代表的基于劃分的聚類算法已被廣泛研究和應用,其基本原理是在給定聚類數K的前提下尋求數據集中簇內對象平方誤差(squared error)最小的K個劃分,這里的誤差是依據對象與簇中心之間的距離定義的。
將K-means型算法運用于類屬數據聚類需要處理兩個主要問題:如何定義類屬數據的簇中心以及如何衡量類屬對象間的距離(或相似度)。對于第一個問題,已提出基于符號分布的“中心”[7-8]和基于“模”的定義[9-10]等,其中又以后者最為常見:使用模符號(mode category),即出現頻率最高的那個符號作為簇的代表。典型算法包括著名的K-modes[9,11]及其變種[10,12]。盡管已提出多種衡量類屬對象間相似性的方法,例如信息熵度量[13]和頻度度量[14]等,但應用于無監督聚類的并不多見。其中的簡單匹配(simple matching)距離具有代表性,其原理是根據取值不同的屬性數目計算對象距離。近年已提出多種基于屬性加權的簡單匹配距離度量,并以此為基礎定義了多種K-modes型子空間聚類算法[7,15-17]。由于這些算法所依賴的距離度量僅限于符號匹配,而忽略了符號的總體分布(一般而言,一個有效的度量應區分高頻符號與低頻符號等[2]),這是不完備的,聚類算法的有效性也將因此受到影響。
本文提出的新型聚類算法基于數據對象與數據集劃分之間的似然(likelihood)衡量對象與簇之間的相似性,從而避免了由簡單匹配距離和以模為簇中心帶來的上述問題。該算法簡稱為WBCC(Weighted Bayesian Clustering of Categories),是一種基于貝葉斯概率估計的類屬數據聚類算法。WBCC算法通過對新定義的屬性加權概率模型的最大似然估計,實現類屬數據的子空間聚類。在實際數據集上的實驗結果驗證了該算法的有效性。
1 相關工作
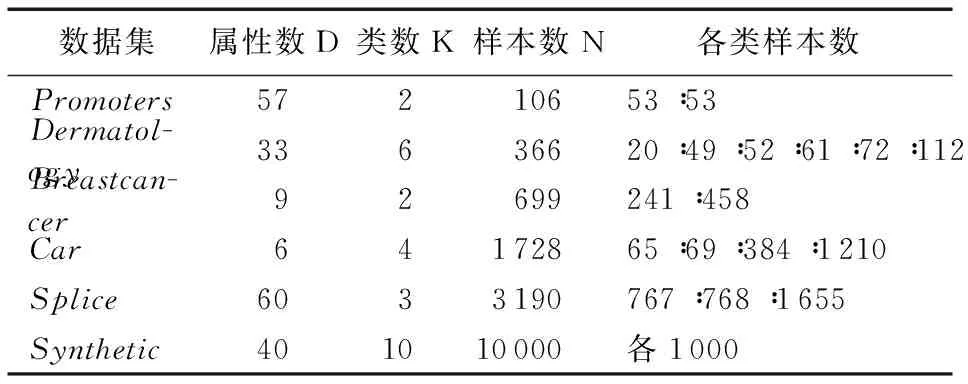
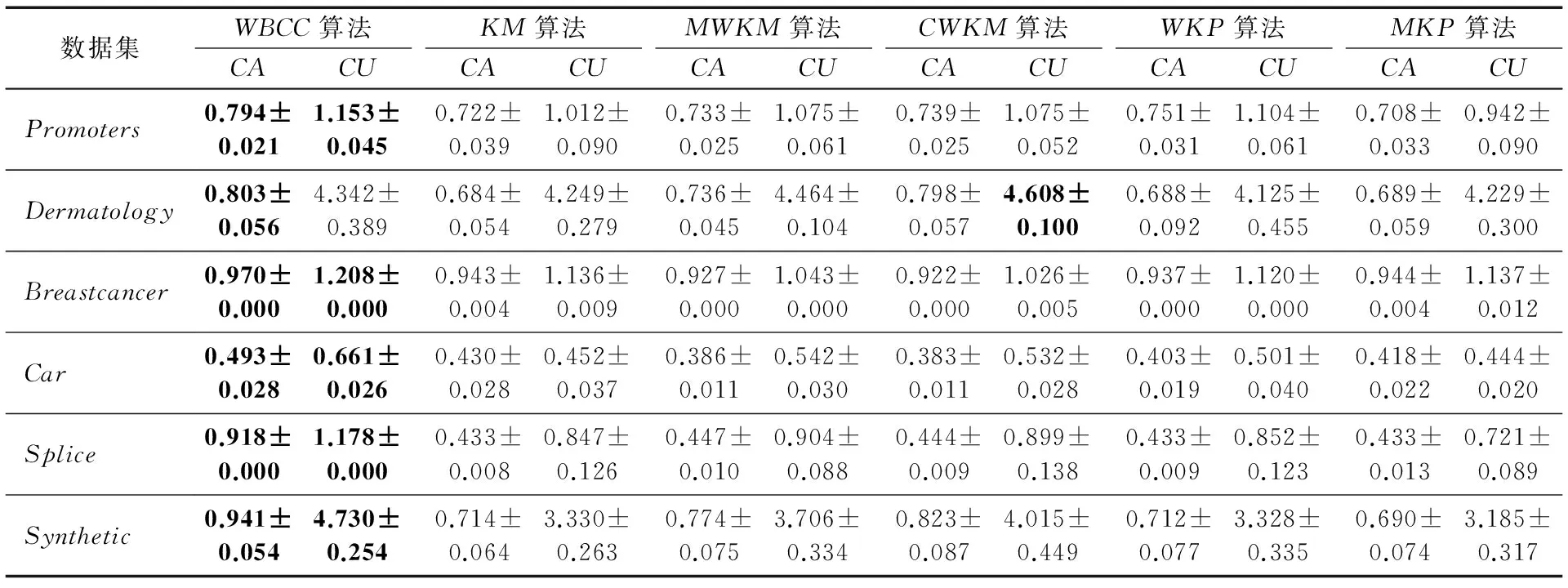
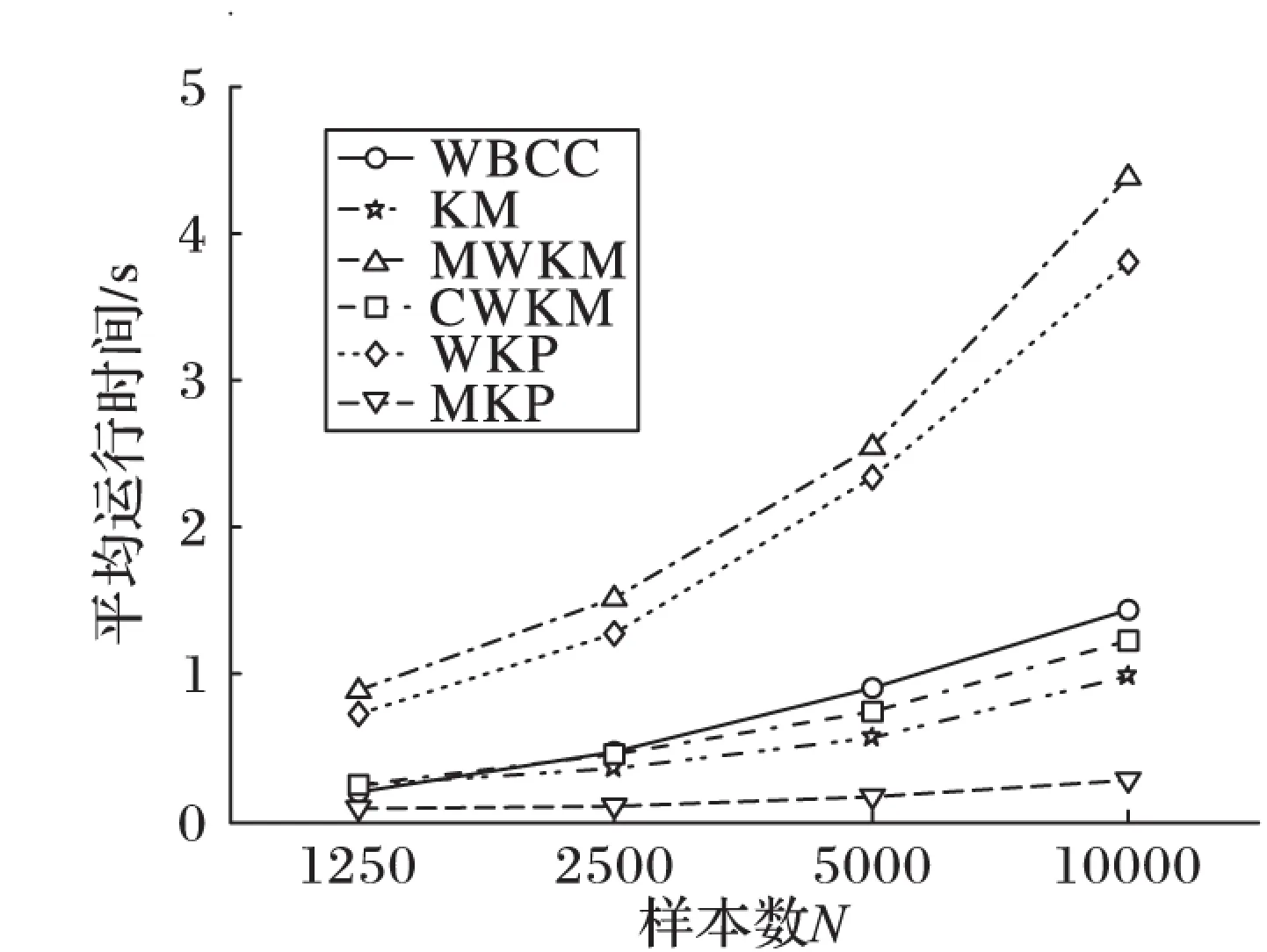
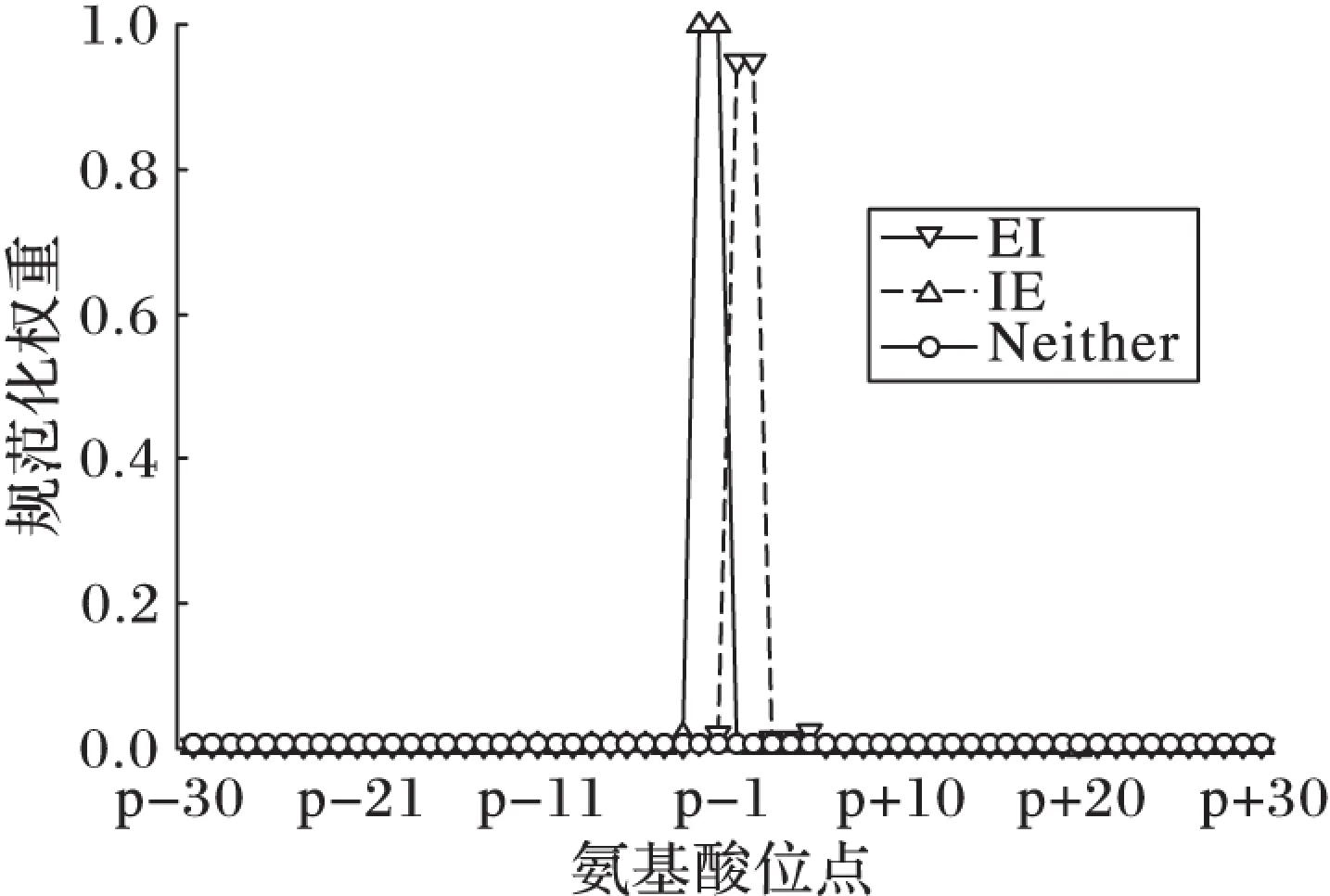
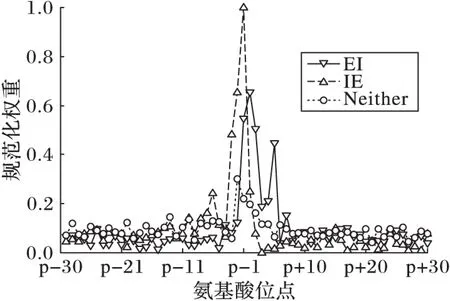
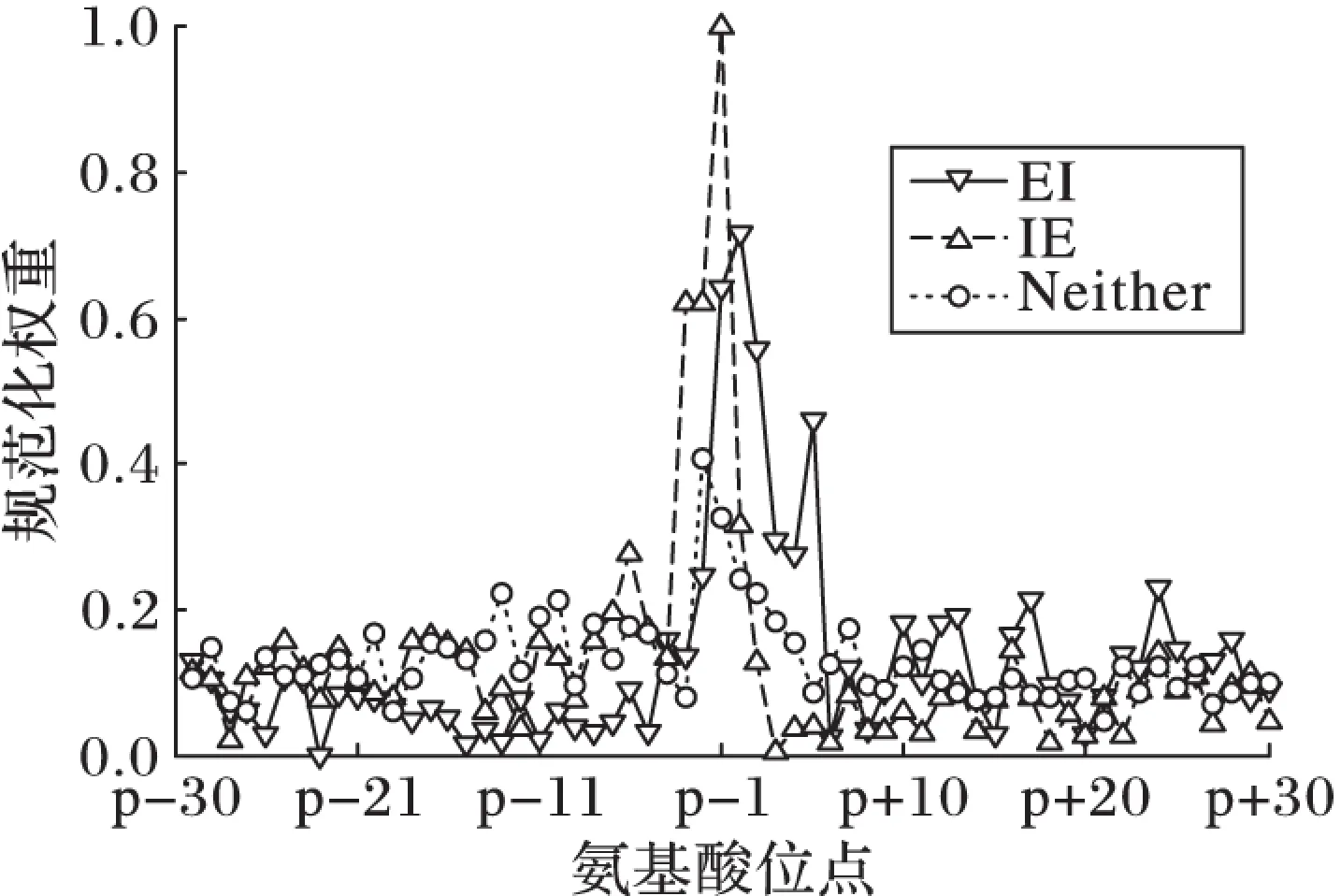
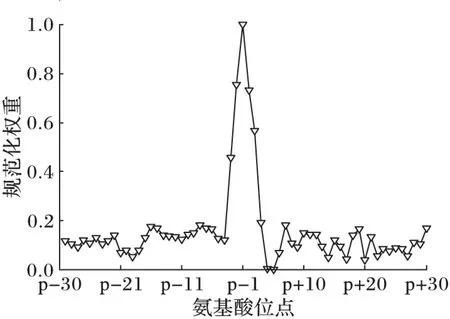
首先約定后文使用的記號。設x=(x1,x2,…,xd,…,xD)或y=(y1,y2,…,yd,…,yD)表示由D個類屬屬性值構成的數據對象,屬性值xd(d=1,2,…,D)的取值集合為Xd,|Xd|表示集合中的元素數目,即xd可取的符號數目。給定N個這樣的類屬對象和整數K(1 對象間的相似性或距離度量是聚類分析的基礎。在類屬型數據聚類中,常用簡單匹配函數dis(x,y)衡量對象x和y之間的距離[1-2],注意到此型度量僅考慮對象本身符號的匹配情況。 (1) Lin[13]根據(被匹配)符號的概率定義了基于熵理論的相似性度量,Goodall[14]的定義則使用了所有符號的概率(因此,該度量考慮了符號總體分布情況),但它們都未能用于基于劃分的數據聚類。實際上,基于劃分的聚類算法的優化目標與所采用對象間距離度量是密切相關的,例如,已廣泛研究和應用的K-modes系列算法[9-12]就基于式(1)所示的簡單匹配距離定義其目標函數。 近年對基于劃分的類屬數據聚類算法研究主要集中在兩個方面:提出替代“模”的簇表示方法以及改進距離度量。“非模”的簇表示方法包括符號分布法[7]和K-representatives[8]等,其實質是將一個類屬型屬性轉換為若干個(等于該屬性的符號數目)二元型屬性加以處理。Chen等[17-18]研究了非中心聚類法,在這種方法中,簇不再以“中心”為代表。本文提出的新算法WBCC也將是“非中心”的,直接使用簇內對象來表示簇。 2.1 貝葉斯聚類模型 給定對象集和聚類數K,貝葉斯聚類算法的目的是生成K個簇的集合C,以最大化每個對象(相對于其所在簇)的似然。該目標可以形式地表示為: 其中:p(k|x)是對象x相對于簇ck的后驗概率。取以2為底的對數,并使用貝葉斯公式,優化目標變換為: (2) 其中:p(x|k)表示x的先驗概率,p(k)為簇ck的概率;p(x)因與C無關被忽略。 基于相關研究中普遍采用的“樸素”假設[3,14-19]來估計p(x|k):數據集的D個屬性是統計獨立的。在這個假設前提下,p(x|k)可以簡單地通過p(x1|k)×p(x2|k)×…×p(xd|k)×…×p(xD|k)來估計。在此基礎上,為區分不同屬性的貢獻,引入局部屬性加權機制,賦予屬性d以權重wkd衡量其對簇ck的重要性,數值越大表明其越重要,且滿足以下約束條件: (3) 注意到式(3)與相關研究采用的“權重之和歸一化”條件[3,15-19]不同,式(3)基于權重之積,這有助于放大屬性權重的差異:例如,若某個屬性被賦予很小的權重(接近0,表明該屬性不重要),則根據式(3)必有其他一些屬性的權重遠大于1。 根據上述定義,用下式估計p(x|k): 其中p(xd|k)是符號xd經Laplace校正的頻度估計: #kd(xd)表示符號xd出現在簇ck屬性d上的次數。綜上,算法WBCC的聚類優化目標可以寫作: s.t. Eqs. (2) and (3) (4) 其中:P={p(k)|k=1,2,…,K},W={wkd|k=1,2,…,K;d=1,2,…,D}。 2.2 聚類算法 給定對象集和K,聚類算法需求解式(4)所示帶約束的非線性優化問題。應用拉格朗日乘子法引入式(2)和(3)定義的約束條件,算法需優化(最大化)的目標函數轉換為: 其中:λ和ξk(k=1,2,…,K)為拉格朗日乘子。 算法WBCC基于K-means或K-modes的算法結構[6,9,11],采用一個兩步驟的迭代方案求取J(C,W)的局部最優解。在第一個迭代步驟中,將W和P視為常數,求解令函數J取得最大值的C,這可以通過將每個對象x重新劃分到與其最相似的簇來實現。對象x與簇ck的相似度根據下面的對數似然函數計算: (5) (6) 基于上述優化策略的WBCC算法描述如下。 算法1 類屬數據貝葉斯聚類算法WBCC。 輸入:N個待聚類類屬型數據對象及聚類數K。 輸出:聚類集合C={c1,c2,…,cK}及屬性權重集合W。 Begin 生成數據集初始劃分C,并初始化W中的每個屬性權重為1;根據式(5)計算初始的P; Repeat 固定W和P,根據式(5)計算每個對象x到當前每個簇ck的似然,并將之劃分至似然最大的簇,生成新的C; 固定C,根據式(6)和(7)更新W和P; UntilJ(C,P,W)的變化小于10-6 End 算法從一個初始的聚類劃分出發,經過一系列迭代步驟,直到目標函數不再發生變化(實際中,當其值的變化很小,比如小于10-6時,判斷為算法收斂)。初始劃分的生成借鑒了文獻[17-18]的方法,即首先隨機選擇K個對象為種子,然后根據式(1)所示的簡單匹配距離,將所有對象劃分到最近的種子,生成數據集的初始劃分。與K-means[6]、K-modes[9,11]等算法一樣,算法1輸出的聚類結果對其初始狀態有一定的依賴性;同時,鑒于初始狀態的隨機性,算法通常只能輸出所優化目標函數的局部優解。 2.3 算法分析 首先分析時間復雜度。從算法過程可以看出,算法WBCC與傳統K-means[6]或K-modes[9,11]具有相似的結構,由于其間每個迭代步驟都使得目標函數值下降或保持不變,且對于給定的對象集和K,目標函數存在下界,因此,經過有限次迭代,可以使得函數值不再下降,此時算法收斂。設迭代次數為T,WBCC的算法時間復雜度為O(NKDT)。 其次,WBCC算法沒有使用簇“中心”概念,也不是基于類屬對象間距離的聚類算法,它根據對象-簇間的似然進行聚類劃分)。在聚類過程中,算法自動賦予每個屬性K個權重,進行子空間聚類。根據式(7)可知,WBCC算法計算屬性d相對于簇ck的權重為: (8) 也就是說,WBCC的屬性權重與其符號分布的信息熵成反比。這與相關研究基于模符號進行屬性加權的方式[5,15,19]不同,WBCC進行屬性加權的依據是符號的總體分布。 實驗分析包括算法聚類結果對比和屬性加權方式有效性驗證兩個方面,并與若干相關工作相比較。 3.1 實驗數據與實驗設置 在6個數據集上檢驗WBCC算法的性能,數據集的詳細信息如表1所示,它們都由類屬型屬性組成。表1所列前5個數據集均為UCI數據集,其中的Splice和Promoters是DNA序列集,其每條序列由60或57個氨基酸排列而成,各氨基酸的位點已經過對齊處理,故每個位點可以看作是一個類屬型屬性,被給予順序編碼,比如,在Splice數據中,這些位點(屬性)命名為p-30~p+30[17]。其余UCI數據集的屬性多為序數型符號,且可能包含有缺失值。例如,在Breastcancer(乳腺癌) 數據中,其9個屬性均為以1~10間整數表示的患者生理指標,其中2個包含缺失數據。在實驗中,所有缺失數據看作一個特別的符號加以處理。如表1所示,除Promoters外的UCI數據集的另一個特點是樣本分布不均衡。 表1 實驗中使用的UCI數據集和合成數據集 為檢驗算法在具有更多簇類的數據上的聚類性能,采用文獻[21]提供的方法人工合成了一個包含10個類的數據,如表1“Synthetic(合成)”所示。合成過程使用的其他參數如下:每個類的平均相關屬性數為20(占全部40個屬性的50%),所有屬性均等寬離散化為10個序數型符號。 實驗選擇K-modes(簡稱KM)[11]、CWKM[16]、MWKM[15]以及兩種混合型數據聚類算法WKP[19]和MKP(ModifiedK-Prototypes)[22]為對比算法。MWKM和WKP的參數分別設置為β=2[19]和β=9[15]。采用兩種指標評價各種算法的聚類結果:CU(CategoryUtility)指標和聚類精度(ClusteringAccuracy,CA)。其中CU是一種評價聚類質量的內部指標,其定義[18]為: 其中:#d(x)表示符號x出現整個數據集屬性d上的次數。CA是一種外部指標,是聚類結果中對象所在簇與其真實類別相匹配的對象比例,根據下式計算: 其中:I是取值0或1 的指示函數,L(x)是對象x真實的類別標號。在計算CA之前,采用二部圖(bipartite graph)最大權重匹配算法建立K個簇標號與K個真實類別標號的對應關系,其中二部圖結點對間的權重為重合對象的數目。與CU一樣,CA的值越大表示聚類結果質量越高。 3.2 聚類結果 由于各種算法的起點(初始中心或初始劃分)都是隨機選擇的,為使得聚類結果具有可比性,對于每個數據集,每種算法均獨立運行100次,然后從中選擇20次具有最高精度的結果作為實驗對比的基礎。表2列出了從每個數據集的20個最好結果中計算的平均性能,以“平均指標值±1個標準差”的格式呈現,每個數據集上最高的平均指標值以加粗方式標注。 如表2所示,WBCC算法在6個數據集上均取得了較高的聚類精度(CA),與其他算法相比,WBCC在這些數據集上都取得了明顯的精度提升,尤其在屬性數目較多的Splice和類數較多的Dermatology及合成數據上。注意到前兩個數據集中各類樣本分布很不均衡(見表1),這驗證了WBCC算法根據對象-簇間似然進行貝葉斯聚類的有效性。對于樣本數較少的類,模符號的代表性下降,進而降低了基于模的距離度量的有效性,這是5種對比算法在這些數據集上性能落后于WBCC算法的主要原因。 根據表2,CWKM算法在Dermatology上取得最高CU指標值。與MWKM和WKP僅根據模符號的頻度進行屬性加權不同,CWKM算法在計算屬性權重時使用了所有符號的頻度信息[16],從這個意義上說,該算法與WBCC是比較接近的,因而取得了高質量的聚類結果。但是,WBCC基于似然估計而非對象-模間相似度計算,在Splice等其他5個數據上獲得了明顯優于CWKM的結果。表2的數據還說明,總體而言,WBCC算法的魯棒性(體現在標準差上)略優于對比算法,這是由于WBCC的初始狀態是數據集的K個劃分,而不是對比算法的K個代表對象,一定程度上降低了算法對初始簇中心的敏感性。 表2 各算法平均CA和CU指標對比 圖1 合成數據上各種算法的平均運行時間對比 圖1對比了各種算法的聚類效率。所用數據為表1所列的合成數據集,為檢驗各種算法相對于樣本數量的可伸縮性,從原數據集(含10 000個樣本)上隨機抽取了1 250、2 500、5 000個樣本組成3個新的測試數據集。如圖所示,隨樣本量增加,WBCC算法使用的平均CPU時間呈線性增加的趨勢。此外,圖1也顯示WBCC的聚類效率介于MWKM、WKP和CWKM、KM、MKP之間;MKP算法未進行屬性加權操作,具有最高的效率;而MWKM算法為每個屬性計算多個權重,因而需要更多的運行時間。 3.3 屬性加權結果 本節從屬性加權方法的角度進一步分析WBCC算法的性能,并于CWKM、MWKM和WKP這三種同樣基于屬性加權的聚類算法作對比。圖2~5顯示了四種算法在Splice數據上計算的權重分布情況,權重數據采自各算法在100次運行中精度最高的聚類結果。為便于對比,圖2~5中各算法生成的屬性權值均規范化到區間[0,1]。選用Splice的一個原因是該數據集擁有較多的屬性(60個),便于分析;另一個原因是該數據具有明確的生物學背景[17],易于理解。Splice數據包含三個類別:EI、IE和Neither,前2個類別在p-2~p+2氨基酸位點(類屬型屬性)上含有“移植體(donor)”或“受體(acceptor)”,而它們未出現在Neither類的DNA序列上。 圖2 Splice數據上WBCC算法計算的屬性權重分布 圖3 Splice數據上CWKM算法計算的屬性權重分布 圖4 Splice數據上MWKM算法計算的屬性權重分布 圖5 Splice數據上WKP算法計算的屬性權重分布 如圖2所示,WBCC算法成功地識別出了p-2~p+2位點(屬性),對于EI和IE類,這些屬性被賦予較高的權重,而其他屬性的權重接近于0;對于Neither類,各屬性的權重都接近于0,并沒有明顯區別。這些都與上述Splice數據的生物學應用背景相符。 反觀對應于CWKM算法和MWKM算法的圖3和圖4(MWKM賦予屬性兩種權重,圖上僅顯示其中“與模頻度成正比”的部分),其權重分布與WBCC的圖2有顯著區別。如圖3~4所示,盡管在p-2~p+2位點的權重分布也呈現出了峰值,但其他屬性也被賦予了較大的權重,尤其對于Neither類,其權重分布并不平滑。同樣情況見于WKP算法輸出的圖5(WKP是全局屬性加權算法[19],因此只輸出一組權重)。上述有差異的屬性加權結果是算法不同加權方法和所采用的相似度(或距離)度量的體現。在WBCC中,屬性權重根據符號分布的信息熵計算(見式(8)),且基于對象-簇似然進行高質量的數據集劃分,因而可以獲得具有實際應用意義的屬性加權結果。 本文提出了一種新型的類屬型數據聚類算法WBCC,與當前多基于模的劃分聚類算法不同,新算法基于貝葉斯概率框架,通過最大似然估計,而不是現有多數算法所采用的對象-模間簡單符號匹配,進行數據集劃分。在聚類過程中,WBCC算法根據類屬符號分布的信息熵自動賦予每個屬性反映其重要性的權重,實現了類屬型數據的子空間聚類。在多個實際應用數據集上進行了實驗驗證,結果表明新算法是有效的,與基于模和類屬對象間距離的現有算法相比,新算法在實驗數據上的聚類結果質量得到較為明顯的改善,并輸出了與實際應用需要相吻合的屬性加權結果。 后續研究工作將著重于以下幾個方面:將新算法推廣到混合型數據,即在混合了數值型和類屬型的數據上直接(不需要將數值型數據事先離散化成類屬型)進行貝葉斯聚類;探討建立數據集初始劃分的方法,以提高算法的魯棒性。鑒于當前的聚類模型評價準則多針對數值型數據且僅對全空間聚類結構進行質量評價,后續工作還將在本文給出的類屬數據子空間聚類概率模型和傳統的貝葉斯信息準則基礎上,開展類屬數據子空間聚類有效性指標的研究,提供類屬數據集最佳聚類數目估計等問題的解決方案。 References) [1] HUNT L, JORGENSEN M. Clustering mixed data[J]. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery, 2011, 1(4):352-361. [2] BORIAH S, CHANDOLA V, KUMAR V. Similarity measures for categorical data: a comparative evaluation[C]// Proceedings of the 8th SIAM International Conference on Data Mining. Philadelphia: SIAM, 2008: 243-254. [3] CHEN L, WANG S. Central clustering of categorical data with automated feature weighting[C]// Proceedings of the 23rd International Joint Conference on Artificial Intelligence. Menlo Park, CA: AAAI Press, 2013: 1260-1266. [4] GUHA S, RASTOGI R, SHIM K. ROCK: a robust clustering algorithm for categorical attributes[J]. Information Systems, 2000, 25(5):345-366. [5] XIONG T, WANG S, MAYERS A, et al. DHCC: divisive hierarchical clustering of categorical data[J]. Data Mining and Knowledge Discovery, 2012, 24(1):103-135. [6] MACQUEEN J. Some methods for classification and analysis of multivariate observation[C]// Proceedings of the 5th Berkley Symposium on Mathematical Statistics and Probability. Berkeley: University of California Press, 1967: 281-297. [7] JI J, BAI T, ZHOU C, et al. An improvedk-prototypes clustering algorithm for mixed numeric and categorical data[J]. Neurocomputing, 2013, 120:590-596. [8] SAN O, HUYNH V, NAKAMORI Y. An alternative extension of thek-means algorithm for clustering categorical data[J]. International Journal of Applied Mathematics and Computer Science, 2004, 14(2):241-247. [9] HUANG Z, NG M. A note onk-modes clustering[J]. Journal of Classification, 2003, 20(2):257-261. [10] 李仁侃, 葉東毅. 粗糙k-modes聚類算法[J]. 計算機應用, 2011, 31(1): 97-100.(LI R K, YE D Y. Roughk-modes clustering algorithm[J]. Journal of Computer Applications, 2011, 31(1): 97-100.) [11] HUANG Z. Extensions to thek-means algorithm for clustering large data sets with categorical values[J]. Data Mining and Knowledge Discovery, 1998, 2(3):283-304. [12] 梁吉業, 白亮, 曹付元. 基于新的距離度量的k-modes聚類算法[J]. 計算機研究與發展, 2010, 47(10):1749-1755.(LIANG J Y, BAI L, CAO F Y.k-modes clustering algorithm based on a new distance measure[J]. Journal of Computer Research and Development, 2010, 47(10):1749-1755.) [13] LIN D. An information-theoretic definition of similarity[C]// Proceedings of the 15th International Conference on Machine Learning. San Francisco: Morgan Kaufmann, 1998: 296-304. [14] GOODALL D. A new similarity index based on probability[J]. Biometrics, 1966, 22(4):882-907. [15] BAI L, LIANG J, DANG C, et al. A novel attribute weighting algorithm for clustering high-dimensional categorical data[J]. Pattern Recognition, 2011, 44(12): 2843-2861. [16] CAO F, LIANG J, LI D, et al. A weightingk-modes algorithm for subspace clustering of categorical data[J]. Neurocomputing, 2013, 108: 23-30. [17] CHEN L, WANG S, WANG K, et al. Soft subspace clustering of categorical data with probabilistic distance[J]. Pattern Recognition, 2016, 51:322-332. [18] 陳黎飛, 郭躬德. 屬性加權的類屬型數據非模聚類[J]. 軟件學報, 2013, 24(11):2628-2641.(CHEN L F, GUO G D. Non-mode clustering of categorical data with attributes weighting[J]. Journal of Software, 2013, 24(11):2628-2641.) [19] HUANG Z, NG M, RONG H, et al. Automated variable weighting ink-means type clustering[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2005, 27(5):657-668. [20] BOUGUESSA M. Clustering categorical data in projected spaces[J]. Data Mining and Knowledge Discovery, 2015, 29(1): 3-38. [21] CHEN L. A probabilistic framework for optimizing projected clusters with categorical attributes[J]. Science China Information Sciences, 2015, 58(7): 072104(15). [22] LIANG J, ZHAO X, LI D, et al. Determining the number of clusters using information entropy for mixed data[J]. Pattern Recognition, 2012, 45(6):2251-2265. This work is partially supported by the National Natural Science Foundation of China (61175123), the Natural Science Foundation of Fujian Province (2015J01238). ZHU Jie, born in 1971, senior engineer. His research interests include pattern recognition, target identification. CHEN Lifei, born in 1972, Ph. D., professor. His research interests include statistical machine learning, data mining, pattern recognition. Bayesian clustering algorithm for categorical data ZHU Jie1, CHEN Lifei2* (1. Southwest China Institute of Electronic Technology, Chengdu Sichuan 610036, China;2. School of Mathematics and Computer Science, Fujian Normal University, Fuzhou Fujian 350117, China) To address the difficulty of defining a meaningful distance measure for categorical data clustering, a new categorical data clustering algorithm was proposed based on Bayesian probability estimation. Firstly, a probability model with automatic attribute-weighting was proposed, in which each categorical attribute is assigned an individual weight to indicate its importance for clustering. Secondly, a clustering objective function was derived using maximum likelihood estimation and Bayesian transformation, then a partitioning algorithm was proposed to optimize the objective function which groups data according to the weighted likelihood between objects and clusters instead of the pairwise distances. Thirdly, an expression for estimating the attribute weights was derived, indicating that the weight should be inversely proportional to the entropy of category distribution. The experiments were conducted on some real datasets and a synthetic dataset. The results show that the proposed algorithm yields higher clustering accuracy than the existing distance-based algorithms, achieving 5%-48% improvements on the Bioinformatics data with meaningful attribute-weighting results for the categorical attributes. data clustering; categorical attribute; attribute weighting; Bayesian clustering; probability model 2016- 09- 12; 2016- 12- 23。 國家自然科學基金資助項目(61175123);福建省自然科學基金資助項目(2015J01238)。 朱杰(1971—),男,浙江余姚人,高級工程師,主要研究方向:模式識別、目標識別; 陳黎飛(1972—),男,福建長樂人,教授,博士,主要研究方向:統計機器學習、數據挖掘、模式識別。 1001- 9081(2017)04- 1026- 06 10.11772/j.issn.1001- 9081.2017.04.1026 TP274.2 A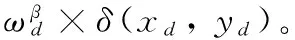
2 貝葉斯聚類算法
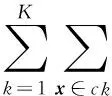
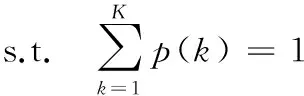
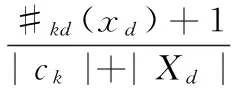
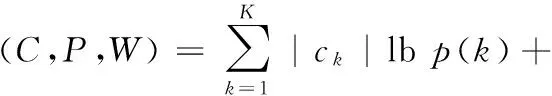
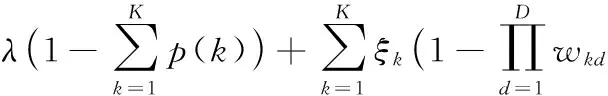

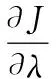
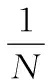
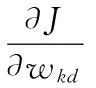
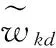
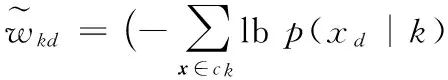
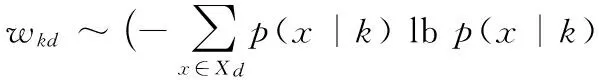
3 實驗與分析
4 結語
猜你喜歡
ELLE世界時裝之苑(2024年5期)2024-05-14 16:00:39
中學生數理化·七年級數學人教版(2021年10期)2021-11-22 07:53:00
幼兒園(2021年6期)2021-07-28 07:42:14
小學生學習指導(低年級)(2019年11期)2019-11-25 07:31:48
散文詩(2017年17期)2018-01-31 02:34:20
小學生學習指導(低年級)(2018年3期)2018-01-31 02:19:05
小學生導刊(2017年13期)2017-06-15 20:29:38
哈爾濱師范大學自然科學學報(2015年1期)2015-04-19 06:55:26
天津科技大學學報(2015年4期)2015-04-16 04:55:11
科普童話·百科探秘(2014年5期)2015-03-09 09:07:41
