融合規則與統計的微博新詞發現方法
2017-06-27 08:10:42周霜霜徐金安陳鈺楓張玉潔
計算機應用 2017年4期
周霜霜,徐金安,陳鈺楓,張玉潔
北京交通大學 計算機與信息技術學院,北京 100044)(*通信作者電子郵箱jaxu@bjtu.edu.cn)
融合規則與統計的微博新詞發現方法
周霜霜,徐金安*,陳鈺楓,張玉潔
北京交通大學 計算機與信息技術學院,北京 100044)(*通信作者電子郵箱jaxu@bjtu.edu.cn)
結合微博新詞的構詞規則自由度大和極其復雜的特點,針對傳統的C/NC-value方法抽取的結果新詞邊界的識別準確率不高,以及低頻微博新詞無法正確識別的問題,提出了一種融合人工啟發式規則、C/NC-value改進算法和條件隨機場(CRF)模型的微博新詞抽取方法。一方面,人工啟發式規則是指對微博新詞的分類和歸納總結,并從微博新詞構詞的詞性(POS)、字符類別和表意符號等角度設計的微博新詞的構詞規則;另一方面,改進的C/NC-value方法通過引入詞頻、鄰接熵和互信息等統計量來重構NC-value目標函數,并使用CRF模型訓練和識別新詞,最終達到提高新詞邊界識別準確率和低頻新詞識別精度的目的。實驗結果顯示,與傳統方法相比,所提出的方法能有效地提高微博新詞識別的F值。
微博新詞;構詞規則;統計量特征;C/NC-value方法;條件隨機場模型
0 引言
微博是中國最熱門的社交平臺之一,是網絡新詞的主要來源。微博新詞作為未登錄詞的大量出現,給微博文本分析帶來很大困難。其中,微博文本的分詞精度低下是必須解決的首要問題。既有研究結果顯示,60%的分詞錯誤都由未登錄詞導致[1]。如何有效地提高微博新詞的識別精度,具有重要的研究意義和實用價值。目前,微博新詞識別主要研究方法包括:基于規則、基于統計、規則與統計相融合等三種方法。
基于規則的方法是從語言學的角度對新詞的構詞規則進行歸納總結并構建正則表達式規則庫。鄒綱等[2]針對網頁上的中文新詞識別問題,提出一種從網頁中自動檢測新詞語的方法,并根據構詞規則對自動檢測的結果進行過濾,最終抽取新詞語。該方法對高頻新詞有很好的識別效果。Ma等[3]針對網絡新聞中的未登錄詞,提出一種自下而上的歸并算法,同時引入一些基本語法規則,避免了過多的高頻垃圾串的抽取。Sasano等[4]針對日語中的未登錄詞,利用衍生規則和象聲詞模式,通過在句子的格框架中添加新節點的方式發現最優路徑,以此實現對未登錄詞的識別,該方法對某些特定類別的未登錄詞有很好的識別效果。基于規則的方法針對特定領域可以得到很高的準確率,但是人工制定規則需要大量人工成本,存在規則領域性適應能力低下等問題。
基于統計的方法通常使用大規模語料庫,通過計算統計信息量來發現新詞。Wang 等[5]將新詞識別問題與分詞問題結合,在對文本分詞標注和新詞標注的基礎上,利用統計量特征對改進的條件隨機場(Conditional Random Field, CRF)模型進行訓練,同時提高了分詞和新詞識別的效果。Sun等[6]融合詞法特征和邊界特征,提出一種快速的線上CRF訓練方法,將識別到的新詞加入到詞典列表不斷進行模型訓練,最后分詞結果和新詞識別結果都得到了提升。Huang等[7]設定少量種子新詞,并依據詞性構建三元組模型循環擴充新詞候選集,通過一系列統計量特征將新詞識別結果量化。該方法不需要復雜的語言規則,只在詞性標注的基礎上就可以得到很好的新詞識別效果。邢恩軍等[8]提出一種基于上下文詞頻詞匯量的統計指標,該指標通過將信息熵公式中的鄰接字符串在語料集中出現的次數改成鄰接字符串集合的大小,克服了左右信息熵在識別新詞時特征不夠明顯的缺點。該方法與領域無關,且對新詞的長度沒有限制,僅采用一個統計指標就能取得較好的效果。統計方法有很強的領域適應能力和可擴展性,但具有需要大規模語料庫和數據稀疏問題嚴重等問題。
規則和統計相融合的方法是目前研究的主流方法。Nuo等[9]提出一種將統計度量值和上下文規則結合的新詞識別方法,先利用互信息等統計量將結合度高的單字組合形成候選新詞,并利用基于上下文的擴展機制,確定新詞的左右邊界。通過該方法構建的新詞詞典有效地提高了分詞效果,但只局限于識別被切分成單字碎片的新詞。杜麗萍等[10]提出一種非監督的新詞識別方法,利用點互信息(Pointwise Mutual Information, PMI)的改進算法——PMIk算法與少量基本的過濾規則相結合,從大規模百度貼吧語料中自動識別出網絡新詞,實驗結果顯示該方法比改進前的算法取得了更好的新詞識別效果。Li等[11]使用基于支持向量機(Support Vector Machine, SVM)和詞特征的方法進行新詞識別,并在程序中引入了少量的規則過濾,有效地提高了新詞識別的效果。Attia等[12]通過使用有限狀態的詞法猜測工具和基于機器學習的預標注工具體系來進行未登錄詞的抽取,實驗證實方法的有效性并已將抽取的未登錄詞集合作為公開的開放資源。規則和統計相融合的方法可以相互取長補短,在一定程度上緩解單獨使用統計方法造成的數據稀疏問題,同時解決單獨使用規則方法造成的領域適應能力差等問題。
綜上所述,針對傳統方法所存在的問題,本文提出了一種基于規則與統計相融合的方法。該方法針對微博新詞的構詞規則極其復雜和自由度大的特點,構建人工啟發式規則庫,引入新的統計量特征改進傳統的C/NC-value方法,并將抽取得到的新詞集作為訓練數據,利用條件隨機場模型對訓練語料進行新詞的標注、建模和識別,最終有效地提高了新詞邊界的識別準確率和低頻新詞的識別精度。最后,將抽取的微博新詞集合加入微博分詞的用戶字典,分詞實驗結果顯示可有效提高微博文本的分詞和詞性標注精度。本文方法具有不需要大規模語料庫作為學習數據進行訓練、計算量小、精準度高等優點。
1 流程描述
本文方法流程如圖1所示,主要包括數據預處理、規則方法抽取、改進C/NC-value方法過濾、后處理和CRF模型訓練與識別新詞等5個部分。
第1步 數據預處理。主要包括:
1)將文本字符統一轉換為UTF-8編碼。
2)過濾微博文本中某些固定格式的特殊字符串。主要包括三類:一是網頁地址URL,如“http://t.cn/zOixljh”“http://t.cn/RPKM61K”等;二是郵箱地址,如“cszyzxj@163.com”“mcq0544@qq.com”等;三是微博文本特有的一種字符串格式,由符號“@”后面緊跟一個用戶名稱和一個空格符號組成,表示提及該用戶,如“@且聽風吟_5734”和“@李開復”等。
3)通過實驗室獨自研發的基于感知機的微博文本分詞工具對微博語料進行分詞和詞性標注處理。如:“石家莊/ns火車站/n成功/a地/u接受/v了/u冰/n桶/q 挑戰/v,/wd接/v下來/v,/wd他/rr有/v權/n挑戰/v三/m個/q火車站/n。/wj”。
第2步 使用新詞的構詞規則庫對已經經過預處理的微博語料進行新詞抽取,得到新詞候選串。
第3步 利用統計量信息重構NC-value目標函數,對新詞候選串進行篩選。
第4步 有針對性地制定規則對一些明顯錯誤的識別結果進行過濾,得到初步新詞集。部分規則實例如下:
1)數字加量詞的組合構成的常規字符串,如:“2015年”“12歲”“3個”等;
2)符號組合形成的非表情字符串,如“!!!”“???”“<<<”等;
3)非語氣詞與語氣詞組合形成的字符串,如“是嗎”“在呢”“行啊”等。
第5步 將抽取的新詞集作為訓練數據,利用條件隨機場模型對訓練語料進行新詞的標注、建模和識別,最后經后處理得到最終的新詞集。
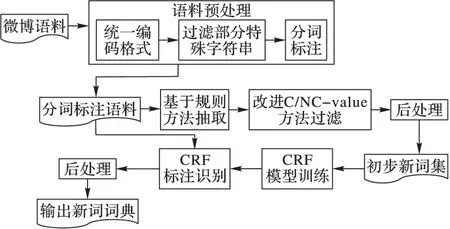
圖1 系統流程
2 微博新詞構詞特點及規則歸納
2.1 微博新詞構詞特點
微博新詞具有涉及領域廣、構詞模式相對自由等特點,因此,從多種角度對新詞進行分析和歸納,總結新詞產生的途徑和構詞規律可有效提高新詞的抽取精度。
2.2 微博新詞構詞規則
如表1所示,微博新詞的構詞方式復雜多樣,有諧音詞、方言詞、舊詞新用、縮略詞、英語音譯詞、符號新詞和新造詞等。從詞性構成的角度分析,新詞的組成集中在名詞、動詞、形容詞和區別詞之間,同時介詞與副詞也具備了一定的構詞能力,能夠與其他詞語組合形成新詞。從音節的角度分析,新詞構成的總趨勢是向多音節發展,以雙音節、三音節和四音節為主;同時,微博新詞還充分運用了英語、漢語、數字、符號等互相組合的方式,結構新穎自由。本文主要從三個角度進行總結:
1) 詞性構成,包括動詞、名詞、形容詞、區別詞相互組合的常規規則以及介詞、副詞與名詞、動詞組合的特殊規則。規則實例見表2的詞性。
2) 成詞字符類別,主要針對英文、數字和漢字的組合。規則實例見表2的字符類別。
3) 符號表意規則,微博文本中存在大量的表情符號,本文將其總結為兩類:一是靜態表情符號,是由一些基本的符號組合形成的,形式上類似于日語中的顏文字;二是動態表情符號,有固定的構成格式:“[字符串]”。規則實例見表2的符號。

表1 微博新詞構詞特點

表2 新詞規則
3 新詞發現
3.1 C/NC-value算法
該算法由Frantzi等[13]提出,是一種領域獨立的復合詞抽取算法。主要包括兩部分:
一是基于統計量信息計算C-value值,統計信息包括候選詞的詞頻和詞長以及包含當前候選詞的更長候選詞的詞頻和詞數,如式(1)所示:
(1)
其中:w=w1w2…wn是候選詞;|w|表示w的長度; f(w)表示w的詞頻;Tw表示包含w的候選詞集;a表示Tw中任意的包含w的候選詞; f(a)表示a的詞頻; p(Tw)表示包含w的候選詞總數。
二是結合上下文信息計算NC-value值,上下文信息是指出現在候選詞前后的上下文相關詞的統計信息,包括上下文相關詞出現在候選詞前后的次數和權重,權重通過與上下文相關詞同時出現的候選詞的數量除以總的候選詞的數量計算得到,如式(2)所示:
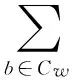
α+β=1
(2)
其中:Cw表示出現在候選詞w前后的上下文相關詞集合,b表示Cw中任意的出現在候選詞w前后的上下文相關詞,fw(b)表示b在候選詞w的上下文中出現的次數,t(b)表示與b同時出現的候選詞數量,n表示候選詞的總個數。α和β為取值0~1的參數。
3.2 改進的C/NC-value算法
既有C/NC-value方法抽取微博新詞的缺點主要包括:1)部分識別結果存在詞語粘連現象,新詞的邊界識別不正確;2)低頻新詞無法正確識別。
針對上述問題,本文引入鄰接熵和互信息兩種統計量,重構NC-value目標函數,以提高新詞邊界的識別準確率和低頻新詞的識別精度。使用鄰接熵改善分詞精度的方法由Huang等[14]提出,能有效解決未登錄詞的左右邊界問題。該方法利用信息熵來衡量候選新詞的左鄰字符和右鄰字符的不確定性,候選新詞的鄰接熵越大,說明鄰接字符的不確定性越大,成為新詞邊界的可能性就越大。具體定義如式(3)~(5)所示:
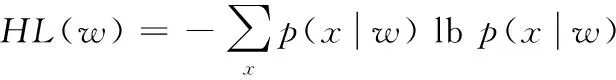
(3)
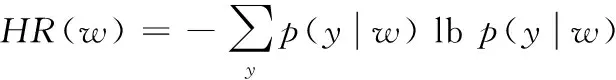
(4)
BE(w)=min{HL(w),HR(w)}
(5)
互信息是一個用來衡量候選詞子串之間的結合程度的統計量。本文將互信息加入到目標函數中,通過計算候選低頻新詞及其子串間的結合程度來提高微博低頻新詞的識別精度。根據文獻[15]對互信息的定義,本文改進如式(6)所示:
(6)
其中:p(w)表示w出現的頻率;p(w1w2…wi)表示w的子串w1w2…wi出現的頻率;p(wi+1wi+2…wn)表示w的子串wi+1wi+2…wn出現的頻率。改進后的NC-value值計算如式(7)所示:
NC-value(w)=α*C-value(w)+β*BE(w)+γ*MI(w);α+β+γ=1
(7)
其中:C-value(w)是根據式(1)得到的C-value值;BE(w)是根據式(3)、(4)、(5)得到的鄰接熵值;MI(w)是根據式(6)得到的互信息值;α、β和γ為參數,取值范圍為[0,1]。
3.3 條件隨機場(CRF)
CRF模型由Lafferty等[16]提出,是一種典型的判別式模型。它在觀測序列的基礎上對目標序列進行建模,重點解決序列化標注的問題。條件隨機場的定義如式(8)所示:

(8)
其中:tk(yi-1,yi,x,i)為轉移函數,表示觀察序列和標記序列在i-1和i時刻的特征;sk(yi,x,i)為狀態函數,表示觀察序列和標記序列在i時刻的特征;Z(X)為歸一化因子;λ和u為訓練所得參數。
CRF模型將新詞發現看作一個序列標注過程,利用單字在新詞中的位置信息來標記新詞。本文采用四詞位標注集,如表3所示。

表3 四詞位標注集
特征模板的設置主要利用上下文的信息,從訓練語料中獲得字特征,采用當前字和其前后兩個字及其詞性信息作為特征。特征模板具體描述如表4所示。
將得到的初步新詞的特征量化,作為訓練特征,利用CRF模型訓練出新詞抽取模板,利用該模型對預處理的微博語料進行標注抽取,并對抽取結果進行后處理修正,識別出更多的新詞。最后,將CRF模型識別出的新詞與初步得到的新詞集合并整理,即為最終識別出的新詞集。
4 實驗與分析
4.1 實驗語料
由于目前尚無公開的微博新詞標準數據集,新詞發現實驗使用的語料數據來源于爬萌(http://www.cnpameng.com/),從2014年6月1日的新浪微博數據(約10萬條)中隨機抽取出2萬條,通過實驗室獨自研發的基于感知機的微博文本分詞工具進行分詞和詞性標注處理,并對預處理后的語料進行新詞的規則方法抽取和C/NC-value的改進算法識別,得到初步的新詞集。
從語料中抽取新詞并進行人工校對,共抽取新詞800個,作為標準新詞集。通常來講,新詞是指未被收錄到詞典中的詞語[17]。在本研究任務中,新詞滿足以下條件:1) 符合本文提出的構詞規則;2) 不在用戶字典中;3) 分詞工具切分出現錯誤;4) 在網絡上被廣泛使用。
4.2 評價方法
通過準確率P、召回率R和F值對新詞發現實驗的結果進行評價。計算公式如下所示:
(9)

(10)
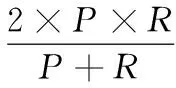
(11)
4.3 初步實驗及參數優化
在計算NC-value值獲取初步新詞集的過程中,需要對候選新詞w的C-value值、鄰接熵和互信息的權重,即參數α、β和γ進行設定。先對三種統計量單獨使用時的情況進行實驗,結果見表5的三種統計量單獨使用部分。實驗結果顯示,單獨使用三種統計量得到的準確率P、召回率R和F值均較低,新詞識別效果較差。
接下來,對三個參數的取值進行調整。依據貪心算法的思想,在滿足α+β+γ=1的基礎上,先將α置于0~1取值,β則在0~1-α取值,相應的γ值為1-α-β,以0.1為步長對三個參數動態調整,結果顯示當α=0.4時得到了最大的F值;再將α的取值范圍設為0.35~0.45,β的取值范圍仍為0~1-α,γ值仍為1-α-β,以0.01為步長再次對三個參數動態調整,記錄下得到最大的F值時的參數取值。再按照相同的方法,依次對β和γ做同樣的實驗。三種情況下得到的最大的F值及相應的參數取值如表5的調參實驗結果部分所示。結果顯示,當α=0.34,β=0.35,γ=0.31時得到了最大的F值,即達到了最好的新詞識別效果。
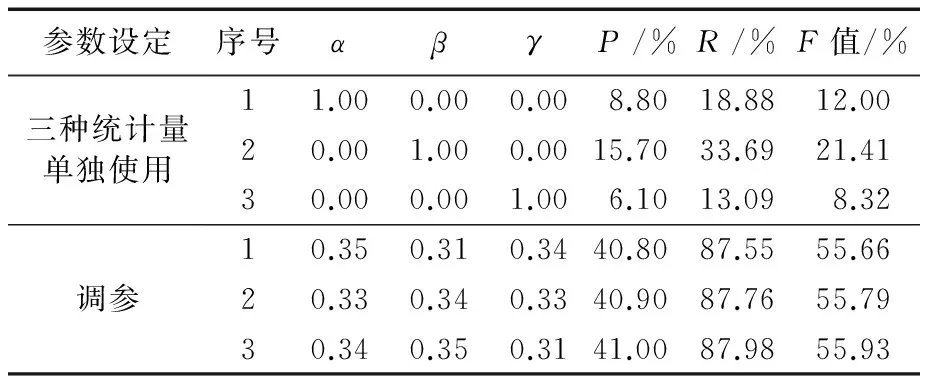
表5 三種統計量單獨使用時和調參的實驗結果
對候選新詞的NC-value值設定閾值,如果閾值設定過高,會過濾掉很多有意義的新詞;反之,如果閾值設定過低,又會使新詞結果中出現很多垃圾串。多次實驗結果顯示,閾值設定為0.42時效果最佳。本文中,當NC-value值大于0.42時,判定該候選詞為初步的新詞。
4.4 新詞發現實驗結果及分析
將本文方法與傳統的新詞發現方法進行對比,選取文獻[10-12]分別提出的方法作為三個基線系統,同時將三個基線系統方法、單獨使用規則的方法、單獨使用改進的C/NC-value方法、規則與傳統的C/NC-value結合的方法、規則與改進的C/NC-value結合的方法、結合支持向量機(SVM)分類器(http://www.csie.ntu.edu.tw/~cjlin/libsvm/)的方法與本文提出的結合條件隨機場(CRF)模型(https://sourceforge.net/projects/crfpp/)的方法進行新詞識別的對比實驗,實驗結果見表6。
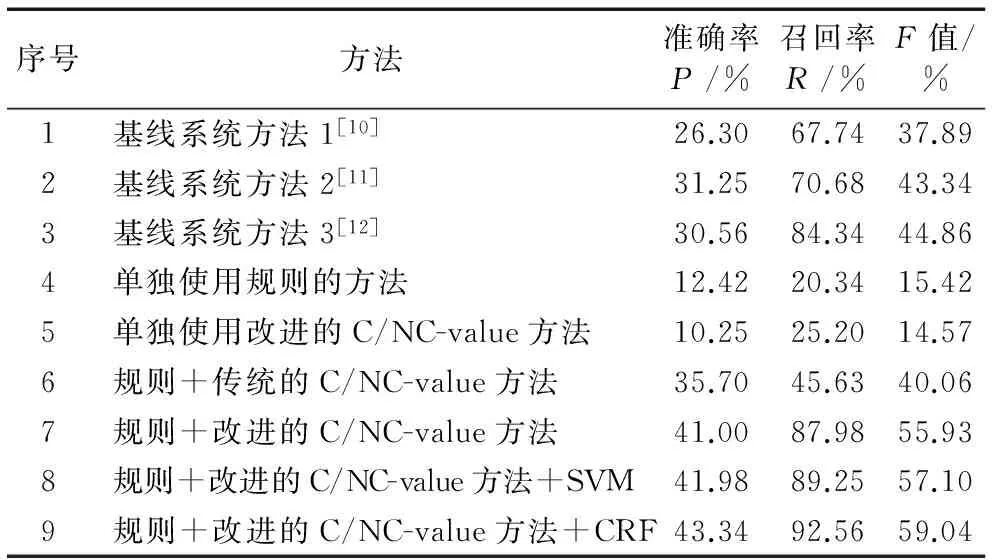
表6 新詞發現結果
實驗結果分析:
1)基線方法1[10]提出了PMI的改進算法,并使用部分過濾規則;基線方法2[11]使用基于SVM和詞特征的方法進行新詞識別,并在程序中引入了少量的規則過濾;基線方法3[12]通過使用有限狀態的詞法猜測工具和基于機器學習的預標注工具體系來進行未登錄詞的抽取。三個基線系統都得到較高的召回率,但新詞識別的準確率較低。一些新詞與其他詞語被錯誤地劃分成一個字串,如在新詞識別結果中出現“太給力”“驚呆了”“的惡搞”等詞。而本文方法更關注微博新詞的語言學特點,進行歸納總結和制定規則,識別結果中均是符合構詞規則的詞語。如在預處理后的語料中存在“太/d給/p力/n”“驚/v呆/v了/y”“的/u惡/a搞/v”的切分,通過使用規則“介詞+名詞”可以將“給力”正確抽取,使用規則“動詞+動詞”可以將“驚呆”正確抽取, 使用規則“形容詞+動詞”可以將“惡搞”正確抽取,因此,構詞規則的引入可以很好地提升新詞識別的準確率。
2)通過對實驗4和實驗5的結果分析可以發現:單獨使用規則的方法,由于缺少對候選串的過濾機制,識別結果中存在大量的非新詞詞語,如“拼盡”(拼/v盡/v)、“學英語”(學/v英語/n)、“媒體人”(媒體/n人/n)等;單獨使用改進的C/NC-value統計方法,由于缺少規則方法抽取候選串的過程,使新詞識別結果中出現大量的垃圾串,如“真好看”“太稀飯”“小心啊”等,因此,兩種方法得到的準確率和召回率均相對較低。本文將規則與統計的方法進行融合,減少了垃圾串的產生,同時又能過濾掉大部分的非新詞詞語,使新詞識別的準確率和召回率都得到很大的提升。
3)實驗6是在規則抽取的基礎上利用傳統的NC-value目標函數過濾得到新詞。規則的引入使其得到相對較高的準確率,不符合本文構詞規則的詞語不會出現在候選新詞列表中;但是新詞識別的召回率較低,說明目標函數考慮的統計信息對新詞的識別效果不佳。實驗7提出的改進的C/NC-value方法,通過引入鄰接熵和互信息有效提高了新詞發現精度。鄰接熵的引入可以很好地解決新詞邊界問題,如通過規則方法抽取后,“歡迎點贊”(歡迎/v點/v贊/v)、“點贊”(點/v贊/v)、“點贊支持”(點/v贊/v支持/v)都出現在候選新詞列表中,通過改進的NC-value方法可以準確地確定新詞的左右邊界,將“點贊”保留,其余兩種情況被過濾掉,因此進一步提高了新詞識別的準確率;同時,互信息反映了候選詞子串之間的結合程度,當低頻新詞的子串出現的頻率也較低,子串之間的結合程度緊密時,其互信息值仍然較高,從而達到精確識別該類新詞的效果。
4)實驗8和實驗9是在得到的初步新詞集的基礎上分別結合SVM分類器和CRF模型進行新詞識別。實驗依據初步新詞集對分詞后的語料進行標注得到訓練集,經分詞工具粗切分的語料作為測試集。其中,在實驗8中,通過選取詞頻、鄰接熵和互信息三個特征組成特征向量,相關參數設定參照文獻[11]。在實驗9中,通過將得到的初步新詞的特征量化作為訓練特征,并利用CRF模型構建新詞抽取模板,對測試語料進行新詞的標注識別。實驗結果顯示兩種方法均能進一步提高對低頻新詞的識別效果。其中,基于序列標注的CRF模型更有效地利用了新詞的上下文信息,對新詞的識別效果達到最佳。通過本文方法識別到的低頻新詞包括“細思恐極”“喜大普奔”“累覺不愛”“hold住”等。
4.5 微博分詞測試
為了驗證本文方法的有效性,將采用不同新詞識別方法得到的新詞集合作為用戶詞典加入到實驗室獨自研發的微博文本分詞工具中,進行分詞和詞性標注實驗,實驗結果如表7所示。本實驗使用2016年NLPCC(http://tcci.ccf.org.cn/conference/2016/pages/page05_evadata.html)微博分詞評測任務提供的2萬條訓練集作為訓練語料,8 000條測試集作為測試語料,同時參照基于賓州大學漢語樹庫的分詞標準[18]對測試語料進行分詞和人工校對,參照中國科學院計算技術研究所漢語詞性標記集(http://ictclas.nlpir.org/nlpir/html/readme.htm)進行手工詞性標注。
實驗評價方法仍然使用準確率P、召回率R和F值,其中準確率P和召回率R定義如下:
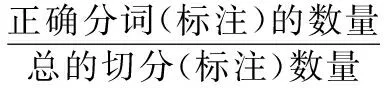
(12)

(13)
實驗結果如表7所示。從實驗結果可看出:1)通過與不加用戶詞典得到的結果對比,加入不同的新詞識別方法得到的新詞詞典,分詞和詞性標注結果的F值都得到了提升,說明新詞詞典的加入可以提高分詞系統的分詞標注精度。2)使用新詞用戶詞典,可以糾正不同類型新詞出現的分詞和詞性標注錯誤,尤其對符合本文提出的構詞規則的新詞效果顯著。如不同詞性組合構成的新詞、數字與漢字結合構成的新詞和表情符號等。三種不同類別的新詞被切分的情況如圖2所示。3)相比其他方法,使用本文方法構建的新詞詞典在分詞標注結果中得到了最大的F值,說明了本文方法的有效性。

圖2 分詞和詞性標注實例
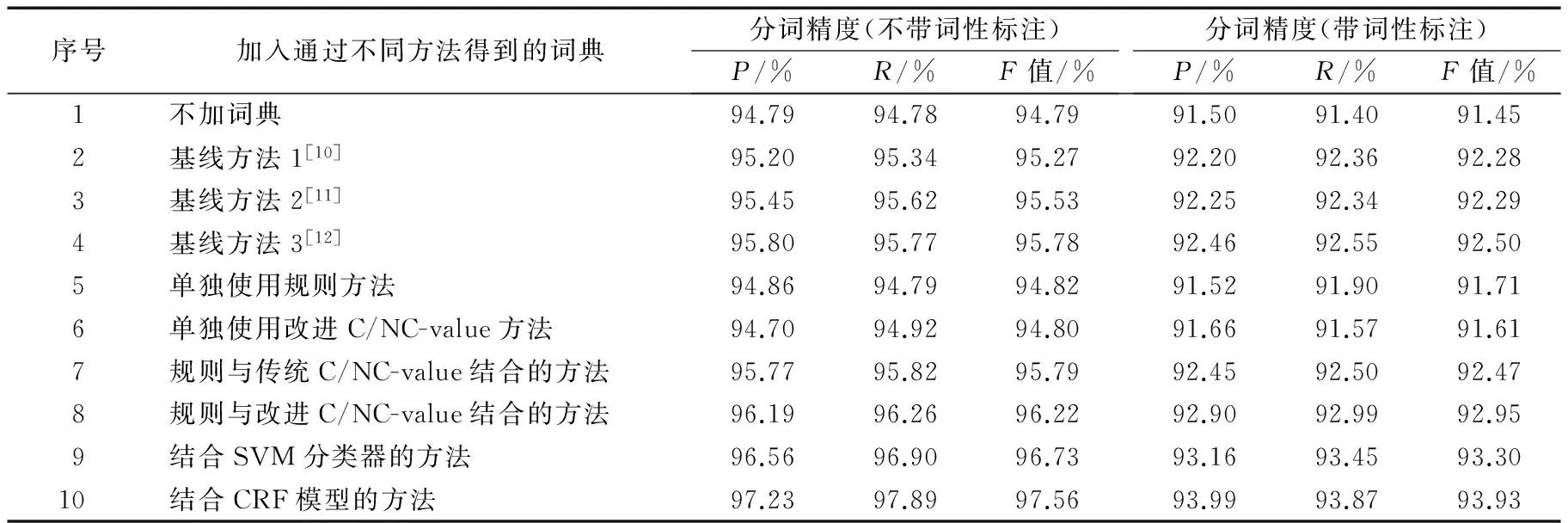
序號加入通過不同方法得到的詞典分詞精度(不帶詞性標注)P/%R/%F值/%分詞精度(帶詞性標注)P/%R/%F值/%1不加詞典94.7994.7894.7991.5091.4091.452基線方法1[10]95.2095.3495.2792.2092.3692.283基線方法2[11]95.4595.6295.5392.2592.3492.294基線方法3[12]95.8095.7795.7892.4692.5592.505單獨使用規則方法94.8694.7994.8291.5291.9091.716單獨使用改進C/NC-value方法94.7094.9294.8091.6691.5791.617規則與傳統C/NC-value結合的方法95.7795.8295.7992.4592.5092.478規則與改進C/NC-value結合的方法96.1996.2696.2292.9092.9992.959結合SVM分類器的方法96.5696.9096.7393.1693.4593.3010結合CRF模型的方法97.2397.8997.5693.9993.8793.93
5 結語
本文結合微博新詞的構詞規則極其復雜和自由度大的特點,針對傳統的C/NC-value方法抽取的結果詞語粘連現象嚴重,新詞邊界的識別準確率不高,以及部分微博新詞由于出現頻率低而無法正確識別的問題,提出了一種融合規則和統計的微博新詞發現方法。通過對微博文本新詞的構詞規則進行歸納總結,建立新詞構詞規則庫;通過改進傳統的C/NC-value方法,重構NC-value目標函數,并結合條件隨機場模型(CRF)訓練和識別新詞,提高了新詞邊界的識別準確率和低頻新詞的識別精度。最后,將新詞識別結果加入用戶字典,分詞實驗結果顯示提高了微博文本分詞和詞性標注的精度。
本研究主要特點如下:
1) 通過對大量微博文本新詞的歸納分析,對微博新詞的構詞規則作了系統的分類和總結,在人工啟發式構詞規則中融合了詞性、構詞字符類別和符號表意等特征。
2) 針對微博新詞發現,改進了C/NC-value算法。導入詞頻、鄰接熵和互信息,重構NC-value的目標函數,有效地解決了該算法抽取結果所包含的詞語粘連現象相對嚴重、新詞邊界識別準確率不高以及低頻新詞無法正確識別的問題。
3) 使用條件隨機場模型(CRF)進一步提高了對低頻新詞的識別精度,使識別效果得到了很大的提升。
4) 規則與統計方法相融合,相互取長補短,該方法具有不需要大規模語料庫、計算量小、精準度高等特點。
未來工作中,將進一步分析新詞識別結果的錯誤類型,面向大規模開放微博語料,總結和歸納微博新詞的構詞規則,以及改進統計算法提高新詞識別精度。
References)
[1] SPROAT R, EMERSON T. The first international Chinese word segmentation bakeoff [C]// Proceedings of the 2nd SIGHAN Workshop on Chinese Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2003, 17: 133-143.
[2] 鄒綱, 劉洋, 劉群, 等.面向Internet的中文新詞語檢測[J]. 中文信息學報, 2004, 18(6):1-9.(ZOU G, LIU Y, LIU Q, et al. Internet-oriented Chinese new words detection [J]. Journal of Chinese Information Processing, 2004, 18(6):1-9.)
[3] MA W Y, CHEN K J. A bottom-up merging algorithm for Chinese unknown word extraction [C]// Proceedings of the 2nd SIGHAN Workshop on Chinese Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2003, 17: 31-38.
[4] SASANO R, KUROHASHI S, OKUMURA M. A simple approach to unknown word processing in Japanese morphological analysis [J]. Nuclear Physics A, 2014, 21(6): 1183-1205.
[5] WANG A, KAN M Y. Mining informal language from Chinese microtext: joint word recognition and segmentation [EB/OL]. [2016- 01- 06]. http://www.aclweb.org/old_anthology/P/P13/P13-1072.pdf.
[6] SUN X, WANG H, LI W. Fast online training with frequency-adaptive learning rates for Chinese word segmentation and new word detection [C]// Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics: Long Papers. Stroudsburg, PA: Association for Computational Linguistics, 2012, 1: 253-262.
[7] HUANG M, YE B, WANG Y, et al. New word detection for sentiment analysis [EB/OL]. [2016- 01- 03]. http://mirror.aclweb.org/acl2014/P14-1/pdf/P14-1050.pdf.
[8] 邢恩軍, 趙富強.基于上下文詞頻詞匯量指標的新詞發現方法[J]. 計算機應用與軟件, 2016, 33(6):64-67.(XING E J, ZHAO F Q. A novel approach for Chinese new word identification based on contextual word frequency-contextual word count [J]. Computer Applications and Software, 2016, 33(6): 64-67.)
[9] NUO M, LIU H, LONG C, et al. Tibetan unknown word identification from news corpora for supporting lexicon-based Tibetan word segmentation [EB/OL]. [2016- 01- 03]. http://rsr.csdb.cn/serverfiles/csdb/paper/upload/20151021/201510210132497839.pdf.
[10] 杜麗萍, 李曉戈, 于根, 等.基于互信息改進算法的新詞發現對中文分詞系統改進[J]. 北京大學學報(自然科學版), 2016, 52(1):35-40.(DU L P, LI X G, YU G, et al. New word detection based on an improved PMI algorithm for enhancing segmentation system [J]. Acta Scientiarum Naturalium Universitatis Pekinensis, 2016, 52(1): 35-40.)
[11] LI C, XU Y. Based on support vector and word features new word discovery research [M]// Trustworthy Computing and Services. Berlin: Springer, 2013: 287-294.
[12] ATTIA M, SAMIH Y, SHAALAN K, et al. The floating Arabic dictionary: an automatic method for updating a lexical database through the detection and lemmatization of unknown words [EB/OL]. [2016- 01- 03]. http://www.aclweb.org/anthology/C12-1006.
[13] FRANTZI K, ANANIADOU S, MIMA H. Automatic recognition of multi-word terms: the C-value/NC-value method [J]. International Journal on Digital Libraries, 2000, 3(2): 115-130.
[14] HUANG J H, POWERS D. Chinese word segmentation based on contextual entropy [EB/OL]. [2016- 01- 06]. http://www.aclweb.org/website/old_anthology/Y/Y03/Y03-1017.pdf.
[15] YE Y, WU Q, LI Y, et al. Unknown Chinese word extraction based on variety of overlapping strings [J]. Information Processing and Management, 2013, 49(2): 497-512.
[16] LAFFERTY J D, MCCALLUM A, PEREIRA F C N. Conditional random fields: probabilistic models for segmenting and labeling sequence data [C]// Proceedings of the 18th International Conference on Machine Learning. San Francisco, CA: Morgan Kaufmann, 2001: 282-289.
[17] LI H, HUANG C, GAO J, et al. The use of SVM for Chinese new word identification [C]// Proceedings of the 1st International Joint Conference on Natural Language Processing. Berlin: Springer, 2004: 723-732.
[18] XIA F. The segmentation guidelines for the PENN Chinese treebank (3.0) [EB/OL]. [2016- 01- 07]. http://repository.upenn.edu/cgi/viewcontent.cgi?article=1038&context=ircs_reports.
This work is partially supported by National Natural Science Foundation of China (61370130, 61473294), the Fundamental Research Funds for the Central Universities (2014RC040), the International Science and Technology Cooperation Program of China (2014DFA11350).
ZHOU Shuangshuang, born in 1991, M. S. candidate. Her research interests include natural language processing, information extraction.
XU Jin’an, born in 1970, Ph. D., associate professor. His research interests include natural language processing, machine translation.
CHEN Yufeng, born in 1981, Ph. D., associate professor. Her research interests include natural language processing, artificial intelligence.
ZHANG Yujie, born in 1961, Ph. D., professor. Her research interests include natural language processing, machine translation.
New words detection method for microblog text based on integrating of rules and statistics
ZHOU Shuangshuang, XU Jin’an*, CHEN Yufeng, ZHANG Yujie
(College of Computer and Information Technology, Beijing Jiaotong University, Beijing 100044, China)
The formation rules of microblog new words are extremely complex with high degree of dispersion, and the extracted results by using traditional C/NC-value method have several problems, including relatively low accuracy of the boundary of identified new words and low detection accuracy of new words with low frequency. To solve these problems, a method of integrating heuristic rules, modified C/NC-value method and Conditional Random Field (CRF) model was proposed. On one hand, heuristic rules included the abstracted information of classification and inductive rules focusing on the components of microblog new words. The rules were artificially summarized by using Part Of Speech (POS), character types and symbols through observing a large number of microblog documents. On the other hand, to improve the accuracy of the boundary of identified new words and the detection accuracy of new words with low frequency, traditional C/NC-value method was modified by merging the information of word frequency, branch entropy, mutual information and other statistical features to reconstruct the objective function. Finally, CRF model was used to train and detect new words. The experimental results show that theFvalue of the proposed method in new words detection is improved effectively.
microblog new word; formation rule; statistical feature; C/NC-value method; Conditional Random Field (CRF) model
2016- 09- 25;
2016- 10- 10。 基金項目:國家自然科學基金資助項目(61370130,61473294);中央高校基本科研業務費專項資金資助項目(2014RC040);科學技術部國際科技合作計劃項目(K11F100010)。
周霜霜(1991—),女,遼寧葫蘆島人,碩士研究生,主要研究方向:自然語言處理、信息抽取; 徐金安(1970—),男,河南開封人,副教授,博士,CCF會員,主要研究方向:自然語言處理、機器翻譯; 陳鈺楓(1981—),女,福建南平人,副教授,博士,主要研究方向:自然語言處理、人工智能; 張玉潔(1961—),女,河南安陽人,教授,博士,主要研究方向:自然語言處理、機器翻譯。
1001- 9081(2017)04- 1044- 07
10.11772/j.issn.1001- 9081.2017.04.1044
TP391.1
A
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
Coco薇(2017年11期)2018-01-03 20:59:57
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
